


هدف اصلی Patroni ارائه دسترسی بالا برای PostgreSQL است. اما Patroni فقط یک الگو است، نه یک ابزار آماده (که به طور کلی در مستندات گفته شده است). در نگاه اول، با راهاندازی Patroni در آزمایشگاه آزمایش، میتوانید ببینید که چه ابزار عالی است و چقدر به راحتی از پس تلاشهای ما برای شکستن خوشه بر میآید. با این حال، در عمل، در یک محیط تولید، همه چیز همیشه به زیبایی و زیبایی در یک آزمایشگاه آزمایشی اتفاق نمی افتد.

من کمی از خودم برایتان می گویم. من به عنوان یک مدیر سیستم شروع به کار کردم. در توسعه وب کار کرده است. من از سال 2014 در Data Egret کار می کنم. این شرکت به مشاوره در زمینه Postgres مشغول است. و ما دقیقا به Postgres خدمت می کنیم و هر روز با Postgres کار می کنیم، بنابراین تخصص های مختلفی در رابطه با عملیات داریم.
و در پایان سال 2018، ما به آرامی شروع به استفاده از Patroni کردیم. و مقداری تجربه انباشته شده است. ما به نوعی آن را تشخیص دادیم، آن را تنظیم کردیم، به بهترین شیوه های خود رسیدیم. و در این گزارش در مورد آنها صحبت خواهم کرد.
علاوه بر Postgres، من دوست دارم Linuxمن عاشق سرهمبندی و کاوش در آن هستم، و عاشق ساختن هستهها هستم. من عاشق مجازیسازی، کانتینرها، داکر و کوبرنتیز هستم. من به همه اینها علاقهمند هستم زیرا عادات قدیمی مدیریتی من در حال جبران است. من عاشق سرهمبندی با مانیتورینگ هستم. من همچنین عاشق چیزهای مرتبط با مدیریت Postgres، مانند تکثیر و پشتیبانگیری هستم. و در اوقات فراغتم، با Go مینویسم. من یک مهندس نرمافزار نیستم، فقط برای خودم با Go مینویسم. و از آن لذت میبرم.

- من فکر می کنم بسیاری از شما می دانید که Postgres HA (در دسترس بودن بالا) را از جعبه ندارد. برای دریافت HA، باید چیزی را نصب کنید، پیکربندی کنید، تلاش کنید و آن را دریافت کنید.
- چندین ابزار وجود دارد و Patroni یکی از آنهاست که HA را بسیار جالب و بسیار خوب حل می کند. اما با قرار دادن همه آن در یک آزمایشگاه آزمایشی و اجرای آن، میتوانیم ببینیم که همه کار میکنند، میتوانیم برخی از مشکلات را بازتولید کنیم، ببینیم Patroni چگونه به آنها خدمت میکند. و خواهیم دید که همه چیز عالی کار می کند.
- اما در عمل با مشکلات متفاوتی مواجه شدیم. و من در مورد این مشکلات صحبت خواهم کرد.
- من به شما خواهم گفت که چگونه آن را تشخیص دادیم، چه چیزی را بهینه کردیم - آیا این به ما کمک کرد یا نه.

- من به شما نمی گویم چگونه Patroni را نصب کنید، زیرا می توانید در اینترنت در گوگل جستجو کنید، می توانید به فایل های پیکربندی نگاه کنید تا بفهمید همه چیز چگونه شروع می شود، چگونه پیکربندی می شود. شما می توانید طرح ها، معماری ها، پیدا کردن اطلاعات در مورد آن را در اینترنت درک کنید.
- من در مورد تجربه شخص دیگری صحبت نمی کنم. من فقط در مورد مشکلاتی که با آن مواجه بودیم صحبت خواهم کرد.
- و من در مورد مشکلاتی که خارج از Patroni و PostgreSQL هستند صحبت نمی کنم. به عنوان مثال، اگر مشکلاتی در ارتباط با تعادل وجود داشته باشد، زمانی که خوشه ما سقوط کرده است، در مورد آن صحبت نمی کنم.

و یک سلب مسئولیت کوچک قبل از شروع گزارش خود.
همه این مشکلاتی که ما با آن مواجه شدیم، در 6-7-8 ماه اول فعالیت داشتیم. با گذشت زمان، به بهترین شیوه های داخلی خود رسیدیم. و مشکلات ما از بین رفت. بنابراین، این گزارش حدود شش ماه پیش اعلام شد، زمانی که همه چیز در ذهنم تازه بود و همه آن را به خوبی به خاطر داشتم.
در حین تهیه گزارش، من قبلاً قتل های قدیمی را جمع آوری کردم، به سیاهههای مربوط نگاه کردم. و برخی از جزئیات را می توان فراموش کرد، یا برخی از برخی از جزئیات را نمی توان به طور کامل در طول تجزیه و تحلیل مشکلات بررسی کرد، بنابراین در برخی موارد ممکن است به نظر برسد که مشکلات به طور کامل در نظر گرفته نشده است، یا مقداری کمبود اطلاعات وجود دارد. و بنابراین از شما می خواهم که مرا برای این لحظه معذرت خواهی کنید.

پاترونی چیست؟
- این یک الگو برای ساختن HA است. این چیزی است که در مستندات می گوید. و از نظر من، این یک توضیح بسیار درست است. Patroni یک گلوله نقره ای نیست که تمام مشکلات شما را حل کند، یعنی باید تلاش کنید تا آن را به کار ببندید و منفعت هایی را به همراه داشته باشید.
- این یک سرویس عامل است که روی هر سرویس پایگاه داده نصب می شود و نوعی سیستم init برای Postgres شما است. Postgres را شروع می کند، متوقف می شود، راه اندازی مجدد می شود، پیکربندی مجدد می کند و توپولوژی خوشه شما را تغییر می دهد.
- بر این اساس، برای ذخیره وضعیت خوشه، نمایش فعلی آن، همانطور که به نظر می رسد، به نوعی ذخیره سازی نیاز است. و از این منظر پاترونی مسیر ذخیره سازی حالت را در یک سیستم خارجی در پیش گرفت. این یک سیستم ذخیره سازی پیکربندی توزیع شده است. این می تواند Etcd، Consul، ZooKeeper یا kubernetes Etcd باشد، یعنی یکی از این گزینه ها.
- و یکی از ویژگی های Patroni این است که شما فقط با راه اندازی فایل خودکار را از جعبه خارج می کنید. اگر Repmgr را برای مقایسه در نظر بگیریم، پس فایلر در آنجا گنجانده شده است. با Repmgr، ما یک جابجایی دریافت می کنیم، اما اگر یک فایل خودکار می خواهیم، باید آن را به صورت اضافی پیکربندی کنیم. Patroni در حال حاضر یک Autofiler خارج از جعبه دارد.
- و خیلی چیزهای دیگر هم هست. به عنوان مثال، نگهداری از تنظیمات، ریختن ماکت های جدید، پشتیبان گیری، و غیره. اما این خارج از حوصله گزارش است، من در مورد آن صحبت نمی کنم.

و یک نتیجه کوچک این است که وظیفه اصلی Patroni این است که یک فایل خودکار را به خوبی و با اطمینان انجام دهد تا خوشه ما عملیاتی بماند و برنامه متوجه تغییرات در توپولوژی کلاستر نشود.

اما وقتی شروع به استفاده از Patroni می کنیم، سیستم ما کمی پیچیده تر می شود. اگر قبلا Postgres داشتیم، پس هنگام استفاده از Patroni خود Patroni را دریافت می کنیم، DCS را در جایی که وضعیت ذخیره می شود دریافت می کنیم. و همه چیز باید به نحوی کار کند. پس چه چیزی می تواند اشتباه باشد؟
ممکن است شکسته شود:
- Postgres ممکن است شکسته شود. این می تواند یک Master یا Replica باشد، یکی از آنها ممکن است شکست بخورد.
- ممکن است خود پاترونی بشکند.
- DCS که در آن حالت ذخیره می شود ممکن است خراب شود.
- و شبکه می تواند شکسته شود.
همه این نکات را در گزارش بررسی خواهم کرد.

من پرونده ها را با پیچیده تر شدن آنها در نظر می گیرم، نه از این منظر که پرونده شامل اجزای زیادی باشد. و از نظر احساسات ذهنی، که این مورد برای من سخت بود، جدا کردن آن دشوار بود ... و بالعکس، برخی از موارد سبک بود و به راحتی آن را جدا کرد.

و مورد اول ساده ترین است. این مورد زمانی است که ما یک کلاستر پایگاه داده را گرفتیم و فضای ذخیره سازی DCS خود را در همان خوشه مستقر کردیم. این رایج ترین اشتباه است. این یک اشتباه در معماری ساختمان است، یعنی ترکیب اجزای مختلف در یک مکان.
بنابراین، یک پرونده وجود داشت، بیایید برویم تا به اتفاقی که افتاده رسیدگی کنیم.

و در اینجا ما علاقه مند هستیم که پرونده چه زمانی اتفاق افتاده است. یعنی ما علاقه مند به این لحظه از زمان هستیم که حالت خوشه تغییر کرده است.
اما فایلر همیشه آنی نیست، یعنی هیچ واحد زمان نمی برد، می توان آن را به تاخیر انداخت. می تواند طولانی مدت باشد.
بنابراین، یک زمان شروع و یک زمان پایان دارد، یعنی یک رویداد پیوسته است. و همه رویدادها را به سه بازه تقسیم میکنیم: قبل از فایلکننده، در طول فایلکننده و بعد از فایلکننده زمان داریم. یعنی همه وقایع را در این جدول زمانی در نظر می گیریم.

و اولین چیز، زمانی که یک فایلر اتفاق افتاد، ما به دنبال علت اتفاقی هستیم که علت آن چه بوده است که منجر به فایلر شده است.
اگر به سیاههها نگاه کنیم، آنها سیاهههای مربوط به پاترونی کلاسیک خواهند بود. او در آنها به ما می گوید که سرور مستر شده است و نقش استاد به این گره رسیده است. در اینجا برجسته شده است.

در مرحله بعد، باید بفهمیم که چرا فایلر اتفاق افتاده است، یعنی چه اتفاقاتی رخ داده است که باعث شده نقش اصلی از یک گره به گره دیگر منتقل شود. و در این مورد، همه چیز ساده است. ما در تعامل با سیستم ذخیره سازی خطا داریم. استاد متوجه شد که نمی تواند با DCS کار کند، یعنی نوعی مشکل در تعامل وجود دارد. و می گوید دیگر نمی تواند استاد باشد و استعفا می دهد. این خط "خود تنزل یافته" دقیقا همین را می گوید.

اگر به وقایع قبل از فایلر نگاه کنیم، میتوانیم همان دلایلی را ببینیم که باعث ادامه مشکل در ویزارد شده است.
اگر به لاگ های Patroni نگاه کنیم، می بینیم که خطاها، تایم اوت های زیادی داریم، یعنی عامل Patroni نمی تواند با DCS کار کند. در این مورد، این نماینده کنسول است که در پورت 8500 در حال ارتباط است.
مشکل اینجاست که پاترونی و پایگاه داده روی یک میزبان اجرا میشوند. سرورهای کنسول نیز روی همین میزبان اجرا میشدند. با ایجاد بار روی سرور، مشکلاتی برای ... ایجاد کردیم. سرورها کنسول. آنها قادر به برقراری ارتباط عادی نبودند.

پس از مدتی که بار فروکش کرد، حامی ما دوباره توانست با ماموران ارتباط برقرار کند. کار عادی از سر گرفته شد و دوباره همان سرور Pgdb-2 استاد شد. یعنی یک تلنگر کوچک وجود داشت که به دلیل آن گره از قدرت های استاد استعفا داد و سپس آنها را دوباره به دست گرفت ، یعنی همه چیز همانطور که بود برگشت.

و این را می توان به عنوان یک هشدار نادرست در نظر گرفت، یا می توان در نظر گرفت که پاترونی همه چیز را درست انجام داده است. یعنی متوجه شد که نمی تواند حالت خوشه را حفظ کند و اختیار خود را حذف کرد.
و در اینجا به دلیل این که سرورهای کنسول روی همان سخت افزار پایه ها هستند، مشکل به وجود آمد. بر این اساس، هر بار: چه بار روی دیسک ها یا پردازنده ها باشد، بر تعامل با کلاستر کنسول نیز تأثیر می گذارد.

و ما تصمیم گرفتیم که نباید با هم زندگی کنند، ما یک خوشه جداگانه برای کنسول اختصاص دادیم. و پاترونی قبلاً با یک کنسول جداگانه کار می کرد، یعنی یک خوشه Postgres جداگانه، یک خوشه کنسول جداگانه وجود داشت. این یک دستورالعمل اساسی در مورد نحوه حمل و نگهداری همه این چیزها است تا با هم زندگی نکند.
به عنوان یک گزینه، می توانید پارامترهای ttl، loop_wait، retry_timeout را بچرخانید، یعنی سعی کنید با افزایش این پارامترها از این پیک های بار کوتاه مدت جان سالم به در ببرید. اما این مناسب ترین گزینه نیست، زیرا این بار می تواند در زمان طولانی باشد. و ما به سادگی از این حدود این پارامترها فراتر خواهیم رفت. و این ممکن است واقعا کمکی نکند.
مشکل اول همانطور که متوجه شدید ساده است. DCS را گرفتیم و با پایه کنار هم گذاشتیم، مشکل پیدا کردیم.

مشکل دوم مشابه مشکل اول است. مشابه این است که ما دوباره با سیستم DCS مشکل همکاری داریم.

اگر به لاگ ها نگاه کنیم، می بینیم که دوباره خطای ارتباطی داریم. و Patroni می گوید من نمی توانم با DCS تعامل داشته باشم بنابراین استاد فعلی به حالت replica می رود.
استاد قدیمی تبدیل به یک ماکت می شود، در اینجا Patroni همانطور که باید کار می کند. pg_rewind را اجرا می کند تا گزارش تراکنش را به عقب برگرداند و سپس به master جدید متصل شود تا با استاد جدید روبرو شود. در اینجا پاترونی همانطور که باید کار می کند.

در اینجا باید مکانی را که قبل از فایلر وجود دارد، پیدا کنیم، یعنی آن خطاهایی که باعث شده ما یک فایلر داشته باشیم. و از این نظر، سیاهههای مربوط به Patroni برای کار با آنها بسیار راحت است. او همان پیام ها را در یک فاصله زمانی مشخص می نویسد. و اگر سریع شروع به پیمایش در این لاگ ها کنیم، از لاگ ها می بینیم که لاگ ها تغییر کرده اند، به این معنی که برخی از مشکلات شروع شده است. سریع به این مکان برمی گردیم، ببینیم چه می شود.
و در یک وضعیت عادی، سیاهههای مربوط چیزی شبیه به این هستند. صاحب قفل چک می شود. و اگر مالک، به عنوان مثال، تغییر کرده باشد، ممکن است اتفاقاتی رخ دهد که پاترونی باید به آنها پاسخ دهد. اما در این مورد ما خوب هستیم. ما به دنبال جایی هستیم که خطاها از آنجا شروع شده اند.

و با پیمایش به نقطه ای که خطاها شروع به ظاهر شدن کردند، می بینیم که یک فایل خودکار داشته ایم. و از آنجایی که خطاهای ما مربوط به تعامل با DCS بود و در مورد ما از Consul استفاده کردیم، ما همچنین به گزارش Consul نگاه می کنیم که در آنجا چه اتفاقی افتاده است.
تقریباً با مقایسه زمان پرونده و زمان در لاگ های کنسول، می بینیم که همسایگان ما در خوشه کنسول نسبت به وجود سایر اعضای خوشه کنسول شک کردند.

و اگر به گزارش های دیگر نمایندگان کنسول نگاه کنید، همچنین می توانید ببینید که نوعی فروپاشی شبکه در آنجا در حال وقوع است. و همه اعضای خوشه کنسول به وجود یکدیگر شک دارند. و این انگیزه ای برای پرونده ساز بود.
اگر به اتفاقات قبل از این خطاها نگاه کنید، می بینید که انواع خطاها وجود دارد، به عنوان مثال، مهلت، RPC سقوط کرد، یعنی به وضوح نوعی مشکل در تعامل اعضای کلاستر کنسول با یکدیگر وجود دارد. .

ساده ترین پاسخ تعمیر شبکه است. اما برای من که روی سکو ایستاده ام، گفتن این حرف آسان است. اما شرایط به گونه ای است که همیشه مشتری نمی تواند هزینه تعمیر شبکه را داشته باشد. او ممکن است در یک DC زندگی کند و ممکن است نتواند شبکه را تعمیر کند، روی تجهیزات تأثیر بگذارد. و بنابراین برخی گزینه های دیگر مورد نیاز است.

گزینه هایی وجود دارد:
- ساده ترین گزینه که به نظر من حتی در مستندات نوشته شده است، غیرفعال کردن چک های کنسول است، یعنی به سادگی یک آرایه خالی را پاس کنید. و به نماینده کنسول می گوییم از هیچ چکی استفاده نکند. با این بررسی ها می توانیم این طوفان های شبکه را نادیده بگیریم و فایلری را راه اندازی نکنیم.
- گزینه دیگر این است که raft_multiplier را دوبار بررسی کنید. این پارامتر مربوط به خود سرور کنسول است. به طور پیش فرض روی 5 تنظیم شده است. این مقدار توسط مستندات برای محیط های مرحله بندی توصیه می شود. در واقع این موضوع بر فرکانس پیام رسانی بین اعضای شبکه کنسول تأثیر می گذارد. در واقع این پارامتر بر سرعت ارتباط سرویس بین اعضای خوشه کنسول تاثیر می گذارد. و برای تولید، قبلاً توصیه می شود آن را کاهش دهید تا گره ها بیشتر پیام ها را مبادله کنند.
- گزینه دیگری که به آن رسیده ایم، افزایش اولویت فرآیندهای Consul در بین سایر فرآیندها برای زمانبندی فرآیند سیستم عامل است. چنین پارامتر "خوب" وجود دارد، فقط اولویت فرآیندهایی را تعیین می کند که توسط زمانبندی سیستم عامل هنگام برنامه ریزی در نظر گرفته می شود. ما همچنین ارزش خوب را برای نمایندگان کنسول کاهش داده ایم. اولویت را افزایش داد تا سیستم عامل به فرآیندهای کنسول زمان بیشتری برای کار و اجرای کد آنها بدهد. در مورد ما، این مشکل ما را حل کرد.
- گزینه دیگر استفاده نکردن از کنسول است. من دوستی دارم که طرفدار بزرگ Etcd است. و ما مرتب با او بحث می کنیم که Etcd یا Consul بهتر است. اما از نظر اینکه کدام بهتر است، ما معمولاً با او موافقیم که کنسول یک عامل دارد که باید روی هر گره با یک پایگاه داده اجرا شود. یعنی تعامل پاترونی با خوشه کنسول از طریق این عامل انجام می شود. و این عامل تبدیل به گلوگاه می شود. اگر اتفاقی برای نماینده بیفتد، آنگاه Patroni دیگر نمی تواند با خوشه کنسول کار کند. و این مشکل است. هیچ عاملی در طرح Etcd وجود ندارد. Patroni می تواند مستقیماً با لیستی از سرورهای Etcd کار کند و از قبل با آنها ارتباط برقرار کند. از این نظر، اگر از Etcd در شرکت خود استفاده می کنید، احتمالا Etcd انتخاب بهتری نسبت به Consul خواهد بود. اما ما در مشتریانمان همیشه با انتخاب و استفاده مشتری محدود می شویم. و ما در بیشتر موارد برای همه مشتریان کنسول داریم.
- و آخرین نکته تجدید نظر در مقادیر پارامتر است. ما می توانیم این پارامترها را افزایش دهیم به این امید که مشکلات شبکه کوتاه مدت ما کوتاه باشد و از محدوده این پارامترها خارج نشود. به این ترتیب میتوانیم در صورت بروز برخی مشکلات شبکه، تهاجمی Patroni را به فایل خودکار کاهش دهیم.
فکر می کنم بسیاری از کسانی که از Patroni استفاده می کنند با این دستور آشنا هستند.
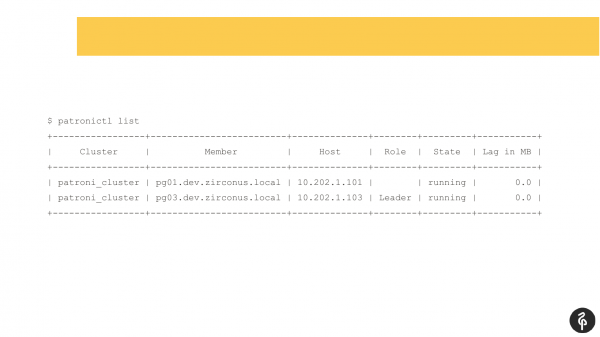
این دستور وضعیت فعلی خوشه را نشان می دهد. و در نگاه اول، این تصویر ممکن است عادی به نظر برسد. ما یک استاد داریم، یک ماکت داریم، هیچ تاخیر تکراری وجود ندارد. اما این تصویر دقیقاً طبیعی است تا زمانی که بدانیم این خوشه باید سه گره داشته باشد نه دو.

بر این اساس، یک فایل خودکار وجود داشت. و بعد از این فایل خودکار، ماکت ما ناپدید شد. ما باید دلیل ناپدید شدن او را پیدا کنیم و او را برگردانیم، او را بازیابی کنیم. و دوباره به گزارشها میرویم و میبینیم که چرا فایلافزار خودکار داشتیم.

در این صورت ماکت دوم استاد شد. اینجا همه چیز درست است.

و ما باید به ماکتی که افتاد و در خوشه نیست نگاه کنیم. لاگ های Patroni را باز می کنیم و می بینیم که در مراحل اتصال به کلاستر در مرحله pg_rewind با مشکل مواجه شده ایم. برای اتصال به خوشه، باید گزارش تراکنش را به عقب برگردانید، گزارش تراکنش مورد نیاز را از Master درخواست کنید و از آن برای رسیدن به Master استفاده کنید.
در این حالت، ما گزارش تراکنش نداریم و ماکت نمی تواند شروع شود. بر این اساس، Postgres را با یک خطا متوقف می کنیم. و بنابراین در خوشه نیست.

ما باید بفهمیم که چرا در خوشه نیست و چرا لاگ وجود ندارد. به سراغ استاد جدید می رویم و به آنچه در سیاهه ها دارد نگاه می کنیم. معلوم شد که وقتی pg_rewind انجام شد، یک چک پوینت رخ داد. و برخی از لاگ های تراکنش های قدیمی به سادگی تغییر نام دادند. وقتی استاد قدیمی سعی کرد به استاد جدید متصل شود و این گزارشها را جستجو کند، آنها قبلاً تغییر نام داده بودند، فقط وجود نداشتند.

زمانی که این وقایع اتفاق افتاد، مهرهای زمانی را مقایسه کردم. و در آنجا تفاوت به معنای واقعی کلمه 150 میلی ثانیه است، یعنی، ایست بازرسی که در 369 میلی ثانیه تکمیل شد، بخش های WAL تغییر نام دادند. و به معنای واقعی کلمه در سال 517، پس از 150 میلی ثانیه، به عقب بر روی ماکت قدیمی شروع شد. یعنی به معنای واقعی کلمه 150 میلی ثانیه برای ما کافی بود تا ماکت نتواند متصل شود و درآمد کسب کند.

چه گزینه هایی وجود دارد؟
ما در ابتدا از اسلات های تکرار استفاده می کردیم. ما فکر می کردیم خوب است. اگرچه در مرحله اول عملیات ما اسلات ها را خاموش کردیم. به نظر ما این بود که اگر اسلات ها بخش های WAL زیادی را جمع کنند، می توانیم Master را رها کنیم. او سقوط خواهد کرد. مدتی بدون اسلات رنج کشیدیم. و متوجه شدیم که به اسلات نیاز داریم، اسلات ها را برگرداندیم.
اما در اینجا یک مشکل وجود دارد، این که وقتی Master به Replica می رود، اسلات ها را حذف می کند و سگمنت های WAL را به همراه اسلات ها حذف می کند. و برای رفع این مشکل تصمیم گرفتیم که پارامتر wal_keep_segments را بالا ببریم. به طور پیش فرض 8 بخش است. ما آن را به 1 رساندیم و دیدیم چقدر فضای خالی داریم. و ما 000 گیگابایت برای wal_keep_segments اهدا کردیم. یعنی در هنگام سوئیچینگ، ما همیشه یک ذخیره 16 گیگابایتی لاگ تراکنش در تمام گره ها داریم.
و به علاوه - هنوز هم برای کارهای تعمیر و نگهداری طولانی مدت مرتبط است. فرض کنید باید یکی از ماکت ها را به روز کنیم. و ما می خواهیم آن را خاموش کنیم. ما باید نرم افزار را به روز کنیم، شاید سیستم عامل، چیز دیگری. و هنگامی که ماکت را خاموش می کنیم، شکاف آن ماکت نیز حذف می شود. و اگر از یک wal_keep_segments کوچک استفاده کنیم، با غیبت طولانی از یک replica، لاگ های تراکنش از بین خواهند رفت. ما یک replica ایجاد می کنیم، آن لاگ های تراکنش را در جایی که متوقف شده است درخواست می کند، اما ممکن است روی Master نباشند. و ماکت نیز قادر به اتصال نخواهد بود. بنابراین، ما انبار زیادی از مجلات داریم.

ما یک پایگاه تولید داریم. در حال حاضر پروژه هایی در حال انجام است.
یک فیلر وجود داشت. ما وارد شدیم و نگاه کردیم - همه چیز مرتب است، ماکت ها سر جای خود هستند، هیچ تاخیر تکراری وجود ندارد. در لاگ ها هم هیچ خطایی وجود ندارد، همه چیز مرتب است.
تیم محصول می گوید که باید مقداری داده وجود داشته باشد، اما ما آن را از یک منبع می بینیم، اما آن را در پایگاه داده نمی بینیم. و ما باید بفهمیم چه اتفاقی برای آنها افتاده است.

واضح است که pg_rewind آنها را از دست داده است. ما بلافاصله این را فهمیدیم، اما رفتیم تا ببینیم چه اتفاقی می افتد.

در گزارشها، ما همیشه میتوانیم پیدا کنیم که فایلکننده چه زمانی اتفاق افتاده است، چه کسی استاد شده است، و میتوانیم تعیین کنیم که استاد قدیمی چه کسی بوده و چه زمانی میخواهد تبدیل به یک نسخه شود، یعنی ما به این گزارشها نیاز داریم تا میزان گزارشهای تراکنش را پیدا کنیم. گم شده بود.
استاد قدیمی ما راه اندازی مجدد شده است. و Patroni در autorun ثبت شد. Patroni را راه اندازی کرد. او سپس Postgres را راه اندازی کرد. به طور دقیق تر، قبل از راه اندازی Postgres و قبل از اینکه آن را یک کپی کند، Patroni فرآیند pg_rewind را راه اندازی کرد. بر این اساس، او بخشی از گزارش تراکنش ها را پاک کرد، موارد جدید را دانلود کرد و متصل شد. در اینجا پاترونی هوشمندانه کار کرد، یعنی همانطور که انتظار می رفت. خوشه بازسازی شده است. ما 3 گره داشتیم، بعد از فیلر 3 گره - همه چیز عالی است.

ما برخی از داده ها را از دست داده ایم. و باید بفهمیم چقدر از دست داده ایم. ما فقط به دنبال لحظه ای هستیم که عقبگرد داشته باشیم. ما می توانیم آن را در چنین نوشته های مجله پیدا کنیم. Rewind شروع شد، کاری انجام داد و به پایان رسید.

ما باید موقعیتی را در گزارش تراکنش پیدا کنیم که استاد قدیمی در آنجا متوقف شده است. در این مورد، این علامت است. و ما به یک علامت دوم نیاز داریم، یعنی فاصله ای که استاد قدیمی با جدید متفاوت است.
pg_wal_lsn_diff معمولی را می گیریم و این دو علامت را با هم مقایسه می کنیم. و در این حالت 17 مگابایت می گیریم. کم یا زیاد، هر کس برای خودش تصمیم می گیرد. چون برای کسی 17 مگ زیاد نیست، برای کسی زیاد و غیرقابل قبول است. در اینجا هر فردی برای خود مطابق با نیازهای کسب و کار تعیین می کند.

اما ما برای خودمان چه چیزی دریافتیم؟
اول، ما باید خودمان تصمیم بگیریم - آیا همیشه به پاترونی برای راه اندازی خودکار پس از راه اندازی مجدد سیستم نیاز داریم؟ خیلی وقت ها پیش می آید که باید به سراغ استاد پیر برویم، ببینیم چقدر پیش رفته است. شاید بخشهایی از گزارش تراکنش را بررسی کنید، ببینید چه چیزی در آنجا وجود دارد. و برای اینکه بفهمیم آیا میتوانیم این دادهها را از دست بدهیم یا اینکه برای بیرون کشیدن این دادهها باید Master قدیمی را در حالت مستقل اجرا کنیم.
و تنها پس از آن باید تصمیم بگیریم که آیا میتوانیم این دادهها را دور بیندازیم یا میتوانیم آنها را بازیابی کنیم، این گره را به عنوان یک کپی به خوشه خود متصل کنیم.
علاوه بر این، یک پارامتر "maximum_lag_on_failover" وجود دارد. به طور پیش فرض، اگر حافظه من به من کمک کند، این پارامتر دارای مقدار 1 مگابایت است.
او چگونه کار می کند؟ اگر ماکت ما با 1 مگابایت داده در تاخیر تکرار عقب باشد، پس این ماکت در انتخابات شرکت نمی کند. و اگر ناگهان فایلی به وجود بیاید، Patroni نگاه می کند که کدام نسخه ها عقب مانده اند. اگر آنها از تعداد زیادی گزارش تراکنش عقب باشند، نمی توانند استاد شوند. این یک ویژگی امنیتی بسیار خوب است که از از دست دادن داده های زیادی جلوگیری می کند.
اما یک مشکل وجود دارد که تاخیر تکرار در خوشه Patroni و DCS در یک بازه زمانی مشخص به روز می شود. من فکر می کنم 30 ثانیه مقدار پیش فرض ttl است.
بر این اساس، ممکن است شرایطی وجود داشته باشد که برای کپیها در DCS یک تأخیر وجود داشته باشد، اما در واقع ممکن است تاخیر کاملاً متفاوتی وجود داشته باشد یا اصلاً تأخیر وجود نداشته باشد، یعنی این مورد واقعی نیست. و همیشه تصویر واقعی را منعکس نمی کند. و ارزش آن را ندارد که منطق فانتزی روی آن انجام دهیم.
و خطر از دست دادن همیشه باقی می ماند. و در بدترین حالت یک فرمول و در حالت متوسط فرمول دیگر. یعنی زمانی که ما اجرای Patroni را برنامه ریزی می کنیم و ارزیابی می کنیم که چه مقدار داده می توانیم از دست بدهیم، باید به این فرمول ها تکیه کنیم و تقریباً تصور کنیم که چقدر داده می توانیم از دست بدهیم.
و خبرهای خوبی وجود دارد. وقتی استاد قدیمی جلو رفته است، به دلیل برخی از فرآیندهای پس زمینه می تواند جلو برود. یعنی نوعی autovacuum وجود داشت، او داده ها را نوشت، آنها را در لاگ تراکنش ذخیره کرد. و ما به راحتی می توانیم این داده ها را نادیده بگیریم و از دست بدهیم. هیچ مشکلی در این مورد وجود ندارد.

و اگر Maximum_lag_on_failover تنظیم شده باشد و فایلری رخ داده باشد، و شما باید یک Master جدید را انتخاب کنید، اینگونه به نظر می رسد. ماکت خود را ناتوان از شرکت در انتخابات ارزیابی می کند. و او از شرکت در مسابقه برای رهبری امتناع می ورزد. و منتظر می ماند تا استاد جدیدی انتخاب شود تا بتواند به آن متصل شود. این یک اقدام اضافی در برابر از دست دادن اطلاعات است.

در اینجا ما یک تیم محصول داریم که نوشته اند محصول آنها با Postgres مشکل دارد. در عین حال، خود استاد قابل دسترسی نیست، زیرا از طریق SSH در دسترس نیست. و فایل خودکار نیز اتفاق نمی افتد.
این میزبان مجبور به راه اندازی مجدد شد. به دلیل راهاندازی مجدد، یک فایل خودکار اتفاق افتاد، اگرچه همانطور که اکنون فهمیدم امکان انجام یک فایل خودکار دستی وجود داشت. و پس از راهاندازی مجدد، ما از قبل میخواهیم ببینیم که با استاد فعلی چه چیزی داشتیم.
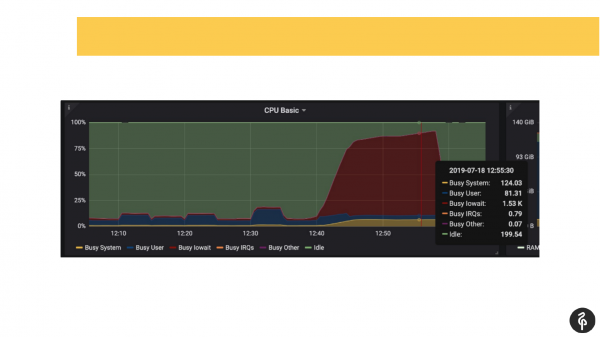
در همان زمان، ما از قبل می دانستیم که با دیسک ها مشکل داریم، یعنی از قبل می دانستیم که کجا باید حفاری کنیم و به دنبال چه چیزی باشیم.

ما وارد دفتر ثبت پست شدیم، شروع کردیم به دیدن آنچه در آنجا اتفاق می افتد. ما شاهد commit هایی بودیم که در آنجا یک، دو، سه ثانیه طول می کشد که اصلا طبیعی نیست. دیدیم که اتوواکیوم ما خیلی کند و عجیب راه اندازی می شود. و فایل های موقتی را روی دیسک دیدیم. یعنی همه اینها نشانگر مشکلات دیسک هستند.

ما به سیستم dmesg (گزارش هسته) نگاه کردیم. و دیدیم که با یکی از دیسک ها مشکل داریم. زیرسیستم دیسک نرم افزار Raid بود. ما به /proc/mdstat نگاه کردیم و دیدیم که یک درایو را از دست داده ایم. یعنی یک Raid از 8 دیسک وجود دارد، ما یکی را از دست می دهیم. اگر با دقت به اسلاید نگاه کنید، در خروجی می توانید ببینید که ما sde در آنجا نداریم. در ما، به طور مشروط، دیسک حذف شده است. این باعث بروز مشکلاتی در دیسک شد و برنامهها نیز هنگام کار با خوشه Postgres با مشکلاتی مواجه شدند.

و در این مورد، Patroni به هیچ وجه به ما کمک نمی کند، زیرا Patroni وظیفه نظارت بر وضعیت سرور، وضعیت دیسک را ندارد. و ما باید چنین شرایطی را با نظارت خارجی رصد کنیم. ما به سرعت مانیتورینگ دیسک را به نظارت خارجی اضافه کردیم.
و چنین فکری وجود داشت - آیا نرم افزار شمشیربازی یا نگهبان می تواند به ما کمک کند؟ ما فکر می کردیم که او به سختی می تواند در این مورد به ما کمک کند، زیرا در طول مشکلات، Patroni به تعامل با خوشه DCS ادامه داد و هیچ مشکلی ندید. یعنی از نظر DCS و Patroni همه چیز با خوشه خوب بود ، اگرچه در واقع مشکلاتی با دیسک وجود داشت ، مشکلات در دسترس بودن پایگاه داده وجود داشت.
به نظر من، این یکی از عجیب ترین مشکلاتی است که من برای مدت طولانی در مورد آن تحقیق کرده ام، بسیاری از لاگ ها را خوانده ام، دوباره انتخاب کرده ام و اسم آن را شبیه ساز خوشه گذاشته ام.

مشکل این بود که استاد قدیمی نمی توانست تبدیل به یک ماکت معمولی شود، یعنی پاترونی آن را شروع کرد، پاترونی نشان داد که این گره به عنوان یک ماکت وجود دارد، اما در عین حال یک ماکت معمولی نیست. حالا خواهید دید که چرا. این چیزی است که من از تجزیه و تحلیل آن مشکل حفظ کرده ام.

و چگونه همه چیز شروع شد؟ مانند مشکل قبلی با ترمزهای دیسکی شروع شد. ما برای یک ثانیه، دو تعهد داشتیم.

در اتصالات قطع شد، یعنی مشتریان پاره شدند.

انسدادهایی با شدت متفاوت وجود داشت.

و بر این اساس، زیرسیستم دیسک خیلی پاسخگو نیست.

و مرموزترین چیز برای من درخواست خاموش کردن فوری است که رسید. Postgres دارای سه حالت خاموش شدن است:
- وقتی منتظر می مانیم تا همه مشتریان به تنهایی ارتباط خود را قطع کنند، بسیار خوب است.
- زمانی که ما مشتریان را مجبور به قطع ارتباط می کنیم، به دلیل اینکه قصد خاموش شدن داریم، سریع است.
- و فوری. در این مورد، فوری حتی به مشتریان نمی گوید که خاموش شوند، فقط بدون هشدار خاموش می شود. و به همه کلاینتها، سیستم عامل قبلاً یک پیام RST ارسال میکند (پیام TCP مبنی بر اینکه اتصال قطع شده است و کلاینت چیز دیگری برای گرفتن ندارد).
چه کسی این سیگنال را ارسال کرده است؟ فرآیندهای پسزمینه Postgres چنین سیگنالهایی را به یکدیگر ارسال نمیکنند، یعنی این kill-9 است. آنها چنین چیزهایی را برای یکدیگر نمی فرستند، آنها فقط به چنین چیزهایی واکنش نشان می دهند، یعنی این یک راه اندازی مجدد اضطراری Postgres است. کی فرستاده نمیدونم
من به دستور "آخرین" نگاه کردم و یک نفر را دیدم که او نیز با ما وارد این سرور شده است، اما از پرسیدن سوال خجالتی بودم. شاید کشتن -9 بود. من کشتن -9 را در لاگ ها می بینم، زیرا Postgres می گوید kill -9 طول کشید، اما من آن را در لاگ ها ندیدم.

با نگاهی بیشتر، دیدم که Patroni برای مدت طولانی - 54 ثانیه - به گزارش نامه نمی نویسد. و اگر دو مهر زمان را با هم مقایسه کنیم، هیچ پیامی برای حدود 54 ثانیه وجود نداشت.
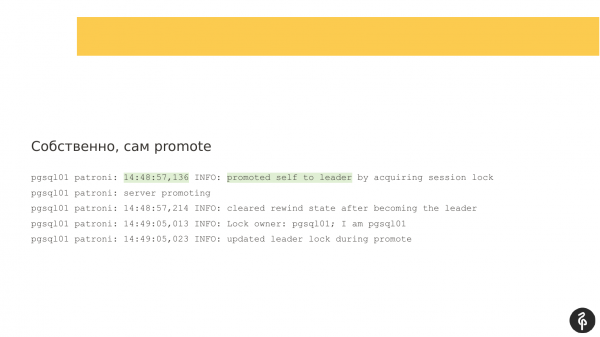
و در این مدت یک فایل خودکار وجود داشت. پاترونی دوباره اینجا کار بزرگی انجام داد. استاد قدیمی ما در دسترس نبود، اتفاقی برای او افتاد. و انتخاب استاد جدید آغاز شد. اینجا همه چیز خوب پیش رفت. pgsql01 ما به رهبر جدید تبدیل شده است.

ما یک ماکت داریم که استاد شده است. و یک پاسخ دوم وجود دارد. و در ماکت دوم مشکلاتی وجود داشت. او سعی کرد دوباره پیکربندی کند. همانطور که من متوجه شدم، او سعی کرد recovery.conf را تغییر دهد، Postgres را مجددا راه اندازی کند و به استاد جدید متصل شود. او هر 10 ثانیه پیام هایی می نویسد که تلاش می کند، اما موفق نمی شود.

و در طول این تلاش ها، یک سیگنال خاموش شدن فوری به استاد قدیمی می رسد. استاد راه اندازی مجدد می شود. و همچنین بازیابی متوقف می شود زیرا استاد قدیمی وارد راه اندازی مجدد می شود. یعنی ماکت نمی تواند به آن وصل شود، زیرا در حالت خاموش شدن است.

در مقطعی کار کرد، اما تکرار شروع نشد.
تنها حدس من این است که یک آدرس اصلی قدیمی در recovery.conf وجود دارد. و هنگامی که یک استاد جدید ظاهر شد، نسخه دوم همچنان سعی می کرد به استاد قدیمی متصل شود.
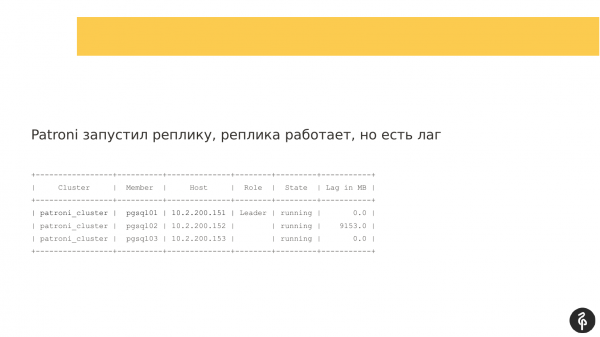
هنگامی که Patroni روی نسخه دوم راه اندازی شد، گره شروع به کار کرد اما نتوانست تکرار شود. و یک تاخیر تکراری شکل گرفت که چیزی شبیه به این بود. یعنی هر سه گره سر جای خود بودند اما گره دوم عقب ماند.
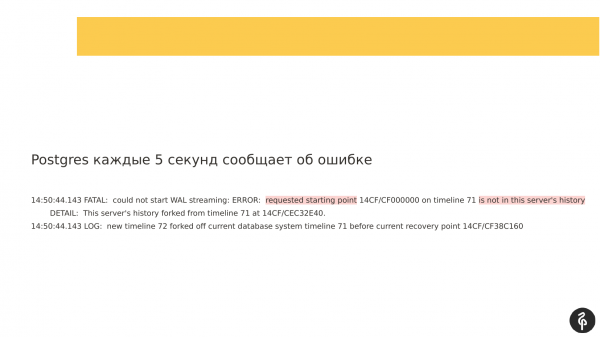
در همان زمان، اگر به گزارشهایی که نوشته شدهاند نگاه کنید، میبینید که Replication نمیتواند شروع شود زیرا گزارشهای تراکنش متفاوت بودند. و آن لاگهای تراکنشهایی که Master ارائه میدهد، که در recovery.conf مشخص شدهاند، به سادگی با گره فعلی ما مطابقت ندارند.

و اینجا من اشتباه کردم. من باید می آمدم و می دیدم که در ریکاوری.conf چه چیزی وجود دارد تا فرضیه خود را مبنی بر اینکه ما به استاد اشتباهی وصل می شدیم آزمایش کنم. اما بعداً من فقط با این کار می کردم و به ذهنم نمی رسید یا دیدم که ماکت عقب مانده است و باید دوباره پر شود ، یعنی به نوعی بی دقت کار کردم. این مفصل من بود

بعد از 30 دقیقه، ادمین قبلاً آمده است، یعنی Patroni را مجدداً روی ماکت راه اندازی کردم. من قبلاً به آن پایان داده بودم ، فکر کردم باید دوباره پر شود. و فکر کردم - پاترونی را مجدداً راه اندازی می کنم، شاید اتفاق خوبی بیفتد. ریکاوری شروع شد و حتی پایه باز شد، آماده پذیرش اتصالات بود.
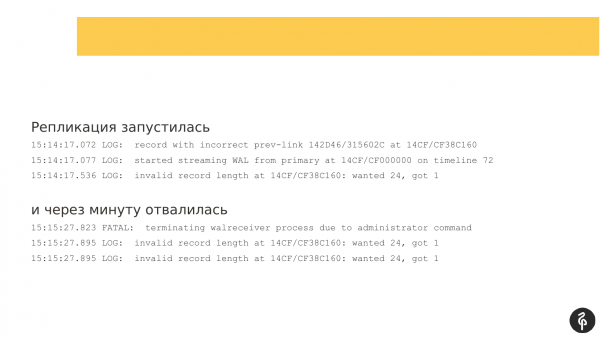
تکثیر شروع شده است. اما یک دقیقه بعد، او با این خطا که سیاهههای مربوط به تراکنش برای او مناسب نیستند، سقوط کرد.

فکر کردم دوباره راه اندازی مجدد کنم. من Patroni را دوباره راه اندازی کردم و Postgres را مجددا راه اندازی نکردم، اما Patroni را مجددا راه اندازی کردم به این امید که به طور جادویی پایگاه داده را راه اندازی کند.

تکرار دوباره شروع شد، اما علائم در گزارش تراکنش متفاوت بود، آنها مانند تلاش قبلی قبلی نبودند. تکرار دوباره متوقف شد. و پیام قبلاً کمی متفاوت بود. و برای من خیلی آموزنده نبود.

و بعد به ذهنم میرسد - اگر Postgres را مجدداً راهاندازی کنم، در این زمان یک چک پوینت روی Master فعلی ایجاد کنم تا نقطه را در گزارش تراکنش کمی به جلو ببرم تا بازیابی از لحظهای دیگر شروع شود؟ به علاوه، ما هنوز سهام WAL را داشتیم.

من Patroni را مجددا راه اندازی کردم، چند چک پوینت روی Master انجام دادم، چند نقطه راه اندازی مجدد روی ماکت وقتی باز شد. و کمک کرد. من مدت زیادی فکر می کردم که چرا کمک کرد و چگونه کار کرد. و ماکت شروع شد. و تکثیر دیگر پاره نشد.

چنین مشکلی برای من یکی از اسرارآمیزترین مشکلاتی است که هنوز در مورد اینکه واقعاً چه اتفاقی در آنجا افتاده است معما هستم.
در اینجا چه پیامدهایی وجود دارد؟ Patroni می تواند همانطور که در نظر گرفته شده و بدون هیچ خطایی کار کند. اما در عین حال، این تضمین 100٪ نیست که همه چیز با ما خوب است. Replica ممکن است شروع شود، اما ممکن است در حالت نیمه کار باشد و برنامه نتواند با چنین ماکتی کار کند، زیرا داده های قدیمی وجود خواهد داشت.
و بعد از فایلر، همیشه باید بررسی کنید که همه چیز با خوشه مرتب است، یعنی تعداد مورد نیاز کپی وجود دارد، هیچ تاخیر تکراری وجود ندارد.
و همانطور که از این مسائل عبور می کنیم، توصیه هایی خواهم کرد. من سعی کردم آنها را در دو اسلاید ترکیب کنم. احتمالاً میتوان تمام داستانها را در دو اسلاید ترکیب کرد و فقط گفت.

وقتی از Patroni استفاده می کنید، باید نظارت داشته باشید. همیشه باید بدانید که فایلافزاری خودکار چه زمانی رخ داده است، زیرا اگر ندانید که فایلافزاری خودکار دارید، کنترلی روی خوشه ندارید. و این بد است.
بعد از هر فایل، همیشه باید خوشه را به صورت دستی بررسی کنیم. ما باید مطمئن شویم که همیشه تعداد نسخه های به روز داریم، هیچ تاخیر تکراری وجود ندارد، هیچ خطایی در لاگ های مربوط به پخش جریانی، با Patroni، با سیستم DCS وجود ندارد.
اتوماسیون می تواند با موفقیت کار کند، Patroni ابزار بسیار خوبی است. می تواند کار کند، اما خوشه را به حالت مطلوب نمی رساند. و اگر از آن مطلع نشویم، دچار مشکل خواهیم شد.
و پاترونی یک گلوله نقره ای نیست. ما هنوز باید بدانیم که Postgres چگونه کار می کند، چگونه تکرار کار می کند و چگونه Patroni با Postgres کار می کند، و چگونه ارتباط بین گره ها فراهم می شود. این برای اینکه بتوانید مشکلات دستان خود را برطرف کنید ضروری است.

چگونه به موضوع تشخیص نزدیک شوم؟ اینطور شد که ما با کلاینت های مختلفی کار می کنیم و هیچکس پشته ELK ندارد و باید با باز کردن 6 کنسول و 2 تب لاگ ها را مرتب کنیم. در یک برگه، اینها لاگ های Patroni برای هر گره هستند، در برگه دیگر، این لاگ های Consul یا در صورت لزوم Postgres هستند. تشخیص این موضوع بسیار دشوار است.
چه رویکردهایی را توسعه داده ام؟ اول، من همیشه نگاه می کنم که فایلر چه زمانی رسیده است. و برای من این یک آبگیر است. من به آنچه قبل از پرونده، در حین پرونده و بعد از پرونده رخ داده است نگاه می کنم. فایل اوور دو علامت دارد: این زمان شروع و پایان است.
بعد، من در گزارشها به دنبال رویدادهای قبل از فایلکننده، که قبل از فایلکننده هستند، میگردم، یعنی به دنبال دلایل وقوع فایلکننده میگردم.
و این تصویری از درک اینکه چه اتفاقی افتاده و چه کارهایی می توان در آینده انجام داد تا چنین شرایطی رخ ندهد (و در نتیجه فایل کننده وجود ندارد) به دست می دهد.
و معمولا به کجا نگاه می کنیم؟ من نگاه می کنم:
- ابتدا به سیاهههای مربوط به Patroni.
- در مرحله بعد، من به گزارشهای Postgres یا گزارشهای DCS، بسته به آنچه در لاگهای Patroni یافت میشود، نگاه میکنم.
- و گزارشهای سیستم نیز گاهی درک درستی از علت ایجاد فایلکننده ارائه میدهند.

من در مورد Patroni چه احساسی دارم؟ من رابطه بسیار خوبی با پاترونی دارم. به نظر من این بهترین چیزی است که امروز وجود دارد. من بسیاری از محصولات دیگر را می شناسم. اینها Stolon، Repmgr، Pg_auto_failover، PAF هستند. 4 ابزار. من همه آنها را امتحان کردم. Patroni مورد علاقه من است.
اگر از من بپرسند: "آیا من پاترونی را توصیه می کنم؟". من می گویم بله، زیرا من پاترونی را دوست دارم. و فکر می کنم طرز پخت آن را یاد گرفتم.
اگر علاقه مندید که ببینید غیر از مشکلاتی که ذکر کردم، با Patroni چه مشکلات دیگری وجود دارد، همیشه می توانید صفحه را بررسی کنید. در GitHub. داستان های مختلفی وجود دارد و موضوعات جالب زیادی در آنجا مورد بحث قرار می گیرد. و در نتیجه برخی از باگ ها معرفی و برطرف شد، یعنی خواندن جالبی است.
داستانهای جالبی در مورد شلیک گلوله به پای خود وجود دارد. بسیار آموزنده شما می خوانید و می فهمید که لازم نیست این کار را انجام دهید. خودم تیک زدم
و من می خواهم از Zalando برای توسعه این پروژه، یعنی الکساندر Kukushkin و Alexey Klyukin تشکر بزرگی کنم. Alexey Klyukin یکی از نویسندگان مشترک است، او دیگر در Zalando کار نمی کند، اما این دو نفر هستند که کار با این محصول را شروع کردند.
و من فکر می کنم که Patroni چیز بسیار جالبی است. من از وجود او خوشحالم، با او جالب است. و یک تشکر بزرگ از همه مشارکتکنندگانی که وصلههایی برای Patroni مینویسند. امیدوارم پاترونی با افزایش سن بالغ تر، خونسردتر و کارآمدتر شود. این در حال حاضر کاربردی است، اما امیدوارم بهتر شود. بنابراین، اگر قصد دارید از Patroni استفاده کنید، نترسید. این راه حل خوبی است، قابل اجرا و استفاده است.
همین. اگر سوالی دارید، بپرسید.

پرسش
با تشکر از گزارش! اگر بعد از یک فایلکننده هنوز باید با دقت به آنجا نگاه کنید، پس چرا به یک فایلکننده خودکار نیاز داریم؟
چون چیز جدیدی است ما فقط یک سال است که با او هستیم. بهتره در امان باشی ما می خواهیم وارد شویم و ببینیم که همه چیز واقعاً همانطور که باید پیش رفت. این سطح بی اعتمادی بزرگسالان است - بهتر است دوباره بررسی کنید و ببینید.
مثلا صبح رفتیم نگاه کردیم درسته؟
نه صبح، معمولاً تقریباً بلافاصله در مورد فایل خودکار یاد میگیریم. ما اعلان ها را دریافت می کنیم، می بینیم که یک فایل خودکار رخ داده است. تقریباً بلافاصله می رویم و نگاه می کنیم. اما همه این بررسی ها باید به سطح نظارت برود. اگر از طریق REST API به Patroni دسترسی داشته باشید، یک تاریخچه وجود دارد. با توجه به تاریخچه، می توانید مُهرهای زمانی را که فایلر اتفاق افتاده است، ببینید. بر این اساس می توان نظارت انجام داد. شما می توانید تاریخچه را ببینید، چه تعداد رویداد وجود دارد. اگر رویدادهای بیشتری داشته باشیم، یک فایل خودکار رخ داده است. می توانید بروید و ببینید. یا اتوماسیون مانیتورینگ ما بررسی کرد که ما همه کپی ها را در جای خود داریم، هیچ تاخیری وجود ندارد و همه چیز خوب است.
با تشکر از شما!
خیلی ممنون برای داستان عالی! اگر خوشه DCS را به جایی دور از خوشه Postgres منتقل کنیم، این خوشه نیز باید به صورت دوره ای سرویس شود؟ بهترین روش هایی که برخی از قطعات خوشه DCS باید خاموش شوند، کاری با آنها انجام شود و غیره چیست؟ چگونه این کل ساختار زنده می ماند؟ و چگونه این کارها را انجام می دهید؟
برای یک شرکت، لازم بود ماتریسی از مشکلات ایجاد شود، اگر یکی از اجزا یا چند جزء از کار بیفتد، چه اتفاقی می افتد. با توجه به این ماتریس، ما به صورت متوالی تمام اجزا را مرور می کنیم و در صورت خرابی این اجزا، سناریوهایی را می سازیم. بر این اساس، برای هر سناریوی شکست، می توانید یک برنامه عملیاتی برای بازیابی داشته باشید. و در مورد DCS، به عنوان بخشی از زیرساخت استاندارد می آید. و ادمین آن را مدیریت می کند، و ما از قبل به ادمین هایی که آن را مدیریت می کنند و توانایی آنها برای رفع آن در صورت بروز حوادث متکی هستیم. اگر اصلاً DCS وجود نداشته باشد، ما آن را مستقر می کنیم، اما در عین حال به طور خاص آن را نظارت نمی کنیم، زیرا ما مسئول زیرساخت نیستیم، اما توصیه هایی در مورد چگونگی و موارد نظارتی ارائه می دهیم.
یعنی درست متوجه شدم که قبل از هر کاری با هاست باید Patroni را غیر فعال کنم، فایلر را غیرفعال کنم، همه چیز را غیرفعال کنم؟
بستگی به تعداد گره های ما در خوشه DCS دارد. اگر تعداد زیادی گره وجود داشته باشد و اگر فقط یکی از گره ها را غیرفعال کنیم (Replica)، خوشه حد نصاب را حفظ می کند. و Patroni همچنان عملیاتی است. و هیچ چیز تحریک نمی شود. اگر عملیات پیچیدهای داشته باشیم که گرههای بیشتری را تحت تأثیر قرار دهد، عدم وجود آنها میتواند حد نصاب را از بین ببرد، - بله، ممکن است منطقی باشد که Patroni را در حالت مکث قرار دهیم. این یک دستور مربوطه دارد - patronictl pause، patronictl resume. ما فقط مکث می کنیم و فایل خودکار در آن زمان کار نمی کند. ما تعمیر و نگهداری را در خوشه DCS انجام می دهیم، سپس مکث را حذف می کنیم و به زندگی ادامه می دهیم.
خیلی ممنونم
از گزارش شما بسیار متشکرم! تیم محصول در مورد از دست رفتن داده ها چه احساسی دارد؟
تیم های محصول اهمیتی نمی دهند و رهبران تیم نگران هستند.
چه تضمینی وجود دارد؟
گارانتی خیلی سخته الکساندر کوکوشکین گزارشی با عنوان "نحوه محاسبه RPO و RTO" دارد، یعنی زمان بازیابی و میزان داده ای که می توانیم از دست بدهیم. به نظر من باید این اسلایدها را پیدا کنیم و مطالعه کنیم. تا جایی که من به یاد دارم، مراحل خاصی برای محاسبه این موارد وجود دارد. چه تعداد تراکنش را می توانیم از دست دهیم، چه مقدار داده را می توانیم از دست دهیم. به عنوان یک گزینه، میتوانیم از تکرار همزمان در سطح Patroni استفاده کنیم، اما این یک شمشیر دو لبه است: یا قابلیت اطمینان دادهها را داریم یا سرعت را از دست میدهیم. تکرار همزمان وجود دارد، اما همچنین تضمینی برای محافظت 100٪ در برابر از دست دادن داده ها ندارد.
الکسی، با تشکر از گزارش عالی! آیا تجربه ای در مورد استفاده از Patroni برای محافظت در سطح صفر دارید؟ یعنی در ارتباط با آماده به کار همزمان؟ این اولین سوال است. و سوال دوم. شما از راه حل های مختلفی استفاده کرده اید. ما از Repmgr استفاده کردیم، اما بدون خودکار، و اکنون در حال برنامه ریزی برای اضافه کردن خودکار فایل هستیم. و ما Patroni را به عنوان یک راه حل جایگزین در نظر می گیریم. در مقایسه با Repmgr چه مزیت هایی می توانید بگویید؟
اولین سوال در مورد کپی های همزمان بود. هیچکس در اینجا از تکرار همزمان استفاده نمیکند، زیرا همه میترسند (چند مشتری قبلاً از آن استفاده میکنند، در اصل، آنها متوجه مشکلات عملکردی نشدهاند - یادداشت سخنران). اما ما برای خودمان قانونی ایجاد کردهایم که باید حداقل سه گره در یک کلاستر تکرار همزمان وجود داشته باشد، زیرا اگر دو گره داشته باشیم و اگر master یا replica از کار بیفتد، Patroni این گره را به حالت مستقل تغییر میدهد تا برنامه به ادامه کار کردن در این صورت خطر از بین رفتن اطلاعات وجود دارد.
در مورد سوال دوم، ما به دلایل تاریخی از Repmgr استفاده کرده ایم و هنوز هم با برخی از مشتریان این کار را انجام می دهیم. چه می توان گفت؟ Patroni با یک فایل خودکار خارج از جعبه عرضه می شود، Repmgr با فایل خودکار به عنوان یک ویژگی اضافی که باید فعال شود ارائه می شود. ما باید دیمون Repmgr را روی هر گره اجرا کنیم و سپس میتوانیم فایل خودکار را پیکربندی کنیم.
Repmgr بررسی می کند که آیا گره های Postgres زنده هستند یا خیر. فرآیندهای Repmgr وجود یکدیگر را بررسی میکنند، این رویکرد چندان کارآمدی نیست. ممکن است موارد پیچیده ای از جداسازی شبکه وجود داشته باشد که در آن یک خوشه بزرگ Repmgr می تواند به چندین گروه کوچکتر تقسیم شود و به کار خود ادامه دهد. من مدت زیادی است که Repmgr را دنبال نمی کنم، شاید درست شده است ... یا شاید هم نه. اما حذف اطلاعات مربوط به وضعیت خوشه در DCS، همانطور که Stolon، Patroni انجام می دهد، قابل اجراترین گزینه است.
الکسی، من یک سوال دارم، شاید یک سوال کوتاه تر. در یکی از اولین نمونه ها، DCS را از ماشین محلی به یک میزبان راه دور منتقل کردید. ما درک می کنیم که شبکه چیزی است که ویژگی های خاص خود را دارد، به تنهایی زندگی می کند. و اگر به دلایلی خوشه DCS در دسترس نباشد چه اتفاقی می افتد؟ دلایل را نمی گویم، آنها می توانند زیاد باشند: از دستان کج نتورکرها تا مشکلات واقعی.
من آن را با صدای بلند نگفتم، اما خوشه DCS نیز باید failover باشد، یعنی تعداد گرههای فرد باشد تا حد نصاب حاصل شود. اگر خوشه DCS در دسترس نباشد، یا حد نصابی حاصل نشود، یعنی نوعی تقسیم شبکه یا شکست گره، چه اتفاقی میافتد؟ در این حالت، خوشه Patroni به حالت فقط خواندنی می رود. خوشه Patroni نمی تواند وضعیت خوشه و آنچه را که باید انجام دهد را تعیین کند. نمی تواند با DCS تماس بگیرد و حالت جدید خوشه را در آنجا ذخیره کند، بنابراین کل خوشه فقط به خواندن می رود. و منتظر مداخله دستی اپراتور یا بازیابی DCS می ماند.
به طور کلی، DCS به سرویسی برای ما تبدیل می شود که به اندازه خود پایگاه مهم است؟
بله بله. در بسیاری از شرکت های مدرن، Service Discovery بخشی جدایی ناپذیر از زیرساخت است. حتی قبل از اینکه حتی یک پایگاه داده در زیرساخت وجود داشته باشد، در حال اجرا است. به طور نسبی، زیرساخت راه اندازی شد، در DC مستقر شد، و ما بلافاصله سرویس Discovery را داریم. اگر کنسول باشد، می توان DNS را روی آن ساخت. اگر این Etcd باشد، ممکن است بخشی از خوشه Kubernetes وجود داشته باشد که هر چیز دیگری در آن مستقر شود. به نظر من کشف سرویس در حال حاضر بخشی جدایی ناپذیر از زیرساخت های مدرن است. و خیلی زودتر از پایگاه های داده به آن فکر می کنند.
با تشکر از شما!
منبع: www.habr.com
