

در این مقاله، می خواهم در مورد ویژگی های تمام آرایه های Flash AccelStor که با یکی از محبوب ترین پلتفرم های مجازی سازی - VMware vSphere کار می کنند، صحبت کنم. به طور خاص، روی آن پارامترهایی تمرکز کنید که به شما کمک می کند حداکثر اثر را از استفاده از ابزار قدرتمندی مانند All Flash بگیرید.

AccelStor NeoSapphire™ همه آرایه های فلش هستند یا دستگاه های گره مبتنی بر درایوهای SSD با رویکردی اساسا متفاوت برای پیاده سازی مفهوم ذخیره سازی داده ها و سازماندهی دسترسی به آن با استفاده از فناوری اختصاصی به جای الگوریتم های RAID بسیار محبوب. آرایه ها دسترسی بلوکی به میزبان ها را از طریق کانال فیبر یا رابط های iSCSI فراهم می کنند. اگر منصف باشیم، توجه داریم که مدلهای دارای رابط ISCSI نیز به عنوان یک امتیاز خوب، دسترسی به فایل دارند. اما در این مقاله ما بر روی استفاده از پروتکل های بلوک به عنوان پربازده ترین پروتکل ها برای All Flash تمرکز خواهیم کرد.
کل فرآیند استقرار و پیکربندی بعدی عملیات مشترک آرایه AccelStor و سیستم مجازی سازی VMware vSphere را می توان به چند مرحله تقسیم کرد:
- پیاده سازی توپولوژی اتصال و پیکربندی شبکه SAN.
- راه اندازی همه آرایه فلش.
- پیکربندی میزبان ESXi.
- راه اندازی ماشین های مجازی
آرایه های کانال فیبر AccelStor NeoSapphire™ و آرایه های iSCSI به عنوان سخت افزار نمونه استفاده شد. نرم افزار پایه VMware vSphere 6.7U1 است.
قبل از استقرار سیستم های شرح داده شده در این مقاله، به شدت توصیه می شود که اسناد VMware را در رابطه با مشکلات عملکرد مطالعه کنید ( ) و تنظیمات iSCSI ()
توپولوژی اتصال و پیکربندی شبکه SAN
اجزای اصلی یک شبکه SAN عبارتند از HBA ها در میزبان های ESXi، سوئیچ های SAN و گره های آرایه. یک توپولوژی معمولی برای چنین شبکه ای به شکل زیر است:
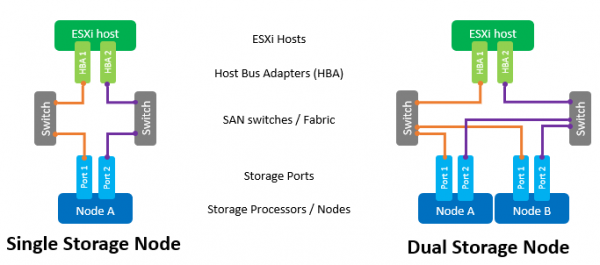
اصطلاح سوئیچ در اینجا به یک سوئیچ فیزیکی جداگانه یا مجموعه ای از سوئیچ ها (Fabric) و هم به یک دستگاه مشترک بین سرویس های مختلف اشاره دارد (VSAN در مورد کانال فیبر و VLAN در مورد iSCSI). استفاده از دو سوئیچ / فابریک مستقل، نقطه خرابی احتمالی را از بین می برد.
اتصال مستقیم هاست به آرایه، اگرچه پشتیبانی می شود، به شدت توصیه نمی شود. عملکرد همه آرایه های فلش بسیار بالاست. و برای حداکثر سرعت باید از تمام پورت های آرایه استفاده کرد. بنابراین، وجود حداقل یک سوئیچ بین هاست و NeoSapphire™ الزامی است.
وجود دو پورت در HBA میزبان نیز یک الزام اجباری برای دستیابی به حداکثر عملکرد و اطمینان از تحمل خطا است.
هنگام استفاده از رابط کانال فیبر، منطقه بندی باید برای از بین بردن برخوردهای احتمالی بین آغازگرها و اهداف پیکربندی شود. مناطق بر اساس اصل "یک پورت آغازگر - یک یا چند پورت آرایه" ساخته شده اند.
اگر از اتصال از طریق iSCSI در مورد استفاده از سوئیچ مشترک با سایر سرویس ها استفاده می کنید، جداسازی ترافیک iSCSI در یک VLAN جداگانه ضروری است. همچنین به شدت توصیه می شود که پشتیبانی از Jumbo Frames (MTU = 9000) را برای افزایش اندازه بسته ها در شبکه و در نتیجه کاهش مقدار اطلاعات سربار در طول انتقال فعال کنید. با این حال، شایان ذکر است که برای عملکرد صحیح، لازم است پارامتر MTU را در تمام اجزای شبکه در امتداد زنجیره "آغاز کننده-سوئیچ-هدف" تغییر دهید.
راه اندازی همه آرایه فلش
آرایه به مشتریان با گروه های از قبل تشکیل شده تحویل داده می شود . بنابراین، هیچ اقدامی برای ترکیب درایوها در یک ساختار واحد لازم نیست. شما فقط باید حجم هایی با اندازه و مقدار مورد نیاز ایجاد کنید.
برای راحتی، قابلیت ایجاد دسته ای از چندین حجم در یک اندازه معین در یک زمان وجود دارد. بهطور پیشفرض، حجمهای نازکی ایجاد میشوند، زیرا این امکان استفاده کارآمدتر از فضای ذخیرهسازی موجود (از جمله پشتیبانی از Space Reclamation) را فراهم میکند. از نظر عملکرد، تفاوت بین حجم های "نازک" و "ضخیم" از 1٪ تجاوز نمی کند. با این حال، اگر میخواهید «تمام آب» را از یک آرایه بگیرید، همیشه میتوانید هر حجم «نازک» را به حجمی «ضخیم» تبدیل کنید. اما باید به خاطر داشت که چنین عملیاتی برگشت ناپذیر است.
در مرحله بعد، باید حجم های ایجاد شده را "انتشار" کرد و حقوق دسترسی به آنها را از میزبان ها با استفاده از ACL (آدرس های IP برای iSCSI و WWPN برای FC) و جداسازی فیزیکی توسط پورت های آرایه تنظیم کرد. برای مدل های iSCSI این کار با ایجاد یک Target انجام می شود.
برای مدلهای FC، انتشار از طریق ایجاد یک LUN برای هر پورت آرایه انجام میشود.
برای سرعت بخشیدن به فرآیند راه اندازی، هاست ها را می توان در گروه ها ترکیب کرد. علاوه بر این، اگر میزبان از یک FC HBA چند پورت استفاده کند (که در عمل اغلب اتفاق میافتد)، سیستم بهطور خودکار تعیین میکند که پورتهای چنین HBA به یک میزبان منفرد متعلق به WWPNهایی است که یک تفاوت دارند. ایجاد دسته ای از Target/LUN نیز برای هر دو رابط پشتیبانی می شود.
نکته مهم هنگام استفاده از رابط iSCSI، ایجاد چندین هدف برای حجم ها به طور همزمان برای افزایش عملکرد است، زیرا صف روی هدف قابل تغییر نیست و عملاً یک گلوگاه خواهد بود.
پیکربندی هاست های ESXi
در سمت میزبان ESXi، پیکربندی اولیه طبق یک سناریوی کاملاً مورد انتظار انجام می شود. مراحل اتصال iSCSI:
- افزودن آداپتور iSCSI نرم افزار (اگر قبلاً اضافه شده باشد، یا اگر از آداپتور سخت افزاری iSCSI استفاده می کنید، لازم نیست).
- ایجاد یک vSwitch که از طریق آن ترافیک iSCSI عبور می کند و یک uplink فیزیکی و VMkernal به آن اضافه می شود.
- اضافه کردن آدرس های آرایه به Dynamic Discovery.
- ایجاد دیتا استور
چند نکته مهم:
- در حالت کلی، البته، می توانید از vSwitch موجود استفاده کنید، اما در مورد vSwitch جداگانه، مدیریت تنظیمات میزبان بسیار آسان تر خواهد بود.
- برای جلوگیری از مشکلات عملکرد، لازم است ترافیک مدیریت و iSCSI را روی پیوندهای فیزیکی و/یا VLAN جداگانه جدا کنید.
- آدرسهای IP VMkernal و پورتهای مربوط به آرایه All Flash باید در همان زیرشبکه باشند، دوباره به دلیل مشکلات عملکرد.
- برای اطمینان از تحمل خطا طبق قوانین VMware، vSwitch باید حداقل دو آپلینک فیزیکی داشته باشد
- اگر از Jumbo Frames استفاده می شود، باید MTU هر دو vSwitch و VMkernal را تغییر دهید
- یادآوری این نکته مفید است که با توجه به توصیههای VMware برای آداپتورهای فیزیکی که برای کار با ترافیک iSCSI استفاده میشوند، باید Teaming و Failover را پیکربندی کنید. به طور خاص، هر VMkernal باید فقط از طریق یک Uplink کار کند، دومین uplink باید به حالت استفاده نشده تغییر کند. برای تحمل خطا، باید دو VMkernal اضافه کنید که هر کدام از طریق uplink خود کار می کنند.
آداپتور VMkernel (vmk#)
آداپتور شبکه فیزیکی (vmnic#)
vmk1 (Storage01)
آداپتورهای فعال
vmnic2
آداپتورهای استفاده نشده
vmnic3
vmk2 (Storage02)
آداپتورهای فعال
vmnic3
آداپتورهای استفاده نشده
vmnic2
برای اتصال از طریق کانال فیبر نیازی به مراحل اولیه نیست. شما می توانید بلافاصله یک Datastore ایجاد کنید.
پس از ایجاد Datastore، باید مطمئن شوید که خط مشی Round Robin برای مسیرهای Target/LUN به عنوان بیشترین کارایی استفاده می شود.
به طور پیش فرض، تنظیمات VMware برای استفاده از این سیاست طبق این طرح ارائه می شود: 1000 درخواست از طریق مسیر اول، 1000 درخواست بعدی از طریق مسیر دوم و غیره. چنین تعاملی بین میزبان و آرایه دو کنترل کننده نامتعادل خواهد بود. بنابراین، توصیه می کنیم پارامتر Round Robin = 1 را از طریق Esxcli/PowerCLI تنظیم کنید.
پارامترهای
برای Esxcli:
- LUN های موجود را فهرست کنید
لیست دستگاه ذخیره سازی nmp esxcli
- کپی نام دستگاه
- تغییر خط مشی Round Robin
ذخیره سازی esxcli nmp psp roundrobin deviceconfig set —type=iops —iops=1 —device=«Device_ID»
اکثر برنامه های مدرن برای تبادل بسته های داده بزرگ به منظور به حداکثر رساندن استفاده از پهنای باند و کاهش بار CPU طراحی شده اند. بنابراین، ESXi بهطور پیشفرض درخواستهای ورودی/خروجی را به دستگاه ذخیرهسازی در قطعات تا 32767 کیلوبایت ارسال میکند. با این حال، برای برخی از سناریوها، مبادله قطعات کوچکتر مفیدتر خواهد بود. برای آرایه های AccelStor، این سناریوهای زیر است:
- ماشین مجازی از UEFI به جای Legacy BIOS استفاده می کند
- از vSphere Replication استفاده می کند
برای چنین سناریوهایی، توصیه می شود مقدار پارامتر Disk.DiskMaxIOSize را به 4096 تغییر دهید.
برای اتصالات iSCSI، توصیه می شود پارامتر Login Timeout را به 30 (پیش فرض 5) تغییر دهید تا پایداری اتصال را افزایش دهید و تاخیر DelayedAck را برای تأیید بسته های ارسال شده غیرفعال کنید. هر دو گزینه در vSphere Client هستند: Host → Configure → Storage → Storage Adapters → Advanced Options for iSCSI Adapter
یک نکته نسبتاً ظریف تعداد جلدهای مورد استفاده برای ذخیره داده است. واضح است که برای سهولت مدیریت، تمایل به ایجاد یک حجم بزرگ برای کل حجم آرایه وجود دارد. با این حال، وجود چندین حجم و، بر این اساس، ذخیره داده تأثیر مفیدی بر عملکرد کلی دارد (اطلاعات بیشتر در مورد صف ها در زیر). بنابراین، توصیه می کنیم حداقل دو جلد ایجاد کنید.
تا همین اواخر، VMware توصیه می کرد که تعداد ماشین های مجازی را در یک دیتا استور محدود کند تا بالاترین عملکرد ممکن را به دست آورد. با این حال، در حال حاضر، به خصوص با گسترش VDI، این مشکل دیگر آنقدر حاد نیست. اما این قانون طولانی مدت را لغو نمی کند - توزیع ماشین های مجازی که نیاز به IO فشرده در بین داده های مختلف دارند. برای تعیین تعداد بهینه ماشین های مجازی در هر حجم، هیچ چیز بهتر از این نیست در زیرساخت های آن
راه اندازی ماشین های مجازی
هنگام راه اندازی ماشین های مجازی هیچ الزامات خاصی وجود ندارد، یا بهتر است بگوییم که آنها کاملا معمولی هستند:
- استفاده از بالاترین نسخه ممکن VM (سازگاری)
- هنگام قرار دادن متراکم ماشین های مجازی، مثلاً در VDI، تنظیم اندازه RAM بیشتر دقت شود (زیرا به طور پیش فرض در هنگام راه اندازی، یک فایل صفحه با اندازه متناسب با RAM ایجاد می شود که ظرفیت مفیدی را مصرف می کند و بر روی آن تأثیر می گذارد. اجرای نهایی)
- از پربازده ترین نسخه های آداپتور از نظر IO استفاده کنید: نوع شبکه VMXNET 3 و نوع SCSI PVSCSI
- از نوع دیسک Thick Provision Eager Zeroed برای حداکثر کارایی و Thin Provisioning برای حداکثر استفاده از فضای ذخیره سازی استفاده کنید.
- در صورت امکان، عملکرد ماشینهای حیاتی غیر I/O را با استفاده از Virtual Disk Limit محدود کنید
- حتما VMware Tools را نصب کنید
یادداشت هایی در مورد صف ها
صف (یا I/Oهای برجسته) تعداد درخواستهای ورودی/خروجی (فرمانهای SCSI) است که در هر زمان معینی برای یک دستگاه/برنامه خاص منتظر پردازش هستند. در صورت سرریز صف، خطاهای QFULL صادر می شود که در نهایت منجر به افزایش پارامتر تاخیر می شود. هنگام استفاده از سیستمهای ذخیرهسازی دیسکی (اسپیندل)، از نظر تئوری، هر چه صف بالاتر باشد، کارایی آنها نیز بالاتر خواهد بود. با این حال، شما نباید از آن سوء استفاده کنید، زیرا به راحتی با QFULL اجرا می شود. در مورد همه سیستم های فلش، از یک طرف، همه چیز تا حدودی ساده تر است: از این گذشته، آرایه دارای تأخیرهایی است که مرتبه های بزرگی کمتری دارند و بنابراین، در اغلب موارد، نیازی به تنظیم جداگانه اندازه صف ها نیست. اما از سوی دیگر، در برخی سناریوهای استفاده (انحراف شدید در نیازمندی های IO برای ماشین های مجازی خاص، تست های حداکثر کارایی و غیره) لازم است، اگر پارامترهای صف ها را تغییر ندهیم، حداقل درک کنیم که چه شاخص هایی می توان به دست آورد، و نکته اصلی این است که از چه راه هایی.
در خود آرایه AccelStor All Flash هیچ محدودیتی در رابطه با حجم ها یا پورت های I/O وجود ندارد. در صورت لزوم، حتی یک جلد می تواند تمام منابع آرایه را دریافت کند. تنها محدودیت در صف برای اهداف iSCSI است. به همین دلیل است که نیاز به ایجاد چندین هدف (در حالت ایده آل تا 8 قطعه) برای هر حجم برای غلبه بر این محدودیت در بالا ذکر شد. اجازه دهید همچنین تکرار کنیم که آرایه های AccelStor راه حل های بسیار سازنده ای هستند. بنابراین برای دستیابی به حداکثر سرعت باید از تمامی پورت های رابط سیستم استفاده کنید.
در سمت میزبان ESXi، وضعیت کاملا متفاوت است. میزبان خود عمل دسترسی برابر به منابع را برای همه شرکت کنندگان اعمال می کند. بنابراین، صف های IO جداگانه برای سیستم عامل مهمان و HBA وجود دارد. صف های سیستم عامل مهمان از صف ها به آداپتور SCSI مجازی و دیسک مجازی ترکیب می شوند:
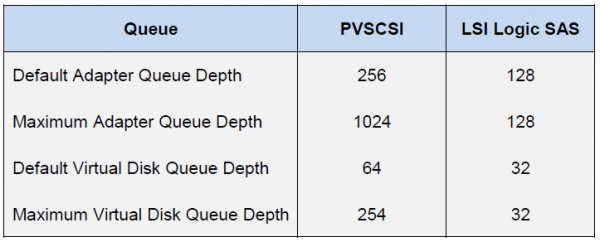
صف HBA به نوع/فروشنده خاص بستگی دارد:
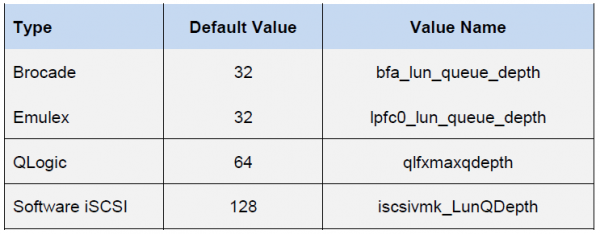
عملکرد نهایی ماشین مجازی با کمترین حد عمق صف در بین اجزای میزبان تعیین می شود.
به لطف این مقادیر، می توانیم شاخص های عملکردی را که می توانیم در یک پیکربندی خاص بدست آوریم، ارزیابی کنیم. به عنوان مثال، ما می خواهیم عملکرد تئوری یک ماشین مجازی (بدون اتصال بلوکی) با تاخیر 0.5 میلی ثانیه را بدانیم. سپس IOPS آن = (1,000/تأخیر) * I/Oهای برجسته (محدودیت عمق صف)
نمونه
به عنوان مثال 1
- آداپتور FC Emulex HBA
- یک VM در هر ذخیرهگاه داده
- آداپتور VMware Paravirtual SCSI
در اینجا محدودیت عمق صف توسط Emulex HBA تعیین می شود. بنابراین IOPS = (1000/0.5)*32 = 64K
به عنوان مثال 2
- آداپتور نرم افزار VMware iSCSI
- یک VM در هر ذخیرهگاه داده
- آداپتور VMware Paravirtual SCSI
در اینجا محدودیت عمق صف قبلاً توسط آداپتور Paravirtual SCSI تعیین شده است. بنابراین IOPS = (1000/0.5)*64 = 128K
مدل های برتر همه آرایه های Flash AccelStor (به عنوان مثال، ) قادر به ارائه عملکرد نوشتن 700K IOPS در بلوک 4K هستند. با چنین اندازه بلوکی، کاملاً واضح است که یک ماشین مجازی منفرد قادر به بارگذاری چنین آرایه ای نیست. برای این کار به 11 (مثلاً 1) یا 6 (مثلاً 2) ماشین مجازی نیاز دارید.
در نتیجه، با پیکربندی صحیح تمام اجزای توصیف شده یک مرکز داده مجازی، می توانید نتایج بسیار چشمگیری از نظر عملکرد دریافت کنید.
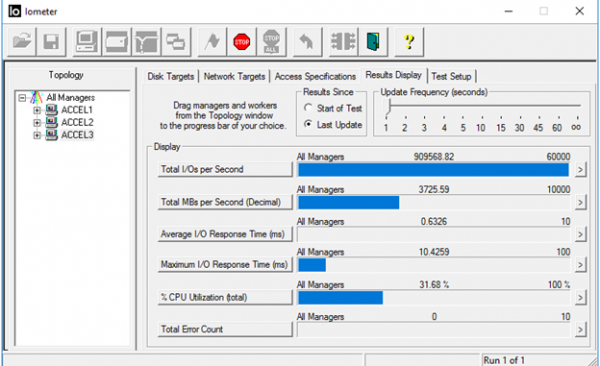
4K تصادفی، 70% خواندن/30% نوشتن
در واقع، دنیای واقعی بسیار پیچیده تر از آن است که بتوان آن را با یک فرمول ساده توصیف کرد. یک هاست همیشه چندین ماشین مجازی با تنظیمات مختلف و نیازمندی های IO را میزبانی می کند. و پردازش I/O توسط پردازنده میزبان انجام می شود که قدرت آن بی نهایت نیست. بنابراین، برای باز کردن پتانسیل کامل همان در واقع شما به سه هاست نیاز دارید. بعلاوه، برنامه هایی که در داخل ماشین های مجازی اجرا می شوند، تنظیمات خود را انجام می دهند. بنابراین، برای اندازه دقیق ما پیشنهاد می کنیم همه آرایه های فلش در زیرساخت مشتری در مورد وظایف فعلی واقعی.
منبع: www.habr.com
