

 سیستم مدیریت پایگاه داده InterSystems IRIS از ساختارهای ذخیرهسازی داده جالبی به نام globals پشتیبانی میکند. این ساختارها اساساً کلیدهای چند سطحی با ویژگیهای اضافی مختلف مانند تراکنشها، توابع سریع برای پیمایش درختهای داده، قفلها و یک زبان اختصاصی ObjectScript هستند.
سیستم مدیریت پایگاه داده InterSystems IRIS از ساختارهای ذخیرهسازی داده جالبی به نام globals پشتیبانی میکند. این ساختارها اساساً کلیدهای چند سطحی با ویژگیهای اضافی مختلف مانند تراکنشها، توابع سریع برای پیمایش درختهای داده، قفلها و یک زبان اختصاصی ObjectScript هستند.
برای اطلاعات بیشتر در مورد گلوبالها، سری مقالات «گلوبالها - شمشیرهای ذخیرهسازی دادهها» را مطالعه کنید:
من به نحوه پیادهسازی تراکنشها در دادههای سراسری و ویژگیهای خاص آنها علاقهمند شدم. به هر حال، این یک ساختار ذخیرهسازی داده کاملاً متفاوت از جداول آشنا است. بسیار سطح پایینتر است.
همانطور که از نظریه پایگاههای داده رابطهای مشخص است، یک پیادهسازی خوب از تراکنشها باید الزامات زیر را برآورده کند: :
الف - اتمی (اتمی بودن). تمام تغییرات ایجاد شده در تراکنش ثبت میشوند، یا اصلاً هیچ تغییری ثبت نمیشود.
ج - ثبات. پس از اتمام یک تراکنش، وضعیت منطقی پایگاه داده باید از نظر داخلی سازگار باشد. این الزام تا حد زیادی مربوط به برنامهنویس است، اما در مورد پایگاههای داده SQL، این امر در مورد کلیدهای خارجی نیز صدق میکند.
من - ایزوله کردن (انزوا). تراکنشهای همزمان نباید روی یکدیگر تأثیر بگذارند.
د - بادوام. پس از اتمام موفقیتآمیز یک تراکنش، مشکلات سطوح پایینتر (مثلاً قطعی برق) نباید روی دادههای تغییر یافته توسط تراکنش تأثیر بگذارند.
دادههای سراسری، ساختارهای داده غیررابطهای هستند. آنها طوری طراحی شدهاند که روی سختافزارهای بسیار محدود، بسیار سریع اجرا شوند. بیایید نگاهی به پیادهسازی تراکنشها در دادههای سراسری با استفاده از ... بیندازیم. .
برای پشتیبانی از تراکنشها در IRIS، از دستورات زیر استفاده میشود: , , .
۱. اتمی بودن
سادهترین راه برای بررسی اتمی بودن، استفاده از کنسول پایگاه داده است.
Kill ^a
TSTART
Set ^a(1) = 1
Set ^a(2) = 2
Set ^a(3) = 3
TCOMMITسپس نتیجه گیری می کنیم:
Write ^a(1), “ ”, ^a(2), “ ”, ^a(3)ما دریافت میکنیم:
1 2 3همه چیز خوب است. اتمی بودن حفظ شده است: همه تغییرات نوشته شدهاند.
بیایید کار را پیچیدهتر کنیم، یک خطا ایجاد کنیم و ببینیم که تراکنش چگونه ذخیره میشود، جزئی یا اصلاً ذخیره نمیشود.
بیایید دوباره اتمی بودن را بررسی کنیم:
Kill ^A
TSTART
Set ^a(1) = 1
Set ^a(2) = 2
Set ^a(3) = 3پس از آن، ما به زور کانتینر را متوقف میکنیم، آن را روشن میکنیم و میبینیم.
docker kill my-irisاین دستور تقریباً معادل خاموش کردن اجباری است، زیرا یک سیگنال SIGKILL برای توقف فوری فرآیند ارسال میکند.
شاید تراکنش تا حدی ذخیره شده باشد؟
WRITE ^a(1), ^a(2), ^a(3)
^
<UNDEFINED> ^a(1)- نه، باقی نمانده است.
بیایید دستور rollback را امتحان کنیم:
Kill ^A
TSTART
Set ^a(1) = 1
Set ^a(2) = 2
Set ^a(3) = 3
TROLLBACK
WRITE ^a(1), ^a(2), ^a(3)
^
<UNDEFINED> ^a(1)هیچ چیز هم زنده نمانده است.
2. سازگاری
از آنجایی که در پایگاههای داده مبتنی بر سراسری، کلیدها نیز روی جداول سراسری ساخته میشوند (به یاد داشته باشید که یک جدول سراسری یک ساختار ذخیرهسازی داده سطح پایینتر از یک جدول رابطهای است)، برای برآورده کردن الزام سازگاری، تغییر کلید باید در همان تراکنشی که تغییر سراسری در آن قرار دارد، لحاظ شود.
برای مثال، ما یک ^person سراسری داریم که در آن اطلاعات شخصی را ذخیره میکنیم و از TIN به عنوان کلید استفاده میکنیم.
^person(1234567, ‘firstname’) = ‘Sergey’
^person(1234567, ‘lastname’) = ‘Kamenev’
^person(1234567, ‘phone’) = ‘+74995555555
...برای اینکه جستجوی سریعی بر اساس نام خانوادگی و نام داشته باشیم، کلید ^index را ایجاد کردیم.
^index(‘Kamenev’, ‘Sergey’, 1234567) = 1برای اینکه پایگاه داده سازگار باشد، باید پرسنل را به صورت زیر اضافه کنیم:
TSTART
^person(1234567, ‘firstname’) = ‘Sergey’
^person(1234567, ‘lastname’) = ‘Kamenev’
^person(1234567, ‘phone’) = ‘+74995555555
^index(‘Kamenev’, ‘Sergey’, 1234567) = 1
TCOMMITبر این اساس، هنگام حذف، باید از یک تراکنش نیز استفاده کنیم:
TSTART
Kill ^person(1234567)
ZKill ^index(‘Kamenev’, ‘Sergey’, 1234567)
TCOMMITبه عبارت دیگر، مسئولیت تضمین سازگاری کاملاً بر عهده برنامهنویس است. اما وقتی صحبت از متغیرهای سراسری میشود، به دلیل ماهیت سطح پایین آنها، این امر طبیعی است.
۳. انزوا
اینجاست که پیچیدگی شروع میشود. بسیاری از کاربران به طور همزمان روی یک پایگاه داده کار میکنند و دادههای یکسانی را تغییر میدهند.
این وضعیت را میتوان با زمانی مقایسه کرد که بسیاری از کاربران همزمان با یک مخزن کد کار میکنند و سعی دارند تغییرات را در چندین فایل به طور همزمان اعمال کنند.
پایگاه داده باید همه این موارد را به صورت بلادرنگ (Real Time) مدیریت کند. با توجه به اینکه شرکتهای جدی حتی یک فرد اختصاصی برای کنترل نسخه (ادغام شاخهها، حل تداخلها و غیره) دارند، و پایگاه داده باید همه این موارد را به صورت بلادرنگ مدیریت کند، پیچیدگی کار و اهمیت طراحی صحیح پایگاه داده و کدی که از آن پشتیبانی میکند، آشکار میشود.
پایگاه داده نمیتواند معنای اقدامات انجام شده توسط کاربران برای جلوگیری از تداخل را در صورتی که روی دادههای یکسانی کار میکنند، درک کند. تنها میتواند یک تراکنش را که با تراکنش دیگر تداخل دارد، به حالت قبل برگرداند یا آنها را به ترتیب اجرا کند.
مشکل دیگر این است که در حین اجرای یک تراکنش (قبل از ثبت نهایی)، وضعیت پایگاه داده ممکن است متناقض باشد، بنابراین مطلوب است که سایر تراکنشها به وضعیت متناقض پایگاه داده دسترسی نداشته باشند، که این امر در پایگاههای داده رابطهای از طرق مختلفی حاصل میشود: ایجاد اسنپشات، چند نسخهای کردن ردیفها و غیره.
هنگام اجرای تراکنشها به صورت موازی، مهم است که آنها با یکدیگر تداخل نداشته باشند. این خاصیت ایزوله بودن است.
SQL چهار سطح ایزولهسازی تعریف میکند:
- بدون تعهد بخوانید
- متعهد به خواندن
- خواندن تکرارپذیر
- قابل سریالسازی
بیایید هر سطح را جداگانه بررسی کنیم. هزینههای اجرای هر سطح تقریباً به صورت تصاعدی افزایش مییابد.
بدون تعهد بخوانید — این پایینترین سطح ایزولاسیون است، اما سریعترین نیز میباشد. تراکنشها میتوانند تغییرات یکدیگر را بخوانند.
متعهد به خواندن — این سطح بعدی از ایزولهسازی است که یک مصالحه محسوب میشود. تراکنشها نمیتوانند تغییرات یکدیگر را قبل از کامیت بخوانند، اما میتوانند هر تغییری را که بعد از کامیت ایجاد میشود، بخوانند.
اگر یک تراکنش طولانیمدت T1 داشته باشیم که در طی آن، کامیتهایی در تراکنشهای T2، T3 و Tn که با دادههای مشابه T1 کار میکردند، انجام شده باشد، وقتی دادهها را در T1 جستجو میکنیم، هر بار نتیجه متفاوتی خواهیم گرفت. این پدیده، خواندنهای تکرارناپذیر نامیده میشود.
خواندن تکرارپذیر — در این سطح ایزولاسیون، پدیده خواندنهای تکرارنشدنی را نداریم، زیرا برای هر درخواست خواندن، یک اسنپشات از دادههای حاصل ایجاد میشود و هنگام استفاده مجدد در همان تراکنش، از دادههای اسنپشات استفاده میشود. با این حال، در این سطح ایزولاسیون، خواندن دادههای فانتوم امکانپذیر است. این به خواندن ردیفهای جدیدی اشاره دارد که توسط تراکنشهای همزمان ثبتشده اضافه شدهاند.
قابل سریالسازی — بالاترین سطح جداسازی. این سطح با این واقعیت مشخص میشود که دادههای مورد استفاده در یک تراکنش (خوانده شده یا اصلاح شده) تنها پس از تکمیل اولین تراکنش، برای سایر تراکنشها در دسترس قرار میگیرند.
ابتدا، بیایید بررسی کنیم که آیا عملیات در یک تراکنش از نخ اصلی جدا شدهاند یا خیر. بیایید دو پنجره ترمینال باز کنیم.
Kill ^t
Write ^t(1)
2
TSTART
Set ^t(1)=2هیچ انزوایی وجود ندارد. یک نخ میبیند که نخ دیگری که تراکنش را باز کرده است، چه کاری انجام میدهد.
بیایید ببینیم آیا تراکنشها در نخهای مختلف میتوانند ببینند که درونشان چه اتفاقی میافتد یا خیر.
بیایید دو پنجره ترمینال باز کنیم و دو تراکنش را به صورت موازی انجام دهیم.
kill ^t
TSTART
Write ^t(1)
3
TSTART
Set ^t(1)=3
تراکنشهای همزمان میتوانند دادههای یکدیگر را ببینند. بنابراین، ما سادهترین، اما در عین حال سریعترین، سطح ایزولهسازی را داریم: READ UNCOMMITTED.
در اصل، این موضوع را میتوان برای مسابقات جهانی انتظار داشت، که عملکرد همیشه در اولویت اصلی آنها بوده است.
اگر در عملیات جهانی به سطح بالاتری از ایزولاسیون نیاز داشته باشیم، چه میشود؟
در اینجا باید به این فکر کنیم که اصلاً چرا سطوح ایزوله مورد نیاز هستند و چگونه کار میکنند.
بالاترین سطح ایزولاسیون، SERIALIZE، به این معنی است که نتیجه تراکنشهای اجرا شده به صورت موازی معادل اجرای متوالی آنها است که عدم وجود تصادم را تضمین میکند.
ما میتوانیم این کار را با کمک قفلهای کارآمد در ObjectScript انجام دهیم، که روشهای کاربردی بسیار متنوعی دارند: میتوانید قفلگذاری منظم، افزایشی و چندگانه را با دستور زیر انجام دهید .
سطوح ایزولاسیون پایینتر، بدهبستانهایی هستند که برای بهبود عملکرد پایگاه داده طراحی شدهاند.
بیایید ببینیم چگونه میتوانیم با استفاده از قفلها به سطوح مختلف ایزولهسازی دست یابیم.
این عملگر به شما امکان میدهد نه تنها قفلهای انحصاری مورد نیاز برای تغییر دادهها را بگیرید، بلکه قفلهای به اصطلاح اشتراکی را نیز در نظر بگیرید که میتوانند به صورت موازی توسط چندین نخ به طور همزمان در زمانی که نیاز به خواندن دادههایی دارند که نباید توسط فرآیندهای دیگر در طول فرآیند خواندن تغییر کنند، گرفته شوند.
درباره روش مسدود کردن دو مرحلهای به زبانهای روسی و انگلیسی بیشتر بدانید:
→
→
مشکل این است که در طول یک تراکنش، وضعیت پایگاه داده ممکن است متناقض باشد، اما این دادههای متناقض برای سایر فرآیندها قابل مشاهده است. چگونه میتوان از این امر اجتناب کرد؟
با استفاده از قفلها، پنجرههای دید ایجاد خواهیم کرد که در آنها وضعیت پایگاه داده سازگار خواهد بود. تمام دسترسیها به این پنجرههای دید وضعیت سازگار توسط قفلها کنترل میشوند.
قفلهای مشترک روی دادههای یکسان، قابل استفاده مجدد هستند - میتوانند توسط چندین فرآیند به دست آیند. این قفلها از تغییر دادهها توسط سایر فرآیندها جلوگیری میکنند، به این معنی که از آنها برای ایجاد پنجرههایی با وضعیت ثابت پایگاه داده استفاده میشود.
قفلهای انحصاری برای تغییر دادهها استفاده میشوند - فقط یک فرآیند میتواند چنین قفلی را به دست آورد. یک قفل انحصاری را میتوان به روشهای زیر به دست آورد:
- هر فرآیندی اگر دادهها رایگان باشند
- فقط فرآیندی که قفل مشترکی روی این دادهها دارد و اولین فرآیندی بوده که درخواست قفل انحصاری داده است.
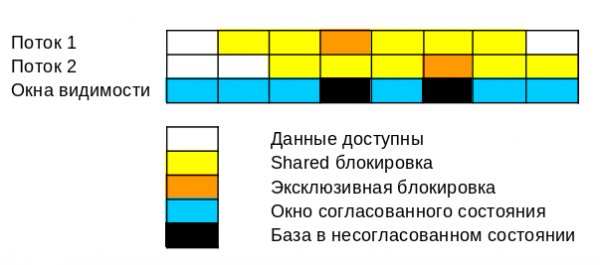
هرچه پنجره دید باریکتر باشد، فرآیندهای دیگر باید مدت زمان بیشتری منتظر آن بمانند، اما وضعیت پایگاه داده میتواند در داخل آن سازگارتر باشد.
خوانده شده_متعهد — اساس این سطح این است که ما فقط دادههای ثبتشده از نخهای دیگر را میبینیم. اگر دادههای تراکنش دیگری هنوز ثبت نشده باشند، نسخه قدیمی آن را میبینیم.
این به ما اجازه میدهد تا به جای انتظار برای آزاد شدن قفل، کار را موازی کنیم.
بدون برخی ترفندهای خاص، ما قادر به دیدن نسخه قدیمی دادهها در IRIS نخواهیم بود، بنابراین باید با قفلها کنار بیاییم.
بر این اساس، ما باید از قفلهای مشترک استفاده کنیم تا فقط در لحظات ثبات، امکان خواندن دادهها فراهم شود.
فرض کنید ما یک پایگاه کاربری متشکل از ^شخص داریم که به یکدیگر پول منتقل میکنند.
لحظه انتقال از شخص ۱۲۳ به شخص ۲۴۲:
LOCK +^person(123), +^person(242)
Set ^person(123, amount) = ^person(123, amount) - amount
Set ^person(242, amount) = ^person(242, amount) + amount
LOCK -^person(123), -^person(242)لحظه درخواست مبلغ پول از شخص ۱۲۳ قبل از کسر باید با یک قفل اختصاصی (به طور پیشفرض) همراه باشد:
LOCK +^person(123)
Write ^person(123)اگر نیاز دارید موجودی حساب خود را در حساب شخصی خود نمایش دهید، میتوانید از قفل مشترک استفاده کنید یا اصلاً از آن استفاده نکنید:
LOCK +^person(123)#”S”
Write ^person(123)با این حال، اگر فرض کنیم که عملیات پایگاه داده تقریباً فوراً انجام میشود (یادآوری میکنم که جداول سراسری ساختار سطح بسیار پایینتری نسبت به جداول رابطهای هستند)، نیاز به این سطح کاهش مییابد.
خواندن تکرارپذیر — این سطح ایزولاسیون امکان خواندن چندگانه دادهها را فراهم میکند که میتوانند توسط تراکنشهای همزمان تغییر داده شوند.
بر این اساس، ما باید یک قفل مشترک روی خواندن دادههایی که تغییر میدهیم و قفلهای انحصاری روی دادههایی که تغییر میدهیم، تنظیم کنیم.
خوشبختانه، اپراتور LOCK به شما این امکان را میدهد که تمام قفلهای لازم، که تعدادشان میتواند زیاد باشد، را در یک اپراتور با جزئیات فهرست کنید.
LOCK +^person(123, amount)#”S”
чтение ^person(123, amount)عملیات دیگر (در این زمان، رشتههای موازی سعی میکنند ^person(123, amount) را تغییر دهند، اما نمیتوانند)
LOCK +^person(123, amount)
изменение ^person(123, amount)
LOCK -^person(123, amount)
чтение ^person(123, amount)
LOCK -^person(123, amount)#”S”هنگام فهرست کردن قفلهایی که با کاما از هم جدا شدهاند، آنها به ترتیب قرار میگیرند و اگر این کار را انجام دهید:
LOCK +(^person(123),^person(242))سپس آنها به صورت اتمی و به طور همزمان گرفته میشوند.
سریال سازی — ما باید قفلهایی را تنظیم کنیم تا تمام تراکنشهایی که دادهها را به اشتراک میگذارند، در نهایت به صورت متوالی اجرا شوند. برای این رویکرد، اکثر قفلها باید انحصاری باشند و به دلایل عملکردی، روی کوچکترین مناطق سراسری اعمال شوند.
اگر در مورد حذف سرمایه در ^person سراسری صحبت کنیم، فقط سطح جداسازی SERIALIZE برای آن قابل قبول است، زیرا پول باید به طور متوالی خرج شود، در غیر این صورت میتوان چندین بار مبلغ یکسانی را خرج کرد.
۴. دوام
من آزمایشهایی را با برش سخت ظرف به وسیلهی ... انجام دادم.
docker kill my-irisپایگاه به خوبی آنها را تحمل کرد. هیچ مشکلی پیش نیامد.
نتیجه
InterSystems IRIS از تراکنشها برای دادههای سراسری پشتیبانی میکند. آنها واقعاً اتمیک و قابل اعتماد هستند. تضمین سازگاری پایگاه داده با دادههای سراسری نیازمند تلاش برنامهنویس و استفاده از تراکنشها است، زیرا فاقد ساختارهای پیچیده داخلی مانند کلیدهای خارجی است.
سطح ایزولاسیون برای متغیرهای سراسری بدون استفاده از قفل، READ UNCOMMITTED است و با استفاده از قفلها میتوان آن را تا سطح SERIALIZE نیز افزایش داد.
صحت و سرعت تراکنشها در دادههای سراسری به شدت به مهارت برنامهنویس بستگی دارد: هرچه قفلهای مشترک بیشتری برای خواندن استفاده شوند، سطح ایزولاسیون بالاتر میرود و هرچه قفلهای انحصاری محدودتری استفاده شوند، عملکرد بالاتر میرود.
منبع: www.habr.com
