

هی هابر!
با توجه به رویدادهای جاری به دلیل ویروس کرونا، تعدادی از خدمات اینترنتی شروع به دریافت بار افزایش یافته اند. مثلا، ، زیرا ظرفیت کافی وجود نداشت. و همیشه نمیتوان سرعت سرور را با افزودن تجهیزات قویتر افزایش داد، اما درخواستهای مشتری باید پردازش شوند (وگرنه به رقبا خواهند رفت).
در این مقاله من به طور خلاصه در مورد روش های رایج صحبت خواهم کرد که به شما امکان می دهد یک سرویس سریع و بدون عیب ایجاد کنید. با این حال، از بین طرح های توسعه احتمالی، من فقط آنهایی را انتخاب کردم که در حال حاضر هستند آسان برای استفاده. برای هر مورد، یا کتابخانه های آماده ای دارید، یا این فرصت را دارید که با استفاده از یک پلتفرم ابری مشکل را حل کنید.
مقیاس بندی افقی
ساده ترین و شناخته شده ترین نکته. به طور معمول، رایج ترین دو طرح توزیع بار، مقیاس بندی افقی و عمودی است. شما به سرویس ها اجازه می دهید به صورت موازی اجرا شوند و در نتیجه بار را بین آنها توزیع کنید. شما سرورهای قدرتمندتری سفارش می دهید یا کد را بهینه می کنید.
برای مثال، من ذخیرهسازی فایل ابری انتزاعی، یعنی مقداری آنالوگ OwnCloud، OneDrive و غیره را میگیرم.
یک تصویر استاندارد از چنین مداری در زیر آمده است، اما فقط پیچیدگی سیستم را نشان می دهد. پس از همه، ما باید به نحوی خدمات را همگام سازی کنیم. اگر کاربر یک فایل را از تبلت ذخیره کند و سپس بخواهد آن را از تلفن مشاهده کند چه اتفاقی می افتد؟
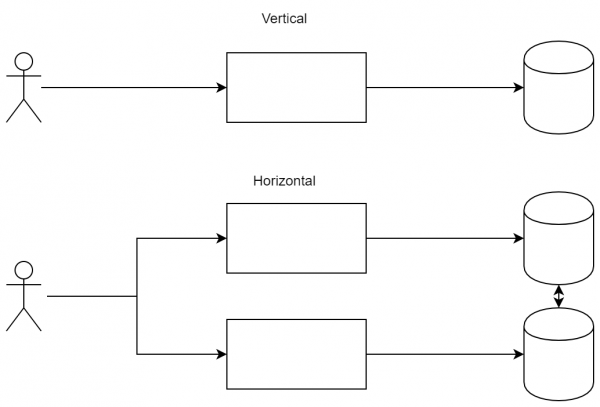
تفاوت بین رویکردها: در مقیاس بندی عمودی، ما آماده افزایش قدرت گره ها هستیم و در مقیاس بندی افقی، آماده اضافه کردن گره های جدید برای توزیع بار هستیم.
CQRS
یک الگوی نسبتاً مهم، زیرا به مشتریان مختلف اجازه میدهد نه تنها به سرویسهای مختلف متصل شوند، بلکه جریانهای رویداد مشابهی را نیز دریافت کنند. مزایای آن برای یک برنامه ساده چندان واضح نیست، اما برای یک سرویس شلوغ بسیار مهم (و ساده) است. ماهیت آن: جریان داده های ورودی و خروجی نباید قطع شوند. یعنی نمی توانید درخواستی ارسال کنید و انتظار پاسخ را داشته باشید، در عوض، درخواستی را به سرویس A ارسال می کنید، اما از سرویس B پاسخ دریافت می کنید.
اولین امتیاز این رویکرد، توانایی قطع ارتباط (به معنای وسیع کلمه) در حین اجرای یک درخواست طولانی است. به عنوان مثال، بیایید یک دنباله کم و بیش استاندارد را در نظر بگیریم:
- مشتری درخواستی را به سرور ارسال کرد.
- سرور زمان پردازش طولانی را شروع کرد.
- سرور با نتیجه به مشتری پاسخ داد.
بیایید تصور کنیم که در نقطه 2 اتصال قطع شد (یا شبکه دوباره وصل شد یا کاربر به صفحه دیگری رفت و اتصال را قطع کرد). در این صورت، ارسال پاسخ به کاربر با اطلاعاتی در مورد اینکه دقیقاً چه چیزی پردازش شده است، برای سرور دشوار خواهد بود. با استفاده از CQRS، توالی کمی متفاوت خواهد بود:
- مشتری مشترک به روز رسانی شده است.
- مشتری درخواستی را به سرور ارسال کرد.
- سرور پاسخ داد "درخواست پذیرفته شد."
- سرور با نتیجه از طریق کانال از نقطه "1" پاسخ داد.
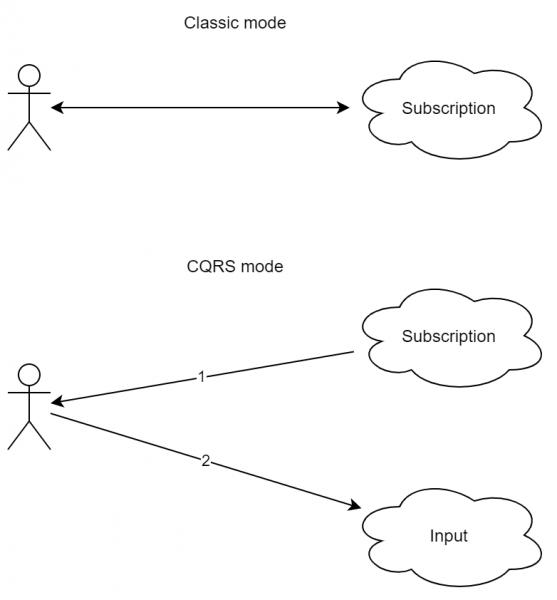
همانطور که می بینید، این طرح کمی پیچیده تر است. علاوه بر این، رویکرد بصری درخواست-پاسخ در اینجا وجود ندارد. با این حال، همانطور که می بینید، قطع اتصال در هنگام پردازش یک درخواست منجر به خطا نمی شود. علاوه بر این، اگر در واقع کاربر از چندین دستگاه (مثلاً از تلفن همراه و تبلت) به سرویس متصل باشد، می توانید مطمئن شوید که پاسخ به هر دو دستگاه می رسد.
جالب اینجاست که کد پردازش پیامهای دریافتی هم برای رویدادهایی که تحت تأثیر خود کلاینت بودهاند و هم برای رویدادهای دیگر، از جمله مواردی که از سایر کلاینتها میآیند، یکسان میشود (نه 100%).
با این حال، در واقعیت به دلیل این واقعیت که جریان یک طرفه را می توان به سبک عملکردی (با استفاده از RX و موارد مشابه) مدیریت کرد، یک امتیاز اضافی دریافت می کنیم. و این در حال حاضر یک مزیت جدی است، زیرا در اصل برنامه را می توان کاملاً واکنشی و همچنین با استفاده از یک رویکرد کاربردی ساخت. برای برنامه های چربی، این می تواند به طور قابل توجهی منابع توسعه و پشتیبانی را ذخیره کند.
اگر این رویکرد را با مقیاس افقی ترکیب کنیم، به عنوان یک امتیاز، توانایی ارسال درخواست به یک سرور و دریافت پاسخ از سرور دیگر را دریافت می کنیم. بنابراین، مشتری می تواند سرویسی را که برای او مناسب است انتخاب کند و سیستم داخل همچنان می تواند رویدادها را به درستی پردازش کند.
منبع یابی رویداد
همانطور که می دانید یکی از ویژگی های اصلی یک سیستم توزیع شده عدم وجود زمان مشترک، بخش بحرانی مشترک است. برای یک فرآیند، می توانید یک همگام سازی (در همان mutexes) انجام دهید، که در آن مطمئن هستید که هیچ کس دیگری این کد را اجرا نمی کند. با این حال، این برای یک سیستم توزیع شده خطرناک است، زیرا به سربار نیاز دارد، و همچنین تمام زیبایی پوسته پوسته شدن را از بین می برد - همه اجزا همچنان منتظر یکی هستند.
از اینجا ما یک واقعیت مهم را دریافت می کنیم - یک سیستم توزیع سریع نمی تواند همگام شود، زیرا در این صورت عملکرد را کاهش خواهیم داد. از سوی دیگر، ما اغلب به یک سازگاری مشخص بین اجزا نیاز داریم. و برای این می توانید از رویکرد با استفاده کنید ، که در آن تضمین می شود که اگر برای مدتی پس از آخرین به روز رسانی ("در نهایت") هیچ تغییری در داده ها وجود نداشته باشد، همه پرس و جوها آخرین مقدار به روز شده را برمی گردانند.
درک این نکته مهم است که برای پایگاه های داده کلاسیک اغلب از آن استفاده می شود ، که در آن هر گره دارای اطلاعات یکسانی است (این اغلب در مواردی حاصل می شود که تراکنش تنها پس از پاسخگویی سرور دوم ایجاد شده باشد). در اینجا به دلیل سطوح انزوا، استراحت هایی وجود دارد، اما ایده کلی همان است - شما می توانید در یک دنیای کاملا هماهنگ زندگی کنید.
با این حال، اجازه دهید به کار اصلی برگردیم. در صورتی که بتوان بخشی از سیستم را با ، سپس می توانیم نمودار زیر را بسازیم.
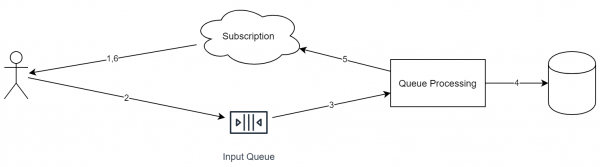
ویژگی های مهم این رویکرد:
- هر درخواست دریافتی در یک صف قرار می گیرد.
- در حین پردازش یک درخواست، سرویس ممکن است وظایف را در صف های دیگر نیز قرار دهد.
- هر رویداد ورودی دارای یک شناسه است (که برای حذف مجدد ضروری است).
- صف از نظر ایدئولوژیک بر اساس طرح "فقط الحاق" کار می کند. شما نمی توانید عناصر را از آن حذف کنید یا آنها را دوباره مرتب کنید.
- صف مطابق با طرح FIFO کار می کند (با عرض پوزش برای توتولوژی). اگر نیاز به اجرای موازی دارید، در یک مرحله باید اشیاء را به صف های مختلف منتقل کنید.
یادآوری می کنم که در حال بررسی پرونده ذخیره سازی آنلاین فایل هستیم. در این حالت، سیستم چیزی شبیه به این خواهد بود:
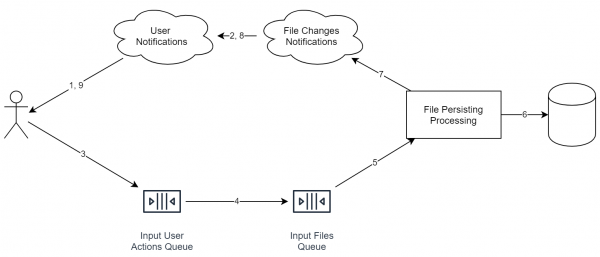
مهم است که سرویس های موجود در نمودار لزوماً به معنای یک سرور جداگانه نیستند. حتی روند ممکن است یکسان باشد. یک چیز دیگر مهم است: از نظر ایدئولوژیکی، این موارد به گونه ای از هم جدا شده اند که مقیاس بندی افقی به راحتی قابل اعمال است.
و برای دو کاربر نمودار به این صورت خواهد بود (خدمات در نظر گرفته شده برای کاربران مختلف با رنگ های مختلف نشان داده شده است):
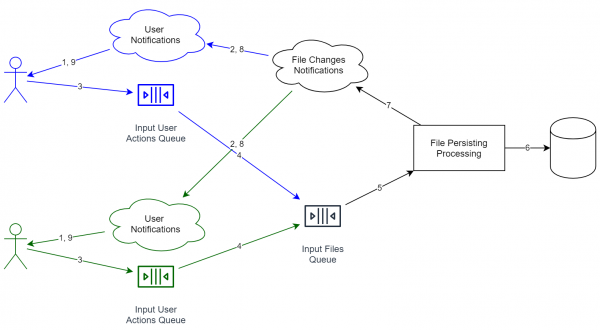
جوایز چنین ترکیبی:
- خدمات پردازش اطلاعات جدا شده است. صف ها هم جداست. اگر نیاز به افزایش توان عملیاتی سیستم داریم، فقط باید خدمات بیشتری را روی سرورهای بیشتری راه اندازی کنیم.
- وقتی اطلاعاتی را از کاربر دریافت می کنیم، لازم نیست منتظر بمانیم تا داده ها به طور کامل ذخیره شوند. برعکس، ما فقط باید به "ok" پاسخ دهیم و سپس به تدریج شروع به کار کنیم. در همان زمان، صف پیک ها را صاف می کند، زیرا اضافه کردن یک شی جدید به سرعت اتفاق می افتد و کاربر مجبور نیست منتظر عبور کامل از کل چرخه باشد.
- به عنوان مثال، من یک سرویس deduplication اضافه کردم که سعی می کند فایل های یکسان را ادغام کند. اگر در 1٪ موارد برای مدت طولانی کار کند، مشتری به سختی متوجه آن می شود (به بالا مراجعه کنید)، که یک مزیت بزرگ است، زیرا دیگر نیازی به سرعت XNUMX٪ و قابل اعتماد بودن نداریم.
با این حال، معایب بلافاصله قابل مشاهده است:
- سیستم ما سازگاری دقیق خود را از دست داده است. این بدان معنی است که اگر به عنوان مثال، مشترک سرویس های مختلفی شوید، از نظر تئوری می توانید وضعیت متفاوتی دریافت کنید (زیرا یکی از سرویس ها ممکن است زمان دریافت اعلان از صف داخلی را نداشته باشد). به عنوان یک پیامد دیگر، سیستم اکنون زمان مشترکی ندارد. به عنوان مثال، مرتب کردن همه رویدادها به سادگی بر اساس زمان رسیدن غیرممکن است، زیرا ساعت های بین سرورها ممکن است همزمان نباشند (علاوه بر این، زمان یکسان در دو سرور یک مدینه فاضله است).
- اکنون هیچ رویدادی را نمی توان به سادگی به عقب بازگرداند (همانطور که می توان با یک پایگاه داده انجام داد). در عوض، باید یک رویداد جدید اضافه کنید - ، که آخرین حالت را به حالت مورد نیاز تغییر می دهد. به عنوان مثال از یک منطقه مشابه: بدون بازنویسی تاریخچه (که در برخی موارد بد است)، نمی توانید یک commit را در git پس بگیرید، اما می توانید یک کامیت ویژه ایجاد کنید. ، که در اصل فقط حالت قبلی را برمی گرداند. با این حال، هر دو ارتکاب اشتباه و بازگشت در تاریخ باقی خواهند ماند.
- طرح داده ممکن است از نسخه به انتشار تغییر کند، اما رویدادهای قدیمی دیگر نمی توانند به استاندارد جدید به روز شوند (زیرا رویدادها در اصل قابل تغییر نیستند).
همانطور که می بینید، Event Sourcing با CQRS به خوبی کار می کند. علاوه بر این، پیادهسازی یک سیستم با صفهای کارآمد و راحت، اما بدون جداسازی جریانهای داده، به خودی خود دشوار است، زیرا باید نقاط هماهنگسازی را اضافه کنید که کل اثر مثبت صفها را خنثی میکند. با اعمال هر دو رویکرد به طور همزمان، لازم است کد برنامه را کمی تنظیم کنید. در مورد ما، هنگام ارسال یک فایل به سرور، پاسخ فقط "ok" است، که فقط به این معنی است که "عملیات افزودن فایل ذخیره شده است." به طور رسمی، این بدان معنا نیست که داده ها از قبل در دستگاه های دیگر در دسترس هستند (به عنوان مثال، سرویس deduplication می تواند ایندکس را بازسازی کند). با این حال، پس از مدتی، مشتری یک اعلان به سبک "فایل X ذخیره شده است" دریافت می کند.
در نتیجه:
- تعداد وضعیتهای ارسال فایل در حال افزایش است: بهجای حالت کلاسیک "فایل ارسال شده"، دو عدد دریافت میکنیم: "فایل به صف روی سرور اضافه شده است" و "فایل در حافظه ذخیره شده است." مورد دوم به این معنی است که دستگاه های دیگر می توانند از قبل دریافت فایل را شروع کنند (برای این واقعیت که صف ها با سرعت های مختلف کار می کنند تنظیم شده است).
- با توجه به اینکه اکنون اطلاعات ارسالی از طریق کانال های مختلف ارائه می شود، باید راهکارهایی برای دریافت وضعیت پردازش فایل ارائه دهیم. در نتیجه: برخلاف درخواست-پاسخ کلاسیک، هنگام پردازش فایل، کلاینت میتواند مجددا راهاندازی شود، اما وضعیت خود این پردازش درست خواهد بود. علاوه بر این، این مورد اساساً خارج از جعبه کار می کند. در نتیجه: ما اکنون در برابر شکست ها تحمل بیشتری داریم.
انزال
همانطور که در بالا توضیح داده شد، سیستم های منبع رویداد فاقد سازگاری دقیق هستند. این بدان معنی است که ما می توانیم از چندین ذخیره سازی بدون هیچ هماهنگی بین آنها استفاده کنیم. با نزدیک شدن به مشکل خود، می توانیم:
- جدا کردن فایل ها بر اساس نوع به عنوان مثال، تصاویر/فیلم ها را می توان رمزگشایی کرد و قالب کارآمدتری را انتخاب کرد.
- حساب ها را بر اساس کشور جدا کنید. با توجه به بسیاری از قوانین، این ممکن است مورد نیاز باشد، اما این طرح معماری چنین فرصتی را به طور خودکار فراهم می کند
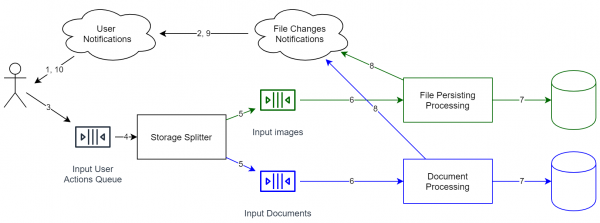
اگر میخواهید دادهها را از یک فضای ذخیرهسازی به حافظه دیگر منتقل کنید، ابزارهای استاندارد دیگر کافی نیستند. متأسفانه، در این حالت، باید صف را متوقف کنید، مهاجرت را انجام دهید و سپس آن را شروع کنید. در حالت کلی، دادهها را نمیتوان "در حال پرواز" منتقل کرد، اما اگر صف رویداد به طور کامل ذخیره شود و شما عکسهای فوری از حالتهای ذخیره قبلی داشته باشید، میتوانیم رویدادها را به صورت زیر پخش کنیم:
- در منبع رویداد، هر رویداد دارای شناسه مخصوص به خود است (در حالت ایده آل، بدون کاهش). این بدان معنی است که می توانیم یک فیلد به حافظه اضافه کنیم - شناسه آخرین عنصر پردازش شده.
- ما صف را کپی می کنیم تا همه رویدادها برای چندین ذخیره سازی مستقل پردازش شوند (اولین موردی است که داده ها قبلاً در آن ذخیره شده اند و دومی جدید است، اما هنوز خالی است). صف دوم البته هنوز در حال انجام نیست.
- صف دوم را راه اندازی می کنیم (یعنی پخش مجدد رویدادها را شروع می کنیم).
- وقتی صف جدید نسبتاً خالی است (یعنی میانگین اختلاف زمانی بین افزودن یک عنصر و بازیابی آن قابل قبول است)، میتوانید خوانندهها را به فضای ذخیرهسازی جدید تغییر دهید.
همانطور که می بینید، ما در سیستم خود انسجام دقیقی نداشتیم و هنوز نداریم. فقط ثبات نهایی وجود دارد، یعنی تضمینی برای پردازش رویدادها به همان ترتیب (اما احتمالاً با تأخیرهای متفاوت). و با استفاده از این، میتوانیم بهراحتی دادهها را بدون توقف سیستم به آن طرف کره زمین منتقل کنیم.
بنابراین، با ادامه مثال ما در مورد ذخیره سازی آنلاین برای فایل ها، چنین معماری در حال حاضر تعدادی امتیاز به ما می دهد:
- ما می توانیم اشیاء را به روشی پویا به کاربران نزدیکتر کنیم. از این طریق می توانید کیفیت خدمات را بهبود ببخشید.
- ممکن است برخی از داده ها را در شرکت ها ذخیره کنیم. به عنوان مثال، کاربران Enterprise اغلب نیاز دارند که داده های آنها در مراکز داده کنترل شده ذخیره شود (برای جلوگیری از نشت داده ها). از طریق شاردینگ ما به راحتی می توانیم از این پشتیبانی کنیم. و اگر مشتری یک ابر سازگار داشته باشد، این کار حتی ساده تر می شود (به عنوان مثال، ).
- و مهمترین چیز این است که ما مجبور نیستیم این کار را انجام دهیم. از این گذشته، برای شروع، ما با یک فضای ذخیره سازی برای همه حساب ها (برای شروع سریع کار) کاملاً خوشحال خواهیم بود. و ویژگی کلیدی این سیستم این است که اگرچه قابل ارتقا است، اما در مرحله اولیه بسیار ساده است. فقط لازم نیست فوراً کدی بنویسید که با میلیون ها صف مستقل جداگانه کار می کند و غیره. در صورت لزوم می توان این کار را در آینده انجام داد.
میزبانی محتوای ثابت
این نکته ممکن است کاملاً بدیهی به نظر برسد، اما هنوز برای یک برنامه کم و بیش استاندارد بارگذاری شده ضروری است. ماهیت آن ساده است: تمام محتوای استاتیک نه از همان سروری که برنامه در آن قرار دارد، بلکه از سرورهای ویژه ای که به طور خاص به این کار اختصاص داده شده است توزیع می شود. در نتیجه، این عملیات سریعتر انجام میشوند (nginx شرطی فایلها را سریعتر و کمهزینهتر از سرور جاوا ارائه میکند). به علاوه معماری CDN () به ما امکان می دهد تا فایل های خود را نزدیک به کاربران نهایی قرار دهیم که تأثیر مثبتی بر راحتی کار با سرویس دارد.
ساده ترین و استانداردترین مثال از محتوای ثابت مجموعه ای از اسکریپت ها و تصاویر برای یک وب سایت است. همه چیز با آنها ساده است - آنها از قبل شناخته شده هستند، سپس بایگانی در سرورهای CDN آپلود می شود، از آنجا به کاربران نهایی توزیع می شود.
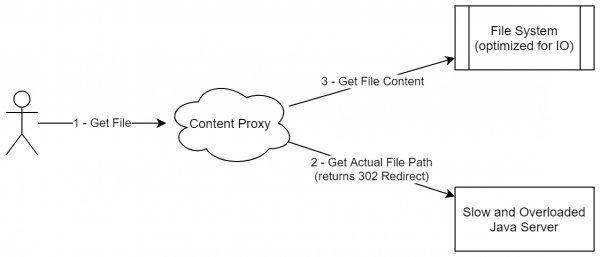
با این حال، در واقعیت، برای محتوای استاتیک، میتوانید از رویکردی تا حدودی شبیه به معماری لامبدا استفاده کنید. بیایید به وظیفه خود (ذخیره فایل آنلاین) برگردیم، که در آن باید فایل ها را بین کاربران توزیع کنیم. ساده ترین راه حل ایجاد سرویسی است که برای هر درخواست کاربر، تمام بررسی های لازم (مجوز و غیره) را انجام می دهد و سپس فایل را مستقیماً از ذخیره سازی ما دانلود می کند. عیب اصلی این رویکرد این است که محتوای ثابت (و یک فایل با یک ویرایش خاص در واقع محتوای ثابت است) توسط همان سروری که منطق تجاری را در خود دارد توزیع می شود. در عوض، می توانید نمودار زیر را ایجاد کنید:
- سرور URL دانلود را ارائه می دهد. این می تواند به شکل file_id + key باشد، که در آن کلید یک امضای دیجیتالی کوچک است که حق دسترسی به منبع را برای XNUMX ساعت آینده می دهد.
- فایل توسط nginx ساده با گزینه های زیر توزیع می شود:
- ذخیره سازی محتوا از آنجایی که این سرویس می تواند در یک سرور جداگانه قرار گیرد، ما برای خود ذخیره ای برای آینده با قابلیت ذخیره آخرین فایل های دانلود شده روی دیسک گذاشته ایم.
- بررسی کلید در زمان ایجاد اتصال
- اختیاری: پردازش محتوای جریانی. به عنوان مثال، اگر همه فایلهای موجود در سرویس را فشرده کنیم، میتوانیم مستقیماً در این ماژول از حالت فشرده خارج کنیم. در نتیجه: عملیات IO در جایی که به آنها تعلق دارد انجام می شود. یک بایگانی کننده در جاوا به راحتی مقدار زیادی حافظه اضافی را اختصاص می دهد، اما بازنویسی یک سرویس با منطق تجاری به شرطی Rust/C++ نیز ممکن است بی اثر باشد. در مورد ما، فرآیندها (یا حتی خدمات) متفاوتی استفاده میشود، و بنابراین میتوانیم به طور موثر منطق تجاری و عملیات IO را از هم جدا کنیم.
این طرح شباهت زیادی به توزیع محتوای ثابت ندارد (چون ما کل بسته استاتیک را در جایی آپلود نمی کنیم)، اما در واقعیت، این رویکرد دقیقاً مربوط به توزیع داده های تغییرناپذیر است. علاوه بر این، این طرح را می توان به موارد دیگری تعمیم داد که در آن محتوا صرفاً ثابت نیست، بلکه می تواند به عنوان مجموعه ای از بلوک های تغییرناپذیر و غیرقابل حذف نمایش داده شود (اگرچه می توان آنها را اضافه کرد).
به عنوان مثال دیگر (برای تقویت): اگر با Jenkins/TeamCity کار کرده اید، می دانید که هر دو راه حل در جاوا نوشته شده اند. هر دوی آنها یک فرآیند جاوا هستند که هم هماهنگ سازی ساخت و هم مدیریت محتوا را انجام می دهد. به طور خاص، هر دو وظایفی مانند "انتقال یک فایل/پوشه از سرور" دارند. به عنوان مثال: صدور مصنوعات، انتقال کد منبع (زمانی که نماینده کد را مستقیماً از مخزن دانلود نمی کند، اما سرور این کار را برای او انجام می دهد)، دسترسی به گزارش ها. همه این وظایف در بار IO متفاوت هستند. یعنی معلوم میشود که سروری که مسئولیت منطق تجاری پیچیده را بر عهده دارد باید در عین حال بتواند به طور مؤثر جریانهای بزرگی از دادهها را از طریق خود هدایت کند. و جالبترین چیز این است که چنین عملیاتی را میتوان به همان nginx بر اساس همان طرح واگذار کرد (به جز اینکه کلید داده باید به درخواست اضافه شود).
با این حال، اگر به سیستم خود بازگردیم، نمودار مشابهی دریافت می کنیم:
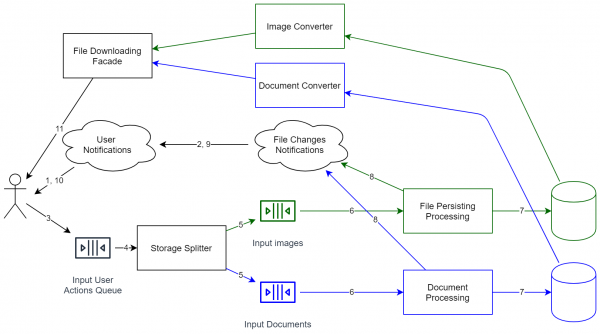
همانطور که می بینید، سیستم به شدت پیچیده تر شده است. اکنون این فقط یک فرآیند کوچک نیست که فایل ها را به صورت محلی ذخیره می کند. اکنون آنچه مورد نیاز است ساده ترین پشتیبانی، کنترل نسخه API و غیره نیست. بنابراین، پس از ترسیم تمام نمودارها، بهتر است به طور دقیق ارزیابی شود که آیا توسعه پذیری ارزش هزینه را دارد یا خیر. با این حال، اگر می خواهید بتوانید سیستم را گسترش دهید (از جمله کار با تعداد بیشتری از کاربران)، باید به سراغ راه حل های مشابه بروید. اما، در نتیجه، سیستم از نظر معماری برای افزایش بار آماده است (تقریباً هر جزء را می توان برای مقیاس بندی افقی کلون کرد). سیستم را می توان بدون توقف آن به روز کرد (به سادگی سرعت برخی از عملیات ها کمی کند می شود).
همانطور که در ابتدا گفتم، در حال حاضر تعدادی از خدمات اینترنتی شروع به دریافت افزایش بار کرده اند. و برخی از آنها به سادگی شروع به متوقف کردن عملکرد صحیح خود کردند. در واقع، سیستم ها دقیقاً در لحظه ای که قرار بود کسب و کار پول در بیاورد، شکست خوردند. یعنی به جای تحویل به تعویق افتاده، به جای اینکه به مشتریان پیشنهاد کند «تحویل خود را برای ماههای آینده برنامهریزی کنید»، سیستم به سادگی گفت «به سراغ رقبای خود بروید». در واقع، این بهای بهرهوری پایین است: زیان دقیقاً زمانی رخ میدهد که سود به بالاترین حد خود برسد.
نتیجه
همه این رویکردها قبلا شناخته شده بودند. همان VK مدتهاست که از ایده میزبانی محتوای ثابت برای نمایش تصاویر استفاده می کند. بسیاری از بازیهای آنلاین از طرح Sharding برای تقسیم بازیکنان به مناطق یا جدا کردن مکانهای بازی استفاده میکنند (اگر خود دنیا یکی باشد). رویکرد منبع یابی رویداد به طور فعال در ایمیل استفاده می شود. اکثر برنامه های تجاری که در آن داده ها به طور مداوم دریافت می شوند، در واقع بر اساس رویکرد CQRS ساخته شده اند تا بتوانند داده های دریافتی را فیلتر کنند. خوب، مقیاس بندی افقی برای مدت طولانی در بسیاری از خدمات استفاده شده است.
با این حال، مهمتر از همه، اعمال همه این الگوها در کاربردهای مدرن بسیار آسان شده است (البته اگر مناسب باشند). ابرها فوراً تقسیم بندی و مقیاس افقی را ارائه می دهند که بسیار ساده تر از سفارش دادن سرورهای اختصاصی مختلف در مراکز داده مختلف است. CQRS بسیار سادهتر شده است، البته فقط به دلیل توسعه کتابخانههایی مانند RX. حدود 10 سال پیش، یک وب سایت کمیاب می توانست از این پشتیبانی کند. به لطف ظروف آماده با آپاچی کافکا، راه اندازی رویداد منبع یابی نیز فوق العاده آسان است. 10 سال پیش این یک نوآوری بود، اکنون عادی شده است. در مورد میزبانی محتوای استاتیک هم همینطور است: به دلیل فناوری های راحت تر (از جمله این واقعیت که اسناد دقیق و پایگاه داده بزرگی از پاسخ ها وجود دارد)، این رویکرد حتی ساده تر شده است.
در نتیجه، اجرای تعدادی از الگوهای معماری نسبتاً پیچیده اکنون بسیار ساده تر شده است، به این معنی که بهتر است از قبل به آن نگاه دقیق تری داشته باشیم. اگر در یک برنامه ده ساله یکی از راه حل های بالا به دلیل هزینه بالای اجرا و بهره برداری کنار گذاشته شد، اکنون در یک برنامه جدید یا پس از بازسازی، می توانید سرویسی ایجاد کنید که از نظر معماری هر دو قابل توسعه باشد ( از نظر عملکرد) و آماده به درخواست های جدید از مشتریان (به عنوان مثال، برای بومی سازی داده های شخصی).
و مهمتر از همه: لطفاً اگر برنامه ساده ای دارید از این رویکردها استفاده نکنید. بله، آنها زیبا و جالب هستند، اما برای یک سایت با اوج بازدید 100 نفر، اغلب می توانید با یک مونولیت کلاسیک (حداقل در خارج، همه چیز در داخل را می توان به ماژول ها تقسیم کرد و غیره) از آن عبور کرد.
منبع: www.habr.com
