

موقعیتهایی وجود دارد که به جدولی بدون کلید اصلی یا برخی از فهرستهای منحصر به فرد دیگر، به دلیل سهلانگاری، شامل کلونهای کاملی از رکوردهای موجود هستند.

برای مثال، مقادیر یک معیار زمانی با استفاده از یک جریان COPY در PostgreSQL نوشته میشوند، و سپس یک خرابی ناگهانی رخ میدهد و برخی از دادههای کاملاً یکسان دوباره وارد میشوند.
چگونه از شر کلونهای غیرضروری از پایگاه داده خلاص شویم؟
وقتی PK مفید نیست
سادهترین راه حل، جلوگیری از وقوع این وضعیت در وهله اول است. به عنوان مثال، با پیادهسازی یک کلید اصلی (PRIMARY KEY). اما این کار همیشه بدون افزایش حجم دادههای ذخیره شده امکانپذیر نیست.
برای مثال، اگر دقت سیستم منبع بالاتر از دقت فیلد در پایگاه داده باشد:
metric | ts | data
--------------------------------------------------
cpu.busy | 2019-12-20 00:00:00 | {"value" : 12.34}
cpu.busy | 2019-12-20 00:00:01 | {"value" : 10}
cpu.busy | 2019-12-20 00:00:01 | {"value" : 11.2}
cpu.busy | 2019-12-20 00:00:03 | {"value" : 15.7}
متوجه شدید؟ شمارش معکوس، به جای 00:00:02، یک ثانیه زودتر در پایگاه داده ts ثبت شده بود، اما از نقطه نظر عملی کاملاً معتبر باقی ماند (به هر حال، مقادیر دادهها متفاوت هستند!).
البته، میشه انجامش داد PK (متریک، ts) — اما در این صورت برای دادههای معتبر با تداخل درج مواجه خواهیم شد.
می تواند انجام دهد PK (متریک، ts، داده) - اما این حجم آن را به میزان قابل توجهی افزایش میدهد، که ما از آن استفاده نخواهیم کرد.
بنابراین، صحیحترین گزینه ایجاد یک شاخص منظم غیرمنحصر به فرد است. (متریک، ts) و اگر مشکلی پیش آمد، پس از وقوع آن، به آن رسیدگی کنید.
جنگهای کلون آغاز شدهاند.
نوعی تصادف اتفاق افتاده است و حالا باید رکوردهای کلون را از جدول حذف کنیم.

بیایید دادههای اولیه را شبیهسازی کنیم:
CREATE TABLE tbl(k text, v integer);
INSERT INTO tbl
VALUES
('a', 1)
, ('a', 3)
, ('b', 2)
, ('b', 2) -- oops!
, ('c', 3)
, ('c', 3) -- oops!!
, ('c', 3) -- oops!!
, ('d', 4)
, ('e', 5)
;اینجا دست ما سه بار لرزید، Ctrl+V گیر کرد، و این هم از ...
اول از همه، بیایید درک کنیم که جدول ما میتواند بسیار بزرگ باشد، بنابراین پس از اینکه همه کلونها را پیدا کردیم، باید به معنای واقعی کلمه "انگشت خود را فشار دهیم" تا آنها را حذف کنیم. سوابق خاص بدون جستجوی مجدد آنها.
و چنین راهی وجود دارد - این است ، شناسه فیزیکی یک رکورد خاص.
بنابراین، اول از همه، باید CTID های رکوردها را بر اساس محتوای کامل ردیف جدول جمع آوری کنیم. ساده ترین گزینه تبدیل کل ردیف به متن است:
SELECT
T::text
, array_agg(ctid) ctids
FROM
tbl T
GROUP BY
1;
t | ctids
---------------------------------
(e,5) | {"(0,9)"}
(d,4) | {"(0,8)"}
(c,3) | {"(0,5)","(0,6)","(0,7)"}
(b,2) | {"(0,3)","(0,4)"}
(a,3) | {"(0,2)"}
(a,1) | {"(0,1)"}
آیا امکانش هست که ریخته نشه؟در اصل، در بیشتر موارد این کار امکانپذیر است. تا زمانی که شروع به استفاده از فیلدها در این جدول نکنید انواع بدون عملگر تساوی:
CREATE TABLE tbl(k text, v integer, x point);
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T;
-- ERROR: could not identify an equality operator for type tbl
آها، بلافاصله میبینیم که اگر بیش از یک ورودی در آرایه وجود داشته باشد، همه آنها کلون هستند. بیایید فقط آنها را نگه داریم:
SELECT
unnest(ctids[2:])
FROM
(
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T::text
) T;unnest
------
(0,6)
(0,7)
(0,4)برای کسانی که دوست دارند کوتاه بنویسندهمچنین میتوانید آن را به این صورت بنویسید:
SELECT
unnest((array_agg(ctid))[2:])
FROM
tbl T
GROUP BY
T::text;از آنجایی که ما به مقدار خود رشته سریالیزه شده علاقهای نداریم، به سادگی آن را از ستونهای برگردانده شده از زیرپرسوجو حذف کردیم.
تنها کاری که باقی مانده این است که DELETE را مجبور کنیم از مجموعه ای که دریافت کرده ایم استفاده کند:
DELETE FROM
tbl
WHERE
ctid = ANY(ARRAY(
SELECT
unnest(ctids[2:])
FROM
(
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T::text
) T
)::tid[]);بیایید خودمان را بررسی کنیم:
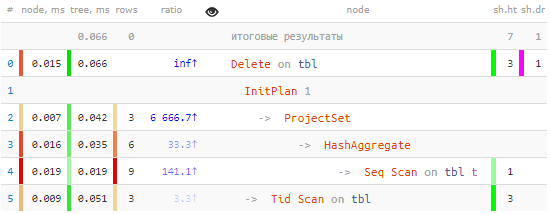
بله، درست است: ۳ رکورد ما در یک اسکن ترتیبی (Seq Scan) از کل جدول انتخاب شدند و از گره Delete برای جستجوی دادهها استفاده شد. تک گذر با Tid Scan:
-> Tid Scan on tbl (actual time=0.050..0.051 rows=3 loops=1)
TID Cond: (ctid = ANY ($0))اگر رکوردهای زیادی را پاک کردهاید، .
بیایید بررسی کنیم که آیا جدول بزرگتری با تعداد بیشتری از مقادیر تکراری وجود دارد یا خیر:
TRUNCATE TABLE tbl;
INSERT INTO tbl
SELECT
chr(ascii('a'::text) + (random() * 26)::integer) k -- a..z
, (random() * 100)::integer v -- 0..99
FROM
generate_series(1, 10000) i; 
بنابراین، این روش با موفقیت کار میکند، اما باید با احتیاط استفاده شود. زیرا برای هر رکورد حذف شده، یک صفحه داده در Tid Scan و یکی در Delete خوانده میشود.
منبع: www.habr.com
