


در کار خود اغلب با راه حل های فنی / محصولات نرم افزاری جدید مواجه می شوم که اطلاعات مربوط به آنها در اینترنت روسی زبان کمیاب است. با این مقاله، سعی میکنم یکی از این شکافها را با مثالی از تمرین اخیرم پر کنم، زمانی که نیاز به تنظیم ارسال رویدادهای CDC از دو DBMS محبوب (PostgreSQL و MongoDB) به یک خوشه کافکا با استفاده از Debezium داشتم. امیدوارم این مقاله مروری که در نتیجه کار انجام شده ظاهر شد، برای دیگران مفید باشد.
Debezium و CDC به طور کلی چیست؟
- نماینده رده نرم افزار CDC ()، یا به طور دقیق تر، مجموعه ای از اتصال دهنده ها برای DBMS های مختلف سازگار با فریم ورک Apache Kafka Connect است.
آن تحت مجوز Apache License v2.0 و توسط Red Hat پشتیبانی می شود. توسعه از سال 2016 ادامه دارد و در حال حاضر پشتیبانی رسمی از DBMS های زیر را ارائه می دهد: MySQL، PostgreSQL، MongoDB، SQL Server. همچنین اتصالاتی برای Cassandra و Oracle وجود دارد، اما در حال حاضر آنها در وضعیت "دسترسی اولیه" هستند و نسخه های جدید سازگاری با عقب را تضمین نمی کنند.
اگر CDC را با رویکرد سنتی مقایسه کنیم (زمانی که برنامه مستقیماً داده ها را از DBMS می خواند)، مزایای اصلی آن شامل اجرای جریان تغییر داده در سطح ردیف با تأخیر کم، قابلیت اطمینان بالا و در دسترس بودن است. دو نکته آخر با استفاده از خوشه کافکا به عنوان مخزن رویدادهای CDC به دست می آید.
همچنین، مزایا شامل این واقعیت است که یک مدل واحد برای ذخیره رویدادها استفاده می شود، بنابراین برنامه نهایی نیازی به نگرانی در مورد تفاوت های ظریف کارکردن DBMS های مختلف ندارد.
در نهایت، استفاده از یک واسطه پیام، زمینه را برای مقیاس افقی برنامههایی که تغییرات دادهها را دنبال میکنند باز میکند. در عین حال، تأثیر بر منبع داده به حداقل می رسد، زیرا داده ها مستقیماً از DBMS دریافت نمی شوند، بلکه از خوشه کافکا دریافت می شوند.
درباره معماری Debezium
استفاده از Debezium به این طرح ساده ختم می شود:
DBMS (به عنوان منبع داده) → رابط در Kafka Connect → Apache Kafka → مصرف کننده
به عنوان مثال، در اینجا نموداری از وب سایت پروژه آمده است:
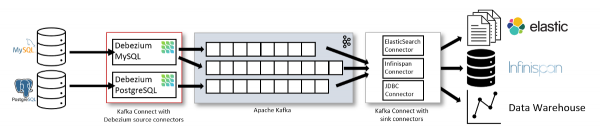
با این حال، من واقعاً این طرح را دوست ندارم، زیرا به نظر می رسد که فقط استفاده از اتصال سینک امکان پذیر است.
در واقعیت، وضعیت متفاوت است: دریاچه داده خود را پر کنید (آخرین لینک در نمودار بالا) تنها راه استفاده از Debezium نیست. رویدادهای ارسال شده به آپاچی کافکا می توانند توسط برنامه های شما برای حل و فصل موقعیت های مختلف استفاده شوند. مثلا:
- حذف داده های نامربوط از کش؛
- ارسال اطلاعیه؛
- به روز رسانی فهرست جستجو؛
- نوعی گزارش حسابرسی؛
- ...
در صورتی که برنامه جاوا دارید و نیازی به استفاده از خوشه کافکا نیست، امکان کار با آن نیز وجود دارد. . مزیت آشکار این است که با آن می توانید زیرساخت های اضافی (به شکل اتصال دهنده و کافکا) را رد کنید. با این حال، این راه حل از نسخه 1.1 منسوخ شده است و دیگر برای استفاده توصیه نمی شود (ممکن است در نسخه های بعدی حذف شود).
این مقاله معماری توصیه شده توسط توسعه دهندگان را مورد بحث قرار می دهد که تحمل خطا و مقیاس پذیری را ارائه می دهد.
پیکربندی اتصال دهنده
برای شروع ردیابی تغییرات در مهمترین مقدار - داده ها - نیاز داریم:
- منبع داده، که می تواند MySQL از نسخه 5.7، PostgreSQL 9.6+، MongoDB 3.2+ ();
- خوشه آپاچی کافکا;
- نمونه Kafka Connect (نسخه های 1.x، 2.x)؛
- کانکتور Debezium پیکربندی شده است.
روی دو نقطه اول کار کنید، یعنی. مراحل نصب DBMS و آپاچی کافکا از حوصله مقاله خارج است. با این حال، برای کسانی که می خواهند همه چیز را در sandbox مستقر کنند، مخزن رسمی با نمونه ها دارای یک آماده است. .
ما روی دو نکته آخر با جزئیات بیشتر تمرکز خواهیم کرد.
0. کافکا کانکت
در اینجا و بعد در مقاله، تمام نمونه های پیکربندی در زمینه تصویر Docker توزیع شده توسط توسعه دهندگان Debezium در نظر گرفته می شوند. این شامل تمام فایل های پلاگین (کانکتورها) لازم است و پیکربندی Kafka Connect را با استفاده از متغیرهای محیطی فراهم می کند.
اگر قصد دارید از Kafka Connect از Confluent استفاده کنید، باید به طور مستقل افزونه های اتصال دهنده های لازم را به دایرکتوری مشخص شده اضافه کنید. plugin.path یا از طریق یک متغیر محیطی تنظیم کنید CLASSPATH. تنظیمات مربوط به کارگر و کانکتورهای Kafka Connect از طریق فایلهای پیکربندی که به عنوان آرگومان به فرمان شروع کارگر ارسال میشوند، تعریف میشوند. برای جزئیات مراجعه کنید .
کل فرآیند راه اندازی Debeizum در نسخه کانکتور در دو مرحله انجام می شود. بیایید هر یک از آنها را در نظر بگیریم:
1. راه اندازی چارچوب Kafka Connect
برای استریم داده ها به یک خوشه آپاچی کافکا، پارامترهای خاصی در چارچوب کافکا کانکت تنظیم می شوند، مانند:
- پارامترهای اتصال به خوشه،
- نام موضوعاتی که پیکربندی خود کانکتور در آنها ذخیره می شود،
- نام گروهی که کانکتور در آن اجرا می شود (در صورت استفاده از حالت توزیع شده).
تصویر رسمی Docker پروژه از پیکربندی با استفاده از متغیرهای محیطی پشتیبانی می کند - این همان چیزی است که ما استفاده خواهیم کرد. بنابراین، تصویر را دانلود کنید:
docker pull debezium/connectحداقل مجموعه ای از متغیرهای محیطی مورد نیاز برای اجرای کانکتور به شرح زیر است:
-
BOOTSTRAP_SERVERS=kafka-1:9092,kafka-2:9092,kafka-3:9092- لیست اولیه سرورهای خوشه کافکا برای به دست آوردن لیست کاملی از اعضای خوشه. -
OFFSET_STORAGE_TOPIC=connector-offsets- موضوعی برای ذخیره موقعیت هایی که کانکتور در حال حاضر در آن قرار دارد. -
CONNECT_STATUS_STORAGE_TOPIC=connector-status- موضوعی برای ذخیره وضعیت کانکتور و وظایف آن؛ -
CONFIG_STORAGE_TOPIC=connector-config- موضوعی برای ذخیره داده های پیکربندی کانکتور و وظایف آن؛ -
GROUP_ID=1- شناسه گروهی از کارگران که وظیفه اتصال را می توان بر روی آنها اجرا کرد. هنگام استفاده از توزیع مورد نیاز است (توزیع شده) رژیم
ظرف را با این متغیرها شروع می کنیم:
docker run
-e BOOTSTRAP_SERVERS='kafka-1:9092,kafka-2:9092,kafka-3:9092'
-e GROUP_ID=1
-e CONFIG_STORAGE_TOPIC=my_connect_configs
-e OFFSET_STORAGE_TOPIC=my_connect_offsets
-e STATUS_STORAGE_TOPIC=my_connect_statuses debezium/connect:1.2نکته ای در مورد Avro
به طور پیشفرض، Debezium دادهها را با فرمت JSON مینویسد، که برای جعبههای ماسهای و مقادیر کمی داده قابل قبول است، اما در پایگاههای دادهای که به شدت بارگذاری شدهاند، میتواند مشکلساز باشد. جایگزینی برای مبدل JSON، سریالسازی پیامها با استفاده از آن است به فرمت باینری، که بار روی زیرسیستم I/O را در آپاچی کافکا کاهش می دهد.
برای استفاده از Avro، شما نیاز به استقرار جداگانه دارید (برای ذخیره طرحواره ها). متغیرهای مبدل به صورت زیر خواهد بود:
name: CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL
value: http://kafka-registry-01:8081/
name: CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL
value: http://kafka-registry-01:8081/
name: VALUE_CONVERTER
value: io.confluent.connect.avro.AvroConverterجزئیات استفاده از Avro و تنظیم رجیستری برای آن فراتر از محدوده مقاله است - برای وضوح بیشتر، ما از JSON استفاده خواهیم کرد.
2. راه اندازی خود کانکتور
اکنون می توانید مستقیماً به پیکربندی خود کانکتور بروید که داده ها را از منبع می خواند.
بیایید به مثال اتصال دهنده ها برای دو DBMS نگاه کنیم: PostgreSQL و MongoDB، که من تجربه آنها را دارم و تفاوت هایی برای آنها وجود دارد (البته کوچک، اما در برخی موارد قابل توجه!).
پیکربندی در نماد JSON توضیح داده شده و با استفاده از درخواست POST در Kafka Connect آپلود می شود.
2.1. PostgreSQL
نمونه پیکربندی رابط برای PostgreSQL:
{
"name": "pg-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"plugin.name": "pgoutput",
"database.hostname": "127.0.0.1",
"database.port": "5432",
"database.user": "debezium",
"database.password": "definitelynotpassword",
"database.dbname" : "dbname",
"database.server.name": "pg-dev",
"table.include.list": "public.(.*)",
"heartbeat.interval.ms": "5000",
"slot.name": "dbname_debezium",
"publication.name": "dbname_publication",
"transforms": "AddPrefix",
"transforms.AddPrefix.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.AddPrefix.regex": "pg-dev.public.(.*)",
"transforms.AddPrefix.replacement": "data.cdc.dbname"
}
}اصل عملکرد کانکتور پس از این پیکربندی بسیار ساده است:
- هنگامی که برای اولین بار راه اندازی می شود، به پایگاه داده مشخص شده در پیکربندی متصل می شود و در حالت شروع می شود. عکس فوری اولیه، مجموعه اولیه داده های دریافت شده با شرطی را برای کافکا ارسال می کند
SELECT * FROM table_name. - پس از تکمیل اولیه، کانکتور برای خواندن تغییرات از فایل های PostgreSQL WAL وارد حالت می شود.
درباره گزینه های استفاده شده:
-
name- نام کانکتوری که پیکربندی شرح داده شده در زیر برای آن استفاده شده است. در آینده، از این نام برای کار با کانکتور (به عنوان مثال مشاهده وضعیت / راه اندازی مجدد / به روز رسانی پیکربندی) از طریق Kafka Connect REST API استفاده می شود. -
connector.class- کلاس رابط DBMS که توسط کانکتور پیکربندی شده استفاده خواهد شد. -
plugin.nameنام افزونه رمزگشایی منطقی داده ها از فایل های WAL است. در دسترس برای انتخابwal2json,decoderbuffsиpgoutput. دو مورد اول مستلزم نصب پسوندهای مناسب در DBMS هستند وpgoutputبرای PostgreSQL نسخه 10 و بالاتر نیازی به دستکاری اضافی ندارد. -
database.*- گزینه هایی برای اتصال به پایگاه داده، جایی کهdatabase.server.name- نام نمونه PostgreSQL که برای تشکیل نام موضوع در خوشه کافکا استفاده می شود. -
table.include.list- لیستی از جداول که می خواهیم تغییرات را در آنها ردیابی کنیم. در قالب ارائه شده استschema.table_name; نمی توان با هم استفاده کردtable.exclude.list; -
heartbeat.interval.ms- فاصله زمانی (بر حسب میلی ثانیه) که با آن کانکتور پیام های ضربان قلب را به یک موضوع خاص ارسال می کند. -
heartbeat.action.query- درخواستی که هنگام ارسال هر پیام ضربان قلب اجرا می شود (این گزینه از نسخه 1.1 ظاهر شده است). -
slot.name- نام شکاف تکراری که توسط کانکتور استفاده خواهد شد. publication.name- نام در PostgreSQL که کانکتور از آن استفاده می کند. در صورتی که وجود نداشته باشد، Debezium سعی خواهد کرد آن را ایجاد کند. اگر کاربری که تحت آن اتصال برقرار شده است، حقوق کافی برای این عمل نداشته باشد، کانکتور با خطا خارج می شود.-
transformsدقیقاً نحوه تغییر نام موضوع مورد نظر را تعیین می کند:-
transforms.AddPrefix.typeنشان می دهد که ما از عبارات منظم استفاده خواهیم کرد. -
transforms.AddPrefix.regex- ماسکی که با آن نام موضوع مورد نظر دوباره تعریف می شود. -
transforms.AddPrefix.replacement- مستقیماً آنچه را که دوباره تعریف می کنیم.
-
بیشتر در مورد ضربان قلب و دگرگونی ها
به طور پیشفرض، رابط برای هر تراکنش متعهد، دادهها را به کافکا میفرستد و LSN (شماره توالی گزارش) خود را در موضوع سرویس مینویسد. offset. اما چه اتفاقی میافتد اگر کانکتور به گونهای پیکربندی شود که نه کل پایگاه داده، بلکه فقط بخشی از جداول آن را بخواند (که در آن بهروزرسانی دادهها اغلب انجام نمیشود)؟
- رابط فایلهای WAL را میخواند و تعهدات تراکنشهای موجود در آنها را به جداولی که نظارت میکند شناسایی نمیکند.
- بنابراین، موقعیت فعلی خود را نه در موضوع و نه در شکاف تکرار به روز نمی کند.
- این به نوبه خود باعث میشود که فایلهای WAL روی دیسک گیر کرده و احتمالاً فضای دیسک تمام شود.
و در اینجا گزینه ها به کمک می آیند. heartbeat.interval.ms и heartbeat.action.query. استفاده از این گزینه ها به صورت جفتی امکان انجام درخواست تغییر داده ها را در یک جدول جداگانه در هر بار ارسال پیام ضربان قلب فراهم می کند. بنابراین، LSN که کانکتور در حال حاضر روی آن قرار دارد (در شکاف تکرار) به طور مداوم به روز می شود. این به DBMS اجازه می دهد تا فایل های WAL را که دیگر مورد نیاز نیستند حذف کند. میتوانید درباره نحوه عملکرد گزینهها بیشتر بدانید .
گزینه دیگری که شایسته توجه بیشتر است transforms. اگرچه این بیشتر به راحتی و زیبایی است ...
به طور پیش فرض، Debezium موضوعات را با استفاده از خط مشی نامگذاری زیر ایجاد می کند: serverName.schemaName.tableName. این ممکن است همیشه راحت نباشد. گزینه ها transforms با استفاده از عبارات منظم، می توانید لیستی از جداول را تعریف کنید که رویدادها باید به موضوعی با نام خاصی هدایت شوند.
در پیکربندی ما با تشکر transforms موارد زیر اتفاق میافتد: همه رویدادهای CDC از پایگاه داده ردیابی شده به موضوعی با نام میروند data.cdc.dbname. در غیر این صورت (بدون این تنظیمات)، Debezium به طور پیش فرض یک موضوع برای هر جدول از فرم ایجاد می کند: pg-dev.public.<table_name>.
محدودیت های اتصال دهنده
برای پایان دادن به توضیح پیکربندی کانکتور برای PostgreSQL، لازم است در مورد ویژگی ها/محدودیت های عملکرد آن صحبت کنیم:
- عملکرد اتصال برای PostgreSQL بر مفهوم رمزگشایی منطقی متکی است. بنابراین او درخواست های تغییر ساختار پایگاه داده را ردیابی نمی کند (DDL) - بر این اساس، این داده ها در موضوعات وجود نخواهد داشت.
- از آنجایی که از اسلات های تکرار استفاده می شود، اتصال کانکتور امکان پذیر است تنها به نمونه اصلی DBMS.
- اگر کاربری که کانکتور تحت آن به پایگاه داده متصل می شود، حقوق فقط خواندنی دارد، قبل از اولین راه اندازی، باید به صورت دستی یک شکاف تکرار ایجاد کنید و در پایگاه داده منتشر کنید.
اعمال یک پیکربندی
بنابراین بیایید پیکربندی خود را در کانکتور بارگذاری کنیم:
curl -i -X POST -H "Accept:application/json"
-H "Content-Type:application/json" http://localhost:8083/connectors/
-d @pg-con.jsonبررسی می کنیم که دانلود با موفقیت انجام شده و رابط شروع شده است:
$ curl -i http://localhost:8083/connectors/pg-connector/status
HTTP/1.1 200 OK
Date: Thu, 17 Sep 2020 20:19:40 GMT
Content-Type: application/json
Content-Length: 175
Server: Jetty(9.4.20.v20190813)
{"name":"pg-connector","connector":{"state":"RUNNING","worker_id":"172.24.0.5:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"172.24.0.5:8083"}],"type":"source"}عالی: راه اندازی شده و آماده کار است. حالا بیایید وانمود کنیم که یک مصرف کننده هستیم و به کافکا متصل می شویم، پس از آن یک ورودی را در جدول اضافه و تغییر می دهیم:
$ kafka/bin/kafka-console-consumer.sh
--bootstrap-server kafka:9092
--from-beginning
--property print.key=true
--topic data.cdc.dbname
postgres=# insert into customers (id, first_name, last_name, email) values (1005, 'foo', 'bar', 'foo@bar.com');
INSERT 0 1
postgres=# update customers set first_name = 'egg' where id = 1005;
UPDATE 1در موضوع ما، این به صورت زیر نمایش داده می شود:
JSON بسیار طولانی با تغییرات ما
{
"schema":{
"type":"struct",
"fields":[
{
"type":"int32",
"optional":false,
"field":"id"
}
],
"optional":false,
"name":"data.cdc.dbname.Key"
},
"payload":{
"id":1005
}
}{
"schema":{
"type":"struct",
"fields":[
{
"type":"struct",
"fields":[
{
"type":"int32",
"optional":false,
"field":"id"
},
{
"type":"string",
"optional":false,
"field":"first_name"
},
{
"type":"string",
"optional":false,
"field":"last_name"
},
{
"type":"string",
"optional":false,
"field":"email"
}
],
"optional":true,
"name":"data.cdc.dbname.Value",
"field":"before"
},
{
"type":"struct",
"fields":[
{
"type":"int32",
"optional":false,
"field":"id"
},
{
"type":"string",
"optional":false,
"field":"first_name"
},
{
"type":"string",
"optional":false,
"field":"last_name"
},
{
"type":"string",
"optional":false,
"field":"email"
}
],
"optional":true,
"name":"data.cdc.dbname.Value",
"field":"after"
},
{
"type":"struct",
"fields":[
{
"type":"string",
"optional":false,
"field":"version"
},
{
"type":"string",
"optional":false,
"field":"connector"
},
{
"type":"string",
"optional":false,
"field":"name"
},
{
"type":"int64",
"optional":false,
"field":"ts_ms"
},
{
"type":"string",
"optional":true,
"name":"io.debezium.data.Enum",
"version":1,
"parameters":{
"allowed":"true,last,false"
},
"default":"false",
"field":"snapshot"
},
{
"type":"string",
"optional":false,
"field":"db"
},
{
"type":"string",
"optional":false,
"field":"schema"
},
{
"type":"string",
"optional":false,
"field":"table"
},
{
"type":"int64",
"optional":true,
"field":"txId"
},
{
"type":"int64",
"optional":true,
"field":"lsn"
},
{
"type":"int64",
"optional":true,
"field":"xmin"
}
],
"optional":false,
"name":"io.debezium.connector.postgresql.Source",
"field":"source"
},
{
"type":"string",
"optional":false,
"field":"op"
},
{
"type":"int64",
"optional":true,
"field":"ts_ms"
},
{
"type":"struct",
"fields":[
{
"type":"string",
"optional":false,
"field":"id"
},
{
"type":"int64",
"optional":false,
"field":"total_order"
},
{
"type":"int64",
"optional":false,
"field":"data_collection_order"
}
],
"optional":true,
"field":"transaction"
}
],
"optional":false,
"name":"data.cdc.dbname.Envelope"
},
"payload":{
"before":null,
"after":{
"id":1005,
"first_name":"foo",
"last_name":"bar",
"email":"foo@bar.com"
},
"source":{
"version":"1.2.3.Final",
"connector":"postgresql",
"name":"dbserver1",
"ts_ms":1600374991648,
"snapshot":"false",
"db":"postgres",
"schema":"public",
"table":"customers",
"txId":602,
"lsn":34088472,
"xmin":null
},
"op":"c",
"ts_ms":1600374991762,
"transaction":null
}
}{
"schema":{
"type":"struct",
"fields":[
{
"type":"int32",
"optional":false,
"field":"id"
}
],
"optional":false,
"name":"data.cdc.dbname.Key"
},
"payload":{
"id":1005
}
}{
"schema":{
"type":"struct",
"fields":[
{
"type":"struct",
"fields":[
{
"type":"int32",
"optional":false,
"field":"id"
},
{
"type":"string",
"optional":false,
"field":"first_name"
},
{
"type":"string",
"optional":false,
"field":"last_name"
},
{
"type":"string",
"optional":false,
"field":"email"
}
],
"optional":true,
"name":"data.cdc.dbname.Value",
"field":"before"
},
{
"type":"struct",
"fields":[
{
"type":"int32",
"optional":false,
"field":"id"
},
{
"type":"string",
"optional":false,
"field":"first_name"
},
{
"type":"string",
"optional":false,
"field":"last_name"
},
{
"type":"string",
"optional":false,
"field":"email"
}
],
"optional":true,
"name":"data.cdc.dbname.Value",
"field":"after"
},
{
"type":"struct",
"fields":[
{
"type":"string",
"optional":false,
"field":"version"
},
{
"type":"string",
"optional":false,
"field":"connector"
},
{
"type":"string",
"optional":false,
"field":"name"
},
{
"type":"int64",
"optional":false,
"field":"ts_ms"
},
{
"type":"string",
"optional":true,
"name":"io.debezium.data.Enum",
"version":1,
"parameters":{
"allowed":"true,last,false"
},
"default":"false",
"field":"snapshot"
},
{
"type":"string",
"optional":false,
"field":"db"
},
{
"type":"string",
"optional":false,
"field":"schema"
},
{
"type":"string",
"optional":false,
"field":"table"
},
{
"type":"int64",
"optional":true,
"field":"txId"
},
{
"type":"int64",
"optional":true,
"field":"lsn"
},
{
"type":"int64",
"optional":true,
"field":"xmin"
}
],
"optional":false,
"name":"io.debezium.connector.postgresql.Source",
"field":"source"
},
{
"type":"string",
"optional":false,
"field":"op"
},
{
"type":"int64",
"optional":true,
"field":"ts_ms"
},
{
"type":"struct",
"fields":[
{
"type":"string",
"optional":false,
"field":"id"
},
{
"type":"int64",
"optional":false,
"field":"total_order"
},
{
"type":"int64",
"optional":false,
"field":"data_collection_order"
}
],
"optional":true,
"field":"transaction"
}
],
"optional":false,
"name":"data.cdc.dbname.Envelope"
},
"payload":{
"before":{
"id":1005,
"first_name":"foo",
"last_name":"bar",
"email":"foo@bar.com"
},
"after":{
"id":1005,
"first_name":"egg",
"last_name":"bar",
"email":"foo@bar.com"
},
"source":{
"version":"1.2.3.Final",
"connector":"postgresql",
"name":"dbserver1",
"ts_ms":1600375609365,
"snapshot":"false",
"db":"postgres",
"schema":"public",
"table":"customers",
"txId":603,
"lsn":34089688,
"xmin":null
},
"op":"u",
"ts_ms":1600375609778,
"transaction":null
}
}در هر دو مورد، رکوردها شامل کلید (PK) رکوردی است که تغییر کرده است، و جوهر تغییرات: رکورد قبل و بعد از آن چیست.
- در مورد
INSERT: ارزش قبل از (before) برابر استnullو بعد از آن - خطی که درج شد. - در مورد
UPDATE: درpayload.beforeحالت قبلی ردیف نمایش داده می شود و درpayload.after- جدید با جوهر تغییر.
2.2 MongoDB
این کانکتور از مکانیزم تکرار استاندارد MongoDB استفاده می کند و اطلاعات را از oplog گره اولیه DBMS می خواند.
مشابه کانکتوری که قبلاً برای PgSQL توضیح داده شده است، در اینجا نیز در اولین شروع، عکس فوری داده اولیه گرفته می شود، پس از آن کانکتور به حالت خواندن آپلوگ سوئیچ می کند.
مثال پیکربندی:
{
"name": "mp-k8s-mongo-connector",
"config": {
"connector.class": "io.debezium.connector.mongodb.MongoDbConnector",
"tasks.max": "1",
"mongodb.hosts": "MainRepSet/mongo:27017",
"mongodb.name": "mongo",
"mongodb.user": "debezium",
"mongodb.password": "dbname",
"database.whitelist": "db_1,db_2",
"transforms": "AddPrefix",
"transforms.AddPrefix.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.AddPrefix.regex": "mongo.([a-zA-Z_0-9]*).([a-zA-Z_0-9]*)",
"transforms.AddPrefix.replacement": "data.cdc.mongo_$1"
}
}همانطور که می بینید، هیچ گزینه جدیدی نسبت به مثال قبلی وجود ندارد، بلکه تنها تعداد گزینه های مسئول اتصال به پایگاه داده و پیشوندهای آنها کاهش یافته است.
تنظیمات transforms این بار آنها کارهای زیر را انجام می دهند: نام موضوع مورد نظر را از طرح برگردانید <server_name>.<db_name>.<collection_name> в data.cdc.mongo_<db_name>.
تحمل خطا
مسئله تحمل خطا و در دسترس بودن بالا در زمان ما حادتر از همیشه است - به خصوص وقتی در مورد داده ها و تراکنش ها صحبت می کنیم و ردیابی تغییر داده ها در این مورد حاشیه ای نیست. بیایید نگاه کنیم که اصولاً چه چیزی ممکن است اشتباه باشد و در هر مورد چه اتفاقی برای Debezium خواهد افتاد.
سه گزینه انصراف وجود دارد:
- شکست کافکا کانکت. اگر Connect برای کار در حالت توزیع پیکربندی شده باشد، این به چندین کارگر نیاز دارد تا گروه.id یکسان را تنظیم کنند. سپس، اگر یکی از آنها خراب شود، کانکتور روی کارگر دیگر مجددا راه اندازی می شود و از آخرین موقعیت متعهد در موضوع در کافکا به خواندن ادامه می دهد.
- از دست دادن ارتباط با خوشه کافکا. رابط به سادگی خواندن را در موقعیتی که نتوانست به کافکا ارسال کند متوقف می کند و به طور دوره ای سعی می کند آن را دوباره ارسال کند تا زمانی که تلاش با موفقیت انجام شود.
- منبع داده در دسترس نیست. کانکتور تلاش می کند تا همانطور که پیکربندی شده است دوباره به منبع متصل شود. پیش فرض 16 تلاش برای استفاده است . پس از شانزدهمین تلاش ناموفق، کار به عنوان علامت گذاری می شود ناموفق و باید به صورت دستی از طریق رابط Kafka Connect REST راه اندازی مجدد شود.
- در مورد PostgreSQL و داده ها از بین نخواهند رفت، زیرا استفاده از اسلاتهای تکرار از حذف فایلهای WAL که توسط کانکتور خوانده نمیشوند جلوگیری میکند. در این مورد، یک نقطه منفی نیز برای سکه وجود دارد: اگر اتصال شبکه بین کانکتور و DBMS برای مدت طولانی مختل شود، این احتمال وجود دارد که فضای دیسک تمام شود و این می تواند منجر به خرابی شود. کل DBMS
- در مورد خروجی فایل های binlog را می توان قبل از بازیابی اتصال توسط خود DBMS چرخاند. این باعث میشود که کانکتور به حالت ناموفق برود و برای بازگرداندن عملکرد عادی، باید در حالت اولیه عکس فوری راهاندازی مجدد کنید تا به خواندن از binlog ادامه دهید.
- بر MongoDB. در مستندات آمده است: رفتار کانکتور در صورتی که فایل های log/oplog حذف شده باشند و کانکتور نتواند به خواندن از جایی که متوقف شده است، برای همه DBMS ها یکسان است. به این معنی است که کانکتور وارد حالت می شود ناموفق و نیاز به راه اندازی مجدد در حالت دارد عکس فوری اولیه.
با این حال، استثناهایی وجود دارد. اگر اتصال برای مدت طولانی قطع شده باشد (یا نتواند به نمونه MongoDB برسد)، و oplog در این مدت چرخش داشته باشد، پس از بازیابی اتصال، کانکتور با آرامش به خواندن داده ها از اولین موقعیت موجود ادامه می دهد. به همین دلیل است که برخی از داده های کافکا هیچ ضربه خواهد زد.
نتیجه
Debezium اولین تجربه من با سیستم های CDC است و در کل بسیار مثبت بوده است. این پروژه به پشتیبانی از DBMS اصلی، سهولت پیکربندی، پشتیبانی از خوشه بندی و یک جامعه فعال رشوه داد. برای کسانی که علاقه مند به تمرین هستند، توصیه می کنم که راهنمای آن را مطالعه کنند и .
در مقایسه با کانکتور JDBC برای Kafka Connect، مزیت اصلی Debezium این است که تغییرات از لاگ های DBMS خوانده می شود، که اجازه می دهد تا داده ها با حداقل تاخیر دریافت شوند. رابط JDBC (ارائه شده توسط کافکا کانکت) جدول ردیابی شده را در یک بازه زمانی ثابت پرس و جو می کند و (به همین دلیل) هنگام حذف داده ها پیامی تولید نمی کند (چگونه می توانید داده هایی را که در آنجا نیستند جستجو کنید؟).
برای حل مشکلات مشابه می توانید به راه حل های زیر (علاوه بر Debezium) توجه کنید:
- چند راه حل فقط برای MySQL:
- ، اما این یک "رده وزن" کاملاً متفاوت است.
PS
در وبلاگ ما نیز بخوانید:
- «"؛
- «"؛
- «'.
منبع: www.habr.com
