

به تازگی منتشر شده است ، که روند خوبی را در یادگیری ماشین در سال های اخیر نشان می دهد. به طور خلاصه: تعداد استارت آپ های یادگیری ماشینی در دو سال گذشته به شدت کاهش یافته است.
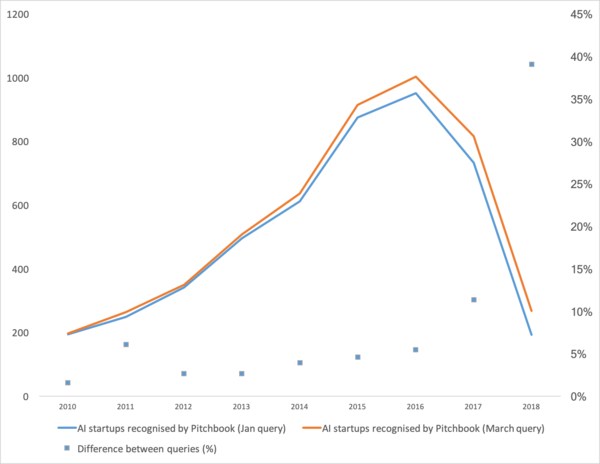
خوب. بیایید به «آیا حباب ترکیده است»، «چگونه به زندگی ادامه دهیم» نگاهی بیاندازیم و در وهله اول در مورد اینکه این خرخر از کجا می آید صحبت کنیم.
ابتدا اجازه دهید در مورد تقویت کننده این منحنی صحبت کنیم. او اهل کجاست؟ آنها احتمالاً همه چیز را به خاطر خواهند آورد یادگیری ماشین در سال 2012 در مسابقه ImageNet. بالاخره این اولین رویداد جهانی است! اما در واقعیت اینطور نیست. و رشد منحنی کمی زودتر شروع می شود. من آن را به چند نکته تقسیم می کنم.
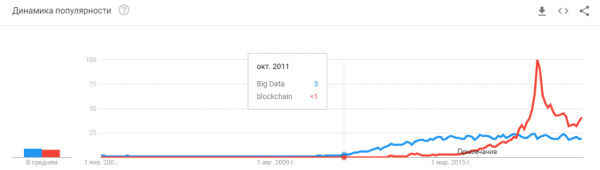
- در سال 2008 اصطلاح "داده های بزرگ" به وجود آمد. محصولات واقعی شروع شد از 2010. کلان داده مستقیماً با یادگیری ماشینی مرتبط است. بدون کلان داده، عملکرد پایدار الگوریتم هایی که در آن زمان وجود داشتند غیرممکن است. و اینها شبکه های عصبی نیستند. تا سال 2012، شبکه های عصبی متعلق به یک اقلیت حاشیه ای بودند. اما سپس الگوریتم های کاملاً متفاوتی شروع به کار کردند که سال ها یا حتی دهه ها وجود داشتند: (1963,1993) (1995) (2003)،... استارتآپهای آن سالها عمدتاً با پردازش خودکار دادههای ساختیافته مرتبط هستند: صندوقهای پول، کاربران، تبلیغات و موارد دیگر.
مشتق این موج اول مجموعه ای از فریم ورک ها مانند XGBoost، CatBoost، LightGBM و غیره است.
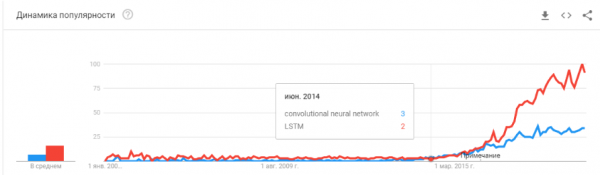
- در سال 2011-2012 برنده تعدادی از مسابقات تشخیص تصویر شد. استفاده واقعی از آنها تا حدودی به تعویق افتاد. میتوانم بگویم که استارتآپها و راهحلهای بسیار معنادار در سال ۲۰۱۴ ظاهر شدند. دو سال طول کشید تا هضم نورونها هنوز کار کند، ایجاد چارچوبهای مناسبی که میتوان آن را در زمان معقولی نصب و راهاندازی کرد، و روشهایی را توسعه داد که زمان همگرایی را تثبیت و سرعت بخشد.
شبکه های کانولوشن حل مشکلات بینایی کامپیوتری را امکان پذیر کردند: طبقه بندی تصاویر و اشیاء در تصویر، تشخیص اشیا، تشخیص اشیا و افراد، بهبود تصویر و غیره و غیره.
- 2015-2017. رونق الگوریتم ها و پروژه های مبتنی بر شبکه های تکراری یا مشابه آنها (LSTM، GRU، TransformerNet و غیره). الگوریتمهای گفتار به متن و سیستمهای ترجمه ماشینی با عملکرد خوب ظاهر شدهاند. آنها تا حدی بر اساس شبکه های کانولوشن برای استخراج ویژگی های اساسی هستند. تا حدی به دلیل این واقعیت است که ما یاد گرفتیم مجموعه داده های بسیار بزرگ و خوبی را جمع آوری کنیم.
«آیا حباب ترکیده است؟ آیا تبلیغات بیش از حد گرم شده است؟ آیا آنها به عنوان یک بلاک چین مردند؟»
در غیر این صورت! فردا سیری روی تلفن شما کار نخواهد کرد و پس فردا تسلا تفاوت بین چرخش و کانگورو را نمی داند.
شبکه های عصبی در حال حاضر کار می کنند. آنها در ده ها دستگاه هستند. آنها واقعاً به شما اجازه می دهند که درآمد کسب کنید، بازار و دنیای اطراف خود را تغییر دهید. هایپ کمی متفاوت به نظر می رسد:
فقط این است که شبکه های عصبی دیگر چیز جدیدی نیستند. بله، بسیاری از مردم انتظارات زیادی دارند. اما تعداد زیادی از شرکتها یاد گرفتهاند که از نورونها استفاده کنند و بر اساس آنها محصولات بسازند. نورون ها عملکرد جدیدی را ارائه می دهند، به شما امکان می دهند مشاغل را کاهش دهید و قیمت خدمات را کاهش دهید:
- شرکت های تولیدی در حال ادغام الگوریتم هایی برای تجزیه و تحلیل عیوب در خط تولید هستند.
- دامداری ها سیستم هایی را برای کنترل گاو می خرند.
- ترکیبات اتوماتیک
- مراکز تماس خودکار
- فیلترها در اسنپ چت (خب، حداقل یک چیز مفید!)
اما نکته اصلی و نه بدیهی ترین چیز: "دیگر ایده های جدیدی وجود ندارد یا آنها سرمایه فوری را به ارمغان نمی آورند." شبکه های عصبی ده ها مشکل را حل کرده اند. و حتی بیشتر تصمیم خواهند گرفت. همه ایدههای واضحی که وجود داشت باعث ایجاد استارتاپهای بسیاری شد. اما هر آنچه در سطح بود قبلاً جمع آوری شده بود. در طول دو سال گذشته، من با یک ایده جدید برای استفاده از شبکه های عصبی مواجه نشده ام. نه یک رویکرد جدید (خوب، خوب، چند مشکل با GAN ها وجود دارد).
و هر راه اندازی بعدی پیچیده تر و پیچیده تر است. دیگر نیازی به دو نفر نیست که یک نورون را با استفاده از داده های باز آموزش دهند. به برنامه نویسان، سرور، تیمی از نشانگرها، پشتیبانی پیچیده و غیره نیاز دارد.
در نتیجه استارتاپ های کمتری وجود دارند. اما تولید بیشتر است. آیا نیاز به اضافه کردن تشخیص پلاک دارید؟ صدها متخصص با تجربه مرتبط در بازار وجود دارد. شما می توانید فردی را استخدام کنید و ظرف چند ماه کارمند شما سیستم را ایجاد می کند. یا آماده خرید کنید. اما انجام یک استارت آپ جدید؟.. دیوانه!
شما باید یک سیستم ردیابی بازدیدکننده ایجاد کنید - چرا باید برای یکسری مجوزها بپردازید در حالی که می توانید در عرض 3-4 ماه مجوزهای خود را بسازید و آن را برای کسب و کار خود تیز کنید.
اکنون شبکه های عصبی همان مسیری را طی می کنند که ده ها فناوری دیگر طی کرده اند.
آیا به یاد دارید که چگونه مفهوم "توسعه دهنده وب سایت" از سال 1995 تغییر کرده است؟ بازار هنوز از متخصصان اشباع نشده است. تعداد بسیار کمی از افراد حرفه ای وجود دارد. اما می توانم شرط ببندم که در 5-10 سال دیگر تفاوت زیادی بین یک برنامه نویس جاوا و یک توسعه دهنده شبکه عصبی وجود نخواهد داشت. به اندازه کافی از هر دو متخصص در بازار وجود خواهد داشت.
به سادگی یک دسته از مشکلات وجود خواهد داشت که می توانند توسط نورون ها حل شوند. وظیفه ای به وجود آمده است - یک متخصص استخدام کنید.
"بعدش چی؟ هوش مصنوعی موعود کجاست؟»
اما اینجا یک سوء تفاهم کوچک اما جالب وجود دارد :)
پشته فناوری که امروزه وجود دارد، ظاهراً ما را به سمت هوش مصنوعی نمیبرد. ایده ها و تازگی آنها تا حد زیادی خود را فرسوده کرده است. بیایید در مورد آنچه که سطح فعلی توسعه را نگه می دارد صحبت کنیم.
محدودیت
بیایید با خودروهای خودران شروع کنیم. به نظر واضح است که ساخت خودروهای کاملاً خودمختار با فناوری امروزی امکان پذیر است. اما اینکه چند سال دیگر این اتفاق خواهد افتاد، مشخص نیست. تسلا معتقد است که این اتفاق در چند سال آینده رخ خواهد داد -

بسیاری دیگر وجود دارد ، که آن را 5-10 سال تخمین می زنند.
به احتمال زیاد به نظر من تا 15 سال دیگر زیرساخت شهرها خود به گونه ای تغییر خواهد کرد که ظهور خودروهای خودران اجتناب ناپذیر خواهد شد و به تداوم آن تبدیل خواهد شد. اما این را نمی توان هوشمندی دانست. تسلا مدرن یک خط لوله بسیار پیچیده برای فیلتر کردن داده ها، جستجو و بازآموزی است. اینها قوانین-قوانین-قوانین، جمع آوری داده ها و فیلترهای روی آنها هستند (اینجا من کمی بیشتر در این مورد نوشتم یا از آن تماشا کنید علائم).
اولین مشکل
و اینجاست که ما می بینیم اولین مشکل اساسی. اطلاعات بزرگ. این دقیقا همان چیزی است که موج کنونی شبکه های عصبی و یادگیری ماشین را به وجود آورد. امروزه برای انجام کاری پیچیده و خودکار به داده های زیادی نیاز دارید. نه فقط زیاد، بلکه خیلی خیلی زیاد. ما برای جمع آوری، علامت گذاری و استفاده از آنها به الگوریتم های خودکار نیاز داریم. ما می خواهیم کاری کنیم که ماشین کامیون های رو به خورشید را ببیند - ابتدا باید تعداد کافی از آنها را جمع آوری کنیم. ما می خواهیم با دوچرخه ای که در صندوق عقب پیچ شده است، ماشین دیوانه نشود - نمونه های بیشتر.
علاوه بر این، یک مثال کافی نیست. صدها؟ هزاران؟

مشکل دوم
مشکل دوم - تجسم آنچه شبکه عصبی ما درک کرده است. این یک کار بسیار بی اهمیت است. تا به حال، تعداد کمی از مردم می دانند که چگونه این را تجسم کنند. این مقالات بسیار جدید هستند، اینها فقط چند نمونه هستند، حتی اگر دور باشند:
وسواس با بافت ها به خوبی نشان می دهد که نورون تمایل دارد روی چه چیزی تثبیت کند + آنچه را که به عنوان اطلاعات شروع درک می کند.

توجه در . در واقع، جاذبه اغلب میتواند دقیقاً برای نشان دادن آنچه باعث چنین واکنش شبکهای شده است مورد استفاده قرار گیرد. من چنین چیزهایی را هم برای رفع اشکال و هم برای راه حل های محصول دیده ام. مقالات زیادی در این زمینه وجود دارد. اما هرچه دادهها پیچیدهتر باشند، درک چگونگی دستیابی به تجسم قوی دشوارتر است.

خوب، بله، مجموعه خوب قدیمی «ببین چه چیزی در داخل مش است " این تصاویر 3-4 سال پیش محبوب بودند، اما همه به سرعت متوجه شدند که این تصاویر زیبا هستند، اما معنای زیادی ندارند.
من به دهها ابزار دیگر، روشها، هکها، تحقیقات در مورد نحوه نمایش قسمتهای داخلی شبکه اشاره نکردم. آیا این ابزارها کار می کنند؟ آیا آنها به شما کمک می کنند تا به سرعت بفهمید مشکل چیست و شبکه را اشکال زدایی کنید؟.. آخرین درصد را دریافت کنید؟ خب تقریبا همینطوره:

شما می توانید هر مسابقه ای را در Kaggle تماشا کنید. و شرح نحوه تصمیم گیری نهایی افراد. ما 100-500-800 واحد از مدل ها را روی هم گذاشتیم و کار کرد!
البته دارم اغراق می کنم. اما این رویکردها پاسخ های سریع و مستقیمی را ارائه نمی دهند.
با داشتن تجربه کافی، با بررسی گزینه های مختلف، می توانید در مورد اینکه چرا سیستم شما چنین تصمیمی گرفته است، تصمیم بگیرید. اما اصلاح رفتار سیستم دشوار خواهد بود. یک عصا نصب کنید، آستانه را حرکت دهید، یک مجموعه داده اضافه کنید، یک شبکه باطن دیگری بگیرید.
مشکل سوم
سومین مشکل اساسی - شبکه ها آمار را آموزش می دهند، نه منطق. از نظر آماری این :

منطقاً خیلی شبیه نیست. شبکه های عصبی هیچ چیز پیچیده ای را نمی آموزند مگر اینکه مجبور شوند. آنها همیشه ساده ترین نشانه های ممکن را آموزش می دهند. چشم، بینی، سر داری؟ پس این صورت است! یا مثالی بزنید که چشم به معنای صورت نیست. و دوباره - میلیون ها نمونه.
فضای زیادی در پایین وجود دارد
من می گویم که این سه مشکل جهانی است که در حال حاضر توسعه شبکه های عصبی و یادگیری ماشین را محدود می کند. و در جایی که این مشکلات آن را محدود نکرد، قبلاً به طور فعال استفاده می شود.
این آخرشه؟ آیا شبکه های عصبی فعال هستند؟
ناشناخته. اما، البته، همه امیدوار نیستند.
رویکردها و مسیرهای زیادی برای حل مشکلات اساسی وجود دارد که در بالا به آنها اشاره کردم. اما تاکنون هیچ یک از این رویکردها امکان انجام کاری اساساً جدید را فراهم نکرده است، برای حل چیزی که هنوز حل نشده است. تا کنون، تمام پروژه های اساسی بر اساس رویکردهای پایدار (تسلا) انجام می شود، یا پروژه های آزمایشی موسسات یا شرکت ها (Google Brain، OpenAI) باقی می مانند.
به طور کلی، جهت اصلی ایجاد برخی نمایشهای سطح بالا از دادههای ورودی است. به یک معنا "حافظه". سادهترین مثال از حافظه، «جاسازی» مختلف است - نمایش تصویر. خوب، برای مثال، تمام سیستم های تشخیص چهره. شبکه یاد میگیرد که از یک چهره، بازنمایی پایداری به دست آورد که به چرخش، روشنایی یا وضوح بستگی ندارد. اساساً، شبکه متریک "چهره های مختلف دور هستند" و "چهره های یکسان نزدیک هستند" را به حداقل می رساند.
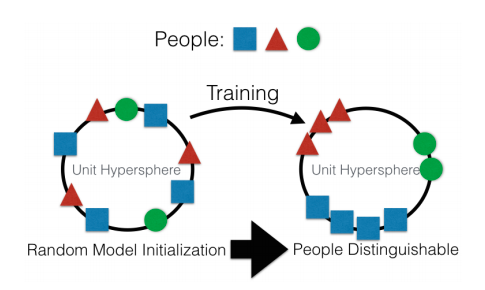
برای چنین آموزش هایی به ده ها و صدها هزار نمونه نیاز است. اما نتیجه شامل برخی از اصول اولیه «یادگیری یک شات» است. حالا ما برای به یاد آوردن یک نفر به صدها چهره نیاز نداریم. فقط یک چهره و این تمام چیزی است که ما هستیم !
فقط یک مشکل وجود دارد... شبکه فقط می تواند اشیاء نسبتاً ساده را یاد بگیرد. هنگامی که سعی می کنید چهره ها را تشخیص دهید، بلکه، به عنوان مثال، "افراد بر اساس لباس" (وظیفه ) - کیفیت با مرتبه های بزرگی کاهش می یابد. و شبکه دیگر نمی تواند تغییرات نسبتاً واضح در زوایای را یاد بگیرد.
و یادگیری از میلیون ها مثال نیز به نوعی سرگرم کننده است.
کار برای کاهش چشمگیر انتخابات وجود دارد. به عنوان مثال، می توان بلافاصله یکی از اولین آثار را به یاد آورد آموزش وان شات :
مثلاً از این دست آثار زیاد است یا یا .
تنها یک منفی وجود دارد - معمولاً آموزش در برخی از نمونه های ساده "MNIST" به خوبی کار می کند. و هنگام حرکت به سمت کارهای پیچیده، به یک پایگاه داده بزرگ، مدلی از اشیا یا نوعی جادو نیاز دارید.
به طور کلی کار روی آموزش تک شات موضوع بسیار جالبی است. شما ایده های زیادی پیدا می کنید. اما در بیشتر موارد، دو مشکلی که من فهرست کردم (پیشآموزش در یک مجموعه داده عظیم / بی ثباتی در داده های پیچیده) تا حد زیادی در یادگیری اختلال ایجاد می کند.
از سوی دیگر، GAN ها – شبکه های متخاصم مولد – به موضوع Embedding می پردازند. احتمالاً تعداد زیادی مقاله در مورد هابره در این زمینه خوانده اید. (, ,)
یکی از ویژگی های GAN تشکیل یک فضای حالت داخلی (در اصل همان Embedding) است که به شما امکان می دهد یک تصویر بکشید. میتونه باشه ، می تواند باشد .
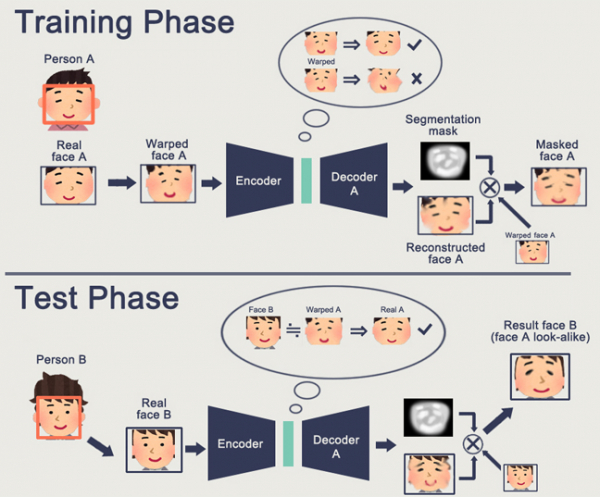
مشکل GAN این است که هر چه شیء تولید شده پیچیده تر باشد، توصیف آن در منطق «تبعیض کننده-مولد» دشوارتر است. در نتیجه، تنها برنامههای واقعی GAN که در مورد آن شنیده میشود، DeepFake است، که باز هم نمایشهای صورت را دستکاری میکند (که پایگاه عظیمی برای آن وجود دارد).
من استفاده های مفید دیگر بسیار کمی را دیده ام. معمولاً نوعی حیله که شامل تکمیل نقشه های تصاویر می شود.
و دوباره. هیچ کس نمی داند که چگونه این به ما اجازه می دهد به آینده ای روشن تر حرکت کنیم. نمایش منطق/فضا در یک شبکه عصبی خوب است. اما ما به تعداد زیادی مثال نیاز داریم، نمیدانیم نورون چگونه این را به خودی خود نشان میدهد، نمیدانیم چگونه نورون را وادار کنیم ایدهای واقعا پیچیده را به خاطر بسپارد.
تقویت یادگیری - این رویکردی از جهتی کاملا متفاوت است. مطمئناً به یاد دارید که چگونه گوگل در Go همه را شکست داد. پیروزی های اخیر در Starcraft و Dota. اما اینجا همه چیز از آنقدر خوشگل و امیدوارکننده دور است. او بهترین صحبت را در مورد RL و پیچیدگی های آن دارد .
به اختصار آنچه نویسنده نوشته است را بیان کنم:
- مدل های خارج از جعبه مناسب نیستند / در بیشتر موارد ضعیف کار می کنند
- حل مسائل عملی از راه های دیگر آسان تر است. Boston Dynamics به دلیل پیچیدگی/غیرقابل پیش بینی بودن/پیچیدگی محاسباتی از RL استفاده نمی کند
- برای اینکه RL کار کند، به یک تابع پیچیده نیاز دارید. ایجاد/نوشتن اغلب دشوار است
- آموزش مدل ها مشکل است. شما باید زمان زیادی را صرف کنید تا پمپاژ کنید و از بهینه محلی خارج شوید
- در نتیجه تکرار مدل مشکل است، مدل با کوچکترین تغییرات ناپایدار است
- اغلب با برخی از الگوهای تصادفی، حتی یک مولد اعداد تصادفی، بیش از حد مناسب است
نکته کلیدی این است که RL هنوز در تولید کار نمی کند. گوگل چند آزمایش دارد ( , ). اما من یک سیستم محصول واحد ندیدم.
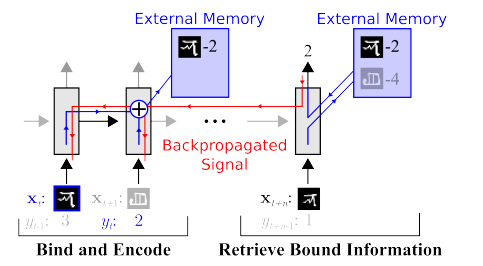
حافظه. نقطه ضعف همه چیزهایی که در بالا توضیح داده شد، عدم ساختار است. یکی از روشهایی که میخواهیم همه اینها را مرتب کنیم، فراهم کردن دسترسی شبکه عصبی به حافظه جداگانه است. تا بتواند نتایج گام هایش را در آنجا ثبت و بازنویسی کند. سپس شبکه عصبی را می توان با وضعیت حافظه فعلی تعیین کرد. این بسیار شبیه به پردازنده ها و کامپیوترهای کلاسیک است.
معروف ترین و محبوب ترین - از DeepMind:
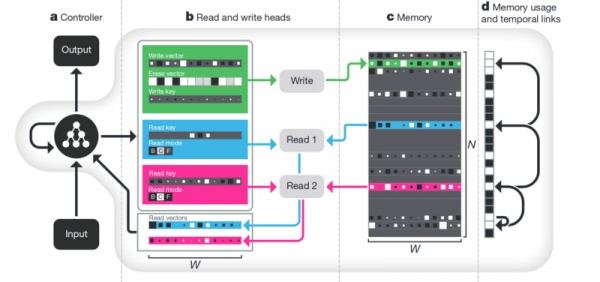
به نظر می رسد که این کلید درک هوش است؟ اما احتمالا نه. این سیستم هنوز به مقدار زیادی داده برای آموزش نیاز دارد. و عمدتاً با داده های جدولی ساخت یافته کار می کند. علاوه بر این، هنگامی که فیس بوک یک مشکل مشابه، سپس آنها مسیر "حافظه را خراب کنید، فقط نورون را پیچیده تر کنید، و نمونه های بیشتری داشته باشید - و خود به خود یاد خواهد گرفت."
گره گشایی. راه دیگر برای ایجاد یک حافظه معنادار، استفاده از همان جاسازیها است، اما در طول آموزش، معیارهای دیگری را معرفی کنید که به شما امکان میدهد «معانی» را در آنها برجسته کنید. به عنوان مثال، ما می خواهیم یک شبکه عصبی را برای تمایز بین رفتار انسان در یک فروشگاه آموزش دهیم. اگر مسیر استاندارد را دنبال میکردیم، باید یک دوجین شبکه بسازیم. یکی به دنبال یک شخص است، دوم تعیین اینکه چه کار می کند، سوم سن او است، چهارم جنسیت اوست. منطق جداگانه به بخشی از فروشگاه نگاه می کند که در آن این کار را انجام می دهد / آموزش دیده است. سوم مسیر آن را تعیین می کند و غیره.
یا اگر تعداد نامتناهی داده وجود داشت، میتوان یک شبکه را برای همه نتایج ممکن آموزش داد (بدیهی است که چنین آرایهای از دادهها را نمیتوان جمعآوری کرد).
رویکرد تفکیک به ما می گوید - بیایید شبکه را طوری آموزش دهیم که خودش بتواند بین مفاهیم تمایز قائل شود. به طوری که بر اساس ویدئو یک جاسازی تشکیل میدهد، جایی که یک ناحیه عمل را تعیین میکند، یکی موقعیت روی زمین را به موقع، یکی قد فرد را تعیین میکند و یکی جنسیت فرد را تعیین میکند. در همان زمان، هنگام آموزش، من می خواهم تقریباً شبکه را با چنین مفاهیم کلیدی ترغیب نکنم، بلکه بیشتر آن را برجسته و گروه بندی کنم. تعداد بسیار کمی از این مقالات وجود دارد (بعضی از آنها , , ) و به طور کلی کاملاً نظری هستند.
اما این جهت، حداقل به لحاظ نظری، باید مشکلات ذکر شده در ابتدا را پوشش دهد.
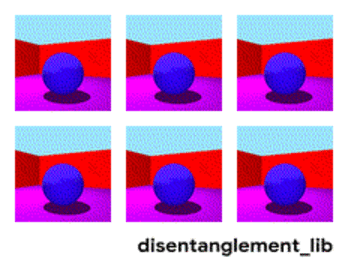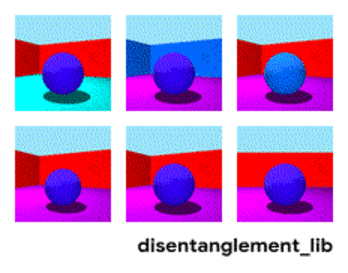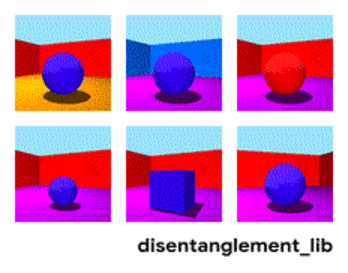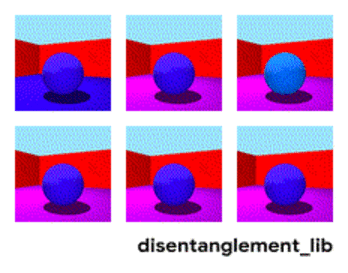
تجزیه تصویر با توجه به پارامترهای "رنگ دیوار / رنگ کف / شکل شی / رنگ شی / غیره."

تجزیه صورت با توجه به پارامترهای "اندازه، ابرو، جهت، رنگ پوست و غیره".
دیگر
بسیاری از مناطق دیگر، نه چندان جهانی، وجود دارند که به شما امکان می دهند به نحوی پایگاه داده را کاهش دهید، با داده های ناهمگن تر کار کنید و غیره.
توجه. احتمالاً منطقی نیست که این را به عنوان یک روش جداگانه جدا کنیم. فقط رویکردی که دیگران را تقویت می کند. مقالات زیادی به او تقدیم شده است (,,). نکته قابل توجه افزایش پاسخ شبکه به طور خاص به اشیاء مهم در طول آموزش است. اغلب با نوعی تعیین هدف خارجی یا یک شبکه خارجی کوچک.
شبیه سازی سه بعدی. اگر یک موتور سه بعدی خوب بسازید، اغلب می توانید 3 درصد از داده های آموزشی را با آن پوشش دهید (حتی نمونه ای دیدم که تقریباً 90 درصد داده ها توسط یک موتور خوب پوشش داده شده است). ایدهها و هکهای زیادی در مورد نحوه ایجاد یک شبکه آموزشدیده بر روی موتور سه بعدی با استفاده از دادههای واقعی (تنظیم دقیق، انتقال سبک و غیره) وجود دارد. اما اغلب ساختن یک موتور خوب چندین مرتبه دشوارتر از جمع آوری داده است. نمونه هایی از زمان ساخت موتورها:
آموزش ربات (, )
پرورش کالاهای موجود در فروشگاه (اما در دو پروژه ای که انجام دادیم، به راحتی می توانستیم بدون آن کار کنیم).
آموزش در تسلا (دوباره، ویدیوی بالا).
یافته ها
کل مقاله به نوعی نتیجه گیری است. احتمالاً پیام اصلی که میخواستم بگویم این بود که «مجازات به پایان رسید، نورونها دیگر راهحلهای ساده ارائه نمیدهند». حالا باید سخت کار کنیم تا تصمیمات پیچیده بگیریم. یا برای انجام تحقیقات علمی پیچیده سخت کار کنید.
در کل موضوع قابل بحث است. شاید خوانندگان نمونه های جالب تری داشته باشند؟
منبع: www.habr.com
