

در این مقاله چندین روش برای تعیین معادله ریاضی یک خط رگرسیون ساده (جفتی) مورد بحث قرار می گیرد.
تمام روش های حل معادله مورد بحث در اینجا بر اساس روش حداقل مربعات است. بیایید روش ها را به صورت زیر مشخص کنیم:
- راه حل تحلیلی
- گرادیان نزول
- نزول گرادیان تصادفی
برای هر روش حل معادله یک خط مستقیم، مقاله توابع مختلفی را ارائه می دهد که عمدتاً به مواردی تقسیم می شوند که بدون استفاده از کتابخانه نوشته شده اند. NumPy و آنهایی که برای محاسبات استفاده می کنند NumPy. اعتقاد بر این است که استفاده ماهرانه NumPy هزینه های محاسباتی را کاهش خواهد داد.
تمام کدهای ارائه شده در مقاله به زبان نوشته شده است پایتون 2.7 با نوت بوک ژوپیتر. کد منبع و فایل با داده های نمونه در پست شده است
این مقاله بیشتر هم برای مبتدیان و هم برای کسانی است که به تدریج شروع به تسلط بر مطالعه یک بخش بسیار گسترده در هوش مصنوعی - یادگیری ماشینی کرده اند.
برای توضیح مطالب از یک مثال بسیار ساده استفاده می کنیم.
شرایط نمونه
ما پنج مقدار داریم که وابستگی را مشخص می کند Y از X (جدول شماره 1):
جدول شماره 1 "شرایط نمونه"

ما فرض می کنیم که مقادیر  ماه سال است و
ماه سال است و  - درآمد این ماه به عبارت دیگر درآمد بستگی به ماه سال دارد و
- درآمد این ماه به عبارت دیگر درآمد بستگی به ماه سال دارد و  - تنها علامتی که درآمد به آن بستگی دارد.
- تنها علامتی که درآمد به آن بستگی دارد.
مثال چنین است، هم از نظر وابستگی مشروط درآمد به ماه سال و هم از نظر تعداد مقادیر - تعداد بسیار کمی از آنها وجود دارد. با این حال، چنین ساده سازی، همانطور که می گویند، توضیح دادن، نه همیشه به راحتی، مطالبی را که مبتدیان جذب می کنند، ممکن می سازد. و همچنین سادگی اعداد به کسانی که می خواهند نمونه را روی کاغذ بدون هزینه کار قابل توجه حل کنند، اجازه می دهد.
اجازه دهید فرض کنیم که وابستگی ارائه شده در مثال را می توان به خوبی با معادله ریاضی یک خط رگرسیون ساده (جفتی) از شکل تقریب زد:

جایی که  ماهی است که در آن درآمد دریافت شده است،
ماهی است که در آن درآمد دریافت شده است،  - درآمد مربوط به ماه،
- درآمد مربوط به ماه،  и
и  ضرایب رگرسیون خط برآورد شده است.
ضرایب رگرسیون خط برآورد شده است.
توجه داشته باشید که ضریب  اغلب شیب یا شیب خط تخمینی نامیده می شود. نشان دهنده مقداری است که
اغلب شیب یا شیب خط تخمینی نامیده می شود. نشان دهنده مقداری است که  وقتی تغییر می کند
وقتی تغییر می کند  .
.
بدیهی است که وظیفه ما در مثال این است که چنین ضرایبی را در معادله انتخاب کنیم  и
и  ، که در آن انحرافات مقادیر درآمد محاسبه شده ما بر اساس ماه از پاسخ های واقعی، یعنی. مقادیر ارائه شده در نمونه حداقل خواهد بود.
، که در آن انحرافات مقادیر درآمد محاسبه شده ما بر اساس ماه از پاسخ های واقعی، یعنی. مقادیر ارائه شده در نمونه حداقل خواهد بود.
روش حداقل مربعات
با توجه به روش حداقل مربعات، انحراف باید با مجذور آن محاسبه شود. این تکنیک به شما امکان می دهد در صورت داشتن علائم مخالف از لغو متقابل انحرافات جلوگیری کنید. به عنوان مثال، اگر در یک مورد، انحراف است +5 (به علاوه پنج)، و در دیگری -5 (منهای پنج)، سپس مجموع انحرافات یکدیگر را خنثی کرده و به 0 (صفر) می رسد. می توان انحراف را مجذور نکرد، بلکه از خاصیت مدول استفاده کرد و سپس همه انحرافات مثبت شده و انباشته می شوند. ما در این مورد با جزئیات صحبت نمی کنیم، بلکه به سادگی نشان می دهیم که برای راحتی محاسبات، مرسوم است که انحراف را مربع کنیم.
این فرمولی است که با آن حداقل مجذور انحرافات (خطاها) را تعیین می کنیم:

جایی که  تابعی از تقریب پاسخ های واقعی است (یعنی درآمدی که ما محاسبه کردیم)
تابعی از تقریب پاسخ های واقعی است (یعنی درآمدی که ما محاسبه کردیم)
 پاسخ های واقعی هستند (درآمد ارائه شده در نمونه)،
پاسخ های واقعی هستند (درآمد ارائه شده در نمونه)،
 شاخص نمونه (تعداد ماهی که در آن انحراف تعیین می شود) است.
شاخص نمونه (تعداد ماهی که در آن انحراف تعیین می شود) است.
بیایید تابع را متمایز کنیم، معادلات دیفرانسیل جزئی را تعریف کنیم و آماده حرکت به سمت حل تحلیلی باشیم. اما ابتدا بیایید گشتی کوتاهی درباره تمایز داشته باشیم و معنای هندسی مشتق را به خاطر بسپاریم.
تفکیک
تمایز عملیات یافتن مشتق یک تابع است.
مشتق برای چه استفاده می شود؟ مشتق تابع سرعت تغییر تابع را مشخص می کند و جهت آن را به ما می گوید. اگر مشتق در یک نقطه معین مثبت باشد، تابع افزایش می یابد، در غیر این صورت، تابع کاهش می یابد. و هر چه مقدار مشتق مطلق بیشتر باشد، نرخ تغییر مقادیر تابع بیشتر می شود و همچنین شیب نمودار تابع بیشتر می شود.
برای مثال، در شرایط یک سیستم مختصات دکارتی، مقدار مشتق در نقطه M(0,0) برابر است با 25+ به این معنی است که در یک نقطه معین، زمانی که مقدار تغییر می کند  در سمت راست توسط یک واحد معمولی، مقدار
در سمت راست توسط یک واحد معمولی، مقدار  25 واحد معمولی افزایش می یابد. در نمودار به نظر می رسد افزایش نسبتاً شدیدی در مقادیر
25 واحد معمولی افزایش می یابد. در نمودار به نظر می رسد افزایش نسبتاً شدیدی در مقادیر  از یک نقطه معین
از یک نقطه معین
مثالی دیگر. مقدار مشتق برابر است -0,1 به این معنی است که وقتی جابجا می شود  به ازای هر واحد متعارف، ارزش
به ازای هر واحد متعارف، ارزش  تنها 0,1 واحد معمولی کاهش می یابد. در همان زمان، در نمودار تابع، میتوانیم شیب رو به پایین قابل توجهی را مشاهده کنیم. با تشبیه یک کوه، انگار خیلی آهسته از یک کوه از یک شیب ملایم پایین می آییم، بر خلاف مثال قبلی که مجبور بودیم از قله های بسیار شیب دار بالا برویم :)
تنها 0,1 واحد معمولی کاهش می یابد. در همان زمان، در نمودار تابع، میتوانیم شیب رو به پایین قابل توجهی را مشاهده کنیم. با تشبیه یک کوه، انگار خیلی آهسته از یک کوه از یک شیب ملایم پایین می آییم، بر خلاف مثال قبلی که مجبور بودیم از قله های بسیار شیب دار بالا برویم :)
بنابراین، پس از تمایز تابع  با شانس
با شانس  и
и  ، معادلات دیفرانسیل جزئی مرتبه 1 را تعریف می کنیم. پس از تعیین معادلات، سیستمی متشکل از دو معادله دریافت می کنیم که با حل آن می توانیم مقادیری از ضرایب را انتخاب کنیم.
، معادلات دیفرانسیل جزئی مرتبه 1 را تعریف می کنیم. پس از تعیین معادلات، سیستمی متشکل از دو معادله دریافت می کنیم که با حل آن می توانیم مقادیری از ضرایب را انتخاب کنیم.  и
и  ، که در آن مقادیر مشتقات مربوطه در نقاط داده شده به مقدار بسیار بسیار کمی تغییر می کند و در مورد حل تحلیلی اصلاً تغییر نمی کند. به عبارت دیگر، تابع خطا در ضرایب یافت شده به حداقل می رسد، زیرا مقادیر مشتقات جزئی در این نقاط برابر با صفر خواهد بود.
، که در آن مقادیر مشتقات مربوطه در نقاط داده شده به مقدار بسیار بسیار کمی تغییر می کند و در مورد حل تحلیلی اصلاً تغییر نمی کند. به عبارت دیگر، تابع خطا در ضرایب یافت شده به حداقل می رسد، زیرا مقادیر مشتقات جزئی در این نقاط برابر با صفر خواهد بود.
بنابراین، با توجه به قوانین تمایز، معادله مشتق جزئی مرتبه 1 نسبت به ضریب  شکل خواهد گرفت:
شکل خواهد گرفت:

معادله مشتق جزئی مرتبه 1 با توجه به  شکل خواهد گرفت:
شکل خواهد گرفت:

در نتیجه، سیستمی از معادلات را دریافت کردیم که یک راه حل تحلیلی نسبتاً ساده دارد:
شروع{معادله*}
شروع{موارد}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i - sumlimits_{i=1}^ny_i) = 0
پایان{موارد}
پایان{معادله*}
قبل از حل معادله، بیایید از قبل بارگذاری کنیم، بررسی کنیم که بارگذاری صحیح است و داده ها را قالب بندی کنیم.
بارگیری و قالب بندی داده ها
لازم به ذکر است که با توجه به اینکه برای حل تحلیلی و متعاقباً گرادیان و نزول گرادیان تصادفی، از کد در دو تغییر استفاده خواهیم کرد: استفاده از کتابخانه NumPy و بدون استفاده از آن، به قالب بندی داده های مناسب نیاز خواهیم داشت (به کد مراجعه کنید).
کد بارگیری و پردازش داده ها
# импортируем все нужные нам библиотеки
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
import pylab as pl
import random
# графики отобразим в Jupyter
%matplotlib inline
# укажем размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 12, 6
# отключим предупреждения Anaconda
import warnings
warnings.simplefilter('ignore')
# загрузим значения
table_zero = pd.read_csv('data_example.txt', header=0, sep='t')
# посмотрим информацию о таблице и на саму таблицу
print table_zero.info()
print '********************************************'
print table_zero
print '********************************************'
# подготовим данные без использования NumPy
x_us = []
[x_us.append(float(i)) for i in table_zero['x']]
print x_us
print type(x_us)
print '********************************************'
y_us = []
[y_us.append(float(i)) for i in table_zero['y']]
print y_us
print type(y_us)
print '********************************************'
# подготовим данные с использованием NumPy
x_np = table_zero[['x']].values
print x_np
print type(x_np)
print x_np.shape
print '********************************************'
y_np = table_zero[['y']].values
print y_np
print type(y_np)
print y_np.shape
print '********************************************'تجسم
حالا بعد از اینکه اولاً داده ها را بارگذاری کردیم، ثانیاً صحت بارگذاری را بررسی کردیم و در نهایت داده ها را قالب بندی کردیم، اولین تصویرسازی را انجام می دهیم. روشی که اغلب برای این مورد استفاده می شود طرح جفتی کتابخانه ها سیبرن. در مثال ما، به دلیل تعداد محدود، استفاده از کتابخانه فایده ای ندارد سیبرن. ما از کتابخانه معمولی استفاده خواهیم کرد matplotlib و فقط به نمودار پراکنده نگاه کنید.
کد پراکندگی
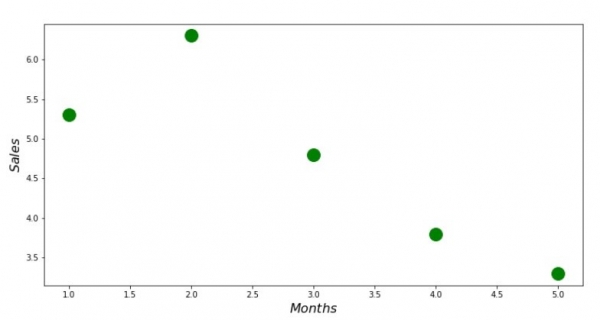
print 'График №1 "Зависимость выручки от месяца года"'
plt.plot(x_us,y_us,'o',color='green',markersize=16)
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.show()نمودار شماره 1 «وابستگی درآمد به ماه سال»
راه حل تحلیلی
بیایید از رایج ترین ابزارها استفاده کنیم پایتون و سیستم معادلات را حل کنید:
شروع{معادله*}
شروع{موارد}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i - sumlimits_{i=1}^ny_i) = 0
پایان{موارد}
پایان{معادله*}
طبق قانون کرامر ما تعیین کننده کلی و همچنین تعیین کننده ها را با  و
و  ، پس از آن، تقسیم بر
، پس از آن، تقسیم بر  به تعیین کننده کلی - ضریب را پیدا کنید
به تعیین کننده کلی - ضریب را پیدا کنید  ، به طور مشابه ضریب را پیدا می کنیم
، به طور مشابه ضریب را پیدا می کنیم  .
.
کد حل تحلیلی
# определим функцию для расчета коэффициентов a и b по правилу Крамера
def Kramer_method (x,y):
# сумма значений (все месяца)
sx = sum(x)
# сумма истинных ответов (выручка за весь период)
sy = sum(y)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x[i]*y[i]) for i in range(len(x))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x[i]**2) for i in range(len(x))]
sx_sq = sum(list_x_sq)
# количество значений
n = len(x)
# общий определитель
det = sx_sq*n - sx*sx
# определитель по a
det_a = sx_sq*sy - sx*sxy
# искомый параметр a
a = (det_a / det)
# определитель по b
det_b = sxy*n - sy*sx
# искомый параметр b
b = (det_b / det)
# контрольные значения (прооверка)
check1 = (n*b + a*sx - sy)
check2 = (b*sx + a*sx_sq - sxy)
return [round(a,4), round(b,4)]
# запустим функцию и запишем правильные ответы
ab_us = Kramer_method(x_us,y_us)
a_us = ab_us[0]
b_us = ab_us[1]
print ' 33[1m' + ' 33[4m' + "Оптимальные значения коэффициентов a и b:" + ' 33[0m'
print 'a =', a_us
print 'b =', b_us
print
# определим функцию для подсчета суммы квадратов ошибок
def errors_sq_Kramer_method(answers,x,y):
list_errors_sq = []
for i in range(len(x)):
err = (answers[0] + answers[1]*x[i] - y[i])**2
list_errors_sq.append(err)
return sum(list_errors_sq)
# запустим функцию и запишем значение ошибки
error_sq = errors_sq_Kramer_method(ab_us,x_us,y_us)
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений" + ' 33[0m'
print error_sq
print
# замерим время расчета
# print ' 33[1m' + ' 33[4m' + "Время выполнения расчета суммы квадратов отклонений:" + ' 33[0m'
# % timeit error_sq = errors_sq_Kramer_method(ab,x_us,y_us)این چیزی است که ما به دست آوردیم:

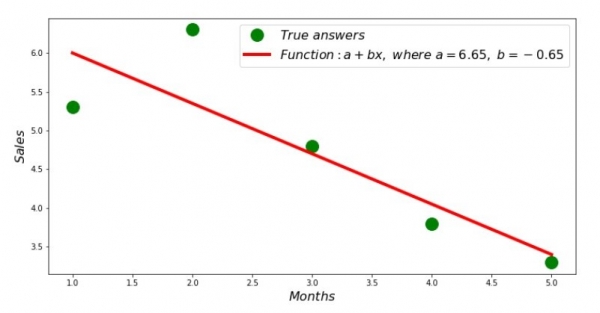
بنابراین، مقادیر ضرایب پیدا شده است، مجموع انحرافات مجذور ایجاد شده است. بیایید یک خط مستقیم بر روی هیستوگرام پراکندگی مطابق با ضرایب پیدا شده رسم کنیم.
کد خط رگرسیون
# определим функцию для формирования массива рассчетных значений выручки
def sales_count(ab,x,y):
line_answers = []
[line_answers.append(ab[0]+ab[1]*x[i]) for i in range(len(x))]
return line_answers
# построим графики
print 'Грфик№2 "Правильные и расчетные ответы"'
plt.plot(x_us,y_us,'o',color='green',markersize=16, label = '$True$ $answers$')
plt.plot(x_us, sales_count(ab_us,x_us,y_us), color='red',lw=4,
label='$Function: a + bx,$ $where$ $a='+str(round(ab_us[0],2))+',$ $b='+str(round(ab_us[1],2))+'$')
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.legend(loc=1, prop={'size': 16})
plt.show()نمودار شماره 2 «پاسخ های صحیح و حساب شده»
می توانید به نمودار انحراف برای هر ماه نگاه کنید. در مورد ما، ما هیچ ارزش عملی قابل توجهی از آن استخراج نخواهیم کرد، اما کنجکاوی خود را در مورد اینکه چگونه معادله رگرسیون خطی ساده وابستگی درآمد را به ماه سال مشخص می کند، ارضا می کنیم.
کد نمودار انحراف
# определим функцию для формирования массива отклонений в процентах
def error_per_month(ab,x,y):
sales_c = sales_count(ab,x,y)
errors_percent = []
for i in range(len(x)):
errors_percent.append(100*(sales_c[i]-y[i])/y[i])
return errors_percent
# построим график
print 'График№3 "Отклонения по-месячно, %"'
plt.gca().bar(x_us, error_per_month(ab_us,x_us,y_us), color='brown')
plt.xlabel('Months', size=16)
plt.ylabel('Calculation error, %', size=16)
plt.show()نمودار شماره 3 "انحرافات، ٪"
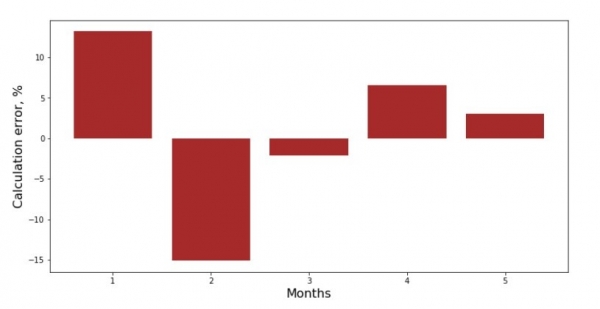
کامل نیست، اما ما وظیفه خود را انجام دادیم.
بیایید تابعی بنویسیم که برای تعیین ضرایب  и
и  از کتابخانه استفاده می کند NumPyبه طور دقیق تر، ما دو تابع می نویسیم: یکی با استفاده از یک ماتریس شبه معکوس (در عمل توصیه نمی شود، زیرا فرآیند از نظر محاسباتی پیچیده و ناپایدار است)، دیگری با استفاده از یک معادله ماتریس.
از کتابخانه استفاده می کند NumPyبه طور دقیق تر، ما دو تابع می نویسیم: یکی با استفاده از یک ماتریس شبه معکوس (در عمل توصیه نمی شود، زیرا فرآیند از نظر محاسباتی پیچیده و ناپایدار است)، دیگری با استفاده از یک معادله ماتریس.
کد حل تحلیلی (NumPy)
# для начала добавим столбец с не изменяющимся значением в 1.
# Данный столбец нужен для того, чтобы не обрабатывать отдельно коэффицент a
vector_1 = np.ones((x_np.shape[0],1))
x_np = table_zero[['x']].values # на всякий случай приведем в первичный формат вектор x_np
x_np = np.hstack((vector_1,x_np))
# проверим то, что все сделали правильно
print vector_1[0:3]
print x_np[0:3]
print '***************************************'
print
# напишем функцию, которая определяет значения коэффициентов a и b с использованием псевдообратной матрицы
def pseudoinverse_matrix(X, y):
# задаем явный формат матрицы признаков
X = np.matrix(X)
# определяем транспонированную матрицу
XT = X.T
# определяем квадратную матрицу
XTX = XT*X
# определяем псевдообратную матрицу
inv = np.linalg.pinv(XTX)
# задаем явный формат матрицы ответов
y = np.matrix(y)
# находим вектор весов
return (inv*XT)*y
# запустим функцию
ab_np = pseudoinverse_matrix(x_np, y_np)
print ab_np
print '***************************************'
print
# напишем функцию, которая использует для решения матричное уравнение
def matrix_equation(X,y):
a = np.dot(X.T, X)
b = np.dot(X.T, y)
return np.linalg.solve(a, b)
# запустим функцию
ab_np = matrix_equation(x_np,y_np)
print ab_npبیایید زمان صرف شده برای تعیین ضرایب را با هم مقایسه کنیم  и
и  ، مطابق با 3 روش ارائه شده است.
، مطابق با 3 روش ارائه شده است.
کد برای محاسبه زمان محاسبه
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов без использования библиотеки NumPy:" + ' 33[0m'
% timeit ab_us = Kramer_method(x_us,y_us)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием псевдообратной матрицы:" + ' 33[0m'
%timeit ab_np = pseudoinverse_matrix(x_np, y_np)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием матричного уравнения:" + ' 33[0m'
%timeit ab_np = matrix_equation(x_np, y_np)
با مقدار کمی داده، یک تابع "خود نوشته" جلوتر می آید که ضرایب را با استفاده از روش کرامر پیدا می کند.
اکنون می توانید به سراغ روش های دیگر برای یافتن ضرایب بروید  и
и  .
.
گرادیان نزول
ابتدا بیایید تعریف کنیم که گرادیان چیست. به بیان ساده، گرادیان قطعه ای است که جهت حداکثر رشد یک تابع را نشان می دهد. در قیاس با بالا رفتن از یک کوه، جایی که شیب وجهی آن جایی است که شیب دارترین صعود به بالای کوه است. با توسعه مثال با کوه، به یاد می آوریم که در واقع ما به تندترین فرود نیاز داریم تا در سریع ترین زمان ممکن به زمین پست برسیم، یعنی حداقل - جایی که عملکرد در آن افزایش یا کاهش نمی یابد. در این مرحله مشتق برابر با صفر خواهد بود. بنابراین، ما به یک گرادیان نیاز نداریم، بلکه به یک ضد گرادیان نیاز داریم. برای پیدا کردن ضد گرادیان فقط باید گرادیان را در ضرب کنید -1 (منهای یک).
اجازه دهید به این واقعیت توجه کنیم که یک تابع می تواند چندین مینیمم داشته باشد و با نزول به یکی از آنها با استفاده از الگوریتم ارائه شده در زیر، نمی توانیم حداقل دیگری را پیدا کنیم که ممکن است کمتر از موجود باشد. بیایید راحت باشیم، این تهدیدی برای ما نیست! در مورد ما، از آنجایی که عملکرد ماست، با یک حداقل واحد سر و کار داریم  روی نمودار یک سهمی منظم است. و همانطور که همه ما باید به خوبی از درس ریاضی مدرسه خود بدانیم، سهمی فقط یک حداقل دارد.
روی نمودار یک سهمی منظم است. و همانطور که همه ما باید به خوبی از درس ریاضی مدرسه خود بدانیم، سهمی فقط یک حداقل دارد.
بعد از اینکه فهمیدیم چرا به یک گرادیان نیاز داریم و همچنین اینکه گرادیان یک قطعه است، یعنی یک بردار با مختصات داده شده، که دقیقاً همان ضرایب هستند.  и
и  ما می توانیم نزول گرادیان را پیاده سازی کنیم.
ما می توانیم نزول گرادیان را پیاده سازی کنیم.
قبل از شروع، پیشنهاد می کنم فقط چند جمله در مورد الگوریتم فرود بخوانید:
- مختصات ضرایب را به صورت شبه تصادفی تعیین می کنیم
 и . در مثال ما ضرایب نزدیک به صفر را تعیین خواهیم کرد. این یک روش معمول است، اما هر مورد ممکن است رویه خاص خود را داشته باشد.
и . در مثال ما ضرایب نزدیک به صفر را تعیین خواهیم کرد. این یک روش معمول است، اما هر مورد ممکن است رویه خاص خود را داشته باشد. - از مختصات مقدار مشتق جزئی مرتبه اول را در نقطه کم کنید . بنابراین، اگر مشتق مثبت باشد، تابع افزایش می یابد. بنابراین با کم کردن مقدار مشتق در جهت مخالف رشد یعنی در جهت نزول حرکت خواهیم کرد. اگر مشتق منفی باشد تابع در این نقطه کاهش می یابد و با کم کردن مقدار مشتق در جهت نزول حرکت می کنیم.
- ما عملیات مشابهی را با مختصات انجام می دهیم : مقدار مشتق جزئی را در نقطه کم کنید .
- برای اینکه از حداقل ها پرش نکنید و به فضای عمیق پرواز نکنید، باید اندازه گام را در جهت فرود تنظیم کنید. به طور کلی، می توانید یک مقاله کامل در مورد نحوه تنظیم صحیح گام و نحوه تغییر آن در طول فرآیند فرود به منظور کاهش هزینه های محاسباتی بنویسید. اما اکنون کار کمی متفاوت در پیش داریم و اندازه گام را با استفاده از روش علمی "poke" یا به قول آنها به صورت تجربی تعیین می کنیم.
- زمانی که از مختصات داده شده هستیم и مقادیر مشتقات را کم کنید، مختصات جدیدی به دست می آوریم и . ما قدم بعدی (تفریق) را از قبل از مختصات محاسبه شده برمی داریم. و بنابراین چرخه بارها و بارها شروع می شود، تا زمانی که همگرایی لازم حاصل شود.
 и
и  . در مثال ما ضرایب نزدیک به صفر را تعیین خواهیم کرد. این یک روش معمول است، اما هر مورد ممکن است رویه خاص خود را داشته باشد.
. در مثال ما ضرایب نزدیک به صفر را تعیین خواهیم کرد. این یک روش معمول است، اما هر مورد ممکن است رویه خاص خود را داشته باشد. مقدار مشتق جزئی مرتبه اول را در نقطه کم کنید
مقدار مشتق جزئی مرتبه اول را در نقطه کم کنید  . بنابراین، اگر مشتق مثبت باشد، تابع افزایش می یابد. بنابراین با کم کردن مقدار مشتق در جهت مخالف رشد یعنی در جهت نزول حرکت خواهیم کرد. اگر مشتق منفی باشد تابع در این نقطه کاهش می یابد و با کم کردن مقدار مشتق در جهت نزول حرکت می کنیم.
. بنابراین، اگر مشتق مثبت باشد، تابع افزایش می یابد. بنابراین با کم کردن مقدار مشتق در جهت مخالف رشد یعنی در جهت نزول حرکت خواهیم کرد. اگر مشتق منفی باشد تابع در این نقطه کاهش می یابد و با کم کردن مقدار مشتق در جهت نزول حرکت می کنیم.  : مقدار مشتق جزئی را در نقطه کم کنید
: مقدار مشتق جزئی را در نقطه کم کنید  .
. и
и  مقادیر مشتقات را کم کنید، مختصات جدیدی به دست می آوریم
مقادیر مشتقات را کم کنید، مختصات جدیدی به دست می آوریم  и
и  . ما قدم بعدی (تفریق) را از قبل از مختصات محاسبه شده برمی داریم. و بنابراین چرخه بارها و بارها شروع می شود، تا زمانی که همگرایی لازم حاصل شود.
. ما قدم بعدی (تفریق) را از قبل از مختصات محاسبه شده برمی داریم. و بنابراین چرخه بارها و بارها شروع می شود، تا زمانی که همگرایی لازم حاصل شود.همه! اکنون ما آماده ایم تا به دنبال عمیق ترین تنگه ترانشه ماریانا برویم. بیا شروع کنیم.
کد برای نزول گرادیان
# напишем функцию градиентного спуска без использования библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = sum(x_us)
# сумма истинных ответов (выручка за весь период)
sy = sum(y_us)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x_us[i]*y_us[i]) for i in range(len(x_us))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x_us[i]**2) for i in range(len(x_us))]
sx_sq = sum(list_x_sq)
# количество значений
num = len(x_us)
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = [a,b]
errors.append(errors_sq_Kramer_method(ab,x_us,y_us))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
ما به پایین ترانشه ماریانا شیرجه زدیم و در آنجا همه مقادیر ضرایب مشابه را پیدا کردیم  и
и  ، که دقیقاً همان چیزی است که انتظار می رفت.
، که دقیقاً همان چیزی است که انتظار می رفت.
بیایید یک شیرجه دیگر انجام دهیم، فقط این بار، وسیله نقلیه ما در اعماق دریا با فناوری های دیگری، یعنی کتابخانه پر می شود. NumPy.
کد برای نزول گرادیان (NumPy)
# перед тем определить функцию для градиентного спуска с использованием библиотеки NumPy,
# напишем функцию определения суммы квадратов отклонений также с использованием NumPy
def error_square_numpy(ab,x_np,y_np):
y_pred = np.dot(x_np,ab)
error = y_pred - y_np
return sum((error)**2)
# напишем функцию градиентного спуска с использованием библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = float(sum(x_np[:,1]))
# сумма истинных ответов (выручка за весь период)
sy = float(sum(y_np))
# сумма произведения значений на истинные ответы
sxy = x_np*y_np
sxy = float(sum(sxy[:,1]))
# сумма квадратов значений
sx_sq = float(sum(x_np[:,1]**2))
# количество значений
num = float(x_np.shape[0])
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = np.array([[a],[b]])
errors.append(error_square_numpy(ab,x_np,y_np))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
مقادیر ضرایب  и
и  غیر قابل تغییر
غیر قابل تغییر
بیایید ببینیم که خطا در حین نزول گرادیان چگونه تغییر کرد، یعنی چگونه مجموع انحرافات مجذور با هر مرحله تغییر کرد.
کد برای رسم مجموع انحرافات مربع
print 'График№4 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_gradient_descence[1])), list_parametres_gradient_descence[1], color='red', lw=3)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()نمودار شماره 4 "مجموع انحرافات مجذور در حین نزول گرادیان"
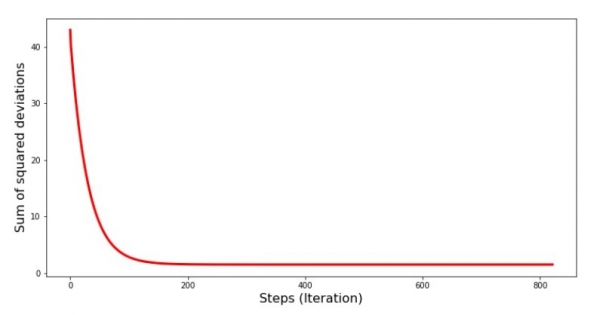
در نمودار می بینیم که با هر مرحله خطا کاهش می یابد و پس از تعداد معینی از تکرار یک خط تقریبا افقی را مشاهده می کنیم.
در نهایت، بیایید تفاوت زمان اجرای کد را تخمین بزنیم:
کد برای تعیین زمان محاسبه نزول گرادیان
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска без использования библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска с использованием библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
شاید ما داریم کار اشتباهی انجام میدهیم، اما دوباره این یک تابع ساده «خانهای» است که از کتابخانه استفاده نمیکند. NumPy از زمان محاسبه یک تابع با استفاده از کتابخانه بهتر عمل می کند NumPy.
اما ما هنوز ایستاده نیستیم، بلکه به سمت مطالعه روش هیجان انگیز دیگری برای حل معادله رگرسیون خطی ساده حرکت می کنیم. ملاقات!
نزول گرادیان تصادفی
برای درک سریع اصل عملکرد شیب نزولی تصادفی، بهتر است تفاوت آن را با نزول گرادیان معمولی مشخص کنیم. ما، در مورد نزول گرادیان، در معادلات مشتقات از  и
и  از مجموع مقادیر همه ویژگی ها و پاسخ های واقعی موجود در نمونه استفاده کرد (یعنی مجموع همه
از مجموع مقادیر همه ویژگی ها و پاسخ های واقعی موجود در نمونه استفاده کرد (یعنی مجموع همه  и
и  ). در نزول گرادیان تصادفی، از تمام مقادیر موجود در نمونه استفاده نمی کنیم، بلکه به طور شبه تصادفی به اصطلاح شاخص نمونه را انتخاب کرده و از مقادیر آن استفاده می کنیم.
). در نزول گرادیان تصادفی، از تمام مقادیر موجود در نمونه استفاده نمی کنیم، بلکه به طور شبه تصادفی به اصطلاح شاخص نمونه را انتخاب کرده و از مقادیر آن استفاده می کنیم.
به عنوان مثال، اگر شاخص به عدد 3 (سه) تعیین شود، آنگاه مقادیر را می گیریم  и
и  سپس مقادیر را جایگزین معادلات مشتق کرده و مختصات جدید را تعیین می کنیم. سپس با تعیین مختصات، دوباره به صورت شبه تصادفی شاخص نمونه را تعیین می کنیم، مقادیر مربوط به شاخص را در معادلات دیفرانسیل جزئی جایگزین می کنیم و مختصات را به روشی جدید تعیین می کنیم.
سپس مقادیر را جایگزین معادلات مشتق کرده و مختصات جدید را تعیین می کنیم. سپس با تعیین مختصات، دوباره به صورت شبه تصادفی شاخص نمونه را تعیین می کنیم، مقادیر مربوط به شاخص را در معادلات دیفرانسیل جزئی جایگزین می کنیم و مختصات را به روشی جدید تعیین می کنیم.  и
и  و غیره. تا زمانی که همگرایی سبز شود. در نگاه اول، ممکن است به نظر برسد که اصلاً نمی تواند کار کند، اما این کار را می کند. درست است که شایان ذکر است که خطا با هر مرحله کاهش نمی یابد، اما قطعاً یک تمایل وجود دارد.
و غیره. تا زمانی که همگرایی سبز شود. در نگاه اول، ممکن است به نظر برسد که اصلاً نمی تواند کار کند، اما این کار را می کند. درست است که شایان ذکر است که خطا با هر مرحله کاهش نمی یابد، اما قطعاً یک تمایل وجود دارد.
مزایای نزول گرادیان تصادفی نسبت به معمولی چیست؟ اگر حجم نمونه ما بسیار بزرگ باشد و در دهها هزار مقدار اندازهگیری شود، پردازش، مثلاً یک هزار تصادفی از آنها، به جای کل نمونه، بسیار آسانتر است. اینجاست که نزول گرادیان تصادفی وارد عمل می شود. در مورد ما، البته، ما تفاوت زیادی را متوجه نخواهیم شد.
بیایید به کد نگاه کنیم.
کد برای نزول گرادیان تصادفی
# определим функцию стох.град.шага
def stoch_grad_step_usual(vector_init, x_us, ind, y_us, l):
# выбираем значение икс, которое соответствует случайному значению параметра ind
# (см.ф-цию stoch_grad_descent_usual)
x = x_us[ind]
# рассчитывыаем значение y (выручку), которая соответствует выбранному значению x
y_pred = vector_init[0] + vector_init[1]*x_us[ind]
# вычисляем ошибку расчетной выручки относительно представленной в выборке
error = y_pred - y_us[ind]
# определяем первую координату градиента ab
grad_a = error
# определяем вторую координату ab
grad_b = x_us[ind]*error
# вычисляем новый вектор коэффициентов
vector_new = [vector_init[0]-l*grad_a, vector_init[1]-l*grad_b]
return vector_new
# определим функцию стох.град.спуска
def stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800):
# для самого начала работы функции зададим начальные значения коэффициентов
vector_init = [float(random.uniform(-0.5, 0.5)), float(random.uniform(-0.5, 0.5))]
errors = []
# запустим цикл спуска
# цикл расчитан на определенное количество шагов (steps)
for i in range(steps):
ind = random.choice(range(len(x_us)))
new_vector = stoch_grad_step_usual(vector_init, x_us, ind, y_us, l)
vector_init = new_vector
errors.append(errors_sq_Kramer_method(vector_init,x_us,y_us))
return (vector_init),(errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
ما به دقت به ضرایب نگاه می کنیم و خودمان را در حال پرسیدن این سوال می دانیم که "چگونه ممکن است؟" مقادیر ضرایب دیگر را به دست آوردیم  и
и  . شاید نزول گرادیان تصادفی پارامترهای بهینه تری برای معادله پیدا کرده باشد؟ متاسفانه نه. کافی است به مجموع انحرافات مجذور نگاه کنیم و ببینیم که با مقادیر جدید ضرایب، خطا بیشتر است. ما عجله ای برای ناامیدی نداریم. بیایید یک نمودار از تغییر خطا بسازیم.
. شاید نزول گرادیان تصادفی پارامترهای بهینه تری برای معادله پیدا کرده باشد؟ متاسفانه نه. کافی است به مجموع انحرافات مجذور نگاه کنیم و ببینیم که با مقادیر جدید ضرایب، خطا بیشتر است. ما عجله ای برای ناامیدی نداریم. بیایید یک نمودار از تغییر خطا بسازیم.
کد رسم مجموع انحرافات مجذور در نزول گرادیان تصادفی
print 'График №5 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()نمودار شماره 5 "مجموع انحرافات مجذور در حین نزول گرادیان تصادفی"
با نگاهی به برنامه، همه چیز سر جای خود قرار می گیرد و اکنون همه چیز را درست می کنیم.
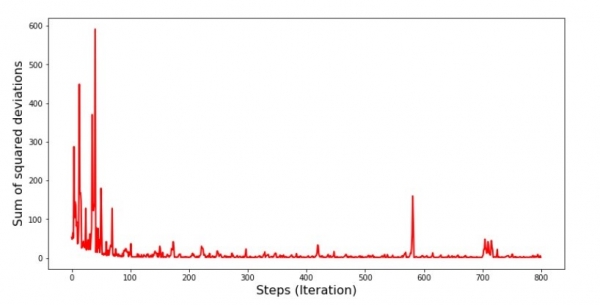
پس چه اتفاقی افتاد؟ موارد زیر اتفاق افتاد. هنگامی که ما به صورت تصادفی یک ماه را انتخاب می کنیم، برای ماه انتخابی است که الگوریتم ما به دنبال کاهش خطا در محاسبه درآمد است. سپس یک ماه دیگر را انتخاب می کنیم و محاسبه را تکرار می کنیم، اما خطای ماه انتخابی دوم را کاهش می دهیم. حال به یاد داشته باشید که دو ماه اول به طور قابل توجهی از خط معادله رگرسیون خطی ساده منحرف می شود. به این معنی که وقتی هر یک از این دو ماه انتخاب می شود، با کاهش خطای هر یک از آنها، الگوریتم ما خطا را برای کل نمونه به طور جدی افزایش می دهد. خوب چه کار کنیم؟ پاسخ ساده است: باید پله فرود را کاهش دهید. از این گذشته، با کاهش مرحله نزول، خطا همچنین "پرش" به بالا و پایین را متوقف می کند. یا بهتر است بگوییم، خطای "پرش" متوقف نمی شود، اما آن را به سرعت انجام نمی دهد :) بیایید بررسی کنیم.
کد برای اجرای SGD با افزایش های کوچکتر
# запустим функцию, уменьшив шаг в 100 раз и увеличив количество шагов соответсвующе
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print 'График №6 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
نمودار شماره 6 "مجموع انحرافات مجذور در حین نزول شیب تصادفی (80 هزار پله)"
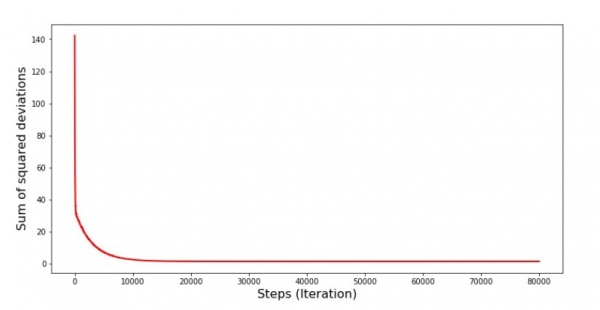
ضرایب بهبود یافته اند، اما هنوز ایده آل نیستند. به طور فرضی، این را می توان از این طریق اصلاح کرد. به عنوان مثال، در 1000 تکرار گذشته مقادیر ضرایبی را که حداقل خطا با آنها انجام شده است، انتخاب می کنیم. درست است، برای این ما باید مقادیر خود ضرایب را نیز بنویسیم. ما این کار را انجام نمی دهیم، بلکه به برنامه توجه می کنیم. صاف به نظر می رسد و به نظر می رسد خطا به طور یکنواخت کاهش می یابد. در واقع، این صحیح نیست. بیایید به 1000 تکرار اول نگاه کنیم و آنها را با آخرین مورد مقایسه کنیم.
کد برای نمودار SGD (1000 مرحله اول)
print 'График №7 "Сумма квадратов отклонений по-шагово. Первые 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][:1000])),
list_parametres_stoch_gradient_descence[1][:1000], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
print 'График №7 "Сумма квадратов отклонений по-шагово. Последние 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][-1000:])),
list_parametres_stoch_gradient_descence[1][-1000:], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
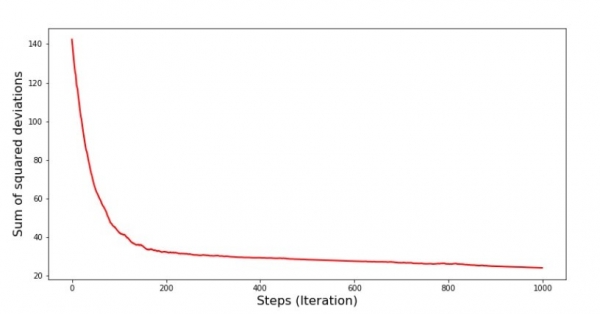
plt.show()نمودار شماره 7 "مجموع انحرافات مربع SGD (1000 مرحله اول)"
نمودار شماره 8 "مجموع انحرافات مربع SGD (1000 قدم آخر)"
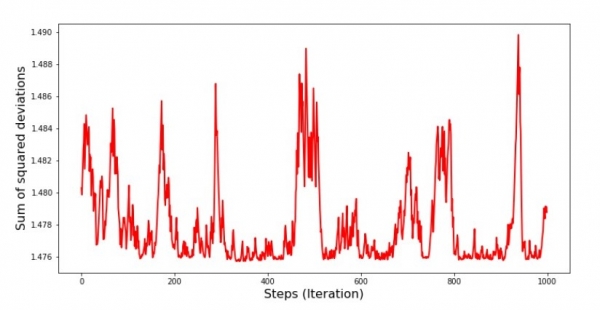
در همان ابتدای فرود، کاهش نسبتاً یکنواخت و تند خطا را مشاهده می کنیم. در تکرارهای آخر می بینیم که خطا دور و اطراف مقدار 1,475 می رود و در برخی لحظات حتی با این مقدار بهینه برابر می شود، اما باز هم بالا می رود... تکرار می کنم، می توانید مقادیر را یادداشت کنید. ضرایب  и
и  و سپس مواردی را انتخاب کنید که خطا در آنها حداقل است. با این حال، ما یک مشکل جدی تری داشتیم: ما مجبور شدیم 80 هزار قدم برداریم (به کد مراجعه کنید) تا مقادیر را به مقدار بهینه نزدیک کنیم. و این در حال حاضر با ایده صرفه جویی در زمان محاسبات با نزول گرادیان تصادفی نسبت به نزول گرادیان در تضاد است. چه چیزی را می توان اصلاح و بهبود بخشید؟ توجه به این که در اولین تکرارها با اطمینان به سمت پایین می رویم کار سختی نیست و بنابراین باید در اولین تکرارها یک پله بزرگ بگذاریم و با حرکت رو به جلو پله را کاهش دهیم. ما در این مقاله این کار را انجام نخواهیم داد - در حال حاضر خیلی طولانی است. کسانی که مایلند می توانند خودشان فکر کنند که چگونه این کار را انجام دهند، دشوار نیست :)
و سپس مواردی را انتخاب کنید که خطا در آنها حداقل است. با این حال، ما یک مشکل جدی تری داشتیم: ما مجبور شدیم 80 هزار قدم برداریم (به کد مراجعه کنید) تا مقادیر را به مقدار بهینه نزدیک کنیم. و این در حال حاضر با ایده صرفه جویی در زمان محاسبات با نزول گرادیان تصادفی نسبت به نزول گرادیان در تضاد است. چه چیزی را می توان اصلاح و بهبود بخشید؟ توجه به این که در اولین تکرارها با اطمینان به سمت پایین می رویم کار سختی نیست و بنابراین باید در اولین تکرارها یک پله بزرگ بگذاریم و با حرکت رو به جلو پله را کاهش دهیم. ما در این مقاله این کار را انجام نخواهیم داد - در حال حاضر خیلی طولانی است. کسانی که مایلند می توانند خودشان فکر کنند که چگونه این کار را انجام دهند، دشوار نیست :)
حال اجازه دهید نزول گرادیان تصادفی را با استفاده از کتابخانه انجام دهیم NumPy (و بیایید سنگ هایی را که قبلاً شناسایی کردیم تلو تلو خوردن نکنیم)
کد برای نزول گرادیان تصادفی (NumPy)
# для начала напишем функцию градиентного шага
def stoch_grad_step_numpy(vector_init, X, ind, y, l):
x = X[ind]
y_pred = np.dot(x,vector_init)
err = y_pred - y[ind]
grad_a = err
grad_b = x[1]*err
return vector_init - l*np.array([grad_a, grad_b])
# определим функцию стохастического градиентного спуска
def stoch_grad_descent_numpy(X, y, l=0.1, steps = 800):
vector_init = np.array([[np.random.randint(X.shape[0])], [np.random.randint(X.shape[0])]])
errors = []
for i in range(steps):
ind = np.random.randint(X.shape[0])
new_vector = stoch_grad_step_numpy(vector_init, X, ind, y, l)
vector_init = new_vector
errors.append(error_square_numpy(vector_init,X,y))
return (vector_init), (errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print
مقادیر تقریباً مشابه هنگام نزول بدون استفاده است NumPy. با این حال، این منطقی است.
بیایید دریابیم که نزول گرادیان تصادفی چقدر طول کشید.
کد تعیین زمان محاسبه SGD (80 هزار مرحله)
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска без использования библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска с использованием библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
هرچه بیشتر به جنگل بروید، ابرها تیره تر می شوند: دوباره، فرمول "خود نوشته" بهترین نتیجه را نشان می دهد. همه اینها نشان می دهد که باید راه های ظریف تری برای استفاده از کتابخانه وجود داشته باشد NumPy، که واقعاً عملیات محاسباتی را سرعت می بخشد. در این مقاله با آنها آشنا نخواهیم شد. در اوقات فراغت چیزی برای فکر کردن وجود دارد :)
خلاصه کنید
قبل از جمع بندی، می خواهم به سوالی که به احتمال زیاد از خواننده عزیزمان برخاسته پاسخ دهم. در واقع چرا چنین "شکنجه" با فرودها، چرا باید از کوه بالا و پایین (بیشتر پایین) راه برویم تا دشت ارزشمند را پیدا کنیم، اگر چنین دستگاه قدرتمند و ساده ای در دست داریم، در شکلی از یک راه حل تحلیلی، که فوراً ما را به مکان درست از راه دور منتقل می کند؟
پاسخ این سوال در ظاهر نهفته است. اکنون ما به یک مثال بسیار ساده نگاه کردیم که در آن پاسخ واقعی است  به یک علامت بستگی دارد
به یک علامت بستگی دارد  . شما اغلب این را در زندگی نمی بینید، بنابراین بیایید تصور کنیم که ما 2، 30، 50 یا بیشتر نشانه داریم. بیایید هزاران یا حتی ده ها هزار مقدار را برای هر ویژگی به این اضافه کنیم. در این حالت، راه حل تحلیلی ممکن است در برابر آزمون مقاومت نکرده و شکست بخورد. به نوبه خود، نزول گرادیان و تغییرات آن به آرامی اما مطمئنا ما را به هدف - حداقل تابع - نزدیکتر می کند. و نگران سرعت نباشید - احتمالاً راههایی را بررسی میکنیم که به ما امکان میدهند طول گام را تنظیم و تنظیم کنیم (یعنی سرعت).
. شما اغلب این را در زندگی نمی بینید، بنابراین بیایید تصور کنیم که ما 2، 30، 50 یا بیشتر نشانه داریم. بیایید هزاران یا حتی ده ها هزار مقدار را برای هر ویژگی به این اضافه کنیم. در این حالت، راه حل تحلیلی ممکن است در برابر آزمون مقاومت نکرده و شکست بخورد. به نوبه خود، نزول گرادیان و تغییرات آن به آرامی اما مطمئنا ما را به هدف - حداقل تابع - نزدیکتر می کند. و نگران سرعت نباشید - احتمالاً راههایی را بررسی میکنیم که به ما امکان میدهند طول گام را تنظیم و تنظیم کنیم (یعنی سرعت).
و اکنون خلاصه واقعی واقعی.
اولاً، امیدوارم مطالب ارائه شده در مقاله به «دانشمندان داده» در درک چگونگی حل معادلات رگرسیون خطی ساده (و نه تنها) کمک کند.
دوم، ما به چندین روش برای حل معادله نگاه کردیم. اکنون بسته به شرایط، میتوانیم بهترین گزینه را برای حل مشکل انتخاب کنیم.
سوم، ما قدرت تنظیمات اضافی، یعنی طول گام نزولی گرادیان را دیدیم. این پارامتر را نمی توان نادیده گرفت. همانطور که در بالا ذکر شد، برای کاهش هزینه محاسبات، طول پله باید در هنگام فرود تغییر یابد.
چهارم، در مورد ما، توابع "خانه نوشته شده" بهترین نتایج زمانی را برای محاسبات نشان دادند. این احتمالاً به دلیل عدم استفاده حرفه ای از قابلیت های کتابخانه است NumPy. اما به هر حال نتیجه گیری زیر خود را نشان می دهد. از یک طرف، گاهی اوقات ارزش زیر سوال بردن نظرات تثبیت شده را دارد، و از طرف دیگر، همیشه ارزش پیچیده کردن همه چیز را ندارد - برعکس، گاهی اوقات یک راه ساده تر برای حل یک مشکل موثرتر است. و از آنجایی که هدف ما تجزیه و تحلیل سه رویکرد برای حل یک معادله رگرسیون خطی ساده بود، استفاده از توابع "خود نوشته" برای ما کاملاً کافی بود.
ادبیات (یا چیزی شبیه به آن)
1. رگرسیون خطی
2. روش حداقل مربعات
3. مشتق
4. گرادیان
5. نزول گرادیان
6. کتابخانه NumPy
منبع: www.habr.com
