

Social Data Hubin toimitusjohtaja Artur Khachuyan puhui BBDO:n luentosalissa 14. maaliskuuta 2017. Artur keskusteli älykkäästä seurannasta, käyttäytymismallien rakentamisesta, kuva- ja videosisällön tunnistamisesta sekä muista Social Data Hubin työkaluista ja tutkimuksesta, jotka mahdollistavat kohdeyleisön kohdentamisen sosiaalisen median ja Big Data -teknologioiden avulla.

Artur Khachuyan (jäljempänä - AH): Hei! Hei kaikki! Nimeni on Artur Khachuyan ja johdan Social Data Hubia, jossa teemme erilaisia mielenkiintoisia älyllisiä analyysejä avoimesta datasta ja tietokentistä sekä suoritamme kaikenlaista mielenkiintoista tutkimusta.
Tänään kollegani BBDO Groupilta pyysivät minua puhumaan nykyaikaisista big data -analytiikkateknologioista, sekä suurista että pienistä, mainonnassa: miten niitä sovelletaan, ja jakamaan mielenkiintoisia esimerkkejä. Toivon, että kysytte kysymyksiä matkan varrella, sillä saatan käydä hieman tylsäksi enkä käsittele asian ydintä, joten älkää ujostelko.
Itse asiassa tärkeimmät alueet, joilla "lähes big data" -ratkaisuja on koskaan sovellettu, ovat kaikki selvät: kohdeyleisön kohdentaminen, analysointi ja jonkinlaisen analyyttisen markkinointitutkimuksen tekeminen. Mutta on aina mielenkiintoista nähdä, mitä lisädataa voidaan löytää, mitä lisämerkityksiä analyysin soveltamisesta voidaan johtaa.
Miksi tarvitsemme teknologiaa mainontaan?
Mistä aloittaisimme? Ilmeisin on sosiaalisen median mainonta. Otin tämän tänä aamuna: jostain syystä VKontakte luulee, että minun pitäisi nähdä tämä tietty mainos… Onko se hyvä vai huono, on eri kysymys. Näemme, että kuulun ehdottomasti varusmiesten kategoriaan:

Ensimmäinen ja mielenkiintoisin asia, joka voidaan ottaa teknologisena ratkaisuna... Ennen kuin aloitamme, halusin ensin määritellä termit: mitä on avoin data ja mitä on big data? Koska jokaisella on tästä oma käsityksensä, enkä halua pakottaa omia termejäni kenellekään, mutta... Jotta ei synny ristiriitoja.
Henkilökohtaisesti pidän avointa dataa kaiken, mihin voin käyttää ilman käyttäjätunnusta tai salasanaa. Tähän sisältyvät avoimet sosiaalisen median profiilit, hakutulokset, avoimet rekisterit ja niin edelleen. Big data on omasta käsityksestäni seuraavaa: jos se on datataulukko, se on miljardi riviä; jos se on jonkinlainen tiedostojen tallennustila, se on jossain petatavun luokkaa dataa. Kaikki muu ei minun terminologiani mukaan ole big dataa, mutta jotain lähellä sitä.
Tarkka profilointi ja profiilien pisteytys
Otetaan asiat askel askeleelta. Ensimmäinen ja mielenkiintoisin asia, jonka avoimia datalähteitä analysoimalla voidaan saada selville, on tarkka profilointi ja profiilien pisteytys. Mitä tämä on? Se on konsepti, jossa sosiaalisen median tiliäsi voidaan käyttää ennustamaan paitsi kuka olet, myös kiinnostuksen kohteitasi.
Mutta nyt, yhdistämällä eri lähteitä, voit ymmärtää keskipalkkasi, asuntosi hinnan ja sijainnin. Ja kaikkea tätä tietoa voidaan käyttää kirjaimellisesti käsillä olevista resursseista. Jos esimerkiksi otat sosiaalisen median tilisi ja näet esimerkiksi missä asut ja työskentelet; ymmärrät, millä toimialalla yritys, jossa työskentelet, toimii; lataat samankaltaisia avoimia työpaikkoja HH:sta ja Superjobista, jos olet analyytikko, johtaja jne.; katsot asuinpaikkaasi (esimerkiksi CIANin tietokantaa), ymmärrät, kuinka paljon siellä on vuokraa, kuinka paljon siellä ostaminen maksaa, ja ennustat karkeasti, kuinka paljon ansaitset. Lisäksi sosiaalisen median avulla voit ymmärtää, kuinka paljon matkustat, missä olet ja kuinka uskollinen olet työnantajallesi.
Näin ollen voimme tehdä mitä haluamme valtavalla määrällä mittareita. Voimme esitellä sinulle tuotteen, joka kiinnostaa sinua. Kuvittele verkkokauppa? Menet sinne – verkkokauppa tunnistaa sosiaalisen median tilisi ja kertoo sinulle: "Masha, juuri erosit poikaystävästäsi, tässä on sinulle tarkoitettuja tuotteita." Se ei ole lähitulevaisuus...
Miten henkilön maantieteellinen sijainti määritetään?
Vastauksia yleisön kysymyksiin:
- Tyypillisesti 80 % kaikista sisäänkirjautumisista perustuu tarkkaan asuinpaikkaan. Mutta ihmisille, jotka eivät kirjaudu sisään missään, on useita vaihtoehtoja: joko sisäänkirjautuminen, maantieteellinen sijainti tai viestien ja julkaisujen analysointi koko siltä ajalta, kun henkilö on kirjoittanut mitään... Ja jossain ponnahtaa esiin jotain tyyliin "Haluan ostaa lastenrattaat läheltä Akademicheskayaa" tai "Näin äskettäin rumia graffiteja seinällä täällä". Toisin sanoen lähes 80 %:lla ihmisistä heidän maantieteellinen sijaintinsa, työpaikkansa ja asuinpaikkansa voidaan määrittää sosiaalisesta mediasta kerättyjen tietojen tai metatietojen perusteella.
Tämäkin on jälkianalyysiä. Yksinkertaisimmassa muodossaan se on sosiaalisten verkostojen kirjautumisten ja geolokaatioiden analysointia, joka ei poista JPEG-metatietoja (joita voidaan käyttää joidenkin tietojen tulkitsemiseen). Mutta muille ihmisille nämä ovat yleensä tekstiviestejä: joko henkilö paljastaa sijaintinsa julkaistessaan jotain tai hän paljastaa puhelinnumeronsa, jota voidaan käyttää mainosten löytämiseen Avitossa tai heidän tililtään Avto.ru-sivustolla. Näiden tietojen avulla voimme yhdistää tietoja (esimerkiksi "Myyn autoa lähellä Majakovskajaa") ja tehdä karkean arvion.
- Ihmiset yleensä julkaisevat tällaista sosiaalisessa mediassa. Työskentelemme yksinomaan avoimen lähdekoodin parissa, ja puhumme tässä yksinomaan avoimesta lähdekoodista. He yleensä julkaisevat mainoksia – eli noin 60 prosentissa tapauksista yleisin tarina, kun ihmiset "jakavat" nykyisen matkapuhelinnumeronsa, on mainos jostakin myytävästä. Joko henkilö julkaisee jonkin ryhmän viestin ("Myyn sitä tai tätä") tai liittyy johonkin muuhun ryhmään.
Kyllä! He yleensä kommentoivat jotakuinkin näin: "Vastaa minulle, lähetä minulle tekstiviesti tai soita minulle tähän numeroon. Tämä tapahtuu hyvin usein ihmisille, jotka myyvät tai ostavat tavaroita sosiaalisessa mediassa tai kommunikoivat jonkun kanssa..." Näin ollen tämä numero voidaan sitten linkittää heidän profiiliinsa CIANissa, jos he ovat koskaan julkaisseet mitään, tai jälleen Avitossa. Nämä ovat yksinkertaisesti suosituimpia ja tärkeimpiä lähteitä, ja se pysyy linkitettynä jatkossakin – Avito, CIAN ja niin edelleen.
- Puhun verkkokaupasta. Seuraavaksi vuorossa on kasvojentunnistus ja profiilien yhteensovitusteknologia (siitä puhumme lisää). Teoriassa tätä voitaisiin soveltaa myös kivijalkamyymälään. Suuri unelmani on, että kun kadulla näkyy mainosbannereita, kamerat seuraavat kasvojasi ohikulkiessasi. Mutta tämä kielletään lailla, koska se loukkaa yksityisyyttä. Toivon, että se tapahtuu ennemmin tai myöhemmin.
- Minulla on tämä omakohtainen kokemus. Hyvin usein, kun joku kirjoittaa sinulle, käytät hänen elämästään tietoja, jotka sinun pitäisi pitää salassa... Ihmiset ovat yleensä peloissaan. Mutta! Viimeaikaisten tilastojen mukaan yksityisten tilien määrä sosiaalisessa mediassa on vähentynyt 14 %. Väärennettyjen tilien määrä kasvaa, kun taas avointen tilien määrä kasvaa – ihmiset siirtyvät yhä enemmän avoimuuteen. Uskon, että kolmen tai neljän vuoden kuluttua he lakkaavat reagoimasta niin voimakkaasti siihen, että joku tietää heistä tietoja, joita heidän ei mahdollisesti pitäisi tietää. Mutta todellisuudessa tämä on hyvin helppo selvittää katsomalla heidän seinäänsä.
Mitä avoimista lähteistä voi ottaa?
Avoimista lähteistä on olemassa karkea lista asioista, jotka voidaan päätellä melko varmasti. Todellisuudessa mittareita on vielä enemmän; se riippuu siitä, kuka tällaisen tutkimuksen tilaa. HR-toimisto saattaa olla kiinnostunut siitä, kiroiletko sosiaalisessa mediassa tai muualla julkisessa tilassa. Joku saattaa olla kiinnostunut siitä, pidätkö Navalnyiin julkaisuista tai Yhtenäinen Venäjä -julkaisuista, tai pidätkö pornografisesta sisällöstä – näitä asioita tapahtuu melko usein.
Tärkeimpiä niistä ovat perhearvot, asunnon tai kodin arvioitu hinta, auton löytäminen ja niin edelleen. Kaikkien näiden tekijöiden perusteella ihmiset voidaan jakaa sosiaalisiin ryhmiin. Nämä ovat Moskovan Tinderin käyttäjiä, keitä he ovat (kuviensa ja löydettyjen Facebook-tilien perusteella); kiinnostuksen kohteidensa perusteella heidät jaetaan eri sosiaalisiin ryhmiin:

Lähestyessämme mainontaa olemme vähitellen siirtyneet pois perinteisestä mainosten kohdentamisesta, jossa valitset esimerkiksi VKontaktessa, että olet kiinnostunut tiettyjä ryhmiä seuraavista 18-vuotiaista miehistä. Minulla on tämä kuva alempana, näytän teille nyt:

Pointtina on, että useimmat nykyiset analyysiä tekevät palvelut – ja itse asiassa sosiaalista mediaa analysoivat ihmiset – keskittyvät erityisesti kiinnostuksen kohteiden analysointiin. Ensimmäisenä mieleen tulee seuraajiensa kärkiryhmien analysointi. Tämä saattaa toimia joillekin, mutta itse pidän sitä perustavanlaatuisesti väärin. Miksi?
Tykkäyksesi kerätään ja analysoidaan
Ota nyt puhelimesi esiin ja katso suosituimpia ryhmiäsi – yli 50 % niistä on varmasti unohtuneita. Tämä sisältö on sinulle todella merkityksetöntä. Et kuluta sitä ollenkaan, mutta järjestelmä suodattaa sinua silti sen perusteella: tilaatko reseptit vai suositut ryhmät. Toisin sanoen häiritset profiiliasi analysoivaa järjestelmää ja kiinnostuksen kohteesi ovat harhaanjohtavia.
Jatketaanpa... Mitä ihmettä? Oletamme, mitä muut ihmiset tekevät. Mielestämme tarkin tapa arvioida käyttäjien kiinnostuksen kohteita on tykkäysten kautta. Esimerkiksi VKontaktella ei ole tykkäyssyötettä, ja ihmiset luulevat, ettei kukaan tiedä, mistä he pitävät. Kyllä, joitakin tykkäyksiä on Instagramissa, ja näemme joitakin asioita Facebookissa, mutta suurin osa tiettyjen ryhmien sisällöstä ei lähetetä yleiseen syötteeseen, ja ihmiset elävät elämäänsä ajatellen, ettei kukaan tiedä, mistä he pitävät.
Keräämällä meitä kiinnostavaa sisältöä, näitä julkaisuja, näitä tykkäyksiä ja sitten tarkistamalla tätä henkilöä tästä tietokannasta, voimme määrittää tarkasti, keitä he ovat, mikä on heidän taustansa ja mitkä ovat heidän kiinnostuksen kohteensa. Voimme sijoittaa heidät tarkasti tiettyyn sosiaaliseen ryhmään ja olla vuorovaikutuksessa heidän kanssaan.
Auton ostaminen muuttaa käyttäytymistä
Minulla on esimerkki. Selvennän heti, että esimerkkini liittyvät puhtaasti mainontaan ja markkinointiin, koska kuten tiedätte, useimmat tapaukset ovat salassapitosopimusten suojaamia. Mutta mielenkiintoista tietoa on silti paljon. Tässä on siis näiden ihmisten tarina: nämä ovat miehiä, jotka ostivat auton vuosien 2010 ja 2015 välillä. Heidän sosiaalisen käyttäytymisensä muuttuminen verkossa on värikoodattu. Naispuolisten tilaajien prosenttiosuus muuttui, he liittyivät "mies"-julkisiin ryhmiin, löysivät säännöllisen seksikumppanin...
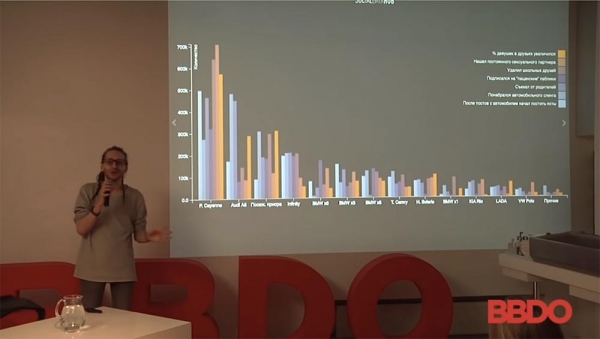
Koko tämä juttu on jaettu automerkin ja ihmisten lukumäärän mukaan. Tästä voimme tehdä monia mielenkiintoisia johtopäätöksiä ihmisten käyttäytymisestä ja siitä, miten se kaikki toimii. Voin sanoa, että Porsche Cayenne ja istutettu Priora ovat käytännössä identtisiä houkuttelemansa yleisön suhteen. Tämän yleisön laatu, heidän käyttäytymisensä, on erilainen, mutta lukumäärä on suunnilleen sama. Johtopäätös, jonka voit tehdä tästä, lähempänä markkinoitasi, on mikä tahansa. Jos myyt Audia, keksit iskulauseen "Osta Audi – pääse pois vanhempiesi luota!" ja niin edelleen.
Kyllä, tämä on hauska esimerkki siitä, miten ihmisten käyttäytyminen, joka perustuu tykkäysten, ryhmien, joihin he siirtyvät, ja analysoidun sisällön analyysiin, voi lähes 100 % tarkasti paljastaa kuka olet. Koska jos sinulla ei ole pääsyä verkkoliikenteeseen tai lue yksityisviestejä, tykkäykset kertovat aina kuka henkilö on – raskaana oleva nainen, äiti, sotilas, poliisi. Ja sinulle, joka voit sijoittaa mainoksia, tämä on valtava hitti.
Vastauksia yleisön kysymyksiin:
- Jokainen palkki edustaa tietyn auton omistavien ihmisten lukumäärää ja sitä, miten heidän käyttäytymismallinsa ovat muuttuneet. Katso: Porsche Cayennen ostaneita ihmisiä – noin 550 (keltainen), naispuolisten seuraajien prosenttiosuus on kasvanut.
- Otos koostuu VKontakten, Facebookin ja Instagramin käyttäjistä vuosina 2010–2015. Ainoa selvennys: valitut ajoneuvot voidaan tunnistaa valokuvista tiettyjen työkalujen avulla yli 80 %:n tarkkuudella.
- Tietyn ajanjakson ajan hänen autonsa (no, ei hänen, jätämme sen sosiaalisen median päätettäväksi)... Tietyn ajanjakson ajan henkilö otti jatkuvasti kuvia auton kanssa, oli sen kanssa, julkaisut vaihtelivat, kuvat olivat eri kulmista ja niin edelleen. Myöhemmin tulee kuva siitä, ketkä ihmiset ottivat kuvia milläkin autoilla ja... Kyllä, se on toinen kysymys – sosiaalisen median datan luotettavuus.
- Koska nyt puhumme aiheesta, niin valitettavasti sosiaalisen median tiedot eivät aina ole tarkkoja. Ihmiset eivät aina ole halukkaita jakamaan tietojaan. Tein henkilökohtaisesti tutkimuksen, jossa verrattiin Moskovan yliopistoista valmistuneiden määrää sosiaaliseen mediaan rekisteröityneiden ihmisten määrään. Keskimäärin 60 % enemmän ihmisiä rekisteröityi sosiaaliseen mediaan – Moskovan valtionyliopiston tiettynä vuonna ja tietyllä erikoisalalla valmistuneita – kuin todellisuudessa on olemassa. Joten kyllä, tietty määrä virheitä on luonnollisesti olemassa, eikä kukaan peittele niitä. Tiedot perustuvat yksinkertaisesti autoihin, jotka voidaan tunnistaa yli 80 %:n varmuudella.
Luettelo mallin kouluttamiseen käytettävistä lähteistä
Tässä on näyteluettelo lähteistä, joita voidaan käyttää määrittämään erittäin luotettavasti henkilön sosiaalinen profiili, kuka hän on.

Saamme profiileja sosiaalisesta mediasta, asunnon likimääräisen hinnan CIANilta ja tietyn henkilön keskipalkan HeadHunterilta ja SuperJobilta. Toivon, ettei täällä ole HeadHunterin edustajia, koska he eivät pidä sopivana ottaa näitä tietoja heiltä. Tämä on kuitenkin tiettyjen alueiden keskipalkka tietyntyyppisissä töissä avoimien työpaikkojen mukaan.
Avito, Avto.ru: hyvin usein, kun ihmiset paljastavat puhelinnumeronsa, heillä on se varmasti (monissa tapauksissa) listattuna jossain Avitossa, Avto.russa tai muutamilla muilla verkkosivustoilla, jotka voivat auttaa heidät tunnistamaan. Jos he ovat käyttäneet kyseistä puhelinnumeroa lastenrattaiden tai auton myymiseen... Rosstat ja yhtenäinen valtion oikeushenkilörekisteri ovat loppujen lopuksi enemmänkin rekistereitä, joita voidaan käyttää työnantajan yrityksen luokitteluun – jonkin kaavan, mallin perusteella, jonka kuka tahansa voi määritellä (voit karkeasti arvioida kyseisen henkilön nettovarallisuuden jne.).
Tinder auttaa keräämään tietoa ihmisten tilanteista
Lisäksi on tämä mielenkiintoinen asia (joka on itse asiassa aika hauska tässä tutkimuksessa) – jälleen kerran he keräsivät dataa Moskovan Tinderistä Tinder-bottien avulla. He määrittivät etäisyyden ihmisiin ja sitten heidän likimääräisen sijaintinsa.
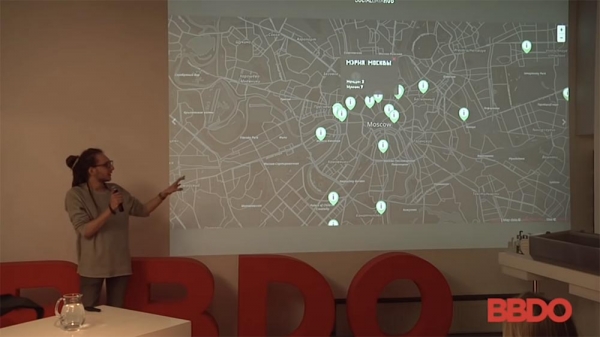
Tämän tutkimuksen tavoitteena oli selvittää Tinder-tilien lukumäärä valtion virastoissa – duumassa, syyttäjänvirastossa ja niin edelleen. Mutta mainostajana voit kuvitella sen miten haluat: se voisi olla esimerkiksi Starbucks tai joku muu... Eli niiden Tinderissä olevien ihmisten määrä, jotka juovat kahvia kanssasi, tilaavat jotain tai ovat kaupoissa. Maantieteellisen sijainnin osalta: tämä voidaan tehdä millä tahansa palvelulla.
Vastaus yleisön kysymykseen:
- Tinder? Etkö tiedä? Tinder on deittisovellus, jossa pyyhkäiset kuvien päällä vasemmalle ja oikealle, ja sovellus näyttää etäisyyden henkilöön. Jos saat etäisyyden henkilöön kolmesta eri kulmasta, voit karkeasti paikantaa hänen sijaintinsa (+5-7 metriä). Tässä tapauksessa ei ole niin vaikeaa paikantaa jotakuta syyttäjänviraston tai duuman tiloissa. Mutta toisaalta se voi olla oma kauppasi tai mikä tahansa muu paikka.
Esimerkiksi meillä oli kauan sitten samanlainen tapaus (ei tutkimus), jossa saimme matkaviestinoperaattorilta liikennetiheystietoja sekä tietoja tukiasemien liikkeistä. Nämä tiedot lisättiin moottoriteillä sijaitsevien mainostaulujen koordinaatteihin. Matkaviestinoperaattorin tehtävänä oli määrittää likimääräinen määrä ihmisiä, jotka ajavat näiden mainostaulujen läpi ja mahdollisesti näkevät ne.
Jos täällä on mainostaulumainonnan asiantuntijoita, voisitte sanoa: sitä on mahdotonta sanoa superluotettavasti – joku ajaa, joku ei katsonut, joku katsoi... Tämä on kuitenkin esimerkki siitä, miten 20 miljardia tällaista polygonia Moskovassa, jotka osoittavat näiden ihmisten tiheyden joka tunti tietyillä reiteillä... Voit nähdä, mitä nämä ihmiset ohittivat milläkin hetkellä, ja arvioida karkeasti matkustajavirran.
Vastaus yleisön kysymykseen:
- Kukaan ei tarjoa tällaista dataa. Teimme tällaisen tutkimuksen yhdelle operaattorille; se on puhtaasti sisäinen juttu, joten valitettavasti sitä ei esitetä kuvamuodossa. Mutta usein suurilla mainostoimistoilla ei ole ongelmia ottaa yhteyttä operaattoriin. Ainakin Moskovassa on monia ennakkotapauksia, joissa esimerkiksi vakuutusyhtiöt kääntyvät GetTaxin kaltaisten yritysten puoleen, jotka tarjoavat anonymisoitua tietoa kuljettajan iästä, ajotavoista (hyvä tai huono, holtiton tai ei) vakuutusmaksujen ennustamiseksi ja niin edelleen. Kaikki kamppailevat tämän kanssa, mutta jollain sisäisellä tasolla en usko, että kenelläkään on ongelmaa tarjota anonymisoitua dataa.
Kuvan ja kuvion tunnistus
Jatketaanpa. Suosikkini on kuvantunnistus. Ohjelmassa on lyhyt osio kasvojentunnistuksesta, mutta emme keskity siihen. Keskitymme erityisesti kuvantunnistukseen ja kuvan sisällön tunnistamiseen – auton merkkiin, väriin ja niin edelleen.

Minulla on hauska esimerkki:

Eräässä tutkimuksessa etsittiin tatuointeja eri sosiaalisen median alustoilta. Samaa voidaan siis soveltaa mihin tahansa brändiin, mihin tahansa visuaaliseen kuvaan, käytännössä mihin tahansa visuaaliseen kuvaan. Joitakin ei voida tunnistaa riittävällä varmuudella (emme käsittele niitä tässä).
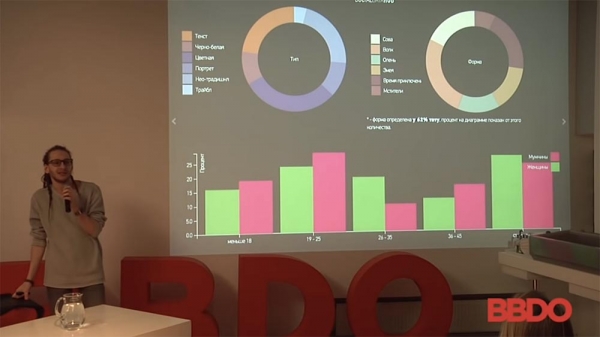
Tässä on suosikkini. Automerkit pyytävät usein tällaista tehtävää, koska niiden tavoitteena on esimerkiksi löytää kaikki BMW X6:n omistajat, ymmärtää keitä he ovat, miten he ovat sukua toisilleen, mitkä ovat heidän kiinnostuksen kohteensa ja niin edelleen. Tämä liittyy kysymykseen siitä, millaisilla autoilla ihmiset ottavat valokuvia sosiaalisessa mediassa.

Tässä ei ollut lainkaan suodatusta: kohde oli heidän, auto ei ollut heidän; se oli yksinkertaisesti autojen erittely – ikä ja niin edelleen. Mutta visuaalista kuvantunnistusta käytetään melko usein: tähän sisältyy raskaana olevien naisten etsiminen ja merkkilogojen etsiminen eri mediakanavista (kuka julkaisee mitä).

Lempiesimerkkini (jota useat ravintolat käyttävät): mitä rullia he julkaisevat sosiaalisessa mediassa. Se on hauskaa, mutta se itse asiassa antaa sinulle paljon tietoa asiakkaistasi: kuka tuli luoksesi ja miksi he tulivat niin. Koska ei ole mikään salaisuus, että sushibaareissa useimmat ihmiset (en sano "tytöt") ottavat valokuvia kirjautuakseen sisään, ottaa kuvia asioista jne.
Brändi voi hyödyntää tätä. He ovat kiinnostuneita siitä, mitä tuotteita heidän on valokuvattava ja esiteltävä kauniisti, ja millaiset ihmiset niillä kävivät. Tämä voidaan tehdä lähes minkä tahansa kanssa, alkaen ruoasta.
Kuvan tunnistus videossa
Vastaus yleisön kysymykseen:
- Ei videolla. Se on testitilassa. Kokeilimme tätä teknologiaa, mutta kävi ilmi, että... Se tunnistaa kaiken videosta aika hyvin, mutta emme ole löytäneet sille mitään sovellusta. Toistaiseksi. Sen lisäksi, että analysoitiin, kuinka paljon ja ketkä videobloggaajat puhuvat jossain... Oli olemassa sellainen tutkimus. Kuinka monen kasvonsa näkyvät, kuinka usein. Mutta emme ole vielä keksineet, missä toteuttaisimme sen brändeille. Ehkä jonain päivänä se tulee.
Jälleen kerran, kyse on ruoasta, se voi olla raskaana olevia naisia, miehiä (ei raskaana olevia), autoja – mitä tahansa.
Vaihtoehtoisesti oli olemassa uudenvuodentutkimus medialle. Sekin on kaukana mainonnasta, mutta silti. Se kertoo siitä, mistä ruoasta ihmiset julkaisivat uutena vuotena:

Se on myös jaoteltu iän mukaan. Voit nähdä korrelaation: nuoret tilaavat enimmäkseen ruokaa, kun taas aikuiset valmistavat enimmäkseen perinteisiä aterioita. Se on vitsi, mutta jos ajattelet asiaa brändinomistajana, voit arvioida monia asioita: kuka käyttää tuotteitasi ja miten, mitä ihmiset kirjoittavat niistä. Ihmiset eivät usein mainitse itse brändiä tekstissä, eivätkä perinteiset analytiikkajärjestelmät aina pysty havaitsemaan tätä brändimainintaa yksinkertaisesti siksi, ettei sitä mainita tekstissä. Tai teksti on kirjoitusvirheellinen, hashtagit puuttuvat tai mitä tahansa.
Voit nähdä valokuvat. Valokuvasta voit päätellä, onko se kuvan keskipiste vai ei. Sitten voit nähdä, mitä henkilö on kirjoittanut. Mutta useimmiten tätä käytetään löytämään potentiaalisia yleisöjä, jotka ovat ajaneet tietyillä autoilla ja niin edelleen. Ja sitten teemme paljon mielenkiintoisia asioita näillä autoilla.
Botteja koulutetaan matkimaan ihmisiä
Henkilöiden laskemiseen oli myös tämä vaihtoehto:

Ihmisten yhteensovittamiseen on olemassa menetelmä, jossa sinun on löydettävä ihmisiä valokuvien perusteella, ymmärrettävä heidän sosiaalisen median profiilinsa ja tunnistettava keitä he ovat. Palaamme jälleen siihen, että jos meillä on kamera kivijalkakaupassa, se on melko hyvä tapa ymmärtää, kuka tulee luoksesi, keitä he ovat, mitkä ovat heidän kiinnostuksen kohteensa ja mikä sai heidät tulemaan luoksesi.
Nyt tulee mielenkiintoisin osuus: jos keräämme heidän sosiaalisen median tilinsä, ymmärrämme keitä he ovat ja mitkä ovat heidän kiinnostuksen kohteensa, voimme (valinnaisesti) luoda botin, joka muistuttaa näitä ihmisiä. Tämä botti alkaa elää näiden ihmisten tavoin ja analysoida mainoksia, joita se näkee eri sosiaalisissa verkostoissa. Näin voimme ymmärtää melko tarkasti, mitkä brändit kohdistavat mainoksiaan tähän henkilöön. Tämä on myös melko yleinen tilanne, jossa on tarpeen analysoida paitsi kuka tämä henkilö on ja mitkä ovat hänen kiinnostuksen kohteensa, myös sitä, mitä mainoksia potentiaaliset kilpailijasi tai muut kiinnostuneet ihmiset kohdistavat häneen.

Sosiaalisen verkoston linkkianalyysi

Seuraava asia on mielenkiintoinen: ihmisten välisten yhteyksien analysointi. Verkoston yhteyksien varsinainen analysointi, nämä verkostograafit – siinä ei ole mitään uutta, kaikki tietävät sen.

Mutta tämän soveltaminen mainontaan on mielenkiintoisin osa. Kyse on ihmisten löytämisestä, jotka luovat trendejä, ihmisten löytämisestä, jotka levittävät tietoa tiettyjen kriteerien perusteella tietyssä verkostossa. Oletetaan, että olemme kiinnostuneita tietyn BMW-mallin omistajista. Kokoamalla heidät kaikki yhteen voimme löytää ne, jotka pitävät yleistä mielipidettä käsissään. Nämä eivät välttämättä ole autobloggaajia tai mitään vastaavaa. Tyypillisesti nämä ovat tavallisia ihmisiä, jotka käyvät usein erilaisissa julkisissa ryhmissä, ovat kiinnostuneita tietystä sisällöstä ja voivat hyvin lyhyessä ajassa vetää brändisi tai jonkun muun kiinnostuksen kohteen tälle vastuualueelle, sinun kiinnostuksen kohteeksesi.
Tässä on esimerkki. Meillä on joitakin potentiaalisia ihmisiä, ihmisten välisiä yhteyksiä. Oranssit ovat ihmisiä, pienet pisteet ovat yhteisiä ryhmiä, yhteisiä ystäviä.

Jos kaikki nämä yhteydet yhdistetään, voidaan nähdä hyvin selvästi, että on ihmisiä, joilla on suuri määrä yhteisiä ryhmiä, keskinäisiä ystäviä, ja he ovat siellä keskenään... Ja jos jaat tämän saman visualisoinnin ryhmiin kiinnostuksen kohteiden, jakaman sisällön ja toistensa kanssa tapahtuvan vuorovaikutuksen mukaan... Tässä näet, että edellinen kuva on muuttunut tältä:

Tässä ryhmät on selvästi erotettu värin mukaan. Tässä tapauksessa he ovat maisteriohjelmamme opiskelijoita Korkeammasta kauppakorkeakoulusta. Näet, että violetit/siniset ovat niitä, jotka tukevat Transparency Internationalia, Avointa Venäjää ja Hodorkovskin julkisia sivuja. Vasemmassa alakulmassa ovat vihreät, jotka tukevat Yhtenäistä Venäjää.
Kuten näet, edellinen kuva oli tällainen (yksinkertaisesti ihmisten välisiä yhteyksiä), mutta nyt se on selkeästi rajattu. Eli kaikki ihmiset ovat aina yhteydessä toisiinsa, heillä on samanlaisia kiinnostuksen kohteita, he ovat ystäviä keskenään. Jotkut ovat ylhäällä, toiset alhaalla, ja sitten on joitakin muita tovereita. Ja jos visualisoit jokaisen näistä pienistä alikehyksistä erikseen eri parametreilla ja tarkastelet sisällön jakelun nopeutta (karkeasti sanottuna kuka julkaisee mitä), voit löytää jokaisesta osiosta yhden tai kaksi ihmistä, jotka pitävät aina yleistä mielipidettä käsissään. Vuorovaikuttamalla heidän kanssaan, pyytämällä heitä jakamaan julkaisun tai jotain muuta, voit saada vastauksen koko tältä mielenkiintoiselta yleisöltä.
Minulla on toinen samanlainen esimerkki. Myös kaavio: nämä ovat BBDO Groupin työntekijöitä, jotka löytyvät esimerkkinä sosiaalisesta mediasta. Se näyttää epämielenkiintoiselta, isolta, vihreältä, ja heidän väliset yhteydet...

Mutta minulla on versio, jossa ryhmät on jo rakennettu heidän välilleen. Sitten, jos jotakuta kiinnostaa, on olemassa interaktiivinen versio – voit napsauttaa sitä ja katsoa.
Ylhäällä oikealla ovat ne, jotka rakastavat Putinia. Violetit ovat suunnittelijoita; niitä, jotka ovat kiinnostuneita suunnittelusta, kaikesta mielenkiintoisesta ja niin edelleen. Valkoiset ovat johtoryhmää (luulen, että näin ymmärsin sen); nämä ovat ihmisiä, jotka eivät ole oikeastaan millään tavalla yhteydessä toisiinsa, mutta työskentelevät suunnilleen samoissa tehtävissä. Loput ovat heidän yhteisiä ryhmiään, yhteyksiään ja niin edelleen.
Brändit eivät tarvitse bloggaajia, ne tarvitsevat mielipidejohtajia
Me löydämme nämä ihmiset, ja sitten mainostoimisto päättää itse: se voi maksaa tälle henkilölle tästä sisällöstä tai jostakin muusta, tai kohdistaa heidät omalla mainoskampanjallaan. Tätäkin käytetään melko usein, varsinkin nyt, koska kaikki brändit haluavat tehdä yhteistyötä bloggaajien kanssa, haluavat heidän mainostavan sisältöään, mutta mainostoimistot ovat haluttomia tekemään yhteistyötä (no, sitä tapahtuu).
Todellinen ratkaisu tähän ongelmaan on löytää ihmisiä, jotka eivät ole bloggaajia tai kauneusbloggaajia, vaan esimerkiksi oikeita ihmisiä, jotka ovat vuorovaikutuksessa brändin kanssa ja jotka voivat kirjoittaa jollekin huonolaatuiselle julkiselle sivulle nimeltä "Mail.ru Answers" ja saada tietyn määrän katselukertoja. Nämä ihmiset, jotka ovat jatkuvasti kiinnostuneita kyseisen henkilön sisällöstä, levittävät sitä, ja brändi saa sitoutumista.
Toinen tapa käyttää tätä teknologiaa, joka on nyt varsin ajankohtainen, on bottien etsiminen, suosikkini. Tämä voi aiheuttaa maineriskin kilpailijoillesi, suodattaa pois epäolennaisia ihmisiä mainoskampanjastasi ja tehdä kaikenlaisia muita asioita (kuten poistaa kommentteja ja löytää yhteyksiä ihmisten välillä). Minulla on tästä esimerkki, se on myös suuri ja vuorovaikutteinen – sitä voi siirtää. Se näyttää yhteyksiä "Lentach"-yhteisössä kommentoineiden ihmisten välillä.
Tässä on esimerkki, joka auttaa sinua ymmärtämään, kuinka helppoa bottien havaitseminen on; et tarvitse siihen edes teknistä tietämystä. Niinpä Lentach julkaisi viestin FBK:n Dmitri Medvedeviä koskevasta tutkinnasta, ja tietyt ihmiset alkoivat kommentoida. Olemme koonneet listan kaikista kommentoijista – nämä ovat aloittelijat. Näytänpä teille:

Ihmiset ovat vihreitä (jotka kirjoittivat kommentteja). He ovat täällä, he ovat täällä. Siniset pisteet heidän välissään ovat heidän jaettuja ryhmiään, keltaiset ovat heidän jaettuja tilaajiaan, ystäviään ja niin edelleen. Se on suurin osa yhteydessä olevista ihmisistä. Koska, olipa kolmen, neljän tai viiden asteen eristäytymisen teoria mikä tahansa, kaikki ihmiset ovat yhteydessä sosiaalisessa mediassa. Kukaan ei ole eristyksissä toisistaan. Jopa sosiaalisesti fobiset ystäväni, jotka käyttävät VKontaktea yksinomaan videoiden katseluun, tilaavat silti joitakin samoja julkisia sivuja kuin me.
Navalnyi käyttää myös botteja. Kaikilla on botteja.
Suurin osa ihmisistä (tässä he ovat) ovat yhteydessä toisiinsa. Mutta on pieni ryhmä tovereita, jotka ovat ystäviä yksinomaan keskenään. Tässä he ovat, vihreät, ja tässä ovat heidän yhteiset ystävänsä ja ryhmänsä. He ovat jopa haarautuneet erikseen tänne:

Ja onnekkaan sattuman kautta nämä samat ihmiset kirjoittivat juuri tämän julkaisun alle "Navalnyilla ei ole todisteita" ja niin edelleen, jättäen identtisiä kommentteja. En todellakaan tee hätiköityjä johtopäätöksiä. Minulla oli kuitenkin toinenkin julkaisu Facebookissa Lebedevin ja Navalnyiin välisen väittelyn aikana, ja analysoin kommentit samalla tavalla: kävi ilmi, että kaikki "Lebedev on paska" -kirjoittaneet eivät olleet kirjautuneet sosiaaliseen mediaan viimeisten neljän kuukauden aikana, eivätkä olleet tilanneet mitään julkisia sivuja, törmäsivät yhtäkkiä tähän tiettyyn julkaisuun, kirjoittivat tämän tietyn kommentin ja sitten lähtivät. Jälleen kerran, tästä ei voi tehdä johtopäätöksiä, mutta joku Navalnyiin tiimistä kommentoi, etteivät he käytä botteja. No jaa!
Lähempänä mainontaa, lähempänä brändiä. Nykyään kaikilla on botteja! Meilläkin on niitä, kilpailijoillamme on niitä, ja niin on joillakin muillakin. Ne pitäisi heittää pois tai säilyttää, jotta ne voivat menestyä; tämän datan perusteella (viitaten edelliseen diaan) meidän pitäisi hioa niitä täydellisiksi, jotta ne näyttäisivät oikeilta ihmisiltä, ja vasta sitten meidän pitäisi käyttää niitä. Vaikka bottien käyttö onkin huono asia! Siitä huolimatta se on melko yleinen tarina...
Automaattisessa tilassa tämän ominaisuuden avulla voit suodattaa analyysistäsi pois epäolennaiset ihmiset, ihmiset, joiden ei pitäisi olla mukana otoksessa, ihmiset, joiden ei pitäisi olla mukana tässä tutkimuksessa. Sitä käytetään hyvin usein. Jälleen kerran, kaikki auton omistajat eivät itse asiassa omista autoa. Joskus olet kiinnostunut vain ihmisistä, jotka mahdollisesti omistavat auton, jotka kuuluvat tiettyihin ryhmiin, jotka kommunikoivat muiden kanssa ja joilla on siellä tietty yleisö.
Faktojen ja mielipiteiden analyysi
Seuraava asia, joka minulla on, on myös suosikkini. Se on faktojen ja mielipiteiden analyysi.

Nykyään kaikki tietävät, miten brändinsä mainitaan eri lähteissä. Siinä ei ole mitään salaisuutta. Ja näyttää siltä, että kaikki tietävät, miten mielipidettä mitataan... Vaikka henkilökohtaisesti en usko, että mielipidemittari itsessään on kovin mielenkiintoinen, koska kun tulet asiakkaan luo ja sanot hänelle: "Kaveri, sinulla on 37 % neutraalius", ja hän vastaa: "Vau! Siistiä!" Olisi siis mielenkiintoisempaa siirtyä hieman pidemmälle: mielipiteen arvioinnista ihmisten tuotteestasi sanomien mielipiteiden arviointiin.
Ja tämä on myös hyvin mielenkiintoinen asia, koska... henkilökohtaisesti uskon, että neutraalit viestit ovat periaatteessa mahdottomia, koska jos joku kirjoittaa jotain julkisessa tilassa, tuo viesti on väistämättä jollain tavalla tahraantunut. En ole henkilökohtaisesti koskaan nähnyt neutraalia viestiä, jossa mainittaisiin tietty brändi. Yleensä se on jonkinlaista panettelua.
Jos otamme suuren määrän näitä viestejä (niitä voi olla miljoonia, jopa 10 miljoonaa), poimimme kustakin viestistä pääajatuksen ja yhdistämme ne, voimme ymmärtää varsin luotettavasti, mitä ihmiset sanovat tästä tuotemerkistä ja mitä he ajattelevat. "En pidä pakkauksesta", "En pidä koostumuksesta" ja niin edelleen.
Mitä ihmiset ajattelevat Transaerosta, tikkarista ja Yhdysvaltain presidentistä?
Minulla on hauska esimerkki: tämä infografiikka siitä, mitä sosiaalisen median käyttäjät tekisivät Transaerolle sen konkurssin jälkeen.

Mielenkiintoisia esimerkkejä on monia: polttaa, tappaa, karkottaa Eurooppaan; jopa 2 % kirjoitti: "Lähettäkää heidät Syyriaan taistelemaan." Naurettavasta eteenpäin, se voisi olla käytännössä mikä tahansa merkki – lempikoiranruoastani autoihin. Ne, jotka eivät pidä pakkauksesta, ne, jotka eivät pidä aidosta tuotteesta – he voivat aina työskennellä sen kanssa, heidät voidaan aina ottaa huomioon. On lukuisia esimerkkejä ihmisistä, jotka käytännössä muuttivat tuotteidensa tuotantoa, koska he kirjoittivat sosiaalisessa mediassa, että tikkari ei ollut tarpeeksi pyöreä tai makea.
Tässä on toinen hauska esimerkki. Arvaa, mitä kommentit ovat ja keitä ne koskevat?

Jostain syystä mielipideanalyysi, eli viestien faktojen analysointi, ei ole tällä hetkellä laajalti käytössä tai yleistynyt. Vaikka tämä teknologia ei olekaan huippusalaista, sen takana ei ole käytännössä mitään tietotaitoa, koska subjektin, predikaatin ja niiden ryhmittelyn erottaminen ihmisten kommenteista – ei tarvitse olla laskennallisen kielitieteen nero tehdäkseen sitä. Se ei ole niin vaikeaa. Mutta toivon, että ihmiset alkavat käyttää sitä seuraavan parin vuoden aikana, koska... Se on mahtavaa – tällainen automaattinen palaute! Tiedät aina, mitä ihmiset sanovat sinusta. No, tiedäthän, se tehtiin Yhdysvaltain presidentistä.
Vastaus yleisön kysymykseen:
- Kyllä, tämä on Facebook englanniksi. Ne on käännetty venäjäksi täällä. Tämä on kirjoitettu jossain.
Big Data ja poliittiset teknologiat
Minulla on itse asiassa monia mielenkiintoisia poliittisia esimerkkejä Trumpista ja kaikista muista, mutta päätimme olla sisällyttämättä niitä tähän. Mutta yksi poliittinen esimerkki on olemassa.
Nämä ovat duuman vaalit. Milloin ne olivat? Viime vuonna? Lähes puolitoista vuotta sitten.
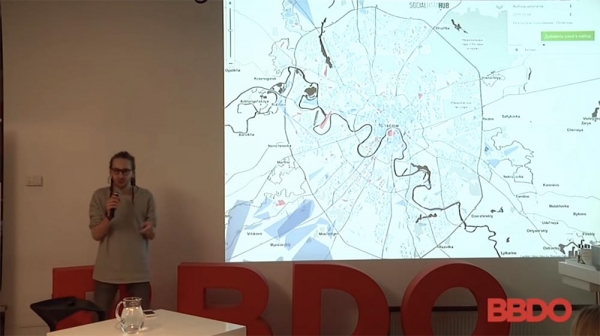
Tässä on ihmisiä, joiden tarkka sijainti määritettiin tiettyyn geolokaatiopisteeseen asti, jotta voitiin määrittää, mihin äänestyspaikkaan he kuuluvat. Mukana olivat vain ne, jotka ilmaisivat tietyn mielipiteen siitä, ketä he äänestäisivät.
Poliittisen strategian näkökulmasta tämä ei ole aivan oikein, koska koko juttu on mukautettava väestötiheyden ja niin edelleen mukaan. Siitä huolimatta siniset äänestäjät täällä aikovat äänestää tiedättehän-ketä ja punaiset äänestäjät oppositiotovereita, joita ei muuten ollut montaa.
Henkilökohtaisesti uskon, että Big Datan soveltaminen poliittiseen teknologiaan on vielä kaukana, mutta ehdokas on myös brändi. Ja tämä on jossain määrin analyysi faktoista ja mielipiteistä heidän brändistään, ja se on varsin mielenkiintoista, koska siitä voi ymmärtää reaaliajassa, kuka tekee mitä. Tiedän useita tapauksia BBC:llä, joissa he seurasivat sosiaalista mediaa reaaliajassa lähetyksen aikana: tällaista vastausta, ihmiset kirjoittivat siitä, kysyivät tällaista kysymystä – ja se on fantastista! Uskon, että tätä tullaan käyttämään hyvin pian, koska se on kiinnostavaa kaikille.
Brändiasemien mallintaminen

Seuraavaksi aion mallintaa brändien asemointia. Lyhyt ja nopea katsaus siihen, miten brändejä voidaan asettaa järjestykseen erilaisten mittareiden avulla (ei vain sosiaalisen median tykkäysten, vaan monimutkaisten mittareiden, sisällön kiinnostuksen ja mittareiden keräämiseen käytetyn ajan avulla).

Minulla on esimerkki tietylle brändille, "Pharma". Pienet, kirkkaanväriset ympyrät sisällä edustavat brändin itse luoman tekstisisällön määrää ja suuri ympyrä edustaa brändin itse luoman kuva- ja videosisällön määrää.
Läheisyys keskustaan osoittaa, kuinka kiinnostavaa tämä sisältö on yleisölle. Se on laaja malli, jossa on joukko erilaisia mittareita: tykkäykset, uudelleenjulkaisut, vastausaika, keskimääräinen jakaja... Tässäpä esimerkki: on upea Kagocel, joka investoi valtavasti rahaa oman sisällön luomiseen, ja tämän vuoksi he ovat melko lähellä keskustaa. Sitten on muita, jotka myös luovat omaa sisältöään, mutta yleisö ei ole siitä kiinnostunut. Tämä ei ole kovin tarkka esimerkki, koska kaikki nämä tilit ovat käytännössä kuolleita.
Jegor Creediä rakastetaan enemmän kuin Bastaa

Valitettavasti loput... sen perusteella mitä voidaan näyttää... Täällä on myös venäläisiä räppäreitä, vaihtoehtona, oikeilta yrityksiltä.
Mikä on etu? Se, että yritys voi ottaa tähän malliin mukaan käytännössä mitä tahansa, alkaen brändisi tilaajien keskipalkasta; minkä tahansa mallin he haluavat. Koska jokainen mainostoimisto laskee omat mittarinsa eri tavalla, ja brändit laskevat omat mittarinsa eri tavalla.
On myös eräs Bastan kaltainen henkilö, joka tuottaa paljon sisältöä, mutta on marginaalissa, koska se ei ilmeisesti ole kovin kiinnostavaa yleisölle. Jälleen kerran, en ole tuomari. Mutta on myös Yegor Creed, joka sosiaalisen median mukaan on käytännössä yksi aikamme parhaista esiintyjistä, mutta hän julkaisee vain henkilökohtaisia kuvia itsestään. Hänellä on kuitenkin suuri seuraajakunta: noin miljoona ihmistä. En muista tarkkaa lukua; muistan, että hänen sitoutumisprosenttinsa on paljon korkeampi kuin 85 %, mikä tarkoittaa, että jokaista miljoonaa seuraajaa kohden hän saa 850 000 vastausta oikeilta ihmisiltä – se on todella hullua. Se on totta.

Vastauksia yleisön kysymyksiin:
Kuinka kauan räppärianalyysimallin kehittäminen kesti?
- Jokaisella on oma kohdeyleisönsä, omat kiinnostuksen kohteensa ja laskelmansa jokaiselle... Kaikki tämä on standardoitu likimääräisen etäisyyden perusteella keskipisteeseen; niiden säteittäisellä sijainnilla ei ole merkitystä (se on vain levitetty tähän esteettisistä syistä, jotta ne eivät ole päällekkäisiä). Vain niiden likimääräinen läheisyys keskipisteeseen on tärkeää. Tämä on käyttämämme malli. Esimerkiksi minä pidän enemmän ympyrästä; jotkut käyttävät puoliympyrää.
- Tämä malli koottiin nopeasti, kahdessa tai kolmessa tunnissa (kyllä, yhden ihmisen toimesta). Kyse oli mittareista: mitä kerrotaan millä, lasketaan yhteen ja sitten jotenkin standardoidaan. Se riippuu mallista. Jotkut ihmiset ovat kiinnostuneita seuraajiensa keskipalkasta (ei vitsi). Ja sitä varten sinun on löydettävä heidän yhteystietonsa, Avito, laskettava kaikki ja kerrottava ne. Joskus sen laskeminen vie kauan, mutta tässä nimenomaisessa (viittaukset edelliseen diaan) on hyvin yksinkertaiset parametrit: seuraajat, uudelleenjulkaisut ja niin edelleen. Sen kokoaminen kesti noin kaksi tai kolme tuntia. Joten tämä asia päivitetään sitten reaaliajassa, ja se on käyttövalmis.
Nyt tulee mielenkiintoisin osuus. Esimerkit ovat loppuneet, koska ei ole mielenkiintoista puhua pitkään yksin. Ja toivon, että kysytte nyt kysymyksiä, ja siirrymme aiheesta toiseen, koska minulla on esimerkkejä siitä, miten teknologioita voidaan käyttää ja niin edelleen...
Vastauksia yleisön kysymyksiin:
- Minulla oli yksi henkilökohtainen tapaus niin sanotusta "kasinomaisesta" paikasta, johon he asensivat kameran, käyttivät kasvojentunnistusta ja niin edelleen. Tunnistettujen ihmisten prosenttiosuus on ehdottomasti melko korkea – sekä meidän että kilpailijoidemme. Mutta se on itse asiassa aika mielenkiintoista. Näen sen mielenkiintoisena asiana: voit ymmärtää, keitä nämä ihmiset ovat, ja ennustaa melko hyvin, miksi he tulivat sinne, mikä heidän elämässään muuttui, mikä sai heidät päättämään tulla kasinolle. Mutta mitä tulee tietyntyyppisiin yrityksiin... Jos asentaisit tällaisen laitteen apteekkiin, siinä ei ole mitään järkeä – et voi ennustaa, miksi joku tulisi apteekkiin alun perin.
Suurin haaste tässä oli rakentaa malli, joka ymmärtäisi, milloin joku saattaisi olla kiinnostunut brändistäsi, jotta voisit kohdistaa heille mainoksia ei vasta sen jälkeen, kun he ovat jo ostaneet jotain (kuten nykyään on tapana), vaan pikemminkin "ennustaa", milloin se todella tapahtuu. Oli mielenkiintoista, että tämä "kasinomainen" asetelma oli; näitä ihmisiä oli melko mielenkiintoinen prosenttiosuus – miksi: jotkut saivat äkillisen tarjouksen, toiset jotain muuta – ne ovat mielenkiintoisia näkemyksiä. Mutta tiettyjen kauppojen, vähittäiskaupan, lääkekaupan kohdalla se ei mielestäni olisi aivan oikein.
Käytetäänkö Big Dataa offline-tilassa?
- Se oli offline-tilassa. Sinun tarvitsee vain ymmärtää tarkalleen, karkeasti, toimiiko tämä malli vai ei. Jälleen kerran, kivennäisveden kanssa... Olen aidosti kiinnostunut kaikesta, mutta en henkilökohtaisesti ymmärrä, missä määrin näiden ihmisten profiilit ja heidän käyttäytymisensä voivat riippua siitä, milloin he haluavat ostaa pullotettua vettä. Vaikka se saattaakin pitää paikkansa, en tiedä.
Kuinka monta avointa sosiaalisen median tiliä sinulla on?
- Meillä on 11 tiettyä sosiaalista verkostoa: VKontakte, Facebook, Twitter, Odnoklassniki, Instagram ja joitakin muita pieniä (voin katsoa listaa, kuten Mail.ru ja niin edelleen). Meillä on ehdottomasti kopio kaikista näistä ihmisistä VKontaktessa. Meillä on ihmisiä VKontaktessa – 430 miljoonaa kaikista koskaan eläneistä ihmisistä (joista noin 200 miljoonaa on jatkuvasti aktiivisia); on ryhmiä, näiden ihmisten välillä on yhteyksiä, ja on sisältöä, joka kiinnostaa meitä (tekstiä), ja jonkin verran mediaa, mutta hyvin pieni osa... Karkeasti sanottuna katsomme tätä kuvaa: jos on kasvoja, tallennamme ne; jos on meemejä, emme tallenna niitä, koska edes meillä ei olisi tarpeeksi resursseja mediasisällön tallentamiseen.
On olemassa venäjänkielinen Facebook. Tällä hetkellä Odnoklassniki on noin 60–80 % käyttäjistä; parin kuukauden kuluttua pääsemme luultavasti kaikkiin. On olemassa venäjänkielinen Instagram. Kaikissa näissä sosiaalisissa verkostoissa on ryhmiä, ihmisiä, yhteyksiä niiden välillä ja tekstiviestejä.
- Noin 400 miljoonaa ihmistä. Tässä on hienovarainen yksityiskohta: on ihmisiä, joiden kaupunkia ei ole listattu (he ovat mahdollisesti venäläisiä/ei-venäläisiä); näistä keskimäärin sosiaalisissa verkostoissa – esimerkiksi VKontaktessa – 14 % on yksityisiä tilejä; en tiedä tarkkaa lukua Facebookin osalta.
- Emme tallenna mediaa Instagramissakaan – vain jos se sisältää kasvoja. Emme tallenna tuota (muuta) mediasisältöä. Yleensä olemme kiinnostuneita vain tekstistä, ihmisten välisistä yhteyksistä – siinä kaikki. Yleisin Instagram-tutkimus on tavanomainen yleisötutkimus: keitä nämä ihmiset ovat ja ennen kaikkea heidän yhteytensä muihin sosiaalisiin verkostoihin. Tämän henkilön profiilin löytäminen VKontaktesta ja Facebookista on hyödyllistä hänen ikänsä laskemisessa ja niin edelleen.
- Ei ole vielä tarvetta ottaa kaikkia muita palvelukseen – yksinkertaisesti siksi, ettei asiakkaita ole. Kielen osalta: meillä on venäjä, englanti ja espanja, mutta niitä käytetään edelleen yksinomaan venäläisille tuotemerkeille tai ainakin yrityksille, jotka operoivat niitä Venäjältä.
- Kyselemme ihmisiä päivittäin lukemattomissa ketjuissa: keräämme dataa kaapimalla verkkoa ja päivitämme näitä mittareita API-rajapintojen avulla. Kahdessa tai kolmessa päivässä voi käydä läpi koko VKontakte-verkoston; noin viikossa voi käydä läpi koko Facebook-verkoston ja ymmärtää, kuka on päivittänyt mitä ja kuka ei. Ja sitten kokoamme nämä ihmiset erikseen: mikä tarkalleen ottaen muuttui, ja tallentamme koko historian. Muistini mukaan on hyvin harvinaista, että jonkun vanhaa sosiaalisen median profiilia olisi käytetty mihinkään todelliseen liiketoimintaan. Näin tapahtui kerran, kun eräs poliittinen hahmo otti meihin yhteyttä, ja hänen tehtävänään oli ymmärtää, millaisia ihmisiä kampanjakeskukseen tuli ja keitä he olivat 6–8 kuukautta sitten (poistivatko he profiilinsa ja äänestivätkö he itse asiassa toista ehdokasta vai tulivatko he pilaamaan äänestyslippuja).
Ja pari kertaa – henkilökohtaisia tarinoita, kun jonkun kuvia julkaistiin julkisesti. Oli tarpeen löytää yhteyksiä jne. Valitettavasti se on sääli, mutta emme voi todistaa oikeudessa, koska tietokantaamme ei voida laillisesti käyttää.
- MongoDB-tallennustila on suosikkini.
Sosiaaliset verkostot yrittävät torjua tiedonkeruuta.
- Yleensä tarjoamme mainostajille vain luettelon näistä tileistä, ja sitten he käyttävät standardia... Eli sosiaalisissa verkostoissa, kuten VKontakte, voit määrittää luettelon näistä ihmisistä.
Mutta Facebook käyttää ostettuja evästeitä. Emme itse käytä evästeitä, mutta on ollut muutamia tapauksia, joissa mainostajat ovat toimittaneet evästeitä tietyille ihmisille, ja olemme olleet heidän kanssaan vuorovaikutuksessa – heillä on näitä verkostoja, joissa on teaser- ja ei-teaser-mainoksia, näitä evästeitä. Linkittäminen on mahdollista – ei ongelmaa! Mutta en ole näiden asioiden suuri fani, koska mielestäni ne eivät ole kovin luotettavia. Mielestäni se on kuin TNS:n televisioiden seuranta – ei ole selvää, katsotko televisiota, et katso sitä, vai tiskatko astioita television ollessa päällä... Ja sama pätee tässä: googlaan usein jotain, mutta se ei tarkoita, että haluaisin ostaa sen.
- Jos käytät tavallista kontekstuaalista mainosverkostoa, olen kuullut useita kertoja, joissa olemme yrittäneet linkittää näitä ihmisiä heidän sivustojensa evästeisiin heidän käyttöliittymiensä kautta. Mutta en ole tuollaisten asioiden suuri fani.
Internetin käyttäjän palkan laskentakaava
- Keskipalkan yleinen kaava on: alue, jolla henkilö asuu, liiketoimintaluokka, jossa hän työskentelee (eli yritys, joka on hänen työnantajansa), sitten otetaan hänen asemansa tässä yrityksessä, arvioidaan tämän tehtävän keskipalkka... Keskipalkka otetaan Head Hunterista ja Superjobista (ja useista muista lähteistä) tietylle avoimelle työpaikalle tietyllä alueella ja tietyssä liiketoimintaympäristössä.
Avito ja Avto.ru tarjoavat yleensä lisätietoja, jos henkilö on paljastanut puhelinnumeronsa. Aviton avulla voit nähdä, millaisia tavaroita henkilö myy – kalliita, halpoja, käytettyjä vai ei. Avto.ru:n avulla voit nähdä, omistaako henkilö auton – omistaako hän sellaisen vai ei. Tämä edustaa alle 20 % ihmisistä, jotka vahingossa pudottivat puhelimensa jonnekin, ja heidän tilinsä voidaan linkittää näihin tietoihin.
Minkälaisia määriä tiedonkeruuyritys käsittelee?
- Tallennettujen valokuvien määrä petatavuina on 6,4. En osaa sanoa tarkalleen, kuinka nopeasti se kasvaa juuri nyt, koska vuonna 2016 aloitimme "periskooppien" tallentamisen ja olemme vasta aloittaneet videon tallennuksen.
En osaa sanoa tarkalleen, milloin se oli nolla. Siirryimme yrityksestä toiseen – se on pitkä tarina. Mutta voin sanoa, että VK, Facebook, Instagram ja Twitter – kaikki se (ihmiset, ryhmät ja heidän väliset yhteydet) tekstin ja sisällön kera – ei oikeastaan ole niin paljon dataa, tuskin edes petatavua. Luulen, että se on noin 700, ehkä 800 gigatavua.
Autatko asiakkaita tunnistamaan asiaankuuluvan markkinaraon ja mistä etsiä?
- Kun asiakas tulee, ehdotamme hänelle tällaisia asioita, mutta emme itse, kuten Google Trends, tee sellaisia.
- Meillä on ollut useita sosiologiaan liittyviä tarinoita, mukaan lukien vaaleihin ja vaaleja edeltäviä tarinoita – olemme analysoineet ne kaikki. Brändeissä ja brändimielipidearvioissa kaikki melkein aina täsmää. Mutta vaaleihin ja vaaleja edeltävissä tarinoissa – ne eivät (ja niissä ei ole arvioita siitä, minkä ehdokkaan pitäisi voittaa). En tiedä, kuka tässä on väärässä – me vai VTsIOM:n tutkimusta tekevät ihmiset.
- Yleensä saamme nämä vertailutulokset brändiltä itseltään, ja he saavat ne tutkimuksen tilaajilta – puhelinkyselyiltä, markkinatutkimuksilta ja niin edelleen. Lisäksi kaikki tämä voidaan varmistaa perusasioilla: vastasiko joku uutiskirjeeseen tai täyttikö joku kyselyn... Jos kyseessä on suuri brändi (esimerkiksi Coca-Cola), heillä on varmasti miljoona tai kaksi omaa sisäistä asiakasarvostelua – ei vain kommentteja sosiaalisessa mediassa ja mielipiteitä; heillä on sisäiset järjestelmät, palaute ja niin edelleen.
Laki ei "tiedä", mitä henkilötiedot ovat!
- Analysoimme yksinomaan avoimia datalähteitä emmekä koskaan perehdy mihinkään epäpuhtaaseen tai likaiseen tietoon. Mallimme perustuu siihen, että tallennamme kaiken avoimen datan julkisiin datakeskuksiin tai vuokraamme sen muualta ja analysoimme sen itse omilla palvelimillamme toimistoissamme emmekä koskaan poistu tiloistamme.
Mutta avoimen datan lainsäädäntömme on hyvin epämääräinen.
Meillä ei ole selkeää käsitystä siitä, mitä avoin data on, mitä henkilötieto on – on olemassa liittovaltion laki 152, mutta silti... Miten he laskevat sen? Eli jos minulla on nimesi ja puhelinnumerosi yhdessä tietokannassa, puhelinnumerosi ja sähköpostiosoitteesi toisessa ja sähköpostiosoitteesi ja autosi kolmannessa – kaikki tämä vaikuttaa ei-henkilökohtaiselta tiedolta. Jos kaikki tämä yhdistetään, näyttää siltä, että lain mukaan siitä tulee henkilötietoa.
Kierrämme tämän kahdella tavalla. Ensinnäkin asennamme palvelimia asiakkaan ohjelmistoilla, jotta nämä tiedot eivät poistu heidän alueeltaan, ja sitten asiakas on vastuussa näiden henkilötietojen, ei-henkilökohtaisten tietojen ja niin edelleen levittämisestä. Tai toiseksi, jos kyseessä on jonkinlainen tilanne, jossa meidän on haastava sosiaalinen verkosto oikeuteen tai jotain vastaavaa...
Teimme tällaisen tutkimuksen (Yhtenäisen Venäjän esivaalien aikana), jossa keräsimme näiden kavereiden LifeNews-tilit ja katsoimme heidän tykkäämäänsä pornoa. Se oli hauska juttu, mutta silti. Myymme sitä omana henkilökohtaisena mielipiteenämme paljastamatta laillisesti asiakirjoissa, mitä analysoimme – yhtenäistä valtion oikeushenkilörekisteriä, palkkoja, sosiaalista mediaa. Myymme asiantuntijalausuntoamme ja sitten kulissien takana selitämme henkilölle, mitä analysoimme ja miten.
Muutamia tarinoita oli, mutta ne liittyivät julkisiin kaupallisiin projekteihin. Meillä on esimerkiksi ilmainen, voittoa tavoittelematon projekti longboardaajille (tällaiset longboardit): tavoitteena oli kerätä ihmisten julkaisuja – kun joku julkaisee "Menin Gorkin puistoon luistelemaan", se näkyisi kartalla ja heidän ympärillään olevat ihmiset näkisivät, että joku oli lähellä. VK riiteli kanssamme tästä pitkään, koska he eivät pitäneet siitä, että julkaisimme näitä tietoja ilman ihmisten lupaa. Mutta tapaus ei mennyt oikeuteen, koska lisäsimme useiden suurten yhteisöjen sääntöihin lausekkeen, joka salli tietojen käytön kolmansille osapuolille, virastoille, yrityksille analysointitarkoituksiin ja niin edelleen. Se ei tietenkään ollut erityisen eettistä, mutta silti. - Heräsimme juuri ajoissa ja aloimme myydä asiantuntijalausuntoamme kaikille.
Työskenteletkö oppilaitosten kanssa?
- Kyllä, teemme yhteistyötä oppilaitosten kanssa. Meillä on niitä laaja valikoima: meillä on maisteriohjelma jatko-opinnoissa ja teemme yhteistyötä muiden yliopistojen kanssa. Me todella rakastamme yliopistoja!
- Minulla on yhteystietoni – voitte kirjoittaa minulle. Ja tässä on linkki esitykseen, jos joku on kiinnostunut – siinä on kaikki nämä esimerkit, voitte jakaa ne.
- Jos puhelinnumero ja sähköpostiosoite ovat tiedossa, se on lähes varma asia; kukaan ei poista niitä. Jos puhelinnumeroa ei ole, se on yleensä kuva; jos kuvaa ei ole, se on vuosi, asuinpaikka ja työpaikka. Eli lähes kaikki voidaan aina tunnistaa melko tarkasti vuoden, asuinpaikan ja työpaikan perusteella. Mutta tämäkin riippuu tehtävästä.
Oletetaan, että meillä on asiakas, joka myy internet-televisiota. Joku on ostanut "Game of Thronesin" tilauksen, ja tehtävänä on käyttää heidän CRM-järjestelmäänsä löytääkseen nämä ihmiset sosiaalisesta mediasta ja sitten löytääkseen potentiaalisia liidejä heidän vaikutuspiiristään. Sanon vain, että heillä on esimerkiksi etunimi, sukunimi ja sähköpostiosoite... Joten on erittäin vaikea tehdä mitään muuta. Useimmissa tapauksissa ihmisiä voi löytää sähköpostiosoitteen perusteella.
- Yleensä "yhdistämme" ihmisiä heidän sosiaalisen median kavereidensa perusteella, mutta tämä ei ole aina oikein. Ei ole kyse vain siitä, etteikö se aina olisi oikein – se ei aina toimi. Ensinnäkin se on työlästä, koska tämä yhdistämisprosessi on tehtävä ensin jokaiselle ystävälle – sen määrittämiseksi, ovatko he siirtyneet sosiaalisesta mediasta. Ja sitten on se tunnettu tosiasia, että meillä on joitakin ystäviä VKontaktessa ja muita ystäviä Facebookissa. Näin ei ole kaikkien kohdalla, mutta se on totta esimerkiksi minulle; ja se on totta useimmille ihmisille myös.
Miten keräät kattavimmat tiedot?
- Asentamalla ohjelmiston asiakkaan päähän. Heidän päähän asennetaan palvelin, joka kerää meiltä vain julkisia tietoja, mutta käsittelee sisäisesti heidän henkilötietojaan. Asiakkaan kanssa allekirjoitetaan salassapitosopimus. Ei ole täysin oikeudenmukaista, että he jakavat tätä kanssamme, mutta oikeudellinen vastuu on asiakkaalla – joko asentamalla ohjelmiston tai siirtämällä anonyymejä tietoja. Tämä oli kuitenkin hyvin harvinaista, koska – olipa anonymisointi oikein tai väärin – useimmissa tapauksissa yhteys näiden ihmisten välillä katkeaa.
Kuka ostaa kasvojentunnistusohjelmistoja?
- Tulemme tänne itse asiassa siksi, että myymämme ohjelmisto on pääasiassa kasvojentunnistus ja parisuhdeanalyysi, ja myymme sitä valtion virastoille. Niinpä puolitoista vuotta sitten päätimme työntää kaikki nämä tarinat mainontaan, markkinointiin ja julkisille markkinoille – näin perustettiin Social Data Hub, kaupallinen oikeushenkilö. Ja niin me vasta nyt tulemme tänne. Olemme hengailleet täällä puolitoista vuotta yrittäen selittää ihmisille, ettei heille pitäisi antaa latauksia mainintojen kera, että heille pitäisi antaa vastauksia kysymyksiinsä, ettei sävylle ole tarvetta ja niin edelleen. Joten on vaikea sanoa, missä...
- (Ketä tarkoitat?) Kaikille tovereille, joiden täytyy etsiä terroristeja, pedofiilejä.
Voin sanoa heti (tämä on seuraava kysymys): tietojemme mukaan yhtäkään opettajaa ei vangittu uudelleenjulkaisusta. - VKontaktessa se on 14 %; Facebookissa ei ole suljettua profiilia (heillä saattaa olla suljettu ystävälista jne.). Ja mielenkiintoisinta on, että juuri kirjoitin viestin – he laskevat sen ja kertovat sinulle.
Älä julkaise mitään, mitä häpeät!
- Älä julkaise sosiaalisessa mediassa mitään, mistä häpeät – se on henkilökohtainen ohjeeni. Vaikka minulla on ollut paljon henkilökohtaisia, koska kiroilen Facebookissa. No, sitä se on ollut, mitäpä sille voi? Älä julkaise mitään, mistä häpeät! Jos aiot myöhemmin työskennellä Yleisölle, kyllä, on parasta olla kommentoimatta. Jos et aio tehdä niin, niin silloin ketään ei yleensä kiinnosta. Voin vain vakuuttaa, ettei kukaan lue henkilökohtaista kirjeenvaihtoasi, ja kaikki tämä eskaloituminen vain pahentaa tätä koko juttua...
Joka viikko, poikkeuksetta, joku tulee luokseni ja sanoo: "Katso, ystäväni kuvat vuodettiin johonkin nimettömään julkiseen ryhmään! Apua!" Muuten, älä koskaan julkaise mitään nimettömiin julkisiin ryhmiin.
- En tiedä muista valvontajärjestelmistä – otamme ehdottomasti huomioon, että brändimaininta oli negatiivinen, Jumala armahtakoon... Mutta voin sanoa, että kaikki nämä hallitukseen kytköksissä olevat ihmiset ovat kiinnostuneita vain yli 5 000 ihmisen yleisöstä, ja heidän mielipiteensä voi vaikuttaa johonkuhun. Kokemukseni mukaan yksikään HR-toimisto, joka on tilannut meiltä profiilien arvioinnin, ei ole koskaan sanonut: "Jos joku pitää Navalnysta, älkää palkatko minua!"
Tulosten julkaisemisesta. Kuinka monta ihmistä on mukana tutkimuksessa?
- Kymmenestä parhaasta mainostoimistosta seitsemän julkaisee tällä hetkellä. Vaikea sanoa: kun aloitimme tämän puolitoista vuotta sitten... Meillä on useita ihmisiä jokaisella alalla – muutama pankeissa, muutama henkilöstöhallinnossa, muutama mainonnassa. Ja nyt mietimme, kenelle on kannattavinta mennä ensin, kenelle meidän pitäisi alkaa kehittää käyttöliittymiä...
- (noin ihmisten lukumäärä markkinasegmenttiä kohden) Enintään 25 ihmistä, koska emme raiskaa ketään.
- Yleisesti ottaen uskon, että yli 50 % markkinoista käyttää näitä teknologioita. Joitakin käytetään mainoskampanjoissa, toisia sisäiseen analytiikkaan. Sanoisin, että 40 % käyttää niitä sisäiseen analytiikkaan, kun taas 50–60 % myy niitä loppukäyttäjille. Mutta kaikki riippuu mainosyrityksistä itsestään. Jotkut raportoivat vain käytetystä rahasta ja manipuloiduista mainoksista, kun taas toiset raportoivat, kuinka monta ihmistä ne toivat mainoksiin, minkä yleisön ne tavoittivat... Sanoisin, että se on totta, mutta voisin olla väärässä – en oikein ymmärrä, miten nämä kaikki toimivat. Tunnen vain kvantitatiivista dataa.

Muutamia mainoksia 🙂
Kiitos, että pysyt kanssamme. Pidätkö artikkeleistamme? Haluatko nähdä mielenkiintoisempaa sisältöä? Tue meitä tekemällä tilauksen tai suosittelemalla ystäville, , ainutlaatuinen lähtötason palvelimien analogi, jonka me keksimme sinulle: (saatavana RAID1:n ja RAID10:n kanssa, jopa 24 ydintä ja jopa 40 Gt DDR4-muistia).
Dell R730xd 2 kertaa halvempi Equinix Tier IV -palvelinkeskuksessa Amsterdamissa? Vain täällä Alankomaissa! Dell R420 - 2x E5-2430 2.2 Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - alkaen 99 dollaria! Lukea
Lähde: will.com
