

Hei Habr! Ilmoittautuminen uuteen kurssivirtaan on nyt auki OTUS:ssa Kurssin avajaisia odotellessa olemme laatineet teille käännöksen mielenkiintoisesta materiaalista.
Joka päivä yli sata miljoonaa ihmistä vierailee Twitterissä oppiakseen ja keskustellakseen maailman tapahtumista. Jokainen twiitti ja muu käyttäjän toiminto luo tapahtuman, joka on käytettävissä Twitterin sisäiseen data-analyysiin. Sadat työntekijät analysoivat ja visualisoivat tätä dataa, ja käyttäjäkokemuksen parantaminen on Twitter Data Platform -tiimin tärkein prioriteetti.
Uskomme, että käyttäjien, joilla on laaja-alainen tekninen osaaminen, tulisi pystyä löytämään dataa ja heillä tulisi olla pääsy tehokkaisiin SQL-pohjaisiin analyysi- ja visualisointityökaluihin. Tämä antaisi kokonaan uudelle vähemmän teknisten käyttäjien ryhmälle, mukaan lukien data-analyytikot ja tuotepäälliköt, mahdollisuuden poimia oivalluksia datasta, mikä mahdollistaisi heille paremman ymmärryksen ja hyödynnän Twitterin ominaisuuksia. Näin demokratisoimme data-analyysiä Twitterissä.
Samalla kun olemme parantaneet työkalujamme ja ominaisuuksiamme sisäiseen data-analyysiin, olemme nähneet parannuksia Twitterin palvelussa. Parantamisen varaa on kuitenkin vielä. Nykyiset työkalut, kuten Scalding, vaativat ohjelmointikokemusta. SQL-pohjaisilla analyysityökaluilla, kuten Prestolla ja Verticalla, on suorituskykyongelmia laajamittaisessa käytössä. Meillä on myös vaikeuksia jakaa dataa useiden järjestelmien välillä ilman yhdenmukaista pääsyä.
Viime vuonna ilmoitimme , jonka puitteissa siirrämme osia Google Cloud Platformissa (GCP). Havaitsimme, että Google Cloud -työkalut voi auttaa meitä aloitteissamme demokratisoida analyysiä, visualisointia ja koneoppimista Twitterissä:
- : yrityksen tietovarasto SQL-moottorilla, joka perustuu , joka on tunnettu nopeudestaan, yksinkertaisuudestaan ja selviytymiskyvystään .
- Suurten tietomäärien visualisointityökalu, jossa on Google Docsia muistuttavia yhteistyöominaisuuksia.
Tässä artikkelissa kerromme kokemuksistamme näiden työkalujen kanssa: mitä olemme tehneet, mitä olemme oppineet ja mitä teemme seuraavaksi. Keskitymme nyt erä- ja interaktiiviseen analytiikkaan. Reaaliaikaisesta analytiikasta keskustelemme seuraavassa artikkelissa.
Twitterin tietovarastojen historia
Ennen kuin syvennymme BigQueryyn, on syytä lyhyesti kerrata Twitterin tietovarastoinnin historiaa. Vuonna 2011 Twitterin data-analyysi tehtiin Verticassa ja Hadoopissa. Käytimme Pigiä MapReduce-työkuormien luomiseen Hadoopille. Vuonna 2012 korvasimme Pigin Scaldingilla, joka tarjosi Scala-rajapinnan, jonka etuja olivat mm. monimutkaisten prosessien luominen ja testauksen helppous. Monille SQL:n kanssa tottuneemmille data-analyytikoille ja tuotepäälliköille tämä oli kuitenkin jyrkkä oppimiskäyrä. Vuoden 2016 tienoilla aloimme käyttää Prestoa SQL-rajapintana Hadoop-datalle. Spark tarjosi Python-rajapinnan, mikä teki siitä hyvän valinnan ad hoc -datan tutkimiseen ja koneoppimiseen.
Vuodesta 2018 lähtien olemme käyttäneet seuraavia työkaluja datan analysointiin ja visualisointiin:
- Tuotantokuljettimien polttaminen
- Scalding ja Spark ad hoc -data-analyysiin ja koneoppimiseen
- Vertica ja Presto ad hoc - ja interaktiiviseen SQL-analyysiin
- Druid matalan latenssin, interaktiivisen ja tutkivan pääsyn aikasarjamittareihin
- Tableau, Zeppelin ja Pivot datan visualisointiin
Huomasimme, että vaikka nämä työkalut tarjoavat erittäin tehokkaita ominaisuuksia, meillä oli vaikeuksia saada ne laajemman yleisön saataville Twitterissä. Laajentamalla alustaamme Google Cloudin avulla keskitymme yksinkertaistamaan analytiikkatyökalujamme koko Twitterissä.
Google BigQuery -tietovarasto
Useat Twitterin tiimit olivat jo integroineet BigQueryn osaksi tuotantoprosessiaan. Heidän kokemuksensa pohjalta aloimme arvioida BigQueryn ominaisuuksia kaikissa Twitterin käyttötapauksissa. Tavoitteenamme oli tarjota BigQuery koko yritykselle ja standardoida ja tukea sitä Data Platform -työkalupaketissa. Tämä oli haastavaa monesta syystä. Meidän piti kehittää infrastruktuuri, joka pystyisi luotettavasti käsittelemään suuria tietomääriä, tukemaan yrityksenlaajuista tiedonhallintaa, varmistamaan asianmukaisen käyttöoikeuksien hallinnan ja suojaamaan asiakkaiden yksityisyyttä. Meidän piti myös luoda järjestelmät resurssien allokointia, valvontaa ja takaisinveloituksia varten, jotta tiimit pystyivät käyttämään BigQuerya tehokkaasti.
Marraskuussa 2018 julkaisimme koko yrityksen kattavan BigQueryn ja Data Studion alfa-version. Tarjosimme Twitterin työntekijöille joitakin useimmin käytettyjä taulukoita, joissa oli puhdistettuja henkilötietoja. Yli 250 käyttäjää eri tiimeistä, mukaan lukien suunnittelu, talous ja markkinointi, käytti BigQueryä. Viimeksi he suorittivat noin 8 000 kyselyä ja käsittelivät noin 100 petatavua kuukaudessa, ajoitettuja kyselyitä lukuun ottamatta. Saatuaan erittäin positiivista palautetta päätimme siirtyä eteenpäin ja tarjota BigQueryn ensisijaiseksi resurssiksi datan käsittelyyn Twitterissä.
Tässä on Google BigQuery -tietovarastomme yleisen tason arkkitehtuurikaavio.
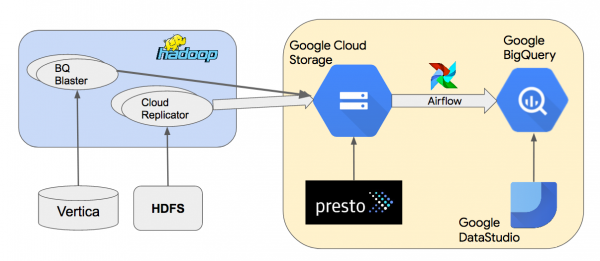
Replikoimme tietoja paikallisista Hadoop-klustereista Google Cloud Storageen (GCS) käyttämällä sisäistä Cloud Replicator -työkaluamme. Sitten käytämme Apache Airflow'ta luodaksemme putkia, jotka hyödyntävät"tietojen lataamiseen GCS:stä BigQueryyn. Käytämme Prestoa Parquet- tai Thrift-LZO-tietojoukkojen kyselyihin GCS:ssä. BQ Blaster on Scaldingin sisäinen työkalu HDFS Vertica- ja Thrift-LZO-tietojoukkojen lataamiseen BigQueryyn.
Seuraavissa osioissa käsittelemme lähestymistapaamme ja näkemyksiämme helppokäyttöisyyden, suorituskyvyn, tiedonhallintajärjestelmän, järjestelmän saatavuuden ja kustannusten aloilla.
Helppokäyttöinen
Huomasimme, että käyttäjien oli helppo aloittaa BigQueryn käyttö, koska se ei vaatinut ohjelmistoasennuksia ja oli käytettävissä intuitiivisen verkkokäyttöliittymän kautta. Käyttäjien oli kuitenkin tutustuttava joihinkin GCP:n ominaisuuksiin ja käsitteisiin, mukaan lukien resursseihin, kuten projekteihin, tietojoukkoihin ja taulukoihin. Kehitimme koulutusmateriaaleja ja opetusohjelmia auttaaksemme käyttäjiä alkuun. Saatuaan perusymmärryksen käyttäjät pystyivät helposti navigoimaan tietojoukoissa, tarkastelemaan skeemaa ja taulukkodataa, suorittamaan yksinkertaisia kyselyitä ja visualisoimaan tuloksia Data Studiossa.
Tavoitteenamme BigQueryyn tapahtuvan datan syöttämisen osalta oli tarjota HDFS- tai GCS-tietojoukkojen saumaton lataus yhdellä napsautuksella. Otimme huomioon (Airflow'n hallinnoima), mutta emme voineet käyttää sitä "Domain Restricted Sharing" -tietoturvamallimme vuoksi (lisätietoja tästä alla olevassa "Tiedonhallinta"-osiossa). Kokeilimme Google Data Transfer Servicen (DTS) käyttöä BigQuery-lataustehtävien organisointiin. Vaikka DTS oli nopea asentaa, se ei ollut joustava riippuvuuksien sisältävien prosessien rakentamiseen. Alfa-julkaisuamme varten rakensimme oman Apache Airflow -ympäristön GCE:ssä ja valmistelemme sitä tuotantoon ja useampien tietolähteiden, kuten Vertican, tukemiseen.
Muuntaakseen dataa BigQuery-muotoon käyttäjät luovat yksinkertaisia SQL-dataprosesseja käyttämällä ajoitettuja kyselyitä. Monimutkaisten, monivaiheisten ja riippuvuuksia sisältävien prosessorien osalta aiomme käyttää joko omaa Airflow-infrastruktuuriamme tai Cloud Composeria yhdessä… .
Suorituskyky
BigQuery on suunniteltu yleiskäyttöisille SQL-kyselyille, jotka käsittelevät suuria tietomääriä. Sitä ei ole suunniteltu transaktiotietokannan vaatimille matalan latenssin ja suuren läpimenon kyselyille tai matalan latenssin aikasarja-analyysille, jota... Interaktiivisissa analyyttisissä kyselyissä käyttäjämme odottavat alle minuutin vasteaikoja. Meidän piti suunnitella BigQuery-kokemuksemme vastaamaan näitä odotuksia. Jotta voisimme varmistaa käyttäjillemme ennustettavan suorituskyvyn, hyödynsimme asiakkaille kiinteähintaista BigQuery-toimintoa, jonka avulla projektien omistajat voivat varata kyselyilleen vain tietyn määrän aikoja. BigQuery on laskentatehon yksikkö, jota tarvitaan SQL-kyselyiden suorittamiseen.
Analysoimme yli 800 kyselyä, jotka käsittelivät kukin noin 1 Tt:n dataa, ja havaitsimme, että keskimääräinen suoritusaika oli 30 sekuntia. Havaitsimme myös, että suorituskyky riippui suuresti paikkojen käyttöasteesta eri projektien ja tehtävien välillä. Meidän oli erotettava selkeästi toisistaan tuotanto- ja ad hoc -paikkavaraukset ylläpitääksemme suorituskykyä tuotantokäyttötapauksissa ja interaktiivisessa analyysissä. Tämä vaikutti merkittävästi paikkojen varaussuunnitteluun ja projektihierarkiaan.
Puhumme tiedonhallinnasta, toiminnallisuudesta ja järjestelmäkustannuksista tulevina päivinä käännöksen toisessa osassa, mutta nyt kutsumme kaikki mukaan , jossa voit oppia lisää kurssista ja esittää kysymyksiä asiantuntijallemme Egor Mateshukille (vanhempi datainsinööri, MaximaTelecom).
Lue lisää:
Lähde: will.com
