

Hei kaikki, nimeni on Alexander, työskentelen CIANissa insinöörinä ja olen mukana järjestelmähallinnassa ja infrastruktuuriprosessien automatisoinnissa. Yhden edellisen artikkelin kommenteissa meitä pyydettiin kertomaan, mistä saamme 4 TB lokeja päivässä ja mitä teemme niillä. Kyllä, meillä on paljon lokeja ja niitä varten on luotu erillinen infrastruktuuriklusteri, jonka avulla voimme ratkaista ongelmat nopeasti. Tässä artikkelissa puhun siitä, kuinka sovitimme sen vuoden aikana toimimaan jatkuvasti kasvavan tietovirran kanssa.
Mistä aloitimme?
Muutaman viime vuoden aikana cian.ru:n kuormitus on kasvanut erittäin nopeasti, ja vuoden 2018 kolmanteen neljännekseen mennessä resurssiliikenne saavutti 11.2 miljoonaa yksittäistä käyttäjää kuukaudessa. Tuolloin kriittisinä hetkinä menetimme jopa 40 % lokeista, minkä vuoksi emme pystyneet käsittelemään tapauksia nopeasti ja käytimme paljon aikaa ja vaivaa niiden ratkaisemiseen. Emme myöskään usein löytäneet ongelman syytä, ja se toistui jonkin ajan kuluttua. Se oli helvettiä ja asialle piti tehdä jotain.
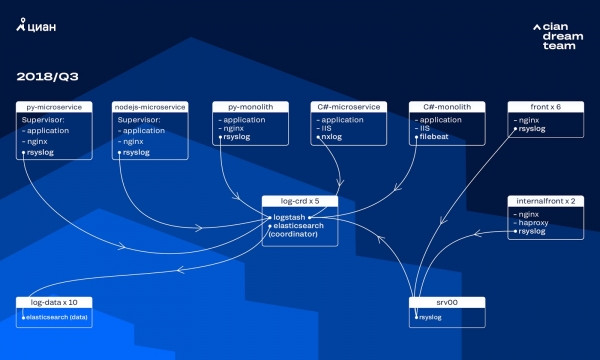
Tuolloin käytimme lokien tallentamiseen 10 datasolmun klusteria ElasticSearchin versiolla 5.5.2 vakiohakemistoasetuksilla. Se esiteltiin yli vuosi sitten suosituna ja edullisena ratkaisuna: silloin tukkien virta ei ollut niin suuri, ei ollut mitään järkeä keksiä epätyypillisiä kokoonpanoja.
Logstash tarjosi saapuvien lokien käsittelyn viiden ElasticSearch-koordinaattorin eri porteissa. Yksi indeksi koosta riippumatta koostui viidestä sirpaleesta. Järjestettiin tunti- ja päiväkierto, jonka seurauksena klusteriin ilmestyi joka tunti noin 100 uutta sirpaletta. Vaikka lokeja ei ollut kovin paljon, klusteri selviytyi hyvin, eikä kukaan kiinnittänyt huomiota sen asetuksiin.
Nopean kasvun haasteet
Tukkitukien määrä kasvoi erittäin nopeasti, kun kaksi prosessia oli päällekkäin. Toisaalta palvelun käyttäjien määrä kasvoi. Toisaalta aloimme siirtymään aktiivisesti mikropalveluarkkitehtuuriin, sahaamalla vanhoja monoliitttejamme C#:ssa ja Pythonissa. Useat kymmenet uudet mikropalvelut, jotka korvasivat osia monoliitista, loivat merkittävästi lisää lokeja infrastruktuuriklusteriin.
Skaalaus johti meidät siihen pisteeseen, että klusteri muuttui käytännössä hallitsemattomaksi. Kun lokit alkoivat saapua nopeudella 20 tuhatta viestiä sekunnissa, toistuva turha kierto nosti sirpaleiden määrän 6 tuhanteen, ja sirpaleita oli yli 600 solmua kohti.
Tämä johti ongelmiin RAM-muistin allokoinnissa, ja kun solmu kaatui, kaikki sirpaleet siirtyivät samanaikaisesti, mikä lisäsi liikennettä ja kuormitti jäljellä olevia solmuja, mikä teki datan kirjoittamisen klusteriin käytännössä mahdottomaksi. Ja tänä aikana meillä ei ollut lokeja. Ja jos ongelmia ilmeni... palvelin Menetimme kokonaisuudessaan 1/10 klusterista. Suuri määrä pieniä indeksejä lisäsi monimutkaisuutta.
Ilman lokeja emme ymmärtäneet tapahtuman syitä ja voisimme ennemmin tai myöhemmin astua samalle haravalle uudelleen, ja tiimimme ideologiassa tämä ei ollut hyväksyttävää, koska kaikki työmekanismimme on suunniteltu toimimaan juuri päinvastoin - älä koskaan toista. samat ongelmat. Tätä varten tarvitsimme täyden lokimäärän ja niiden toimituksen lähes reaaliajassa, sillä päivystävä insinööritiimi seurasi hälytyksiä paitsi mittareista myös lokeista. Ongelman laajuuden ymmärtämiseksi tukkien kokonaismäärä oli tuolloin noin 2 TB päivässä.
Asetimme tavoitteeksi eliminoida tukkien katoamisen kokonaan ja lyhentää niiden toimitusaika ELK-klusteriin enintään 15 minuuttiin ylivoimaisen esteen aikana (käytimme tätä lukua myöhemmin sisäisenä KPI:nä).
Uusi pyöritysmekanismi ja kuuma-lämmin solmut
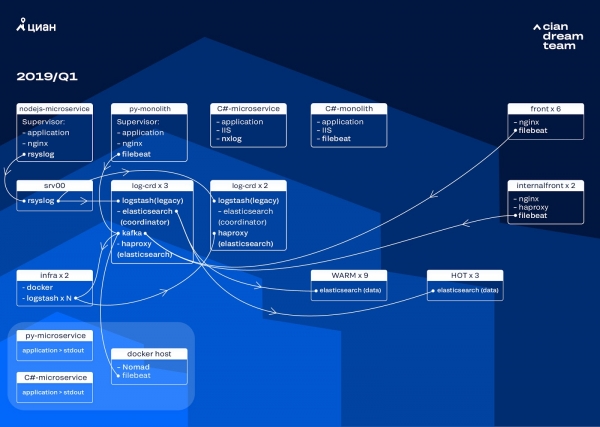
Aloitimme klusterin muuntamisen päivittämällä ElasticSearch-version versiosta 5.5.2 versioon 6.4.3. Jälleen kerran versio 5 -klusterimme kuoli, ja päätimme sammuttaa sen ja päivittää sen kokonaan - lokeja ei vieläkään ole. Joten teimme tämän muutoksen vain parissa tunnissa.
Suurin muutos tässä vaiheessa oli Apache Kafkan käyttöönotto kolmessa solmussa koordinaattorin välipuskurina. Viestinvälittäjä pelasti meidät lokien menettämisestä ElasticSearchin ongelmien aikana. Samalla lisäsimme klusteriin 2 solmua ja siirryimme hot-warm-arkkitehtuuriin, jossa kolme "kuumaa" solmua sijaitsevat palvelinkeskuksen eri telineissä. Uudelleenohjasimme lokit heille maskilla, jota ei pitäisi kadota missään olosuhteissa - nginx, samoin kuin sovellusvirhelokeja. Pienet lokit lähetettiin jäljellä oleviin solmuihin - virheenkorjaus, varoitus jne., ja 24 tunnin kuluttua "tärkeät" lokit "kuumista" solmuista siirrettiin.
Jotta pienten indeksien lukumäärä ei kasvaisi, siirryimme aikakierrosta rollover-mekanismiin. Foorumeilla oli paljon tietoa siitä, että rotaatio hakemistokoon mukaan on erittäin epäluotettavaa, joten päätimme käyttää hakemistossa olevien asiakirjojen kiertoa. Analysoimme jokaisen indeksin ja kirjasimme dokumenttien lukumäärän, jonka jälkeen rotaation pitäisi toimia. Siten olemme saavuttaneet optimaalisen sirpaleen koon - enintään 50 Gt.
Klusterin optimointi
Emme kuitenkaan ole päässeet kokonaan eroon ongelmista. Valitettavasti pieniä indeksejä ilmestyi edelleen: ne eivät saavuttaneet määritettyä määrää, niitä ei kierretty ja ne poistettiin yli kolme päivää vanhojen indeksien yleisellä puhdistuksella, koska poistimme vuorottelun päivämäärän mukaan. Tämä johti tietojen menettämiseen, koska klusterin indeksi katosi kokonaan ja yritys kirjoittaa olemattomaan indeksiin rikkoi hallintaan käyttämämme kuraattorin logiikan. Kirjoittamisen alias muunnettiin indeksiksi ja rikkoi rollover-logiikan, mikä aiheutti joidenkin indeksien hallitsemattoman kasvun 600 Gt asti.
Esimerkiksi kiertomäärityksessä:
сurator-elk-rollover.yaml
---
actions:
1:
action: rollover
options:
name: "nginx_write"
conditions:
max_docs: 100000000
2:
action: rollover
options:
name: "python_error_write"
conditions:
max_docs: 10000000
Jos aliasta ei ollut, tapahtui virhe:
ERROR alias "nginx_write" not found.
ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
Jätimme tämän ongelman ratkaisun seuraavaan iteraatioon ja otimme toisen ongelman: siirryimme Logstashin vetologiikkaan, joka käsittelee saapuvat lokit (poistaa tarpeettomat tiedot ja rikastaa). Laitoimme sen dockeriin, jonka käynnistämme docker-composen kautta, ja sijoitimme sinne myös logstash-exporterin, joka lähettää mittareita Prometheukselle lokivirran toiminnan seurantaa varten. Näin annoimme itsellemme mahdollisuuden muuttaa sujuvasti kunkin lokityypin käsittelystä vastaavien logstash-instanssien määrää.
Samalla kun kehitimme klusteria, cian.ru:n liikenne kasvoi 12,8 miljoonaan yksittäiseen käyttäjään kuukaudessa. Tuloksena kävi ilmi, että muutoksemme olivat hieman tuotannon muutosten takana ja kohtasimme sen, että ”lämpimät” solmut eivät kestäneet kuormaa ja hidastivat koko tukkien toimitusta. Saimme ”kuumaa” dataa ilman virheitä, mutta jouduimme puuttumaan lopun toimittamiseen ja tekemään manuaalisen rolloverin, jotta indeksit jakautuisivat tasaisesti.
Samanaikaisesti klusterin logstash-esiintymien asetusten skaalausta ja muuttamista vaikeutti se, että kyseessä oli paikallinen telakointiasema ja kaikki toiminnot tehtiin manuaalisesti (uusien päätyjen lisäämiseksi piti käydä manuaalisesti läpi kaikki palvelimet ja docker-kirjoitus -d kaikkialla).
Lokin uudelleenjako
Tämän vuoden syyskuussa leikkasimme vielä monoliittia, klusterin kuormitus kasvoi ja lokivirta lähestyi 30 tuhatta viestiä sekunnissa.
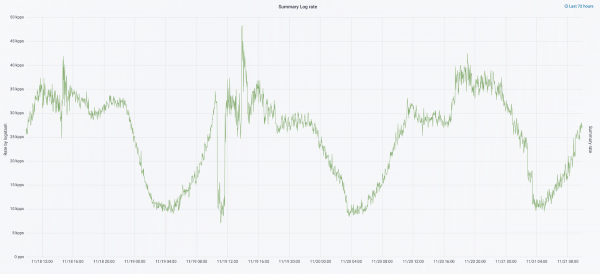
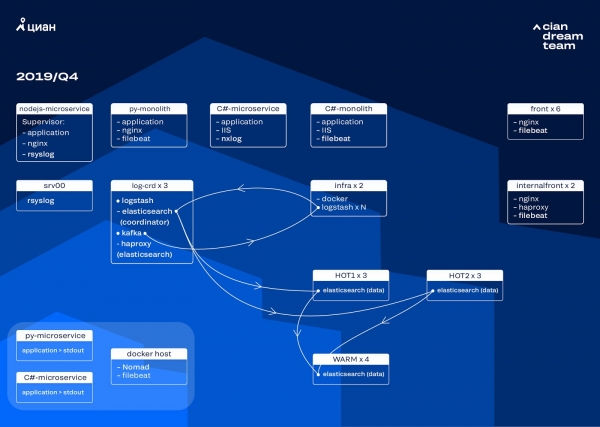
Aloitimme seuraavan iteraation laitteistopäivityksellä. Vaihdoimme viidestä koordinaattorista kolmeen, korvasimme datasolmut ja voitimme rahan ja tallennustilan suhteen. Solmuille käytämme kahta kokoonpanoa:
- "Kuumat" solmut: E3-1270 v6 / 960 Gb SSD / 32 Gb x 3 x 2 (3 Hot1:lle ja 3 Hot2:lle).
- "Lämpimille" solmuille: E3-1230 v6 / 4Tb SSD / 32 Gb x 4.
Tässä iteraatiossa siirsimme indeksin mikropalvelujen käyttölokeilla, jotka vievät saman tilan kuin etulinjan nginx-lokit, toiseen kolmen "kuuman" solmun ryhmään. Tallennamme nyt tietoja "kuumiin" solmuihin 20 tunnin ajan ja siirrämme ne sitten "lämpimiin" solmuihin muihin lokeihin.
Ratkaisimme pienten indeksien katoamisen ongelman määrittämällä niiden kierto uudelleen. Nyt indeksejä pyöritetään joka tapauksessa 23 tunnin välein, vaikka dataa olisi vähän. Tämä lisäsi hieman sirpaleiden määrää (niitä oli noin 800), mutta klusterin suorituskyvyn kannalta se on siedettävää.
Tämän seurauksena klusterissa oli kuusi "kuumaa" ja vain neljä "lämmintä" solmua. Tämä aiheuttaa pientä viivettä pyyntöihin pitkien ajanjaksojen aikana, mutta solmujen määrän lisääminen tulevaisuudessa ratkaisee tämän ongelman.
Tämä iteraatio korjasi myös puoliautomaattisen skaalauksen puutteen. Tätä varten otimme käyttöön Nomad-infrastruktuuriklusterin - samanlaisen kuin olemme jo ottaneet käyttöön tuotannossa. Toistaiseksi Logstashin määrä ei automaattisesti muutu kuormituksen mukaan, mutta tähän tullaan.
Tulevaisuuden suunnitelmat
Toteutettu konfiguraatio skaalautuu täydellisesti, ja nyt tallennamme 13,3 TB dataa - kaikki lokit 4 päivän ajan, mikä on tarpeen hälytysten hätäanalyysiin. Muunnamme osan lokeista mittareiksi, jotka lisäämme Graphiteen. Insinöörien työn helpottamiseksi meillä on mittareita infrastruktuuriklusterille ja komentosarjat yleisten ongelmien puoliautomaattiseen korjaamiseen. Ensi vuodelle suunnitellun datasolmujen määrän lisäämisen jälkeen siirrymme datan varastointiin 4 päivästä 7 päivään. Tämä riittää operatiiviseen työhön, sillä pyrimme aina tutkimaan tapaukset mahdollisimman pian ja pitkäaikaisiin tutkimuksiin on olemassa telemetriatietoa.
Lokakuussa 2019 cian.ru:n liikenne oli jo kasvanut 15,3 miljoonaan yksittäiseen käyttäjään kuukaudessa. Tästä tuli vakava testi hirsien toimituksen arkkitehtoniselle ratkaisulle.
Nyt valmistaudumme päivittämään ElasticSearchin versioon 7. Tätä varten meidän on kuitenkin päivitettävä monien hakemistojen kartoitus ElasticSearchissa, koska ne siirtyivät versiosta 5.5 ja julistettiin vanhentuneiksi versiossa 6 (niitä ei yksinkertaisesti ole versiossa 7). Tämä tarkoittaa, että päivitysprosessin aikana tulee varmasti jonkinlainen ylivoimainen este, joka jättää meidät ilman lokeja, kun ongelma ratkaistaan. Versiosta 7 odotamme eniten Kibanaa parannetulla käyttöliittymällä ja uusilla suodattimilla.
Saavutimme päätavoitteemme: lopetimme lokien häviämisen ja lyhensimme infrastruktuuriklusterin seisokit 2-3 kaatumisesta viikossa parin tunnin huoltotyöhön kuukaudessa. Kaikki tämä tuotantotyö on lähes näkymätöntä. Nyt voimme kuitenkin määrittää tarkalleen, mitä palvelussamme tapahtuu, voimme tehdä sen nopeasti hiljaisessa tilassa, emmekä ole huolissamme lokien katoamisesta. Yleisesti ottaen olemme tyytyväisiä, onnellisia ja valmistaudumme uusiin hyökkäyksiin, joista puhumme myöhemmin.
Lähde: will.com
