

Kuutio kuutiolla, metaklusterit, hunajakennot, resurssien jakelu
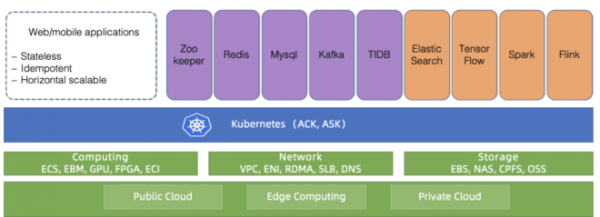
Riisi. 1. Kubernetes-ekosysteemi Alibaba Cloudissa
Vuodesta 2015 lähtien Alibaba Cloud Container Service for Kubernetes (ACK) on ollut yksi nopeimmin kasvavista pilvipalveluista Alibaba Cloudissa. Se palvelee lukuisia asiakkaita ja tukee myös Alibaban sisäistä infrastruktuuria ja yhtiön muita pilvipalveluita.
Kuten maailmanluokan pilvipalveluntarjoajien vastaavien konttipalveluiden kohdalla, tärkein prioriteettimme ovat luotettavuus ja saatavuus. Siksi kymmenille tuhansille Kubernetes-klustereille on luotu skaalautuva ja maailmanlaajuisesti saavutettava alusta.
Tässä artikkelissa jaamme kokemuksemme lukuisten Kubernetes-klustereiden hallinnasta pilviinfrastruktuurissa sekä taustalla olevan alustan arkkitehtuurista.
Merkintä
Kubernetesista on tullut de facto standardi erilaisille pilvityökuormille. Kuten kuvassa näkyy. Kuvassa 1, yhä useammat Alibaba Cloud -sovellukset ovat nyt käynnissä Kubernetes-klustereissa: tilallisia ja tilattomia sovelluksia sekä sovellusten hallintaohjelmia. Kubernetes-hallinta on aina ollut mielenkiintoinen ja vakava keskustelunaihe infrastruktuuria rakentaville ja ylläpitäville insinööreille. Mitä tulee pilvipalveluntarjoajiin, kuten Alibaba Cloud, skaalauskysymys tulee esiin. Kuinka hallita Kubernetes-klustereita tässä mittakaavassa? Olemme jo käsitelleet parhaita käytäntöjä valtavien 10 000 solmun Kubernetes-klusterien hallintaan. Tämä on tietysti mielenkiintoinen skaalausongelma. Mutta on toinenkin asteikko: määrä itse klusterit.
Olemme keskustelleet tästä aiheesta monien ACK-käyttäjien kanssa. Useimmat heistä valitsevat kymmeniä, ellei satoja pieniä tai keskisuuria Kubernetes-klustereita. Tähän on hyvät syyt: mahdollisten vahinkojen rajoittaminen, klusterien erottaminen eri ryhmille, virtuaalisten klustereiden luominen testausta varten. Jos ACK pyrkii palvelemaan maailmanlaajuista yleisöä tällä käyttömallilla, sen on hallittava luotettavasti ja tehokkaasti suurta määrää klustereita yli 20 alueella.
Riisi. 2. Valtavan Kubernetes-klustereiden hallinnan ongelmat
Mitkä ovat tämän mittakaavan klusterien hallinnan suurimmat haasteet? Kuten kuvasta näkyy, on käsiteltävä neljä asiaa:
- Heterogeenisuus
ACK:n tulisi tukea erilaisia klusterityyppejä, mukaan lukien standardi, palvelimeton, Edge, Windows ja joitakin muita. Eri klusterit vaativat erilaisia parametreja, komponentteja ja hosting-malleja. Jotkut asiakkaat tarvitsevat apua konfiguroinnissa erityistarpeisiinsa.
- Erilaisia klusterin kokoja
Klusterit vaihtelevat kooltaan: muutamasta solmusta, joissa on useita tyynyjä, kymmeniin tuhansiin solmuihin, joissa on tuhansia paloja. Myös resurssivaatimukset vaihtelevat suuresti. Väärä resurssien allokointi voi vaikuttaa suorituskykyyn tai jopa aiheuttaa epäonnistumisen.
- Eri versiot
Kubernetes kehittyy erittäin nopeasti. Uusia versioita julkaistaan muutaman kuukauden välein. Asiakkaat ovat aina valmiita kokeilemaan uusia ominaisuuksia. Joten he haluavat asettaa testikuormituksen uusille Kubernetesin versioille ja tuotantokuormituksen vakaille. Tämän vaatimuksen täyttämiseksi ACK:n on jatkuvasti toimitettava uusia Kubernetes-versioita asiakkaille säilyttäen samalla vakaat versiot.
- Turvallisuusvaatimustenmukaisuus
Klusterit ovat jakautuneet eri alueille. Sellaisenaan niiden tulee täyttää erilaisia turvallisuusvaatimuksia ja viranomaismääräyksiä. Esimerkiksi Euroopan klusterin on oltava GDPR-yhteensopiva, kun taas Kiinan talouspilvessä on oltava lisäsuojakerroksia. Nämä vaatimukset ovat pakollisia, eikä niitä voida hyväksyä, koska se aiheuttaa valtavia riskejä pilvialustan asiakkaille.
ACK-alusta on suunniteltu ratkaisemaan useimmat yllä mainituista ongelmista. Tällä hetkellä se hallitsee luotettavasti ja vakaasti yli 10 tuhatta Kubernetes-klusteria ympäri maailmaa. Katsotaanpa, kuinka tämä saavutettiin, mukaan lukien useiden suunnittelun/arkkitehtuurin keskeisten periaatteiden avulla.
Suunnittelu
Kuutio kuutiolla ja hunajakenno
Toisin kuin keskitetty hierarkia, solupohjaista arkkitehtuuria käytetään tyypillisesti alustan skaalaamiseen yhden datakeskuksen ulkopuolelle tai katastrofipalautuksen laajentamiseen.
Jokainen Alibaba Cloudin alue koostuu useista vyöhykkeistä (AZ) ja vastaa yleensä tiettyä datakeskusta. Suurella alueella (esim. Huangzhou) on usein tuhansia Kubernetes-asiakasklustereita, joissa on käytössä ACK.
ACK hallitsee näitä Kubernetes-klustereita itse Kubernetesin avulla, mikä tarkoittaa, että meillä on käynnissä Kubernetes-metaklusteri hallitsemaan Kubernetes-asiakasklustereita. Tätä arkkitehtuuria kutsutaan myös nimellä "kube-on-kube" (KoK). KoK-arkkitehtuuri yksinkertaistaa asiakasklusterien hallintaa, koska klusterin käyttöönotto on yksinkertaista ja determinististä. Vielä tärkeämpää on, että voimme käyttää Kubernetesin alkuperäisiä ominaisuuksia uudelleen. Esimerkiksi API-palvelimien hallinta käyttöönoton kautta, etcd-operaattorin käyttö useiden etcd:iden hallintaan. Tällainen rekursio tuo aina erityistä iloa.
Yhdellä alueella on käytössä useita Kubernetes-metaklustereita asiakkaiden lukumäärästä riippuen. Kutsumme näitä metaklustereita soluiksi. Suojatakseen koko vyöhykkeen epäonnistumiselta ACK tukee moniaktiivisia käyttöönottoja yhdellä alueella: metaklusteri jakaa Kubernetes-asiakasklusterin pääkomponentit useille vyöhykkeille ja suorittaa ne samanaikaisesti, eli moniaktiivisessa tilassa. Isäntäkoneen luotettavuuden ja tehokkuuden varmistamiseksi ACK optimoi komponenttien sijoittelun ja varmistaa, että API-palvelin ja etcd ovat lähellä toisiaan.
Tämän mallin avulla voit hallita Kubernetesia tehokkaasti, joustavasti ja luotettavasti.
Metacluster-resurssisuunnittelu
Kuten jo mainitsimme, metaklusterien määrä kullakin alueella riippuu asiakkaiden määrästä. Mutta missä vaiheessa uusi metaklusteri lisätään? Tämä on tyypillinen resurssisuunnittelun ongelma. Yleensä on tapana luoda uusi, kun olemassa olevat metaklusterit ovat käyttäneet kaikki resurssinsa.
Otetaan esimerkiksi verkkoresurssit. KoK-arkkitehtuurissa asiakasklusterien Kubernetes-komponentit otetaan käyttöön podeina metaklusterissa. Käytämme (Kuva 3) on Alibaba Cloudin kehittämä korkean suorituskyvyn laajennus konttiverkon hallintaan. Se tarjoaa runsaasti suojauskäytäntöjä ja mahdollistaa yhteyden muodostamisen asiakkaiden virtuaalisiin yksityispilviin (VPC) Alibaba Cloud Elastic Networking Interfacen (ENI) kautta. Jotta verkkoresurssit voidaan jakaa tehokkaasti metaklusterin solmuille, podille ja palveluille, meidän on tarkkailtava tarkasti niiden käyttöä virtuaalisten yksityispilvien metaklusterissa. Kun verkkoresurssit loppuvat, luodaan uusi solu.
Määrittääksemme optimaalisen asiakasklusterien määrän kussakin metaklusterissa, otamme huomioon myös kustannukset, tiheysvaatimukset, resurssikiintiöt, luotettavuusvaatimukset ja tilastot. Päätös uuden metaklusterin luomisesta tehdään kaiken tämän tiedon perusteella. Huomioi, että pienet klusterit voivat laajentua tulevaisuudessa suuresti, joten resurssien kulutus kasvaa, vaikka klusterien määrä pysyisi ennallaan. Jätämme yleensä tarpeeksi vapaata tilaa kullekin klusterille kasvaa.
Riisi. 3. Terway-verkkoarkkitehtuuri
Ohjatun toiminnon komponenttien skaalaus asiakasklusterien välillä
Ohjatun toiminnon komponenteilla on erilaiset resurssitarpeet. Ne riippuvat klusterin solmujen ja podien määrästä sekä APIServerin kanssa vuorovaikutuksessa olevien ei-standardien ohjaimien/operaattoreiden määrästä.
ACK:ssa jokainen Kubernetes-asiakasklusteri eroaa kooltaan ja ajonaikavaatimuksiltaan. Ohjatun toiminnon osien sijoittamiseen ei ole yleistä konfiguraatiota. Jos asetamme vahingossa pienen resurssirajan suurelle asiakkaalle, sen klusteri ei kestä kuormitusta. Jos asetat konservatiivisesti korkean rajan kaikille klusteille, resurssit menevät hukkaan.
Löytääkseen hienovaraisen kompromissin luotettavuuden ja kustannusten välillä ACK käyttää tyyppijärjestelmää. Nimittäin määrittelemme kolme klusterityyppiä: pienet, keskisuuret ja suuret. Jokaisella tyypillä on erillinen resurssien allokointiprofiili. Tyyppi määritetään ohjatun toiminnon komponenttien kuormituksen, solmujen lukumäärän ja muiden tekijöiden perusteella. Klusterin tyyppi voi muuttua ajan myötä. ACK tarkkailee jatkuvasti näitä tekijöitä ja voi kirjoittaa ylös/alas sen mukaisesti. Kun klusterin tyyppiä muutetaan, resurssien allokointi päivitetään automaattisesti ilman käyttäjän toimia.
Pyrimme parantamaan tätä järjestelmää tarkemmalla skaalauksella ja tarkemmalla tyyppipäivityksellä, jotta nämä muutokset tapahtuvat sujuvammin ja taloudellisemmin järkevämmin.
Riisi. 4. Älykäs monivaiheinen tyypin vaihto
Asiakasklustereiden kehitys mittakaavassa
Edellisissä osissa käsiteltiin joitain näkökohtia suurten Kubernetes-klustereiden hallinnassa. On kuitenkin toinen ongelma, joka on ratkaistava: klusterien kehitys.
Kubernetes on "Linux"pilvimaailmassa. Sitä päivitetään jatkuvasti ja siitä tulee modulaarisempi. Meidän on jatkuvasti toimitettava asiakkaillemme uusia versioita, korjattava haavoittuvuuksia ja päivitettävä olemassa olevia klustereita sekä hallittava suurta määrää toisiinsa liittyviä komponentteja (CSI, CNI, laitelaajennus, aikataulutuslaajennus ja monet muut)."
Otetaan esimerkiksi Kubernetes-komponenttien hallinta. Aluksi kehitimme keskitetyn järjestelmän kaikkien näiden yhdistettyjen komponenttien rekisteröintiä ja hallintaa varten.
Riisi. 5. Joustavat ja kytkettävät komponentit
Ennen kuin siirryt eteenpäin, sinun on varmistettava, että päivitys onnistui. Tätä varten olemme kehittäneet järjestelmän komponenttien toimivuuden tarkistamiseksi. Tarkistus suoritetaan ennen päivitystä ja sen jälkeen.
Riisi. 6. Klusterin komponenttien alustava tarkastus
Näiden komponenttien päivittämiseksi nopeasti ja luotettavasti jatkuvan käyttöönoton järjestelmä tukee osittaista edistymistä (harmaasävyt), taukoja ja muita toimintoja. Vakiokubernetes-ohjaimet eivät sovellu hyvin tähän käyttötapaukseen. Siksi olemme kehittäneet klusterin komponenttien hallintaa varten joukon erikoisohjaimia, mukaan lukien laajennuksen ja apuohjausmoduulin (sivuvaunun hallinta).
Esimerkiksi BroadcastJob-ohjain on suunniteltu päivittämään komponentit jokaisessa työntekijäkoneessa tai tarkistamaan kunkin koneen solmut. Broadcast-työ suorittaa podin jokaisessa klusterin solmussa, kuten DaemonSet. DaemonSet kuitenkin pitää podin aina käynnissä pitkän aikaa, kun taas BroadcastJob tiivistää sen. Broadcast-ohjain käynnistää myös podeja vastaliitetyissä solmuissa ja alustaa solmut tarvittavilla komponenteilla. Kesäkuussa 2019 avasimme OpenKruise-automaatiomoottorin lähdekoodin, jota itse käytämme yrityksessä.
Riisi. 7. OpenKurise järjestää Broadcast-tehtävän suorittamisen kaikissa solmuissa
Jotta asiakkaat voivat valita oikeat klusterikokoonpanot, tarjoamme myös joukon valmiiksi määritettyjä profiileja, mukaan lukien Serverless, Edge, Windows ja Bare Metal. Kun markkinat laajenevat ja asiakkaidemme tarpeet kehittyvät, lisäämme lisää profiileja yksinkertaistaaksemme työlästä asennusprosessia.
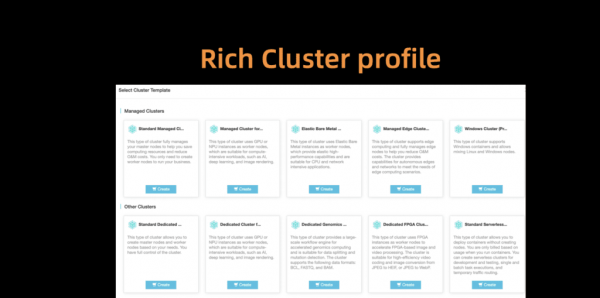
Riisi. 8. Kehittyneet ja joustavat klusteriprofiilit erilaisiin skenaarioihin
Globaali havainnointi palvelinkeskuksissa
Kuten alla olevasta kuvasta näkyy. 9, Alibaba Cloud Container -pilvipalvelu on otettu käyttöön kahdellakymmenellä alueella ympäri maailmaa. Tässä mittakaavassa yksi ACK:n keskeisistä tavoitteista on valvoa helposti käynnissä olevien klusterien tilaa, jotta voimme reagoida tilanteeseen nopeasti, jos asiakasklusteri kohtaa ongelman. Toisin sanoen sinun on keksittävä ratkaisu, jonka avulla voit tehokkaasti ja turvallisesti kerätä tilastoja reaaliajassa asiakasklustereista kaikilla alueilla - ja esittää tulokset visuaalisesti.
Riisi. 9. Alibaba Cloud Container -palvelun maailmanlaajuinen käyttöönotto kahdellakymmenellä alueella
Kuten monet Kubernetes-valvontajärjestelmät, käytämme Prometheusta päätyökalumme. Prometheus-agentit keräävät jokaisesta metaklusterista seuraavat tiedot:
- Käyttöjärjestelmän tiedot, kuten isäntäresurssit (CPU, muisti, levy jne.) ja verkon kaistanleveys.
- Metaklusterin ja asiakasklusterin hallintajärjestelmän mittarit, kuten kube-apiserver, kube-controller-manager ja kube-scheduler.
- Mittarit kubernetes-state-metricsistä ja cadvisorista.
- etcd-mittarit, kuten levyn kirjoitusaika, tietokannan koko, solmujen välisten yhteyksien suorituskyky jne.
Globaalit tilastot kerätään käyttämällä tyypillistä monikerroksista aggregointimallia. Jokaisen metaklusterin seurantatiedot kootaan ensin kullakin alueella ja lähetetään sitten keskuspalvelimelle, joka näyttää kokonaiskuvan. Kaikki toimii liittoutumismekanismin kautta. Jokaisessa palvelinkeskuksessa oleva Prometheus-palvelin kerää mittareita kyseisestä palvelinkeskuksesta, ja Prometheus-keskuspalvelin on vastuussa seurantatietojen yhdistämisestä. AlertManager muodostaa yhteyden Prometheuksen keskusyksikköön ja lähettää tarvittaessa hälytyksiä DingTalkin, sähköpostin, tekstiviestien jne. kautta. Visualisointi - Grafanan avulla.
Kuvassa 10 valvontajärjestelmä voidaan jakaa kolmeen tasoon:
- Rajataso
Keskustasta kauimpana oleva kerros. Prometheus Edge Server toimii jokaisessa metaklusterissa ja kerää mittareita saman verkkoalueen meta- ja asiakasklustereista.
- Kaskaditaso
Prometheus-kaskadikerroksen tehtävänä on kerätä seurantadataa useilta alueilta. Nämä serveria Ne toimivat suurempien maantieteellisten yksiköiden, kuten Kiinan, Aasian, Euroopan ja Amerikan, tasolla. Klusterien kasvaessa alue voidaan jakaa, ja jokaiselle uudelle suurelle alueelle otetaan sitten käyttöön CSS-pohjainen Prometheus-palvelin. Tämä strategia mahdollistaa sujuvan skaalauksen tarpeen mukaan.
- Keskitaso
Keskitetty Prometheus-palvelin muodostaa yhteyden kaikkiin kaskadipalvelimiin ja suorittaa lopullisen datan yhdistämisen. Luotettavuuden vuoksi kaksi Prometheus-instanssia nostettiin eri vyöhykkeille yhdistettynä samoihin kaskadipalvelimiin.
Riisi. 10. Globaali monitasoinen valvonta-arkkitehtuuri, joka perustuu Prometheus-federaatiomekanismiin
Yhteenveto
Kubernetes-pohjaiset pilviratkaisut muuttavat edelleen toimialaamme. Alibaba Cloud -konttipalvelu tarjoaa turvallisen, luotettavan ja tehokkaan isännöinnin - se on yksi parhaista Kubernetes-pilvipalveluista. Alibaba Cloud -tiimi uskoo vahvasti avoimen lähdekoodin ja avoimen lähdekoodin yhteisön periaatteisiin. Jatkamme varmasti jatkossakin osaamisemme jakamista pilviteknologioiden toiminnassa ja hallinnassa.
Lähde: will.com
