

Huomautus. käännös: Esittelemme huomionne teknisiä yksityiskohtia Grafanan tekijöiden ylläpitämän pilvipalvelun viimeaikaisten seisokkien syistä. Tämä on klassinen esimerkki siitä, kuinka uusi ja näennäisesti erittäin hyödyllinen ominaisuus, joka on suunniteltu parantamaan infrastruktuurin laatua... voi aiheuttaa vahinkoa, jos et ota huomioon sen soveltamisen lukuisia vivahteita tuotantotodellisuudessa. On hienoa, kun tällaisia materiaaleja tulee näkyviin, joiden avulla voit oppia paitsi virheistäsi. Yksityiskohdat ovat tämän tekstin käännöksessä, jonka on kirjoittanut Grafana Labsin tuotejohtaja.

Perjantaina 19. heinäkuuta Hosted Prometheus -palvelu Grafana Cloudissa lakkasi toimimasta noin 30 minuutiksi. Pyydän anteeksi kaikilta asiakkailta, joita katkos koskee. Meidän tehtävämme on tarjota tarvitsemasi seurantatyökalut, ja ymmärrämme, että niiden puuttuminen voi vaikeuttaa elämääsi. Otamme tämän tapauksen erittäin vakavasti. Tämä muistiinpano selittää, mitä tapahtui, kuinka reagoimme ja mitä teemme varmistaaksemme, ettei se toistu.
esihistoria
Grafana Cloud Hosted Prometheus -palvelu perustuu — CNCF-projekti horisontaalisesti skaalautuvan, erittäin saatavilla olevan, usean vuokralaisen Prometheus-palvelun luomiseksi. Cortex-arkkitehtuuri koostuu joukosta yksittäisiä mikropalveluita, joista jokainen suorittaa oman tehtävänsä: replikointi, tallennus, kyselyt jne. Cortex on aktiivisesti kehitteillä ja lisää jatkuvasti uusia ominaisuuksia ja parantaa suorituskykyä. Otamme säännöllisesti käyttöön uusia Cortex-julkaisuja klustereihin, jotta asiakkaat voivat hyödyntää näitä ominaisuuksia – onneksi Cortex voidaan päivittää ilman seisokkeja.
Saumattomia päivityksiä varten Ingester Cortex -palvelu vaatii ylimääräisen Ingester-replikan päivitysprosessin aikana. (Huomautus. käännös: - Cortexin peruskomponentti. Sen tehtävänä on kerätä jatkuva näytevirta, ryhmitellä ne Prometheus-paloihin ja tallentaa ne tietokantaan, kuten DynamoDB, BigTable tai Cassandra.) Tämä antaa vanhoille käyttäjille mahdollisuuden välittää nykyiset tiedot uusille Ingestereille. On syytä huomata, että Ingesterit ovat resursseja vaativia. Jotta ne toimivat, sinulla on oltava 4 ydintä ja 15 Gt muistia per pod, ts. 25 % peruskoneen prosessointitehosta ja muistista Kubernetes-klusteriemme tapauksessa. Yleensä meillä on klusterissa yleensä paljon enemmän käyttämättömiä resursseja kuin 4 ydintä ja 15 Gt muistia, joten voimme helposti pyörittää näitä lisäosia päivitysten aikana.
Usein kuitenkin käy niin, että normaalikäytössä millään koneella ei ole tätä 25 % käyttämättömistä resursseista. Kyllä, emme edes pyri: CPU ja muisti ovat aina hyödyllisiä muille prosesseille. Tämän ongelman ratkaisemiseksi päätimme käyttää . Ajatuksena on antaa Ingestersille korkeampi prioriteetti kuin muille (valtiottomille) mikropalveluille. Kun meidän on käytettävä ylimääräistä (N+1) Ingesteriä, syrjäyttämme väliaikaisesti muut pienemmät kotelot. Nämä kotelot siirretään vapaisiin resursseihin toisissa koneissa, jolloin jää tarpeeksi suuri ”reikä” ylimääräisen Ingesterin käyttämiseen.
Torstaina 18. heinäkuuta otimme klustereillemme neljä uutta prioriteettitasoa: kriittinen, pitkä, keskimääräinen и matala. Niitä testattiin sisäisessä klusterissa, jossa ei ollut asiakasliikennettä noin viikon ajan. Oletusarvoisesti vastaanotetaan podeja, joilla ei ole määritettyä prioriteettia keskimääräinen prioriteetti, luokka oli asetettu Ingestersille korkea etusijalla. Kriittinen oli varattu seurantaa varten (Prometheus, Alertmanager, node-exporter, kube-state-metrics jne.). Kokoonpanomme on auki, ja voit tarkastella PR:ää .
onnettomuus
Perjantaina 19. heinäkuuta yksi insinööreistä lanseerasi uuden Cortex-klusterin suurelle asiakkaalle. Tämän klusterin kokoonpano ei sisältänyt uusia pod-prioriteetteja, joten kaikille uusille podille määritettiin oletusprioriteetti - keskimääräinen.
Kubernetes-klusterilla ei ollut tarpeeksi resursseja uuteen Cortex-klusteriin, eikä olemassa olevaa Cortex-klusteria päivitetty (Ingesterit jäivät ilman korkea prioriteetti). Koska Ingesters uuden klusterin oletuksena oli keskimääräinen etusijalla, ja nykyiset kotelot tuotannossa toimivat ilman prioriteettia ollenkaan, uuden klusterin Ingesterit korvasivat nykyisen Cortex-tuotantoklusterin Ingesterit.
Tuotantoklusterin häätetyn Ingesterin ReplicaSet havaitsi häätetyn kotelon ja loi uuden ylläpitämään määritetyn määrän kopioita. Uusi pod määritettiin oletuksena keskimääräinen etusijalle, ja toinen tuotannossa oleva "vanha" Ingester menetti resurssinsa. Tuloksena oli lumivyöryprosessi, mikä johti kaikkien koteloiden syrjäyttämiseen Ingesteristä Cortex-tuotantoklustereissa.
Syöttäjät ovat tilallisia ja tallentavat tietoja edellisiltä 12 tunnilta. Tämän ansiosta voimme pakata ne tehokkaammin ennen niiden kirjoittamista pitkäaikaiseen varastointiin. Tämän saavuttamiseksi Cortex sirpalee tietoja sarjoista Distributed Hash Table (DHT) -taulukon (Distributed Hash Table) avulla ja replikoi jokaisen sarjan kolmessa Ingesterissä käyttämällä Dynamo-tyylistä quorum-konsistenssia. Cortex ei kirjoita tietoja Ingestereille, jotka on poistettu käytöstä. Näin ollen, kun suuri määrä ingesterejä poistuu DHT:sta, Cortex ei pysty tarjoamaan riittävää kopiota merkinnöistä, ja ne kaatuvat.
Havaitseminen ja korjaaminen
Uudet Prometheus-ilmoitukset perustuvat "virhebudjettiin" (virhebudjettipohjainen — yksityiskohdat julkaistaan seuraavassa artikkelissa) alkoivat hälyttää 4 minuuttia sammutuksen alkamisen jälkeen. Seuraavien viiden minuutin aikana suoritimme diagnostiikkaa ja laajensimme taustalla olevaa Kubernetes-klusteria isännöimään sekä uusia että olemassa olevia tuotantoklustereita.
Toisen viiden minuutin kuluttua vanhat Ingesterit kirjoittivat onnistuneesti tietonsa, uudet käynnistyivät ja Cortex-klusterit tulivat taas saataville.
Toiset 10 minuuttia käytettiin muistin loppumisen (OOM) virheiden diagnosointiin ja korjaamiseen Cortexin edessä sijaitsevien todennuskäänteisten välityspalvelinten kautta. OOM-virheet johtuivat QPS:n kymmenkertaisesta kasvusta (uskomme johtuvan liian aggressiivisista pyynnöistä asiakkaan Prometheus-palvelimista).
Jälkiseuraukset
Kokonaisseisonta-aika oli 26 minuuttia. Tietoja ei hävinnyt. Ingesters on ladannut onnistuneesti kaikki muistissa olevat tiedot pitkäaikaiseen varastointiin. Sammutuksen aikana puskuroidut Prometheus-asiakaspalvelimet poistettiin (etä) tallenteita käyttämällä perustuu WAL:iin (tekijä Grafana Labsilta) ja toisti epäonnistuneet kirjoitukset kaatumisen jälkeen.
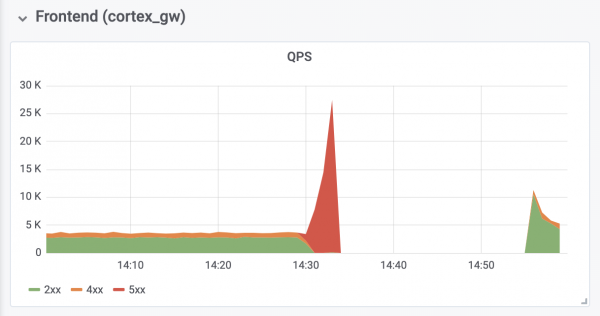
Tuotantoklusterin kirjoitustoiminnot
Tulokset
On tärkeää ottaa oppia tästä tapauksesta ja ryhtyä tarvittaviin toimiin sen toistumisen välttämiseksi.
Jälkikäteen ajateltuna meidän ei olisi pitänyt asettaa oletusarvoa keskimääräinen etusijalla, kunnes kaikki tuotannossa olevat syöttölaitteet ovat saaneet pitkä prioriteetti. Lisäksi niistä piti huolehtia etukäteen korkea etusijalla. Kaikki on nyt korjattu. Toivomme, että kokemuksemme auttaa muita organisaatioita harkitsemaan pod-prioriteettien käyttöä Kubernetesissa.
Lisäämme ylimääräisen hallintatason kaikkien sellaisten lisäobjektien käyttöönotolle, joiden kokoonpanot ovat klusterin globaaleja. Tästä eteenpäin tällaisia muutoksia arvioidaan bоenemmän ihmisiä. Lisäksi kaatumisen aiheuttanut muutos katsottiin liian pieneksi erilliselle projektidokumentille - siitä keskusteltiin vain GitHub-numerossa. Tästä eteenpäin kaikkiin tällaisiin konfiguraatioihin tehtyihin muutoksiin liitetään asianmukainen projektidokumentaatio.
Lopuksi automatisoimme todennuksen käänteisen välityspalvelimen koon muuttamisen estääksemme havaitsemamme ylikuormituksen OOM:ssa ja tarkistamme Prometheuksen oletusasetukset, jotka liittyvät varatoimitukseen ja skaalaukseen, jotta vastaavat ongelmat voidaan välttää tulevaisuudessa.
Epäonnistumisella oli myös positiivisia seurauksia: Cortex toipui automaattisesti ilman lisätoimia saatuaan tarvittavat resurssit. Saimme myös arvokasta kokemusta yhteistyöstä - uusi tukkien kokoamisjärjestelmämme - joka auttoi varmistamaan, että kaikki Ingesterit toimivat oikein vian aikana ja sen jälkeen.
PS kääntäjältä
Lue myös blogistamme:
- «";
- «";
- «";
- «'.
Lähde: will.com
