


Monet ihmiset kamppailevat Elasticsearchin kanssa. Mutta mitä tapahtuu, kun haluat käyttää sitä lokien tallentamiseen "erityisen suurena volyymina"? Ja onko myös kivutonta kokea jonkin useista palvelinkeskuksista vikaantuminen? Millaista arkkitehtuuria sinun pitäisi tehdä, ja mihin sudenkuoppiin törmäät?
Me Odnoklassnikissa päätimme käyttää elasticsearchia tukkien hallinnan ratkaisemiseen, ja nyt jaamme kokemuksemme Habrin kanssa: sekä arkkitehtuurista että sudenkuoppista.
Olen Pjotr Zaitsev, työskentelen järjestelmänvalvojana Odnoklassnikissa. Ennen sitä olin myös järjestelmänvalvoja, työskentelin Manticore Searchin, Sphinx searchin, Elasticsearchin kanssa. Ehkä, jos toinen ...haku tulee näkyviin, työskentelen todennäköisesti myös sen kanssa. Osallistun myös useisiin avoimen lähdekoodin projekteihin vapaaehtoisesti.
Kun tulin Odnoklassnikiin, sanoin piittaamattomasti haastattelussa, että voisin työskennellä Elasticsearchin kanssa. Kun olin perehtynyt asiaan ja tehnyt muutamia yksinkertaisia tehtäviä, minulle annettiin suuri tehtävä uudistaa tuolloin olemassa ollut lokinhallintajärjestelmä.
Vaatimukset
Järjestelmävaatimukset muotoiltiin seuraavasti:
- Graylogia oli tarkoitus käyttää etuosana. Koska yrityksellä oli jo kokemusta tämän tuotteen käytöstä, ohjelmoijat ja testaajat tiesivät sen, se oli heille tuttua ja kätevää.
- Datamäärä: keskimäärin 50-80 tuhatta viestiä sekunnissa, mutta jos jokin katkeaa, liikennettä ei rajoita mikään, se voi olla 2-3 miljoonaa riviä sekunnissa
- Keskusteltuamme asiakkaiden kanssa hakukyselyiden käsittelyn nopeuden vaatimuksista, huomasimme, että tyypillinen malli tällaiselle järjestelmälle on tämä: ihmiset etsivät lokeja sovelluksestaan viimeisen kahden päivän ajalta eivätkä halua odottaa enempää kuin toinen muotoillun kyselyn tulokselle.
- Järjestelmänvalvojat vaativat, että järjestelmä on tarvittaessa helposti skaalattava ilman, että heidän olisi pitänyt perehtyä syvällisesti sen toimintaan.
- Joten ainoa huoltotehtävä, jota nämä järjestelmät vaativat säännöllisesti, on laitteiston vaihtaminen.
- Lisäksi Odnoklassnikilla on erinomainen tekninen perinne: minkä tahansa lanseeraamamme palvelun on selviydyttävä datakeskuksen vioista (äkillinen, suunnittelematon ja ehdottomasti milloin tahansa).
Viimeinen vaatimus tämän projektin toteuttamisessa maksoi meille eniten, josta puhun tarkemmin.
keskiviikko
Työskentelemme neljässä palvelinkeskuksessa, kun taas Elasticsearch-tietosolmuja voidaan sijoittaa vain kolmeen (useita ei-teknisiä syitä).
Nämä neljä datakeskusta sisältävät noin 18 tuhatta erilaista lokilähdettä - laitteistoa, konttia, virtuaalikoneita.
Tärkeä ominaisuus: klusteri alkaa säiliöissä ei fyysisillä koneilla, vaan . Säiliöille taataan 2 ydintä, samanlainen kuin 2.0 GHz v4, ja loput ytimet voidaan kierrättää, jos ne ovat käyttämättömänä.
Toisin sanoen:

Topologia
Alun perin näin ratkaisun yleisen muodon seuraavasti:
- Graylog-domainin A-tietueen takana on 3-4 VIPiä, tähän osoitteeseen lokit lähetetään.
- jokainen VIP on LVS-tasapainottaja.
- Sen jälkeen lokit menevät Graylog-akkuun, osa tiedoista on GELF-muodossa, osa syslog-muodossa.
- Sitten kaikki tämä kirjoitetaan suurissa erissä Elasticsearch-koordinaattorien paristolle.
- Ja he puolestaan lähettävät kirjoitus- ja lukupyyntöjä asianmukaisille datasolmuille.
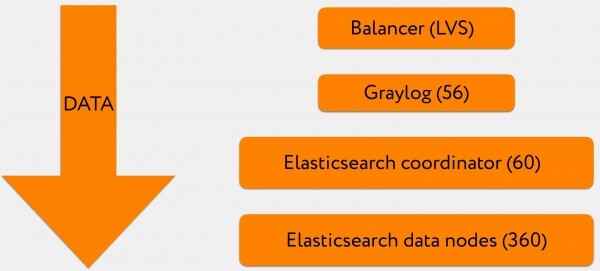
terminologia
Ehkä kaikki eivät ymmärrä terminologiaa yksityiskohtaisesti, joten haluaisin keskittyä siihen hieman.
Elasticsearchissa on useita solmutyyppejä - isäntä, koordinaattori, datasolmu. Eri lokimuunnoksille ja eri klusterien väliselle tiedonsiirrolle on olemassa kaksi muuta tyyppiä, mutta käytimme vain lueteltuja.
Master
Se pingttaa kaikki klusterissa olevat solmut, ylläpitää ajan tasalla olevaa klusterikarttaa ja jakaa sen solmujen välillä, käsittelee tapahtumalogiikkaa ja suorittaa monenlaisia klusterin laajuisia huoltotoimenpiteitä.
Koordinaattori
Suorittaa yhden tehtävän: hyväksyy luku- tai kirjoituspyynnöt asiakkailta ja reitittää tämän liikenteen. Mikäli kirjoituspyyntö tulee, se todennäköisesti kysyy isännältä, mihin kyseisen indeksin sirpaleeseen se tulee laittaa, ja ohjaa pyynnön edelleen.
Datasolmu
Tallentaa tietoja, suorittaa ulkopuolelta tulevia hakukyselyitä ja suorittaa toimintoja niillä sijaitseville sirpaleille.
harmaalogo
Tämä on jotain kuin Kibana ja Logstash fuusio ELK-pinossa. Graylog yhdistää sekä käyttöliittymän että lokinkäsittelyprosessin. Konepellin alla Graylog pyörittää Kafkaa ja Zookeeperiä, jotka tarjoavat yhteyden Graylogiin klusterina. Graylog voi tallentaa lokit (Kafka) välimuistiin, jos Elasticsearch ei ole käytettävissä, ja toistaa epäonnistuneita luku- ja kirjoituspyyntöjä, ryhmitellä ja merkitä lokit määritettyjen sääntöjen mukaisesti. Kuten Logstash, Graylogilla on mahdollisuus muokata rivejä ennen niiden kirjoittamista Elasticsearchiin.
Lisäksi Graylogissa on sisäänrakennettu palveluetsintä, jonka avulla voidaan yhden käytettävissä olevan Elasticsearch-solmun perusteella saada koko klusterikartta ja suodattaa se tietyllä tunnisteella, mikä mahdollistaa pyyntöjen ohjaamisen tiettyihin säilöihin.
Visuaalisesti se näyttää tältä:

Tämä on kuvakaappaus tietystä tapauksesta. Täällä rakennamme histogrammin hakukyselyn perusteella ja näytämme asiaankuuluvat rivit.
Indeksit
Palatakseni järjestelmäarkkitehtuuriin, haluaisin tarkastella tarkemmin, kuinka rakensimme indeksimallin niin, että se kaikki toimi oikein.
Yllä olevassa kaaviossa tämä on alin taso: Elasticsearch-tietosolmut.
Indeksi on suuri virtuaalinen kokonaisuus, joka koostuu Elasticsearch-sirpaleista. Jokainen sirpale itsessään on vain Lucenen indeksi. Ja jokainen Lucene-indeksi puolestaan koostuu yhdestä tai useammasta segmentistä.
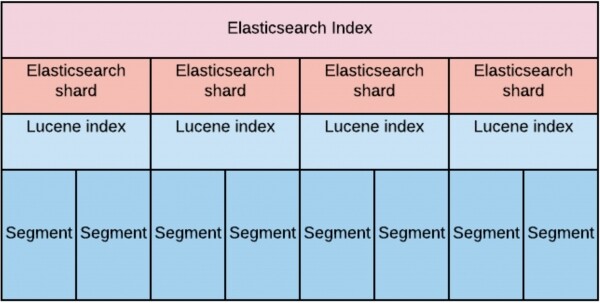
Suunnitellessamme ajattelimme, että voidaksemme täyttää suuren datamäärän lukunopeuden vaatimuksen, meidän on "hajattava" tämä data tasaisesti datasolmujen kesken.
Tämä johti siihen, että sirpaleiden lukumäärän indeksiä kohti (kopioiden kanssa) tulisi olla tiukasti sama kuin datasolmujen lukumäärä. Ensinnäkin varmistaaksemme, että replikointitekijä on kaksi (eli voimme menettää puolet klusterista). Ja toiseksi, jotta voidaan käsitellä luku- ja kirjoituspyyntöjä vähintään puolessa klusterista.
Määritimme ensin säilytysajaksi 30 päivää.
Sirpaleiden jakautuminen voidaan esittää graafisesti seuraavasti:

Koko tummanharmaa suorakulmio on indeksi. Sen vasen punainen neliö on ensisijainen sirpale, ensimmäinen hakemistossa. Ja sininen neliö on replikan sirpale. Ne sijaitsevat eri datakeskuksissa.
Kun lisäämme toisen sirpaleen, se menee kolmanteen datakeskukseen. Ja loppujen lopuksi saamme tämän rakenteen, jonka avulla on mahdollista menettää DC menettämättä tietojen johdonmukaisuutta:

Indeksien rotaatio, ts. luomalla uusi hakemisto ja poistamalla vanhin, teimme sen 48 tunniksi (hakemiston käyttömallin mukaan: viimeisiä 48 tuntia haetaan useimmiten).
Tämä indeksin kiertoväli johtuu seuraavista syistä:
Kun hakupyyntö saapuu tiettyyn datasolmuun, on suorituskyvyn kannalta kannattavampaa, kun kysellään yhtä sirpaletta, jos sen koko on verrattavissa solmun lonkan kokoon. Näin voit pitää indeksin "kuuman" osan kasassa ja käyttää sitä nopeasti. Kun "kuumia osia" on paljon, indeksihaun nopeus heikkenee.
Kun solmu alkaa suorittaa hakukyselyä yhdellä sirpaleella, se varaa säikeitä yhtä monta kuin fyysisen koneen hypersäikeistysytimiä. Jos hakukysely vaikuttaa suureen määrään sirpaleita, säikeiden määrä kasvaa suhteessa. Tällä on negatiivinen vaikutus hakunopeuteen ja negatiivinen vaikutus uusien tietojen indeksointiin.
Tarvittavan hakuviiveen tarjoamiseksi päätimme käyttää SSD-levyä. Pyyntöjen nopeaa käsittelyä varten näitä säiliöitä isännöineissä koneissa oli oltava vähintään 56 ydintä. Luku 56 valittiin ehdollisesti riittäväksi arvoksi, joka määrää Elasticsearchin toiminnan aikana luomien säikeiden määrän. Elasitcsearchissa monet säikeen poolin parametrit riippuvat suoraan käytettävissä olevien ytimien lukumäärästä, mikä puolestaan vaikuttaa suoraan tarvittavaan klusterin solmujen määrään periaatteen "vähemmän ytimiä - enemmän solmuja" mukaisesti.
Tuloksena havaitsimme, että sirpale painaa keskimäärin noin 20 gigatavua ja indeksiä kohti on 1 sirpaletta. Vastaavasti, jos kierrätämme niitä kerran 360 tunnin välein, meillä on niitä 48. Jokainen indeksi sisältää tiedot 15 päivältä.
Tiedon kirjoitus- ja lukupiirit
Selvitetään, kuinka tiedot tallennetaan tähän järjestelmään.
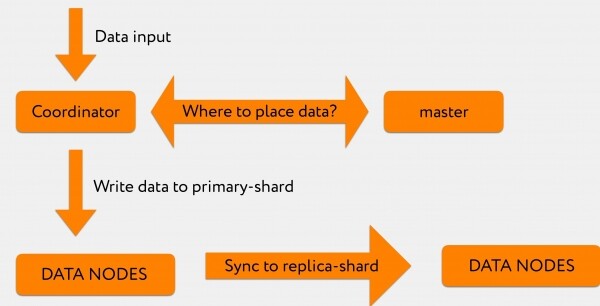
Oletetaan, että jokin pyyntö saapuu Graylogista koordinaattorille. Haluamme esimerkiksi indeksoida 2-3 tuhatta riviä.
Koordinaattori, saatuaan pyynnön Graylogilta, kyselee päällikköä: "Indeksointipyynnössä määritimme nimenomaan indeksin, mutta mihin sirpaleeseen se kirjoitetaan, sitä ei määritetty."
Isäntä vastaa: "Kirjoita nämä tiedot sirpaleen numeroon 71", minkä jälkeen ne lähetetään suoraan asiaankuuluvaan datasolmuun, jossa ensisijainen sirpale numero 71 sijaitsee.
Tämän jälkeen tapahtumaloki replikoidaan replika-sirpaleeseen, joka sijaitsee toisessa tietokeskuksessa.
Hakupyyntö saapuu Graylogista koordinaattorille. Koordinaattori ohjaa sen uudelleen indeksin mukaan, kun taas Elasticsearch jakaa pyynnöt ensisijaisen sirpaleen ja replikasirun välillä round-robin-periaatteella.
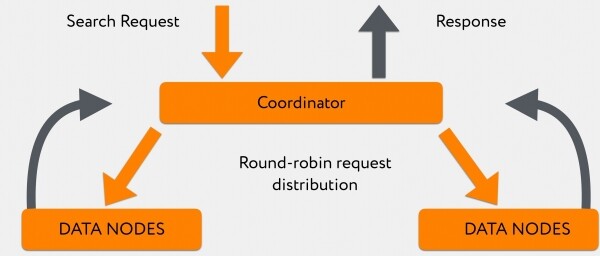
180 solmua reagoivat epätasaisesti, ja samalla kun ne vastaavat, koordinaattori kerää tietoa, jonka nopeammat datasolmut ovat jo "sylkeneet". Tämän jälkeen, kun joko kaikki tiedot ovat saapuneet tai pyyntö on saavuttanut aikakatkaisun, se antaa kaiken suoraan asiakkaalle.
Tämä koko järjestelmä käsittelee keskimäärin viimeisten 48 tunnin hakukyselyt 300–400 ms:ssa, pois lukien kyselyt, joissa on johtava jokerimerkki.
Flowers with Elasticsearch: Java-asetukset

Jotta kaikki toimisi alun perin halutulla tavalla, käytimme hyvin pitkän aikaa klusterin erilaisten asioiden vianmäärityksessä.
Ensimmäinen osa havaituista ongelmista liittyi tapaan, jolla Java on oletusarvoisesti esikonfiguroitu Elasticsearchissa.
Ongelma yksi
Olemme havainneet erittäin suuren määrän raportteja, joiden mukaan Lucene-tasolla, kun taustatöitä on käynnissä, Lucene-segmenttien yhdistämiset epäonnistuvat ja aiheuttavat virheen. Samaan aikaan lokeista kävi selväksi, että tämä oli OutOfMemoryError-virhe. Näimme telemetrialla, että lonkka oli vapaa, eikä ollut selvää, miksi tämä leikkaus epäonnistui.
Kävi ilmi, että Lucene-indeksisulautumista tapahtuu lonkan ulkopuolella. Ja kontit ovat melko tiukasti rajoitettuja kulutettujen resurssien suhteen. Näihin resursseihin mahtui vain kasa (heap.size-arvo oli suunnilleen yhtä suuri kuin RAM), ja jotkin off-keap-toiminnot kaatui muistin varausvirheellä, jos ne jostain syystä eivät mahtuneet siihen ~500 megatavuun, joka jäi ennen rajaa.
Korjaus oli melko triviaali: kontin käytettävissä olevaa RAM-muistia lisättiin, minkä jälkeen unohdimme, että meillä oli jopa sellaisia ongelmia.
Ongelma kaksi
4-5 päivää klusterin käynnistämisen jälkeen huomasimme, että datasolmut alkoivat ajoittain pudota ulos klusterista ja saapua siihen 10-20 sekunnin kuluttua.
Kun aloimme selvittää sitä, kävi ilmi, että tätä Elasticsearchin ulkopuolista muistia ei ohjata millään tavalla. Kun annoimme säiliölle lisää muistia, pystyimme täyttämään suorat puskurivarastot erilaisilla tiedoilla, ja se tyhjennettiin vasta sen jälkeen, kun eksplisiittinen GC käynnistettiin Elasticsearchista.
Joissakin tapauksissa tämä toiminto kesti melko kauan, ja tänä aikana klusteri onnistui merkitsemään tämän solmun jo poistetuksi. Tämä ongelma on kuvattu hyvin .
Ratkaisu oli seuraava: rajoitimme Javan kykyä käyttää valtaosaa kasan ulkopuolella olevasta muistista näihin toimintoihin. Rajoitimme sen 16 gigatavuun (-XX:MaxDirectMemorySize=16g), mikä varmistimme, että eksplisiittistä GC:tä kutsuttiin paljon useammin ja prosessoitiin paljon nopeammin, mikä ei enää horjuta klusteria.
Ongelma kolme
Jos luulet, että ongelmat "klusterista odottamattomimmalla hetkellä lähtevät solmut" ovat ohi, olet väärässä.
Kun määritimme työn indekseillä, valitsimme mmapfs to tuoreilla sirpaleilla erinomaisella segmentoinnilla. Tämä oli melkoinen virhe, koska mmapfs:a käytettäessä tiedosto kartoitetaan RAM-muistiin, ja sitten työskentelemme yhdistetyn tiedoston kanssa. Tästä johtuen käy ilmi, että kun GC yrittää pysäyttää säikeitä sovelluksessa, menemme turvapisteeseen hyvin pitkäksi aikaa ja matkalla siihen sovellus lakkaa vastaamasta isännän kyselyihin onko se elossa. . Vastaavasti isäntä uskoo, että solmu ei ole enää läsnä klusterissa. Tämän jälkeen, 5-10 sekunnin kuluttua, roskankeräin toimii, solmu herää eloon, tulee uudelleen klusteriin ja alkaa alustaa sirpaleita. Kaikki tuntui kovasti "tuotannolta, jonka ansaitsimme", eikä se sopinut mihinkään vakavaan.
Päästäksemme eroon tästä käytöksestä vaihdoimme ensin tavallisiin niofeihin, ja sitten, kun siirryimme Elasticin viidennestä versiosta kuudenteen versioon, kokeilimme hybridejä, joissa tämä ongelma ei toistunut. Voit lukea lisää säilytystyypeistä .
Ongelma neljä
Sitten oli toinen erittäin mielenkiintoinen ongelma, jota käsittelimme ennätysajan. Saimme sen kiinni 2-3 kuukautta, koska sen kuvio oli täysin käsittämätön.
Joskus koordinaattorimme menivät Full GC:hen, yleensä joskus lounaan jälkeen, eivätkä koskaan palanneet sieltä. Samaan aikaan GC-viivettä kirjattaessa se näytti tältä: kaikki menee hyvin, no, no, ja sitten yhtäkkiä kaikki menee erittäin huonosti.
Aluksi luulimme, että meillä on ilkeä käyttäjä, joka käynnisti jonkinlaisen pyynnön, joka pudotti koordinaattorin pois työtilasta. Kirjasimme pyyntöjä hyvin pitkän ajan yrittäessämme selvittää, mitä oli tapahtumassa.
Tuloksena kävi ilmi, että sillä hetkellä, kun käyttäjä käynnistää valtavan pyynnön ja se saapuu tietylle Elasticsearch-koordinaattorille, jotkut solmut vastaavat pidempään kuin toiset.
Ja samalla kun koordinaattori odottaa vastausta kaikilta solmuilta, hän kerää tuloksia, jotka on lähetetty jo vastanneilta solmuilta. GC:lle tämä tarkoittaa, että kasan käyttötottumukset muuttuvat hyvin nopeasti. Ja käyttämämme GC ei pystynyt selviytymään tästä tehtävästä.
Ainoa korjaus, jonka löysimme muuttavan klusterin käyttäytymistä tässä tilanteessa, on siirtyminen JDK13:een ja Shenandoah-jätteenkeräimen käyttö. Tämä ratkaisi ongelman, koordinaattorimme lakkasivat kaatumasta.
Tähän Java-ongelmat päättyivät ja kaistanleveysongelmat alkoivat.
"Marjat" Elasticsearchilla: suorituskyky

Suorituskyvyn ongelmat tarkoittavat, että klusterimme toimii vakaasti, mutta indeksoitujen asiakirjojen huipuissa ja liikkeiden aikana suorituskyky on riittämätön.
Ensimmäinen havaittu oire: joidenkin tuotannon "räjähdysten" aikana, kun yhtäkkiä syntyy erittäin suuri määrä lokeja, indeksointivirhe es_rejected_execution alkaa vilkkua usein Graylogissa.
Tämä johtui siitä, että thread_pool.write.queue yhdessä datasolmussa, siihen hetkeen asti, kun Elasticsearch pystyy käsittelemään indeksointipyynnön ja lataamaan tiedot levyllä olevaan sirpaleeseen, pystyy oletusarvoisesti tallentamaan välimuistiin vain 200 pyyntöä. Ja sisään Tästä parametrista puhutaan hyvin vähän. Vain lankojen enimmäismäärä ja oletuskoko näytetään.
Tietenkin menimme kiertämään tätä arvoa ja saimme selville seuraavaa: erityisesti asetuksissamme jopa 300 pyyntöä tallennetaan melko hyvin välimuistiin, ja korkeampi arvo on täynnä tosiasiaa, että lensämme jälleen Full GC:hen.
Lisäksi, koska nämä ovat viestisarjoja, jotka saapuvat yhden pyynnön sisällä, oli tarpeen säätää Graylogia niin, että se ei kirjoita usein ja pienissä erissä, vaan suurissa erissä tai kerran 3 sekunnissa, jos erä ei ole vielä valmis. Tässä tapauksessa käy ilmi, että Elasticsearchiin kirjoittamamme tiedot eivät tule saataville kahdessa sekunnissa, vaan viidessä (mikä sopii meille varsin hyvin), mutta kuinka monta uudelleenlokeroa täytyy tehdä, jotta se pääsisi läpi suuren. tietopino pienenee.
Tämä on erityisen tärkeää niillä hetkillä, kun jokin on kaatunut jossain ja raportoi siitä raivokkaasti, jotta ei tulisi täysin roskapostia Elastinen, ja jonkin ajan kuluttua - Graylog-solmuja, jotka eivät toimi tukkeutuneiden puskureiden takia.
Lisäksi, kun meillä oli samat räjähdykset tuotannossa, saimme valituksia ohjelmoijilta ja testaajilta: sillä hetkellä, kun he todella tarvitsivat näitä lokeja, niitä annettiin hyvin hitaasti.
He alkoivat selvittää sitä. Toisaalta oli selvää, että sekä haku- että indeksointikyselyt käsiteltiin olennaisesti samoilla fyysisillä koneilla, ja tavalla tai toisella tulee tiettyjä puutteita.
Mutta tämä voitaisiin osittain kiertää johtuen siitä, että Elasticsearchin kuudennessa versiossa ilmestyi algoritmi, jonka avulla voit jakaa kyselyitä relevanttien datasolmujen välillä ei satunnaisen round-robin-periaatteen mukaisesti (säilö, joka indeksoi ja pitää ensisijaisen -shard voi olla hyvin kiireinen, ei ole mahdollisuutta vastata nopeasti), mutta välitä tämä pyyntö vähemmän ladattuihin säiliöön, jossa on replika-shard, joka vastaa paljon nopeammin. Toisin sanoen päädyimme kohtaan use_adaptive_replica_selection: true.
Lukukuva alkaa näyttää tältä:
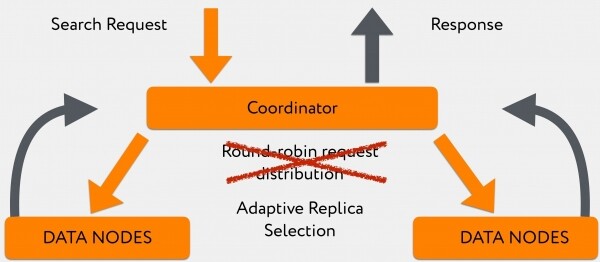
Siirtyminen tähän algoritmiin mahdollisti merkittävästi kyselyn ajan parantamisen hetkinä, jolloin meillä oli suuri määrä lokeja kirjoitettavana.
Lopuksi suurin ongelma oli palvelinkeskuksen kivuton poistaminen.
Mitä halusimme klusterilta heti yhteyden katkettua yhden DC:n kanssa:
- Jos epäonnistuneessa datakeskuksessa on nykyinen isäntä, se valitaan uudelleen ja siirretään roolina toiseen solmuun toisessa DC:ssä.
- Isäntä poistaa nopeasti kaikki saavuttamattomat solmut klusterista.
- Jäljelle jääneiden perusteella hän ymmärtää: kadonneessa palvelinkeskuksessa meillä oli sellaisia ja sellaisia ensisijaisia sirpaleita, hän tulee nopeasti edistämään täydentäviä replikasirpaleita jäljellä olevissa palvelinkeskuksissa, ja jatkamme tietojen indeksointia.
- Tämän seurauksena klusterin kirjoitus- ja lukunopeus heikkenee vähitellen, mutta yleisesti ottaen kaikki toimii, vaikkakin hitaasti, mutta vakaasti.
Kuten kävi ilmi, halusimme jotain tällaista:

Ja saimme seuraavat:

Miten se tapahtui?
Kun palvelinkeskus kaatui, mestaristamme tuli pullonkaula.
Miksi?
Tosiasia on, että isännällä on TaskBatcher, joka vastaa tiettyjen tehtävien ja tapahtumien jakamisesta klusterissa. Mikä tahansa solmun poistuminen, mikä tahansa sirpaleen edistäminen replikästä ensisijaiseksi, mikä tahansa tehtävä sirpaleen luomiseksi jonnekin - kaikki tämä menee ensin TaskBatcheriin, jossa se käsitellään peräkkäin ja yhdessä säikeessä.
Yhden palvelinkeskuksen vetäytymishetkellä kävi ilmi, että kaikki säilyneiden palvelinkeskusten datasolmut pitivät velvollisuutenaan ilmoittaa isännälle "olemme menettäneet sellaisia ja sellaisia sirpaleita ja sellaisia ja sellaisia datasolmuja".
Samaan aikaan säilyneet datasolmut lähettivät kaiken tämän tiedon nykyiselle isännälle ja yrittivät odottaa vahvistusta, että tämä hyväksyi ne. He eivät odottaneet tätä, koska mestari sai tehtävät nopeammin kuin pystyi vastaamaan. Solmut aikakatkaisivat toistuvat pyynnöt, ja isäntä ei tällä hetkellä edes yrittänyt vastata niihin, vaan oli täysin imeytynyt pyyntöjen lajitteluun prioriteetin mukaan.
Päätemuodossa kävi ilmi, että datasolmut lähettivät isäntälle roskapostia niin, että se meni täyteen GC:hen. Sen jälkeen isäntäroolimme siirtyi johonkin seuraavaan solmuun, täysin sama asia tapahtui sille, ja seurauksena klusteri romahti kokonaan.
Teimme mittauksia, ja ennen versiota 6.4.0, jossa tämä korjattiin, riitti, että syötimme samanaikaisesti vain 10 datasolmua 360:stä, jotta klusteri suljettiin kokonaan.
Se näytti jotakuinkin tältä:

Version 6.4.0 jälkeen, jossa tämä kauhea virhe korjattiin, datasolmut lakkasivat tappamasta isäntää. Mutta se ei tehnyt hänestä "älykkäämpää". Nimittäin: kun tulostamme 2, 3 tai 10 (mikä tahansa muu kuin yksi) datasolmua, isäntä vastaanottaa jonkin ensimmäisen viestin, joka sanoo, että solmu A on lähtenyt, ja yrittää kertoa tästä solmulle B, solmulle C, solmulle D.
Ja tällä hetkellä tämä voidaan hoitaa vain asettamalla aikakatkaisu yrityksille kertoa jollekin jostakin, joka on noin 20-30 sekuntia ja siten ohjata klusterista poistuvan datakeskuksen nopeutta.
Periaatteessa tämä sopii niihin vaatimuksiin, jotka alun perin esitettiin lopputuotteelle osana projektia, mutta "puhtaan tieteen" näkökulmasta tämä on bugi. Minkä muuten kehittäjät korjasivat onnistuneesti versiossa 7.2.
Lisäksi kun tietty datasolmu sammui, kävi ilmi, että tiedon levittäminen sen poistumisesta oli tärkeämpää kuin kertoa koko klusterille, että siinä oli sellaisia ja sellaisia ensisijaisia sirpaleita (replica-shardin edistämiseksi toisessa datassa keskus ensisijassa, ja niihin voitaisiin kirjoittaa tiedot).
Siksi, kun kaikki on jo lamaantunut, vapautettuja datasolmuja ei välittömästi merkitä vanhentuneiksi. Näin ollen joudumme odottamaan, kunnes kaikki pingit ovat aikakatkaistut vapautettuihin datasolmuihin, ja vasta sen jälkeen klusterimme alkaa kertoa meille, että siellä, siellä ja siellä meidän on jatkettava tietojen tallennusta. Voit lukea tästä lisää .
Tämän seurauksena konesalikeskuksen poistaminen vie meiltä tänään ruuhka-aikoina noin 5 minuuttia. Näin suurelle ja kömpelölle kolossille tämä on melko hyvä tulos.
Tuloksena päädyimme seuraavaan päätökseen:
- Meillä on 360 datasolmua 700 gigatavun levyillä.
- 60 koordinaattoria liikenteen reitittämiseksi samojen datasolmujen kautta.
- 40 isäntää, jotka olemme jättäneet eräänlaiseksi perinnöksi versiota 6.4.0 edeltävistä versioista lähtien - selviytyäksemme palvelinkeskuksen vetäytymisestä olimme henkisesti valmiita menettämään useita koneita, jotta taattaisiin isäntien päätösvaltaisuus myös vuonna pahimmassa tapauksessa
- Kaikki yritykset yhdistää rooleja yhdessä säiliössä kohtasivat sen tosiasian, että ennemmin tai myöhemmin solmu hajosi kuormituksen alaisena.
- Koko klusteri käyttää 31 gigatavun heap.sizea: kaikki yritykset pienentää kokoa johtivat joko joidenkin solmujen tappamiseen raskaassa hakukyselyssä johtavalla jokerimerkillä tai itse Elasticsearchin katkaisijan saamiseen.
- Lisäksi haun suorituskyvyn varmistamiseksi pyrimme pitämään klusterin objektien määrän mahdollisimman pienenä, jotta masterissa saamamme pullonkaula tapahtuisi mahdollisimman vähän.
Lopuksi tarkkailusta
Varmistaaksemme, että tämä kaikki toimii tarkoitetulla tavalla, seuraamme seuraavia asioita:
- Jokainen datasolmu raportoi pilveemme olemassaolostaan, ja siinä on sellaisia ja sellaisia sirpaleita. Kun sammutamme jotain jossain, klusteri ilmoittaa 2-3 sekunnin kuluttua, että sammutimme keskustassa A solmut 2, 3 ja 4 - tämä tarkoittaa, että muissa palvelinkeskuksissa emme voi missään olosuhteissa sammuttaa niitä solmuja, joissa on vain yksi sirpale. vasemmalle.
- Kun tiedämme päällikön käyttäytymisen luonteen, tarkastelemme erittäin huolellisesti vireillä olevien tehtävien määrää. Koska yksikin jumissa tehtävä, jos se ei aikakatkaisu ajoissa, voi teoreettisesti jossain hätätilanteessa tulla syynä siihen, miksi esimerkiksi replikan sirpaleen promootio ei toimi ensisijaisessa, minkä vuoksi indeksointi lakkaa toimimasta.
- Tarkkailemme myös erittäin tarkasti roskienkeräysviiveitä, koska meillä on ollut suuria vaikeuksia tämän kanssa jo optimoinnin aikana.
- Hylkää langalla ymmärtääkseen etukäteen missä pullonkaula on.
- No, vakiomittaukset, kuten kasa, RAM ja I/O.
Kun rakennat valvontaa, sinun on otettava huomioon Elasticsearchin Thread Poolin ominaisuudet. kuvailee haku- ja indeksointiasetuksia ja oletusarvoja, mutta on täysin hiljaa thread_pool.managementista. Nämä säikeet käsittelevät erityisesti kyselyitä, kuten _cat/shards ja muita vastaavia, joita on kätevä käyttää seurantaa kirjoitettaessa. Mitä suurempi klusteri, sitä enemmän tällaisia pyyntöjä suoritetaan aikayksikköä kohden, ja edellä mainittua thread_pool.managementa ei vain ole esitetty virallisessa dokumentaatiossa, vaan se on myös oletusarvoisesti rajoitettu viiteen säikeeseen, mikä hävitetään erittäin nopeasti mikä valvonta lakkaa toimimasta oikein.
Lopuksi haluan sanoa: teimme sen! Pystyimme tarjoamaan ohjelmoijillemme ja kehittäjillemme työkalun, joka voi melkein missä tahansa tilanteessa antaa nopeasti ja luotettavasti tietoa tuotannon tapahtumista.
Kyllä, se osoittautui melko monimutkaiseksi, mutta onnistuimme kuitenkin sovittamaan toiveemme olemassa oleviin tuotteisiin, joita meidän ei tarvinnut korjata ja kirjoittaa uudelleen itse.

Lähde: will.com
