

Viime aikoina Habressa on alkanut ilmestyä useammin viestejä siitä, kuinka hyvä Telegram on, kuinka loistavia ja kokeneita Durov-veljekset ovat verkkojärjestelmien rakentamisessa jne. Samaan aikaan hyvin harvat ihmiset ovat todella uppoaneet tekniseen laitteeseen - korkeintaan he käyttävät melko yksinkertaista (ja aivan erilaista kuin MTProto) JSON-pohjaista Bot APIa ja yleensä vain hyväksyvät. uskosta kaikki ylistykset ja PR, jotka pyörivät sanansaattajan ympärillä. Melkein puolitoista vuotta sitten kollegani Eshelonin kansalaisjärjestöstä Vasily (valitettavasti hänen tilinsä Habressa poistettiin luonnoksen mukana) alkoi kirjoittaa omaa Telegram-asiakastaan tyhjästä Perlissä, ja myöhemmin näiden rivien kirjoittaja liittyi mukaan. Miksi Perl, jotkut kysyvät heti? Koska tällaisia projekteja on jo muilla kielillä. Itse asiassa tässä ei ole kysymys, voisi olla mitä tahansa muuta kieltä, jolla ei ole valmis kirjasto, ja siksi kirjoittajan on mentävä loppuun asti tyhjästä. Lisäksi kryptografia on luottamuskysymys, mutta varmista. Turvallisuuteen tähtäävässä tuotteessa ei voi vain luottaa valmistajan valmiiseen kirjastoon ja luottaa siihen sokeasti (tämä on kuitenkin toisen osan aihe). Tällä hetkellä kirjasto toimii melko hyvin "keskimääräisellä" tasolla (mahdollistaa API-pyyntöjen tekemisen).
Tässä viestisarjassa ei kuitenkaan ole paljon salausta tai matematiikkaa. Mutta siellä on monia muita teknisiä yksityiskohtia ja arkkitehtonisia kainalosauvoja (hyödyllinen myös niille, jotka eivät kirjoita tyhjästä, mutta käyttävät kirjastoa millä tahansa kielellä). Päätavoitteena oli siis yrittää toteuttaa asiakas alusta alkaen virallisten asiakirjojen mukaan. Eli oletetaan, että virallisten asiakkaiden lähdekoodi on suljettu (jälleen toisessa osassa käsitellään tarkemmin aihetta, että tämä on totta se tapahtuu niin), mutta kuten ennen vanhaan, on olemassa standardi, kuten RFC - onko mahdollista kirjoittaa asiakas yksinomaan määrittelyn mukaan, "katsomatta" lähdekoodia, oli se sitten virallinen (Telegram Desktop, mobiili) tai epävirallinen Telethon?
Vastaaja:
Dokumentaatio... se on olemassa, eikö? Onko se totta?..
Tämän artikkelin muistiinpanojen katkelmia alettiin kerätä viime kesänä. Koko tämän ajan virallisella verkkosivustolla Dokumentaatio oli kerroksen 23 mukaista, ts. juuttunut jonnekin vuonna 2014 (muistatko, että silloin ei edes ollut kanavia?). Tietenkin teoriassa tämän olisi pitänyt mahdollistaa tuolloin toiminnallinen asiakas ottaa käyttöön vuonna 2014. Mutta jopa tässä tilassa dokumentaatio oli ensinnäkin epätäydellinen ja toiseksi se oli paikoin ristiriitainen itsensä kanssa. Hieman yli kuukausi sitten, syyskuussa 2019, se oli sattumalta Havaittiin, että sivustolla oli suuri päivitys dokumentaatiosta täysin tuoreelle Layer 105:lle, jossa huomautettiin, että nyt kaikki on luettava uudelleen. Itse asiassa monia artikkeleita tarkistettiin, mutta monet säilyivät ennallaan. Siksi, kun luet alla olevaa kritiikkiä dokumentaatiosta, sinun tulee muistaa, että osa näistä asioista ei ole enää relevanttia, mutta osa on edelleen melko. Loppujen lopuksi 5 vuotta nykymaailmassa ei ole vain pitkä aika, vaan hyvin paljon. Noista ajoista lähtien (varsinkin jos et ota huomioon sen jälkeen hylättyjä ja elvytettyjä geochat-sivustoja) ohjelman API-menetelmien määrä on kasvanut sadasta yli kahteensataanviisikymmeneen!
Mistä aloittaa nuorena kirjailijana?
Ei ole väliä, kirjoitatko tyhjästä vai käytätkö esimerkiksi valmiita kirjastoja, kuten tai , tarvitset joka tapauksessa ensin rekisteröi hakemuksesi - api_id и api_hash (VKontakte API:n kanssa työskennelleet ymmärtävät heti), jonka avulla palvelin tunnistaa sovelluksen. Tämä täytyy tee se oikeudellisista syistä, mutta puhumme lisää siitä, miksi kirjastojen kirjoittajat eivät voi julkaista sitä toisessa osassa. Saatat olla tyytyväinen testiarvoihin, vaikka ne ovat hyvin rajallisia - tosiasia on, että nyt voit rekisteröityä vain yksi sovellus, joten älä kiirehdi siihen.
Nyt teknisestä näkökulmasta meidän pitäisi olla kiinnostuneita siitä, että rekisteröinnin jälkeen meidän pitäisi saada Telegramilta ilmoituksia dokumentaation, protokollan jne. päivityksistä. Toisin sanoen voitaisiin olettaa, että telakat sisältävä sivusto yksinkertaisesti hylättiin ja työskenteli edelleen erityisesti niiden kanssa, jotka alkoivat tehdä asiakkaita, koska se on helpompaa. Mutta ei, mitään sellaista ei havaittu, tietoa ei tullut.
Ja jos kirjoitat tyhjästä, niin saatujen parametrien käyttäminen on itse asiassa vielä kaukana. Siitä huolimatta ja puhuu niistä Aloitusvaiheessa, itse asiassa sinun on ensin otettava käyttöön - mutta jos uskoisit sivun lopussa protokollan yleiskuvaus, niin se on täysin turhaa.
Itse asiassa sekä ennen MTProtoa että sen jälkeen usealla tasolla kerralla (kuten käyttöjärjestelmän ytimessä työskentelevät ulkomaiset verkottajat sanovat, kerrosrikkomus) iso, tuskallinen ja kauhea aihe tulee tielle...
Binäärinen serialisointi: TL (Type Language) ja sen järjestelmä, ja tasot ja monet muut pelottavat sanat
Tämä aihe on itse asiassa avain Telegramin ongelmiin. Ja sieltä tulee paljon kauheita sanoja, jos yrität sukeltaa siihen.
Joten tässä on kaavio. Jos tämä sana tulee mieleesi, sano: , Arvasit oikein. Tavoite on sama: jokin kieli mahdollisen siirrettävän tiedon kuvaamiseksi. Tähän yhtäläisyydet loppuvat. Jos sivulta , tai virallisen asiakkaan lähdepuusta, yritämme avata jonkin skeeman, näemme jotain tällaista:
int ? = Int;
long ? = Long;
double ? = Double;
string ? = String;
vector#1cb5c415 {t:Type} # [ t ] = Vector t;
rpc_error#2144ca19 error_code:int error_message:string = RpcError;
rpc_answer_unknown#5e2ad36e = RpcDropAnswer;
rpc_answer_dropped_running#cd78e586 = RpcDropAnswer;
rpc_answer_dropped#a43ad8b7 msg_id:long seq_no:int bytes:int = RpcDropAnswer;
msg_container#73f1f8dc messages:vector<%Message> = MessageContainer;
---functions---
set_client_DH_params#f5045f1f nonce:int128 server_nonce:int128 encrypted_data:bytes = Set_client_DH_params_answer;
ping#7abe77ec ping_id:long = Pong;
ping_delay_disconnect#f3427b8c ping_id:long disconnect_delay:int = Pong;
invokeAfterMsg#cb9f372d msg_id:long query:!X = X;
invokeAfterMsgs#3dc4b4f0 msg_ids:Vector<long> query:!X = X;
account.updateProfile#78515775 flags:# first_name:flags.0?string last_name:flags.1?string about:flags.2?string = User;
account.sendChangePhoneCode#8e57deb flags:# allow_flashcall:flags.0?true phone_number:string current_number:flags.0?Bool = auth.SentCode;Tämän ensimmäistä kertaa näkevä pystyy intuitiivisesti tunnistamaan vain osan kirjoitetusta - no, nämä ovat ilmeisesti rakenteita (vaikka missä on nimi, vasemmalla vai oikealla?), niissä on kenttiä, jonka jälkeen kaksoispisteen jälkeen seuraa tyyppi... luultavasti. Tässä kulmasuluissa on luultavasti malleja, kuten C++:ssa (itse asiassa, ei oikeasti). Ja mitä kaikki muut symbolit tarkoittavat, kysymysmerkit, huutomerkit, prosenttiosuudet, hash-merkit (ja ilmeisesti ne tarkoittavat eri asioita eri paikoissa), joskus läsnä ja joskus ei, heksadesimaaliluvut - ja mikä tärkeintä, miten tästä päästään правильный (jota palvelin ei hylkää) tavuvirta? Sinun on luettava dokumentaatio (kyllä, lähellä on linkkejä JSON-version skeemaan - mutta se ei tee siitä selkeämpää).
Avaa sivu ja sukeltaa sienien ja diskreetin matematiikan maagiseen maailmaan, joka on samanlainen kuin matan 4. vuonna. Aakkoset, tyyppi, arvo, kombinaattori, toiminnallinen kombinaattori, normaalimuoto, yhdistelmätyyppi, polymorfinen tyyppi... ja siinä kaikki vain ensimmäinen sivu! Seuraava odottaa sinua , joka, vaikka se sisältää jo esimerkin triviaalista pyynnöstä ja vastauksesta, ei anna vastausta tyypillisimpiin tapauksiin, mikä tarkoittaa, että joudut kahlaamaan läpi venäjästä englanniksi käännetyn matematiikan uudelleenkerronta toisella kahdeksalla upotetulla sivuja!
Toiminnallisiin kieliin ja automaattiseen tyyppipäätelmään perehtyneet lukijat näkevät luonnollisesti tämän kielen kuvauskielen, vaikka esimerkistäkin, paljon tutumpana ja voivat sanoa, että tämä ei itse asiassa ole periaatteessa huonoa. Tämän vastalauseet ovat:
- kyllä, tavoite kuulostaa hyvältä, mutta valitettavasti hän ei saavutettu
- Koulutus venäläisissä yliopistoissa vaihtelee jopa IT-erikoisuuksien välillä - kaikki eivät ole suorittaneet vastaavaa kurssia
- Lopuksi, kuten näemme, käytännössä se on ei edellytä, koska vain rajoitettua osajoukkoa jopa kuvatusta TL:stä käytetään
Kuten sanottu kanavalla #perl FreeNode IRC -verkossa, joka yritti toteuttaa portin Telegramista Matrixiin (lainauksen käännös on muistista epätarkka):
Tuntuu, että joku tutustui tyyppiteoriaan ensimmäistä kertaa, innostui ja alkoi yrittää leikkiä sen kanssa välittämättä siitä, tarvitaanko sitä käytännössä.
Katso itse, jos paljaiden tyyppien (int, long jne.) tarve alkeellisena asiana ei herätä kysymyksiä - loppujen lopuksi ne täytyy toteuttaa manuaalisesti - vaikkapa yritetään johtaa niistä vektori. Eli itse asiassa joukko, jos kutsut tuloksena olevia asioita niiden oikeilla nimillä.
Mutta ennen
Lyhyt kuvaus TL-syntaksin osajoukosta niille, jotka eivät lue virallista dokumentaatiota
constructor = Type;
myVec ids:Vector<long> = Type;
fixed#abcdef34 id:int = Type2;
fixedVec set:Vector<Type2> = FixedVec;
constructorOne#crc32 field1:int = PolymorType;
constructorTwo#2crc32 field_a:long field_b:Type3 field_c:int = PolymorType;
constructorThree#deadcrc bit_flags_of_what_really_present:# optional_field4:bit_flags_of_what_really_present.1?Type = PolymorType;
an_id#12abcd34 id:int = Type3;
a_null#6789cdef = Type3;Määrittely alkaa aina suunnittelija, jonka jälkeen valinnaisesti (käytännössä - aina) symbolin kautta # on oltava CRC32 tämän tyyppisestä normalisoidusta kuvausmerkkijonosta. Seuraavaksi tulee kuvaus kentistä; jos ne ovat olemassa, tyyppi voi olla tyhjä. Tämä kaikki päättyy yhtäläisyysmerkkiin, sen tyypin nimeen, johon tämä konstruktori - eli itse asiassa alatyyppi - kuuluu. Mies yhtäläisyysmerkin oikealla puolella on polymorfinen - eli useat tietyt tyypit voivat vastata sitä.
Jos määritelmä esiintyy rivin jälkeen ---functions---, silloin syntaksi pysyy samana, mutta merkitys on erilainen: rakentajasta tulee RPC-funktion nimi, kentistä tulee parametreja (no, eli se pysyy täsmälleen samana annetussa rakenteessa, kuten alla on kuvattu , tämä on yksinkertaisesti määritetty merkitys) ja "polymorfinen tyyppi" - palautetun tuloksen tyyppi. Totta, se pysyy silti polymorfisena - juuri määritelty osiossa ---types---, mutta tätä rakentajaa "ei oteta huomioon". Kutsuttujen funktioiden ylikuormittaminen argumenteilla, ts. Jostain syystä useat samalla nimellä mutta eri allekirjoituksilla varustetut funktiot, kuten C++:ssa, eivät sisälly käyttöoikeussopimukseen.
Miksi "konstruktori" ja "polymorfinen", jos se ei ole OOP? No, itse asiassa jonkun on helpompi ajatella tätä OOP-termeillä - polymorfinen tyyppi abstraktina luokkana, ja konstruktorit ovat sen suoria jälkeläisiä luokkia, ja final useiden kielten terminologiassa. Itse asiassa tietysti vain täällä samankaltaisuus todellisilla ylikuormitetuilla konstruktorimenetelmillä OO-ohjelmointikielissä. Koska nämä ovat vain tietorakenteita, menetelmiä ei ole (vaikka funktioiden ja menetelmien kuvaus edelleen voi aiheuttaa hämmennystä niiden olemassaolosta, mutta se on eri asia) - konstruktoria voi ajatella arvona joka rakennetaan kirjoita kun luet tavuvirtaa.
Miten tämä tapahtuu? Deserialisoija, joka lukee aina 4 tavua, näkee arvon 0xcrc32 - ja ymmärtää mitä tapahtuu seuraavaksi field1 tyypin kanssa int, eli lukee tasan 4 tavua, tässä päällä oleva kenttä tyypin kanssa PolymorType lukea. Näkee 0x2crc32 ja ymmärtää, että ensin on kaksi kenttää kauempana long, mikä tarkoittaa, että luemme 8 tavua. Ja sitten taas monimutkainen tyyppi, joka deserialisoidaan samalla tavalla. Esimerkiksi, Type3 voidaan ilmoittaa piirissä heti, kun kaksi rakentajaa, vastaavasti, niin heidän on kohdattava jompikumpi 0x12abcd34, jonka jälkeen sinun on luettava vielä 4 tavua intTai 0x6789cdef, jonka jälkeen ei ole mitään. Kaikki muu - sinun on tehtävä poikkeus. Joka tapauksessa tämän jälkeen palataan 4 tavun lukemiseen int kenttiä field_c в constructorTwo ja lopetamme lukemisemme PolymorType.
Lopulta, jos jää kiinni 0xdeadcrc varten constructorThree, sitten kaikki muuttuu monimutkaisemmaksi. Ensimmäinen alamme on bit_flags_of_what_really_present tyypin kanssa # - itse asiassa tämä on vain tyypin alias nat, joka tarkoittaa "luonnollista numeroa". Eli itse asiassa etumerkitön int on muuten ainoa tapaus, jossa etumerkittömiä lukuja esiintyy todellisissa piireissä. Seuraavaksi siis kysymysmerkkinen rakennelma, eli tämä kenttä - se on johdossa vain jos vastaava bitti on asetettu kyseiseen kenttään (suunnilleen kolmioperaattorin tapaan). Joten oletetaan, että tämä bitti asetettiin, mikä tarkoittaa, että meidän on luettava edelleen kenttä, kuten Type, jossa esimerkissämme on 2 konstruktoria. Toinen on tyhjä (koostuu vain tunnisteesta), toisessa on kenttä ids tyypin kanssa ids:Vector<long>.
Saatat ajatella, että sekä mallit että geneeriset ominaisuudet ovat etuja tai Javaa. Mutta ei. Melkein. Tämä ainoa tapaus, jossa käytetään kulmasulkuja todellisissa piireissä, ja sitä käytetään VAIN Vectorissa. Tavuvirrassa nämä ovat 4 CRC32 tavua itse Vector-tyypille, aina sama, sitten 4 tavua - taulukon elementtien lukumäärä ja sitten itse nämä elementit.
Kun tähän lisätään se tosiasia, että serialisointi tapahtuu aina 4 tavun sanoilla, kaikki tyypit ovat sen kerrannaisia - myös sisäänrakennetut tyypit kuvataan bytes и string pituuden manuaalisella sarjoituksella ja tällä kohdistuksella 4 - no, kuulostaako normaalilta ja jopa suhteellisen tehokkaalta? Vaikka TL:n väitetään olevan tehokas binäärinen serialisointi, tuleeko JSON silti paljon paksummaksi, kun melkein mitä tahansa, jopa Boolen arvot ja yksimerkkiset merkkijonot laajennetaan 4 tavuksi? Katsos, tarpeettomatkin kentät voidaan ohittaa bittilipuilla, kaikki on melko hyvin, ja jopa laajennettavissa tulevaisuutta varten, joten miksi ei myöhemmin lisäisi konstruktoriin uusia valinnaisia kenttiä?..
Mutta ei, jos et lue lyhyttä kuvaustani, vaan koko dokumentaatiota ja ajattele toteutusta. Ensinnäkin konstruktorin CRC32 lasketaan kaavion tekstikuvauksen normalisoidun rivin mukaan (poista ylimääräinen välilyönti jne.) - joten jos uusi kenttä lisätään, tyypin kuvausrivi muuttuu ja siten sen CRC32 ja , näin ollen serialisointi. Ja mitä vanha asiakas tekisi, jos hän saisi kentän uusilla lipuilla, eikä hän tiedä mitä tehdä niille seuraavaksi?
Toiseksi, muistetaan CRC32, jota käytetään tässä pääasiassa nimellä hash-toiminnot määrittää yksiselitteisesti, minkä tyyppistä (de)sarjoitetaan. Tässä kohtaamme törmäysongelman - ja ei, todennäköisyys ei ole yksi 232:sta, vaan paljon suurempi. Kuka muistaa, että CRC32 on suunniteltu havaitsemaan (ja korjaamaan) tietoliikennekanavan virheet ja siten parantamaan näitä ominaisuuksia muiden vahingoksi? Se ei esimerkiksi välitä tavujen uudelleenjärjestelystä: jos lasket CRC32:n kahdesta rivistä, vaihdat toisella ensimmäiset 4 tavua seuraavien 4 tavujen kanssa - se on sama. Kun syötteemme on latinalaisista aakkosista peräisin olevia tekstijonoja (ja vähän välimerkkejä), eivätkä nämä nimet ole erityisen satunnaisia, tällaisen uudelleenjärjestelyn todennäköisyys kasvaa huomattavasti.
Muuten, kuka tarkisti mitä siellä oli? todella CRC32? Yhdessä aikaisemmista lähdekoodeista (jo ennen Waltmania) oli hash-funktio, joka kertoi jokaisen merkin numerolla 239, niin rakas näiden ihmisten, ha ha!
Lopulta, okei, tajusimme, että rakentajat, joilla on kenttätyyppi Vector<int> и Vector<PolymorType> on erilainen CRC32. Entä online-suorituskyky? Ja teoreettisesta näkökulmasta tuleeko tästä osa tyyppiä? Oletetaan, että ohitamme kymmenen tuhannen numeron joukon, hyvin kanssa Vector<int> kaikki on selvää, pituus ja vielä 40000 XNUMX tavua. Mitä jos tämä Vector<Type2>, joka koostuu vain yhdestä kentästä int ja se on yksin tyypissä - täytyykö meidän toistaa 10000xabcdef0 34 4 kertaa ja sitten XNUMX tavua int, tai kieli pystyy RIIPPUMAAN sen puolestamme rakentajasta fixedVec ja siirrätkö 80000 40000 tavun sijaan vain XNUMX XNUMX?
Tämä ei ole ollenkaan turha teoreettinen kysymys - kuvittele, että saat luettelon ryhmän käyttäjistä, joilla jokaisella on tunnus, etunimi, sukunimi - ero mobiiliyhteyden kautta siirrettävän tiedon määrässä voi olla merkittävä. Meille mainostetaan juuri Telegram-sarjan tehokkuutta.
Niin…
Vector, jota ei koskaan julkaistu
Jos yrität kahlata läpi kombinaattoreiden kuvaussivuja ja niin edelleen, huomaat, että vektori (ja jopa matriisi) yritetään muodollisesti tulostaa useiden arkkien monikoiden kautta. Mutta lopulta he unohtavat, viimeinen vaihe ohitetaan ja vektorille annetaan yksinkertaisesti määritelmä, jota ei ole vielä sidottu tyyppiin. Mikä hätänä? kielillä ohjelmointi, varsinkin toiminnalliset, on varsin tyypillistä kuvata rakennetta rekursiivisesti - kääntäjä laiskalla arvioinnillaan ymmärtää ja tekee kaiken itse. Kielessä tietojen serialisointi tarvitaan TEHOKKUUS: riittää, kun kuvataan lista, eli kahden elementin rakenne - ensimmäinen on tietoelementti, toinen on sama rakenne itse tai tyhjä tila häntää varten (paketti (cons) Lispissä). Mutta tämä tietysti vaatii kukin elementti kuluttaa vielä 4 tavua (TL:n tapauksessa CRC32) tyyppinsä kuvaamiseen. Joukko voidaan myös kuvata helposti kiinteä koko, mutta jos kyseessä on ennalta tuntemattoman pituinen taulukko, katkeamme.
Siksi, koska TL ei salli vektorin tulostamista, se piti lisätä sivuun. Lopulta asiakirjoissa sanotaan:
Serialisointi käyttää aina samaa konstruktori "vektoria" (const 0x1cb5c415 = crc32("vektori t: Tyyppi # [ t ] = Vektori t"), joka ei ole riippuvainen tyypin t muuttujan tietystä arvosta.
Valinnaisen parametrin t arvo ei ole mukana sarjoituksessa, koska se on johdettu tulostyypistä (tunnetaan aina ennen sarjoitusta).
Katso tarkemmin: vector {t:Type} # [ t ] = Vector t - mutta ei missään Tämä määritelmä itsessään ei tarkoita, että ensimmäisen luvun tulee olla yhtä suuri kuin vektorin pituus! Eikä se tule mistään. Tämä on asia, joka on pidettävä mielessä ja toteutettava käsin. Muualla dokumentaatiossa jopa mainitaan rehellisesti, että tyyppi ei ole todellinen:
Vektorin t polymorfinen pseudotyyppi on "tyyppi", jonka arvo on minkä tahansa tyypin t arvojen sarja, joko laatikoitu tai paljas.
... mutta ei keskity siihen. Kun olet kyllästynyt kahlaamaan matematiikan venyttelyä (jotka olet tuntenut jopa yliopistokurssilta), päätät luovuttaa ja katsot käytännössä, miten sen kanssa työskentelet, päähän jää vaikutelma, että tämä on vakavaa Matematiikka on ytimessä, sen keksivät selvästi Cool People (kaksi matemaatikkoa - ACM-voittaja), eikä kuka tahansa. Tavoite - esitellä - on saavutettu.
Muuten, numerosta. Muistutetaan tästä
#se on synonyyminat, luonnollinen luku:On tyyppilausekkeita (type-expr) ja numeerisia lausekkeita (nat-laus). Ne määritellään kuitenkin samalla tavalla.
type-expr ::= expr nat-expr ::= exprmutta kieliopissa ne kuvataan samalla tavalla, ts. Tämä ero on jälleen muistettava ja toteutettava käsin.
No, kyllä, mallityypit (vector<int>, vector<User>) niillä on yhteinen tunniste (#1cb5c415), eli jos tiedät, että puhelu on ilmoitettu nimellä
users.getUsers#d91a548 id:Vector<InputUser> = Vector<User>;silloin et enää odota vain vektoria, vaan käyttäjien vektoria. Tarkemmin, pitäisi odota - todellisessa koodissa jokaisella elementillä, ellei paljaalla tyypillä, on konstruktori, ja hyvällä tavalla toteutuksessa se olisi tarpeen tarkistaa - mutta meidät lähetettiin tarkalleen tämän vektorin jokaisessa elementissä sitä tyyppiä? Entä jos se olisi jonkinlainen PHP, jossa taulukko voi sisältää eri tyyppejä eri elementeissä?
Tässä vaiheessa alat miettiä - onko tällainen TL tarpeen? Ehkä kärryyn olisi mahdollista käyttää ihmisserialisaattoria, samaa protobufia, joka oli jo silloin olemassa? Se oli teoria, katsotaanpa käytäntöä.
Olemassa olevat TL-toteutukset koodissa
TL syntyi VKontakten syvyyksissä jo ennen kuuluisia tapahtumia Durovin osuuden myynnistä ja (varmasti), jo ennen Telegramin kehittämistä. Ja avoimessa lähdekoodissa löydät paljon hauskoja kainalosauvoja. Ja itse kieli toteutettiin siellä täydellisemmin kuin nyt Telegramissa. Esimerkiksi hajautusarvoja ei käytetä lainkaan järjestelmässä (tarkoittaa sisäänrakennettua pseudotyyppiä (kuten vektoria), jolla on poikkeava käyttäytyminen). Tai
Templates are not used now. Instead, the same universal constructors (for example, vector {t:Type} [t] = Vector t) are used wmutta tarkastelkaamme täydellisyyden vuoksi niin sanotusti Ajatuksen jättiläisen kehitystä.
#define ZHUKOV_BYTES_HACK
#ifdef ZHUKOV_BYTES_HACK
/* dirty hack for Zhukov request */Tai tämä kaunis:
static const char *reserved_words_polymorhic[] = {
"alpha", "beta", "gamma", "delta", "epsilon", "zeta", "eta", "theta", NULL
};Tämä fragmentti käsittelee malleja, kuten:
intHash {alpha:Type} vector<coupleInt<alpha>> = IntHash<alpha>;Tämä on hashmap-mallin tyypin määritelmä int - tyyppi -parien vektorina. C++:ssa se näyttäisi suunnilleen tältä:
template <T> class IntHash {
vector<pair<int,T>> _map;
}niin, alpha - avainsana! Mutta vain C++:ssa voi kirjoittaa T, mutta kannattaa kirjoittaa alfa, beta... Mutta enintään 8 parametria, siihen fantasia loppuu. Näyttää siltä, että joskus Pietarissa on käyty tällaisia dialogeja:
-- Надо сделать в TL шаблоны
-- Бл... Ну пусть параметры зовут альфа, бета,... Какие там ещё буквы есть... О, тэта!
-- Грамматика? Ну потом напишем
-- Смотрите, какой я синтаксис придумал для шаблонов и вектора!
-- Ты долбанулся, как мы это парсить будем?
-- Да не ссыте, он там один в схеме, захаркодить -- и окMutta tässä oli kyse ensimmäisestä julkaistusta TL:n toteutuksesta "yleensä". Siirrytään tarkastelemaan toteutuksia itse Telegram-asiakkaissa.
Sana Vasilylle:
Vasily, [09.10.18 17:07]
Minua oikeasti ärsyttää se, että he ovat lätkäisseet yhteen joukon abstraktioita ja sitten luopuneet niistä ja peittäneet koodigeneraattorin kainalosauvoilla.
Tämän seurauksena ensin dock pilot.jpg -tiedostosta
Sitten koodista dzhekichan.webp
Algoritmeihin ja matematiikkaan perehtyneiltä ihmisiltä voimme tietysti odottaa, että he ovat lukeneet Ahoa, Ullmannia ja tuntevat työkalut, joista on vuosikymmenten aikana tullut teollisuudessa de facto standardi DSL-kääntäjien kirjoittamiseen, eikö niin?
Tekijän toimesta on Vitaly Valtman, kuten TLO-formaatin esiintymisestä sen (kli)rajojen ulkopuolella voi ymmärtää, tiimin jäsen - nyt on varattu kirjasto TL-jäsennystä varten , mikä vaikutelma hänestä on ? ..
16.12 04:18 Vasily: Luulen, että joku ei hallinnut lex+yaccia
16.12 04:18 Vasily: En osaa selittää sitä muuten
16.12 04:18 Vasily: no, tai sitten heille maksettiin VK:n rivien määrästä
16.12 04:19 Vasily: 3k+ riviä jne.<censored>jäsentimen sijaan
Ehkä poikkeus? Katsotaanpa miten Tämä on VIRALLINEN asiakas - Telegram Desktop:
nametype = re.match(r'([a-zA-Z.0-9_]+)(#[0-9a-f]+)?([^=]*)=s*([a-zA-Z.<>0-9_]+);', line);
if (not nametype):
if (not re.match(r'vector#1cb5c415 {t:Type} # [ t ] = Vector t;', line)):
print('Bad line found: ' + line);Pythonissa yli 1100 riviä, pari säännöllistä lauseketta + erikoistapauksia kuten vektori, joka tietysti on ilmoitettu kaavassa niin kuin sen pitäisi olla TL-syntaksin mukaan, mutta he luottivat tähän syntaksiin jäsentäessään sen... Herää kysymys, miksi se kaikki oli ihmettä?иSe on kerroksellisempaa, jos kukaan ei kuitenkaan aio jäsentää sitä dokumentaation mukaan?!
Muuten... Muistatko, että puhuimme CRC32-tarkastuksesta? Joten Telegram Desktop -koodigeneraattorissa on luettelo poikkeuksista niille tyypeille, joissa laskettu CRC32 ei sovi yhteen kaaviossa esitetyn kanssa!
Vasily, [18.12 22:49]
ja tässä pitäisi miettiä, onko tällainen TL tarpeen
jos haluaisin sotkea vaihtoehtoisten toteutusten kanssa, alkaisin lisätä rivinvaihtoja, puolet jäsentimistä katkeaa monirivisten määritelmien yhteydessä
tdesktop kuitenkin myös
Muista pointti one-lineristä, palaamme siihen hieman myöhemmin.
Okei, Telegram-cli on epävirallinen, Telegram Desktop on virallinen, mutta entä muut? Kuka tietää? Koodissa. Android- asiakkaalla ei ollut lainkaan skeemajäsennintä (mikä herättää kysymyksiä sen avoimen lähdekoodin luonteesta, mutta se on toisen osan osalta), mutta useita muita hauskoja koodinpätkiä löytyi, mutta lisää niistä alla olevassa alaosiossa.
Mitä muita kysymyksiä serialisointi käytännössä herättää? He esimerkiksi tekivät paljon asioita tietysti bittikentillä ja ehdollisilla kentillä:
Vasily:
flags.0? true
tarkoittaa, että kenttä on olemassa ja on yhtä suuri kuin tosi, jos lippu on asetettuVasily:
flags.1? int
tarkoittaa, että kenttä on olemassa ja se on deserialisoitavaVasily: Perse, älä välitä mitä teet!
Vasily: Jossain dokumentissa mainitaan, että true on paljas nollapituustyyppi, mutta heidän dokumentistaan on mahdotonta koota mitään
Vasily: Avoimen lähdekoodin toteutuksissa näin ei myöskään ole, mutta siellä on joukko kainalosauvoja ja tukia
Entä Telethon? MTProton aihetta eteenpäin katsoen esimerkki - dokumentaatiossa on sellaisia kappaleita, mutta merkki % sitä kuvataan vain "vastaamaan tiettyä paljastyyppiä", ts. alla olevissa esimerkeissä on joko virhe tai jotain dokumentoimatonta:
Vasily, [22.06.18 18:38]
Yhdessä paikassa:msg_container#73f1f8dc messages:vector message = MessageContainer;Toisessa:
msg_container#73f1f8dc messages:vector<%Message> = MessageContainer;Ja nämä ovat kaksi suurta eroa, tosielämässä tulee jonkinlainen paljas vektori
En ole nähnyt paljaaa vektorimääritelmää, enkä ole törmännyt sellaiseen
Analyysi kirjoitetaan käsin telethonissa
Hänen kaaviossaan määritelmä on kommentoitu
msg_containerJälleen kysymys on prosentista. Sitä ei kuvata.
Vadim Gontšarov, [22.06.18 19:22]
ja tdesktopissa?Vasily, [22.06.18 19:23]
Mutta heidän TL-jäsennin säätimillä ei todennäköisesti syö sitä myöskään.
// parsed manuallyTL on kaunis abstraktio, kukaan ei toteuta sitä täysin
Ja % ei ole heidän versiossaan järjestelmästä
Mutta tässä dokumentaatio on ristiriidassa itsensä kanssa, joten idk
Se löytyi kielioppista, he saattoivat yksinkertaisesti unohtaa kuvata semantiikan
Näit asiakirjan TL:ssä, et voi selvittää sitä ilman puoli litraa
"No, sanotaanpa", toinen lukija sanoo, "sinä kritisoit jotain, joten näytä minulle, kuinka se pitäisi tehdä."
Vasily vastaa: ”Jäsentimen osalta pidän sellaisista asioista
args: /* empty */ { $$ = NULL; }
| args arg { $$ = g_list_append( $1, $2 ); }
;
arg: LC_ID ':' type-term { $$ = tl_arg_new( $1, $3 ); }
| LC_ID ':' condition '?' type-term { $$ = tl_arg_new_cond( $1, $5, $3 ); free($3); }
| UC_ID ':' type-term { $$ = tl_arg_new( $1, $3 ); }
| type-term { $$ = tl_arg_new( "", $1 ); }
| '[' LC_ID ']' { $$ = tl_arg_new_mult( "", tl_type_new( $2, TYPE_MOD_NONE ) ); }
;jotenkin pidä siitä paremmin kuin
struct tree *parse_args4 (void) {
PARSE_INIT (type_args4);
struct parse so = save_parse ();
PARSE_TRY (parse_optional_arg_def);
if (S) {
tree_add_child (T, S);
} else {
load_parse (so);
}
if (LEX_CHAR ('!')) {
PARSE_ADD (type_exclam);
EXPECT ("!");
}
PARSE_TRY_PES (parse_type_term);
PARSE_OK;
}tai
# Regex to match the whole line
match = re.match(r'''
^ # We want to match from the beginning to the end
([w.]+) # The .tl object can contain alpha_name or namespace.alpha_name
(?:
# # After the name, comes the ID of the object
([0-9a-f]+) # The constructor ID is in hexadecimal form
)? # If no constructor ID was given, CRC32 the 'tl' to determine it
(?:s # After that, we want to match its arguments (name:type)
{? # For handling the start of the '{X:Type}' case
w+ # The argument name will always be an alpha-only name
: # Then comes the separator between name:type
[wd<>#.?!]+ # The type is slightly more complex, since it's alphanumeric and it can
# also have Vector<type>, flags:# and flags.0?default, plus :!X as type
}? # For handling the end of the '{X:Type}' case
)* # Match 0 or more arguments
s # Leave a space between the arguments and the equal
=
s # Leave another space between the equal and the result
([wd<>#.?]+) # The result can again be as complex as any argument type
;$ # Finally, the line should always end with ;
''', tl, re.IGNORECASE | re.VERBOSE)tämä on KOKO lexer:
---functions--- return FUNCTIONS;
---types--- return TYPES;
[a-z][a-zA-Z0-9_]* yylval.string = strdup(yytext); return LC_ID;
[A-Z][a-zA-Z0-9_]* yylval.string = strdup(yytext); return UC_ID;
[0-9]+ yylval.number = atoi(yytext); return NUM;
#[0-9a-fA-F]{1,8} yylval.number = strtol(yytext+1, NULL, 16); return ID_HASH;
n /* skip new line */
[ t]+ /* skip spaces */
//.*$ /* skip comments */
/*.**/ /* skip comments */
. return (int)yytext[0];nuo. yksinkertaisempaa on lievästi sanottuna."
Yleensä seurauksena TL:n todellisuudessa käytetyn osajoukon jäsentäjä ja koodigeneraattori mahtuvat noin 100 kielioppiriville ja ~300 generaattorin riville (kaikki laskettuna print's luoma koodi), mukaan lukien tyyppitietopussit itsetutkiskelua varten kussakin luokassa. Jokainen polymorfinen tyyppi muuttuu tyhjäksi abstraktiksi perusluokiksi, ja konstruktorit perivät siitä ja heillä on menetelmät sarjoitukseen ja deserialisointiin.
Tyyppien puute tyyppikielessä
Vahva kirjoittaminen on hyvä asia, eikö? Ei, tämä ei ole holivar (vaikka pidän mieluummin dynaamisista kielistä), vaan postulaatti TL:n puitteissa. Sen perusteella kielen pitäisi tarjota meille kaikenlaisia tarkastuksia. No, okei, ei ehkä hän itse, vaan toteutus, mutta hänen pitäisi ainakin kuvata ne. Ja millaisia mahdollisuuksia haluamme?
Ensinnäkin rajoitukset. Tässä näkyy tiedostojen lataamisen dokumentaatio:
Tiedoston binaarisisältö jaetaan sitten osiin. Kaikkien osien tulee olla samankokoisia ( osa_koko ) ja seuraavat ehdot on täytettävä:
part_size % 1024 = 0(jaollinen 1 kilotavulla)524288 % part_size = 0(512 kt:n on oltava tasaisesti jaettavissa osan koolla)Viimeisen osan ei tarvitse täyttää näitä ehtoja, jos sen koko on pienempi kuin osakoko.
Jokaisella osalla tulee olla järjestysnumero, file_part, jonka arvo vaihtelee välillä 0 - 2,999 XNUMX.
Kun tiedosto on osioitu, sinun on valittava menetelmä sen tallentamiseksi palvelimelle. Käyttää jos tiedoston täysi koko on yli 10 Mt ja pienempiä tiedostoja varten.
[…] jokin seuraavista tietojen syöttövirheistä voidaan palauttaa:
- FILE_PARTS_INVALID — Virheellinen osien määrä. Arvo ei ole välillä
1..3000
Onko kaaviossa jokin näistä? Onko tämä jotenkin ilmaistavissa TL:llä? Ei. Mutta anteeksi, jopa isoisän Turbo Pascal pystyi kuvaamaan määritellyt tyypit vaihteluvälit. Ja hän tiesi vielä yhden asian, joka nyt tunnetaan paremmin nimellä enum - tyyppi, joka koostuu kiinteän (pienen) arvojen lukumäärästä. Kielessä, kuten C - numeerinen, huomaa, että toistaiseksi olemme puhuneet vain tyypeistä numerot. Mutta on myös taulukoita, merkkijonoja... esimerkiksi olisi kiva kuvailla, että tämä merkkijono voi sisältää vain puhelinnumeron, eikö niin?
Mikään näistä ei ole TL:ssä. Mutta on olemassa esimerkiksi JSON Schema. Ja jos joku muu saattaisi kiistellä 512 KB:n jaettavuudesta, että tämä pitää vielä tarkistaa koodissa, niin varmista, että asiakas yksinkertaisesti ei pystynyt lähettää numeron alueen ulkopuolella 1..3000 (ja vastaavaa virhettä ei olisi voinut syntyä) se olisi ollut mahdollista, eikö?..
Muuten, virheistä ja palautusarvoista. Jopa ne, jotka ovat työskennelleet TL:n parissa, sumentavat silmänsä - se ei tullut meille heti jokainen TL:n funktio voi itse asiassa palauttaa kuvatun palautustyypin lisäksi myös virheen. Mutta tätä ei voida millään tavalla päätellä käyttämällä itse TL:ää. Tietysti asia on jo selvä, eikä käytännössä tarvita mitään (vaikka itse asiassa RPC voidaan tehdä eri tavoin, palataan tähän myöhemmin) - mutta entä abstraktien tyyppien matematiikan käsitteiden puhtaus taivaallisesta maailmasta?.. Otin hinaajan - niin sovita se.
Ja lopuksi, entä luettavuus? No, siellä, yleensä, haluaisin kuvaus onko se oikein skeemassa (jälleen JSON-skeemassa), mutta jos olet jo jännittynyt siihen, entä sitten käytännön puoli - ainakin triviaalia tarkastella eroja päivitysten aikana? Katso itse osoitteessa :
-channelFull#76af5481 flags:# can_view_participants:flags.3?true can_set_username:flags.6?true can_set_stickers:flags.7?true hidden_prehistory:flags.10?true id:int about:string participants_count:flags.0?int admins_count:flags.1?int kicked_count:flags.2?int banned_count:flags.2?int read_inbox_max_id:int read_outbox_max_id:int unread_count:int chat_photo:Photo notify_settings:PeerNotifySettings exported_invite:ExportedChatInvite bot_info:Vector<BotInfo> migrated_from_chat_id:flags.4?int migrated_from_max_id:flags.4?int pinned_msg_id:flags.5?int stickerset:flags.8?StickerSet available_min_id:flags.9?int = ChatFull;
+channelFull#1c87a71a flags:# can_view_participants:flags.3?true can_set_username:flags.6?true can_set_stickers:flags.7?true hidden_prehistory:flags.10?true can_view_stats:flags.12?true id:int about:string participants_count:flags.0?int admins_count:flags.1?int kicked_count:flags.2?int banned_count:flags.2?int online_count:flags.13?int read_inbox_max_id:int read_outbox_max_id:int unread_count:int chat_photo:Photo notify_settings:PeerNotifySettings exported_invite:ExportedChatInvite bot_info:Vector<BotInfo> migrated_from_chat_id:flags.4?int migrated_from_max_id:flags.4?int pinned_msg_id:flags.5?int stickerset:flags.8?StickerSet available_min_id:flags.9?int = ChatFull;
tai
-message#44f9b43d flags:# out:flags.1?true mentioned:flags.4?true media_unread:flags.5?true silent:flags.13?true post:flags.14?true id:int from_id:flags.8?int to_id:Peer fwd_from:flags.2?MessageFwdHeader via_bot_id:flags.11?int reply_to_msg_id:flags.3?int date:int message:string media:flags.9?MessageMedia reply_markup:flags.6?ReplyMarkup entities:flags.7?Vector<MessageEntity> views:flags.10?int edit_date:flags.15?int post_author:flags.16?string grouped_id:flags.17?long = Message;
+message#44f9b43d flags:# out:flags.1?true mentioned:flags.4?true media_unread:flags.5?true silent:flags.13?true post:flags.14?true from_scheduled:flags.18?true id:int from_id:flags.8?int to_id:Peer fwd_from:flags.2?MessageFwdHeader via_bot_id:flags.11?int reply_to_msg_id:flags.3?int date:int message:string media:flags.9?MessageMedia reply_markup:flags.6?ReplyMarkup entities:flags.7?Vector<MessageEntity> views:flags.10?int edit_date:flags.15?int post_author:flags.16?string grouped_id:flags.17?long = Message;
Se riippuu kaikista, mutta esimerkiksi GitHub kieltäytyy korostamasta muutoksia niin pitkien rivien sisällä. Peli "löydä 10 eroa", ja aivot näkevät heti sen, että molemmissa esimerkeissä alku ja loppu ovat samat, sinun täytyy lukea ikävästi jostain puolivälistä... Mielestäni tämä ei ole vain teoriassa, mutta puhtaasti visuaalisesti likainen ja huolimaton.
Muuten, teorian puhtaudesta. Miksi tarvitsemme bittikenttiä? Eikö näytä siltä haju huono tyyppiteorian kannalta? Selitys näkyy kaavion aiemmissa versioissa. Aluksi kyllä, näin se oli, jokaista aivastelua kohti luotiin uusi tyyppi. Nämä alkeet ovat edelleen olemassa tässä muodossa, esimerkiksi:
storage.fileUnknown#aa963b05 = storage.FileType;
storage.filePartial#40bc6f52 = storage.FileType;
storage.fileJpeg#7efe0e = storage.FileType;
storage.fileGif#cae1aadf = storage.FileType;
storage.filePng#a4f63c0 = storage.FileType;
storage.filePdf#ae1e508d = storage.FileType;
storage.fileMp3#528a0677 = storage.FileType;
storage.fileMov#4b09ebbc = storage.FileType;
storage.fileMp4#b3cea0e4 = storage.FileType;
storage.fileWebp#1081464c = storage.FileType;Mutta nyt kuvittele, että jos rakenteessasi on 5 valinnaista kenttää, tarvitset 32 tyyppiä kaikkia mahdollisia vaihtoehtoja varten. Kombinatorinen räjähdys. Siten TL-teorian kristallipuhtaus särkyi jälleen kerran sarjaamisen ankaran todellisuuden valurautapersettä vastaan.
Lisäksi joissain paikoissa nämä kaverit itse rikkovat omaa typologiaan. Esimerkiksi MTProtossa (seuraava luku) Gzip voi pakata vastauksen, kaikki on kunnossa - paitsi että kerrokset ja piiri ovat rikki. Jälleen kerran, itse RpcResult ei korjattu, vaan sen sisältö. No miksi näin?.. Minun piti leikata kainalosauvaan, jotta puristus toimisi missä tahansa.
Tai toinen esimerkki, löysimme kerran virheen - se lähetettiin InputPeerUser sen sijasta InputUser. Tai päinvastoin. Mutta se toimi! Eli palvelin ei välittänyt tyypistä. Miten tämä voi olla? Vastauksen voivat antaa meille koodinpätkä telegram-cli:stä:
if (tgl_get_peer_type (E->id) != TGL_PEER_CHANNEL || (C && (C->flags & TGLCHF_MEGAGROUP))) {
out_int (CODE_messages_get_history);
out_peer_id (TLS, E->id);
} else {
out_int (CODE_channels_get_important_history);
out_int (CODE_input_channel);
out_int (tgl_get_peer_id (E->id));
out_long (E->id.access_hash);
}
out_int (E->max_id);
out_int (E->offset);
out_int (E->limit);
out_int (0);
out_int (0);Toisin sanoen tässä tehdään serialisointi KÄSIN, ei luotu koodi! Ehkä palvelin on toteutettu samalla tavalla?.. Periaatteessa tämä onnistuu kerran tehtynä, mutta miten sitä voidaan tukea myöhemmin päivitysten aikana? Siksikö järjestelmä keksittiin? Ja tässä siirrytään seuraavaan kysymykseen.
Versiointi. Kerrokset
Miksi kaavamaisia versioita kutsutaan tasoiksi, voidaan vain spekuloida julkaistujen kaavioiden historian perusteella. Ilmeisesti kirjoittajat ajattelivat aluksi, että perusasiat voidaan tehdä ennallaan kaaviolla, ja vain tarvittaessa, erityisistä pyynnöistä osoittavat, että ne tehdään eri versiolla. Periaatteessa jopa hyvä idea - ja uusi tulee ikään kuin "sekoitettua", kerrostettuna vanhan päälle. Mutta katsotaan kuinka se tehtiin. Totta, en voinut katsoa sitä alusta alkaen - se on hauskaa, mutta pohjakerroksen kaaviota ei yksinkertaisesti ole olemassa. Tasot alkoivat 2:lla. Dokumentaatio kertoo meille erityisestä TL-ominaisuudesta:
Jos asiakas tukee tasoa 2, on käytettävä seuraavaa rakentajaa:
invokeWithLayer2#289dd1f6 {X:Type} query:!X = X;Käytännössä tämä tarkoittaa, että ennen jokaista API-kutsua, int, jossa on arvo
0x289dd1f6on lisättävä ennen menetelmän numeroa.
Kuulostaa normaalilta. Mutta mitä tapahtui seuraavaksi? Sitten ilmestyi
invokeWithLayer3#b7475268 query:!X = X;Mitä seuraavaksi? Kuten arvata saattaa,
invokeWithLayer4#dea0d430 query:!X = X;Hauska? Ei, on liian aikaista nauraa, ajattele sitä tosiasiaa kukin toisen kerroksen pyyntö on käärittävä sellaiseen erikoistyyppiin - jos ne ovat kaikki erilaisia sinulle, kuinka muuten voit erottaa ne? Ja vain 4 tavun lisääminen eteen on melko tehokas tapa. Niin,
invokeWithLayer5#417a57ae query:!X = X;Mutta on selvää, että jonkin ajan kuluttua tästä tulee jonkinlainen bakkanalia. Ja ratkaisu tuli:
Päivitys: Alkaen Tasosta 9, apumenetelmistä
invokeWithLayerNvoidaan käyttää vain yhdessäinitConnection
Hurraa! Yhdeksän version jälkeen päästiin vihdoin siihen, mitä Internet-protokollassa tehtiin 9-luvulla - versiosta sovittiin kerran yhteyden alussa!
Joten mitä seuraavaksi?...
invokeWithLayer10#39620c41 query:!X = X;
...
invokeWithLayer18#1c900537 query:!X = X;Mutta nyt saa vielä nauraa. Vasta 9 kerroksen jälkeen lisättiin vihdoin universaali konstruktori versionumerolla, jota tarvitsee kutsua vain kerran yhteyden alussa ja kerrosten merkitys näytti kadonneen, nyt se on vain ehdollinen versio, esim. kaikkialla muualla. Ongelma ratkaistu.
Tarkalleen?..
Vasily, [16.07.18 14:01]
Mietin perjantaina:
Telepalvelin lähettää tapahtumia ilman pyyntöä. Pyynnöt on käärittävä InvokeWithLayeriin. Palvelin ei kääri päivityksiä; vastausten ja päivitysten käärimiseen ei ole rakennetta.Nuo. asiakas ei voi määrittää kerrosta, johon hän haluaa päivityksiä
Vadim Gontšarov, [16.07.18 14:02]
Eikö InvokeWithLayer ole periaatteessa hakkerointi?Vasily, [16.07.18 14:02]
Tämä on ainoa tapaVadim Gontšarov, [16.07.18 14:02]
mikä pohjimmiltaan tarkoittaa kerroksen sopimista istunnon alussaMuuten, tästä seuraa, että asiakasversiota ei tarjota
Päivitykset, ts. tyyppi Updates järjestelmässä tämän palvelin lähettää asiakkaalle ei vastauksena API-pyyntöön, vaan itsenäisesti tapahtuman sattuessa. Tämä on monimutkainen aihe, josta keskustellaan toisessa viestissä, mutta toistaiseksi on tärkeää tietää, että palvelin tallentaa päivitykset myös silloin, kun asiakas on offline-tilassa.
Jos siis kieltäydyt käärimästä kukin paketti ilmoittaa sen version, tämä johtaa loogisesti seuraaviin mahdollisiin ongelmiin:
- palvelin lähettää päivitykset asiakkaalle jo ennen kuin asiakas on ilmoittanut, mitä versiota se tukee
- mitä minun pitäisi tehdä asiakkaan päivittämisen jälkeen?
- joka takuitaettä palvelimen mielipide tasonumerosta ei muutu prosessin aikana?
Luuletko, että tämä on puhtaasti teoreettista spekulaatiota, ja käytännössä näin ei voi tapahtua, koska palvelin on kirjoitettu oikein (ainakin se on testattu hyvin)? Hah! Ihan sama miten se on!
Juuri tähän törmäsimme elokuussa. Elokuun 14. päivänä tuli viestejä, että jotain päivitettiin Telegram-palvelimilla... ja sitten lokeissa:
2019-08-15 09:28:35.880640 MSK warn main: ANON:87: unknown object type: 0x80d182d1 at TL/Object.pm line 213.
2019-08-15 09:28:35.751899 MSK warn main: ANON:87: unknown object type: 0xb5223b0f at TL/Object.pm line 213.ja sitten useita megatavuja pinojälkiä (no, samaan aikaan lokikirjaus korjattiin). Loppujen lopuksi, jos jotain ei tunnisteta TL:ssäsi, se on binääritunnus allekirjoituksella, myöhemmässä rivissä KAIKKI dekoodauksesta tulee mahdotonta. Mitä tällaisessa tilanteessa pitäisi tehdä?
No, ensimmäinen asia, joka kenenkään mieleen tulee, on katkaista yhteys ja yrittää uudelleen. Ei auttanut. Googlaamme CRC32:ta - nämä osoittautuivat objekteiksi kaaviosta 73, vaikka työskentelimme 82:n parissa. Katsomme lokit huolellisesti - siellä on tunnisteita kahdesta eri skeemasta!
Voisiko ongelma olla puhtaasti epävirallisessa asiakasohjelmassamme? Ei, käynnistetään Telegram Desktop 1.2.17 (versio, joka sisältyy joihinkin jakeluihin). Linux), hän kirjoittaa poikkeuslokiin: MTP Odottamaton tyyppitunnus #b5223b0f luettu MTPMessageMedia-tiedostosta…
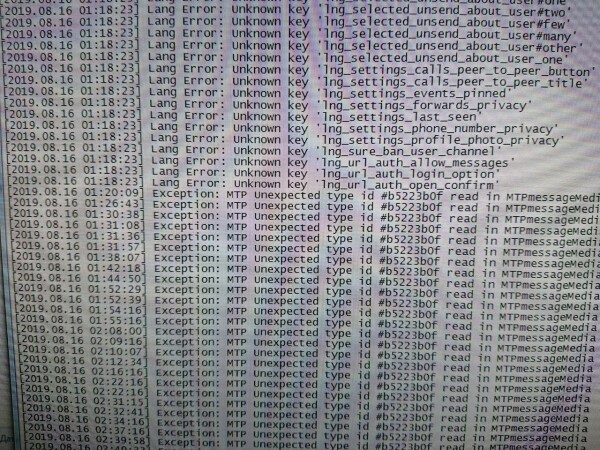
Google osoitti, että samanlainen ongelma oli jo sattunut yhdelle epävirallisista asiakkaista, mutta sitten versionumerot ja vastaavasti oletukset olivat erilaisia...
Mitä meidän pitäisi tehdä? Vasili ja minä erosimme: hän yritti päivittää piirin 91:een, päätin odottaa muutaman päivän ja kokeilla 73:a. Molemmat menetelmät toimivat, mutta koska ne ovat empiirisiä, ei ole käsitystä siitä, kuinka monta versiota ylös tai alas tarvitset. hypätä tai kuinka kauan sinun on odotettava .
Myöhemmin pystyin toistamaan tilanteen: käynnistämme asiakkaan, sammutamme sen, käännämme piirin uudelleen toiselle kerrokselle, käynnistetään uudelleen, havaitsemme ongelman uudelleen, palaamme edelliseen - hups, ei piirin vaihtoa ja asiakas käynnistyy uudelleen hetkeksi. muutama minuutti auttaa. Saat yhdistelmän tietorakenteita eri tasoilta.
Selitys? Kuten useista epäsuorista oireista voi päätellä, palvelin koostuu useista erityyppisistä prosesseista eri koneissa. Todennäköisimmin "puskuroinnista" vastaava palvelin laittoi jonoon sen, minkä esimiehet sille antoivat, ja he antoivat sen siinä järjestelmässä, joka oli käytössä luomishetkellä. Ja ennen kuin tämä jono "mätä", sille ei voitu tehdä mitään.
Ellei sitten... mutta eikö se ole kamala kiertotie?!.. Ei, ennen kuin ajattelemme hulluja ideoita, katsotaanpa virallisten asiakkaiden koodia. Versiossa, joka on tarkoitettu Android Emme löydä TL-jäsenninohjelmaa, mutta löydämme valtavan tiedoston (GitHub kieltäytyy värittämästä sitä) josta on poistettu (ja/poistettu) sarjoitukset. Tässä ovat koodinpätkät:
public static class TL_message_layer68 extends TL_message {
public static int constructor = 0xc09be45f;
//...
//еще пачка подобных
//...
public static class TL_message_layer47 extends TL_message {
public static int constructor = 0xc992e15c;
public static Message TLdeserialize(AbstractSerializedData stream, int constructor, boolean exception) {
Message result = null;
switch (constructor) {
case 0x1d86f70e:
result = new TL_messageService_old2();
break;
case 0xa7ab1991:
result = new TL_message_old3();
break;
case 0xc3060325:
result = new TL_message_old4();
break;
case 0x555555fa:
result = new TL_message_secret();
break;
case 0x555555f9:
result = new TL_message_secret_layer72();
break;
case 0x90dddc11:
result = new TL_message_layer72();
break;
case 0xc09be45f:
result = new TL_message_layer68();
break;
case 0xc992e15c:
result = new TL_message_layer47();
break;
case 0x5ba66c13:
result = new TL_message_old7();
break;
case 0xc06b9607:
result = new TL_messageService_layer48();
break;
case 0x83e5de54:
result = new TL_messageEmpty();
break;
case 0x2bebfa86:
result = new TL_message_old6();
break;
case 0x44f9b43d:
result = new TL_message_layer104();
break;
case 0x1c9b1027:
result = new TL_message_layer104_2();
break;
case 0xa367e716:
result = new TL_messageForwarded_old2(); //custom
break;
case 0x5f46804:
result = new TL_messageForwarded_old(); //custom
break;
case 0x567699b3:
result = new TL_message_old2(); //custom
break;
case 0x9f8d60bb:
result = new TL_messageService_old(); //custom
break;
case 0x22eb6aba:
result = new TL_message_old(); //custom
break;
case 0x555555F8:
result = new TL_message_secret_old(); //custom
break;
case 0x9789dac4:
result = new TL_message_layer104_3();
break;tai
boolean fixCaption = !TextUtils.isEmpty(message) &&
(media instanceof TLRPC.TL_messageMediaPhoto_old ||
media instanceof TLRPC.TL_messageMediaPhoto_layer68 ||
media instanceof TLRPC.TL_messageMediaPhoto_layer74 ||
media instanceof TLRPC.TL_messageMediaDocument_old ||
media instanceof TLRPC.TL_messageMediaDocument_layer68 ||
media instanceof TLRPC.TL_messageMediaDocument_layer74)
&& message.startsWith("-1");Hmm... näyttää villiltä. Mutta luultavasti tämä on generoitu koodi, niin okei?... Mutta se varmasti tukee kaikkia versioita! Totta, ei ole selvää, miksi kaikki sekoitetaan yhteen, salaiset keskustelut ja kaikenlaiset _old7 jotenkin eivät näytä konesukupolvilta... Eniten kuitenkin hämmästyin
TL_message_layer104
TL_message_layer104_2
TL_message_layer104_3Kaverit, ettekö osaa edes päättää, mitä yhden kerroksen sisällä on?! No, okei, sanotaan, että "kaksi" vapautettiin virheellä, no, se tapahtuu, mutta KOLME?.. Heti sama rake uudestaan? Mitä pornografiaa tämä on, anteeksi?
Muuten, Telegram Desktopin lähdekoodissa tapahtuu vastaavaa - jos näin on, useat peräkkäiset sitoumukset skeemaan eivät muuta sen kerrosnumeroa, vaan korjaavat jotain. Jos järjestelmälle ei ole virallista tietolähdettä, mistä ne voidaan saada, paitsi virallisen asiakkaan lähdekoodi? Ja jos otat sen sieltä, et voi olla varma, että kaavio on täysin oikea, ennen kuin testaat kaikki menetelmät.
Miten tätä voi edes testata? Toivon, että yksikkö-, toiminnallisten ja muiden testien fanit jakavat kommenteissa.
Okei, katsotaanpa toista koodinpätkää:
public static class TL_folders_deleteFolder extends TLObject {
public static int constructor = 0x1c295881;
public int folder_id;
public TLObject deserializeResponse(AbstractSerializedData stream, int constructor, boolean exception) {
return Updates.TLdeserialize(stream, constructor, exception);
}
public void serializeToStream(AbstractSerializedData stream) {
stream.writeInt32(constructor);
stream.writeInt32(folder_id);
}
}
//manually created
//RichText start
public static abstract class RichText extends TLObject {
public String url;
public long webpage_id;
public String email;
public ArrayList<RichText> texts = new ArrayList<>();
public RichText parentRichText;
public static RichText TLdeserialize(AbstractSerializedData stream, int constructor, boolean exception) {
RichText result = null;
switch (constructor) {
case 0x1ccb966a:
result = new TL_textPhone();
break;
case 0xc7fb5e01:
result = new TL_textSuperscript();
break;Tämä "manuaalisesti luotu" kommentti viittaa siihen, että vain osa tästä tiedostosta on kirjoitettu manuaalisesti (voitko kuvitella koko ylläpidon painajaisen?), ja loput oli koneella luotu. Sitten herää kuitenkin toinen kysymys - että lähteet ovat saatavilla ei täysin (GPL-blobien tapaan ytimessä Linux), mutta tämä onkin jo toisen osan aihe.
Mutta tarpeeksi. Siirrytään protokollaan, jonka päällä kaikki tämä sarjoittaminen tapahtuu.
MT Proto
Joten, avataan и ja ensimmäinen asia, johon kompastamme, on terminologia. Ja kaiken runsaudella. Yleisesti ottaen tämä näyttää olevan Telegramin oma ominaisuus - kutsua asioita eri tavalla eri paikoissa tai eri asioita yhdellä sanalla tai päinvastoin (esimerkiksi korkean tason API:ssa, jos näet tarrapaketin, se ei ole mitä ajattelit).
Esimerkiksi "viesti" ja "istunto" tarkoittavat tässä jotain erilaista kuin tavallisessa Telegram-asiakasliittymässä. No, viestissä kaikki on selvää, se voidaan tulkita OOP-termeillä tai kutsua yksinkertaisesti sanaksi "paketti" - tämä on matala, kuljetustaso, ei ole samoja viestejä kuin käyttöliittymässä, palveluviestejä on monia . Mutta istunto... mutta ensin asiat ensin.
Kuljetuskerros
Ensimmäinen asia on kuljetus. He kertovat meille viidestä vaihtoehdosta:
- TCP
- Websocket
- Websocket HTTPS:n kautta
- HTTP
- HTTPS
Vasily, [15.06.18 15:04]
On myös UDP-siirtoa, mutta sitä ei ole dokumentoitu.Ja TCP kolmessa versiossa
Ensimmäinen on samanlainen kuin UDP over TCP, jokainen paketti sisältää järjestysnumeron ja crc
Miksi asiakirjojen lukeminen kärryssä on niin tuskallista?
No siinä se nyt on :
- Lyhennetty
- väli-
- Pehmustettu väliosa
- Koko
No, ok, pehmustettu välimuoto MTProxylle, tämä lisättiin myöhemmin tunnettujen tapahtumien vuoksi. Mutta miksi kaksi versiota lisää (yhteensä kolme), kun pärjäisit yhdellä? Kaikki neljä eroavat olennaisesti vain siinä, kuinka pää-MTProton pituus ja hyötykuorma asetetaan, josta keskustellaan edelleen:
- Lyhennetyssä se on 1 tai 4 tavua, mutta ei 0xef, sitten runko
- Intermediateissa tämä on 4 tavua pitkä ja kenttä, ja ensimmäinen kerta, kun asiakkaan on lähetettävä
0xeeeeeeeeosoittamaan, että se on Keskitaso - Täysin riippuvuutta aiheuttavin verkkokäyttäjän näkökulmasta: pituus, järjestysnumero ja EI SE, joka on pääasiassa MTProto, body, CRC32. Kyllä, kaikki tämä on TCP:n päällä. Joka tarjoaa meille luotettavan kuljetuksen peräkkäisen tavuvirran muodossa; sekvenssejä ei tarvita, etenkään tarkistussummia. Okei, nyt joku vastustaa minua, että TCP:llä on 16-bittinen tarkistussumma, joten tietojen vioittuminen tapahtuu. Hienoa, mutta meillä on itse asiassa salausprotokolla, jonka tiivisteet ovat yli 16 tavua, kaikki nämä virheet - ja vielä enemmän - jää kiinni korkeamman tason SHA-virheestä. CRC32:ssa ei ole mitään järkeä tämän lisäksi.
Verrataanpa Abridgedia, jossa yhden tavun pituus on mahdollista, Intermediateen, joka oikeuttaa "Jos 4-tavuinen datakohdistus tarvitaan", mikä on aivan hölynpölyä. Mitä, uskotaan, että Telegram-ohjelmoijat ovat niin epäpäteviä, etteivät he pysty lukemaan tietoja socketista kohdistettuun puskuriin? Sinun on silti tehtävä tämä, koska lukeminen voi palauttaa sinulle kuinka monta tavua tahansa (ja on myös proxy-palvelimia, esim....). Tai toisaalta, miksi estää Abridged, jos meillä on edelleen 16 tavun päälle kova täyte - säästä 3 tavua joskus ?
Saa vaikutelman, että Nikolai Durov todella haluaa keksiä pyörät uudelleen, mukaan lukien verkkoprotokollat, ilman todellista käytännön tarvetta.
Muut kuljetusvaihtoehdot, mm. Web ja MTProxy, emme harkitse nyt, ehkä toisessa viestissä, jos on pyyntö. Muistakaamme nyt tästä samasta MTProxysta, että pian sen julkaisun jälkeen vuonna 2018 palveluntarjoajat oppivat nopeasti estämään sen, mikä oli tarkoitettu ohituksen estoMukaan paketin koko! Ja myös se, että MTProxy-palvelin, jonka (jälleen Waltman on kirjoittanut) C-kielellä, oli liiaksi sidottu Linuxin ominaisuuksiin, vaikka sitä ei vaadittu ollenkaan (Phil Kulin vahvistaa), ja että samanlainen palvelin joko Go- tai Node.js:ssä mahtuu alle sata riviä.
Mutta teemme johtopäätökset näiden ihmisten teknisestä lukutaidosta osion lopussa, kun olemme pohtineet muita asioita. Toistaiseksi siirrytään OSI-kerrokseen 5, istuntoon - johon he asettivat MTProto-istunnon.
Avaimet, viestit, istunnot, Diffie-Hellman
He asettivat sen sinne väärin... Istunto ei ole sama istunto, joka näkyy käyttöliittymässä Aktiiviset istunnot -kohdassa. Mutta järjestyksessä.
Joten saimme kuljetuskerrokselta tunnetun pituisen tavujonon. Tämä on joko salattu viesti tai pelkkä teksti - jos olemme vielä avainsopimusvaiheessa ja todella teemme sitä. Mistä "avaimeksi" kutsutuista käsitteistä puhumme? Selvitetään tämä asia Telegram-tiimille itselleen (pahoittelen, että käänsin omaa dokumentaatiotani englannista väsynein aivoin kello 4 aamulla, oli helpompi jättää jotkut lauseet sellaisiksi kuin ne ovat):
On olemassa kaksi entiteettiä nimeltä Istunto - yksi virallisten asiakkaiden käyttöliittymässä kohdassa "nykyiset istunnot", jossa jokainen istunto vastaa kokonaista laitetta / käyttöjärjestelmää.
Toinen on MTProto-istunto, jossa on viestin järjestysnumero (matalan tason merkityksessä) ja mikä voi kestää eri TCP-yhteyksien välillä. Useita MTProto-istuntoja voidaan asentaa samanaikaisesti esimerkiksi tiedostojen lataamisen nopeuttamiseksi.Näiden kahden välillä istuntoja on käsite lupa. Degeneroituneessa tapauksessa voimme sanoa niin Käyttöliittymän istunto on sama kuin lupa, mutta valitettavasti kaikki on monimutkaista. Katsotaan:
- Uuden laitteen käyttäjä luo ensin auth_key ja sitoo sen tiliin esimerkiksi tekstiviestillä - siksi lupa
- Se tapahtui ensimmäisen sisällä MTProto-istunto, joka on
session_idsisälläsi.- Tässä vaiheessa yhdistelmä lupa и
session_idvoisi kutsua esimerkki - Tämä sana esiintyy joidenkin asiakkaiden dokumentaatiossa ja koodissa- Sitten asiakas voi avata useat MTProto-istunnot saman alla auth_key - samaan DC:hen.
- Sitten eräänä päivänä asiakkaan on pyydettävä tiedosto osoitteesta toinen DC - ja tälle DC:lle luodaan uusi auth_key !
- Ilmoittaa järjestelmälle, että se ei ole uusi käyttäjä, joka rekisteröityy, vaan sama lupa (Käyttöliittymän istunto), asiakas käyttää API-kutsuja
auth.exportAuthorizationkodin DC:ssäauth.importAuthorizationuudessa DC:ssä.- Kaikki on sama, useita voi olla auki MTProto-istunnot (jokaisella omansa
session_id) tähän uuteen DC:hen, alle hänen auth_key.- Lopuksi asiakas saattaa haluta Perfect Forward Secrecy. Joka auth_key se oli pysyvä avain - per DC - ja asiakas voi soittaa
auth.bindTempAuthKeykäytettäväksi tilapäinen auth_key - ja taas vain yksi temp_auth_key per DC, yhteinen kaikille MTProto-istunnot tähän DC:hen.Huomaa, että suolaa (ja tulevat suolat) on myös yksi auth_key nuo. jaettu kaikkien kesken MTProto-istunnot samaan DC:hen.
Mitä "eri TCP-yhteyksien välillä" tarkoittaa? Tämä tarkoittaa siis vähän niin kuin valtuutuseväste verkkosivustolla - se säilyttää (hengissä) useita TCP-yhteyksiä tiettyyn palvelimeen, mutta jonain päivänä se menee huonosti. Ainoastaan toisin kuin HTTP:ssä, MTProtossa istunnon sisällä olevat viestit numeroidaan ja vahvistetaan peräkkäin; jos ne menivät tunneliin, yhteys katkesi - uuden yhteyden muodostamisen jälkeen palvelin lähettää ystävällisesti tässä istunnossa kaiken, mitä se ei toimittanut edellisessä TCP-yhteys.
Yllä olevat tiedot on kuitenkin tiivistetty useiden kuukausien tutkimuksen jälkeen. Toteutammeko sillä välin asiakkaamme tyhjästä? - Palataan alkuun.
Joten generoidaan auth_key päälle . Yritetään ymmärtää asiakirjoja...
Vasily, [19.06.18 20:05]
data_with_hash := SHA1(data) + data + (mikä tahansa satunnainen tavu); siten, että pituus on 255 tavua;
salatut_tiedot := RSA(data_ja_tiiviste, palvelin_julkinen_avain); 255 tavua pitkä luku (big endian) nostetaan vaadittuun tehoon vaaditun moduulin yli, ja tulos tallennetaan 256-tavuisena numerona.Heillä on töykeä DH
Ei näytä terveen ihmisen DH:lta
Dx:ssä ei ole kahta julkista avainta
No, loppujen lopuksi tämä selvisi, mutta jäännös jäi - asiakas on tehnyt todisteen työstä, että hän osasi laskea numeron. Suojaustyyppi DoS-hyökkäyksiä vastaan. Ja RSA-avainta käytetään vain kerran yhteen suuntaan, lähinnä salaukseen new_nonce. Mutta vaikka tämä näennäisesti yksinkertainen toimenpide onnistuu, mitä sinun on kohdattava?
Vasily, [20.06.18 00:26]
En ole vielä päässyt sovellustunnuspyyntöön asti.Lähetin tämän pyynnön DH:lle
Ja kuljetustelakalla sanotaan, että se voi vastata 4 tavun virhekoodilla. Siinä kaikki
No, hän sanoi minulle -404, mitä sitten?
Joten sanoin hänelle: "Ota kiinni palvelimen avaimella salattu paska, jolla on tällainen sormenjälki, haluan DH:n", ja se vastasi typerällä 404
Mitä mieltä olisit tästä palvelimen vastauksesta? Mitä tehdä? Ei ole keneltäkään kysyä (mutta siitä lisää toisessa osassa).
Täällä kaikki kiinnostus tehdään laiturilla
Minulla ei ole muuta tekemistä, haaveilin vain lukujen muuntamisesta edestakaisin
Kaksi 32-bittistä numeroa. Pakkasin ne kuten kaikki muutkin
Mutta ei, nämä kaksi on lisättävä riville ensin nimellä BE
Vadim Gontšarov, [20.06.18 15:49]
ja tämän 404-virheen takia?Vasily, [20.06.18 15:49]
KYLLÄ!Vadim Gontšarov, [20.06.18 15:50]
En ymmärrä, miksi hän ei "löytänyt" sitä.Vasily, [20.06.18 15:50]
noinEn löytänyt tällaista hajoamista alkutekijöihin %)
Emme edes hoitaneet virheraportointia
Vasily, [20.06.18 20:18]
Ai niin, ja on myös MD5. Siinä on kolme eri tiivistettä.Avaimen sormenjälki lasketaan seuraavasti:
digest = md5(key + iv) fingerprint = substr(digest, 0, 4) XOR substr(digest, 4, 4)SHA1 ja sha2
Joten laitetaan se auth_key saimme 2048 bittiä Diffie-Hellmanin avulla. Mitä seuraavaksi? Seuraavaksi huomaamme, että tämän avaimen alempia 1024 bittiä ei käytetä millään tavalla... mutta mietitäänpä tätä nyt. Tässä vaiheessa meillä on palvelimen kanssa yhteinen salaisuus. TLS-istunnon analogi on perustettu, mikä on erittäin kallis menettely. Mutta palvelin ei vieläkään tiedä keitä me olemme! Ei oikeastaan vielä. valtuutus. Nuo. jos ajattelit "sisäänkirjautumissalasanaa", kuten teit kerran ICQ:ssa, tai ainakin "kirjautumisavain", kuten SSH:ssa (esimerkiksi jossain gitlabissa/githubissa). Saimme nimettömän. Entä jos palvelin kertoo meille "näitä puhelinnumeroita palvelee toinen DC"? Tai jopa "puhelinnumerosi on kielletty"? Parasta, mitä voimme tehdä, on säilyttää avain siinä toivossa, että siitä on hyötyä eikä se mene mätäneeksi siihen mennessä.
Muuten, "vastaanotimme" sen varauksella. Luotammeko esimerkiksi palvelimeen? Entä jos se on väärennös? Kryptografisia tarkistuksia tarvitaan:
Vasily, [21.06.18 17:53]
Ne tarjoavat mobiiliasiakkaille mahdollisuuden tarkistaa 2 kbit/s-luvun alkuperäisyyden.Mutta se ei ole ollenkaan selvää, nafeijoa
Vasily, [21.06.18 18:02]
Lääkäri ei kerro, mitä tehdä, jos se ei olekaan niin yksinkertaista.
Ei sanottu. Katsotaanpa mitä virallinen Android-asiakas tekee tässä tapauksessa? A (ja kyllä, koko tiedosto on mielenkiintoinen) - kuten sanotaan, jätän tämän tähän:
278 static const char *goodPrime = "c71caeb9c6b1c9048e6c522f70f13f73980d40238e3e21c14934d037563d930f48198a0aa7c14058229493d22530f4dbfa336f6e0ac925139543aed44cce7c3720fd51f69458705ac68cd4fe6b6b13abdc9746512969328454f18faf8c595f642477fe96bb2a941d5bcd1d4ac8cc49880708fa9b378e3c4f3a9060bee67cf9a4a4a695811051907e162753b56b0f6b410dba74d8a84b2a14b3144e0ef1284754fd17ed950d5965b4b9dd46582db1178d169c6bc465b0d6ff9ca3928fef5b9ae4e418fc15e83ebea0f87fa9ff5eed70050ded2849f47bf959d956850ce929851f0d8115f635b105ee2e4e15d04b2454bf6f4fadf034b10403119cd8e3b92fcc5b";
279 if (!strcasecmp(prime, goodPrime)) {Ei, tietysti se on edelleen siellä jonkin verran On olemassa testejä luvun primaalisuudesta, mutta henkilökohtaisesti minulla ei ole enää riittävää tietämystä matematiikasta.
Okei, meillä on pääavain. Kirjautuaksesi sisään, ts. lähettää pyyntöjä, sinun on suoritettava lisäsalaus AES:n avulla.
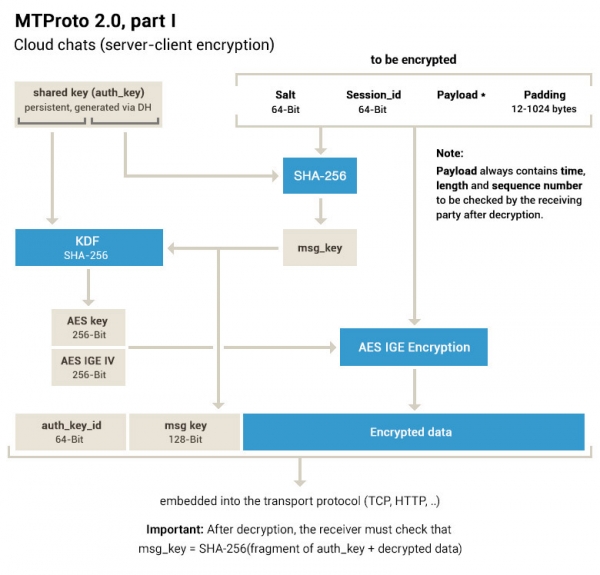
Viestiavain määritellään sanoman rungon SHA128:n 256 keskibitiksi (mukaan lukien istunto, viestitunnus jne.), mukaan lukien täytetavut, joita edeltää 32 valtuutusavaimesta otettua tavua.
Vasily, [22.06.18 14:08]
Keskiverto, narttu, bittiäSain sen
auth_key. Kaikki. Niiden lisäksi... se ei käy selväksi asiakirjasta. Voit vapaasti opiskella avoimen lähdekoodin.Huomaa, että MTProto 2.0 vaatii 12-1024 tavua täyttöä, kuitenkin sillä ehdolla, että tuloksena olevan viestin pituus on jaollinen 16 tavulla.
Kuinka paljon pehmustetta pitäisi lisätä?
Ja kyllä, siellä on myös 404 virheen sattuessa
Jos joku tutki huolellisesti dokumentaation kaaviota ja tekstiä, hän huomasi, että siellä ei ole MAC:ia. Ja että AES:tä käytetään tietyssä IGE-tilassa, jota ei käytetä missään muualla. Tästä he tietysti kirjoittavat usein kysytyissä kysymyksissään... Täällä esimerkiksi itse sanoma-avain on myös puretun tiedon SHA-hajautus, jota käytetään eheyden tarkistamiseen - ja jos ei täsmää, dokumentaatio jostain syystä suosittelee jättämään ne hiljaa huomiotta (mutta entä turvallisuus, entä jos he rikkovat meidät?).
En ole kryptografi, ehkä tässä tilassa ei ole tässä tapauksessa mitään vikaa teoreettisesta näkökulmasta. Mutta voin selvästi nimetä käytännön ongelman käyttämällä esimerkkinä Telegram Desktopia. Se salaa paikallisen välimuistin (kaikki nämä D877F783D5D3EF8C) samalla tavalla kuin viestit MTProtossa (vain tässä tapauksessa versio 1.0), ts. ensin viestiavain, sitten itse tiedot (ja jonnekin pääsuuren sivuun auth_key 256 tavua, ilman sitä msg_key hyödytön). Joten ongelma tulee havaittavaksi suurissa tiedostoissa. Nimittäin sinun on säilytettävä tiedoista kaksi kopiota - salattu ja salattu. Ja jos on megatavuja, tai esimerkiksi suoratoistovideota?.. Klassiset mallit, joissa MAC on salakirjoituksen jälkeen, mahdollistaa sen lukemisen suoratoistona, välittömässä lähetyksessä. Mutta MTProton kanssa sinun täytyy aluksi salaa tai purkaa koko viesti ja siirrä se vasta sitten verkkoon tai levylle. Siksi Telegram Desktopin uusimmissa versioissa välimuistissa user_data Käytetään myös toista muotoa - AES:n kanssa CTR-tilassa.
Vasily, [21.06.18 01:27]
Ai niin, sain selville, mikä IGE on: IGE oli ensimmäinen yritys "todentavaan salaustilaan", alun perin Kerberosta varten. Se epäonnistui (se ei tarjoa eheyssuojaa), ja se piti poistaa. Tästä alkoi 20 vuotta kestänyt pyrkimys löytää toimiva todentava salaustila, joka huipentui hiljattain OCB:n ja GCM:n kaltaisiin tiloihin.Ja nyt argumentit kärryjen puolelta:
Telegramin takana oleva tiimi, jota johtaa Nikolai Durov, koostuu kuudesta ACM-mestarista, joista puolet on matematiikan tohtoreita. Heiltä kesti noin kaksi vuotta ottaa käyttöön nykyinen MTProton versio.
Tuo on hauskaa. Kaksi vuotta alemmalla tasolla
Tai voit ottaa vain tls:n
Okei, oletetaan, että olemme tehneet salauksen ja muut vivahteet. Onko vihdoin mahdollista lähettää TL:ssä sarjoitetut pyynnöt ja deserialisoida vastaukset? Mitä ja miten sitten pitäisi lähettää? Tässä, sanotaanpa menetelmä , ehkä tämä on se?
Vasily, [25.06.18 18:46]
Alustaa yhteyden ja tallentaa tiedot käyttäjän laitteelle ja sovellukseen.Se hyväksyy arvot app_id, device_model, system_version, app_version ja lang_code.
Ja vähän kyselyä
Dokumentaatio kuten aina. Voit vapaasti tutkia avointa lähdekoodia
Jos kaikki oli suunnilleen selvää invokeWithLayerin kanssa, niin mikä tässä on vialla? Sanotaan, että meillä on - asiakkaalla oli jo jotain kysyttävää palvelimelta - on pyyntö, jonka halusimme lähettää:
Vasily, [25.06.18 19:13]
Koodin perusteella ensimmäinen kutsu on kääritty tähän roskaan, ja itse roska on kääritty invokewithlayer-koodiin
Miksei initConnection voisi olla erillinen puhelu, vaan sen täytyy olla kääre? Kyllä, kuten kävi ilmi, se on tehtävä joka kerta jokaisen istunnon alussa, eikä kerran, kuten pääavaimella. Mutta! Luvaton käyttäjä ei voi kutsua sitä! Nyt olemme saavuttaneet vaiheen, jossa sitä voidaan soveltaa dokumentaatiosivulla - ja se kertoo meille, että...
Vain pieni osa API-menetelmistä on luvattomien käyttäjien saatavilla:
- auth.sendCode
- auth.resendCode
- account.getPassword
- auth.checkPassword
- auth.checkPhone
- auth.signUp
- auth.signIn
- auth.importAuthorization
- help.getConfig
- help.getNearestDc
- help.getAppUpdate
- help.getCdnConfig
- langpack.getLangPack
- langpack.getStrings
- langpack.getDifference
- langpack.getLanguages
- langpack.getLanguage
Aivan ensimmäinen niistä, auth.sendCode, ja siellä on se rakastettu ensimmäinen pyyntö, jossa lähetämme api_id ja api_hash, ja jonka jälkeen saamme tekstiviestin koodilla. Ja jos olemme väärässä DC:ssä (esim. tämän maan puhelinnumeroita palvelee toinen), saamme virheilmoituksen halutun DC:n numerolla. Auta meitä saadaksesi selville, mihin IP-osoitteeseen DC-numeron perusteella sinun on muodostettava yhteys help.getConfig. Kerran oli vain 5 ilmoittautumista, mutta vuoden 2018 kuuluisien tapahtumien jälkeen määrä on kasvanut merkittävästi.
Muistetaan nyt, että pääsimme tähän vaiheeseen palvelimella nimettömänä. Eikö vain IP-osoitteen hankkiminen ole liian kallista? Mikset tekisi tätä ja muita toimintoja MTProton salaamattomassa osassa? Kuulen vastalauseen: "Kuinka voimme varmistaa, että RKN ei vastaa väärillä osoitteilla?" Tähän muistamme, että yleensä viralliset asiakkaat RSA-avaimet on upotettu, eli voitko vain merkki Tämä informaatio. Itse asiassa tämä on jo tehty tiedoksi eston ohittamisesta, jonka asiakkaat saavat muiden kanavien kautta (loogisesti tätä ei voi tehdä itse MTProtossa; sinun on myös tiedettävä, mihin muodostaa yhteys).
OK. Tässä asiakkaan valtuutuksen vaiheessa emme ole vielä valtuutettuja emmekä ole rekisteröineet hakemustamme. Haluamme nyt vain nähdä, mitä palvelin reagoi luvattomien käyttäjien käytettävissä oleviin menetelmiin. Ja täällä…
Vasily, [10.07.18 14:45]
config#7dae33e0 [...] = Config; help.getConfig#c4f9186b = Config;config#232d5905 [...] = Config; help.getConfig#c4f9186b = Config;Ohjelmassa ensimmäinen tulee toiseksi
Tdesktop-skeemassa kolmas arvo on
Kyllä, sen jälkeen dokumentaatiota on tietysti päivitetty. Vaikka siitä voi pian tulla taas merkityksetön. Mistä aloittelevan kehittäjän pitäisi tietää? Ehkä jos rekisteröit hakemuksesi, he ilmoittavat sinulle? Vasily teki tämän, mutta valitettavasti he eivät lähettäneet hänelle mitään (puhumme tästä taas toisessa osassa).
...Huomasit, että olemme jo jotenkin siirtyneet API:hen, ts. seuraavalle tasolle ja jäikö jotain MTProto-aiheesta paitsi? Ei yllätys:
Vasily, [28.06.18 02:04]
Mm, he jakavat joitakin algoritmeja e2e:ssäMtproto määrittelee salausalgoritmit ja avaimet molemmille alueille sekä vähän käärerakennetta
Mutta ne sekoittavat jatkuvasti pinon eri tasoja, joten ei aina ole selvää, missä mtproto päättyi ja seuraava taso alkoi
Miten ne sekoittuvat? No, tässä on sama väliaikainen avain esimerkiksi PFS:lle (muuten, Telegram Desktop ei voi tehdä sitä). Se suoritetaan API-pyynnöllä auth.bindTempAuthKey, eli ylimmältä tasolta. Mutta samalla se häiritsee salausta alemmalla tasolla - sen jälkeen sinun on esimerkiksi tehtävä se uudelleen initConnection jne., tämä ei ole vain normaali pyyntö. Erikoista on myös se, että sinulla voi olla vain YKSI väliaikainen avain per DC, vaikka kenttä auth_key_id jokaisessa viestissä sallii avaimen vaihtamisen ainakin jokaisessa viestissä ja että palvelimella on oikeus "unohtaa" väliaikainen avain milloin tahansa - dokumentaatio ei kerro mitä tässä tapauksessa pitäisi tehdä... no miksi voisi Eikö sinulla ole useita avaimia, kuten tulevien suolojen sarjassa, ja?...
MTProto-teemassa on muutamia muita huomionarvoisia asioita.
Viestiviestit, msg_id, msg_seqno, vahvistukset, pingit väärään suuntaan ja muut omituisuudet
Miksi sinun pitää tietää niistä? Koska ne "vuotavat" korkeammalle tasolle, ja sinun on oltava tietoinen niistä, kun työskentelet API:n kanssa. Oletetaan, että msg_key ei kiinnosta meitä; alempi taso on purkanut kaiken puolestamme. Mutta salauksen purettujen tietojen sisällä meillä on seuraavat kentät (myös tietojen pituus, joten tiedämme missä täyte on, mutta se ei ole tärkeää):
- suola - int64
- istunnon_tunnus - int64
- viestin_id - int64
- sek_no - int32
Muistutetaan, että koko tasavirtaa kohti on vain yksi suola. Miksi tietää hänestä? Ei vain siksi, että on pyyntö get_future_salts, joka kertoo, mitkä välit ovat voimassa, mutta myös siksi, että jos suolasi on "mätä", viesti (pyyntö) yksinkertaisesti katoaa. Palvelin tietysti ilmoittaa uuden suolan myöntämällä new_session_created - mutta vanhan kanssa sinun on lähetettävä se esimerkiksi jotenkin uudelleen. Ja tämä ongelma vaikuttaa sovellusarkkitehtuuriin.
Palvelin saa lopettaa istunnot kokonaan ja vastata tällä tavalla monista syistä. Mikä itse asiassa on MTProto-istunto asiakkaan puolelta? Nämä ovat kaksi numeroa session_id и seq_no viestejä tämän istunnon aikana. No, ja taustalla oleva TCP-yhteys tietysti. Oletetaan, että asiakkaamme ei vieläkään osaa tehdä monia asioita, hän katkaisi yhteyden ja palasi. Jos tämä tapahtui nopeasti - vanha istunto jatkui uudessa TCP-yhteydessä, lisää seq_no edelleen. Jos se kestää kauan, palvelin voi poistaa sen, koska sen puolella se on myös jono, kuten huomasimme.
Mitä sen pitäisi olla seq_no? Oho, se on hankala kysymys. Yritä rehellisesti ymmärtää, mitä tarkoitettiin:
Sisältöä koskeva viesti
Viesti, joka vaatii nimenomaisen kuittauksen. Nämä sisältävät kaikki käyttäjä- ja monet palveluviestit, käytännössä kaikki lukuun ottamatta säiliöitä ja kuittauksia.
Viestin järjestysnumero (msg_seqno)
32-bittinen luku, joka vastaa kaksi kertaa lähettäjän ennen tätä viestiä luomien "sisältöön liittyvien" viestien (kuittausta vaativien viestien, erityisesti niiden, jotka eivät ole säilöjä) lukumäärää, jota lisätään myöhemmin yhdellä, jos nykyinen viesti on sisältöön liittyvä viesti. Säiliö luodaan aina sen koko sisällön jälkeen; siksi sen järjestysnumero on suurempi tai yhtä suuri kuin sen sisältämien viestien järjestysnumerot.
Millainen sirkus tämä on, kun lisäys 1:llä ja sitten toinen kahdella?.. Epäilen, että alun perin tarkoitettiin "vähiten merkitsevää bittiä ACK:lle, loput on numeroita", mutta tulos ei ole aivan sama - erityisesti se tulee ulos, voidaan lähettää useat vahvistukset, joilla on sama seq_no! Miten? No, esimerkiksi palvelin lähettää meille jotain, lähettää sen, ja me itse olemme hiljaa, vastaamme vain palveluviesteillä, jotka vahvistavat sen viestien vastaanottamisen. Tässä tapauksessa lähtevillä vahvistuksillamme on sama lähtevän numeron. Jos olet perehtynyt TCP:hen ja ajattelit, että tämä kuulostaa jotenkin villiltä, mutta se ei vaikuta kovin villiltä, koska TCP:ssä seq_no ei muutu, mutta vahvistus menee seq_no toisella puolella, kiirehdin järkyttää sinua. Vahvistukset annetaan MTProtossa EI päälle seq_no, kuten TCP:ssä, mutta by msg_id !
Mikä tämä on msg_id, tärkein näistä aloista? Yksilöllinen viestin tunniste, kuten nimestä voi päätellä. Se määritellään 64-bittiseksi luvuksi, jonka alimmilla biteillä on jälleen "palvelin-ei-palvelin"-taika, ja loput on Unix-aikaleima, murto-osa mukaan lukien, siirretty 32 bittiä vasemmalle. Nuo. aikaleima sinänsä (ja viestit, joiden ajat eroavat liian paljon, hylkäävät palvelimen). Tästä käy ilmi, että yleensä tämä on asiakkaalle globaali tunniste. Ottaen huomioon, että - muistakaamme session_id - meillä on takuu: Yhdelle istunnolle tarkoitettua viestiä ei saa missään tapauksessa lähettää toiseen istuntoon. Eli käy ilmi, että on jo kolme taso - istunto, istunnon numero, viestin tunnus. Miksi tällainen monimutkaisuus, tämä mysteeri on erittäin suuri.
Niin, msg_id tarvitaan...
RPC: pyynnöt, vastaukset, virheet. Vahvistukset.
Kuten olet ehkä huomannut, kaaviossa ei ole erityistä "tee RPC-pyyntö" -tyyppiä tai -toimintoa, vaikka vastauksia onkin. Meillähän on sisältöön liittyviä viestejä! Tuo on, kaikki viesti voi olla pyyntö! Tai olla olematta. Kuitenkin, kukin on msg_id. Mutta vastauksia on:
rpc_result#f35c6d01 req_msg_id:long result:Object = RpcResult;Tässä näkyy, mihin viestiin tämä on vastaus. Siksi API:n ylimmällä tasolla sinun on muistettava, mikä pyyntösi numero oli - mielestäni ei tarvitse selittää, että työ on asynkronista, ja käynnissä voi olla useita pyyntöjä samanaikaisesti, joiden vastaukset voidaan palauttaa missä tahansa järjestyksessä? Periaatteessa tästä ja virheilmoituksista kuten ei työntekijöitä, tämän takana oleva arkkitehtuuri voidaan jäljittää: kanssasi TCP-yhteyttä ylläpitävä palvelin on etupään tasapainottaja, se välittää pyynnöt taustajärjestelmille ja kerää ne takaisin message_id. Näyttää siltä, että kaikki täällä on selkeää, loogista ja hyvää.
Kyllä?.. Ja jos ajattelet sitä? Loppujen lopuksi itse RPC-vasteella on myös kenttä msg_id! Pitääkö meidän huutaa palvelimelle "et vastaa vastaukseni!"? Ja kyllä, mitä vahvistuksissa oli? Tietoja sivusta kertoo meille mikä on
msgs_ack#62d6b459 msg_ids:Vector long = MsgsAck;ja se on tehtävä molemmin puolin. Mutta ei aina! Jos sait RpcResultin, se itsessään toimii vahvistuksena. Toisin sanoen palvelin voi vastata pyyntöösi MsgsAckilla - kuten "Sain sen". RpcResult voi vastata välittömästi. Se voi olla molempia.
Ja kyllä, sinun on vielä vastattava kysymykseen! Vahvistus. Muussa tapauksessa palvelin pitää sitä toimittamattomana ja lähettää sen sinulle uudelleen. Myös yhteydenoton jälkeen. Mutta tässä tietysti herää kysymys aikakatkaisuista. Katsotaanpa niitä hieman myöhemmin.
Sillä välin tarkastellaan mahdollisia kyselyn suoritusvirheitä.
rpc_error#2144ca19 error_code:int error_message:string = RpcError;Voi, joku huudahtaa, tässä on inhimillisempi muoto - siinä on viiva! Ei kiirettä. Tässä , mutta ei tietenkään täydellinen. Siitä opimme, että koodi on vähän niin kuin HTTP-virheet (no, tietenkään vastausten semantiikkaa ei kunnioiteta, paikoin ne jakautuvat satunnaisesti koodien kesken), ja rivi näyttää tältä CAPITAL_LETTERS_AND_NUMBERS. Esimerkiksi PHONE_NUMBER_OCCUPIED tai FILE_PART_Х_MISSING. Eli tarvitset silti tätä riviä jäsentää. Esimerkiksi FLOOD_WAIT_3600 tarkoittaa, että sinun on odotettava tunti ja PHONE_MIGRATE_5, että tällä etuliitteellä varustettu puhelinnumero on rekisteröitävä 5. DC:hen. Meillä on tyyppikieli, eikö niin? Emme tarvitse argumenttia merkkijonosta, tavalliset argumentit kelpaavat, okei.
Tämä ei taaskaan ole palveluviestisivulla, mutta kuten tässä projektissa on jo tavallista, tiedot löytyvät toisella dokumentaatiosivulla. tai herättää epäilystä. Ensinnäkin, katso, kirjoitus/tasorikkomus - RpcError voidaan upottaa sisään RpcResult. Miksei ulkona? Mitä emme ottaneet huomioon?... Missä on siis takuu siitä RpcError EI saa upottaa RpcResult, mutta olla suoraan tai sisäkkäinen toiseen tyyppiin?.. Ja jos se ei voi, miksi se ei ole ylimmällä tasolla, ts. se puuttuu req_msg_id ? ..
Mutta jatketaanpa palveluviesteistä. Asiakas saattaa ajatella, että palvelin ajattelee pitkään ja esittää tämän upean pyynnön:
rpc_drop_answer#58e4a740 req_msg_id:long = RpcDropAnswer;Tähän kysymykseen on kolme mahdollista vastausta, jotka risteävät jälleen vahvistusmekanismin kanssa; yrittäminen ymmärtää, mitä niiden pitäisi olla (ja mikä yleinen luettelo tyypeistä, jotka eivät vaadi vahvistusta) jätetään lukijalle kotitehtäväksi (huom: tiedot Telegram Desktopin lähdekoodi ei ole täydellinen).
Huumeriippuvuus: viestien tilat
Yleisesti ottaen monet paikat TL:ssä, MTProtossa ja Telegramissa yleensä jättävät itsepäisyyden tunteen, mutta kohteliaisuudesta, tahdikkuudesta ja muista pehmeitä taitoja Olimme kohteliaasti hiljaa siitä ja sensuroimme vuoropuhelujen siveettömyyttä. Tämä paikka kuitenkinОsuurin osa sivusta kertoo Se on järkyttävää jopa minulle, joka olen pitkään työskennellyt verkkoprotokollien parissa ja olen nähnyt eri asteisia polkupyöriä.
Se alkaa harmittomasti, vahvistuksilla. Seuraavaksi he kertovat meille
bad_msg_notification#a7eff811 bad_msg_id:long bad_msg_seqno:int error_code:int = BadMsgNotification;
bad_server_salt#edab447b bad_msg_id:long bad_msg_seqno:int error_code:int new_server_salt:long = BadMsgNotification;No, jokaisen, joka aloittaa työskentelyn MTProton kanssa, täytyy käsitellä niitä, "korjattu - uudelleen käännetty - käynnistetty" -syklissä numerovirheiden tai muokkausten aikana huonontuneen suolan saaminen on yleistä. Tässä on kuitenkin kaksi kohtaa:
- Tämä tarkoittaa, että alkuperäinen viesti on kadonnut. Meidän on luotava joitain jonoja, katsomme sitä myöhemmin.
- Mitä nämä oudot virhenumerot ovat? 16, 17, 18, 19, 20, 32, 33, 34, 35, 48, 64... missä ovat muut numerot, Tommy?
Dokumentaatiossa sanotaan:
Tarkoituksena on, että error_code-arvot ryhmitellään (error_code >> 4): esimerkiksi koodit 0x40 — 0x4f vastaavat virheitä kontin hajotuksessa.
mutta ensinnäkin muutos toiseen suuntaan, ja toiseksi, sillä ei ole väliä, missä ovat muut koodit? Kirjoittajan päässä?.. Nämä ovat kuitenkin pikkujuttuja.
Riippuvuus alkaa viestien tilasta ja viestikopioista:
- Viestin tilatietojen pyyntö
Jos jompikumpi osapuoli ei ole saanut tietoa lähtevien viestiensä tilasta vähään aikaan, se voi nimenomaisesti pyytää sitä toiselta osapuolelta:
msgs_state_req#da69fb52 msg_ids:Vector long = MsgsStateReq; - Viestien tilaa koskeva tiedotusviesti
msgs_state_info#04deb57d req_msg_id:long info:string = MsgsStateInfo;
Täälläinfoon merkkijono, joka sisältää täsmälleen yhden tavun viestin tilaa kullekin saapuvan msg_ids-luettelon viestille:- 1 = viestistä ei tiedetä mitään (msg_id liian pieni, toinen osapuoli on saattanut unohtaa sen)
- 2 = viestiä ei vastaanotettu (msg_id kuuluu tallennettujen tunnisteiden alueelle; toinen osapuoli ei kuitenkaan ole varmasti saanut tällaista viestiä)
- 3 = viestiä ei vastaanotettu (msg_id liian korkea; toinen osapuoli ei kuitenkaan ole vielä saanut sitä)
- 4 = viesti vastaanotettu (huomaa, että tämä vastaus on samalla kuittaus kuittauksesta)
- +8 = viesti on jo kuitattu
- +16 = viesti ei vaadi kuittausta
- +32 = RPC-kysely sisältyy sanomaan, jota käsitellään tai käsittely on jo valmis
- +64 = sisältöön liittyvä vastaus jo luotuun viestiin
- +128 = toinen osapuoli tietää varmasti, että viesti on jo vastaanotettu
Tämä vastaus ei vaadi kuittausta. Se on kuittaus asiaankuuluvalle msgs_state_req:lle sinänsä.
Huomaa, että jos toisella osapuolella yhtäkkiä käy ilmi, ettei sille lähetetyltä näyttävää viestiä ole, viesti voidaan yksinkertaisesti lähettää uudelleen. Vaikka toinen osapuoli saisi kaksi kopiota viestistä samanaikaisesti, kaksoiskappale ohitetaan. (Jos liian paljon aikaa on kulunut ja alkuperäinen msg_id ei ole enää voimassa, viesti on käärittävä muotoon msg_copy).
- Vapaaehtoinen viestien tila
Kumpikin osapuoli voi vapaaehtoisesti ilmoittaa toiselle osapuolelle toisen osapuolen välittämien viestien tilasta.
msgs_all_info#8cc0d131 msg_ids:Vector long info:string = MsgsAllInfo - Laajennettu vapaaehtoinen tiedonanto yhden viestin tilasta
...
msg_detailed_info#276d3ec6 msg_id:long answer_msg_id:long bytes:int status:int = MsgDetailedInfo;
msg_new_detailed_info#809db6df answer_msg_id:long bytes:int status:int = MsgDetailedInfo; - Nimenomainen pyyntö lähettää viestejä uudelleen
msg_resend_req#7d861a08 msg_ids:Vector long = MsgResendReq;
Etäosapuoli vastaa välittömästi lähettämällä pyydetyt viestit uudelleen […] - Nimenomainen pyyntö lähettää vastauksia uudelleen
msg_resend_ans_req#8610baeb msg_ids:Vector long = MsgResendReq;
Etäosapuoli vastaa välittömästi lähettämällä uudelleen vastauksia pyydettyihin viesteihin […] - Viestien kopiot
Joissakin tilanteissa vanha viesti, jonka msg_id ei ole enää voimassa, on lähetettävä uudelleen. Sitten se kääritään kopiosäiliöön:
msg_copy#e06046b2 orig_message:Message = MessageCopy;
Kun viesti on vastaanotettu, se käsitellään ikään kuin käärettä ei olisi olemassa. Jos kuitenkin tiedetään varmasti, että viesti orig_message.msg_id vastaanotettiin, uutta viestiä ei käsitellä (samalla kun se ja orig_message.msg_id kuitataan). Orig_message.msg_id-arvon on oltava pienempi kuin säilön msg_id.
Ollaanpa vaikka hiljaa mistä msgs_state_info jälleen keskeneräisen TL:n korvat työntyvät ulos (tarvitsimme tavuvektorin, ja kahdessa alemmassa bitissä oli enum, ja kahdessa ylempänä oli liput). Pointti on eri. Ymmärtääkö kukaan miksi tämä kaikki on käytännössä? todellisessa asiakkaassa tarpeen?.. Vaikeasti, mutta voidaan kuvitella jonkinlaista hyötyä, jos henkilö on mukana virheenkorjauksessa ja interaktiivisessa tilassa - kysy palvelimelta mitä ja miten. Mutta tässä kuvataan pyynnöt meno-paluu matka.
Tästä seuraa, että jokaisen osapuolen tulee paitsi salata ja lähettää viestejä, myös tallentaa tietoja itsestään, niihin vastauksista tuntemattoman ajan. Dokumentaatio ei kuvaa näiden ominaisuuksien ajoitusta tai käytännön soveltuvuutta. ei mitenkään. Mikä hämmästyttävintä on, että niitä todella käytetään virallisten asiakkaiden koodissa! Ilmeisesti heille kerrottiin jotain, mitä ei ollut julkisessa dokumentaatiossa. Ymmärrä koodista miksi, ei ole enää niin yksinkertainen kuin TL:n tapauksessa - se ei ole (suhteellisesti) loogisesti eristetty osa, vaan sovellusarkkitehtuuriin sidottu pala, ts. vaatii huomattavasti enemmän aikaa sovelluskoodin ymmärtämiseen.
Pingit ja ajoitukset. Jonot.
Kaikesta, jos muistamme arvaukset palvelinarkkitehtuurista (pyyntöjen jakautuminen taustajärjestelmien välillä), seuraa melko surullinen asia - huolimatta kaikista TCP:n toimitustakuista (joko tiedot toimitetaan tai sinulle ilmoitetaan aukosta, mutta tiedot toimitetaan ennen ongelman ilmenemistä), että vahvistukset itse MTProtossa - ei takuita. Palvelin voi helposti kadottaa tai heittää viestisi pois, eikä sille voi tehdä mitään, vain käyttää erilaisia kainalosauvoja.
Ja ennen kaikkea - viestijonot. No, yhdellä asialla kaikki oli selvää alusta alkaen - vahvistamaton viesti on tallennettava ja lähetettävä uudelleen. Ja minkä ajan kuluttua? Ja narri tuntee hänet. Ehkä nuo riippuvaiset palveluviestit jotenkin ratkaisevat tämän ongelman kainalosauvoilla, sanotaan, että Telegram Desktopissa on noin 4 jonoa, jotka vastaavat niitä (ehkä enemmän, kuten jo mainittiin, tätä varten sinun täytyy syventyä sen koodiin ja arkkitehtuuriin vakavammin; samalla Aika, me Tiedämme, että sitä ei voi ottaa näytteeksi; tiettyä määrää MTProto-kaavion tyyppejä ei käytetä siinä).
Miksi tämä tapahtuu? Todennäköisesti palvelinohjelmoijat eivät kyenneet varmistamaan luotettavuutta klusterin sisällä tai edes puskurointia etutasapainottimessa, ja siirsivät tämän ongelman asiakkaalle. Epätoivosta Vasily yritti toteuttaa vaihtoehtoisen vaihtoehdon, vain kahdella jonolla, käyttämällä TCP:n algoritmeja - mittaamalla RTT:n palvelimelle ja säätämällä "ikkunan" kokoa (viesteissä) vahvistamattomien pyyntöjen lukumäärän mukaan. Toisin sanoen tällainen karkea heuristinen palvelimen kuormituksen arvioiminen on se, kuinka monta pyyntöämme se voi pureskella samanaikaisesti eikä hävitä.
No, ymmärrätkö, eikö niin? Jos joudut toteuttamaan TCP:n uudelleen TCP:tä käyttävän protokollan päälle, tämä tarkoittaa erittäin huonosti suunniteltua protokollaa.
Ai niin, miksi tarvitset useamman kuin yhden jonon, ja mitä tämä tarkoittaa korkean tason API:n kanssa työskentelevälle henkilölle? Katso, teet pyynnön, sarjoit sen, mutta usein et voi lähettää sitä heti. Miksi? Koska vastaus tulee olemaan msg_id, joka on väliaikainenаOlen etiketti, jonka antaminen on parasta lykätä mahdollisimman myöhään - jos palvelin hylkää sen meidän ja hänen välillämme olevan aikaeron vuoksi (tottakai voimme tehdä kainalosauvan, joka siirtää aikamme nykyisestä palvelimelle lisäämällä palvelimen vastauksista laskettu delta - viralliset asiakkaat tekevät niin, mutta se on karkeaa ja epätarkka puskuroinnin vuoksi). Siksi, kun teet pyynnön paikallisella funktiokutsulla kirjastosta, viesti käy läpi seuraavat vaiheet:
- Se on yhdessä jonossa ja odottaa salausta.
- Nimitetty
msg_idja viesti meni toiseen jonoon - mahdollinen edelleenlähetys; lähetä pistorasiaan. - a) Palvelin vastasi MsgsAck - viesti toimitettiin, poistamme sen "toisesta jonosta".
b) Tai päinvastoin, hän ei pitänyt jostain, hän vastasi viestiin - lähetä uudelleen "toisesta jonosta"
c) Mitään ei tiedetä, viesti on lähetettävä uudelleen toisesta jonosta - mutta ei tiedetä tarkalleen milloin. - Palvelin lopulta vastasi
RpcResult- todellinen vastaus (tai virhe) - ei vain toimitettu, vaan myös käsitelty.
Ehkä, säiliöiden käyttö voisi osittain ratkaista ongelman. Tällöin joukko viestejä pakataan yhteen ja palvelin vastasi vahvistuksella kaikkiin kerralla, yhdessä msg_id. Mutta hän myös hylkää tämän paketin kokonaan, jos jokin meni pieleen.
Ja tässä vaiheessa ei-tekniset näkökohdat tulevat peliin. Kokemuksen mukaan olemme nähneet monia kainalosauvoja, ja lisäksi näemme nyt lisää esimerkkejä huonoista neuvoista ja arkkitehtuurista - kannattaako tällaisissa olosuhteissa luottaa ja tehdä tällaisia päätöksiä? Kysymys on retorinen (ei tietenkään).
Mistä puhutaan? Jos aiheesta "huumeviestit viesteistä" voit silti spekuloida vastalauseilla, kuten "olet tyhmä, et ymmärtänyt loistavaa suunnitelmaamme!" (kirjoita siis ensin dokumentaatio, kuten tavallisten ihmisten pitää, perustelut ja esimerkit pakettien vaihdosta, sitten puhutaan), sitten ajoitukset/aikakatkaisut ovat puhtaasti käytännöllinen ja konkreettinen kysymys, kaikki täällä on ollut tiedossa pitkään. Mitä dokumentaatio kertoo meille aikakatkaisuista?
Palvelin yleensä kuittaa vastaanottaneen viestin asiakkaalta (yleensä RPC-kyselyn) käyttämällä RPC-vastausta. Jos vastausta odotetaan pitkään, palvelin voi ensin lähettää kuittauksen kuittauksesta ja jonkin verran myöhemmin itse RPC-vastauksen.
Asiakas tavallisesti kuittaa palvelimelta saapuvan viestin (yleensä RPC-vastauksen) lisäämällä kuittauksen seuraavaan RPC-kyselyyn, jos sitä ei lähetetä liian myöhään (jos se luodaan esimerkiksi 60-120 sekuntia vastaanottamisesta palvelimelta tulevasta viestistä). Jos kuitenkin pitkään aikaan ei ole syytä lähettää viestejä palvelimelle tai jos palvelimelta tulee paljon kuittaamattomia viestejä (esim. yli 16), asiakas lähettää erillisen kuittauksen.
... Käännän: emme itse tiedä kuinka paljon ja miten sitä tarvitsemme, joten oletetaan, että olkoon näin.
Ja pingistä:
Ping-viestit (PING/PONG)
ping#7abe77ec ping_id:long = Pong;Vastaus palautetaan yleensä samaan yhteyteen:
pong#347773c5 msg_id:long ping_id:long = Pong;Nämä viestit eivät vaadi kuittauksia. Pong lähetetään vain vastauksena pingiin, kun taas pingin voi aloittaa jompikumpi osapuoli.
Viivästetty yhteyden sulkeminen + PING
ping_delay_disconnect#f3427b8c ping_id:long disconnect_delay:int = Pong;Toimii kuin ping. Lisäksi tämän vastaanottamisen jälkeen palvelin käynnistää ajastimen, joka sulkee nykyisen yhteyden disconnect_delay sekuntia myöhemmin, ellei se vastaanota uutta samantyyppistä viestiä, joka nollaa automaattisesti kaikki aikaisemmat ajastimet. Jos asiakas lähettää nämä ping-kutsut esimerkiksi kerran 60 sekunnissa, se voi asettaa disconnect_delay-arvoksi 75 sekuntia.
Oletko hullu?! 60 sekunnissa juna saapuu asemalle, laskee pois ja noutaa matkustajia ja menettää jälleen yhteyden tunnelissa. 120 sekunnin kuluttua, kun kuulet sen, se saapuu toiseen, ja yhteys todennäköisesti katkeaa. No, on selvää, mistä jalat tulevat - "Kuulin soittoa, mutta en tiedä missä se on", on Naglin algoritmi ja TCP_NODELAY-vaihtoehto, joka on tarkoitettu interaktiiviseen työhön. Mutta anteeksi, pidä kiinni oletusarvostaan - 200 millisekuntia Jos todella haluat kuvata jotain vastaavaa ja säästää parissa mahdollisessa paketissa, lykkää 5 sekuntia tai mitä tahansa "Käyttäjä kirjoittaa..." -viestin aikakatkaisu on nyt. Mutta ei enempää.
Ja lopuksi pingit. Eli TCP-yhteyden elävyyden tarkistaminen. Hassua, mutta noin 10 vuotta sitten kirjoitin kriittisen tekstin tiedekuntamme asuntolan sanansaattajasta - siellä kirjoittajat pingoivat myös palvelimen asiakkaalta, eivätkä päinvastoin. Mutta 3. vuoden opiskelijat ovat yksi asia ja kansainvälinen toimisto toinen, eikö niin?
Ensinnäkin pieni koulutusohjelma. TCP-yhteys voi toimia viikkoja ilman pakettivaihtoa. Tämä on sekä hyvä että huono, riippuen tarkoituksesta. On hyvä, jos sinulla oli SSH-yhteys auki palvelimelle, nousit tietokoneelta, käynnistit reitittimen uudelleen, palasit takaisin paikoilleen - istunto tämän palvelimen kautta ei katkennut (et kirjoittanut mitään, paketteja ei ollut) , se on kätevää. On huonoa, jos palvelimella on tuhansia asiakkaita, joista jokainen vie resursseja (hei, Postgres!), ja asiakkaan isäntä on saattanut käynnistyä uudelleen kauan sitten - mutta emme tiedä siitä.
Chat-/pikaviestintäjärjestelmät kuuluvat toiseen kategoriaan toisesta lisäsyystä: online-tilasta. Jos käyttäjä "keskeyttää yhteyden", hänen keskustelukumppaneilleen on ilmoitettava siitä. Muuten päädytään samaan virheeseen, jonka Jabberin luojat tekivät (ja jonka korjaamiseen käytettiin 20 vuotta): käyttäjä katkaisee yhteyden, mutta viestien lähettäminen hänelle jatkuu, koska hän uskoo hänen olevan online-tilassa (viestit katosivat kokonaan muutamaa minuuttia ennen yhteyden katkaisun havaitsemista). Ei, TCP_KEEPALIVE-asetus, jota monet TCP-ajastinten toimintaa ymmärtämättömät ihmiset käyttävät (asettamalla villejä arvoja, kuten kymmeniä sekunteja), ei auta tässä. Sinun on varmistettava, että käyttäjän käyttöjärjestelmän ydin on toiminnassa, että se toimii oikein, pystyy vastaamaan ja että itse sovellus (luuletko, ettei se voi kaatua? Telegram Desktop päällä Ubuntu 18.04 jäätyi minulla useita kertoja).
Siksi sinun täytyy pingata palvelin asiakas, eikä päinvastoin - jos asiakas tekee tämän, jos yhteys katkeaa, pingiä ei toimiteta, tavoitetta ei saavuteta.
Mitä näemme Telegramissa? Asia on juuri päinvastoin! No niin. Muodollisesti tietysti molemmat osapuolet voivat pingata toisiaan. Käytännössä asiakkaat käyttävät kainalosauvaa ping_delay_disconnect, joka asettaa ajastimen palvelimelle. Anteeksi, asiakas ei voi päättää, kuinka kauan hän haluaa asua siellä ilman pingiä. Palvelin tietää paremmin kuormituksensa perusteella. Mutta tietysti, jos et välitä resursseista, olet oma paha Pinocchio, ja kainalosauva käy...
Miten se olisi pitänyt suunnitella?
Uskon, että yllä olevat tosiasiat osoittavat selvästi, että Telegram/VKontakte-tiimi ei ole kovin pätevä tietoverkkojen liikenteen (ja alemman) tason alalla ja heidän alhainen pätevyytensä asiaan liittyvissä asioissa.
Miksi se osoittautui niin monimutkaiseksi, ja kuinka Telegramin arkkitehdit voivat yrittää vastustaa? Se, että he yrittivät tehdä istunnon, joka selviää TCP-yhteyskatkoksista, eli mitä ei toimitettu nyt, toimitamme myöhemmin. Luultavasti he yrittivät myös tehdä UDP-siirtoa, mutta he kohtasivat vaikeuksia ja hylkäsivät sen (siksi dokumentaatio on tyhjä - ei ollut mitään kehumista). Mutta koska ei ole ymmärrystä siitä, miten verkot yleensä ja TCP erityisesti toimivat, missä voit luottaa siihen ja missä sinun täytyy tehdä se itse (ja miten), ja yritys yhdistää tämä kryptografiaan "kaksi kärpästä yksi kivi”, tämä on tulos.
Miten se oli tarpeen? Perustuu siihen tosiasiaan msg_id on salauksen kannalta välttämätön aikaleima uusintahyökkäysten estämiseksi, on virhe liittää siihen yksilöllinen tunnistetoiminto. Siksi muuttamatta perusteellisesti nykyistä arkkitehtuuria (kun päivitykset-stream luodaan, se on korkean tason API-aihe tämän viestisarjan toiselle osalle), sinun on:
- Asiakkaaseen TCP-yhteyden pitävä palvelin ottaa vastuun - jos se on lukenut socketista, kuittaa, käsittele tai palauta virhe, ei tappioita. Tällöin vahvistus ei ole ids-vektori, vaan yksinkertaisesti "viimeksi vastaanotettu seq_no" - vain numero, kuten TCP:ssä (kaksi numeroa - sinun sekvenssisi ja vahvistettu). Olemme aina istunnon sisällä, eikö niin?
- Toistohyökkäysten estämiseen käytettävä aikaleima tulee erilliseksi kenttään, a la nonce. Se on tarkistettu, mutta se ei vaikuta muuhun. Tarpeeksi ja
uint32- jos suolamme vaihtuu vähintään puolen päivän välein, voimme allokoida 16 bittiä nykyisen ajan kokonaisluvun matalan kertaluvun biteille, loput - sekunnin murto-osalle (kuten nyt). - Poistettu
msg_idollenkaan - taustaohjelmien pyyntöjen erottamisen kannalta on olemassa ensinnäkin asiakastunnus ja toiseksi istuntotunnus, ketjuttaa ne. Näin ollen vain yksi asia riittää pyyntötunnisteenaseq_no.
Tämä ei myöskään ole menestynein vaihtoehto, täydellinen satunnainen voisi toimia tunnisteena - tämä tehdään muuten jo korkean tason API:ssa viestiä lähetettäessä. Olisi parempi tehdä arkkitehtuuri kokonaan uudelleen suhteellisesta absoluuttiseksi, mutta tämä on toisen osan aihe, ei tämän postauksen.
API?
Ta-daam! Joten kamppailtuamme läpi polun, joka on täynnä kipua ja kainalosauvoja, pystyimme vihdoin lähettämään pyynnöt palvelimelle ja vastaanottamaan niihin vastauksia sekä vastaanottamaan päivityksiä palvelimelta (ei vastauksena pyyntöön, vaan se itse lähettää meille, kuten PUSH, jos joku on selvempää).
Huomio, nyt artikkelissa on ainoa esimerkki Perlissä! (niille, jotka eivät tunne syntaksia, blessin ensimmäinen argumentti on objektin tietorakenne, toinen on sen luokka):
2019.10.24 12:00:51 $1 = {
'cb' => 'TeleUpd::__ANON__',
'out' => bless( {
'filter' => bless( {}, 'Telegram::ChannelMessagesFilterEmpty' ),
'channel' => bless( {
'access_hash' => '-6698103710539760874',
'channel_id' => '1380524958'
}, 'Telegram::InputPeerChannel' ),
'pts' => '158503',
'flags' => 0,
'limit' => 0
}, 'Telegram::Updates::GetChannelDifference' ),
'req_id' => '6751291954012037292'
};
2019.10.24 12:00:51 $1 = {
'in' => bless( {
'req_msg_id' => '6751291954012037292',
'result' => bless( {
'pts' => 158508,
'flags' => 3,
'final' => 1,
'new_messages' => [],
'users' => [],
'chats' => [
bless( {
'title' => 'Хулиномика',
'username' => 'hoolinomics',
'flags' => 8288,
'id' => 1380524958,
'access_hash' => '-6698103710539760874',
'broadcast' => 1,
'version' => 0,
'photo' => bless( {
'photo_small' => bless( {
'volume_id' => 246933270,
'file_reference' => '
'secret' => '1854156056801727328',
'local_id' => 228648,
'dc_id' => 2
}, 'Telegram::FileLocation' ),
'photo_big' => bless( {
'dc_id' => 2,
'local_id' => 228650,
'file_reference' => '
'secret' => '1275570353387113110',
'volume_id' => 246933270
}, 'Telegram::FileLocation' )
}, 'Telegram::ChatPhoto' ),
'date' => 1531221081
}, 'Telegram::Channel' )
],
'timeout' => 300,
'other_updates' => [
bless( {
'pts_count' => 0,
'message' => bless( {
'post' => 1,
'id' => 852,
'flags' => 50368,
'views' => 8013,
'entities' => [
bless( {
'length' => 20,
'offset' => 0
}, 'Telegram::MessageEntityBold' ),
bless( {
'length' => 18,
'offset' => 480,
'url' => 'https://alexeymarkov.livejournal.com/[url_вырезан].html'
}, 'Telegram::MessageEntityTextUrl' )
],
'reply_markup' => bless( {
'rows' => [
bless( {
'buttons' => [
bless( {
'text' => '???? 165',
'data' => 'send_reaction_0'
}, 'Telegram::KeyboardButtonCallback' ),
bless( {
'data' => 'send_reaction_1',
'text' => '???? 9'
}, 'Telegram::KeyboardButtonCallback' )
]
}, 'Telegram::KeyboardButtonRow' )
]
}, 'Telegram::ReplyInlineMarkup' ),
'message' => 'А вот и новая книга!
// [текст сообщения вырезан чтоб не нарушать правил Хабра о рекламе]
напечатаю.',
'to_id' => bless( {
'channel_id' => 1380524958
}, 'Telegram::PeerChannel' ),
'date' => 1571724559,
'edit_date' => 1571907562
}, 'Telegram::Message' ),
'pts' => 158508
}, 'Telegram::UpdateEditChannelMessage' ),
bless( {
'pts' => 158508,
'message' => bless( {
'edit_date' => 1571907589,
'to_id' => bless( {
'channel_id' => 1380524958
}, 'Telegram::PeerChannel' ),
'date' => 1571807301,
'message' => 'Почему Вы считаете Facebook плохой компанией? Можете прокомментировать? По-моему, это шикарная компания. Без долгов, с хорошей прибылью, а если решат дивы платить, то и еще могут нехило подорожать.
Для меня ответ совершенно очевиден: потому что Facebook делает ужасный по качеству продукт. Да, у него монопольное положение и да, им пользуется огромное количество людей. Но мир не стоит на месте. Когда-то владельцам Нокии было смешно от первого Айфона. Они думали, что лучше Нокии ничего быть не может и она навсегда останется самым удобным, красивым и твёрдым телефоном - и доля рынка это красноречиво демонстрировала. Теперь им не смешно.
Конечно, рептилоиды сопротивляются напору молодых гениев: так Цукербергом был пожран Whatsapp, потом Instagram. Но всё им не пожрать, Паша Дуров не продаётся!
Так будет и с Фейсбуком. Нельзя всё время делать говно. Кто-то когда-то сделает хороший продукт, куда всё и уйдут.
#соцсети #facebook #акции #рептилоиды',
'reply_markup' => bless( {
'rows' => [
bless( {
'buttons' => [
bless( {
'data' => 'send_reaction_0',
'text' => '???? 452'
}, 'Telegram::KeyboardButtonCallback' ),
bless( {
'text' => '???? 21',
'data' => 'send_reaction_1'
}, 'Telegram::KeyboardButtonCallback' )
]
}, 'Telegram::KeyboardButtonRow' )
]
}, 'Telegram::ReplyInlineMarkup' ),
'entities' => [
bless( {
'length' => 199,
'offset' => 0
}, 'Telegram::MessageEntityBold' ),
bless( {
'length' => 8,
'offset' => 919
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'offset' => 928,
'length' => 9
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'length' => 6,
'offset' => 938
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'length' => 11,
'offset' => 945
}, 'Telegram::MessageEntityHashtag' )
],
'views' => 6964,
'flags' => 50368,
'id' => 854,
'post' => 1
}, 'Telegram::Message' ),
'pts_count' => 0
}, 'Telegram::UpdateEditChannelMessage' ),
bless( {
'message' => bless( {
'reply_markup' => bless( {
'rows' => [
bless( {
'buttons' => [
bless( {
'data' => 'send_reaction_0',
'text' => '???? 213'
}, 'Telegram::KeyboardButtonCallback' ),
bless( {
'data' => 'send_reaction_1',
'text' => '???? 8'
}, 'Telegram::KeyboardButtonCallback' )
]
}, 'Telegram::KeyboardButtonRow' )
]
}, 'Telegram::ReplyInlineMarkup' ),
'views' => 2940,
'entities' => [
bless( {
'length' => 609,
'offset' => 348
}, 'Telegram::MessageEntityItalic' )
],
'flags' => 50368,
'post' => 1,
'id' => 857,
'edit_date' => 1571907636,
'date' => 1571902479,
'to_id' => bless( {
'channel_id' => 1380524958
}, 'Telegram::PeerChannel' ),
'message' => 'Пост про 1С вызвал бурную полемику. Человек 10 (видимо, 1с-программистов) единодушно написали:
// [текст сообщения вырезан чтоб не нарушать правил Хабра о рекламе]
Я бы добавил, что блестящая у 1С дистрибуция, а маркетинг... ну, такое.'
}, 'Telegram::Message' ),
'pts_count' => 0,
'pts' => 158508
}, 'Telegram::UpdateEditChannelMessage' ),
bless( {
'pts' => 158508,
'pts_count' => 0,
'message' => bless( {
'message' => 'Здравствуйте, расскажите, пожалуйста, чем вредит экономике 1С?
// [текст сообщения вырезан чтоб не нарушать правил Хабра о рекламе]
#софт #it #экономика',
'edit_date' => 1571907650,
'date' => 1571893707,
'to_id' => bless( {
'channel_id' => 1380524958
}, 'Telegram::PeerChannel' ),
'flags' => 50368,
'post' => 1,
'id' => 856,
'reply_markup' => bless( {
'rows' => [
bless( {
'buttons' => [
bless( {
'data' => 'send_reaction_0',
'text' => '???? 360'
}, 'Telegram::KeyboardButtonCallback' ),
bless( {
'data' => 'send_reaction_1',
'text' => '???? 32'
}, 'Telegram::KeyboardButtonCallback' )
]
}, 'Telegram::KeyboardButtonRow' )
]
}, 'Telegram::ReplyInlineMarkup' ),
'views' => 4416,
'entities' => [
bless( {
'offset' => 0,
'length' => 64
}, 'Telegram::MessageEntityBold' ),
bless( {
'offset' => 1551,
'length' => 5
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'length' => 3,
'offset' => 1557
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'offset' => 1561,
'length' => 10
}, 'Telegram::MessageEntityHashtag' )
]
}, 'Telegram::Message' )
}, 'Telegram::UpdateEditChannelMessage' )
]
}, 'Telegram::Updates::ChannelDifference' )
}, 'MTProto::RpcResult' )
};
2019.10.24 12:00:51 $1 = {
'in' => bless( {
'update' => bless( {
'user_id' => 2507460,
'status' => bless( {
'was_online' => 1571907651
}, 'Telegram::UserStatusOffline' )
}, 'Telegram::UpdateUserStatus' ),
'date' => 1571907650
}, 'Telegram::UpdateShort' )
};
2019.10.24 12:05:46 $1 = {
'in' => bless( {
'chats' => [],
'date' => 1571907946,
'seq' => 0,
'updates' => [
bless( {
'max_id' => 141719,
'channel_id' => 1295963795
}, 'Telegram::UpdateReadChannelInbox' )
],
'users' => []
}, 'Telegram::Updates' )
};
2019.10.24 13:01:23 $1 = {
'in' => bless( {
'server_salt' => '4914425622822907323',
'unique_id' => '5297282355827493819',
'first_msg_id' => '6751307555044380692'
}, 'MTProto::NewSessionCreated' )
};
2019.10.24 13:24:21 $1 = {
'in' => bless( {
'chats' => [
bless( {
'username' => 'freebsd_ru',
'version' => 0,
'flags' => 5440,
'title' => 'freebsd_ru',
'min' => 1,
'photo' => bless( {
'photo_small' => bless( {
'local_id' => 328733,
'volume_id' => 235140688,
'dc_id' => 2,
'file_reference' => '
'secret' => '4426006807282303416'
}, 'Telegram::FileLocation' ),
'photo_big' => bless( {
'dc_id' => 2,
'file_reference' => '
'volume_id' => 235140688,
'local_id' => 328735,
'secret' => '71251192991540083'
}, 'Telegram::FileLocation' )
}, 'Telegram::ChatPhoto' ),
'date' => 1461248502,
'id' => 1038300508,
'democracy' => 1,
'megagroup' => 1
}, 'Telegram::Channel' )
],
'users' => [
bless( {
'last_name' => 'Panov',
'flags' => 1048646,
'min' => 1,
'id' => 82234609,
'status' => bless( {}, 'Telegram::UserStatusRecently' ),
'first_name' => 'Dima'
}, 'Telegram::User' )
],
'seq' => 0,
'date' => 1571912647,
'updates' => [
bless( {
'pts' => 137596,
'message' => bless( {
'flags' => 256,
'message' => 'Создать джейл с именем покороче ??',
'to_id' => bless( {
'channel_id' => 1038300508
}, 'Telegram::PeerChannel' ),
'id' => 119634,
'date' => 1571912647,
'from_id' => 82234609
}, 'Telegram::Message' ),
'pts_count' => 1
}, 'Telegram::UpdateNewChannelMessage' )
]
}, 'Telegram::Updates' )
};Kyllä, ei spoileri tarkoituksella - jos et ole vielä lukenut sitä, tee se!
Oh, wai~~... miltä tämä näyttää? Jotain hyvin tuttua... ehkä tämä on tyypillisen JSON-verkkosovellusliittymän tietorakenne, paitsi että objekteihin liitetään myös luokat?...
Joten näin se käy... Mistä siinä on kyse, toverit?.. Niin paljon vaivaa - ja pysähdyimme lepäämään missä Web-ohjelmoijat vasta alkamassa?..Eikö vain JSON HTTPS:n yli olisi yksinkertaisempaa?! Mitä saimme vaihdossa? Oliko vaivannäkö sen arvoista?
Arvioidaan, mitä TL+MTProto antoi meille ja mitkä vaihtoehdot ovat mahdollisia. No, HTTP, joka keskittyy pyyntö-vastausmalliin, sopii huonosti, mutta ainakin jotain TLS:n päälle?
Kompakti serialisointi. Nähdessään tämän JSON:n kaltaisen tietorakenteen muistan, että siitä on olemassa binääriversioita. Merkitään MsgPack riittämättömäksi laajennettavaksi, mutta siellä on esim. CBOR - muuten julkaisussa kuvattu standardi. . Se on merkittävä siitä, että se määrittelee tunnisteita, laajennusmekanismina ja muun muassa on:
- 25 + 256 - toistuvien rivien korvaaminen viittauksella rivin numeroon, niin halpa pakkausmenetelmä
- 26 - sarjoitettu Perl-objekti luokan nimen ja rakentajan argumenteilla
- 27 - sarjoitettu kielestä riippumaton objekti tyypin nimellä ja konstruktoriargumenteilla
No, yritin sarjoittaa samat tiedot TL:ssä ja CBOR:ssa merkkijonojen ja objektien pakkausten ollessa käytössä. Tulos alkoi vaihdella CBOR:n hyväksi jostain megatavusta:
cborlen=1039673 tl_len=1095092Niin, johtopäätös: On olemassa huomattavasti yksinkertaisempia formaatteja, joihin ei liity synkronointivirheen tai tuntemattoman tunnisteen ongelma, ja joiden tehokkuus on vertailukelpoinen.
Nopea yhteyden muodostus. Tämä tarkoittaa nollaa RTT:tä uudelleenkytkennän jälkeen (kun avain on jo luotu kerran) - voimassa heti ensimmäisestä MTProto-viestistä, mutta tietyin varauksin - osuu samaan suolaan, istunto ei ole mätä jne. Mitä TLS tarjoaa meille sen sijaan? Lainaus aiheesta:
Käytettäessä PFS:ää TLS:ssä, TLS-istuntoliput () jatkaaksesi salattua istuntoa neuvottelematta avaimia uudelleen ja tallentamatta avaintietoja palvelimelle. Ensimmäistä yhteyttä avattaessa ja avaimia luotaessa palvelin salaa yhteyden tilan ja välittää sen asiakkaalle (istuntolipun muodossa). Vastaavasti kun yhteyttä jatketaan, asiakas lähettää istuntolipun, mukaan lukien istuntoavaimen, takaisin palvelimelle. Itse lippu on salattu väliaikaisella avaimella (istuntolipun avaimella), joka tallennetaan palvelimelle ja joka on jaettava kaikkien SSL:ää klusteroiduissa ratkaisuissa käsittelevien käyttöliittymäpalvelimien kesken.[10] Siten istuntolipun käyttöönotto voi rikkoa PFS:ää, jos väliaikaiset palvelinavaimet vaarantuvat, esimerkiksi kun niitä säilytetään pitkään (OpenSSL, nginx, Apache tallentavat ne oletuksena koko ohjelman ajan; suositut sivustot käyttävät avain useita tunteja, jopa päiviä).
Tässä RTT ei ole nolla, sinun on vaihdettava ainakin ClientHello ja ServerHello, jonka jälkeen asiakas voi lähettää tietoja Finishedin kanssa. Mutta tässä on syytä muistaa, että meillä ei ole verkkoa uusineen yhteyksineen, vaan sanansaattaja, jonka yhteys on usein yksi ja enemmän tai vähemmän pitkäikäinen, suhteellisen lyhyt pyyntö web-sivuille - kaikki on multipleksoitua sisäisesti. Eli on aivan hyväksyttävää, jos emme törmänneet todella huonoon metroosaan.
Unohditko jotain muuta? Kirjoita kommentteihin.
Jatkuu!
Tämän artikkelisarjan toisessa osassa emme käsittele teknisiä, vaan organisatorisia kysymyksiä - lähestymistapoja, ideologiaa, käyttöliittymää, asennetta käyttäjiin jne. Perustuu kuitenkin tässä esitettyihin teknisiin tietoihin.
Kolmannessa osassa jatketaan teknisen komponentin/kehityskokemuksen analysointia. Opit erityisesti:
- pandemonian jatkoa erilaisilla TL-tyypeillä
- tuntemattomia asioita kanavista ja superryhmistä
- miksi dialogit ovat huonompia kuin lista
- absoluuttisesta vs. suhteellisesta viestiosoitteesta
- mitä eroa on valokuvalla ja kuvalla
- kuinka emojit häiritsevät kursivoitua tekstiä
ja muut kainalosauvat! Pysy kanavalla!
Lähde: will.com
