

Esittely
 "Sinun täytyy juosta niin nopeasti kuin pystyt pysyäksesi paikallasi,"
"Sinun täytyy juosta niin nopeasti kuin pystyt pysyäksesi paikallasi,"
ja päästäkseen jonnekin, täytyy juosta ainakin kaksi kertaa nopeammin!
(c) Liisa Ihmemaassa
Jonkin aikaa sitten minua pyydettiin pitämään luento analyytikot Yrityksemme keskittyy datamallien suunnitteluun, koska työskentelemme projekteissa pitkään (joskus useita vuosia) ja unohdamme IT-maailman tapahtumat. Yrityksessämme monet projektit eivät satu käyttämään NoSQL-tietokantoja (ainakaan vielä), joten luennollani keskityin niihin erityisesti käyttäen esimerkkinä HBasea ja yritin räätälöidä esitystä niille, jotka eivät ole koskaan työskennelleet niiden kanssa. Havainnollistin erityisesti datamallien suunnittelun yksityiskohtia useita vuosia sitten lukemallani esimerkillä. Esimerkkejä analysoidessani vertasin useita ratkaisuja samaan ongelmaan välittääkseni pääajatukset paremmin yleisölle.
Hiljattain "tylsyydestä" mietin (erityisesti pitkät toukokuun lomat karanteenin aikana suotuisat tälle kysymykselle): kuinka hyvin teoreettiset käsitteet soveltuisivat käytäntöön? Näin syntyi idea tähän artikkeliin. Kehittäjä, joka on työskennellyt NoSQL:n kanssa jonkin aikaa, ei välttämättä saa siitä mitään uutta (ja saattaa siksi ohittaa puolet artikkelista). Mutta analyytikotNiille, jotka eivät ole vielä työskennelleet laajasti NoSQL:n kanssa, uskon, että siitä on hyötyä HBase-tietomallien suunnittelun yksityiskohtien ymmärtämisessä.
Esimerkkianalyysi
Mielestäni ennen NoSQL-tietokantojen käyttöä on ajateltava huolellisesti ja punnittava hyvät ja huonot puolet. Usein tehtävä voidaan todennäköisesti ratkaista perinteisillä relaatiotietokannan hallintajärjestelmillä. Siksi on parasta välttää NoSQL:n käyttöä ilman pakottavaa syytä. Jos päätät käyttää NoSQL-tietokantaa, muista, että suunnittelumenetelmät ovat jonkin verran erilaisia. Jotkut niistä saattavat olla erityisen vieraita niille, jotka ovat aiemmin työskennelleet vain relaatiotietokannan hallintajärjestelmien kanssa (kokemukseni mukaan). Esimerkiksi relaatiomaailmassa aloitamme yleensä mallintamalla aihealueen ja tarvittaessa denormalisoimme mallin. NoSQL:ssä me kuitenkin on välittömästi otettava huomioon odotettavissa olevat datan kanssa työskentelyn skenaariot ja aluksi denormalisoi data. On myös useita muita eroja, joita käsitellään jäljempänä.
Tarkastellaan seuraavaa "synteettistä" ongelmaa, jonka parissa jatkamme työskentelyä:
Meidän on suunniteltava tallennusrakenne tietyn abstraktin sosiaalisen verkoston käyttäjien ystävälistalle. Yksinkertaisuuden vuoksi oletamme, että kaikki yhteydet ovat suunnattuja (kuten Instagramissa, ei LinkedInissä). Rakenteen tulisi mahdollistaa seuraavien tehokas toteuttaminen:
- Vastaa kysymykseen, lukeeko käyttäjä A käyttäjää B (lukumalli)
- Salli yhteyksien lisääminen/poistaminen, kun käyttäjä A seuraa käyttäjää B/lopettaa sen seuraamisen (tietojen muutosmalli)
Tähän ongelmaan on tietysti monia mahdollisia ratkaisuja. Perinteisessä relaatiotietokannassa luomme todennäköisesti vain relaatiotaulukon (ehkä tyypitetyn, jos esimerkiksi meidän on tallennettava käyttäjäryhmiä – perhe, työ jne. – jotka sisältävät tietyn "ystävän") ja lisäämme indeksejä/osiointia käyttönopeuden optimoimiseksi. Tuloksena oleva taulukko näyttäisi todennäköisesti suurin piirtein tältä:
USER_ID
ystävätunnus
Vasya
Petya
Vasya
Olya
Tästä eteenpäin selkeyden ja paremman ymmärryksen vuoksi käytän nimiä henkilötunnusten sijaan.
HBasen tapauksessa tiedämme, että:
- tehokas haku ilman koko taulukon skannausta on mahdollista yksinomaan avaimen avulla
- Siksi tuttujen SQL-kyselyiden kirjoittaminen tällaisiin tietokantoihin on huono idea; teknisesti ottaen voit tietenkin lähettää SQL-kyselyn liitoksilla ja muulla logiikalla Impalasta HBaseen, mutta kuinka tehokasta se on?
Siksi meidän on pakko käyttää käyttäjätunnusta avaimena. Ensimmäinen ajatus aiheesta "mihin ja miten tallentaa ystävätunnukset?" saattaa olla ajatus niiden tallentamisesta sarakkeisiin. Tämä ilmeisin ja "naiivi" vaihtoehto näyttäisi suurin piirtein tältä (kutsutaan sitä Vaihtoehto 1 (oletus), tulevaa tarvetta varten):
Rivin avain
kaiuttimet
Vasya
1: Petja
2: Olja
3: Daša
Petya
1: Maša
2: Vasja
Tässä jokainen rivi vastaa yhtä verkon käyttäjää. Sarakkeet on nimetty 1, 2, ... – ystävien lukumäärän perusteella – ja niihin tallennetaan ystävien tunnukset. On tärkeää huomata, että jokaisella rivillä on eri määrä sarakkeita. Yllä olevassa esimerkissä yhdellä rivillä on kolme saraketta (1, 2 ja 3), kun taas toisella on vain kaksi (1 ja 2). Tässä olemme hyödyntäneet kahta HBase-ominaisuutta, joita relaatiotietokannoissa ei ole:
- kyky muuttaa sarakkeiden koostumusta dynaamisesti (lisää ystävä -> lisää sarake, poista ystävä -> poista sarake)
- eri riveillä voi olla erilaiset sarakekoostumukset
Tarkistetaan, että rakenne täyttää tehtävän vaatimukset:
- Tietojen lukeminen: ymmärtääksemme, onko Vasya tilannut Olyan, meidän on vähennettävä koko rivi RowKey = "Vasya" ja iteroi sarakearvot läpi, kunnes "tapaamme" Olyan. Tai iteroi kaikkien sarakearvojen läpi, "emme tapaa" Olyaa ja palauta False;
- Tietojen muokkaaminen: ystävän lisääminensamankaltaisessa ongelmassa meidän on myös vähennettävä koko rivi RowKey = "Vasya" laskeaksemme hänen ystäviensä kokonaismäärän. Tarvitsemme tämän ystävien kokonaismäärän määrittääksemme sarakenumeron, johon uuden ystävän tunnus tallennetaan.
- Tietojen muokkaaminen: ystävän poistaminen:
- On tarpeen vähentää koko rivi avaimella RowKey = “Vasya” ja käy läpi sarakkeet löytääksesi sen, johon poistettava ystävä on tallennettu;
- Seuraavaksi, ystävän poistamisen jälkeen, meidän on "siirrettävä" kaikki tiedot yhteen sarakkeeseen, jotta niiden numeroinnissa ei ole "aukkoja".
Arvioidaan nyt, kuinka tuottavia nämä algoritmit, jotka meidän on toteutettava "ehdollisen sovelluksen" puolella, tulevat olemaan. Merkitään hypoteettisen sosiaalisen verkostomme kokoa n:llä. Tällöin yhden käyttäjän ystävien enimmäismäärä on (n-1). Voimme jättää tämän (-1) huomiotta tässä yhteydessä, koska sillä ei ole merkitystä O-symbolien käytön yhteydessä.
- Tietojen lukeminen: on tarpeen vähentää koko rivi ja raja-arvossa iteroida kaikkien sen sarakkeiden läpi. Tämä tarkoittaa, että ylempi kustannusarvio on noin O(n)
- Tietojen muokkaaminen: ystävän lisääminen: ystävien lukumäärän määrittämiseksi sinun on iteroitava rivin kaikki sarakkeet ja lisättävä sitten uusi sarake => O(n)
- Tietojen muokkaaminen: ystävän poistaminen:
- Samoin kuin yhteenlasku, tämäkin vaatii iteroinnin kaikkien raja-arvon sarakkeiden läpi => O(n)
- Sarakkeiden poistamisen jälkeen meidän on "siirrettävä" ne. Yksinkertainen lähestymistapa vaatisi jopa (n-1) operaatiota lisää. Tässä ja koko käytännön osiossa käytämme kuitenkin erilaista lähestymistapaa, joka toteuttaa "näennäissiirron" kiinteässä määrässä operaatioita – eli se vie vakioajan riippumatta n:stä. Tämä vakioaika (tarkalleen ottaen O(2)) on merkityksetön verrattuna O(n):ään. Lähestymistapaa havainnollistetaan alla olevassa kuvassa: kopioimme tiedot "viimeisestä" sarakkeesta siihen, josta tiedot on poistettava, ja poistamme sitten viimeisen sarakkeen:

Kaiken kaikkiaan kaikissa skenaarioissa saatiin asymptoottinen laskennallinen kompleksisuus O(n).
Olet luultavasti jo huomannut, että meidän on lähes aina luettava koko rivi tietokannasta, ja kahdessa kolmesta tapauksessa vain käydäksemme läpi kaikki sarakkeet ja laskeaksemme ystävien kokonaismäärän. Siksi optimointiyrityksenä voimme lisätä "count"-sarakkeen, johon tallennetaan kunkin verkon käyttäjän ystävien kokonaismäärä. Tässä tapauksessa meidän ei tarvitse lukea koko riviä ystävien kokonaismäärän laskemiseksi, vaan vain "count"-sarake. Tärkeintä on muistaa päivittää "count"-sarake tietoja käsiteltäessä. Tällä tavoin saamme parannetun Vaihtoehto 2 (määrä):
Rivin avain
kaiuttimet
Vasya
1: Petja
2: Olja
3: Daša
laskea: 3
Petya
1: Maša
2: Vasja
laskea: 2
Verrattuna ensimmäiseen vaihtoehtoon:
- Tietojen lukeminen: saadaksesi vastauksen kysymykseen "Lukeeko Vasja Oljaa?" mikään ei ole muuttunut => O(n)
- Tietojen muokkaaminen: ystävän lisääminenOlemme yksinkertaistaneet uuden ystävän lisäämistä, koska meidän ei enää tarvitse lukea koko riviä ja iteroida sen sarakkeiden läpi. Voimme nyt hakea vain "count"-sarakkeen arvon ja siten välittömästi määrittää sarakenumeron uuden ystävän lisäämistä varten. Tämä vähentää laskennallisen monimutkaisuuden O(1):een.
- Tietojen muokkaaminen: ystävän poistaminenKun poistamme ystävän, voimme käyttää tätä saraketta myös vähentääksemme I/O-operaatioiden määrää siirrettäessä tietoja yhden solun vasemmalle. Meidän on kuitenkin silti iteroitava sarakkeet läpi löytääksemme poistettavan, joten => O(n)
- Toisaalta, nyt tietoja päivitettäessä meidän on päivitettävä "count"-sarake joka kerta, mutta tämä vie vakioaikaa, mikä voidaan jättää huomiotta O-symbolien viitekehyksessä.
Kaiken kaikkiaan vaihtoehto 2 vaikuttaa hieman optimaalisemmalta, mutta se on enemmänkin "evoluution kuin vallankumouksen" kaltainen. "Vallankumouksen" saavuttamiseksi tarvitsemme Vaihtoehto 3 (sarake).
Käännetään kaikki ylösalaisin: nimitetään sarakkeen nimi käyttäjätunnus! Sarakkeen teksti itsessään ei ole meille ratkaisevan tärkeää; käytetäänpä numeroa 1 (yleensä sinne voisi tallentaa hyödyllisiä asioita, esimerkiksi ryhmänä "perhe/ystävät/jne."). Tämä lähestymistapa saattaa yllättää aloittelijan "maallikon", jolla ei ole aiempaa kokemusta NoSQL-tietokannoista, mutta se antaa meille mahdollisuuden hyödyntää HBasen potentiaalia paljon tehokkaammin tässä tehtävässä:
Rivin avain
kaiuttimet
Vasya
Petja: 1
Olja: 1
Daša: 1
Petya
Maša: 1
Vasja: 1
Tämä tarjoaa useita etuja. Ymmärtääksemme ne, analysoidaan uutta rakennetta ja arvioidaan sen laskennallinen monimutkaisuus:
- Tietojen lukeminenVastatakseen kysymykseen siitä, onko Vasja tilannut Olya-kanavan, riittää lukea yksi sarake ”Olya”: jos on, niin vastaus on Tosi, jos ei – Epätosi => O(1)
- Tietojen muokkaaminen: ystävän lisääminen: Kaverin lisääminen: lisää vain uusi sarake "Kaveritunnus" => O(1)
- Tietojen muokkaaminen: ystävän poistaminen: poista vain "Ystävätunnus"-sarake => O(1)
Kuten voimme nähdä, tämän tallennusmallin merkittävä etu on se, että kaikissa tarvittavissa tilanteissa käytämme vain yhtä saraketta, jolloin vältymme koko rivin lukemiselta tietokannasta, saati sitten kaikkien kyseisen rivin sarakkeiden läpikäymiseltä. Voisimme lopettaa tähän, mutta…
Voimme olla hieman luovempia ja mennä hieman pidemmälle suorituskyvyn optimoinnissa ja I/O-toimintojen vähentämisessä tietokantaa käytettäessä. Entä jos tallentaisimme koko suhdetiedon suoraan itse riviavaimeen? Eli tekisimme avaimesta yhdistetyn, kuten userID.friendID? Siinä tapauksessa meidän ei tarvitsisi edes lukea rivisarakkeita ollenkaan (Vaihtoehto 4 (rivi)):
Rivin avain
kaiuttimet
Vasja. Petja
Petja: 1
Vasja.Olja
Olja: 1
Vasja.Dasha
Daša: 1
Petja. Maša
Maša: 1
Petja. Vasja
Vasja: 1
Kaikkien datan käsittelyskenaarioiden arviointi tällaisessa rakenteessa on luonnollisesti O(1), aivan kuten edellisessä vaihtoehdossa. Ero vaihtoehtoon 3 on yksinomaan tietokannan I/O-toimintojen tehokkuudessa.
Ja lopuksi viimeinen huomio. On helppo nähdä, että vaihtoehdossa 4 riviavaimemme pituus vaihtelee, mikä voi vaikuttaa suorituskykyyn (muista, että HBase tallentaa tiedot tavujoukkona ja taulukon rivit lajitellaan avaimen mukaan). Lisäksi meillä on erotin, jota on ehkä käsiteltävä joissakin tilanteissa. Tämän vaikutuksen poistamiseksi voimme käyttää käyttäjätunnuksen ja ystävätunnuksen tiivisteitä. Koska molemmilla tiivisteillä on vakio pituus, voimme yksinkertaisesti ketjuttaa ne ilman erotinta. Tällöin taulukon tiedot näyttävät tältä:Vaihtoehto 5 (hajautusarvo)):
Rivin avain
kaiuttimet
dc084ef00e94aef49be885f9b01f51c01918fa783851db0dc1f72f83d33a5994
Petja: 1
dc084ef00e94aef49be885f9b01f51c0f06b7714b5ba522c3cf51328b66fe28a
Olja: 1
dc084ef00e94aef49be885f9b01f51c00d2c2e5d69df6b238754f650d56c896a
Daša: 1
1918fa783851db0dc1f72f83d33a59949ee3309645bd2c0775899fca14f311e1
Maša: 1
1918fa783851db0dc1f72f83d33a5994dc084ef00e94aef49be885f9b01f51c0
Vasja: 1
On selvää, että tällaisen rakenteen kanssa työskentelyn algoritminen monimutkaisuus tarkastelemiemme skenaarioiden mukaan on sama kuin vaihtoehdossa 4 – eli O(1):ssä.
Yhteenvetona kaikista laskennallisen monimutkaisuuden arvioistamme yhdessä taulukossa:
Ystävän lisääminen
Ystävän tarkistaminen
Ystävän poistaminen
Vaihtoehto 1 (oletus)
O (n)
O (n)
O (n)
Vaihtoehto 2 (määrä)
O (1)
O (n)
O (n)
Vaihtoehto 3 (sarake)
O (1)
O (1)
O (1)
Vaihtoehto 4 (rivi)
O (1)
O (1)
O (1)
Vaihtoehto 5 (hajautusarvo)
O (1)
O (1)
O (1)
Kuten näette, vaihtoehdot 3–5 vaikuttavat paremmilta ja teoriassa varmistavat kaikkien tarvittavien datankäsittelyskenaarioiden suorittamisen vakioajassa. Ongelma-asetelmassamme ei nimenomaisesti vaadita kaikkien käyttäjän ystävien luettelon hakemista, mutta tosielämän projekteissa meidän on hyvinä analyytikkoina viisasta ennakoida tällainen ongelma ja ryhtyä varotoimiin. Siksi kannatan vaihtoehtoa 3. On kuitenkin täysin mahdollista, että tosielämän projektissa tämä pyyntö on jo käsitelty muilla tavoilla, joten ilman yleistä ymmärrystä koko ongelmasta on parasta olla tekemättä lopullisia johtopäätöksiä.
Kokeen valmistelu
Haluaisin testata edellä mainittua teoreettista päättelyä käytännössä – se oli pitkän viikonlopun aikana syntyneen idean tavoite. Tätä varten meidän on arvioitava "hypoteettisen sovelluksemme" suorituskykyä kaikissa kuvatuissa tietokannan käyttöskenaarioissa sekä sitä, miten tämä aika kasvaa sosiaalisen verkoston koon (n) myötä. Kohdeparametri, josta olemme kiinnostuneita ja jota mittaamme kokeen aikana, on aika, joka "hypoteettiselta sovellukselta" kuluu yhden "liiketoimintaoperaation" suorittamiseen. "Liiketoimintaoperaatiolla" tarkoitamme jotakin seuraavista:
- Yhden uuden ystävän lisääminen
- Tarkistetaan, onko käyttäjä A käyttäjän B ystävä
- Yhden ystävän poistaminen
Näin ollen, ottaen huomioon alkuperäisessä lausunnossa määritellyt vaatimukset, todentamisskenaario on seuraava:
- Tietojen tallennusLuo satunnaisesti alkuverkko, jonka koko on n. Jotta "todellista maailmaa" voitaisiin kuvastaa paremmin, myös kunkin käyttäjän ystävien määrä on satunnainen. Mittaa aika, joka "valesovelluksellamme" kuluu kaikkien luotujen tietojen kirjoittamiseen HBaseen. Jaa sitten tämä aika lisättyjen ystävien kokonaismäärällä – tämä antaa meille yhden "liiketoimintaoperaation" keskimääräisen ajan.
- Tietojen lukeminenLuo jokaiselle käyttäjälle lista "persoonallisuuksista", joiden perusteella sinun on määritettävä, seuraako käyttäjä heitä vai ei. Listan pituus on suunnilleen yhtä suuri kuin käyttäjän ystävien lukumäärä, ja vastaus on "Kyllä" puolelle tarkistetuista ystävistä ja "Ei" toiselle puolelle. Tarkistukset suoritetaan siten, että "Kyllä"- ja "Ei"-vastaukset vuorottelevat (eli jokaisessa muussa tapauksessa meidän on käytävä läpi kaikki rivin sarakkeet vaihtoehtojen 1 ja 2 osalta). Kokonaistarkistusaika jaetaan sitten tarkistettujen ystävien lukumäärällä, jotta saadaan keskimääräinen tarkistusaika.
- Tietojen poistaminenPoista kaikki käyttäjän kaverit. Poistojärjestys on satunnainen (eli sekoitamme alkuperäisen listan, jota käytettiin tietojen tallentamiseen). Kokonaisvahvistusaika jaetaan sitten poistettujen kavereiden lukumäärällä, jolloin saadaan keskimääräinen vahvistusaika.
Skenaariot on suoritettava jokaiselle viidelle datamallimuunnelmalle ja eri kokoisille sosiaalisille verkostoille, jotta voidaan nähdä, miten aika muuttuu verkoston kasvaessa. Yhden n-mallin sisällä verkkoyhteyksien ja testattavien käyttäjien luettelon on luonnollisesti oltava samat kaikille viidelle muunnelmalle.
Paremman ymmärryksen vuoksi alla on esimerkki generoidusta datasta, kun n = 5. Kirjoittamani "generaattori" tuottaa kolme tunnistesanakirjaa:
- ensimmäinen on tarkoitettu lisättäväksi
- toinen on tarkistusta varten
- kolmas on poistettavaksi
{0: [1], 1: [4, 5, 3, 2, 1], 2: [1, 2], 3: [2, 4, 1, 5, 3], 4: [2, 1]} # всего 15 друзей
{0: [1, 10800], 1: [5, 10800, 2, 10801, 4, 10802], 2: [1, 10800], 3: [3, 10800, 1, 10801, 5, 10802], 4: [2, 10800]} # всего 18 проверяемых субъектов
{0: [1], 1: [1, 3, 2, 5, 4], 2: [1, 2], 3: [4, 1, 2, 3, 5], 4: [1, 2]} # всего 15 друзей
Kuten näet, kaikki yli 10 000:n tunnukset sanakirjassa vahvistusta varten ovat juuri niitä, jotka varmasti palauttavat arvon False. "Ystävien" lisääminen, vahvistaminen ja poistaminen suoritetaan sanakirjassa määritellyssä järjestyksessä.
Koe suoritettiin kannettavalla tietokoneella, jossa oli Windows 10, jossa HBase suoritettiin yhdessä Docker-kontissa ja Python Jupyter Notebookin kanssa toisessa. Dockerille varattiin kaksi suorittimen ydintä ja 2 Gt RAM-muistia. Kaikki logiikka, mukaan lukien "dummy-sovelluksen" simulointi ja testidatan luomisen ja ajan mittaamisen kehys, kirjoitettiin Pythonilla. Kirjasto , laskeaksesi tiivisteet (MD5) vaihtoehdolle 5 - hashlib
Ottaen huomioon tietyn kannettavan tietokoneen laskentatehon, valittiin kokeellisesti käynnistys ajanhetkelle n = 10, 30, … 170 – jolloin koko testaussyklin kokonaiskestoaika (kaikki skenaariot kaikille vaihtoehdoille kaikille n vaihtoehdolle) oli vielä enemmän tai vähemmän kohtuullinen ja sopi yksiin teekutsuihin (keskimäärin 15 minuuttia).
On tärkeää huomata, että tässä kokeessa emme ensisijaisesti arvioi absoluuttisia suorituskykylukuja. Edes kahden eri variantin suhteellinen vertailu ei välttämättä ole täysin tarkka. Olemme tällä hetkellä kiinnostuneita ajan muutoksen luonteesta n:n funktiona, koska edellä mainitun testiympäristön kokoonpanon vuoksi satunnaisten ja muiden tekijöiden vaikutuksesta "puhdistettujen" aika-arvioiden saaminen on erittäin vaikeaa (eikä se itse asiassa ollutkaan tavoitteena).
Kokeen tulos
Ensimmäisessä testissä tarkasteltiin, miten ystävälistan täyttämiseen kuluva aika muuttuu. Tulokset näkyvät alla olevassa kaaviossa.
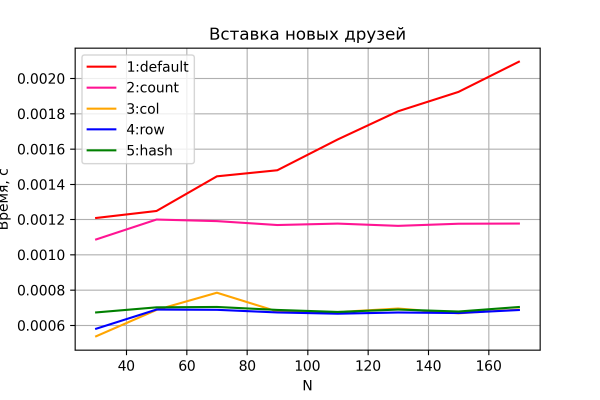
Vaihtoehdot 3–5 osoittavat odotetusti käytännössä vakion "liiketoiminnan" ajan, joka on riippumaton verkon koon kasvusta, ja eron suorituskyvyssä, joka on huomattava.
Myös variantti 2 osoittaa vakiota, mutta hieman huonompaa suorituskykyä, lähes tasan kaksi kertaa variantteihin 3–5 verrattuna. Tämä on rohkaisevaa, koska se on teorian mukainen – tässä variantissa HBaseen tulevien ja siitä pois suuntautuvien I/O-operaatioiden määrä on tasan kaksi kertaa suurempi. Tämä voi toimia epäsuorana todisteena siitä, että testijärjestelymme yleensä tuottaa kohtuullisen tarkkuuden.
Vaihtoehto 1 osoittautuu myös odotetusti hitaimmaksi ja osoittaa yhden ystävän lisäämiseen kuluvan ajan lineaarista kasvua verkon koosta riippuen.
Katsotaanpa nyt toisen testin tuloksia.
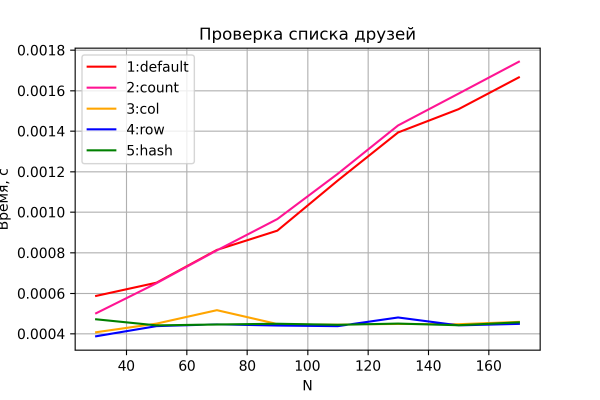
Variantit 3–5 käyttäytyvät jälleen odotetulla tavalla – vakioaikaisesti, verkon koosta riippumatta. Variantit 1 ja 2 osoittavat lineaarista ajan kasvua verkon koon myötä ja samanlaista suorituskykyä. Variantti 2 on kuitenkin hieman hitaampi – ilmeisesti johtuen tarpeesta jäsentää ja käsitellä ylimääräinen "count"-sarake, joka tulee havaittavammaksi n:n kasvaessa. Pidätän kuitenkin arvioni, koska tämän vertailun tarkkuus on suhteellisen alhainen. Lisäksi korrelaatiot (kumpi variantti, 1 vai 2, on nopeampi) vaihtelivat ajosta toiseen (vaikka ne säilyttivät johdonmukaisen kuvion ja olivat tasaväkisiä).
No, viimeinen kuvaaja on poistotestin tulos.
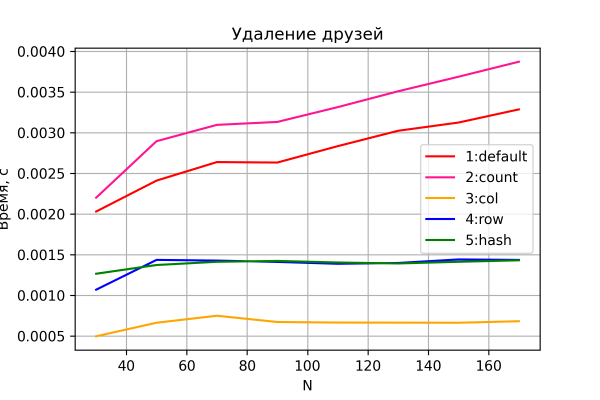
Jälleen kerran, ei yllätyksiä. Vaihtoehdot 3–5 suorittavat poiston vakioajassa.
Mielenkiintoista kyllä, vaihtoehdot 4 ja 5, toisin kuin edellisissä skenaarioissa, osoittavat huomattavasti hieman huonompaa suorituskykyä kuin vaihtoehto 3. Ilmeisesti rivien poistotoiminto on kalliimpi kuin sarakkeiden poistotoiminto, mikä on yleisesti ottaen loogista.
Vaihtoehdot 1 ja 2 osoittavat odotetusti lineaarista aikakasvua. Vaihtoehto 2 on kuitenkin jatkuvasti hitaampi kuin vaihtoehto 1 johtuen lisä-I/O-operaatioista, joita tarvitaan laskurisarakkeen ylläpitoon.
Kokeen yleiset johtopäätökset:
- Vaihtoehdot 3–5 osoittavat suurempaa tehokkuutta, koska ne hyödyntävät HBasea; niiden suorituskyky eroaa kuitenkin toisistaan vakion verran eikä riipu verkon koosta.
- Vaihtoehtojen 4 ja 5 välillä ei havaittu eroa. Tämä ei kuitenkaan tarkoita, etteikö vaihtoehtoa 5 pitäisi käyttää. On todennäköistä, että käytetty kokeellinen skenaario, ottaen huomioon testiympäristön suorituskykyominaisuudet, esti tämän havaitsemisen.
- Datan avulla "liiketoimintojen" suorittamiseen tarvittavan ajan kasvun luonne vahvisti yleisesti aiemmin saadut teoreettiset laskelmat kaikille vaihtoehdoille.
Epilogi
Näitä karkeita kokeita ei pidä pitää absoluuttisena totuutena. On monia tekijöitä, joita ei otettu huomioon ja jotka vääristivät tuloksia (nämä vaihtelut näkyvät erityisesti pienten verkkojen kokojen kuvaajissa). Esimerkiksi happybasen käyttämän thriftin nopeus, Pythonilla kirjoittamani logiikan määrä ja toteutustapa (en voi väittää, että koodi olisi kirjoitettu optimaalisesti tai että kaikkia komponentteja olisi käytetty tehokkaasti), mahdollisesti HBase-välimuistiominaisuudet ja taustalla tapahtuva toiminta. Windows 10 Kannettavalla tietokoneellani jne. Kaiken kaikkiaan voidaan todeta, että kaikki teoreettiset oletukset on kokeellisesti todistettu päteviksi. Tai ainakaan niitä ei ollut mahdollista kumota tällaisella suoralla hyökkäyksellä.
Yhteenvetona voidaan todeta, että tässä on joitakin suosituksia kaikille, jotka vasta aloittavat tietomallien suunnittelun HBase-sovelluksella: unohda aiempi kokemuksesi relaatiotietokannoista ja muista "käskyt":
- Suunnittelussa lähdemme tehtävä- ja datankäsittelymalleista, emme toimialuemallista.
- Tehokas pääsy (ilman koko taulukon skannausta) – vain avaimella
- Denormalisointi
- Eri rivit voivat sisältää eri sarakkeita.
- Dynaaminen sarakkeiden kokoonpano
Lähde: will.com
