

Työni luonteen vuoksi joudun käsittelemään tilanteita, joissa kehittäjä kirjoittaa pyynnön ja ajattelee "Pohja on älykäs, se hoitaa kaiken itse!«
Joissakin tapauksissa (osittain tietokannan ominaisuuksien tuntemattomuuden, osittain ennenaikaisten optimointien vuoksi) tämä lähestymistapa johtaa "Frankensteinien" syntymiseen.
Kerron ensin esimerkin tällaisesta pyynnöstä:
-- для каждой ключевой пары находим ассоциированные значения полей
WITH RECURSIVE cte_bind AS (
SELECT DISTINCT ON (key_a, key_b)
key_a a
, key_b b
, fld1 bind_fld1
, fld2 bind_fld2
FROM
tbl
)
-- находим min/max значений для каждого первого ключа
, cte_max AS (
SELECT
a
, max(bind_fld1) bind_fld1
, min(bind_fld2) bind_fld2
FROM
cte_bind
GROUP BY
a
)
-- связываем по первому ключу ключевые пары и min/max-значения
, cte_a_bind AS (
SELECT
cte_bind.a
, cte_bind.b
, cte_max.bind_fld1
, cte_max.bind_fld2
FROM
cte_bind
INNER JOIN
cte_max
ON cte_max.a = cte_bind.a
)
SELECT * FROM cte_a_bind;Jotta kyselyn laatua voitaisiin arvioida objektiivisesti, luodaan satunnainen tietojoukko:
CREATE TABLE tbl AS
SELECT
(random() * 1000)::integer key_a
, (random() * 1000)::integer key_b
, (random() * 10000)::integer fld1
, (random() * 10000)::integer fld2
FROM
generate_series(1, 10000);
CREATE INDEX ON tbl(key_a, key_b);
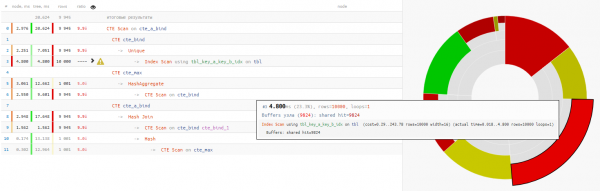
Käy ilmi, että se on tietojen lukeminen vei alle neljänneksen kokonaisajasta kyselyn suoritus:
Puretaan se pala palalta
Katsotaanpa pyyntöä tarkemmin ja hämmentykäämme:
- Miksi tässä on WITH RECURSIVE, jos rekursiivisia CTE:itä ei ole?
- Miksi ryhmitellä min/max-arvot erilliseen CTE:hen, jos ne ovat silti sidoksissa alkuperäiseen näytteeseen?
+25 % aikaa - Miksi käyttää edellisen CTE:n uudelleenlukua lopussa ehdottoman 'SELECT * FROM' -operaattorin avulla?
+14 % aikaa
Tässä tapauksessa olimme erittäin onnekkaita, että yhteydelle valittiin Hash Join, eikä Nested Loop, koska silloin emme olisi saaneet yhtäkään CTE-skannauksen läpäisyä, vaan 10K!
Hieman TT-kuvauksestaTässä meidän on muistettava, että CTE Scan on Seq Scanin analogi - eli ei indeksointia, vaan ainoastaan täydellinen luettelointi, mikä edellyttäisi 10K x 0.3 ms = 3000ms kun pyöräillään cte_maxin läpi tai 1K x 1.5 ms = 1500ms kun cte_bind suorittaa silmukan!
Mitä oikeastaan halusit saada lopputuloksena? Joo, tuollainen kysymys yleensä nousee esiin noin viidennen minuutin kohdalla analysoitaessa "kolmikerroksisia" kyselyitä.
Halusimme tuottaa jokaiselle ainutlaatuiselle avainparille min/max ryhmästä key_a:n mukaan.
Käytetäänpä sitä siis tähän tarkoitukseen :
SELECT DISTINCT ON(key_a, key_b)
key_a a
, key_b b
, max(fld1) OVER(w) bind_fld1
, min(fld2) OVER(w) bind_fld2
FROM
tbl
WINDOW
w AS (PARTITION BY key_a); 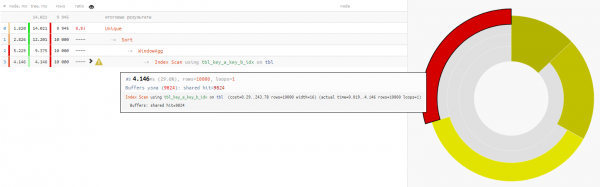
Koska datan lukeminen molemmissa vaihtoehdoissa kestää saman verran, noin 4–5 ms, niin koko ajanvoittomme -32% - tämä on puhtaimmassa muodossaan kuormitus poistettu suorittimen alustaltajos tällainen pyyntö suoritetaan riittävän usein.
Yleisesti ottaen ei ole tarvetta pakottaa perusasioita "pukeutumaan pyöreisiin vaatteisiin, rullaamaan neliömäisiä asioita".
Lähde: will.com
