

Nykyaikaisissa datakeskuksissa on satoja aktiivisia laitteita, jotka on katettu erityyppisten valvonnan alaisina. Mutta jopa täydellinen insinööri, jolla on täydellinen valvonta kädessään, pystyy reagoimaan oikein verkkovikaan vain muutamassa minuutissa. Esittelin Next Hop 2020 -konferenssin raportissa palvelinkeskusten verkon suunnittelumetodologian, jossa on ainutlaatuinen ominaisuus - palvelinkeskus paranee itsestään millisekunneissa. Tarkemmin sanottuna insinööri korjaa ongelman rauhallisesti, kun taas palvelut eivät yksinkertaisesti huomaa sitä.
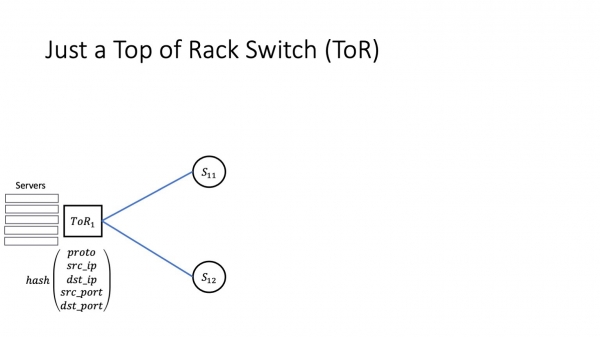
Monille verkkoinsinööreille konesaliverkko alkaa tietysti ToR:lla, telineessä olevalla kytkimellä. ToR:ssa on yleensä kahdenlaisia linkkejä. Pienet menevät palvelimille, toiset - niitä on N kertaa enemmän - menevät kohti ensimmäisen tason spinejä eli sen uplinkkejä. Ylösnousevia linkkejä pidetään yleensä tasa-arvoisina, ja nousevien linkkien välinen liikenne on tasapainotettu 5-tuple hashin perusteella, joka sisältää proton, src_ip, dst_ip, src_port, dst_port. Tässä ei ole yllätyksiä.
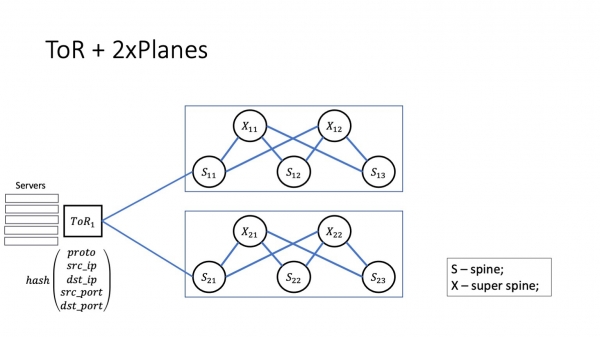
Seuraavaksi, miltä lentokoneiden arkkitehtuuri näyttää? Ensimmäisen tason piikit eivät ole yhteydessä toisiinsa, vaan ne on yhdistetty superspinien avulla. Kirjain X on vastuussa superpyöräytyksistä, se on melkein kuin ristikytkentä.
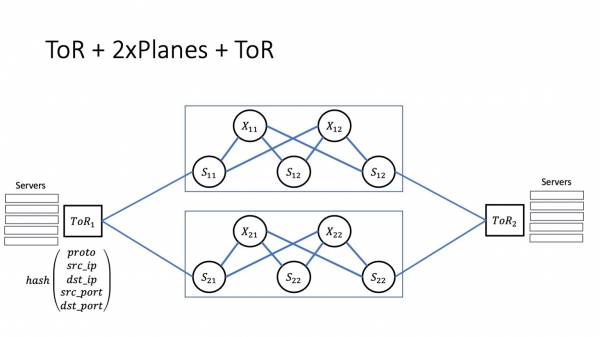
Ja on selvää, että toisaalta torit ovat yhteydessä kaikkiin ensimmäisen tason piikkeihin. Mikä tässä kuvassa on tärkeää? Jos meillä on vuorovaikutusta telineen sisällä, vuorovaikutus tapahtuu tietysti ToR:n kautta. Jos vuorovaikutus menee moduulin sisään, vuorovaikutus kulkee ensimmäisen tason piikien läpi. Jos vuorovaikutus on modulaarista - kuten tässä, ToR 1 ja ToR 2 - niin vuorovaikutus kulkee sekä ensimmäisen että toisen tason piikin läpi.
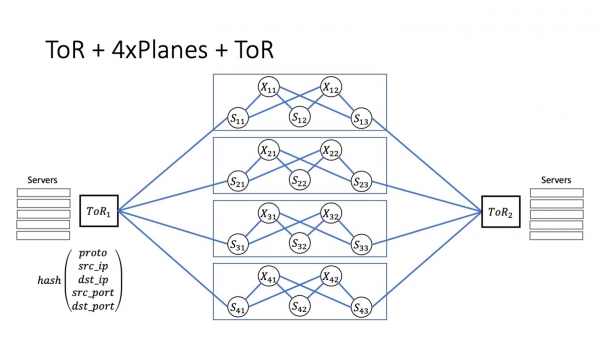
Teoriassa tällainen arkkitehtuuri on helposti skaalautuva. Jos meillä on porttikapasiteettia, tilaa palvelinkeskuksessa ja valmiiksi asennettu kuitu, niin koneiden määrää voidaan aina lisätä, mikä lisää järjestelmän kokonaiskapasiteettia. Paperilla tämä on erittäin helppo tehdä. Niin se olisi oikeassa elämässä. Mutta tämän päivän tarina ei koske sitä.

Haluan tehdä oikeat johtopäätökset. Meillä on monia polkuja palvelinkeskuksen sisällä. He ovat ehdollisesti riippumattomia. Yksi tapa palvelinkeskuksen sisällä on mahdollista vain ToR:n sisällä. Moduulin sisällä meillä on sama määrä polkuja kuin tasoja. Moduulien välisten polkujen määrä on yhtä suuri kuin tasojen lukumäärän ja kunkin tason superspins-määrän tulo. Selkeyttääkseni ja tunteakseni mittakaavan annan numerot, jotka ovat voimassa yhdelle Yandex-palvelinkeskuksesta.

Lentokoneita on kahdeksan, jokaisessa koneessa on 32 superpyöräytystä. Tuloksena käy ilmi, että moduulin sisällä on kahdeksan polkua, ja moduulien välisellä vuorovaikutuksella niitä on jo 256.

Eli jos kehitämme keittokirjaa ja yritämme oppia rakentamaan vikasietoisia datakeskuksia, jotka parantavat itsensä, tasomaarkkitehtuuri on oikea valinta. Sen avulla voit ratkaista skaalausongelman, ja teoriassa se on helppoa. On monia itsenäisiä polkuja. Kysymys jää: kuinka tällainen arkkitehtuuri selviää epäonnistumisista? On erilaisia törmäyksiä. Ja keskustelemme tästä nyt.
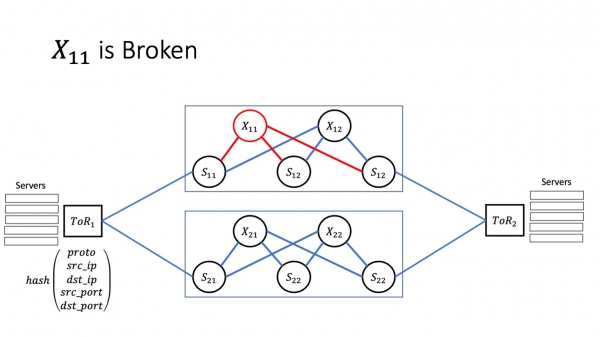
Anna yhden superspinistämme sairastua. Tässä palasin kahden koneen arkkitehtuuriin. Pidämme niistä esimerkkinä, koska on yksinkertaisesti helpompi nähdä, mitä täällä tapahtuu, kun liikkuvia osia on vähemmän. Anna X11 sairastua. Miten tämä vaikuttaa palvelinkeskusten sisällä oleviin palveluihin? Paljon riippuu siitä, miltä epäonnistuminen todella näyttää.
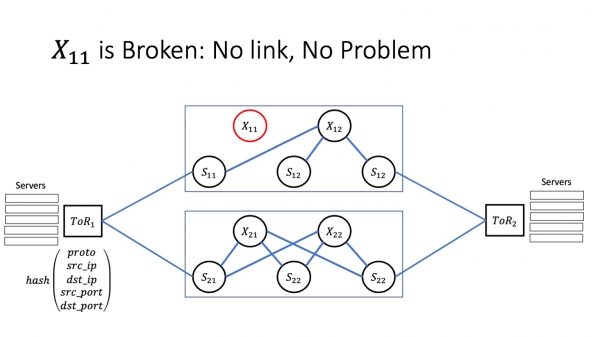
Jos vika on hyvä, se jää kiinni saman BFD:n automaation tasolle, automaatio laittaa iloisesti ongelmaliitoksia ja eristää ongelman, niin kaikki on hyvin. Meillä on monia polkuja, liikenne ohjautuu välittömästi vaihtoehtoisille reiteille, eivätkä palvelut huomaa mitään. Tämä on hyvä skenaario.
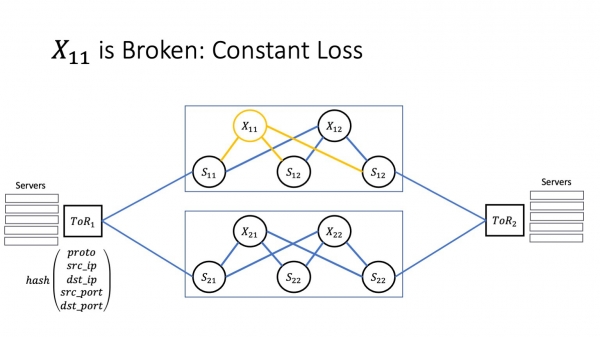
Huono skenaario on, jos meillä on jatkuvaa tappiota, eikä automaatio huomaa ongelmaa. Ymmärtääksemme, kuinka tämä vaikuttaa sovellukseen, meidän on käytävä vähän aikaa keskustelemalla siitä, kuinka TCP-protokolla toimii.
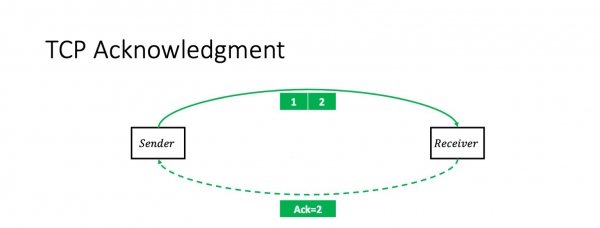
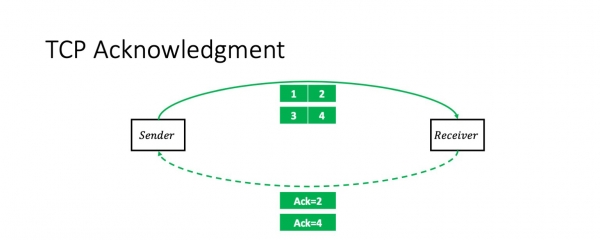
Toivottavasti en järkytä ketään tällä tiedolla: TCP on kättelyprotokolla. Eli yksinkertaisimmassa tapauksessa lähettäjä lähettää kaksi pakettia ja saa niistä kumulatiivisen kuittauksen: "Sain kaksi pakettia."
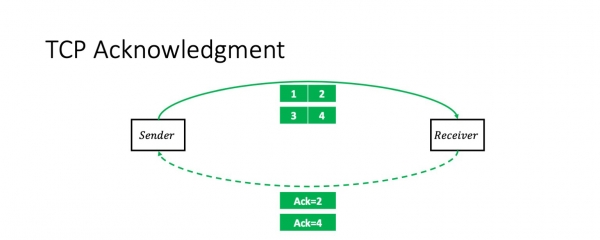
Sen jälkeen hän lähettää vielä kaksi pakettia, ja tilanne toistuu. Pahoittelen jo etukäteen pientä yksinkertaistamista. Tämä skenaario on oikea, jos ikkuna (pakettien lukumäärä lennolla) on kaksi. Tämä ei tietenkään välttämättä pidä paikkaansa yleisesti. Mutta ikkunan koko ei vaikuta pakettien edelleenlähetyskontekstiin.
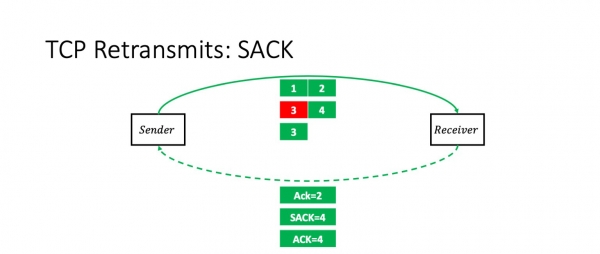
Mitä tapahtuu, jos menetämme paketin 3? Tässä tapauksessa vastaanottaja saa paketit 1, 2 ja 4. Ja hän ilmoittaa lähettäjälle SACK-vaihtoehdolla nimenomaisesti: "Tiedät, kolme tuli, mutta keskimmäinen hävisi." Hän sanoo "Ack 2, SACK 4".
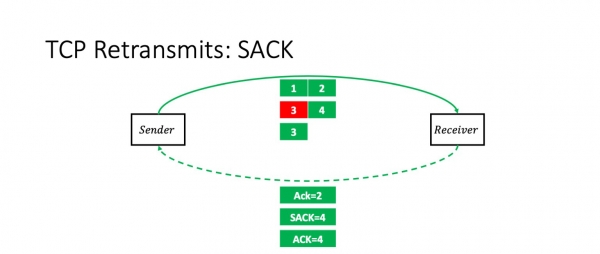
Lähettäjä toistaa tällä hetkellä tarkalleen kadonneen paketin ilman ongelmia.
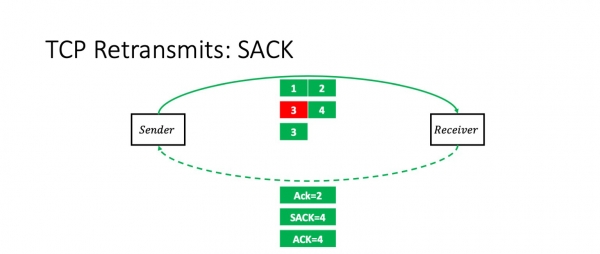
Mutta jos ikkunan viimeinen paketti katoaa, tilanne näyttää hyvin erilaiselta.
Vastaanottaja vastaanottaa kolme ensimmäistä pakettia ja alkaa odottaa. Ytimen TCP-pinon optimointien ansiosta Linux Se odottaa vastaavaa pakettia, ellei ole olemassa nimenomaista merkintää, joka ilmoittaisi sen olevan viimeinen paketti tai jotain vastaavaa. Se odottaa, kunnes viivästetyn kuittauksen aikakatkaisu umpeutuu, ja lähettää sitten kuittauksen kolmelle ensimmäiselle paketille. Mutta nyt lähettäjän on odotettava. Se ei tiedä, onko neljäs paketti kadonnut vai onko se saapumassa. Verkon ylikuormituksen välttämiseksi se yrittää odottaa, kunnes on nimenomainen ilmoitus paketin katoamisesta tai kunnes RTO-aikakatkaisu umpeutuu.
Mikä on RTO-aikakatkaisu? Tämä on TCP-pinon laskeman RTT:n maksimi ja jokin vakio. Mikä tämä vakio on, keskustelemme nyt.
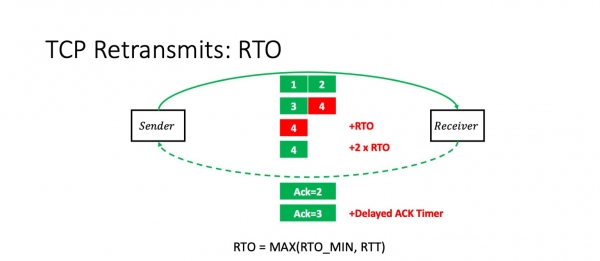
Mutta on tärkeää, että jos olemme jälleen epäonnisia ja neljäs paketti häviää jälleen, RTO kaksinkertaistuu. Eli jokainen epäonnistunut yritys kaksinkertaistaa aikakatkaisun.
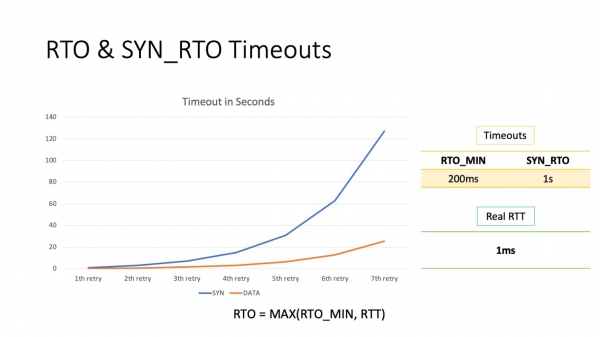
Katsotaan nyt, mitä tämä perusta vastaa. Oletuksena pienin RTO on 200 ms. Tämä on pienin RTO datapaketteille. SYN-pakettien kohdalla se on erilainen, 1 sekunti. Kuten näet, jopa ensimmäinen yritys lähettää paketteja uudelleen kestää 100 kertaa kauemmin kuin RTT datakeskuksen sisällä.
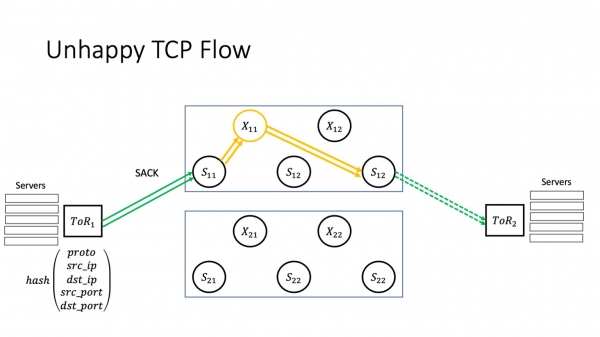
Nyt takaisin skenaarioimme. Mitä palvelulle tapahtuu? Palvelu alkaa menettää paketteja. Olkoon palvelu aluksi onnekas ja menettää jotain keskellä ikkunaa, sitten se vastaanottaa SACKin, lähettää kadonneet paketit uudelleen.
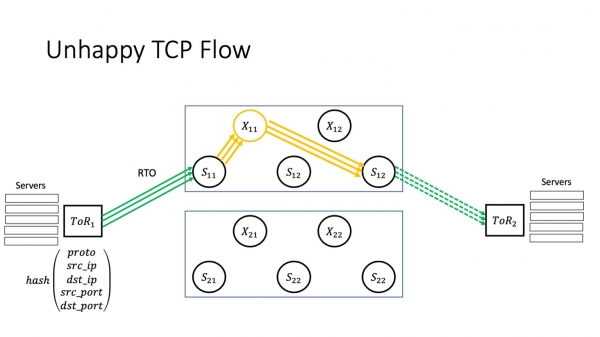
Mutta jos huono onni toistuu, meillä on RTO. Mikä tässä on tärkeää? Kyllä, meillä on monia polkuja verkossa. Mutta tietyn TCP-yhteyden TCP-liikenne kulkee edelleen saman rikkinäisen pinon läpi. Pakettien katoaminen, mikäli taika X11 ei sammu itsestään, ei johda liikenteen virtaamiseen alueille, jotka eivät ole ongelmallisia. Yritämme toimittaa paketin saman rikkinäisen pinon kautta. Tämä johtaa peräkkäiseen epäonnistumiseen: datakeskus on joukko vuorovaikutuksessa olevia sovelluksia, ja osa kaikkien näiden sovellusten TCP-yhteyksistä alkaa heikentyä - koska superspin vaikuttaa kaikkiin DC:n sisällä oleviin sovelluksiin. Kuten sanonnassa: jos et kenkiä hevosta, hevonen ontuu; hevonen ontui - raporttia ei toimitettu; viestiä ei toimitettu - he hävisivät sodan. Vain tässä laskenta kestää sekunteja siitä hetkestä, kun ongelma ilmenee, siihen huononemisvaiheeseen, jota palvelut alkavat tuntea. Tämä tarkoittaa, että käyttäjät eivät välttämättä saa jotain jonnekin.

On olemassa kaksi klassista ratkaisua, jotka täydentävät toisiaan. Ensimmäinen niistä on palveluja, jotka yrittävät laskea olkia ja ratkaista ongelman seuraavasti: ”Tipitetään jotain TCP-pinossa. Tehdään sovellustason aikakatkaisut tai pitkäikäiset TCP-istunnot sisäisten kuntotarkastusten kanssa. Ongelmana on, että tällaiset ratkaisut: a) eivät skaalaudu ollenkaan; b) erittäin huonosti testattu. Eli vaikka palvelu vahingossa määrittää TCP-pinon niin, että siitä tulee parempi, ensinnäkin tämä ei todennäköisesti sovellu kaikkiin sovelluksiin ja kaikkiin tietokeskuksiin, ja toiseksi, todennäköisimmin se ei ymmärrä mitä tehtiin oikein ja mitä ei. Eli se toimii, mutta toimii huonosti eikä skaalaudu. Ja jos on verkko-ongelma, kuka on syyllinen? Tietenkin NOC. Mitä NOC tekee?

Monet palvelut uskovat, että NOC:ssa työ menee suunnilleen näin. Mutta ollakseni rehellinen, ei vain.

Klassisessa järjestelmässä NOC on mukana monien monitorointien kehittämisessä. Nämä ovat sekä mustan laatikon valvontaa että valkoisen laatikon valvontaa. Esimerkkinä selkärangan mustan laatikon seurannasta Alexander Klimenko menneestä Next Hopista. Tämä valvonta muuten toimii. Mutta jopa täydellisellä seurannalla on aikaviive. Yleensä se on useita minuutteja. Kun se toimii, päivystävät insinöörit tarvitsevat aikaa tarkistaakseen sen toiminnan, paikallistaakseen ongelman ja sammuttaakseen ongelma-alueen. Eli ongelman hoito kestää parhaassa tapauksessa 5 minuuttia, pahimmillaan 20 minuuttia, jos ei heti ole selvää, missä häviöt syntyvät. On selvää, että koko tämän ajan - 5 tai 20 minuuttia - palvelumme kärsii edelleen, mikä ei todennäköisesti ole hyvä.
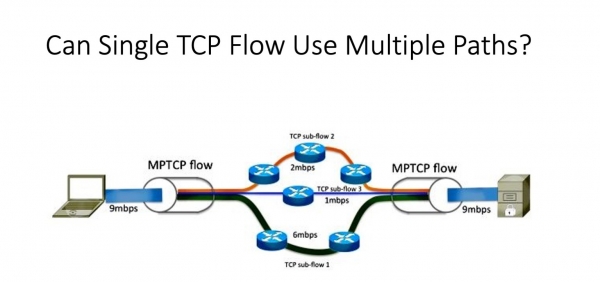
Mitä haluaisit saada? Meillä on niin monia polkuja. Ja ongelmia syntyy juuri siksi, että epäonniset TCP-virrat käyttävät edelleen samaa reittiä. Tarvitsemme jotain, jonka avulla voimme käyttää useita reittejä yhdessä TCP-yhteydessä. Vaikuttaa siltä, että meillä on ratkaisu. On olemassa TCP, jota kutsutaan niin - monitie-TCP:ksi, eli TCP monille poluille. Totta, se kehitettiin täysin eri tehtävään - älypuhelimille, joissa on useita verkkolaitteita. Siirron maksimoimiseksi tai ensisijaisen / varmuuskopiointitilan tekemiseksi kehitettiin mekanismi, joka luo läpinäkyvästi useita säikeitä (istuntoja) sovellukselle ja antaa sinun vaihtaa niiden välillä epäonnistumisen sattuessa. Tai, kuten sanoin, maksimoi kaistanleveys.
Mutta tässä on vivahde. Ymmärtääksemme, mikä se on, meidän on tarkasteltava, miten streamit on määritetty.
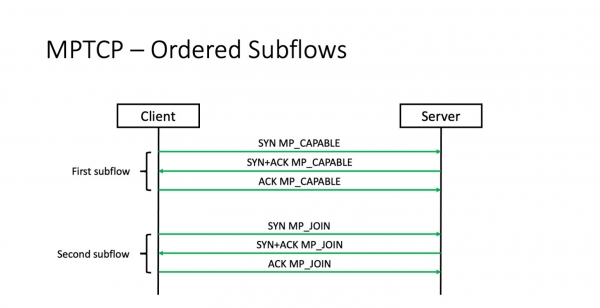
Langat asetetaan peräkkäin. Ensimmäinen stream asennetaan ensin. Seuraavat virtaukset asetetaan sitten käyttämällä kyseisessä säikeessä jo sovittua evästettä. Ja tässä on ongelma.

Ongelmana on, että jos ensimmäinen säie ei asennu, toista ja kolmatta säiettä ei tule koskaan esiin. Toisin sanoen monitie-TCP ei ratkaise SYN-paketin menetystä ensimmäisessä virrassa. Ja jos SYN katoaa, monitie-TCP:stä tulee normaali TCP. Joten palvelinkeskusympäristössä se ei auta meitä ratkaisemaan tehtaan hävikkiongelmaa ja oppimaan käyttämään useita polkuja vikatilanteissa.
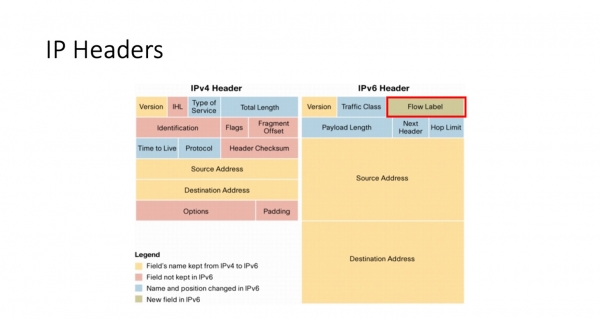
Mikä voi auttaa meitä? Jotkut teistä ovat jo otsikosta arvanneet, että tärkeä kenttä jatkokeskustelussamme on IPv6-vuon tunnisteen otsikkokenttä. Tämä kenttä, joka esiintyy versiossa 6 ja puuttuu versiosta 4, vie itse asiassa 20 bittiä, ja sen käytöstä on keskusteltu paljon. Tämä on erittäin mielenkiintoista – keskustelua käytiin, joitakin asioita korjattiin RFC-asiakirjoissa ja... Linux- samaan aikaan ytimeen ilmestyi toteutus, jota ei koskaan dokumentoitu missään.

Kutsun sinut mukaan pieneen tutkimukseen. Katsotaanpa, mitä ytimessä tapahtui. Linux viime vuosien aikana.

2014. Suuren ja arvostetun yrityksen insinööri lisää toiminnallisuutta ytimeen Linux Virtaustunnisteen arvon riippuvuus soketin tiivisteestä. Mitä he yrittivät tässä korjata? Tämä liittyy RFC 6438:aan, jossa käsiteltiin seuraavaa ongelmaa. Datakeskuksen sisällä IPv4 on usein kapseloitu IPv6-paketteihin, koska itse kudos on IPv6, mutta IPv4 on toimitettava ulkoisesti. Pitkään oli ongelmia kytkimien kanssa, jotka eivät pystyneet etsimään kahden IP-otsikon alta TCP- tai UDP-protokollaan ja löytämään src_ports- ja dst_ports-osoitteita. Tämä tarkoitti, että tiiviste, kun tarkastellaan kahta ensimmäistä IP-otsikkoa, oli käytännössä kiinteä. Tämän välttämiseksi ja tämän kapseloidun liikenteen asianmukaisen tasapainottamisen varmistamiseksi ehdotettiin, että 5-tupleisen kapseloidun paketin tiiviste lisättäisiin virtaustunnistekenttään. Suunnilleen sama tehtiin muille kapselointimalleille, UDP:lle ja GRE:lle, jälkimmäisessä käytettiin GRE-avainkenttää. Joka tapauksessa tavoitteet ovat selvät. Ja ainakin tuolloin ne olivat hyödyllisiä.
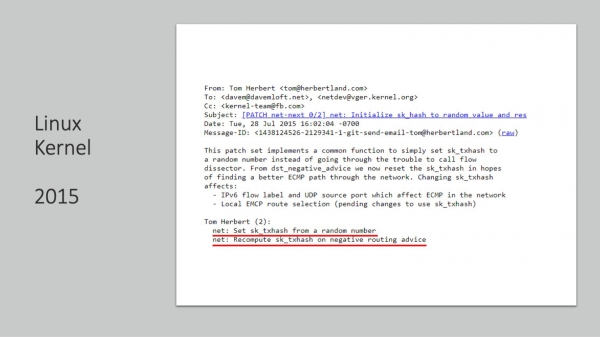
Vuonna 2015 uusi korjaustiedosto tulee samalta arvostetulta insinööriltä. Hän on erittäin mielenkiintoinen. Se sanoo seuraavaa - satunnaistamme tiivisteen negatiivisen reititystapahtuman tapauksessa. Mikä on negatiivinen reititystapahtuma? Tämä on RTO, josta keskustelimme aiemmin, eli ikkunan hännän menetys on tapahtuma, joka on todella negatiivinen. On totta, että on suhteellisen vaikea arvata, mikä se on.

2016, toinen arvostettu yritys, myös iso. Se jäsentää viimeiset kainalosauvat ja tekee siitä niin, että aiemmin satunnaistettu hash muuttuu nyt jokaisen SYN-uudelleenlähetyksen ja jokaisen RTO-aikakatkaisun jälkeen. Ja tässä kirjeessä, ensimmäistä ja viimeistä kertaa, perimmäinen tavoite kuuluu - varmistaa, että liikenteellä kanavien katoamisen tai ylikuormituksen sattuessa on mahdollisuus pehmeään uudelleenreitittämiseen käyttämällä useita polkuja. Tietenkin sen jälkeen oli paljon julkaisuja, löydät ne helposti.
Vaikka ei, et voi, koska tästä aiheesta ei ole julkaistu yhtään julkaisua. Mutta me tiedämme!

Ja jos et täysin ymmärrä mitä tehtiin, kerron sinulle nyt.

Mitä tehtiin, mitä toimintoja ytimeen lisättiin? Linux? Txhash muuttuu satunnaiseksi arvoksi jokaisen RTO-tapahtuman jälkeen. Tämä on sama negatiivinen reititystulos. Hajautus riippuu tästä txhashista ja vuon tunniste riippuu skb-hajautuksesta. Tässä on joitakin toiminnallisia selityksiä, mutta yksi dia ei kata kaikkia yksityiskohtia. Jos jotakuta kiinnostaa, voit käydä kernel-koodin läpi askel askeleelta ja tarkistaa sen.
Mikä tässä on tärkeää? Vuon otsikkokentän arvo muuttuu satunnaisluvuksi jokaisen RTO:n jälkeen. Miten tämä vaikuttaa epäonniseen TCP-virtaamme?
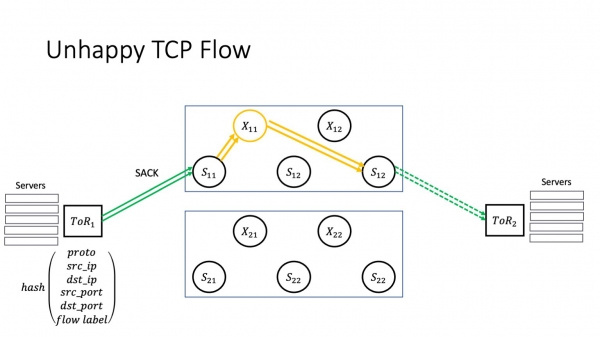
SACK:n tapauksessa mikään ei ole muuttunut, koska yritämme lähettää tunnetun kadonneen paketin uudelleen. Toistaiseksi hyvin.
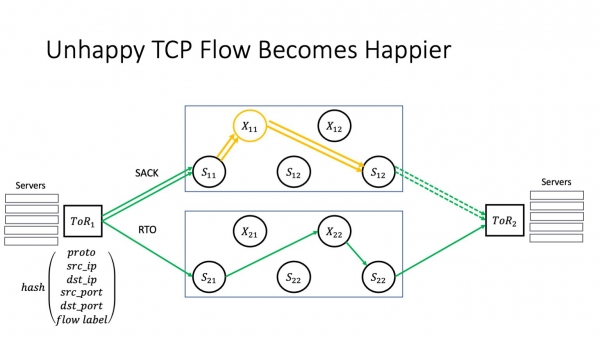
Mutta RTO:n tapauksessa, jos olemme lisänneet kulkutunnisteen hajautustoimintoon ToR:ssa, liikenne voi kulkea eri reittiä. Ja mitä enemmän lentokoneita, sitä todennäköisemmin on löydetty polku, johon tietyn laitteen törmäys ei vaikuta.
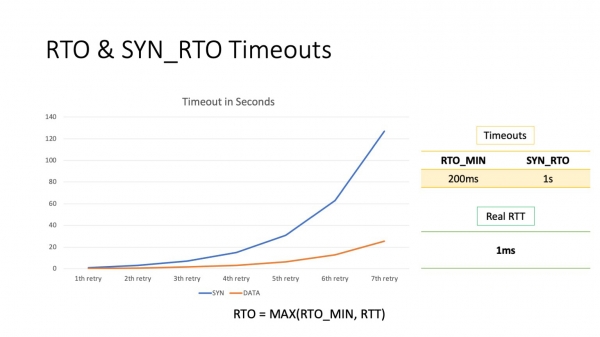
Yksi ongelma on edelleen - RTO. Toinen reitti tietysti löytyy, mutta siihen kuluu paljon aikaa. 200ms on paljon. Toinen on yleensä villiä. Aiemmin puhuin aikakatkaisuista, jotka määrittävät palvelut. Sekunti on siis aikakatkaisu, joka yleensä asettaa palvelun sovellustasolle, ja tässä palvelu on jopa suhteellisen oikea. Lisäksi toistan, että todellinen RTT nykyaikaisen datakeskuksen sisällä on noin 1 millisekunti.

Mitä RTO-aikakatkaisuille voidaan tehdä? Aikakatkaisu, joka vastaa RTO:sta datapakettien katoamisen yhteydessä, on suhteellisen helposti konfiguroitavissa käyttäjätilasta: IP-apuohjelma on olemassa, ja yksi sen parametreista sisältää saman rto_min. Ottaen huomioon, että sinun ei tietenkään tarvitse kääntää RTO:ta ei globaalisti, vaan tietyille etuliitteille, tällainen mekanismi näyttää varsin toimivalta.

Totta, SYN_RTO:lla kaikki on hieman huonompaa. Se on luonnollisesti naulattu. Arvo on kiinteä ytimessä - 1 sekunti, ja siinä se. Et voi tavoittaa sitä käyttäjätilasta. On vain yksi tapa.
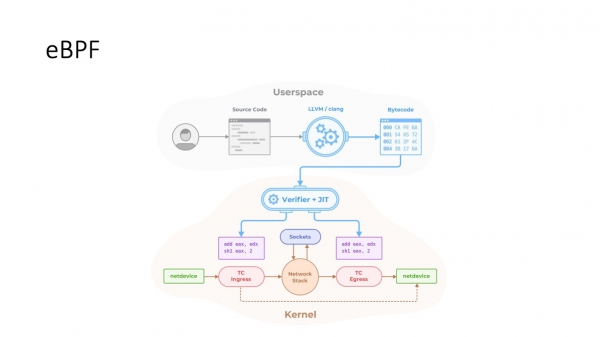
eBPF tulee apuun. Yksinkertaisesti sanottuna nämä ovat pieniä C-ohjelmia, jotka voidaan laittaa koukkuihin eri paikkoihin ydinpinon ja TCP-pinon suorituksessa, joilla voidaan muuttaa erittäin paljon asetuksia. Yleensä eBPF on pitkän aikavälin trendi. Sen sijaan, että sahattaisiin kymmeniä uusia sysctl-parametreja ja laajettaisiin IP-apuohjelmaa, liike on eBPF:n suuntaan ja sen toiminnallisuuden laajentamiseen. eBPF:n avulla voit dynaamisesti muuttaa ruuhkanhallintaa ja monia muita TCP-asetuksia.
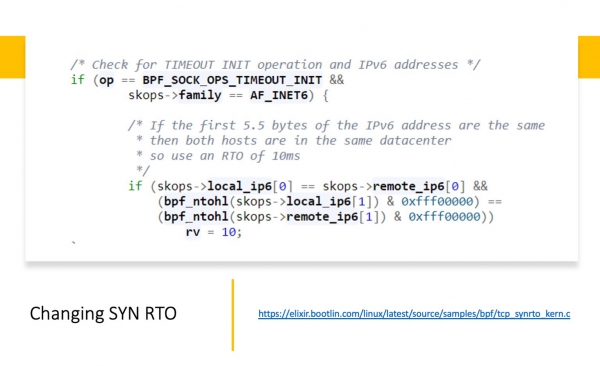
Mutta meille on tärkeää, että sen avulla voit kääntää SYN_RTO:n arvoja. Ja on julkisesti julkaistu esimerkki: . Mitä täällä tehdään? Esimerkki toimii, mutta itsessään on erittäin karkea. Tässä oletetaan, että datakeskuksen sisällä vertaamme ensimmäisiä 44 bittiä, jos ne täsmäävät, olemme DC:n sisällä. Ja tässä tapauksessa muutamme SYN_RTO-aikakatkaisun arvon 4 ms. Saman tehtävän voi tehdä paljon sulavammin. Mutta tämä yksinkertainen esimerkki osoittaa, mikä on a) mahdollista; b) suhteellisen helppoa.

Mitä me jo tiedämme? Se, että tasomaista arkkitehtuuria mahdollistaa skaalauksen, osoittautuu meille erittäin hyödylliseksi, kun laitamme virtausmerkinnän päälle ToR:ssa ja saamme mahdollisuuden virrata ongelma-alueiden ympäri. Paras tapa alentaa RTO- ja SYN-RTO-arvoja on käyttää eBPF-ohjelmia. Kysymys kuuluu: onko virtausmerkinnän käyttäminen tasapainoitukseen turvallista? Ja tässä on vivahde.
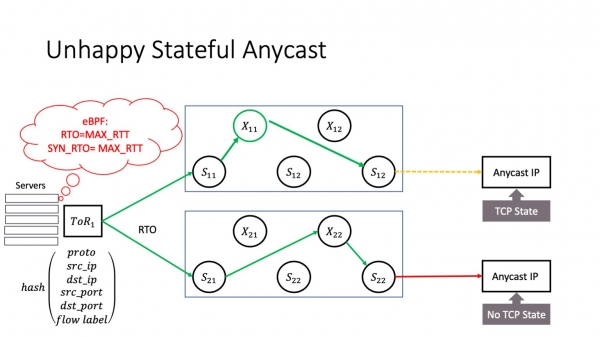
Oletetaan, että sinulla on verkossa palvelu, joka toimii anycastissa. Valitettavasti minulla ei ole aikaa mennä yksityiskohtiin anycastista, mutta se on hajautettu palvelu, jossa eri fyysisiä palvelimia on saatavilla samalla IP-osoitteella. Ja tässä on mahdollinen ongelma: RTO-tapahtuma ei voi tapahtua vain silloin, kun liikenne kulkee tehtaan läpi. Se voi tapahtua myös ToR-puskuritasolla: kun incast-tapahtuma tapahtuu, se voi tapahtua jopa isännässä, kun isäntä roiskuu jotain. Kun RTO-tapahtuma tapahtuu ja se muuttaa kulun nimeä. Tässä tapauksessa liikenne voi siirtyä toiseen anycast-esiintymään. Oletetaan, että se on tilallinen anycast, se sisältää yhteystilan - se voi olla L3 Balancer tai jokin muu palvelu. Sitten syntyy ongelma, koska RTO:n jälkeen TCP-yhteys saapuu palvelimelle, joka ei tiedä tästä TCP-yhteydestä mitään. Ja jos meillä ei ole tilanjakoa anycast-palvelimien välillä, tällainen liikenne katkeaa ja TCP-yhteys katkeaa.
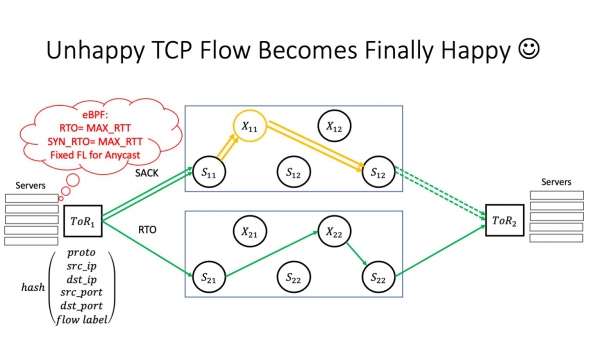
Mitä tässä voi tehdä? Hallitussa ympäristössäsi, jossa otat käyttöön vuotunnisteen tasapainotuksen, sinun on korjattava vuotunnisteen arvo, kun käytät anycast-palvelimia. Helpoin tapa on tehdä se saman eBPF-ohjelman kautta. Mutta tässä on erittäin tärkeä kohta - mitä tehdä, jos et käytä datakeskusverkkoa, mutta olet teleoperaattori? Tämä on myös sinun ongelmasi: alkaen tietyistä Juniperin ja Aristan versioista, ne sisältävät virtatunnisteen oletuksena hash-funktioon - ollakseni rehellinen, syystä, jota en ymmärrä. Tämä voi aiheuttaa TCP-yhteyksien katkeamisen verkkosi kautta kulkevilta käyttäjiltä. Siksi suosittelen tarkistamaan reitittimen asetukset tässä paikassa.
Tavalla tai toisella minusta näyttää siltä, että olemme valmiita siirtymään kokeiluihin.
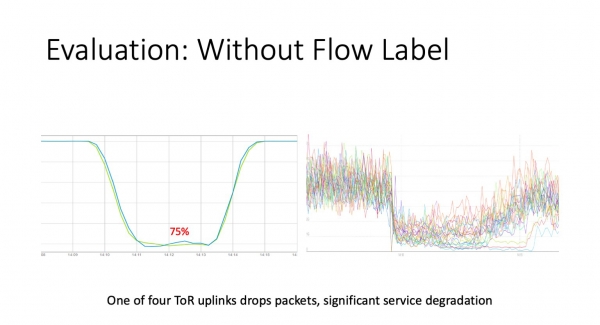
Kun otimme käyttöön virtausmerkinnän ToR:ssa, valmistelimme agentin eBPF:n, joka nyt elää isännissä, päätimme olla odottamatta seuraavaa suurta epäonnistumista, vaan suorittaa kontrolloituja räjähdyksiä. Otimme ToR:n, jossa on neljä uplinkkiä, ja teimme pudotuksia yhdelle niistä. He piirsivät säännön, he sanoivat - nyt menetät kaikki paketit. Kuten näet vasemmalla, meillä on pakettikohtainen valvonta, joka on pudonnut 75 %:iin, eli 25 % paketeista katoaa. Oikealla on kaavioita tämän ToR:n takana olevista palveluista. Itse asiassa nämä ovat liikennekaavioita telineen sisällä olevien palvelimien liitoksista. Kuten näette, ne putosivat vielä alemmas. Miksi ne upposivat alemmas - ei 25%, mutta joissain tapauksissa 3-4 kertaa? Jos TCP-yhteys on epäonninen, se yrittää edelleen päästä rikkinäisen rajapinnan kautta. Tätä pahentaa palvelun tyypillinen käyttäytyminen DC:n sisällä - yhdelle käyttäjäpyynnölle luodaan N pyyntöä sisäisiin palveluihin, ja vastaus lähetetään käyttäjälle joko kun kaikki tietolähteet vastaavat tai kun aikakatkaisu laukeaa sovellustaso, joka on vielä määritettävä. Eli kaikki on erittäin, erittäin huonosti.
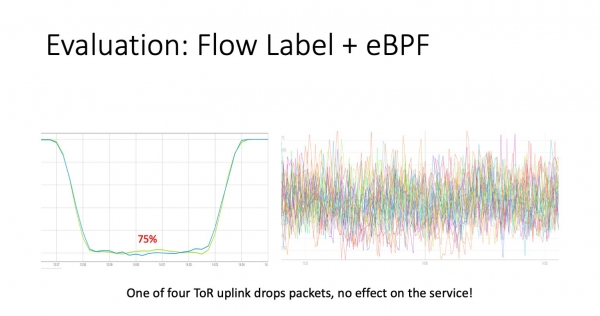
Nyt sama kokeilu, mutta virtausmerkintä käytössä. Kuten näette, vasemmalla erävalvontamme laski samat 25%. Tämä on täysin oikein, koska se ei tiedä mitään uudelleenlähetyksistä, se lähettää paketteja ja yksinkertaisesti laskee toimitettujen ja kadonneiden pakettien määrän.
Ja oikealla on palveluiden aikataulu. Et löydä ongelmanivelen vaikutusta täältä. Samassa millisekunnissa liikennettä virtasi ongelma-alueelta kolmeen jäljellä olevaan ylöslinkkiin, joihin ongelma ei vaikuttanut. Meillä on verkosto, joka parantaa itsensä.

Tämä on viimeinen diani; aika tiivistää asiat. Toivottavasti nyt tiedät, miten rakennetaan itseään korjaava datakeskusverkko. Sinun ei tarvitse kaivautua kernel-arkistoon. Linux Ja etsi sieltä erikoiskorjauksia. Tiedät, että Flow Label ratkaisee ongelman tässä tapauksessa, mutta sinun on lähestyttävä tätä mekanismia varoen. Ja korostan jälleen, että jos olet teleoperaattori, sinun ei tule käyttää Flow Labelia hajautusfunktiona, muuten häiritset käyttäjiesi istuntoja.
Verkkoinsinöörien kannalta käsitteellisen muutoksen on tapahduttava: verkko ei aloita ToR:sta, ei verkkolaitteesta, vaan isännästä. Melko silmiinpistävä esimerkki on se, kuinka käytämme eBPF:ää sekä RTO:n muuttamiseen että vuotunnisteen kiinnittämiseen anycast-palveluihin.
Virtaustarramekaanikko soveltuu varmasti muihinkin käyttötarkoituksiin valvotun hallinnollisen segmentin sisällä. Tämä voi olla datakeskusten välistä liikennettä tai voit käyttää tällaista mekaniikkaa erityisellä tavalla ohjaamaan lähtevää liikennettä. Mutta toivottavasti puhun tästä ensi kerralla. Kiitos paljon huomiostanne.
Lähde: will.com
