

Äskettäin julkaistu , mikä osoittaa hyvää trendiä koneoppimisessa viime vuosina. Lyhyesti sanottuna: koneoppimisyritysten määrä on romahtanut viimeisen kahden vuoden aikana.
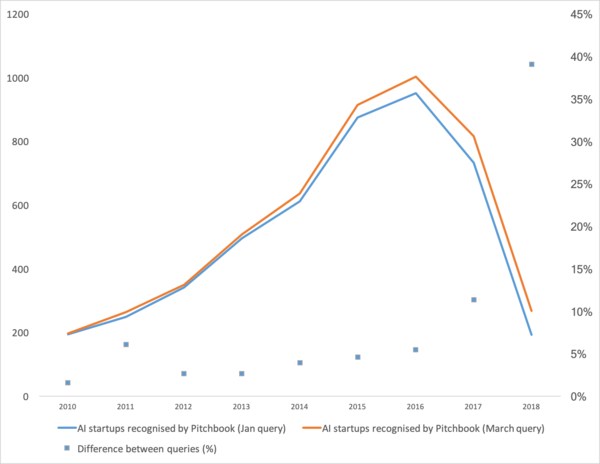
Hyvin. Katsotaanpa "onko kupla puhjennut", "kuinka jatkaa elämää" ja keskustellaan siitä, mistä tämä kikka tulee.
Ensin puhutaan siitä, mikä oli tämän käyrän tehostin. Mistä hän tuli? He varmaan muistavat kaiken koneoppimista vuonna 2012 ImageNet-kilpailussa. Onhan tämä ensimmäinen maailmanlaajuinen tapahtuma! Mutta todellisuudessa näin ei ole. Ja käyrän kasvu alkaa hieman aikaisemmin. Jakaisin sen useaan kohtaan.
- Vuonna 2008 ilmaantui termi "big data". Oikeat tuotteet alkoivat vuodesta 2010 lähtien. Big data liittyy suoraan koneoppimiseen. Ilman big dataa tuolloin olemassa olevien algoritmien vakaa toiminta on mahdotonta. Ja nämä eivät ole neuroverkkoja. Vuoteen 2012 asti neuroverkot olivat marginaalisen vähemmistön omaisuutta. Mutta sitten alkoivat toimia täysin erilaiset algoritmit, jotka olivat olleet olemassa vuosia tai jopa vuosikymmeniä: (1963,1993, XNUMX), (1995) (2003),... Noiden vuosien startup-yritykset liittyvät ensisijaisesti strukturoidun tiedon automaattiseen käsittelyyn: kassakoneet, käyttäjät, mainonta, paljon muuta.
Tämän ensimmäisen aallon johdannainen on joukko kehyksiä, kuten XGBoost, CatBoost, LightGBM jne.
- Vuosina 2011-2012 voitti useita kuvantunnistuskilpailuja. Niiden todellinen käyttö viivästyi jonkin verran. Sanoisin, että massiivisesti merkityksellisiä startuppeja ja ratkaisuja alkoi ilmestyä vuonna 2014. Kesti kaksi vuotta sulatella, että neuronit edelleen toimivat, luoda käteviä puitteita, jotka voidaan asentaa ja käynnistää kohtuullisessa ajassa, kehittää menetelmiä, jotka vakauttaisivat ja nopeuttaisivat konvergenssiaikaa.
Konvoluutioverkot mahdollistivat tietokonenäköongelmien ratkaisemisen: kuvien ja esineiden luokittelu kuvassa, esineiden havaitseminen, esineiden ja ihmisten tunnistaminen, kuvan parantaminen jne.
- 2015-2017. Toistuviin verkkoihin tai niiden analogeihin (LSTM, GRU, TransformerNet jne.) perustuvien algoritmien ja projektien buumi. Hyvin toimivat puheen tekstiksi -algoritmit ja konekäännösjärjestelmät ovat ilmaantuneet. Ne perustuvat osittain konvoluutioverkkoihin perusominaisuuksien poimimiseksi. Osittain siitä syystä, että opimme keräämään todella suuria ja hyviä aineistoja.
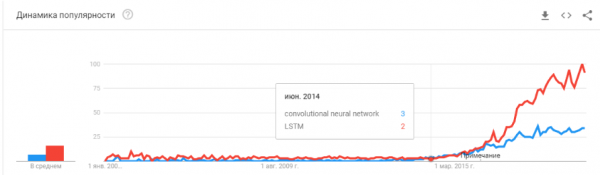
"Onko kupla puhjennut? Onko hype ylikuumentunut? Kuoliko he lohkoketjuna?"
Muuten! Huomenna Siri lakkaa toimimasta puhelimellasi, ja ylihuomenna Tesla ei tiedä eroa käännöksen ja kengurun välillä.
Neuroverkot toimivat jo. Niitä on kymmenissä laitteissa. Niiden avulla voit todella ansaita rahaa, muuttaa markkinoita ja maailmaa ympärilläsi. Hype näyttää hieman erilaiselta:
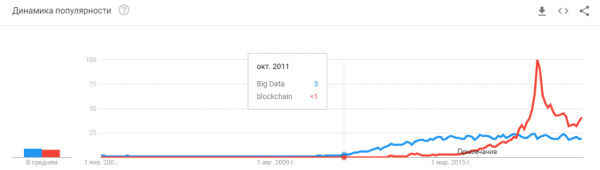
Se on vain, että neuroverkot eivät ole enää jotain uutta. Kyllä, monilla ihmisillä on korkeat odotukset. Mutta monet yritykset ovat oppineet käyttämään hermosoluja ja valmistamaan tuotteita niiden pohjalta. Neuronit tarjoavat uusia toimintoja, mahdollistavat työpaikkojen leikkaamisen ja alentaa palveluiden hintoja:
- Valmistusyritykset integroivat algoritmeja analysoidakseen vikoja tuotantolinjalla.
- Karjatilat ostavat järjestelmiä lehmien valvontaan.
- Automaattiset yhdistelmät.
- Automaattiset puhelinkeskukset.
- Suodattimet SnapChatissa. (No, ainakin jotain hyödyllistä!)
Mutta tärkein asia, eikä ilmeisin: "Uusia ideoita ei ole enää, tai ne eivät tuo välitöntä pääomaa." Neuroverkot ovat ratkaisseet kymmeniä ongelmia. Ja he päättävät vielä enemmän. Kaikki olemassa olevat ilmeiset ideat synnyttivät monia startupeja. Mutta kaikki, mikä oli pinnalla, oli jo kerätty. Kahden viime vuoden aikana en ole törmännyt yhtään uuteen ideaan hermoverkkojen käytöstä. Ei yhtään uutta lähestymistapaa (no, ok, GAN-verkoissa on muutamia ongelmia).
Ja jokainen seuraava käynnistys on entistä monimutkaisempi. Se ei enää vaadi kahta kaveria, jotka kouluttavat neuronia avoimen datan avulla. Se vaatii ohjelmoijia, palvelimen, merkkitiimin, monimutkaisen tuen jne.
Tämän seurauksena startup-yrityksiä on vähemmän. Mutta tuotantoa on enemmän. Tarvitseeko rekisterikilven tunnistusta lisätä? Markkinoilla on satoja asiantuntevia asiantuntijoita. Voit palkata jonkun ja parin kuukauden kuluttua työntekijäsi tekee järjestelmän. Tai ostaa valmiina. Mutta tehdä uusi startup?... Hullua!
Sinun on luotava vierailijoiden seurantajärjestelmä - miksi maksaa lisenssistä, kun voit tehdä oman 3-4 kuukaudessa, terävöittää sitä yrityksellesi.
Nyt neuroverkot käyvät läpi samaa polkua, jota kymmenet muut tekniikat ovat käyneet läpi.
Muistatko kuinka käsite "verkkosivustokehittäjä" on muuttunut vuodesta 1995? Markkinat eivät ole vielä täynnä asiantuntijoita. Ammattilaisia on todella vähän. Mutta voin lyödä vetoa, että 5-10 vuoden kuluttua Java-ohjelmoijan ja hermoverkkokehittäjän välillä ei ole paljon eroa. Molempia asiantuntijoita riittää markkinoille.
Tulee yksinkertaisesti joukko ongelmia, jotka neuronit voivat ratkaista. Tehtävä on syntynyt - palkkaa asiantuntija.
"Mitä seuraavaksi? Missä on luvattu tekoäly?"
Mutta tässä on pieni mutta mielenkiintoinen väärinkäsitys :)
Nykyinen teknologiapino ei ilmeisesti johda meitä tekoälyyn. Ideat ja niiden uutuus ovat pitkälti uuvuttaneet itsensä. Puhutaanpa siitä, mikä vallitsee nykyisen kehitystason.
Rajoitukset
Aloitetaan itseohjautuvista autoista. Näyttää selvältä, että täysin autonomisia autoja on mahdollista tehdä nykytekniikalla. Mutta kuinka monen vuoden kuluttua tämä tapahtuu, ei ole selvää. Tesla uskoo, että tämä tapahtuu parin vuoden sisällä -

On monia muitakin , jotka arvioivat sen olevan 5-10 vuotta.
Todennäköisimmin mielestäni 15 vuoden kuluttua kaupunkien infrastruktuuri muuttuu itse niin, että autonomisten autojen ilmaantumisesta tulee väistämätöntä ja siitä tulee sen jatkoa. Mutta tätä ei voida pitää älykkyytenä. Nykyaikainen Tesla on erittäin monimutkainen putki tietojen suodattamiseen, etsimiseen ja uudelleenkoulutukseen. Nämä ovat säännöt-säännöt-säännöt, tiedonkeruu ja suodattimet niiden päälle (täällä Kirjoitin tästä hieman enemmän tai katson merkit).
Ensimmäinen ongelma
Ja tässä me näemme ensimmäinen perusongelma. Suuri data. Juuri tästä syntyi nykyinen neuroverkkojen ja koneoppimisen aalto. Nykyään tarvitset paljon dataa tehdäksesi jotain monimutkaista ja automaattista. Ei vain paljon, vaan erittäin, erittäin paljon. Tarvitsemme automaattisia algoritmeja niiden keräämiseen, merkitsemiseen ja käyttöön. Haluamme saada auton näkemään kuorma-autot aurinkoon päin - niitä on ensin kerättävä riittävä määrä. Haluamme, että auto ei tule hulluksi takakonttiin pultatulla polkupyörällä - lisää näytteitä.
Lisäksi yksi esimerkki ei riitä. satoja? Tuhansia?

Toinen ongelma
Toinen ongelma - visualisointi siitä, mitä hermoverkkomme on ymmärtänyt. Tämä on erittäin ei-triviaali tehtävä. Tähän mennessä harvat ihmiset ymmärtävät, kuinka tämä visualisoidaan. Nämä artikkelit ovat hyvin tuoreita, nämä ovat vain muutamia esimerkkejä, vaikka ne ovat kaukana:
pakkomielle tekstuureihin. Se näyttää hyvin, mihin neuroni pyrkii kiinnittämään + mitä se näkee lähtötiedona.

Huomio klo . Itse asiassa vetovoimaa voidaan usein käyttää juuri sen osoittamiseen, mikä aiheutti tällaisen verkostoreaktion. Olen nähnyt tällaisia asioita sekä virheenkorjauksessa että tuoteratkaisuissa. Tästä aiheesta on paljon artikkeleita. Mutta mitä monimutkaisempi data on, sitä vaikeampaa on ymmärtää, kuinka vankka visualisointi saadaan aikaan.

No, kyllä, vanha kunnon sarja "katso, mitä verkon sisällä on " Nämä kuvat olivat suosittuja 3-4 vuotta sitten, mutta kaikki huomasivat nopeasti, että kuvat olivat kauniita, mutta niillä ei ollut paljon merkitystä.
En maininnut kymmeniä muita vempaimia, menetelmiä, hakkereita, tutkimuksia verkon sisäpuolen näyttämisestä. Toimivatko nämä työkalut? Auttavatko ne sinua nopeasti ymmärtämään ongelman ja korjaavatko verkkoa?... Saatko viimeiset prosenttiosuudet? No, se on suunnilleen sama:

Voit katsoa mitä tahansa kilpailua Kagglesta. Ja kuvaus siitä, kuinka ihmiset tekevät lopulliset päätökset. Pinoimme malleja 100-500-800 kappaletta ja se toimi!
Tietysti liioittelen. Mutta nämä lähestymistavat eivät tarjoa nopeita ja suoria vastauksia.
Riittävällä kokemuksella ja eri vaihtoehdoista pohdittuasi voit antaa tuomion siitä, miksi järjestelmäsi teki tällaisen päätöksen. Mutta järjestelmän käyttäytymistä on vaikea korjata. Asenna kainalosauva, siirrä kynnystä, lisää tietojoukko, ota toinen taustaverkko.
Kolmas ongelma
Kolmas perusongelma — ruudukot opettavat tilastoja, eivät logiikkaa. Tilastollisesti tämä :

Loogisesti se ei ole kovin samanlainen. Neuroverkot eivät opi mitään monimutkaista, elleivät ne ole pakotettuja. He opettavat aina yksinkertaisimpia mahdollisia merkkejä. Onko sinulla silmät, nenä, pää? Tämä on siis kasvot! Tai anna esimerkki, jossa silmät eivät tarkoita kasvoja. Ja jälleen - miljoonia esimerkkejä.
Alareunassa on paljon tilaa
Sanoisin, että juuri nämä kolme globaalia ongelmaa rajoittavat tällä hetkellä neuroverkkojen ja koneoppimisen kehitystä. Ja missä nämä ongelmat eivät rajoita sitä, sitä käytetään jo aktiivisesti.
Tämä on loppu? Ovatko hermoverkot toiminnassa?
Tuntematon. Mutta kaikki tietysti toivovat, että eivät.
Edellä korostamieni perusongelmien ratkaisemiseen on monia lähestymistapoja ja ohjeita. Mutta toistaiseksi mikään näistä lähestymistavoista ei ole tehnyt mahdolliseksi tehdä jotain täysin uutta, ratkaista jotain, jota ei ole vielä ratkaistu. Toistaiseksi kaikki perusprojektit tehdään vakaiden lähestymistapojen pohjalta (Tesla) tai jäävät instituuttien tai yritysten testiprojekteiksi (Google Brain, OpenAI).
Karkeasti sanottuna pääsuunta on luoda syöttötiedoista korkeatasoinen esitys. Tietyssä mielessä "muisti". Yksinkertaisin esimerkki muistista on erilaiset "Upotus" - kuvaesitykset. No, esimerkiksi kaikki kasvojentunnistusjärjestelmät. Verkko oppii saamaan kasvoilta vakaan esityksen, joka ei riipu pyörimisestä, valaistuksesta tai resoluutiosta. Pohjimmiltaan verkko minimoi mittarin "eri kasvot ovat kaukana" ja "identtiset kasvot ovat lähellä".
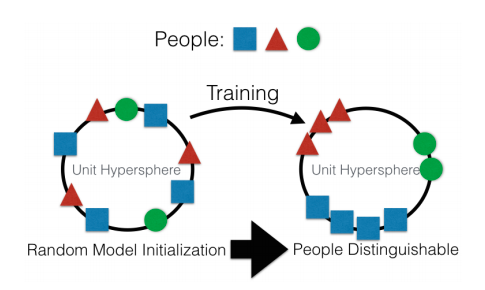
Tällaista koulutusta varten tarvitaan kymmeniä ja satoja tuhansia esimerkkejä. Mutta tulos kantaa joitain "One-shot Learningin" alkeita. Nyt emme tarvitse satoja kasvoja muistaaksemme henkilöä. Vain yhdet kasvot ja siinä kaikki olemme !
On vain yksi ongelma... Ruudukko voi oppia vain melko yksinkertaisia esineitä. Kun yrität erottaa kasvoja ei, vaan esimerkiksi "ihmisiä vaatteiden perusteella" (tehtävä ) - laatu heikkenee monta suuruusluokkaa. Ja verkko ei voi enää oppia melko ilmeisiä kulmien muutoksia.
Ja miljoonista esimerkeistä oppiminen on myös hauskaa.
Työtä on tehtävä vaalien vähentämiseksi merkittävästi. Esimerkiksi yksi ensimmäisistä teoksista voidaan heti muistaa OneShot-oppiminen :
Tällaisia teoksia on esimerkiksi monia tai tai .
On yksi miinus - yleensä harjoittelu toimii hyvin joissakin yksinkertaisissa "MNIST"-esimerkeissä. Ja kun siirryt monimutkaisiin tehtäviin, tarvitset suuren tietokannan, mallin esineistä tai jonkinlaisen taikuuden.
Yleensä One-Shot-koulutuksen parissa työskenteleminen on erittäin mielenkiintoinen aihe. Löydät paljon ideoita. Mutta suurimmaksi osaksi luetellut kaksi ongelmaa (valtavan tietojoukon esiharjoittelu / monimutkaisten tietojen epävakaus) häiritsevät suuresti oppimista.
Toisaalta GAN-verkot – generatiiviset vastakkainasettelut – lähestyvät upotuksen aihetta. Olet luultavasti lukenut joukon artikkeleita Habresta tästä aiheesta. (, ,)
GANin ominaisuus on jonkin sisäisen tila-avaruuden muodostaminen (olennaisesti sama Embedding), jonka avulla voit piirtää kuvan. Se voi olla , voi olla .
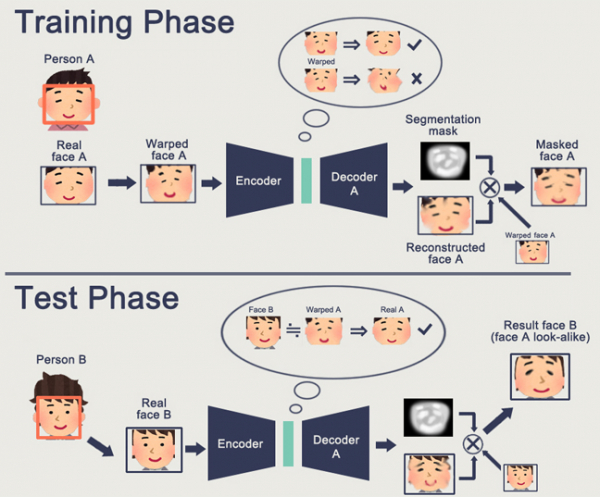
GAN:n ongelmana on, että mitä monimutkaisempi luotu objekti on, sitä vaikeampaa on kuvata sitä "generaattori-diskriminaattori" -logiikalla. Tämän seurauksena ainoat todelliset GAN-sovellukset, joista on kuultu, ovat DeepFake, joka taas manipuloi kasvojen esityksiä (joille on valtava perusta).
Olen nähnyt hyvin vähän muuta hyödyllistä käyttöä. Yleensä jonkinlainen temppu, johon liittyy kuvien piirustusten viimeistely.
Ja uudelleen. Kenelläkään ei ole aavistustakaan, kuinka tämä antaa meille mahdollisuuden siirtyä valoisampaan tulevaisuuteen. Logiikan/avaruuden esittäminen hermoverkossa on hyvä asia. Mutta tarvitsemme valtavan määrän esimerkkejä, emme ymmärrä, kuinka hermosolu edustaa tätä itsessään, emme ymmärrä kuinka saada neuroni muistamaan todella monimutkainen idea.
Vahvistusoppiminen - Tämä on lähestymistapa täysin eri suunnasta. Muistat varmasti, kuinka Google voitti kaikki Gossa. Viimeaikaiset voitot Starcraftissa ja Dotassa. Mutta täällä kaikki ei ole kaikkea muuta kuin ruusuista ja lupaavaa. Hän puhuu parhaiten RL:stä ja sen monimutkaisuudesta .
Lyhyesti, mitä kirjoittaja kirjoitti:
- Paketista valmistetut mallit eivät sovi / toimivat huonosti useimmissa tapauksissa
- Käytännön ongelmat on helpompi ratkaista muilla tavoilla. Boston Dynamics ei käytä RL:ää sen monimutkaisuuden/ennustamattomuuden/laskennan monimutkaisuuden vuoksi
- Jotta RL toimisi, tarvitset monimutkaisen funktion. Sen luominen/kirjoittaminen on usein vaikeaa
- Malleja on vaikea kouluttaa. Sinun täytyy viettää paljon aikaa pumppaamiseen ja päästäksesi eroon paikallisesta optimaalisuudesta
- Tästä johtuen mallia on vaikea toistaa, malli on epävakaa pienimmilläkin muutoksilla
- Usein ylisopivat joitakin satunnaiskuvioita, jopa satunnaislukugeneraattorin
Keskeistä on, että RL ei vielä toimi tuotannossa. Googlella on joitain kokeiluja ( , ). Mutta en ole nähnyt yhtä tuotejärjestelmää.
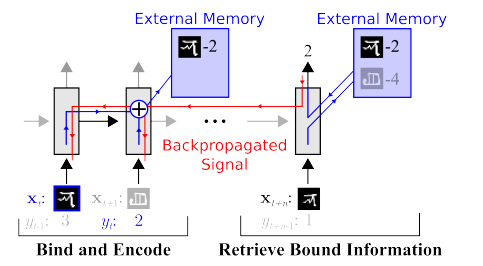
Muisti. Kaiken edellä kuvatun haittapuolena on rakenteen puute. Yksi tapa yrittää siivota tätä kaikkea on tarjota hermoverkolle pääsy erilliseen muistiin. Jotta hän voi tallentaa ja kirjoittaa uudelleen askeleidensa tulokset sinne. Sitten hermoverkko voidaan määrittää nykyisen muistin tilan perusteella. Tämä on hyvin samanlainen kuin klassiset prosessorit ja tietokoneet.
Tunnetuin ja suosituin - DeepMindistä:
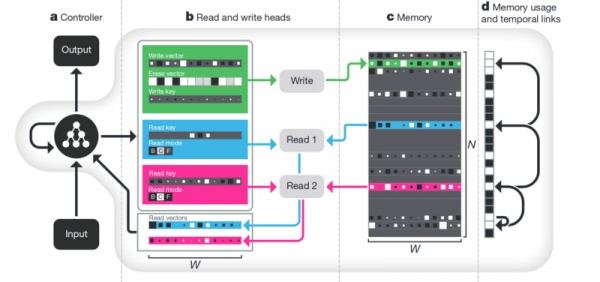
Näyttää siltä, että tämä on avain älykkyyden ymmärtämiseen? Mutta luultavasti ei. Järjestelmä vaatii edelleen valtavan määrän dataa harjoitteluun. Ja se toimii pääasiassa strukturoidun taulukkotiedon kanssa. Lisäksi kun Facebook samanlaisen ongelman, sitten he valitsivat polun "väänä muisti, tee neuronista monimutkaisempi ja saa lisää esimerkkejä - ja se oppii itsestään."
Irrottaminen. Toinen tapa luoda mielekästä muistia on ottaa samat upotukset, mutta harjoituksen aikana ottaa käyttöön lisäkriteerejä, joiden avulla voit korostaa niissä olevia "merkityksiä". Haluamme esimerkiksi kouluttaa hermoverkkoa erottamaan ihmisten käyttäytymisen kaupassa. Jos seuraisimme standardipolkua, meidän olisi tehtävä tusina verkkoa. Toinen etsii henkilöä, toinen määrittelee, mitä hän tekee, kolmas on hänen ikänsä, neljäs on hänen sukupuolensa. Erillinen logiikka tarkastelee sitä kaupan osaa, jossa se tekee/on koulutettu tähän. Kolmas määrittää sen liikeradan jne.
Tai jos dataa olisi ääretön määrä, niin yksi verkko olisi mahdollista kouluttaa kaikkiin mahdollisiin tuloksiin (ilmeisesti tällaista datajoukkoa ei voida kerätä).
Irrotuslähestymistapa kertoo meille - koulutetaan verkostoa niin, että se pystyy itse erottamaan käsitteet. Jotta se muodostaisi videon pohjalta upotteen, jossa yksi alue määrittäisi toiminnan, määrittäisi asento lattialla ajoissa, määrittäisi henkilön pituus ja määrittäisi henkilön sukupuolen. Samaan aikaan koulutuksessa haluaisin lähes olematta kannustamassa verkostoa tällaisilla keskeisillä käsitteillä, vaan sen korostamaan ja ryhmittelemään alueita. Tällaisia artikkeleita on melko vähän (jotkut niistä , , ) ja yleensä ne ovat melko teoreettisia.
Mutta tämän suunnan pitäisi ainakin teoreettisesti kattaa alussa luetellut ongelmat.
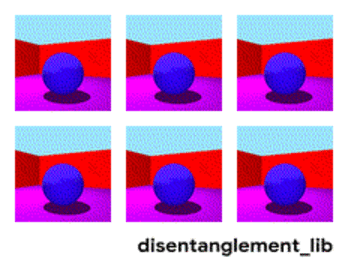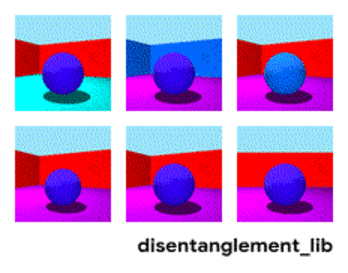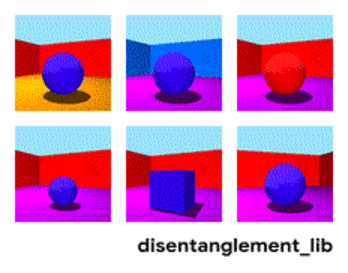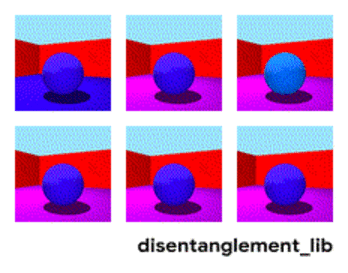
Kuvan jakautuminen parametrien "seinän väri/lattian väri/objektin muoto/objektin väri/jne mukaan" mukaan.

Kasvojen hajoaminen parametrien "koko, kulmakarvat, suunta, ihonväri jne." mukaan.
Muut
On monia muita, ei niin globaaleja alueita, joiden avulla voit jollakin tavalla pienentää tietokantaa, työskennellä heterogeenisempien tietojen kanssa jne.
Huomio. Ei luultavasti ole järkevää erottaa tätä erilliseksi menetelmäksi. Vain lähestymistapa, joka parantaa muita. Hänelle on omistettu monia artikkeleita (,,). Tarkoituksena on tehostaa verkon vastetta erityisesti merkittäviin esineisiin harjoituksen aikana. Usein jonkinlaisen ulkoisen kohdemerkinnän tai pienen ulkoisen verkon perusteella.
3D-simulaatio. Jos tekee hyvän 3D-moottorin, sillä voi usein peittää 90% harjoitustiedoista (näin jopa esimerkin, jossa lähes 99% tiedoista oli hyvällä moottorilla). On olemassa monia ideoita ja hakkereita, kuinka saada 3D-moottorilla koulutettu verkko toimimaan todellista dataa käyttäen (hienosäätö, tyylinsiirto jne.). Mutta usein hyvän moottorin tekeminen on useita suuruusluokkaa vaikeampaa kuin tiedon kerääminen. Esimerkkejä moottoreiden valmistamisesta:
Robottikoulutus (, )
Opetus tavarat kaupassa (mutta kahdessa tekemässämme projektissa pärjäsimme helposti ilman sitä).
Treenit Teslassa (taas video yllä).
Tulokset
Koko artikkeli on tietyssä mielessä johtopäätöksiä. Luultavasti tärkein viesti, jonka halusin tehdä, oli "ilmaistarjoukset ovat ohi, neuronit eivät enää tarjoa yksinkertaisia ratkaisuja." Nyt meidän on tehtävä lujasti töitä tehdäksemme monimutkaisia päätöksiä. Tai työskentele lujasti tekemällä monimutkaista tieteellistä tutkimusta.
Yleisesti ottaen aihe on kiistanalainen. Ehkä lukijoilla on mielenkiintoisempia esimerkkejä?
Lähde: will.com
