


Je m'appelle Denis Rozhkov, je suis responsable du développement logiciel chez Gazinformservice, dans l'équipe produit . La législation et les réglementations des entreprises imposent certaines exigences en matière de sécurité du stockage des données. Personne ne souhaite que des tiers aient accès à des informations confidentielles, c'est pourquoi les questions suivantes sont importantes pour tout projet : identification et authentification, gestion de l'accès aux données, garantie de l'intégrité des informations dans le système, journalisation des événements de sécurité. Par conséquent, je souhaite parler de quelques points intéressants concernant la sécurité du SGBD.
L'article a été préparé sur la base d'un discours prononcé à organisé . Si vous ne voulez pas lire, vous pouvez regarder :

L'article comportera trois parties :
- Comment sécuriser les connexions.
- Qu'est-ce qu'un audit des actions et comment enregistrer ce qui se passe côté base de données et s'y connecter.
- Comment protéger les données dans la base de données elle-même et quelles technologies sont disponibles pour cela.
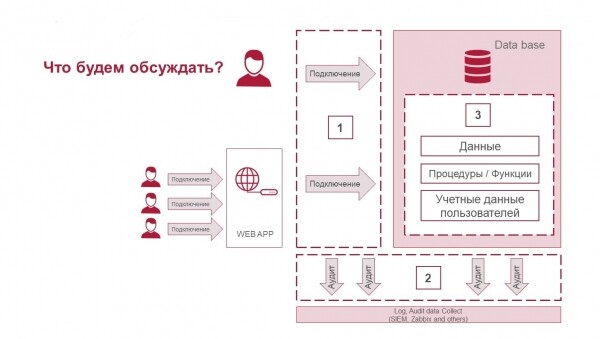
Trois composants de sécurité du SGBD : protection des connexions, audit des activités et protection des données
Sécuriser vos connexions
Vous pouvez vous connecter à la base de données directement ou indirectement via des applications Web. En règle générale, l'utilisateur professionnel, c'est-à-dire la personne qui travaille avec le SGBD, interagit indirectement avec celui-ci.
Avant de parler de protection des connexions, vous devez répondre à des questions importantes qui déterminent la manière dont les mesures de sécurité seront structurées :
- Un utilisateur professionnel équivaut-il à un utilisateur de SGBD ?
- si l'accès aux données du SGBD est fourni uniquement via une API que vous contrôlez, ou si les tables sont accessibles directement ;
- si le SGBD est attribué à un segment protégé distinct, qui interagit avec lui et comment ;
- si les couches de pooling/proxy et intermédiaires sont utilisées, ce qui peut modifier les informations sur la façon dont la connexion est établie et qui utilise la base de données.
Voyons maintenant quels outils peuvent être utilisés pour sécuriser les connexions :
- Utilisez des solutions de classe de pare-feu de base de données. Une couche de protection supplémentaire augmentera, au minimum, la transparence de ce qui se passe dans le SGBD et, au maximum, vous pourrez fournir une protection supplémentaire des données.
- Utilisez des politiques de mot de passe. Leur utilisation dépend de la manière dont votre architecture est construite. Dans tous les cas, un mot de passe dans le fichier de configuration d'une application web qui se connecte au SGBD ne suffit pas pour la protection. Il existe un certain nombre d'outils SGBD qui vous permettent de contrôler que l'utilisateur et le mot de passe nécessitent une mise à jour.
Vous pouvez en savoir plus sur les fonctions d'évaluation des utilisateurs , vous pouvez également vous renseigner sur les évaluateurs de vulnérabilités MS SQL .
- Enrichissez le contexte de la séance avec les informations nécessaires. Si la session est opaque, vous ne comprenez pas qui travaille dans le SGBD dans son cadre, vous pouvez, dans le cadre de l'opération en cours, ajouter des informations sur qui fait quoi et pourquoi. Ces informations sont visibles dans l'audit.
- Configurez SSL si vous n'avez pas de séparation réseau entre le SGBD et les utilisateurs finaux ; il ne se trouve pas dans un VLAN distinct. Dans de tels cas, il est impératif de protéger le canal entre le consommateur et le SGBD lui-même. Des outils de sécurité sont également disponibles en open source.
Comment cela affectera-t-il les performances du SGBD ?
Regardons l'exemple de PostgreSQL pour voir comment SSL affecte la charge du processeur, augmente les timings et diminue le TPS, et s'il consommera trop de ressources si vous l'activez.
Charger PostgreSQL à l'aide de pgbench est un programme simple permettant d'exécuter des tests de performances. Il exécute une seule séquence de commandes de manière répétée, éventuellement lors de sessions de base de données parallèles, puis calcule le taux de transaction moyen.
Test 1 sans SSL et en utilisant SSL — la connexion est établie pour chaque transaction :
pgbench.exe --connect -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres sslmode=require
sslrootcert=rootCA.crt sslcert=client.crt sslkey=client.key"vs
pgbench.exe --connect -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres"Test 2 sans SSL et en utilisant SSL — toutes les transactions sont effectuées en une seule connexion :
pgbench.exe -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres sslmode=require
sslrootcert=rootCA.crt sslcert=client.crt sslkey=client.key"vs
pgbench.exe -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres"Autres réglages:
scaling factor: 1
query mode: simple
number of clients: 10
number of threads: 1
number of transactions per client: 5000
number of transactions actually processed: 50000/50000Résultats de test:
PAS DE SSL
SSL
Une connexion est établie pour chaque transaction
latence moyenne
171.915 ms
187.695 ms
tps incluant l'établissement des connexions
58.168112
53.278062
tps hors établissement de connexions
64.084546
58.725846
Processeur
24 %
28 %
Toutes les transactions sont effectuées en une seule connexion
latence moyenne
6.722 ms
6.342 ms
tps incluant l'établissement des connexions
1587.657278
1576.792883
tps hors établissement de connexions
1588.380574
1577.694766
Processeur
17 %
21 %
À faibles charges, l'influence du SSL est comparable à l'erreur de mesure. Si la quantité de données transférées est très importante, la situation peut être différente. Si on établit une connexion par transaction (c'est rare, généralement la connexion est partagée entre utilisateurs), vous avez un grand nombre de connexions/déconnexions, l'impact peut être un peu plus important. Autrement dit, il peut y avoir des risques de diminution des performances, mais la différence n'est pas si grande que de ne pas utiliser de protection.
Attention, il y a une forte différence si vous comparez les modes de fonctionnement : vous travaillez au sein de la même session ou dans des sessions différentes. C'est compréhensible : des ressources sont dépensées pour créer chaque connexion.
Nous avons eu un cas où nous avons connecté Zabbix en mode confiance, c'est-à-dire que md5 n'a pas été vérifié, il n'y avait pas besoin d'authentification. Ensuite, le client a demandé d'activer le mode d'authentification md5. Cela mettait une lourde charge sur le processeur et les performances diminuaient. Nous avons commencé à chercher des moyens d'optimiser. L'une des solutions possibles au problème consiste à implémenter des restrictions de réseau, à créer des VLAN séparés pour le SGBD, à ajouter des paramètres pour indiquer clairement qui se connecte d'où et à supprimer l'authentification. Vous pouvez également optimiser les paramètres d'authentification pour réduire les coûts lors de l'activation de l'authentification, mais en général, l'utilisation de différentes méthodes d'authentification affecte les performances et nécessite de prendre en compte ces facteurs lors de la conception de la puissance de calcul des serveurs (matériel) pour le SGBD.
Conclusion : dans un certain nombre de solutions, même de petites nuances d'authentification peuvent grandement affecter le projet et c'est mauvais lorsque cela ne devient clair qu'une fois mis en œuvre en production.
Audit des actions
L'audit ne peut pas être seulement un SGBD. Un audit consiste à obtenir des informations sur ce qui se passe dans différents segments. Il peut s'agir soit d'un pare-feu de base de données, soit du système d'exploitation sur lequel le SGBD est construit.
Dans les SGBD commerciaux au niveau de l'entreprise, tout va bien avec l'audit, mais en open source - pas toujours. Voici ce que PostgreSQL propose :
- journal par défaut - journalisation intégrée ;
- extensions : pgaudit - si la journalisation par défaut ne vous suffit pas, vous pouvez utiliser des paramètres distincts qui résolvent certains problèmes.
Ajout au reportage dans la vidéo :
"La journalisation des instructions de base peut être fournie par une fonction de journalisation standard avec log_statement = all.
Ceci est acceptable pour la surveillance et d’autres utilisations, mais ne fournit pas le niveau de détail généralement requis pour l’audit.
Il ne suffit pas d'avoir une liste de toutes les opérations effectuées sur la base de données.
Il devrait également être possible de trouver des déclarations spécifiques qui intéressent l'auditeur.
La journalisation standard montre ce que l'utilisateur a demandé, tandis que pgAudit se concentre sur les détails de ce qui s'est passé lorsque la base de données a exécuté la requête.
Par exemple, l'auditeur peut vouloir vérifier qu'une table particulière a été créée dans une fenêtre de maintenance documentée.
Cela peut sembler une tâche simple avec un audit et grep de base, mais que se passerait-il si on vous présentait quelque chose comme cet exemple (intentionnellement déroutant) :
FAIRE$$
COMMENCER
EXÉCUTER 'CRÉER une importation de TABLE' || 'ant_table(id int)';
FIN$$ ;
La journalisation standard vous donnera ceci :
LOG : instruction : FAIRE $$
COMMENCER
EXÉCUTER 'CRÉER une importation de TABLE' || 'ant_table(id int)';
FIN$$ ;
Il semble que trouver la table qui vous intéresse peut nécessiter certaines connaissances en code dans les cas où les tables sont créées dynamiquement.
Ce n’est pas idéal, car il serait préférable d’effectuer simplement une recherche par nom de table.
C'est là que pgAudit s'avère utile.
Pour la même entrée, il produira cette sortie dans le journal :
AUDIT : SESSION,33,1,FONCTION,DO,,,"DO $$
COMMENCER
EXÉCUTER 'CRÉER une importation de TABLE' || 'ant_table(id int)';
FIN$$;"
AUDIT : SESSION,33,2,DDL,CREATE TABLE,TABLE,public.important_table,CREATE TABLE important_table (id INT)
Non seulement le bloc DO est enregistré, mais également le texte intégral de CREATE TABLE avec le type d'instruction, le type d'objet et le nom complet, ce qui facilite la recherche.
Lors de la journalisation des instructions SELECT et DML, pgAudit peut être configuré pour enregistrer une entrée distincte pour chaque relation référencée dans l'instruction.
Aucune analyse n'est requise pour trouver toutes les instructions qui touchent une table particulière (). "
Comment cela affectera-t-il les performances du SGBD ?
Exécutons des tests avec l'audit complet activé et voyons ce qui arrive aux performances de PostgreSQL. Activons la journalisation maximale de la base de données pour tous les paramètres.
On ne change quasiment rien dans le fichier de configuration, le plus important est d'activer le mode debug5 pour obtenir un maximum d'informations.
postgresql.conf
log_destination = 'stderr'
logging_collector = activé
log_truncate_on_rotation = activé
log_rotation_age = 1j
log_rotation_size = 10 Mo
log_min_messages = débogage5
log_min_error_statement = débogage5
log_min_duration_statement = 0
debug_print_parse = activé
debug_print_rewrite = activé
debug_print_plan = activé
debug_pretty_print = activé
log_checkpoints = activé
log_connections = activé
log_disconnections = activé
log_duration = activé
log_hostname = activé
log_lock_waits = activé
log_replication_commands = activé
log_temp_files = 0
log_timezone = 'Europe/Moscou'
Sur un SGBD PostgreSQL avec des paramètres de 1 CPU, 2,8 GHz, 2 Go de RAM, 40 Go de disque dur, nous effectuons trois tests de charge à l'aide des commandes :
$ pgbench -p 3389 -U postgres -i -s 150 benchmark
$ pgbench -p 3389 -U postgres -c 50 -j 2 -P 60 -T 600 benchmark
$ pgbench -p 3389 -U postgres -c 150 -j 2 -P 60 -T 600 benchmarkRésultats de test:
Pas de journalisation
Avec journalisation
Temps total de remplissage de la base de données
43,74 sec
53,23 sec
vol
24 %
40 %
Processeur
72 %
91 %
Test 1 (50 connexions)
Nombre de transactions en 10 minutes
74169
32445
Transactions/s
123
54
Latence moyenne
405 ms
925 ms
Test 2 (150 connexions dont 100 possibles)
Nombre de transactions en 10 minutes
81727
31429
Transactions/s
136
52
Latence moyenne
550 ms
1432 ms
À propos des tailles
Taille de la base de données
2251 MB
2262 MB
Taille du journal de base de données
0 MB
4587 MB
En résumé : un audit complet n’est pas très bon. Les données de l'audit seront aussi volumineuses que les données de la base de données elle-même, voire plus. La quantité de journalisation générée lorsque vous travaillez avec un SGBD est un problème courant en production.
Regardons d'autres paramètres :
- La vitesse ne change pas beaucoup : sans journalisation - 43,74 secondes, avec journalisation - 53,23 secondes.
- Les performances de la RAM et du processeur en souffriront, car vous devrez générer un fichier d'audit. Cela se remarque également en termes de productivité.
À mesure que le nombre de connexions augmente, les performances se détérioreront naturellement légèrement.
Dans les entreprises avec audit, c'est encore plus difficile :
- il y a beaucoup de données ;
- l'audit est nécessaire non seulement via syslog dans SIEM, mais également dans les fichiers : si quelque chose arrive à syslog, il doit y avoir un fichier proche de la base de données dans laquelle les données sont enregistrées ;
- une étagère séparée est nécessaire pour l'audit afin de ne pas gaspiller de disques d'E/S, car cela prend beaucoup de place ;
- Il arrive que les employés chargés de la sécurité de l'information aient besoin des normes GOST partout, ils ont besoin d'une identification par l'État.
Restreindre l'accès aux données
Examinons les technologies utilisées pour protéger les données et y accéder dans les SGBD commerciaux et open source.
Que pouvez-vous généralement utiliser :
- Cryptage et obscurcissement des procédures et des fonctions (Wrapping) - c'est-à-dire des outils et utilitaires distincts qui rendent illisible le code lisible. C'est vrai, alors il ne peut être ni modifié ni refactorisé. Cette approche est parfois requise au moins du côté du SGBD - la logique des restrictions de licence ou la logique d'autorisation est cryptée précisément au niveau de la procédure et de la fonction.
- La limitation de la visibilité des données par lignes (RLS) se produit lorsque différents utilisateurs voient une table, mais une composition différente de lignes, c'est-à-dire que quelque chose ne peut pas être montré à quelqu'un au niveau de la ligne.
- La modification des données affichées (masquage) se produit lorsque les utilisateurs d'une colonne du tableau voient soit des données, soit uniquement des astérisques, c'est-à-dire que pour certains utilisateurs, les informations seront fermées. La technologie détermine quel utilisateur voit quoi en fonction de son niveau d'accès.
- Le contrôle d'accès de sécurité DBA/Application DBA/DBA consiste plutôt à restreindre l'accès au SGBD lui-même, c'est-à-dire que les employés chargés de la sécurité des informations peuvent être séparés des administrateurs de bases de données et des administrateurs d'applications. Il existe peu de technologies de ce type en open source, mais elles sont nombreuses dans les SGBD commerciaux. Ils sont nécessaires lorsque de nombreux utilisateurs ont accès aux serveurs eux-mêmes.
- Restreindre l'accès aux fichiers au niveau du système de fichiers. Vous pouvez accorder des droits et privilèges d'accès aux répertoires afin que chaque administrateur ait accès uniquement aux données nécessaires.
- Accès obligatoire et effacement de la mémoire - ces technologies sont rarement utilisées.
- Le chiffrement de bout en bout directement à partir du SGBD est un chiffrement côté client avec gestion des clés côté serveur.
- Cryptage des données. Par exemple, le chiffrement en colonnes consiste à utiliser un mécanisme qui chiffre une seule colonne de la base de données.
Comment cela affecte-t-il les performances du SGBD ?
Regardons l'exemple du chiffrement en colonnes dans PostgreSQL. Il existe un module pgcrypto, il permet de stocker les champs sélectionnés sous forme cryptée. Ceci est utile lorsque seules certaines données sont utiles. Pour lire les champs chiffrés, le client transmet une clé de déchiffrement, le serveur décrypte les données et les renvoie au client. Sans la clé, personne ne peut rien faire avec vos données.
Testons avec pgcrypto. Créons une table avec des données cryptées et des données régulières. Vous trouverez ci-dessous les commandes pour créer des tables, dans la toute première ligne se trouve une commande utile - créer l'extension elle-même avec l'enregistrement du SGBD :
CREATE EXTENSION pgcrypto;
CREATE TABLE t1 (id integer, text1 text, text2 text);
CREATE TABLE t2 (id integer, text1 bytea, text2 bytea);
INSERT INTO t1 (id, text1, text2)
VALUES (generate_series(1,10000000), generate_series(1,10000000)::text, generate_series(1,10000000)::text);
INSERT INTO t2 (id, text1, text2) VALUES (
generate_series(1,10000000),
encrypt(cast(generate_series(1,10000000) AS text)::bytea, 'key'::bytea, 'bf'),
encrypt(cast(generate_series(1,10000000) AS text)::bytea, 'key'::bytea, 'bf'));Essayons ensuite de créer un échantillon de données de chaque table et d'examiner les délais d'exécution.
Sélection dans un tableau sans fonction de cryptage:
psql -c "timing" -c "select * from t1 limit 1000;" "host=192.168.220.129 dbname=taskdb
user=postgres sslmode=disable" > 1.txtLe chronomètre est allumé.
identifiant | texte1 | texte2
——+——-+——-
1 | 1 | 1
2 | 2 | 2
3 | 3 | 3
...
997 | 997 | 997
998 | 998 | 998
999 | 999 | 999
1000 | 1000 | 1000
(1000 lignes)
Temps : 1,386 ms
Sélection dans un tableau avec fonction de cryptage :
psql -c "timing" -c "select id, decrypt(text1, 'key'::bytea, 'bf'),
decrypt(text2, 'key'::bytea, 'bf') from t2 limit 1000;"
"host=192.168.220.129 dbname=taskdb user=postgres sslmode=disable" > 2.txtLe chronomètre est allumé.
identifiant | décrypter | décrypter
——+—————+————
1 | x31 | x31
2 | x32 | x32
3 | x33 | x33
...
999 | x393939 | x393939
1000 | x31303030 | x31303030
(1000 lignes)
Temps : 50,203 ms
Résultats de test:
Sans cryptage
Pgcrypto (décrypter)
Échantillon de 1000 XNUMX lignes
1,386 ms
50,203 ms
Processeur
15 %
35 %
vol
+ 5%
Le chiffrement a un impact important sur les performances. On peut constater que le délai a augmenté, car les opérations de décryptage des données cryptées (et le décryptage est généralement encore intégré dans votre logique) nécessitent des ressources importantes. Autrement dit, l'idée de chiffrer toutes les colonnes contenant certaines données entraîne une diminution des performances.
Cependant, le chiffrement n’est pas une solution miracle qui résoudra tous les problèmes. Les données décryptées et la clé de décryptage pendant le processus de décryptage et de transmission des données se trouvent sur le serveur. Par conséquent, les clés peuvent être interceptées par une personne disposant d'un accès complet au serveur de base de données, comme un administrateur système.
Lorsqu'il existe une clé pour toute la colonne pour tous les utilisateurs (même si ce n'est pas pour tous, mais pour les clients d'un ensemble limité), ce n'est pas toujours bon et correct. C'est pourquoi ils ont commencé à effectuer un chiffrement de bout en bout, dans le SGBD, ils ont commencé à envisager des options de chiffrement des données côté client et serveur, et ces mêmes stockages de coffre-fort de clés sont apparus - des produits distincts qui assurent la gestion des clés sur le SGBD. côté.

Fonctionnalités de sécurité dans les SGBD commerciaux et open source
fonctions
type
Politique de mot de passe
Audit
Protéger le code source des procédures et fonctions
RLS
Chiffrement
Oracle
commercial
+
+
+
+
+
MsSQL
commercial
+
+
+
+
+
commercial
+
+
+
+
extensions
PostgreSQL
Gratuit
extensions
extensions
-
+
extensions
MongoDB
Gratuit
-
+
-
-
Disponible uniquement dans MongoDB Enterprise
Le tableau est loin d'être complet, mais la situation est la suivante : dans les produits commerciaux, les problèmes de sécurité sont résolus depuis longtemps, dans l'open source, en règle générale, certains modules complémentaires sont utilisés pour la sécurité, de nombreuses fonctions manquent , il faut parfois ajouter quelque chose. Par exemple, les politiques de mot de passe - PostgreSQL a de nombreuses extensions différentes (, , , , ), qui mettent en œuvre des politiques de mots de passe, mais, à mon avis, aucune d'entre elles ne couvre tous les besoins du segment des entreprises nationales.
Que faire si vous n’avez ce dont vous avez besoin nulle part? Par exemple, vous souhaitez utiliser un SGBD spécifique qui ne possède pas les fonctions requises par le client.
Vous pouvez ensuite utiliser des solutions tierces qui fonctionnent avec différents SGBD, par exemple Crypto DB ou Garda DB. Si nous parlons de solutions du segment national, ils connaissent mieux les GOST que l'open source.
La deuxième option consiste à écrire vous-même ce dont vous avez besoin, à mettre en œuvre l'accès aux données et le cryptage dans l'application au niveau de la procédure. Certes, ce sera plus difficile avec GOST. Mais en général, vous pouvez masquer les données selon vos besoins, les mettre dans un SGBD, puis les récupérer et les déchiffrer selon vos besoins, directement au niveau de l'application. Dans le même temps, réfléchissez immédiatement à la manière dont vous protégerez ces algorithmes dans l'application. À notre avis, cela devrait être fait au niveau du SGBD, car cela fonctionnera plus rapidement.
Ce rapport a été présenté pour la première fois à par Mail.ru Cloud Solutions. Regarderd'autres performances et abonnez-vous aux annonces d'événements sur Telegram .
Quoi d'autre à lire sur le sujet:
- .
- .
Source: habr.com
