

Ce n'est même pas une blague, il semble que cette image particulière reflète le plus fidèlement l'essence de ces bases de données, et à la fin, on comprendra pourquoi :

Selon DB-Engines Ranking, les deux bases de données en colonnes NoSQL les plus populaires sont Cassandra (ci-après CS) et HBase (HB).
Par la volonté du destin, notre équipe de gestion du chargement des données à la Sberbank a déjà et travaille en étroite collaboration avec HB. Pendant ce temps, nous avons assez bien étudié ses forces et ses faiblesses et avons appris à le cuisiner. Cependant, la présence d'une alternative sous forme de CS nous a toujours obligé à nous tourmenter un peu de doutes : avons-nous fait le bon choix ? De plus, les résultats , réalisé par DataStax, ils ont déclaré que CS battait facilement HB avec un score presque écrasant. D’un autre côté, DataStax est une partie intéressée et vous ne devriez pas les croire sur parole. Nous avons également été déconcertés par le peu d'informations sur les conditions de test, nous avons donc décidé de découvrir par nous-mêmes qui est le roi du BigData NoSql, et les résultats obtenus se sont avérés très intéressants.
Cependant, avant de passer aux résultats des tests réalisés, il est nécessaire de décrire les aspects significatifs des configurations de l’environnement. Le fait est que CS peut être utilisé dans un mode qui permet la perte de données. Ceux. c'est lorsqu'un seul serveur (nœud) est responsable des données d'une certaine clé, et si pour une raison quelconque il échoue, la valeur de cette clé sera perdue. Pour de nombreuses tâches, cela n’est pas critique, mais pour le secteur bancaire, c’est plutôt l’exception que la règle. Dans notre cas, il est important de disposer de plusieurs copies des données pour un stockage fiable.
Par conséquent, seul le mode de fonctionnement CS en mode triple réplication a été considéré, c'est-à-dire La création du casespace a été réalisée avec les paramètres suivants :
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}; Ensuite, il existe deux manières de garantir le niveau de cohérence requis. Règle générale:
NO + NR > RF
Ce qui signifie que le nombre de confirmations des nœuds lors de l'écriture (NW) plus le nombre de confirmations des nœuds lors de la lecture (NR) doivent être supérieurs au facteur de réplication. Dans notre cas, RF = 3, ce qui signifie que les options suivantes conviennent :
2 + 2> 3
3 + 1> 3
Comme il est fondamentalement important pour nous de stocker les données de la manière la plus fiable possible, le schéma 3+1 a été choisi. De plus, HB fonctionne sur un principe similaire, c'est-à-dire une telle comparaison sera plus juste.
Il convient de noter que DataStax a fait le contraire dans son étude, ils ont fixé RF = 1 pour CS et HB (pour ce dernier en modifiant les paramètres HDFS). C'est un aspect très important car l'impact sur les performances du CS dans ce cas est énorme. Par exemple, l'image ci-dessous montre l'augmentation du temps nécessaire pour charger les données dans CS :
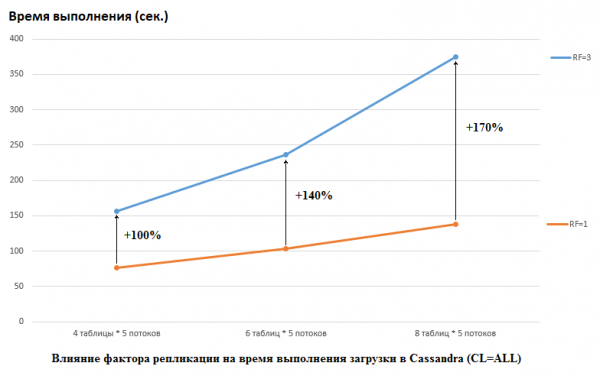
Ici, nous voyons ce qui suit : plus les threads concurrents écrivent des données, plus cela prend de temps. C'est naturel, mais il est important que la dégradation des performances pour RF=3 soit nettement plus élevée. En d'autres termes, si nous écrivons 4 threads dans 5 tables chacun (20 au total), alors RF=3 perd environ 2 fois (150 secondes pour RF=3 contre 75 pour RF=1). Mais si nous augmentons la charge en chargeant les données dans 8 tables de 5 threads chacune (40 au total), alors la perte de RF=3 est déjà 2,7 fois (375 secondes contre 138).
C'est peut-être en partie le secret du succès des tests de charge effectués par DataStax pour CS, car pour HB, sur notre stand, le changement du facteur de réplication de 2 à 3 n'a eu aucun effet. Ceux. les disques ne sont pas le goulot d'étranglement HB pour notre configuration. Cependant, il y a ici bien d'autres écueils, car il faut savoir que notre version de HB a été légèrement patchée et peaufinée, les environnements sont complètement différents, etc. Il convient également de noter que je ne sais peut-être tout simplement pas comment préparer correctement CS et qu'il existe des moyens plus efficaces de travailler avec, et j'espère que nous le découvrirons dans les commentaires. Mais tout d’abord.
Tous les tests ont été effectués sur un cluster matériel composé de 4 serveurs, chacun avec la configuration suivante :
Processeur : Xeon E5-2680 v4 à 2.40 GHz 64 threads.
Disques : 12 disques durs SATA
version Java : 1.8.0_111
Version CS : 3.11.5
Paramètres cassandra.ymlnum_tokens : 256
hinted_handoff_enabled : vrai
hinted_handoff_throttle_in_kb : 1024
max_hints_delivery_threads : 2
répertoire_indices : /data10/cassandra/indices
conseils_flush_period_in_ms : 10000 XNUMX
max_hints_file_size_in_mb : 128
batchlog_replay_throttle_in_kb : 1024
authentificateur : AllowAllAuthenticator
autorisateur : AllowAllAuthorizer
role_manager : CassandraRoleManager
rôles_validité_in_ms : 2000
permissions_validity_in_ms : 2000
qualifications_validity_in_ms : 2000
partitionneur : org.apache.cassandra.dht.Murmur3Partitioner
répertoires_fichier_données :
- /data1/cassandra/data # chaque répertoire dataN est un disque séparé
- /data2/cassandra/data
- /data3/cassandra/data
- /data4/cassandra/data
- /data5/cassandra/data
- /data6/cassandra/data
- /data7/cassandra/data
- /data8/cassandra/data
répertoire_commitlog : /data9/cassandra/commitlog
cdc_enabled : faux
disk_failure_policy : arrêter
commit_failure_policy : arrêter
préparé_statements_cache_size_mb :
thrift_prepared_statements_cache_size_mb :
key_cache_size_in_mb :
key_cache_save_period: 14400
row_cache_size_in_mb : 0
row_cache_save_period : 0
counter_cache_size_in_mb :
counter_cache_save_period: 7200
répertoire_caches_sauvé : /data10/cassandra/saved_caches
commitlog_sync : périodique
commitlog_sync_period_in_ms : 10000 XNUMX
commitlog_segment_size_in_mb : 32
fournisseur_seed :
- nom_classe : org.apache.cassandra.locator.SimpleSeedProvider
paramètres:
- graines: "*,*"
concurrent_reads : 256 # essayé 64 - aucune différence remarquée
concurrent_writes : 256 # essayé 64 - aucune différence remarquée
concurrent_counter_writes : 256 # essayé 64 - aucune différence remarquée
concurrent_materialized_view_writes : 32
memtable_heap_space_in_mb : 2048 # essayé 16 Go - c'était plus lent
memtable_allocation_type : tas_buffers
index_summary_capacity_in_mb :
index_summary_resize_interval_in_minutes : 60
trickle_fsync : faux
trickle_fsync_interval_in_kb : 10240
port_de stockage : 7000 XNUMX
port_storage_ssl : 7001
adresse_d'écoute : *
Adresse de diffusion: *
Listen_on_broadcast_address : vrai
internode_authenticator : org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport : vrai
port_transport_natif : 9042
start_rpc : vrai
adresse_rpc : *
rpc_port : 9160
rpc_keepalive : vrai
rpc_server_type : synchronisation
thrift_framed_transport_size_in_mb : 15
incrémental_backups : faux
snapshot_before_compaction : faux
auto_snapshot : vrai
column_index_size_in_ko : 64
column_index_cache_size_in_kb : 2
concurrent_compactors : 4
compaction_throughput_mb_per_sec : 1600 XNUMX
sstable_preemptive_open_interval_in_mb : 50
read_request_timeout_in_ms : 100000 XNUMX
range_request_timeout_in_ms : 200000 XNUMX
write_request_timeout_in_ms : 40000 XNUMX
counter_write_request_timeout_in_ms : 100000 XNUMX
cas_contention_timeout_in_ms : 20000 XNUMX
truncate_request_timeout_in_ms : 60000 XNUMX
request_timeout_in_ms : 200000 XNUMX
slow_query_log_timeout_in_ms : 500
cross_node_timeout : faux
endpoint_snitch : GossipingPropertyFileSnitch
Dynamic_snitch_update_interval_in_ms : 100
Dynamic_snitch_reset_interval_in_ms : 600000 XNUMX
Dynamic_snitch_badness_threshold : 0.1
request_scheduler : org.apache.cassandra.scheduler.NoScheduler
options_de_cryptage_serveur :
internode_encryption : aucun
client_encryption_options :
activé : faux
internode_compression : cc
inter_dc_tcp_nodelay : faux
tracetype_query_ttl : 86400
tracetype_repair_ttl : 604800
activate_user_defined_functions : faux
activate_scripted_user_defined_functions : faux
windows_timer_interval : 1
transparent_data_encryption_options :
activé : faux
tombstone_warn_threshold : 1000 XNUMX
tombstone_failure_threshold : 100000 XNUMX
batch_size_warn_threshold_in_ko : 200
batch_size_fail_threshold_in_ko : 250
unlogged_batch_across_partitions_warn_threshold : 10
compaction_large_partition_warning_threshold_mb : 100
gc_warn_threshold_in_ms : 1000
back_pression_enabled : faux
activate_materialized_views : vrai
activate_sasi_indexes : vrai
Paramètres du CPG :
### Paramètres du CMS-XX:+UtiliserParNouveauGC
-XX: + UseConcMarkSweepGC
-XX:+CMSParallelRemarkActivé
-XX : Rapport de survivants = 8
-XX :Seuil d'occupation maximal=1
-XX :CMSInitiatingOccupancyFraction=75
-XX:+UtiliserCMSInitiatingOccupancyUniquement
-XX :CMSWaitDuration=10000 XNUMX
-XX:+CMSParallelInitialMarkEnabled
-XX:+CMSEdenChunksRecordAlways
-XX : +CMSClassUnloadingEnabled
La mémoire jvm.options était allouée à 16 Go (nous avons également essayé 32 Go, aucune différence n'a été remarquée).
Les tables ont été créées avec la commande :
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};Version HB : 1.2.0-cdh5.14.2 (dans la classe org.apache.hadoop.hbase.regionserver.HRegion nous avons exclu MetricsRegion qui conduisait à GC lorsque le nombre de régions était supérieur à 1000 sur RegionServer)
Paramètres HBase autres que ceux par défautzookeeper.session.timeout: 120000
hbase.rpc.timeout : 2 minute(s)
hbase.client.scanner.timeout.period: 2 minute(s)
hbase.master.handler.count : 10
hbase.regionserver.lease.period, hbase.client.scanner.timeout.period : 2 minute(s)
hbase.regionserver.handler.count : 160
hbase.regionserver.metahandler.count : 30
hbase.regionserver.logroll.period: 4 heure(s)
hbase.regionserver.maxlogs : 200
hbase.hregion.memstore.flush.size : 1 Gio
hbase.hregion.memstore.block.multiplier : 6
hbase.hstore.compactionThreshold : 5
hbase.hstore.blockingStoreFiles : 200
hbase.hregion.majorcompaction : 1 jour(s)
Extrait de configuration avancée du service HBase (soupape de sécurité) pour hbase-site.xml :
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
Options de configuration Java pour HBase RegionServer :
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:ReservedCodeCacheSize=256m
hbase.snapshot.master.timeoutMillis : 2 minute(s)
hbase.snapshot.region.timeout : 2 minute(s)
hbase.snapshot.master.timeout.millis : 2 minute(s)
Taille maximale du journal du serveur HBase REST : 100 Mio
Sauvegardes maximales des fichiers journaux du serveur HBase REST : 5
Taille maximale des journaux du serveur HBase Thrift : 100 Mio
Sauvegardes maximales des fichiers journaux du HBase Thrift Server : 5
Taille maximale du journal principal : 100 Mio
Sauvegardes maximales des fichiers journaux principaux : 5
Taille maximale du journal RegionServer : 100 Mio
Sauvegardes maximales des fichiers journaux de RegionServer : 5
Fenêtre de détection du maître actif HBase : 4 minute(s)
dfs.client.hedged.read.threadpool.size : 40
dfs.client.hedged.read.threshold.millis : 10 milliseconde(s)
hbase.rest.threads.min : 8
hbase.rest.threads.max : 150
Descripteurs de fichiers de processus maximum : 180000 XNUMX
hbase.thrift.minWorkerThreads : 200
hbase.master.executor.openregion.threads : 30
hbase.master.executor.closeregion.threads : 30
hbase.master.executor.serverops.threads : 60
hbase.regionserver.thread.compaction.small : 6
hbase.ipc.server.read.threadpool.size : 20
Sujets de déplacement de région : 6
Taille du tas Java client en octets : 1 Gio
Groupe par défaut du serveur HBase REST : 3 Gio
Groupe par défaut du serveur HBase Thrift : 3 Gio
Taille du tas Java du maître HBase en octets : 16 Gio
Taille du tas Java de HBase RegionServer en octets : 32 Gio
+Gardien de zoo
maxClientCnxns : 601
maxSessionTimeout : 120000 XNUMX
Création de tableaux :
hbase org.apache.hadoop.hbase.util.RegionSplitter ns:t1 UniformSplit -c 64 -f cf
modifier 'ns:t1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', COMPRESSION => 'GZ'}
Il y a un point important ici : la description de DataStax ne dit pas combien de régions ont été utilisées pour créer les tables HB, bien que cela soit critique pour les gros volumes. Ainsi, pour les tests, la quantité = 64 a été choisie, ce qui permet de stocker jusqu'à 640 Go, soit table de taille moyenne.
Au moment du test, HBase comptait 22 67 tables et 1.2.0 XNUMX régions (cela aurait été mortel pour la version XNUMX sans le patch mentionné ci-dessus).
Maintenant pour le code. Comme il n’était pas clair quelles configurations étaient les plus avantageuses pour une base de données particulière, les tests ont été effectués selon diverses combinaisons. Ceux. dans certains tests, 4 tables ont été chargées simultanément (les 4 nœuds ont été utilisés pour la connexion). Dans d'autres tests, nous avons travaillé avec 8 tables différentes. Dans certains cas, la taille du lot était de 100, dans d'autres de 200 (paramètre du lot - voir le code ci-dessous). La taille des données pour la valeur est de 10 octets ou 100 octets (dataSize). Au total, 5 millions d'enregistrements ont été écrits et lus dans chaque table à chaque fois. Dans le même temps, 5 threads ont été écrits/lus dans chaque table (numéro de thread - thNum), chacun utilisant sa propre plage de clés (nombre = 1 million) :
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("BEGIN BATCH ");
for (int i = 0; i < batch; i++) {
String value = RandomStringUtils.random(dataSize, true, true);
sb.append("INSERT INTO ")
.append(tableName)
.append("(id, title) ")
.append("VALUES (")
.append(key)
.append(", '")
.append(value)
.append("');");
key++;
}
sb.append("APPLY BATCH;");
final String query = sb.toString();
session.execute(query);
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN (");
for (int i = 0; i < batch; i++) {
sb = sb.append(key);
if (i+1 < batch)
sb.append(",");
key++;
}
sb = sb.append(");");
final String query = sb.toString();
ResultSet rs = session.execute(query);
}
}
En conséquence, des fonctionnalités similaires ont été fournies pour HB :
Configuration conf = getConf();
HTable table = new HTable(conf, keyspace + ":" + tableName);
table.setAutoFlush(false, false);
List<Get> lGet = new ArrayList<>();
List<Put> lPut = new ArrayList<>();
byte[] cf = Bytes.toBytes("cf");
byte[] qf = Bytes.toBytes("value");
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lPut.clear();
for (int i = 0; i < batch; i++) {
Put p = new Put(makeHbaseRowKey(key));
String value = RandomStringUtils.random(dataSize, true, true);
p.addColumn(cf, qf, value.getBytes());
lPut.add(p);
key++;
}
table.put(lPut);
table.flushCommits();
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lGet.clear();
for (int i = 0; i < batch; i++) {
Get g = new Get(makeHbaseRowKey(key));
lGet.add(g);
key++;
}
Result[] rs = table.get(lGet);
}
}
Puisque dans HB, le client doit veiller à la distribution uniforme des données, la fonction de salage des clés ressemblait à ceci :
public static byte[] makeHbaseRowKey(long key) {
byte[] nonSaltedRowKey = Bytes.toBytes(key);
CRC32 crc32 = new CRC32();
crc32.update(nonSaltedRowKey);
long crc32Value = crc32.getValue();
byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7);
return ArrayUtils.addAll(salt, nonSaltedRowKey);
}
Maintenant, la partie la plus intéressante : les résultats :
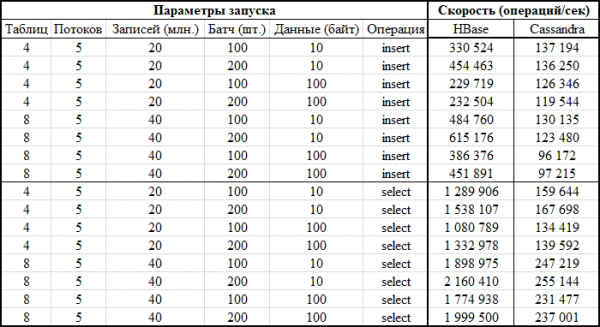
La même chose sous forme graphique :
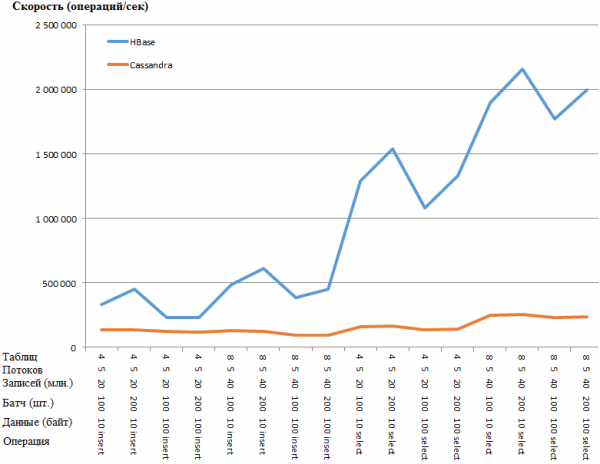
L'avantage de HB est si surprenant qu'on soupçonne qu'il existe une sorte de goulot d'étranglement dans la configuration CS. Cependant, rechercher sur Google et rechercher les paramètres les plus évidents (comme concurrent_writes ou memtable_heap_space_in_mb) n'a pas accéléré les choses. En même temps, les bûches sont propres et ne jurent de rien.
Les données étaient réparties uniformément entre les nœuds, les statistiques de tous les nœuds étaient à peu près les mêmes.
Voici à quoi ressemblent les statistiques du tableau provenant de l'un des nœudsEspace clé : ks
Nombre de lectures : 9383707
Latence de lecture : 0.04287025042448576 ms
Nombre d'écritures : 15462012 XNUMX XNUMX
Latence d'écriture : 0.1350068438699957 ms
Vidages en attente : 0
Tableau : t1
Nombre de tables SS : 16
Espace utilisé (en direct) : 148.59 Mo
Espace utilisé (total) : 148.59 Mo
Espace utilisé par les instantanés (total) : 0 octet
Mémoire hors tas utilisée (total) : 5.17 Mio
Taux de compression SStable : 0.5720989576459437
Nombre de cloisons (estimation) : 3970323
Nombre de cellules mémorisables : 0
Taille des données mémorisables : 0 octet
Mémoire hors tas mémorisable utilisée : 0 octet
Nombre de commutateurs mémorisables : 5
Nombre de lectures locales : 2346045 XNUMX XNUMX
Latence de lecture locale : NaN ms
Nombre d'écritures locales : 3865503
Latence d'écriture locale : NaN ms
Flushs en attente : 0
Pourcentage réparé : 0.0
Faux positifs du filtre Bloom : 25
Taux de faux filtre Bloom : 0.00000
Espace de filtre Bloom utilisé : 4.57 Mio
Filtre Bloom sur la mémoire tas utilisée : 4.57 Mio
Résumé de l'index sur la mémoire tas utilisée : 590.02 Ko
Métadonnées de compression de la mémoire tas utilisée : 19.45 Ko
Octets minimum de partition compactée : 36
Octets maximum de la partition compactée : 42
Octets moyens de partition compactée : 42
Cellules vivantes moyennes par tranche (cinq dernières minutes) : NaN
Nombre maximum de cellules vivantes par tranche (cinq dernières minutes) : 0
Pierres tombales moyennes par tranche (cinq dernières minutes) : NaN
Nombre maximum de pierres tombales par tranche (cinq dernières minutes) : 0
Mutations abandonnées : 0 octet
Une tentative de réduire la taille du lot (même en l'envoyant individuellement) n'a eu aucun effet, la situation n'a fait qu'empirer. Il est possible qu'il s'agisse en fait des performances maximales pour CS, puisque les résultats obtenus pour CS sont similaires à ceux obtenus pour DataStax - environ des centaines de milliers d'opérations par seconde. De plus, si nous regardons l’utilisation des ressources, nous verrons que CS utilise beaucoup plus de CPU et de disques :
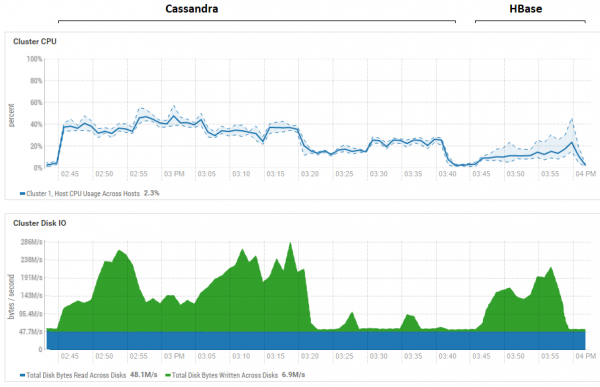
La figure montre l'utilisation lors de l'exécution de tous les tests consécutifs pour les deux bases de données.
Concernant le puissant avantage de lecture de HB. Ici, vous pouvez voir que pour les deux bases de données, l'utilisation du disque pendant la lecture est extrêmement faible (les tests de lecture constituent la dernière partie du cycle de test pour chaque base de données, par exemple pour CS, ils se déroulent de 15h20 à 15h40). Dans le cas de HB, la raison est claire : la plupart des données sont bloquées en mémoire, dans le memstore, et certaines sont mises en cache dans le cache de bloc. Quant à CS, son fonctionnement n'est pas très clair, mais le recyclage du disque n'est pas non plus visible, mais juste au cas où, une tentative a été faite pour activer le cache row_cache_size_in_mb = 2048 et définir la mise en cache = {'keys': 'ALL', 'rows_per_partition': ' 2000000'}, mais cela a rendu la situation encore un peu pire.
Il convient également de mentionner une fois de plus un point important concernant le nombre de régions en HB. Dans notre cas, la valeur a été spécifiée à 64. Si vous la réduisez et la rendez égale à, par exemple, 4, alors lors de la lecture, la vitesse diminue de 2 fois. La raison en est que la mémoire se remplira plus rapidement et les fichiers seront vidés plus souvent et lors de la lecture, davantage de fichiers devront être traités, ce qui est une opération plutôt compliquée pour HB. Dans des conditions réelles, cela peut être traité en réfléchissant à une stratégie de pré-découpage et de compactification ; en particulier, nous utilisons un utilitaire auto-écrit qui collecte les déchets et compresse les HFiles en permanence en arrière-plan. Il est fort possible que pour les tests DataStax, ils n'aient alloué qu'une seule région par table (ce qui n'est pas correct), ce qui expliquerait quelque peu pourquoi HB était si inférieur dans leurs tests de lecture.
Les conclusions préliminaires suivantes en sont tirées. En supposant qu’aucune erreur majeure n’ait été commise lors des tests, Cassandra ressemble alors à un colosse aux pieds d’argile. Plus précisément, alors qu'elle est en équilibre sur une jambe, comme sur la photo au début de l'article, elle montre des résultats relativement bons, mais dans un combat dans les mêmes conditions, elle perd carrément. Dans le même temps, compte tenu de la faible utilisation du processeur sur notre matériel, nous avons appris à installer deux RegionServer HB par hôte et avons ainsi doublé les performances. Ceux. Compte tenu de l'utilisation des ressources, la situation du CS est encore plus déplorable.
Bien entendu, ces tests sont assez synthétiques et la quantité de données utilisée ici est relativement modeste. Il est possible que si nous passions aux téraoctets, la situation serait différente, mais si pour HB nous pouvons charger des téraoctets, pour CS cela s'est avéré problématique. Il lançait souvent une OperationTimedOutException même avec ces volumes, bien que les paramètres d'attente d'une réponse aient déjà été augmentés plusieurs fois par rapport à ceux par défaut.
J'espère que grâce à des efforts conjoints, nous trouverons les goulots d'étranglement du CS et si nous pouvons l'accélérer, alors à la fin du message, j'ajouterai certainement des informations sur les résultats finaux.
UPD : Grâce aux conseils de camarades, j'ai réussi à accélérer la lecture. Était:
159 644 opérations (4 tables, 5 flux, lot 100).
Ajouté:
.withLoadBalancingPolicy(nouveau TokenAwarePolicy(DCAwareRoundRobinPolicy.builder().build()))
Et j'ai joué avec le nombre de threads. Le résultat est le suivant :
4 tables, 100 threads, lot = 1 (pièce par pièce) : 301 969 opérations
4 tables, 100 threads, lot = 10 : 447 608 opérations
4 tables, 100 threads, lot = 100 : 625 655 opérations
Plus tard, j'appliquerai d'autres conseils de réglage, exécuterai un cycle de test complet et ajouterai les résultats à la fin du message.
Source: habr.com
