

À l'automne 2019, un événement tant attendu a eu lieu dans l'équipe Mail.ru Cloud iOS. La base de données principale pour le stockage persistant de l'état des applications est devenue assez exotique pour le monde mobile (LMDB). Sous la coupe, votre attention est invitée à sa revue détaillée en quatre parties. Parlons d'abord des raisons d'un choix aussi non trivial et difficile. Passons ensuite à l'examen de trois baleines au cœur de l'architecture LMDB : les fichiers mappés en mémoire, l'arborescence B +, l'approche de copie sur écriture pour la mise en œuvre du transactionnel et du multiversion. Enfin, pour le dessert - la partie pratique. Dans ce document, nous verrons comment concevoir et implémenter un schéma de base avec plusieurs tables, dont une table d'index, en plus de l'API clé-valeur de bas niveau.
Teneur
3.1.
3.2.
3.3.
4.1.
4.2.
4.3.
1. Motivation pour la mise en œuvre
Une fois par an, en 2015, nous nous sommes occupés de prendre une métrique, à quelle fréquence l'interface de notre application lagnait. Nous ne nous sommes pas contentés de faire cela. On se plaint de plus en plus du fait que parfois l'application ne répond plus aux actions de l'utilisateur : les boutons ne sont pas appuyés, les listes ne défilent pas, etc. À propos de la mécanique des mesures sur AvitoTech, donc ici je ne donne que l'ordre des numéros.
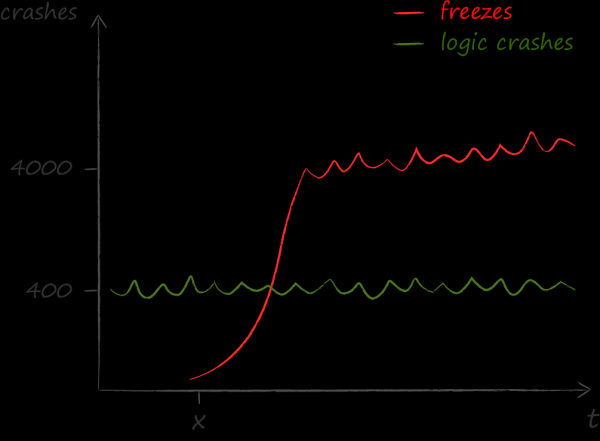
Les résultats de mesure sont devenus une douche froide pour nous. Il s'est avéré que les problèmes causés par les gels sont bien plus importants que tout autre. Si, avant de se rendre compte de ce fait, le principal indicateur technique de qualité était sans crash, alors après la mise au point sans congélation.
En construisant et ayant passé и analyse de leurs causes, l'ennemi principal est devenu clair - une logique métier lourde s'exécutant dans le fil principal de l'application. Une réaction naturelle à cette disgrâce était un désir ardent de la pousser dans les flux de travail. Pour une solution systématique de ce problème, nous avons eu recours à une architecture multi-thread basée sur des acteurs légers. J'ai dédié ses adaptations pour le monde iOS dans le collectif twitter et . Dans le cadre de l'histoire actuelle, je souhaite souligner les aspects de la décision qui ont influencé le choix de la base de données.
Le modèle d'acteur de l'organisation du système suppose que le multithreading devient sa deuxième essence. Les objets modèles qu'il contient aiment franchir les limites de thread. Et ils ne le font pas parfois et à certains endroits, mais presque constamment et partout.
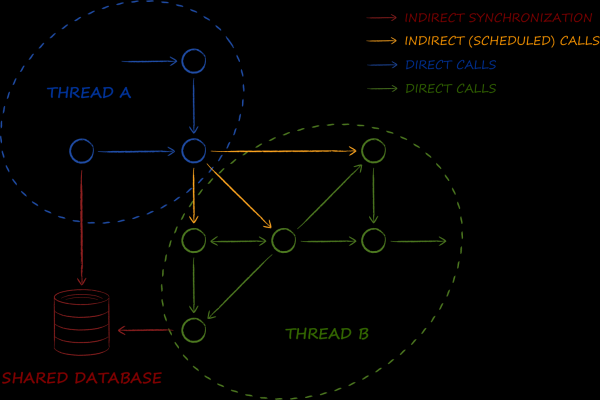
La base de données est l'un des composants fondamentaux du schéma présenté. Sa tâche principale est d'implémenter un modèle de macro . Si dans le monde de l'entreprise il est utilisé pour organiser la synchronisation des données entre services, alors dans le cas d'une architecture d'acteurs, les données entre threads. Ainsi, nous avions besoin d'une telle base de données, avec laquelle travailler dans un environnement multithread ne cause même pas de difficultés minimes. En particulier, cela signifie que les objets qui en sont dérivés doivent être au moins thread-safe et, idéalement, pas modifiables du tout. Comme vous le savez, ce dernier peut être utilisé simultanément à partir de plusieurs threads sans recourir à aucun type de verrous, ce qui a un effet bénéfique sur les performances.
 Le deuxième facteur important qui a influencé le choix de la base de données était notre API cloud. Il a été inspiré par l'approche git de la synchronisation. Comme lui, nous visons , ce qui semble plus que approprié pour les clients cloud. On a supposé qu'ils ne pomperaient qu'une seule fois l'état complet du cloud, puis la synchronisation dans la grande majorité des cas se produirait par le biais de changements progressifs. Hélas, cette possibilité n'est encore que dans la zone théorique et, dans la pratique, les clients n'ont pas appris à travailler avec des correctifs. Il y a un certain nombre de raisons objectives à cela, que, afin de ne pas retarder l'introduction, nous laisserons entre parenthèses. Maintenant, beaucoup plus intéressants sont les résultats instructifs de la leçon sur ce qui se passe lorsque l'API a dit "A" et que son consommateur n'a pas dit "B".
Le deuxième facteur important qui a influencé le choix de la base de données était notre API cloud. Il a été inspiré par l'approche git de la synchronisation. Comme lui, nous visons , ce qui semble plus que approprié pour les clients cloud. On a supposé qu'ils ne pomperaient qu'une seule fois l'état complet du cloud, puis la synchronisation dans la grande majorité des cas se produirait par le biais de changements progressifs. Hélas, cette possibilité n'est encore que dans la zone théorique et, dans la pratique, les clients n'ont pas appris à travailler avec des correctifs. Il y a un certain nombre de raisons objectives à cela, que, afin de ne pas retarder l'introduction, nous laisserons entre parenthèses. Maintenant, beaucoup plus intéressants sont les résultats instructifs de la leçon sur ce qui se passe lorsque l'API a dit "A" et que son consommateur n'a pas dit "B".
Donc, si vous imaginez git, qui, lors de l'exécution d'une commande pull, au lieu d'appliquer des correctifs à un instantané local, compare son état complet avec celui du serveur complet, alors vous aurez une idée assez précise de la façon dont la synchronisation se produit dans les clients cloud. Il est facile de deviner que pour sa mise en œuvre, il est nécessaire d'allouer deux arbres DOM en mémoire avec des méta-informations sur tous les fichiers serveur et locaux. Il s'avère que si un utilisateur stocke 500 1 fichiers dans le cloud, alors pour le synchroniser, il est nécessaire de recréer et de détruire deux arbres avec XNUMX million de nœuds. Mais chaque nœud est un agrégat contenant un graphe de sous-objets. Dans cette optique, les résultats du profilage étaient attendus. Il s'est avéré que même sans tenir compte de l'algorithme de fusion, la procédure même de création puis de destruction d'un grand nombre de petits objets coûte un joli centime.La situation est aggravée par le fait que l'opération de synchronisation de base est incluse dans un grand nombre de scripts utilisateur. En conséquence, nous fixons le deuxième critère important dans le choix d'une base de données - la capacité à implémenter des opérations CRUD sans allocation dynamique d'objets.
D'autres exigences sont plus traditionnelles et leur liste complète est la suivante.
- Sécurité des fils.
- Multitraitement. Dicté par le désir d'utiliser la même instance de base de données pour synchroniser l'état non seulement entre les threads, mais également entre l'application principale et les extensions iOS.
- La possibilité de représenter des entités stockées en tant qu'objets non modifiables.
- Manque d'allocations dynamiques dans les opérations CRUD.
- Prise en charge des transactions pour les propriétés de base Mots clés : atomicité, cohérence, isolement et fiabilité.
- Rapidité sur les cas les plus populaires.
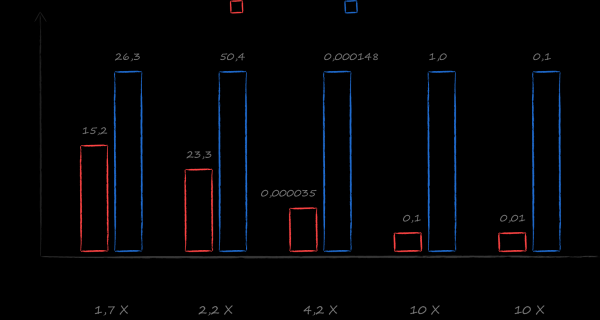
Avec cet ensemble d'exigences, SQLite était et est toujours un bon choix. Cependant, dans le cadre de l'étude des alternatives, je suis tombé sur un livre . Sous sa direction, un benchmark a été rédigé qui compare la vitesse de travail avec différentes bases de données dans des scénarios cloud réels. Le résultat a dépassé les attentes les plus folles. Dans les cas les plus courants - obtenir un curseur sur une liste triée de tous les fichiers et une liste triée de tous les fichiers pour un répertoire donné - LMDB s'est avéré 10 fois plus rapide que SQLite. Le choix est devenu une évidence.
2. Positionnement LMDB
LMDB est une bibliothèque, très petite (seulement 10K lignes), qui implémente la couche fondamentale la plus basse des bases de données - le stockage.
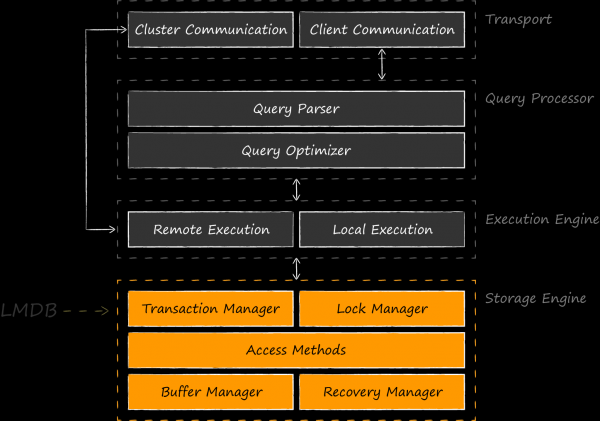
Le diagramme ci-dessus montre que comparer LMDB avec SQLite, qui implémente des niveaux encore plus élevés, n'est généralement pas plus correct que SQLite avec Core Data. Il serait plus juste de citer les mêmes moteurs de stockage que des concurrents égaux - BerkeleyDB, LevelDB, Sophia, RocksDB, etc. Il existe même des développements où LMDB agit comme un composant de moteur de stockage pour SQLite. La première expérience de ce type en 2012 auteur LMDB . s'avéra si intrigante que son initiative fut reprise par des passionnés d'OSS, et trouva sa pérennité face à . En janvier 2020 l'auteur de ce projet est Den Shearer lui sur LinuxConfAu.
L'utilisation principale de LMDB est en tant que moteur pour les bases de données d'application. La bibliothèque doit son apparence aux développeurs , qui étaient fortement mécontents de BerkeleyDB comme base de leur projet. Loin de l'humble bibliothèque , Howard Chu a pu créer l'une des alternatives les plus populaires de notre époque. Il a consacré son reportage très cool à cette histoire, ainsi qu'à la structure interne de LMDB . Leonid Yuriev (alias ) de Positive Technologies dans sa présentation à Highload 2015 . Il y parle de LMDB dans le cadre d'une tâche similaire de mise en œuvre de ReOpenLDAP, et LevelDB a déjà fait l'objet de critiques comparatives. À la suite de la mise en œuvre, Positive Technologies a même obtenu un fork en développement actif avec des fonctionnalités très savoureuses, des optimisations et .
LMDB est souvent utilisé comme stockage tel quel. Par exemple, le navigateur Mozilla Firefox pour un certain nombre de besoins, et, à partir de la version 9, Xcode son SQLite pour stocker les index.
Le moteur s'est également imposé dans le monde du développement mobile. Des traces de son utilisation peuvent être dans le client iOS pour Telegram. LinkedIn est allé encore plus loin et a choisi LMDB comme stockage par défaut pour son framework de mise en cache de données maison, Rocket Data, à propos duquel dans un article en 2016.
LMDB se bat avec succès pour une place au soleil dans le créneau laissé par BerkeleyDB après le passage sous le contrôle d'Oracle. La bibliothèque est appréciée pour sa rapidité et sa fiabilité, même en comparaison avec son propre type. Comme vous le savez, il n'y a pas de repas gratuits, et je voudrais souligner le compromis auquel vous devrez faire face lors du choix entre LMDB et SQLite. Le schéma ci-dessus montre clairement comment la vitesse accrue est obtenue. Premièrement, nous ne payons pas pour des couches d'abstraction supplémentaires en plus du stockage sur disque. Bien sûr, dans une bonne architecture, vous ne pourrez toujours pas vous en passer, et ils apparaîtront inévitablement dans le code de l'application, mais ils seront beaucoup plus fins. Ils n'auront pas de fonctionnalités qui ne sont pas requises par une application spécifique, par exemple, la prise en charge des requêtes en langage SQL. Deuxièmement, il devient possible d'implémenter de manière optimale le mappage des opérations d'application aux requêtes vers le stockage sur disque. Si SQLite provient des besoins moyens d'une application moyenne, alors vous, en tant que développeur d'applications, connaissez bien les principaux scénarios de charge. Pour une solution plus productive, vous devrez payer un prix plus élevé à la fois pour le développement de la solution initiale et son support ultérieur.
3. Trois baleines LMDB
Après avoir regardé la LMDB à vol d'oiseau, il est temps d'aller plus loin. Les trois sections suivantes seront consacrées à l'analyse des principales baleines sur lesquelles repose l'architecture de stockage :
- Fichiers mappés en mémoire comme mécanisme pour travailler avec le disque et synchroniser les structures de données internes.
- B+-tree en tant qu'organisation de la structure de données stockée.
- Copie sur écriture en tant qu'approche pour fournir des propriétés transactionnelles ACID et le multiversioning.
3.1. Baleine #1. Fichiers mappés en mémoire
Les fichiers mappés en mémoire sont un élément architectural si important qu'ils apparaissent même dans le nom du référentiel. Les problèmes de mise en cache et de synchronisation de l'accès aux informations stockées sont entièrement à la merci du système d'exploitation. LMDB ne contient aucun cache en lui-même. Il s'agit d'une décision consciente de l'auteur, car la lecture de données directement à partir de fichiers mappés vous permet de réduire considérablement la mise en œuvre du moteur. Vous trouverez ci-dessous une liste loin d'être complète de certains d'entre eux.
- Le maintien de la cohérence des données dans le stockage lorsque vous travaillez avec celui-ci à partir de plusieurs processus devient la responsabilité du système d'exploitation. Dans la section suivante, ce mécanisme est discuté en détail et avec des images.
- L'absence de caches soulage complètement LMDB de la surcharge associée aux allocations dynamiques. La lecture de données consiste en pratique à positionner le pointeur sur la bonne adresse dans la mémoire virtuelle et rien de plus. Cela ressemble à de la fantaisie, mais dans la source du référentiel, tous les appels calloc sont concentrés dans la fonction de configuration du référentiel.
- L'absence de caches signifie également l'absence de verrous associés à la synchronisation pour y accéder. Les lecteurs, dont un nombre arbitraire peut exister en même temps, ne rencontrent pas un seul mutex sur leur chemin vers les données. De ce fait, la vitesse de lecture a une évolutivité linéaire idéale en termes de nombre de processeurs. Dans LMDB, seules les opérations de modification sont synchronisées. Il ne peut y avoir qu'un seul auteur à la fois.
- Un minimum de logique de mise en cache et de synchronisation évite au code un type extrêmement complexe d'erreurs associées au travail dans un environnement multithread. Il y avait deux études de bases de données intéressantes à la conférence Usenix OSDI 2014 : и . D'eux, vous pouvez obtenir des informations à la fois sur la fiabilité sans précédent de LMDB et sur la mise en œuvre presque sans faille des propriétés ACID des transactions, qui la surpasse dans le même SQLite.
- Le minimalisme de LMDB permet à la représentation machine de son code d'être complètement placée dans le cache L1 du processeur avec les caractéristiques de vitesse qui en résultent.
Malheureusement, dans iOS, les fichiers mappés en mémoire ne sont pas aussi roses que nous le souhaiterions. Pour parler plus consciemment des inconvénients qui leur sont associés, il est nécessaire de rappeler les principes généraux de mise en œuvre de ce mécanisme dans les systèmes d'exploitation.
Informations générales sur les fichiers mappés en mémoire
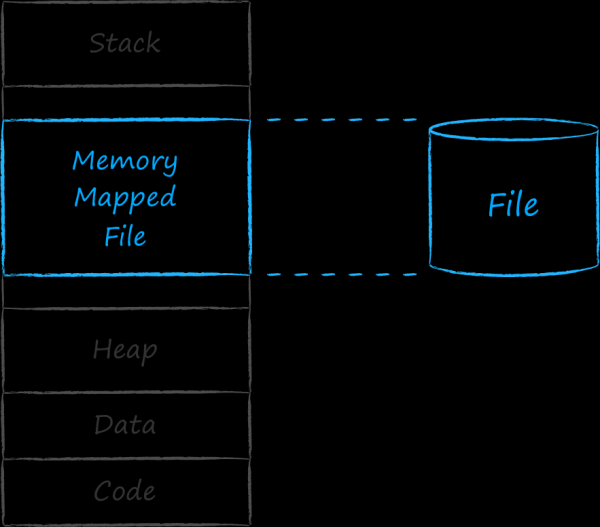 A chaque application exécutable, le système d'exploitation associe une entité appelée processus. Chaque processus se voit attribuer une plage d'adresses contiguës, dans laquelle il place tout ce dont il a besoin pour fonctionner. Les adresses les plus basses contiennent des sections avec du code et des données et ressources codées en dur. Vient ensuite le bloc croissant d'espace d'adressage dynamique, bien connu de nous sous le nom de tas. Il contient les adresses des entités qui apparaissent pendant le fonctionnement du programme. En haut se trouve la zone de mémoire utilisée par la pile applicative. Il grandit ou rétrécit, en d'autres termes, sa taille a également un caractère dynamique. Pour que la pile et le tas ne se poussent pas et n'interfèrent pas l'un avec l'autre, ils sont séparés à différentes extrémités de l'espace d'adressage. Il y a un trou entre les deux sections dynamiques en haut et en bas. Les adresses de cette section médiane sont utilisées par le système d'exploitation pour s'associer à un processus de diverses entités. En particulier, il peut mapper un certain ensemble continu d'adresses à un fichier sur disque. Un tel fichier est appelé un fichier mappé en mémoire.
A chaque application exécutable, le système d'exploitation associe une entité appelée processus. Chaque processus se voit attribuer une plage d'adresses contiguës, dans laquelle il place tout ce dont il a besoin pour fonctionner. Les adresses les plus basses contiennent des sections avec du code et des données et ressources codées en dur. Vient ensuite le bloc croissant d'espace d'adressage dynamique, bien connu de nous sous le nom de tas. Il contient les adresses des entités qui apparaissent pendant le fonctionnement du programme. En haut se trouve la zone de mémoire utilisée par la pile applicative. Il grandit ou rétrécit, en d'autres termes, sa taille a également un caractère dynamique. Pour que la pile et le tas ne se poussent pas et n'interfèrent pas l'un avec l'autre, ils sont séparés à différentes extrémités de l'espace d'adressage. Il y a un trou entre les deux sections dynamiques en haut et en bas. Les adresses de cette section médiane sont utilisées par le système d'exploitation pour s'associer à un processus de diverses entités. En particulier, il peut mapper un certain ensemble continu d'adresses à un fichier sur disque. Un tel fichier est appelé un fichier mappé en mémoire.
L'espace d'adressage alloué à un processus est énorme. Théoriquement, le nombre d'adresses n'est limité que par la taille du pointeur, qui est déterminée par le nombre de bits du système. Si la mémoire physique lui était attribuée 1-en-1, alors le premier processus engloutirait toute la RAM, et il ne serait plus question de multitâche.
Cependant, nous savons par expérience que les systèmes d'exploitation modernes peuvent exécuter autant de processus que vous le souhaitez en même temps. Cela est possible car ils allouent beaucoup de mémoire aux processus uniquement sur papier, mais en réalité, ils ne chargent dans la mémoire physique principale que la partie demandée ici et maintenant. Par conséquent, la mémoire associée au processus est appelée virtuelle.
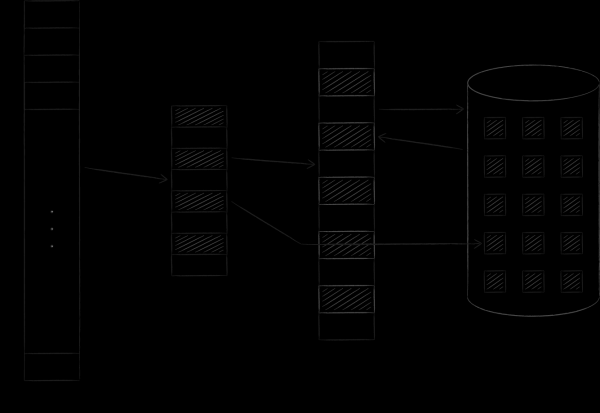
Le système d'exploitation organise la mémoire virtuelle et physique en pages d'une certaine taille. Dès qu'une certaine page de mémoire virtuelle est demandée, le système d'exploitation la charge dans la mémoire physique et établit une correspondance entre elles dans une table spéciale. S'il n'y a pas d'emplacements libres, l'une des pages précédemment chargées est copiée sur le disque et celle demandée prend sa place. Cette procédure, sur laquelle nous reviendrons bientôt, s'appelle l'échange. La figure ci-dessous illustre le processus décrit. Sur celui-ci, la page A avec l'adresse 0 a été chargée et placée sur la page de mémoire principale avec l'adresse 4. Ce fait a été reflété dans le tableau de correspondance dans la cellule numéro 0.
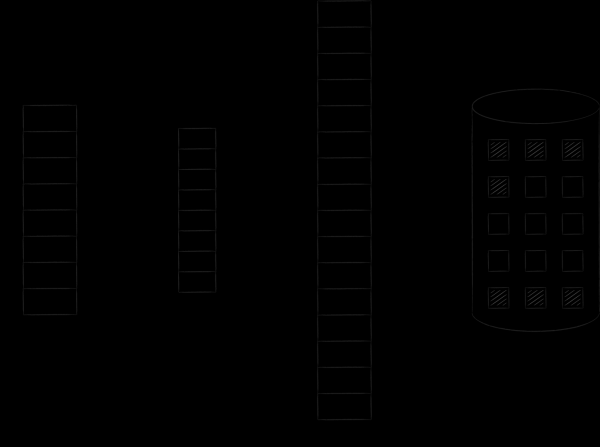
Avec les fichiers mappés en mémoire, l'histoire est exactement la même. Logiquement, ils sont censés être continuellement et entièrement placés dans l'espace d'adressage virtuel. Cependant, ils entrent dans la mémoire physique page par page et uniquement à la demande. La modification de ces pages est synchronisée avec le fichier sur disque. Ainsi, vous pouvez effectuer des E / S de fichiers, en travaillant simplement avec des octets en mémoire - toutes les modifications seront automatiquement transférées par le noyau du système d'exploitation vers le fichier d'origine.
L'image ci-dessous montre comment LMDB synchronise son état lorsque vous travaillez avec la base de données à partir de différents processus. En mappant la mémoire virtuelle de différents processus sur le même fichier, nous obligeons de facto le système d'exploitation à synchroniser de manière transitive certains blocs de leurs espaces d'adressage entre eux, c'est là que LMDB regarde.
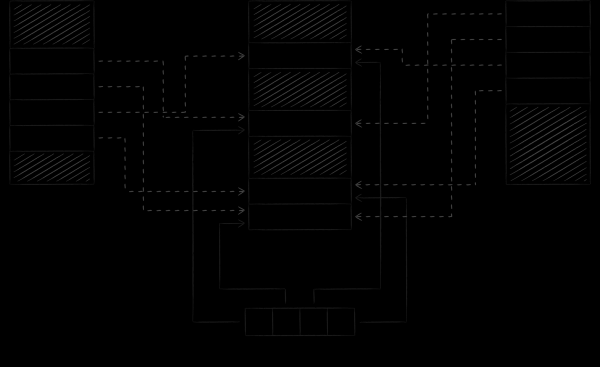
Une nuance importante est que, par défaut, LMDB modifie le fichier de données via le mécanisme d'appel système en écriture, et le fichier lui-même s'affiche en mode lecture seule. Cette approche a deux implications importantes.
La première conséquence est commune à tous les systèmes d'exploitation. Son essence est d'ajouter une protection contre les dommages involontaires à la base de données par un code incorrect. Comme vous le savez, les instructions exécutables d'un processus sont libres d'accéder aux données de n'importe où dans son espace d'adressage. En même temps, comme on vient de le rappeler, afficher un fichier en lecture-écriture signifie que n'importe quelle instruction peut aussi le modifier en plus. Si elle le fait par erreur, en essayant, par exemple, d'écraser un élément de tableau à un index inexistant, elle peut ainsi modifier accidentellement le fichier mappé à cette adresse, ce qui entraînera une corruption de la base de données. Si le fichier est affiché en mode lecture seule, alors une tentative de modification de l'espace d'adressage qui lui correspond entraînera le plantage du programme avec le signal SIGSEGV, et le fichier restera intact.
La seconde conséquence est déjà propre à iOS. Ni l'auteur ni aucune autre source ne le mentionnent explicitement, mais sans cela, LMDB ne serait pas adapté pour fonctionner sur ce système d'exploitation mobile. La section suivante est consacrée à son examen.
Spécificités des fichiers mappés en mémoire dans iOS
En 2018, il y a eu un magnifique reportage à la WWDC . Il indique que dans iOS, toutes les pages situées dans la mémoire physique appartiennent à l'un des 3 types : sales, compressées et propres.

La mémoire propre est une collection de pages qui peuvent être extraites en toute sécurité de la mémoire physique. Les données qu'ils contiennent peuvent être rechargées à partir de leurs sources d'origine selon les besoins. Les fichiers mappés en mémoire en lecture seule entrent dans cette catégorie. iOS n'a pas peur de décharger à tout moment les pages mappées sur un fichier de la mémoire, car elles sont garanties d'être synchronisées avec le fichier sur le disque.
Toutes les pages modifiées entrent dans la mémoire sale, peu importe où elles se trouvent à l'origine. En particulier, les fichiers mappés en mémoire modifiés par écriture dans la mémoire virtuelle qui leur est associée seront également classés de cette manière. Ouverture de LMDB avec drapeau MDB_WRITEMAP, après y avoir apporté des modifications, vous pouvez voir par vous-même.
Dès qu'une application commence à occuper trop de mémoire physique, iOS compresse ses pages sales. La collection de mémoire occupée par les pages sales et compressées est ce que l'on appelle l'empreinte mémoire de l'application. Lorsqu'il atteint une certaine valeur seuil, le démon système OOM killer vient après le processus et le met fin de force. C'est la particularité d'iOS par rapport aux systèmes d'exploitation de bureau. En revanche, la réduction de l'empreinte mémoire en échangeant des pages de la mémoire physique vers le disque n'est pas prévue dans iOS, on ne peut que deviner les raisons. Peut-être que la procédure de déplacement intensif des pages vers le disque et l'arrière consomme trop d'énergie pour les appareils mobiles, ou iOS économise la ressource de réécriture des cellules sur les disques SSD, ou peut-être que les concepteurs n'étaient pas satisfaits des performances globales du système, où tout est constamment échangé. Quoi qu'il en soit, le fait demeure.
La bonne nouvelle, déjà mentionnée précédemment, est que LMDB n'utilise pas le mécanisme mmap par défaut pour mettre à jour les fichiers. Il s'ensuit que les données rendues sont classées comme mémoire propre par iOS et ne contribuent pas à l'empreinte mémoire. Cela peut être vérifié à l'aide de l'outil Xcode appelé VM Tracker. La capture d'écran ci-dessous montre l'état de la mémoire virtuelle de l'application iOS Cloud pendant le fonctionnement. Au départ, 2 instances LMDB y étaient initialisées. Le premier a été autorisé à mapper son fichier sur 1 Go de mémoire virtuelle, le second - 512 Mo. Malgré le fait que les deux stockages occupent une certaine quantité de mémoire résidente, aucun d'eux ne contribue à la taille sale.
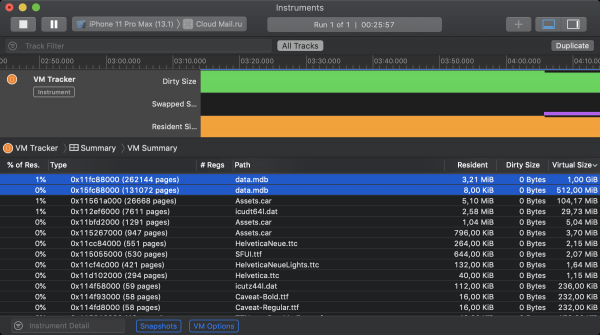
Il est maintenant temps pour les mauvaises nouvelles. Grâce au mécanisme d'échange des systèmes d'exploitation de bureau 64 bits, chaque processus peut occuper autant d'espace d'adressage virtuel que l'espace libre sur le disque dur le permet pour son échange potentiel. Remplacer le swap par la compression dans iOS réduit considérablement le maximum théorique. Désormais, tous les processus vivants doivent tenir dans la mémoire principale (RAM de lecture), et tous ceux qui ne rentrent pas sont soumis à une terminaison forcée. Il est mentionné comme ci-dessus et . En conséquence, iOS limite considérablement la quantité de mémoire disponible pour l'allocation via mmap. Ici vous pouvez consulter les limites empiriques de la quantité de mémoire pouvant être allouée sur différents appareils à l'aide de cet appel système. Sur les modèles de smartphones les plus modernes, iOS est devenu généreux de 2 gigaoctets, et sur les meilleures versions de l'iPad - de 4. En pratique, bien sûr, vous devez vous concentrer sur les modèles d'appareils pris en charge les plus jeunes, où tout est très triste. Pire encore, en regardant l'état de la mémoire de l'application dans VM Tracker, vous constaterez que LMDB est loin d'être le seul à revendiquer une mémoire mappée en mémoire. Les bons morceaux sont rongés par les répartiteurs système, les fichiers de ressources, les cadres d'image et d'autres prédateurs plus petits.
Sur la base des résultats d'expériences dans le Cloud, nous sommes arrivés aux valeurs de compromis suivantes de la mémoire allouée par LMDB : 384 mégaoctets pour les appareils 32 bits et 768 pour ceux 64 bits. Une fois ce volume épuisé, toutes les opérations de modification commencent à se terminer avec le code MDB_MAP_FULL. Nous observons de telles erreurs dans notre suivi, mais elles sont suffisamment petites pour être négligées à ce stade.
Une raison non évidente de la consommation excessive de mémoire par le stockage peut être les transactions de longue durée. Pour comprendre comment ces deux phénomènes sont liés, cela nous aidera à considérer les deux baleines LMDB restantes.
3.2. Baleine #2. Arbre B+
Pour émuler des tables au-dessus d'un magasin clé-valeur, les opérations suivantes doivent être présentes dans son API :
- Insertion d'un nouvel élément.
- Recherche un élément avec une clé donnée.
- Suppression d'un élément.
- Itérer sur les intervalles clés dans leur ordre de tri.
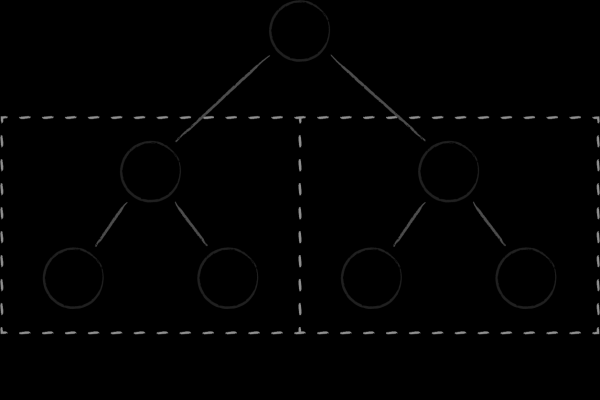 La structure de données la plus simple qui peut facilement implémenter les quatre opérations est un arbre de recherche binaire. Chacun de ses nœuds est une clé qui divise l'ensemble du sous-ensemble de clés enfants en deux sous-arborescences. À gauche, ceux qui sont plus petits que le parent et à droite, ceux qui sont plus grands. L'obtention d'un ensemble ordonné de clés est obtenue par l'une des traversées d'arbres classiques.
La structure de données la plus simple qui peut facilement implémenter les quatre opérations est un arbre de recherche binaire. Chacun de ses nœuds est une clé qui divise l'ensemble du sous-ensemble de clés enfants en deux sous-arborescences. À gauche, ceux qui sont plus petits que le parent et à droite, ceux qui sont plus grands. L'obtention d'un ensemble ordonné de clés est obtenue par l'une des traversées d'arbres classiques.
Les arbres binaires présentent deux inconvénients fondamentaux qui les empêchent d'être efficaces en tant que structure de données de disque. Premièrement, le degré de leur équilibre est imprévisible. Il existe un risque considérable d'obtenir des arbres dans lesquels la hauteur des différentes branches peut fortement varier, ce qui aggrave considérablement la complexité algorithmique de la recherche par rapport à ce qui est attendu. Deuxièmement, l'abondance de liens croisés entre nœuds prive les arbres binaires de localité en mémoire : des nœuds proches (en termes de liens entre eux) peuvent être situés sur des pages complètement différentes de la mémoire virtuelle. Par conséquent, même un simple parcours de plusieurs nœuds voisins dans un arbre peut nécessiter la visite d'un nombre comparable de pages. C'est un problème même lorsque nous parlons de l'efficacité des arbres binaires en tant que structure de données en mémoire, car la rotation constante des pages dans le cache du processeur n'est pas bon marché. Lorsqu'il s'agit de générer fréquemment des pages liées aux nœuds à partir du disque, les choses deviennent vraiment mauvaises. .
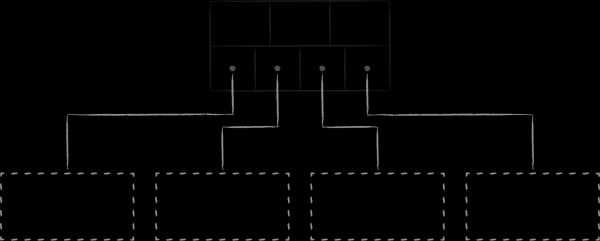 Les arbres B, étant une évolution des arbres binaires, résolvent les problèmes identifiés dans le paragraphe précédent. Premièrement, ils sont auto-équilibrés. Deuxièmement, chacun de leurs nœuds divise l'ensemble des clés enfants non pas en 2, mais en M sous-ensembles ordonnés, et le nombre M peut être assez grand, de l'ordre de plusieurs centaines voire de milliers.
Les arbres B, étant une évolution des arbres binaires, résolvent les problèmes identifiés dans le paragraphe précédent. Premièrement, ils sont auto-équilibrés. Deuxièmement, chacun de leurs nœuds divise l'ensemble des clés enfants non pas en 2, mais en M sous-ensembles ordonnés, et le nombre M peut être assez grand, de l'ordre de plusieurs centaines voire de milliers.
Ainsi:
- Chaque nœud a un grand nombre de clés déjà ordonnées et les arbres sont très petits.
- L'arbre acquiert la propriété de localité en mémoire, puisque des clés de valeur proche sont naturellement situées les unes à côté des autres sur un ou des nœuds voisins.
- Réduit le nombre de nœuds de transit lors de la descente de l'arborescence lors d'une opération de recherche.
- Réduit le nombre de nœuds cibles lus pour les requêtes de plage, puisque chacun d'eux contient déjà un grand nombre de clés ordonnées.
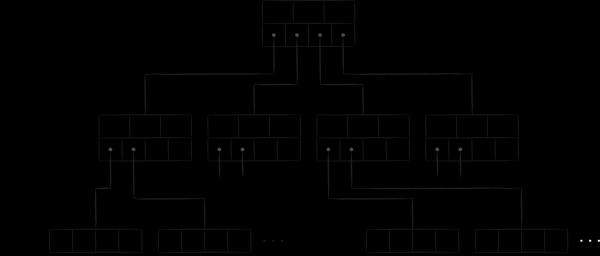
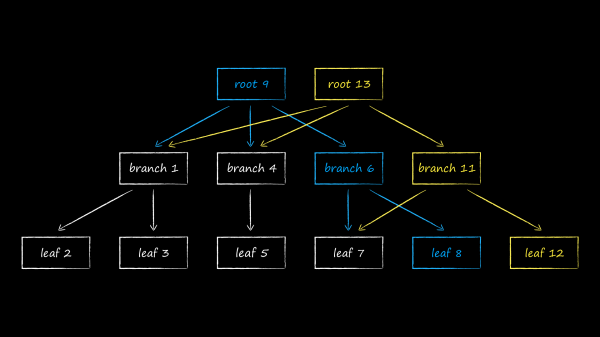
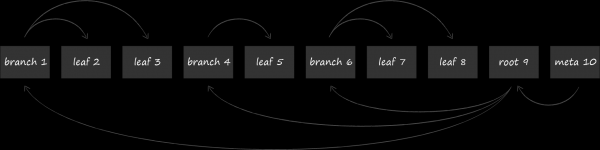
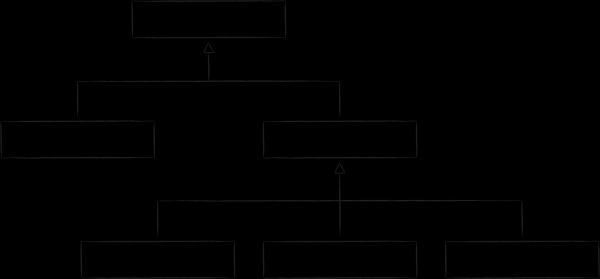
LMDB utilise une variante de l'arbre B appelée arbre B+ pour stocker les données. Le schéma ci-dessus montre les trois types de nœuds qu'il contient :
- Au sommet se trouve la racine. Il ne matérialise rien de plus que le concept d'une base de données au sein d'un référentiel. Dans une seule instance LMDB, vous pouvez créer plusieurs bases de données qui partagent l'espace d'adressage virtuel mappé. Chacun d'eux part de sa propre racine.
- Au niveau le plus bas se trouvent les feuilles (feuille). Ce sont eux et seulement eux qui contiennent les paires clé-valeur stockées dans la base de données. C'est d'ailleurs la particularité des arbres B+. Si un arbre B normal stocke les parties de valeur aux nœuds de tous les niveaux, alors la variation B+ n'est qu'au niveau le plus bas. Ayant corrigé ce fait, dans ce qui suit nous appellerons simplement le sous-type de l'arbre utilisé dans LMDB un B-tree.
- Entre la racine et les feuilles, il y a 0 ou plusieurs niveaux techniques avec des nœuds de navigation (branche). Leur tâche est de diviser le jeu de clés trié entre les feuilles.
Physiquement, les nœuds sont des blocs de mémoire d'une longueur prédéterminée. Leur taille est un multiple de la taille des pages mémoire du système d'exploitation, dont nous avons parlé plus haut. La structure des nœuds est illustrée ci-dessous. L'en-tête contient des méta-informations, dont la plus évidente, par exemple, est la somme de contrôle. Viennent ensuite les informations sur les décalages, le long desquelles se trouvent les cellules contenant des données. Le rôle des données peut être soit des clés, si nous parlons de nœuds de navigation, soit des paires clé-valeur entières dans le cas de feuilles.Vous pouvez en savoir plus sur la structure des pages dans le travail .
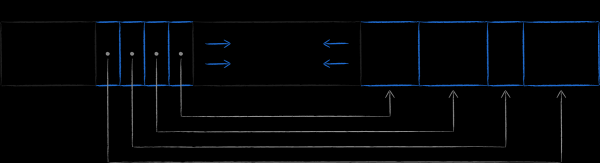
Après avoir traité le contenu interne des nœuds de page, nous allons encore représenter le B-tree LMDB de manière simplifiée sous la forme suivante.
Les pages avec des nœuds sont disposées séquentiellement sur le disque. Les pages avec un numéro plus élevé sont situées vers la fin du fichier. La soi-disant page méta (page méta) contient des informations sur les décalages, qui peuvent être utilisées pour trouver les racines de tous les arbres. Lorsqu'un fichier est ouvert, LMDB scanne le fichier page par page de la fin au début à la recherche d'une métapage valide et trouve des bases de données existantes à travers elle.
Maintenant, ayant une idée de la structure logique et physique de l'organisation des données, nous pouvons passer à la troisième baleine de LMDB. C'est avec son aide que toutes les modifications de stockage se produisent de manière transactionnelle et isolées les unes des autres, donnant à la base de données dans son ensemble également la propriété multiversion.
3.3. Baleine #3. copie sur écriture
Certaines opérations de B-tree impliquent d'apporter toute une série de modifications à ses nœuds. Un exemple consiste à ajouter une nouvelle clé à un nœud qui a déjà atteint sa capacité maximale. Dans ce cas, il est nécessaire, d'une part, de scinder le nœud en deux, et d'autre part, d'ajouter un lien vers le nouveau nœud enfant dérivé dans son parent. Cette procédure est potentiellement très dangereuse. Si, pour une raison quelconque (crash, panne de courant, etc.), seule une partie des modifications de la série se produit, l'arbre restera dans un état incohérent.
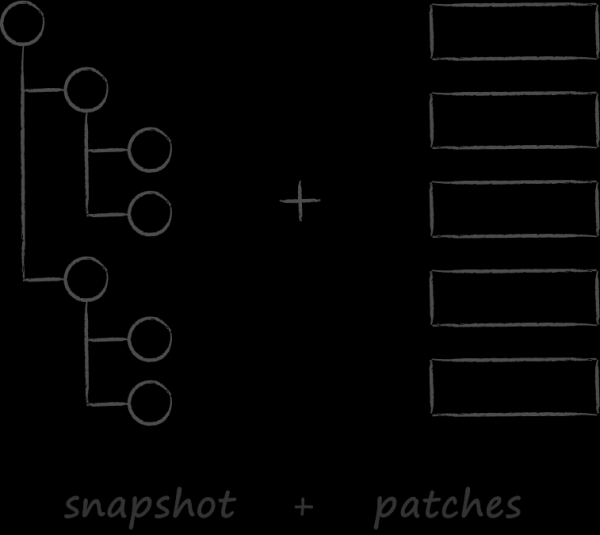
Une solution traditionnelle pour rendre une base de données tolérante aux pannes consiste à ajouter une structure de données supplémentaire sur disque, le journal des transactions, également connu sous le nom de journal d'écriture anticipée (WAL), à côté du B-tree. C'est un fichier à la fin duquel, strictement avant la modification du B-tree lui-même, l'opération envisagée est écrite. Ainsi, si une corruption de données est détectée lors de l'autodiagnostic, la base de données consulte le journal pour se nettoyer.
LMDB a choisi une méthode différente comme mécanisme de tolérance aux pannes, appelée copie sur écriture. Son essence est qu'au lieu de mettre à jour les données sur une page existante, il la copie d'abord entièrement et apporte toutes les modifications déjà dans la copie.
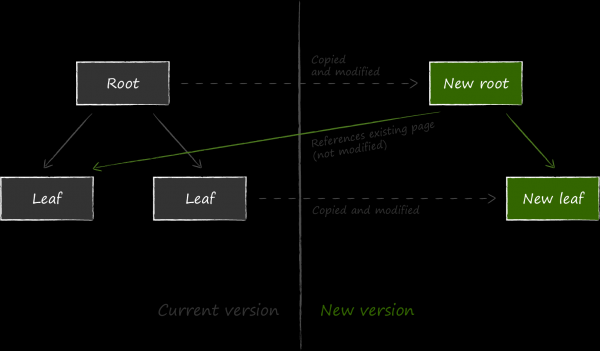
De plus, pour que les données mises à jour soient disponibles, il est nécessaire de changer le lien vers le nœud devenu à jour dans le nœud parent par rapport à celui-ci. Puisqu'il doit également être modifié pour cela, il est également pré-copié. Le processus continue récursivement jusqu'à la racine. Les données de la métapage sont les dernières à changer.
Si soudainement le processus se bloque pendant la procédure de mise à jour, soit une nouvelle page méta ne sera pas créée, soit elle ne sera pas écrite sur le disque jusqu'à la fin, et sa somme de contrôle sera incorrecte. Dans l'un ou l'autre de ces deux cas, les nouvelles pages seront inaccessibles et les anciennes ne seront pas affectées. Cela élimine le besoin pour LMDB d'écrire à l'avance le journal pour maintenir la cohérence des données. De fait, la structure de stockage des données sur le disque, décrite ci-dessus, assume simultanément sa fonction. L'absence de journal de transactions explicite est l'une des caractéristiques de LMDB, qui offre une vitesse de lecture des données élevée.
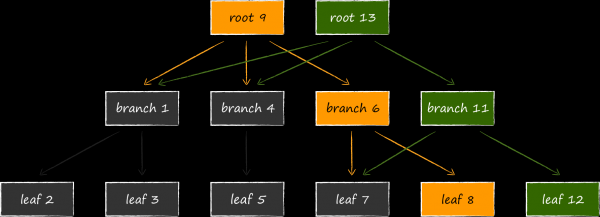
La construction résultante, appelée append-only B-tree, fournit naturellement l'isolation des transactions et le multiversioning. Dans LMDB, chaque transaction ouverte est associée à une racine d'arborescence à jour. Tant que la transaction n'est pas terminée, les pages de l'arborescence qui lui sont associées ne seront jamais modifiées ni réutilisées pour de nouvelles versions de données. Ainsi, vous pouvez travailler aussi longtemps que vous le souhaitez exactement avec le jeu de données qui était pertinent au moment moment où la transaction a été ouverte, même si le stockage continue d'être activement mis à jour à ce moment. C'est l'essence du multiversioning, faisant de LMDB une source de données idéale pour notre bien-aimé UICollectionView. Après avoir ouvert une transaction, vous n'avez pas besoin d'augmenter l'empreinte mémoire de l'application, en pompant à la hâte les données actuelles dans une structure en mémoire, en ayant peur de ne rien avoir. Cette fonctionnalité distingue LMDB du même SQLite, qui ne peut se vanter d'une telle isolation totale. Après avoir ouvert deux transactions dans cette dernière et supprimé un certain enregistrement dans l'une d'elles, le même enregistrement ne peut plus être obtenu dans le second restant.
Le revers de la médaille est la consommation potentiellement significativement plus élevée de mémoire virtuelle. La diapositive montre à quoi ressemblera la structure de la base de données si elle est modifiée en même temps avec 3 transactions de lecture ouvertes examinant différentes versions de la base de données. Étant donné que LMDB ne peut pas réutiliser les nœuds accessibles à partir des racines associées aux transactions réelles, le stockage n'a d'autre choix que d'allouer une autre quatrième racine en mémoire et de cloner à nouveau les pages modifiées sous celle-ci.
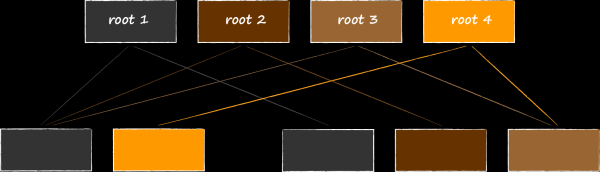
Ici, il ne sera pas superflu de rappeler la section sur les fichiers mappés en mémoire. Il semble que la consommation supplémentaire de mémoire virtuelle ne devrait pas trop nous déranger, puisqu'elle ne contribue pas à l'empreinte mémoire de l'application. Cependant, en même temps, il a été noté qu'iOS est très avare en l'allouant, et nous ne pouvons pas fournir une région LMDB de 1 téraoctet sur un serveur ou un bureau à partir de l'épaule du maître et ne pas penser du tout à cette fonctionnalité. Lorsque cela est possible, vous devez essayer de garder la durée de vie des transactions aussi courte que possible.
4. Concevoir un schéma de données au-dessus de l'API clé-valeur
Commençons par analyser l'API en examinant les abstractions de base fournies par LMDB : environnement et bases de données, clés et valeurs, transactions et curseurs.
Remarque sur les listes de codes
Toutes les fonctions de l'API publique LMDB renvoient le résultat de leur travail sous la forme d'un code d'erreur, mais dans toutes les listes suivantes, sa vérification est omise par souci de concision. En pratique, nous avons utilisé notre propre code pour interagir avec le référentiel. wrappers C++ , dans lequel les erreurs se matérialisent en tant qu'exceptions C++.
Comme moyen le plus rapide de connecter LMDB à un projet pour iOS ou macOS Je propose mon CocoaPod .
4.1. Abstractions de base
Environnement
structure MDB_env C'est le référentiel de l'état interne de la LMDB. Famille de fonctions préfixées mdb_env permet de configurer certaines de ses propriétés. Dans le cas le plus simple, l'initialisation du moteur ressemble à ceci.
mdb_env_create(env);
mdb_env_set_map_size(*env, 1024 * 1024 * 512)
mdb_env_open(*env, path.UTF8String, MDB_NOTLS, 0664);Dans l'application Mail.ru Cloud, nous avons modifié les valeurs par défaut pour seulement deux paramètres.
Le premier est la taille de l'espace d'adressage virtuel auquel le fichier de stockage est mappé. Malheureusement, même sur le même appareil, la valeur spécifique peut varier considérablement d'une exécution à l'autre. Pour prendre en compte cette fonctionnalité d'iOS, nous sélectionnons dynamiquement la quantité maximale de stockage. A partir d'une certaine valeur, il se divise successivement par deux jusqu'à la fonction mdb_env_open ne renverra pas de résultat autre que ENOMEM. En théorie, il existe une manière opposée - d'abord allouer un minimum de mémoire au moteur, puis, lorsque des erreurs sont reçues MDB_MAP_FULL, augmentez-le. Cependant, il est beaucoup plus épineux. La raison en est que la procédure de remappage de la mémoire à l'aide de la fonction mdb_env_set_map_size invalide toutes les entités (curseurs, transactions, clés et valeurs) reçues du moteur plus tôt. La prise en compte d'une telle tournure des événements dans le code conduira à sa complication significative. Si, néanmoins, la mémoire virtuelle vous est très chère, alors cela peut être une raison de regarder le fork qui est allé loin. , où parmi les fonctionnalités déclarées, il y a "l'ajustement automatique à la volée de la taille de la base de données".
Le deuxième paramètre, dont la valeur par défaut ne nous convenait pas, régule la mécanique assurant la sécurité des threads. Malheureusement, au moins dans iOS 10, il y a des problèmes avec la prise en charge du stockage local des threads. Pour cette raison, dans l'exemple ci-dessus, le référentiel est ouvert avec le drapeau MDB_NOTLS. De plus, il fallait aussi wrapper C++ pour couper les variables avec et dans cet attribut.
bases de données
La base de données est une instance distincte de l'arbre B dont nous avons parlé ci-dessus. Son ouverture se produit à l'intérieur d'une transaction, ce qui peut sembler un peu étrange au premier abord.
MDB_txn *txn;
MDB_dbi dbi;
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn);
mdb_dbi_open(txn, NULL, MDB_CREATE, &dbi);
mdb_txn_abort(txn);En effet, une transaction dans LMDB est une entité de stockage, pas une base de données spécifique. Ce concept vous permet d'effectuer des opérations atomiques sur des entités situées dans différentes bases de données. En théorie, cela ouvre la possibilité de modéliser des tables sous la forme de différentes bases de données, mais j'ai une fois fait l'inverse, décrit en détail ci-dessous.
Clés et valeurs
structure MDB_val modélise le concept à la fois d'une clé et d'une valeur. Le référentiel n'a aucune idée de leur sémantique. Pour elle, quelque chose de différent n'est qu'un tableau d'octets d'une taille donnée. La taille de clé maximale est de 512 octets.
typedef struct MDB_val {
size_t mv_size;
void *mv_data;
} MDB_val;Le magasin utilise un comparateur pour trier les clés par ordre croissant. Si vous ne le remplacez pas par le vôtre, celui par défaut sera utilisé, qui les trie octet par octet dans l'ordre lexicographique.
Transactions
Le dispositif de transaction est décrit en détail dans , donc ici je vais répéter leurs principales propriétés en quelques lignes :
- Prise en charge de toutes les propriétés de base : atomicité, cohérence, isolation et fiabilité. Je ne peux m'empêcher de remarquer qu'en termes de durabilité, macOS Un bug d'iOS a été corrigé dans MDBX. Vous trouverez plus d'informations à ce sujet dans leur documentation. .
- L'approche du multithreading est décrite par le schéma « écrivain unique / lecteurs multiples ». Les écrivains se bloquent, mais ils ne bloquent pas les lecteurs. Les lecteurs ne bloquent pas les écrivains ou les uns les autres.
- Prise en charge des transactions imbriquées.
- Prise en charge de plusieurs versions.
Le multiversioning dans LMDB est si bon que je veux le démontrer en action. Le code ci-dessous montre que chaque transaction fonctionne avec exactement la version de la base de données qui était pertinente au moment de son ouverture, étant complètement isolée de toutes les modifications ultérieures. Initialiser le référentiel et y ajouter un enregistrement de test n'a aucun intérêt, donc ces rituels sont laissés sous le spoiler.
Ajout d'une entrée de test
MDB_env *env;
MDB_dbi dbi;
MDB_txn *txn;
mdb_env_create(&env);
mdb_env_open(env, "./testdb", MDB_NOTLS, 0664);
mdb_txn_begin(env, NULL, 0, &txn);
mdb_dbi_open(txn, NULL, 0, &dbi);
mdb_txn_abort(txn);
char k = 'k';
MDB_val key;
key.mv_size = sizeof(k);
key.mv_data = (void *)&k;
int v = 997;
MDB_val value;
value.mv_size = sizeof(v);
value.mv_data = (void *)&v;
mdb_txn_begin(env, NULL, 0, &txn);
mdb_put(txn, dbi, &key, &value, MDB_NOOVERWRITE);
mdb_txn_commit(txn);MDB_txn *txn1, *txn2, *txn3;
MDB_val val;
// Открываем 2 транзакции, каждая из которых смотрит
// на версию базы данных с одной записью.
mdb_txn_begin(env, NULL, 0, &txn1); // read-write
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn2); // read-only
// В рамках первой транзакции удаляем из базы данных существующую в ней запись.
mdb_del(txn1, dbi, &key, NULL);
// Фиксируем удаление.
mdb_txn_commit(txn1);
// Открываем третью транзакцию, которая смотрит на
// актуальную версию базы данных, где записи уже нет.
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn3);
// Убеждаемся, что запись по искомому ключу уже не существует.
assert(mdb_get(txn3, dbi, &key, &val) == MDB_NOTFOUND);
// Завершаем транзакцию.
mdb_txn_abort(txn3);
// Убеждаемся, что в рамках второй транзакции, открытой на момент
// существования записи в базе данных, её всё ещё можно найти по ключу.
assert(mdb_get(txn2, dbi, &key, &val) == MDB_SUCCESS);
// Проверяем, что по ключу получен не абы какой мусор, а валидные данные.
assert(*(int *)val.mv_data == 997);
// Завершаем транзакцию, работающей хоть и с устаревшей, но консистентной базой данных.
mdb_txn_abort(txn2);En option, je recommande d'essayer la même astuce avec SQLite et de voir ce qui se passe.
Le multiversioning apporte de très beaux avantages à la vie d'un développeur iOS. À l'aide de cette propriété, vous pouvez facilement et naturellement ajuster le taux de mise à jour de la source de données pour les écrans en fonction de l'expérience utilisateur. Par exemple, prenons une telle fonctionnalité de l'application Mail.ru Cloud comme le chargement automatique du contenu de la galerie multimédia du système. Avec une bonne connexion, le client est capable d'ajouter plusieurs photos par seconde au serveur. Si vous mettez à jour après chaque téléchargement UICollectionView avec le contenu multimédia dans le cloud de l'utilisateur, vous pouvez oublier environ 60 ips et un défilement fluide pendant ce processus. Pour éviter les mises à jour fréquentes de l'écran, vous devez en quelque sorte limiter le taux de changement de données dans la base UICollectionViewDataSource.
Si la base de données ne prend pas en charge la multiversion et vous permet de travailler uniquement avec l'état actuel actuel, pour créer un instantané de données stable dans le temps, vous devez le copier soit dans une structure de données en mémoire, soit dans une table temporaire. Chacune de ces approches est très coûteuse. Dans le cas du stockage en mémoire, nous obtenons à la fois les coûts de mémoire causés par le stockage des objets construits et les coûts de temps associés aux transformations ORM redondantes. Quant à la table temporaire, c'est un plaisir encore plus cher, qui n'a de sens que dans des cas non triviaux.
Le multiversioning LMDB résout le problème du maintien d'une source de données stable d'une manière très élégante. Il suffit d'ouvrir une transaction et le tour est joué - jusqu'à ce que nous la terminions, l'ensemble de données est garanti d'être corrigé. La logique de son taux de mise à jour est désormais entièrement entre les mains de la couche de présentation, sans surcharge de ressources importantes.
Curseurs
Les curseurs fournissent un mécanisme d'itération ordonnée sur des paires clé-valeur en traversant un arbre B. Sans eux, il serait impossible de modéliser efficacement les tables de la base de données, vers laquelle nous nous tournons maintenant.
4.2. Modélisation de tableaux
La propriété d'ordre des clés vous permet de construire une abstraction de niveau supérieur telle qu'une table au-dessus des abstractions de base. Considérons ce processus sur l'exemple de la table principale du client cloud, dans laquelle les informations sur tous les fichiers et dossiers de l'utilisateur sont mises en cache.
Schéma de tableau
L'un des scénarios courants pour lesquels la structure d'une table avec une arborescence de dossiers doit être affinée consiste à sélectionner tous les éléments situés à l'intérieur d'un répertoire donné. Un bon modèle d'organisation des données pour des requêtes efficaces de ce type est Pour l'implémenter sur un système de stockage clé-valeur, il est nécessaire de trier les clés des fichiers et des dossiers afin qu'elles soient regroupées en fonction de leur répertoire parent. De plus, il faut afficher le contenu du répertoire de manière conviviale. Windows Pour afficher les dossiers (d'abord les dossiers, puis les fichiers, les deux triés par ordre alphabétique), il est nécessaire d'inclure les champs supplémentaires correspondants dans la clé.
L'image ci-dessous montre à quoi peut ressembler, en fonction de la tâche, la représentation des clés sous forme de tableau d'octets. D'abord, les octets avec l'identifiant du répertoire parent (rouge) sont placés, puis avec le type (vert), et déjà dans la queue avec le nom (bleu).Étant triés par le comparateur LMDB par défaut dans l'ordre lexicographique, ils sont ordonnés dans la manière requise. Le parcours séquentiel des clés avec le même préfixe rouge nous donne les valeurs qui leur sont associées dans l'ordre dans lequel elles doivent être affichées dans l'interface utilisateur (à droite), sans nécessiter de post-traitement supplémentaire.

Sérialisation des clés et des valeurs
Il existe de nombreuses méthodes pour sérialiser des objets dans le monde entier. Comme nous n'avions pas d'autre exigence que la vitesse, nous avons choisi la plus rapide possible pour nous-mêmes - un vidage mémoire occupé par une instance de la structure du langage C. Ainsi, la clé d'un élément de répertoire peut être modélisée par la structure suivante NodeKey.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameBuffer[256];
} NodeKey;Sauver NodeKey dans le besoin de stockage dans l'objet MDB_val positionner le pointeur sur les données à l'adresse du début de la structure, et calculer leur taille avec la fonction sizeof.
MDB_val serialize(NodeKey * const key) {
return MDB_val {
.mv_size = sizeof(NodeKey),
.mv_data = (void *)key
};
}Dans le premier chapitre sur les critères de sélection des bases de données, j'ai mentionné la minimisation des allocations dynamiques dans le cadre des opérations CRUD comme un facteur de sélection important. Code de fonction serialize montre comment, dans le cas de LMDB, ils peuvent être complètement évités lorsque de nouveaux enregistrements sont insérés dans la base de données. Le tableau d'octets entrant du serveur est d'abord transformé en structures de pile, puis ils sont trivialement déversés dans le stockage. Étant donné qu'il n'y a pas non plus d'allocations dynamiques à l'intérieur de LMDB, vous pouvez obtenir une situation fantastique selon les normes d'iOS - utilisez uniquement la mémoire de la pile pour travailler avec les données du réseau au disque !
Commander des clés avec un comparateur binaire
La relation d'ordre des clés est donnée par une fonction spéciale appelée comparateur. Le moteur ne sachant rien de la sémantique des octets qu'elles contiennent, le comparateur par défaut n'a d'autre choix que de classer les clés dans l'ordre lexicographique, en recourant à leur comparaison octet par octet. L'utiliser pour organiser des structures s'apparente à se raser avec une hache à découper. Cependant, dans des cas simples, je trouve cette méthode acceptable. L'alternative est décrite ci-dessous, mais ici, je noterai quelques râteaux dispersés le long du chemin.
La première chose à garder à l'esprit est la représentation en mémoire des types de données primitifs. Ainsi, sur tous les appareils Apple, les variables entières sont stockées au format . Cela signifie que l'octet le moins significatif sera à gauche et que vous ne pourrez pas trier les entiers en utilisant leur comparaison octet par octet. Par exemple, si vous essayez de le faire avec un ensemble de nombres de 0 à 511, vous obtiendrez le résultat suivant.
// value (hex dump)
000 (0000)
256 (0001)
001 (0100)
257 (0101)
...
254 (fe00)
510 (fe01)
255 (ff00)
511 (ff01)Pour résoudre ce problème, les entiers doivent être stockés dans la clé dans un format adapté au comparateur d'octets. Les fonctions de la famille aideront à mener à bien la transformation nécessaire. hton* (en particulier htons pour les nombres à deux octets de l'exemple).
Le format de représentation des chaînes en programmation est, comme vous le savez, un tout . Si la sémantique des chaînes, ainsi que l'encodage utilisé pour les représenter en mémoire, suggèrent qu'il peut y avoir plus d'un octet par caractère, alors il vaut mieux abandonner immédiatement l'idée d'utiliser un comparateur par défaut.
La deuxième chose à garder à l'esprit est compilateur de champs struct. Grâce à eux, des octets avec des valeurs parasites peuvent être formés en mémoire entre les champs, ce qui, bien sûr, interrompt le tri des octets. Pour éliminer les ordures, vous devez soit déclarer les champs dans un ordre strictement défini, en gardant à l'esprit les règles d'alignement, soit utiliser l'attribut dans la déclaration de structure packed.
Commande des clés par un comparateur externe
La logique de comparaison clé peut s'avérer trop complexe pour un comparateur binaire. L'une des nombreuses raisons est la présence de champs techniques à l'intérieur des structures. J'illustrerai leur occurrence sur l'exemple d'une clé qui nous est déjà familière pour un élément de répertoire.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameBuffer[256];
} NodeKey;Malgré toute sa simplicité, dans la grande majorité des cas, il consomme trop de mémoire. Le tampon de titre est de 256 octets, bien qu'en moyenne les noms de fichiers et de dossiers dépassent rarement 20 à 30 caractères.
L'une des techniques standard pour optimiser la taille d'un enregistrement consiste à le couper pour l'adapter à sa taille réelle. Son essence est que le contenu de tous les champs de longueur variable est stocké dans un tampon à la fin de la structure, et leurs longueurs sont stockées dans des variables séparées. Conformément à cette approche, la clé NodeKey se transforme de la manière suivante.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeKey;De plus, lors de la sérialisation, non spécifié comme la taille des données sizeof la structure entière, et la taille de tous les champs est une longueur fixe plus la taille de la partie réellement utilisée du tampon.
MDB_val serialize(NodeKey * const key) {
return MDB_val {
.mv_size = offsetof(NodeKey, nameBuffer) + key->nameLength,
.mv_data = (void *)key
};
}À la suite de la refactorisation, nous avons obtenu une économie importante dans l'espace occupé par les clés. Cependant, en raison du domaine technique nameLength, le comparateur binaire par défaut n'est plus adapté à la comparaison clé. Si nous ne le remplaçons pas par le nôtre, la longueur du nom sera un facteur de tri plus prioritaire que le nom lui-même.
LMDB permet à chaque base de données d'avoir sa propre fonction de comparaison clé. Cela se fait à l'aide de la fonction mdb_set_compare strictement avant l'ouverture. Pour des raisons évidentes, une base de données ne peut pas être modifiée tout au long de sa vie. En entrée, le comparateur reçoit deux clés au format binaire, et en sortie il renvoie le résultat de la comparaison : inférieur à (-1), supérieur à (1) ou égal à (0). Pseudocode pour NodeKey Ressemble à ça.
int compare(MDB_val * const a, MDB_val * const b) {
NodeKey * const aKey = (NodeKey * const)a->mv_data;
NodeKey * const bKey = (NodeKey * const)b->mv_data;
return // ...
}Tant que toutes les clés de la base de données sont du même type, il est légal de convertir inconditionnellement leur représentation en octets en type de la structure d'application de la clé. Il y a une nuance ici, mais elle sera abordée un peu plus bas dans la sous-section « Lecture des enregistrements ».
Sérialisation de la valeur
Avec les clés des enregistrements stockés, LMDB travaille de manière extrêmement intensive. Ils sont comparés entre eux dans le cadre de toute opération applicative, et les performances de l'ensemble de la solution dépendent de la rapidité du comparateur. Dans un monde idéal, le comparateur binaire par défaut devrait suffire à comparer les clés, mais si vous deviez vraiment utiliser le vôtre, la procédure de désérialisation des clés devrait être aussi rapide que possible.
La base de données n'est pas particulièrement intéressée par la partie Valeur de l'enregistrement (valeur). Sa conversion d'une représentation byte en objet ne se produit que lorsqu'elle est déjà requise par le code de l'application, par exemple pour l'afficher à l'écran. Comme cela se produit relativement rarement, les exigences de rapidité de cette procédure ne sont pas si critiques et, dans sa mise en œuvre, nous sommes beaucoup plus libres de nous concentrer sur la commodité. Par exemple, pour sérialiser les métadonnées sur les fichiers qui n'ont pas encore été téléchargés, nous utilisons NSKeyedArchiver.
NSData *data = serialize(object);
MDB_val value = {
.mv_size = data.length,
.mv_data = (void *)data.bytes
};Cependant, il y a des moments où les performances comptent. Par exemple, lors de l'enregistrement de méta-informations sur la structure de fichiers du cloud utilisateur, nous utilisons le même vidage de mémoire d'objet. Le point culminant de la tâche de génération de leur représentation sérialisée est le fait que les éléments d'un répertoire sont modélisés par une hiérarchie de classes.
Pour son implémentation dans le langage C, les champs spécifiques des héritiers sont sortis dans des structures séparées, et leur connexion avec celle de base est spécifiée à travers un champ de type union. Le contenu réel de l'union est spécifié via l'attribut technique type.
typedef struct NodeValue {
EntityId localId;
EntityType type;
union {
FileInfo file;
DirectoryInfo directory;
} info;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeValue;Ajouter et mettre à jour des entrées
La clé et la valeur sérialisées peuvent être ajoutées au magasin. Pour cela, la fonction est utilisée mdb_put.
// key и value имеют тип MDB_val
mdb_put(..., &key, &value, MDB_NOOVERWRITE);Au stade de la configuration, le référentiel peut être autorisé ou interdit de stocker plusieurs enregistrements avec la même clé. Si la duplication des clés est interdite, alors lors de l'insertion d'un enregistrement, vous pouvez déterminer si la mise à jour d'un enregistrement déjà existant est autorisée ou non. Si l'effilochage ne peut se produire qu'à la suite d'une erreur dans le code, vous pouvez vous en assurer en spécifiant le drapeau NOOVERWRITE.
Lire des enregistrements
La fonction de lecture des enregistrements dans LMDB est mdb_get. Si la paire clé-valeur est représentée par des structures précédemment vidées, cette procédure ressemble à ceci.
NodeValue * const readNode(..., NodeKey * const key) {
MDB_val rawKey = serialize(key);
MDB_val rawValue;
mdb_get(..., &rawKey, &rawValue);
return (NodeValue * const)rawValue.mv_data;
}La liste présentée montre comment la sérialisation via un vidage de structures vous permet de vous débarrasser des allocations dynamiques non seulement lors de l'écriture, mais lors de la lecture des données. Dérivé de la fonction mdb_get le pointeur regarde exactement l'adresse de la mémoire virtuelle où la base de données stocke la représentation en octets de l'objet. En fait, nous obtenons une sorte d'ORM, quasi-gratuit offrant une très grande vitesse de lecture des données. Avec toute la beauté de l'approche, il est nécessaire de rappeler plusieurs caractéristiques qui y sont associées.
- Pour une transaction en lecture seule, un pointeur vers une structure de valeur est garanti pour rester valide uniquement jusqu'à ce que la transaction soit fermée. Comme indiqué précédemment, les pages du B-tree sur lesquelles réside l'objet, grâce au principe de copie sur écriture, restent inchangées tant qu'au moins une transaction y fait référence. Parallèlement, dès que la dernière transaction qui leur est associée est terminée, les pages peuvent être réutilisées pour de nouvelles données. S'il est nécessaire que les objets survivent à la transaction qui les a créés, ils doivent encore être copiés.
- Pour une transaction en lecture-écriture, le pointeur vers la valeur-structure résultante ne sera valide que jusqu'à la première procédure de modification (écriture ou suppression de données).
- Même si la structure
NodeValuepas à part entière, mais rogné (voir sous-section "Commande de clés par un comparateur externe"), via le pointeur, vous pouvez facilement accéder à ses champs. L'essentiel est de ne pas le déréférencer ! - Vous ne pouvez en aucun cas modifier la structure via le pointeur reçu. Toutes les modifications doivent être effectuées uniquement via la méthode
mdb_put. Cependant, avec tout le désir de le faire, cela ne fonctionnera pas, car la zone de mémoire où se trouve cette structure est mappée en mode lecture seule. - Remappez un fichier sur l'espace d'adressage d'un processus afin, par exemple, d'augmenter la taille de stockage maximale à l'aide de la fonction
mdb_env_set_map_sizeinvalide complètement toutes les transactions et les entités associées en général et les pointeurs pour lire les objets en particulier.
Enfin, une autre caractéristique est si insidieuse que la divulgation de son essence ne rentre pas dans un seul point de plus. Dans le chapitre sur le B-tree, j'ai donné un schéma de l'organisation de ses pages en mémoire. Il s'ensuit que l'adresse du début du tampon avec des données sérialisées peut être absolument arbitraire. De ce fait, le pointeur vers eux, obtenu dans la structure MDB_val et converti en un pointeur vers une structure est généralement non aligné. Dans le même temps, les architectures de certaines puces (dans le cas d'iOS, il s'agit d'armv7) exigent que l'adresse de toute donnée soit un multiple de la taille d'un mot machine, ou, en d'autres termes, du nombre de bits du système (pour armv7, c'est 32 bits). Autrement dit, une opération comme *(int *foo)0x800002 sur eux est assimilé à s'échapper et conduit à l'exécution avec un verdict EXC_ARM_DA_ALIGN. Il y a deux façons d'éviter un si triste sort.
La première consiste à copier au préalable les données dans une structure alignée connue. Par exemple, sur un comparateur personnalisé, cela se reflétera comme suit.
int compare(MDB_val * const a, MDB_val * const b) {
NodeKey aKey, bKey;
memcpy(&aKey, a->mv_data, a->mv_size);
memcpy(&bKey, b->mv_data, b->mv_size);
return // ...
}Une autre méthode consiste à informer le compilateur à l'avance que les structures avec une clé et une valeur peuvent ne pas être alignées à l'aide d'un attribut aligned(1). Sur ARM, le même effet peut être et en utilisant l'attribut emballé. Considérant qu'elle contribue également à l'optimisation de l'espace occupé par la structure, cette méthode me semble préférable, bien que augmenter le coût des opérations d'accès aux données.
typedef struct __attribute__((packed)) NodeKey {
uint8_t parentId;
uint8_t type;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeKey;Requêtes de plage
Pour parcourir un groupe d'enregistrements, LMDB fournit une abstraction de curseur. Voyons comment l'utiliser en utilisant l'exemple d'une table avec des métadonnées de cloud utilisateur qui nous sont déjà familières.
Dans le cadre de l'affichage d'une liste de fichiers dans un répertoire, vous devez trouver toutes les clés auxquelles ses fichiers et dossiers enfants sont associés. Dans les sous-sections précédentes, nous avons trié les clés NodeKey afin qu'ils soient d'abord triés par leur ID de répertoire parent. Ainsi, techniquement, la tâche d'obtenir le contenu d'un dossier se réduit à placer le curseur sur la limite supérieure d'un groupe de clés avec un préfixe donné, suivi d'une itération jusqu'à la limite inférieure.

Vous pouvez trouver la limite supérieure "sur le front" par recherche séquentielle. Pour ce faire, le curseur est placé au début de toute la liste des clés de la base de données, puis incrémenté jusqu'à ce que la clé avec l'identifiant du répertoire parent apparaisse en dessous. Cette approche présente 2 inconvénients évidents :
- La complexité linéaire de la recherche, bien que, comme vous le savez, dans les arbres en général et dans un B-tree en particulier, elle puisse se faire en temps logarithmique.
- En vain, toutes les pages précédant celle souhaitée sont remontées du fichier vers la mémoire principale, ce qui est extrêmement coûteux.
Heureusement, l'API LMDB fournit un moyen efficace pour positionner initialement le curseur. Pour ce faire, vous devez former une telle clé, dont la valeur sera certainement inférieure ou égale à la clé située sur la borne supérieure de l'intervalle . Par exemple, par rapport à la liste de la figure ci-dessus, on peut faire une clé dans laquelle le champ parentId sera égal à 2, et tout le reste est rempli de zéros. Une telle clé partiellement remplie est envoyée à l'entrée de la fonction mdb_cursor_get indiquant le fonctionnement MDB_SET_RANGE.
NodeKey upperBoundSearchKey = {
.parentId = 2,
.type = 0,
.nameLength = 0
};
MDB_val value, key = serialize(upperBoundSearchKey);
MDB_cursor *cursor;
mdb_cursor_open(..., &cursor);
mdb_cursor_get(cursor, &key, &value, MDB_SET_RANGE);Si la limite supérieure du groupe de clés est trouvée, alors nous itérons dessus jusqu'à ce que nous rencontrions ou la clé avec une autre parentId, ou les clés ne s'épuiseront pas du tout.
do {
rc = mdb_cursor_get(cursor, &key, &value, MDB_NEXT);
// processing...
} while (MDB_NOTFOUND != rc && // check end of table
IsTargetKey(key)); // check end of keys groupCe qui est bien, dans le cadre de l'itération à l'aide de mdb_cursor_get, nous obtenons non seulement la clé, mais également la valeur. Si, pour remplir les conditions de sélection, il est nécessaire de vérifier, entre autres, les champs de la partie valeur de l'enregistrement, ils sont alors tout à fait accessibles à eux-mêmes sans gestes supplémentaires.
4.3. Modélisation des relations entre les tables
À ce jour, nous avons réussi à prendre en compte tous les aspects de la conception et de l'utilisation d'une base de données à table unique. Nous pouvons dire qu'une table est un ensemble d'enregistrements triés constitués de paires clé-valeur du même type. Si vous affichez une clé sous forme de rectangle et sa valeur associée sous forme de boîte, vous obtenez un schéma visuel de la base de données.
![]()
Cependant, dans la vraie vie, il est rarement possible de s'en sortir avec si peu de sang. Souvent, dans une base de données, il est nécessaire, d'une part, d'avoir plusieurs tables, et d'autre part, d'y effectuer des sélections dans un ordre différent de la clé primaire. Cette dernière section est consacrée aux enjeux de leur création et de leur interconnexion.
Tableaux d'index
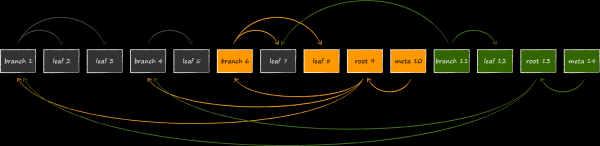
L'application cloud a une section "Galerie". Il affiche le contenu multimédia de l'ensemble du cloud, trié par date. Pour une mise en œuvre optimale d'une telle sélection, à côté de la table principale, vous devez en créer une autre avec un nouveau type de clés. Ils contiendront un champ avec la date de création du fichier, qui servira de critère de tri principal. Étant donné que les nouvelles clés font référence aux mêmes données que les clés de la table sous-jacente, elles sont appelées clés d'index. Ils sont surlignés en orange dans l'image ci-dessous.
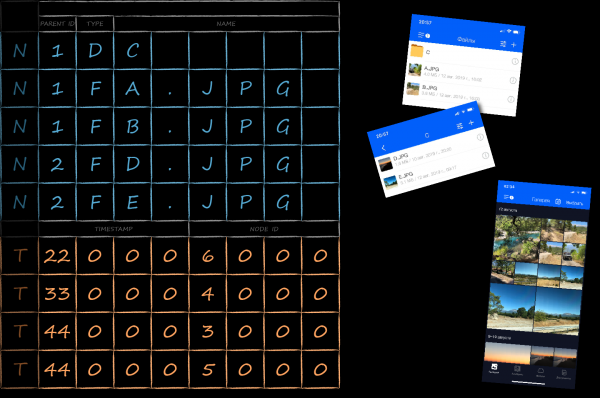
Afin de séparer les clés des différentes tables les unes des autres au sein d'une même base de données, un champ technique supplémentaire tableId a été ajouté à toutes. En en faisant la priorité la plus élevée pour le tri, nous regrouperons d'abord les clés par tables, et déjà à l'intérieur des tables - selon nos propres règles.
La clé d'index fait référence aux mêmes données que la clé primaire. L'implémentation simple de cette propriété en lui associant une copie de la partie valeur de la clé primaire est sous-optimale de plusieurs points de vue à la fois :
- Du point de vue de l'espace occupé, les métadonnées peuvent être assez riches.
- D'un point de vue performance, puisque lors de la mise à jour des métadonnées du nœud, vous devrez écraser deux clés.
- Du point de vue de la prise en charge du code, après tout, si nous oublions de mettre à jour les données pour l'une des clés, nous aurons un bogue subtil d'incohérence des données dans le stockage.
Ensuite, nous verrons comment éliminer ces lacunes.
Organisation des relations entre les tables
Le modèle est bien adapté pour lier une table d'index avec la table principale "clé comme valeur". Comme son nom l'indique, la partie valeur de l'enregistrement d'index est une copie de la valeur de la clé primaire. Cette approche élimine tous les inconvénients énumérés ci-dessus associés au stockage d'une copie de la partie valeur de l'enregistrement principal. Le seul frais est que pour obtenir la valeur par la clé d'index, vous devez effectuer 2 requêtes à la base de données au lieu d'une. Schématiquement, le schéma de base de données résultant est le suivant.
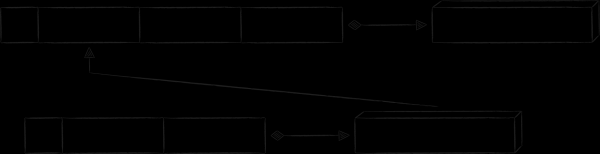
Un autre modèle d'organisation des relations entre les tables est "clé redondante". Son essence est d'ajouter des attributs supplémentaires à la clé, qui sont nécessaires non pas pour le tri, mais pour recréer la clé associée. Il existe cependant de vrais exemples de son utilisation dans l'application Mail.ru Cloud, afin d'éviter de plonger profondément dans le contexte de cadres iOS spécifiques, je vais donner un exemple fictif, mais plus compréhensible.
Les clients mobiles cloud ont une page qui affiche tous les fichiers et dossiers que l'utilisateur a partagés avec d'autres personnes. Étant donné qu'il existe relativement peu de fichiers de ce type et qu'il existe de nombreuses informations spécifiques sur la publicité qui leur est associée (à qui l'accès est accordé, avec quels droits, etc.), il ne sera pas rationnel de le surcharger avec la partie valeur de l'entrée dans la table principale. Cependant, si vous souhaitez afficher ces fichiers hors ligne, vous devez toujours les stocker quelque part. Une solution naturelle consiste à créer une table séparée pour cela. Dans le schéma ci-dessous, sa clé est préfixée par "P", et l'espace réservé "propname" peut être remplacé par la valeur plus spécifique "public info".
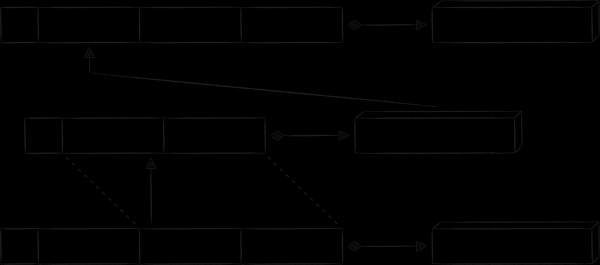
Toutes les métadonnées uniques, pour lesquelles la nouvelle table a été créée, sont déplacées vers la partie valeur de l'enregistrement. En même temps, je ne veux pas dupliquer les données sur les fichiers et dossiers qui sont déjà stockés dans la table principale. Au lieu de cela, des données redondantes sont ajoutées à la clé "P" sous la forme des champs "ID de nœud" et "horodatage". Grâce à eux, vous pouvez construire une clé d'index, par laquelle vous pouvez obtenir la clé primaire, par laquelle, enfin, vous pouvez obtenir les métadonnées du nœud.
Conclusion
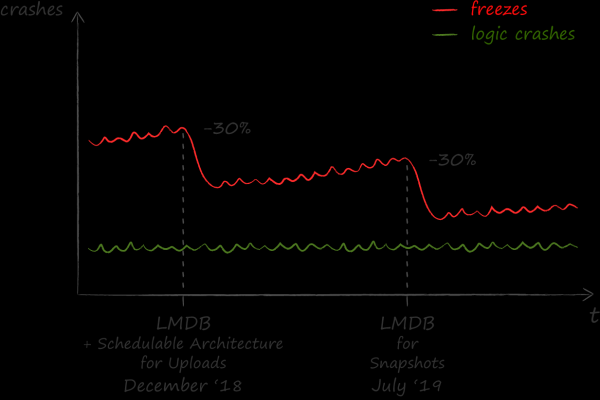
Nous évaluons positivement les résultats de la mise en œuvre de la LMDB. Après cela, le nombre de gels d'applications a diminué de 30 %.
Les résultats de ce travail ont trouvé un écho bien au-delà de l'équipe iOS. Actuellement, l'une des principales sections de l'application « Fichiers » est concernée. Android J'ai également opté pour LMDB, et d'autres éléments suivront. Le langage C, dans lequel le système de stockage clé-valeur est implémenté, a constitué un bon point de départ pour la création initiale d'un framework d'application multiplateforme en C++. Un générateur de code a permis d'intégrer facilement la bibliothèque C++ ainsi obtenue au code natif Objective-C et Kotlin. de Dropbox, mais c'est une autre histoire.
Source: habr.com
