

Noter. trad.: Cette histoire révélatrice d'Omio, un agrégateur de voyages européen, emmène les lecteurs de la théorie de base aux fascinantes subtilités pratiques de la configuration de Kubernetes. La connaissance de tels cas permet non seulement d'élargir vos horizons, mais également d'éviter des problèmes non triviaux.
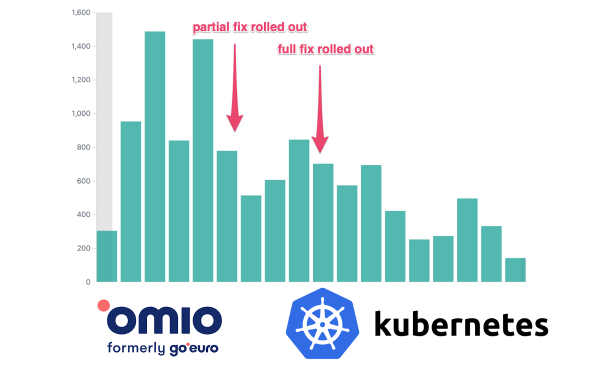
Avez-vous déjà vu une application rester bloquée, cesser de répondre aux contrôles de santé et ne pas comprendre pourquoi ? Une explication possible est liée aux limites de quota de ressources CPU. C'est ce dont nous parlerons dans cet article.
TL; DR:
Nous recommandons fortement de désactiver les limites de CPU dans Kubernetes (ou de désactiver les quotas CFS dans Kubelet) si vous utilisez une version du noyau Linux avec une erreur de quota CFS. Dans le noyau sérieux et un bug qui entraîne une limitation et des retards excessifs.
Sur Omio toute l'infrastructure est gérée par Kubernetes. Toutes nos charges de travail avec et sans état s'exécutent exclusivement sur Kubernetes (nous utilisons Google Kubernetes Engine). Au cours des six derniers mois, nous avons commencé à observer des ralentissements aléatoires. Les applications se bloquent ou cessent de répondre aux contrôles de santé, perdent la connexion au réseau, etc. Ce comportement nous a longtemps intrigués et nous avons finalement décidé de prendre le problème au sérieux.
Résumé de l'article:
- Quelques mots sur les conteneurs et Kubernetes ;
- Comment les demandes et les limites du processeur sont mises en œuvre ;
- Comment fonctionne la limite du processeur dans les environnements multicœurs ;
- Comment suivre la limitation du processeur ;
- Solution du problème et nuances.
Quelques mots sur les conteneurs et Kubernetes
Kubernetes est essentiellement la norme moderne dans le monde des infrastructures. Sa tâche principale est l'orchestration des conteneurs.
Containers
Dans le passé, nous devions créer des artefacts tels que des JAR/WAR Java, des Python Eggs ou des exécutables à exécuter sur des serveurs. Cependant, pour les faire fonctionner, un travail supplémentaire a dû être effectué : installer l'environnement d'exécution (Java/Python), placer les fichiers nécessaires aux bons endroits, s'assurer de la compatibilité avec une version spécifique du système d'exploitation, etc. En d’autres termes, il fallait prêter une attention particulière à la gestion de la configuration (qui était souvent source de conflits entre développeurs et administrateurs système).
Les conteneurs ont tout changé. L'artefact est désormais une image conteneur. Il peut être représenté comme une sorte de fichier exécutable étendu contenant non seulement le programme, mais également un environnement d'exécution à part entière (Java/Python/...), ainsi que les fichiers/packages nécessaires, préinstallés et prêts à être utilisés. courir. Les conteneurs peuvent être déployés et exécutés sur différents serveurs sans aucune étape supplémentaire.
De plus, les conteneurs s'exécutent dans leur propre environnement isolé. Ils disposent de leur propre carte réseau virtuelle, de leur propre système de fichiers à accès restreint, de leur propre hiérarchie de processus, de leurs propres limites de processeur et de mémoire, etc. Tout cela est implémenté grâce à un sous-système du noyau dédié. Linux — espaces de noms.
Kubernetes
Comme indiqué précédemment, Kubernetes est un orchestrateur de conteneurs. Cela fonctionne comme ceci : vous lui donnez un pool de machines, puis dites : « Hé, Kubernetes, lançons dix instances de mon conteneur avec 2 processeurs et 3 Go de mémoire chacune, et faisons-les fonctionner ! Kubernetes s'occupera du reste. Il va trouver de la capacité libre, lancer des conteneurs et les redémarrer si nécessaire, déployer une mise à jour lors d'un changement de version, etc. Essentiellement, Kubernetes vous permet d'abstraire le composant matériel et de créer une grande variété de systèmes adaptés au déploiement et à l'exécution d'applications.
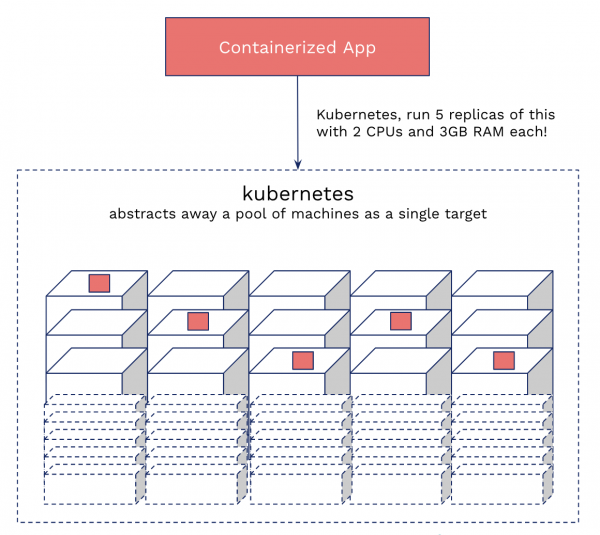
Kubernetes du point de vue du profane
Que sont les requêtes et les limites dans Kubernetes
D'accord, nous avons couvert les conteneurs et Kubernetes. Nous savons également que plusieurs conteneurs peuvent résider sur la même machine.
Une analogie peut être faite avec un appartement communal. Un local spacieux (machines/unités) est pris et loué à plusieurs locataires (conteneurs). Kubernetes agit en tant qu'agent immobilier. La question se pose, comment éviter les conflits entre locataires ? Et si l’un d’eux, par exemple, décide d’emprunter la salle de bain pour une demi-journée ?
C’est là qu’interviennent les demandes et les limites. CPU Demander nécessaire uniquement à des fins de planification. C'est quelque chose comme une « liste de souhaits » du conteneur, et elle est utilisée pour sélectionner le nœud le plus approprié. En même temps le CPU Limiter peut être comparé à un contrat de location - dès que nous sélectionnons une unité pour le conteneur, le ne sera pas capable dépasser les limites établies. Et c'est là que le problème se pose...
Comment les requêtes et les limites sont implémentées dans Kubernetes
Kubernetes utilise un mécanisme de limitation (saut de cycles d'horloge) intégré au noyau pour implémenter les limites du processeur. Si une application dépasse la limite, la limitation est activée (c'est-à-dire qu'elle reçoit moins de cycles CPU). Les demandes et les limites de mémoire sont organisées différemment, elles sont donc plus faciles à détecter. Pour cela, il suffit de vérifier le dernier statut de redémarrage du pod : s'il est « OOMKilled ». La limitation du processeur n'est pas si simple, puisque K8 ne rend les métriques disponibles que par utilisation, et non par groupes de contrôle.
Demande de processeur
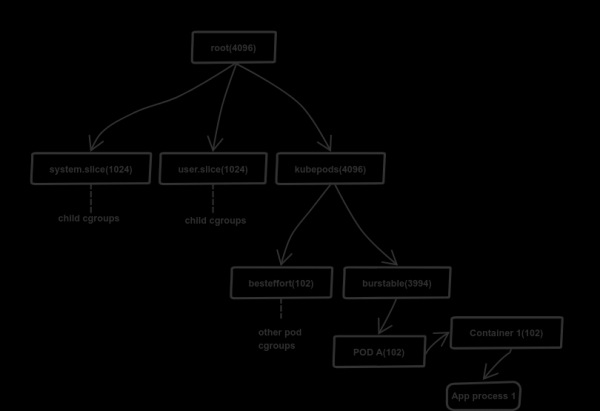
Comment la requête CPU est implémentée
Pour plus de simplicité, examinons le processus en utilisant comme exemple une machine dotée d'un processeur à 4 cœurs.
K8s utilise un mécanisme de groupe de contrôle (cgroups) pour contrôler l'allocation des ressources (mémoire et processeur). Un modèle hiérarchique lui est proposé : l'enfant hérite des limites du groupe parent. Les détails de la distribution sont stockés dans un système de fichiers virtuel (/sys/fs/cgroup). Dans le cas d'un processeur, c'est /sys/fs/cgroup/cpu,cpuacct/*.
K8s utilise un fichier cpu.share pour allouer les ressources du processeur. Dans notre cas, le groupe de contrôle racine obtient 4096 100 parts de ressources CPU, soit 1 % de la puissance du processeur disponible (1024 cœur = XNUMX XNUMX ; il s'agit d'une valeur fixe). Le groupe racine répartit les ressources proportionnellement en fonction des parts des descendants inscrits dans cpu.share, et eux, à leur tour, font de même avec leurs descendants, etc. Sur un nœud Kubernetes typique, le groupe de contrôle racine a trois enfants : system.slice, user.slice и kubepods. Les deux premiers sous-groupes sont utilisés pour répartir les ressources entre les charges système critiques et les programmes utilisateur en dehors des K8. Le dernier - kubepods — créé par Kubernetes pour distribuer les ressources entre les pods.
Le diagramme ci-dessus montre que le premier et le deuxième sous-groupes ont reçu chacun 1024 partages, avec le sous-groupe kuberpod attribué 4096 actions Comment est-ce possible : après tout, le groupe racine n'a accès qu'à 4096 actions, et la somme des actions de ses descendants dépasse largement ce nombre (6144L'important est que la valeur ait une signification logique, donc le planificateur Linux (CFS) l'utilise pour répartir proportionnellement les ressources du processeur. Dans notre cas, les deux premiers groupes reçoivent 680 actions réelles (16,6% de 4096), et kubepod reçoit le reste 2736 actions En cas d'indisponibilité, les deux premiers groupes n'utiliseront pas les ressources allouées.
Heureusement, le planificateur dispose d'un mécanisme pour éviter de gaspiller les ressources CPU inutilisées. Il transfère la capacité « inactive » vers un pool global, à partir duquel elle est distribuée aux groupes ayant besoin de puissance de processeur supplémentaire (le transfert s'effectue par lots pour éviter les pertes d'arrondi). Une méthode similaire est appliquée à tous les descendants des descendants.
Ce mécanisme garantit une répartition équitable de la puissance du processeur et garantit qu'aucun processus ne « vole » les ressources des autres.
Limite du processeur
Malgré le fait que les configurations de limites et de requêtes dans les K8 se ressemblent, leur mise en œuvre est radicalement différente : le plus trompeur et la partie la moins documentée.
Les K8 s'engagent pour mettre en œuvre des limites. Leurs paramètres sont spécifiés dans des fichiers cfs_period_us и cfs_quota_us dans le répertoire cgroup (le fichier s'y trouve également cpu.share).
Contrairement à cpu.share, le quota est basé sur période de temps, et non sur la puissance disponible du processeur. cfs_period_us spécifie la durée de la période (époque) - elle est toujours de 100000 100 μs (8 ms). Il existe une option pour modifier cette valeur dans KXNUMX, mais elle n'est disponible qu'en alpha pour le moment. Le planificateur utilise l'époque pour redémarrer les quotas utilisés. Deuxième fichier cfs_quota_us, spécifie le temps disponible (quota) à chaque époque. Notez qu'il est également spécifié en microsecondes. Le quota peut dépasser la durée de l'époque ; autrement dit, elle peut être supérieure à 100 ms.
Examinons deux scénarios sur des machines à 16 cœurs (le type d'ordinateur le plus courant dont nous disposons chez Omio) :

Scénario 1 : 2 threads et une limite de 200 ms. Pas de limitation
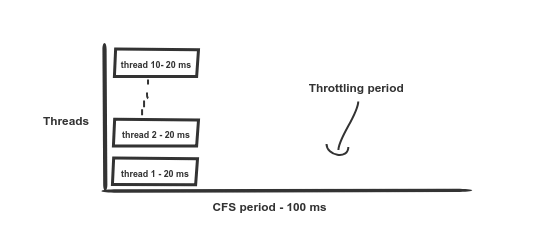
Scénario 2 : 10 threads et limite de 200 ms. La limitation commence après 20 ms, l'accès aux ressources du processeur reprend après 80 ms supplémentaires
Disons que vous définissez la limite du processeur sur 2 graines; Kubernetes traduira cette valeur en 200 ms. Cela signifie que le conteneur peut utiliser un maximum de 200 ms de temps CPU sans limitation.
Et c'est là que le plaisir commence. Comme mentionné ci-dessus, le quota disponible est de 200 ms. Si vous travaillez en parallèle dix threads sur une machine à 12 cœurs (voir illustration du scénario 2), alors que tous les autres pods sont inactifs, le quota sera épuisé en seulement 20 ms (puisque 10 * 20 ms = 200 ms), et tous les threads de ce pod se bloqueront » (Manette de Gaz) pour les 80 prochaines ms. Le déjà mentionné , à cause de quoi une limitation excessive se produit et le conteneur ne peut même pas remplir le quota existant.
Comment évaluer la limitation dans les pods ?
Connectez-vous simplement au pod et exécutez cat /sys/fs/cgroup/cpu/cpu.stat.
-
nr_periods— le nombre total de périodes de planification ; -
nr_throttled— nombre de périodes limitées dans la compositionnr_periods; -
throttled_time— temps de limitation cumulé en nanosecondes.
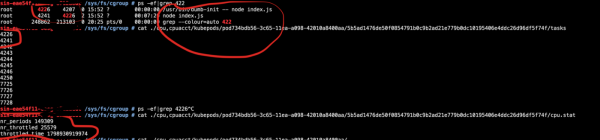
Que se passe-t-il réellement ?
En conséquence, nous obtenons une limitation élevée dans toutes les applications. Parfois, il est dans une fois et demie plus fort que prévu !
Cela entraîne diverses erreurs : échecs du contrôle de préparation, gels des conteneurs, ruptures de connexion réseau, délais d'attente lors des appels de service. Cela se traduit finalement par une latence accrue et des taux d’erreur plus élevés.
Décision et conséquences
Tout est simple ici. Nous avons abandonné les limites du processeur et commencé à mettre à jour le noyau du système d'exploitation en cluster vers la dernière version, dans laquelle le bug a été corrigé. Le nombre d'erreurs (HTTP 5xx) dans nos services a immédiatement diminué de manière significative :
Erreurs HTTP 5xx
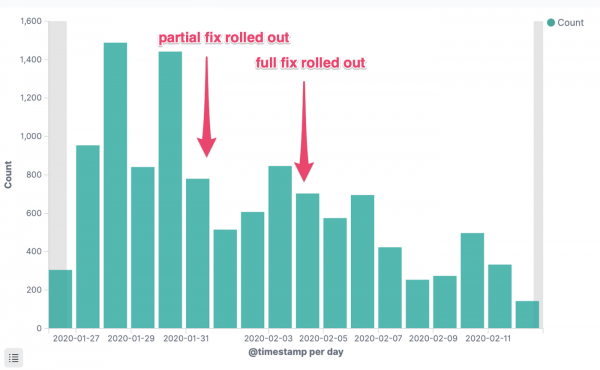
Erreurs HTTP 5xx pour un service critique
Temps de réponse p95
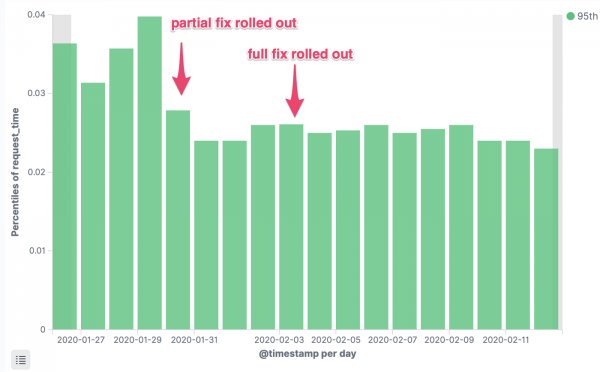
Latence des demandes de service critiques, 95e percentile
Les coûts d'exploitation
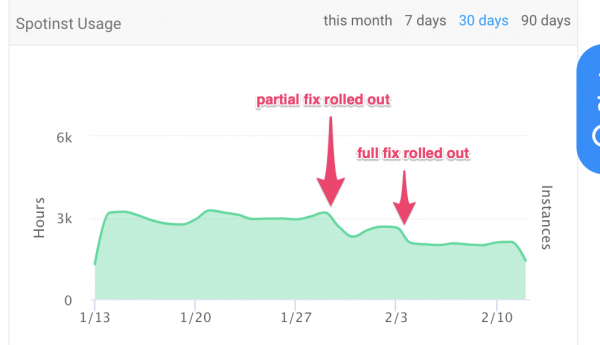
Nombre d'heures d'instance passées
Quel est le piège?
Comme indiqué au début de l'article :
Une analogie peut être faite avec un appartement communal... Kubernetes agit en tant qu'agent immobilier. Mais comment éviter les conflits entre locataires ? Et si l’un d’eux, par exemple, décide d’emprunter la salle de bain pour une demi-journée ?
Voici le piège. Un conteneur imprudent peut consommer toutes les ressources CPU disponibles sur une machine. Si vous disposez d'une pile d'applications intelligente (par exemple, JVM, Go, Node VM sont correctement configurés), alors ce n'est pas un problème : vous pouvez travailler longtemps dans de telles conditions. Mais si les applications sont mal optimisées ou pas optimisées du tout (FROM java:latest), la situation pourrait devenir incontrôlable. Chez Omio, nous avons des Dockerfiles de base automatisés avec des paramètres par défaut adéquats pour la principale pile de langues, ce problème n'existait donc pas.
Nous vous recommandons de surveiller les métriques (utilisation, saturation et erreurs), délais API et taux d'erreur. S'assurer que les résultats répondent aux attentes.
références
C'est notre histoire. Les documents suivants ont grandement aidé à comprendre ce qui se passait :
- ;
- ;
- ;
- ;
- - recherchez « limitation du processeur ».
Rapports de bogues Kubernetes :
- ;
- ;
- .
Avez-vous rencontré des problèmes similaires dans votre pratique ou avez-vous une expérience liée à la limitation dans des environnements de production conteneurisés ? Partagez votre histoire dans les commentaires !
PS du traducteur
A lire aussi sur notre blog :
- «";
- «";
- «».
Source: habr.com
