

Les métiers de Data Scientist et Data Engineer sont souvent confondus. Chaque entreprise a ses propres spécificités en matière de travail avec les données, des objectifs différents pour leur analyse et une idée différente de quel spécialiste doit s'occuper de quelle partie du travail, chacun a donc ses propres exigences.
Voyons quelle est la différence entre ces spécialistes, quels problèmes commerciaux ils résolvent, quelles compétences ils possèdent et combien ils gagnent. Le matériel s'est avéré volumineux, nous l'avons donc divisé en deux publications.
Dans le premier article, Elena Gerasimova, directrice de la faculté «" en Netologie, raconte quelle est la différence entre un Data Scientist et un Data Engineer et avec quels outils ils travaillent.
Comment les rôles des ingénieurs et des scientifiques diffèrent
Un data Engineer est un spécialiste qui, d'une part, développe, teste et maintient l'infrastructure de données : bases de données, systèmes de stockage et de traitement de masse. D’un autre côté, c’est celui qui nettoie et « passe au peigne fin » les données destinées aux analystes et aux data scientists, c’est-à-dire qui crée des pipelines de traitement des données.
Data Scientist crée et entraîne des modèles prédictifs (et autres) à l'aide d'algorithmes d'apprentissage automatique et de réseaux neuronaux, aidant ainsi les entreprises à trouver des modèles cachés, à prédire les développements et à optimiser les processus commerciaux clés.
La principale différence entre un Data Scientist et un Data Engineer est qu’ils ont généralement des objectifs différents. Tous deux veillent à ce que les données soient accessibles et de haute qualité. Mais un Data Scientist trouve des réponses à ses questions et teste des hypothèses dans un écosystème de données (par exemple, basé sur Hadoop), et un Data Engineer crée un pipeline pour desservir un algorithme d'apprentissage automatique écrit par un data scientist dans un cluster Spark au sein du même écosystème.
Un ingénieur de données apporte de la valeur à une entreprise en travaillant en équipe. Sa tâche est d'agir comme un lien important entre les différents acteurs : des développeurs aux professionnels consommateurs de reporting, et d'augmenter la productivité des analystes, du marketing et produit à la BI.
Un Data Scientist, au contraire, participe activement à la stratégie de l'entreprise et extrait des informations, prend des décisions, met en œuvre des algorithmes d'automatisation, modélise et génère de la valeur à partir des données.
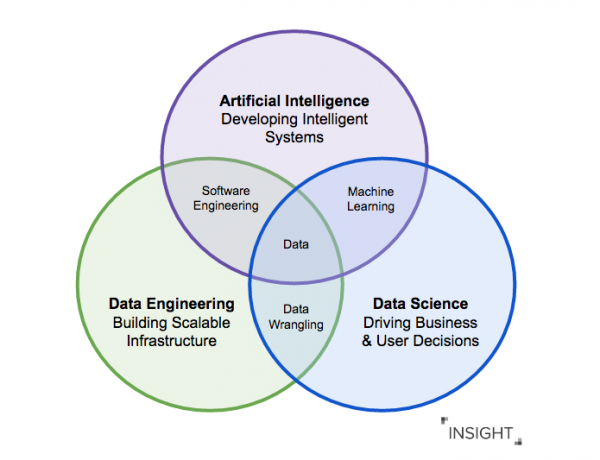
Le travail avec des données est soumis au principe GIGO (garbage in - garbage out) : si les analystes et les data scientists traitent des données non préparées et potentiellement incorrectes, alors les résultats, même en utilisant les algorithmes d'analyse les plus sophistiqués, seront incorrects.
Les ingénieurs de données résolvent ce problème en créant des pipelines pour traiter, nettoyer et transformer les données et en permettant aux data scientists de travailler avec des données de haute qualité.
Il existe sur le marché de nombreux outils pour travailler avec les données qui couvrent chaque étape : de l'apparition des données à la sortie jusqu'au tableau de bord pour le conseil d'administration. Et il est important que la décision de les utiliser soit prise par un ingénieur - non pas parce que c'est à la mode, mais parce qu'il aidera vraiment le travail des autres participants au processus.
Classiquement : si une entreprise a besoin d'établir des connexions entre BI et ETL - chargement de données et mise à jour de rapports, voici une base héritée typique avec laquelle un Data Engineer devra composer (c'est bien s'il y a aussi un architecte dans l'équipe).
Responsabilités d'un ingénieur de données
- Développement, construction et maintenance d'infrastructures de traitement de données.
- Gérer les erreurs et créer des pipelines de traitement de données fiables.
- Amener des données non structurées provenant de diverses sources dynamiques sous la forme nécessaire au travail des analystes.
- Fournir des recommandations pour améliorer la cohérence et la qualité des données.
- Fournir et maintenir l'architecture de données utilisée par les data scientists et les analystes de données.
- Traitez et stockez les données de manière cohérente et efficace dans un cluster distribué de dizaines ou de centaines de serveurs.
- Évaluez les compromis techniques des outils pour créer des architectures simples mais robustes capables de survivre aux perturbations.
- Contrôle et support des flux de données et des systèmes associés (mise en place de surveillances et d'alertes).
Il existe une autre spécialisation dans la trajectoire Data Engineer : l’ingénieur ML. En bref, ces ingénieurs se spécialisent dans la mise en œuvre et l’utilisation industrielles de modèles d’apprentissage automatique. Souvent, un modèle reçu d'un data scientist fait partie d'une étude et peut ne pas fonctionner dans des conditions de combat.
Responsabilités d'un data scientist
- Extraire des fonctionnalités des données pour appliquer des algorithmes d'apprentissage automatique.
- Utiliser divers outils d'apprentissage automatique pour prédire et classer des modèles dans les données.
- Améliorer les performances et la précision des algorithmes d'apprentissage automatique en affinant et en optimisant les algorithmes.
- Formation d’hypothèses « fortes » en accord avec la stratégie de l’entreprise qu’il convient de tester.
Data Engineer et Data Scientist partagent une contribution tangible au développement d’une culture des données, grâce à laquelle une entreprise peut générer des bénéfices supplémentaires ou réduire ses coûts.
Avec quels langages et outils les ingénieurs et scientifiques travaillent-ils ?
Aujourd’hui, les attentes envers les data scientists ont changé. Auparavant, les ingénieurs collectaient des requêtes SQL volumineuses, écrivaient manuellement MapReduce et traitaient les données à l'aide d'outils tels qu'Informatica ETL, Pentaho ETL, Talend.
En 2020, un spécialiste ne peut se passer de la connaissance de Python et des outils de calcul modernes (par exemple Airflow), de la compréhension des principes de travail avec les plateformes cloud (les utiliser pour économiser sur le matériel, tout en respectant les principes de sécurité).
SAP, Oracle, MySQL, Redis sont des outils traditionnels pour les ingénieurs données des grandes entreprises. Ils sont bons, mais le coût des licences est si élevé qu'apprendre à travailler avec eux n'a de sens que dans le cadre de projets industriels. Dans le même temps, il existe une alternative gratuite sous la forme de Postgres - elle est gratuite et ne convient pas seulement à la formation.

Historiquement, les demandes pour Java et Scala sont courantes, même si à mesure que les technologies et les approches se développent, ces langages passent au second plan.
Cependant, le BigData hardcore : Hadoop, Spark et le reste du zoo n'est plus une condition préalable pour un ingénieur de données, mais une sorte d'outils pour résoudre des problèmes qui ne peuvent pas être résolus par l'ETL traditionnel.
La tendance est aux services d'utilisation d'outils sans connaissance du langage dans lequel ils sont écrits (par exemple, Hadoop sans connaissance de Java), ainsi qu'à la fourniture de services prêts à l'emploi pour le traitement des données en streaming (reconnaissance vocale ou reconnaissance d'image sur vidéo ).
Les solutions industrielles de SAS et SPSS sont populaires, tandis que Tableau, Rapidminer, Stata et Julia sont également largement utilisées par les data scientists pour des tâches locales.
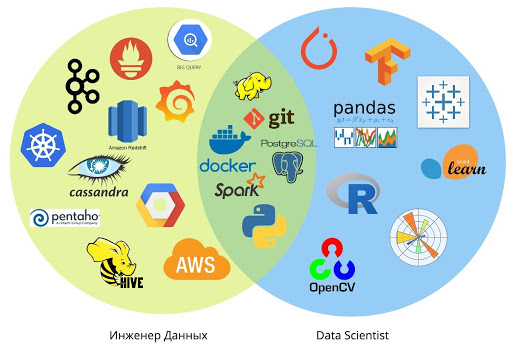
La possibilité de créer eux-mêmes des pipelines est apparue aux analystes et aux data scientists il y a seulement quelques années : par exemple, il est déjà possible d'envoyer des données vers un stockage basé sur PostgreSQL à l'aide de scripts relativement simples.
Généralement, l’utilisation de pipelines et de structures de données intégrées reste de la responsabilité des ingénieurs de données. Mais aujourd’hui, la tendance aux spécialistes en forme de T dotés de vastes compétences dans des domaines connexes est plus forte que jamais, car les outils sont constamment simplifiés.
Pourquoi Data Engineer et Data Scientist travaillent ensemble
En travaillant en étroite collaboration avec les ingénieurs, les Data Scientists peuvent se concentrer sur la recherche, en créant des algorithmes d'apprentissage automatique prêts pour la production.
Et les ingénieurs doivent se concentrer sur l’évolutivité, la réutilisation des données et s’assurer que les pipelines d’entrée et de sortie de données dans chaque projet individuel sont conformes à l’architecture globale.
Cette séparation des responsabilités garantit la cohérence entre les équipes travaillant sur différents projets d'apprentissage automatique.
La collaboration permet de créer efficacement de nouveaux produits. Rapidité et qualité s'obtiennent grâce à un équilibre entre la création d'un service pour tous (stockage global ou intégration de tableaux de bord) et la mise en œuvre de chaque besoin ou projet spécifique (pipeline hautement spécialisé, connexion de sources externes).
Travailler en étroite collaboration avec des scientifiques et des analystes de données aide les ingénieurs à développer des compétences analytiques et de recherche pour écrire un meilleur code. Le partage des connaissances entre les utilisateurs des entrepôts et des lacs de données s'améliore, rendant les projets plus agiles et fournissant des résultats plus durables à long terme.
Dans les entreprises qui visent à développer une culture de travail avec les données et à construire des processus commerciaux basés sur celles-ci, Data Scientist et Data Engineer se complètent et créent un système complet d'analyse de données.
Dans le prochain article, nous parlerons du type de formation qu'un Data Engineer et un Data Scientists devraient avoir, des compétences qu'ils doivent développer et du fonctionnement du marché.
Des éditeurs de Netology
Si vous vous intéressez au métier de Data Engineer ou Data Scientist, nous vous invitons à étudier nos programmes de formations :
- Profession "».
- Profession "».
Source: habr.com
