


Basé sur mes présentations à Highload++ et DataFest Minsk 2019.
Aujourd'hui, pour beaucoup, le courrier électronique fait partie intégrante de la vie en ligne. Il nous permet de communiquer professionnellement, de stocker toutes sortes d'informations importantes liées aux finances, aux réservations d'hôtel, au traitement des commandes et bien plus encore. Mi-2018, nous avons élaboré une stratégie produit pour le développement du courrier électronique. À quoi devrait ressembler un courrier électronique moderne ?
Le courrier doit être intelligent, c'est-à-dire aider les utilisateurs à naviguer dans le volume croissant d'informations : les filtrer, les structurer et les présenter de la manière la plus pratique. utile, vous permettant de résoudre divers problèmes directement dans votre boîte mail, par exemple payer des amendes (une fonction que j'utilise malheureusement). Parallèlement, bien sûr, la messagerie doit assurer la protection des informations, en bloquant le spam et en vous protégeant contre le piratage, c'est-à-dire en étant en sécurité.
Ces domaines définissent un certain nombre de tâches clés, dont beaucoup peuvent être efficacement résolues grâce à l'apprentissage automatique. Voici des exemples de fonctionnalités existantes développées dans le cadre de la stratégie, une pour chaque domaine.
- Réponse intelligenteLe courrier électronique dispose d'une fonction de réponse intelligente. Le réseau neuronal analyse le texte de la lettre, en comprend le sens et l'objectif, et propose ainsi trois options de réponse les plus adaptées : positive, négative et neutre. Cela permet de gagner un temps précieux lors de la réponse aux lettres et de répondre de manière originale et amusante.
- Regroupement de lettres, relatif aux commandes dans les boutiques en ligne. Nous effectuons souvent des achats en ligne et, en règle générale, les boutiques envoient plusieurs messages pour chaque commande. Par exemple, AliExpress, le plus grand service, envoie de nombreux messages pour une commande, et nous avons calculé que, dans le cas d'un terminal, leur nombre peut atteindre 29. Par conséquent, grâce au modèle de reconnaissance d'entités nommées, nous extrayons le numéro de commande et d'autres informations du texte et regroupons toutes les lettres dans un seul fil. Nous affichons également les informations principales de la commande dans un encadré séparé, ce qui facilite le traitement de ce type de messages.

- Anti hameçonnageLe phishing est un type d'e-mail frauduleux particulièrement dangereux, utilisé par les attaquants pour obtenir des informations financières (notamment sur les cartes bancaires) et des identifiants de connexion. Ces e-mails imitent visuellement les véritables e-mails envoyés par le service. C'est pourquoi, grâce à la vision par ordinateur, nous reconnaissons les logos et le style des e-mails de grandes entreprises (par exemple, Mail.ru, Sber, Alfa) et les prenons en compte, ainsi que le texte et d'autres caractéristiques, dans nos classificateurs de spam et de phishing.
Apprentissage automatique
Quelques mots sur l'apprentissage automatique dans le domaine du courrier électronique en général. Le courrier électronique est un système très chargé : en moyenne, 1,5 milliard de lettres transitent par nos serveurs chaque jour pour 30 millions d'utilisateurs DAU. Toutes les fonctions et fonctionnalités nécessaires sont prises en charge par une trentaine de systèmes d'apprentissage automatique.
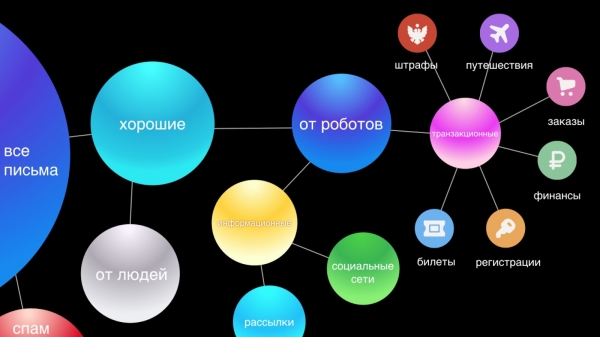
Chaque courrier passe par un système de classification complet. Nous filtrons d'abord le spam et laissons les courriers non sollicités. Les utilisateurs ne remarquent souvent pas le travail de l'antispam, car 95 à 99 % des courriers indésirables n'arrivent même pas dans le dossier approprié. La détection du spam est un élément essentiel de notre système, et le plus complexe, car dans le domaine de l'antispam, l'adaptation constante entre les systèmes de défense et d'attaque représente un défi technique permanent pour notre équipe.
Ensuite, nous séparons les lettres des personnes et des robots. Les lettres des personnes sont les plus importantes, c'est pourquoi nous leur proposons des fonctionnalités comme la Réponse Intelligente. Les lettres des robots sont divisées en deux parties : transactionnelles (lettres importantes concernant les services, par exemple, confirmations d'achats ou réservations d'hôtels, finances) ; et informatives (publicités commerciales, remises).
Nous pensons que les e-mails transactionnels sont aussi importants que la correspondance personnelle. Ils doivent être à portée de main, car nous avons souvent besoin de trouver rapidement des informations concernant une commande ou une réservation de vol, et nous perdons du temps à les rechercher. C'est pourquoi, pour plus de commodité, nous les classons automatiquement en six catégories principales : voyages, commandes, finances, billets, inscriptions et, enfin, amendes.
Les lettres d'information constituent le groupe le plus nombreux et probablement le moins important. Elles ne nécessitent pas de réponse immédiate, car rien de significatif ne changera la vie de l'utilisateur s'il ne les lit pas. Dans notre nouvelle interface, nous les avons regroupées en deux catégories : les réseaux sociaux et les newsletters, ce qui permet de nettoyer visuellement la boîte de réception et de ne laisser apparaître que les messages importants.
exploitation
Un grand nombre de systèmes engendrent de nombreuses difficultés d'exploitation. Après tout, les modèles se dégradent avec le temps, comme tout logiciel : fonctionnalités défaillantes, machines défaillantes, code corrompu déployé. De plus, les données évoluent constamment : de nouvelles données sont ajoutées, les comportements des utilisateurs se transforment, etc. Un modèle sans support adéquat fonctionnera donc de moins en moins bien avec le temps.
Il ne faut pas oublier que plus l'apprentissage automatique pénètre profondément dans la vie des utilisateurs, plus son impact sur l'écosystème est important et, par conséquent, plus les pertes ou profits financiers des acteurs du marché sont importants. C'est pourquoi, dans de plus en plus de domaines, les acteurs s'adaptent aux algorithmes d'apprentissage automatique (par exemple, la publicité, la recherche et l'antispam déjà mentionné).
Les tâches d'apprentissage automatique présentent également une particularité : toute modification du système, même mineure, peut engendrer une charge de travail importante sur le modèle : manipulation des données, réentraînement, déploiement, qui peut s'étendre sur des semaines, voire des mois. Par conséquent, plus l'environnement dans lequel vos modèles évoluent rapidement, plus leur support requiert d'efforts. L'équipe peut créer de nombreux systèmes et s'en réjouir, puis consacrer la quasi-totalité de ses ressources au support, sans pouvoir rien innover. Nous avons déjà rencontré une telle situation au sein de l'équipe anti-spam. Nous en avons conclu que le support devait être automatisé.
Automation
Qu'est-ce qui peut être automatisé ? Presque tout, en fait. J'ai identifié quatre domaines qui définissent l'infrastructure d'apprentissage automatique :
- collecte de données;
- formation continue;
- déployer;
- tests et surveillance.
Si l'environnement est instable et en constante évolution, l'infrastructure autour du modèle est bien plus importante que le modèle lui-même. Il peut s'agir d'un bon classificateur linéaire, mais si vous lui fournissez les fonctionnalités appropriées et que vous obtenez un retour d'information pertinent de la part des utilisateurs, il fonctionnera bien mieux que les modèles de pointe, dotés de toutes les options.
Цикл обратной связи
Ce cycle combine la collecte de données, la formation complémentaire et le déploiement, soit l'intégralité du cycle de mise à jour du modèle. Pourquoi est-ce important ? Consultez le calendrier d'inscription au courrier :
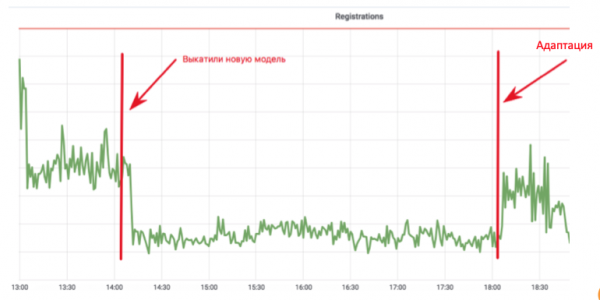
Un développeur d'apprentissage automatique a implémenté un modèle anti-bot qui empêche les robots de s'inscrire dans le courrier. Le graphique chute à une valeur où seuls les vrais utilisateurs restent. Tout va bien ! Mais quatre heures plus tard, les opérateurs de robots peaufinent leurs scripts, et tout revient à la normale. Dans cette implémentation, le développeur a passé un mois à ajouter des fonctionnalités et à réentraîner le modèle, mais le spammeur a pu s'adapter en quatre heures.
Pour éviter une telle souffrance et éviter de devoir tout recommencer plus tard, nous devons d'abord réfléchir à la forme que prendra la boucle de rétroaction et à ce que nous ferons si l'environnement change. Commençons par la collecte de données : elles constituent le carburant de nos algorithmes.
Collecte de données
Il est clair que plus les réseaux neuronaux modernes disposent de données, mieux c'est. Ces données sont essentiellement générées par les utilisateurs du produit. Ces derniers peuvent nous aider en étiquetant les données, mais nous ne pouvons pas en abuser, car à un moment donné, ils se lasseront d'entraîner vos modèles et passeront à un autre produit.
L'une des erreurs les plus courantes (je fais ici référence à Andrew Ng) consiste à trop se concentrer sur les indicateurs du jeu de données de test, au détriment des retours utilisateurs, qui constituent pourtant le principal indicateur de la qualité du travail, puisque nous créons un produit pour l'utilisateur. Si l'utilisateur ne comprend pas ou n'apprécie pas le fonctionnement du modèle, tout est vain.
Par conséquent, l'utilisateur devrait toujours avoir la possibilité de voter et nous devrions lui fournir un outil de retour d'information. Si nous pensons qu'un courrier est arrivé dans sa boîte aux lettres concernant des questions financières, nous devrions le marquer comme « finance » et créer un bouton permettant à l'utilisateur d'indiquer qu'il ne s'agit pas de questions financières.
Qualité des commentaires
Parlons de la qualité des retours utilisateurs. Premièrement, vous et l'utilisateur pouvez donner des significations différentes à un même concept. Par exemple, vous et les chefs de produit pensez que les « finances » sont des lettres de la banque, et l'utilisateur pense qu'une lettre de grand-mère concernant sa retraite est également liée aux finances. Deuxièmement, certains utilisateurs aiment appuyer sur des boutons sans réfléchir et sans aucune logique. Troisièmement, l'utilisateur peut se tromper lourdement dans ses conclusions. Un exemple frappant de notre pratique est la mise en œuvre d'un classificateur. , un type de spam très amusant, où l'utilisateur se voit proposer plusieurs millions de dollars d'un parent éloigné retrouvé subitement en Afrique. Après avoir mis en œuvre ce classificateur, nous avons vérifié les clics « Pas du spam » sur ces lettres, et il s'est avéré que 80 % d'entre elles étaient du spam nigérian juteux, ce qui suggère que les utilisateurs peuvent être extrêmement crédules.
Et n'oublions pas que les gens ne sont pas les seuls à pouvoir cliquer sur des boutons, mais aussi les robots qui se font passer pour un navigateur. Le feedback brut n'est donc pas bon pour l'apprentissage. Que pouvez-vous faire de ces informations ?
Nous utilisons deux approches :
- Retour d'information du ML associéPar exemple, nous disposons d'un système anti-robot en ligne qui, comme je l'ai déjà mentionné, prend une décision rapide en fonction d'un nombre limité de fonctionnalités. Il existe également un second système, plus lent, fonctionnant a posteriori. Il dispose de davantage de données sur l'utilisateur, son comportement, etc. Ainsi, la décision la plus équilibrée est prise, et donc plus précise et complète. Les différences de fonctionnement de ces systèmes peuvent être utilisées comme données d'apprentissage pour le premier. Ainsi, le système le plus simple cherchera toujours à se rapprocher des performances du système le plus complexe.
- Classification des clicsIl est possible de classer simplement chaque clic utilisateur et d'évaluer sa validité et sa facilité d'utilisation. C'est ce que nous faisons dans l'antispam, en utilisant les attributs utilisateur, leur historique, les attributs de l'expéditeur, le texte lui-même et le résultat des classificateurs. Nous obtenons ainsi un système automatique qui valide les retours utilisateurs. Et comme il nécessite beaucoup moins de réapprentissage, son travail peut devenir la priorité de tous les autres systèmes. La priorité absolue de ce modèle est la précision, car l'entraînement d'un modèle sur des données inexactes est lourd de conséquences.
Lors du nettoyage des données et de l'entraînement de nos systèmes d'apprentissage automatique, nous ne devons pas oublier les utilisateurs. Pour nous, des milliers, voire des millions d'erreurs sur le graphique sont des statistiques, et pour l'utilisateur, chaque bug est une tragédie. Outre le fait que l'utilisateur doit s'accommoder d'une erreur dans le produit, après un retour d'information, il s'attend à une exception à cette situation à l'avenir. Il est donc toujours judicieux de donner aux utilisateurs la possibilité non seulement de voter, mais aussi de corriger le comportement des systèmes d'apprentissage automatique, en créant, par exemple, des heuristiques personnalisées pour chaque clic de retour. Dans le cas des e-mails, cela pourrait prendre la forme d'un filtrage par expéditeur et par titre pour cet utilisateur.
Il est également nécessaire d'utiliser certains rapports ou demandes de support pour peaufiner le modèle en mode semi-automatique ou manuel afin que d'autres utilisateurs ne souffrent pas de problèmes similaires.
Heuristiques pour l'apprentissage
Ces heuristiques et béquilles présentent deux problèmes. Le premier est que le nombre croissant de béquilles rend leur maintenance difficile, sans parler de leur qualité et de leurs performances sur de longues distances. Le second est que l'erreur peut être rare et que quelques clics pour réentraîner le modèle ne suffiront pas. Il semblerait que ces deux effets, sans rapport entre eux, puissent être considérablement atténués par l'application de l'approche suivante.
- Créons une béquille temporaire.
- Nous envoyons les données au modèle, qui est régulièrement entraîné, notamment sur les données reçues. Il est bien sûr important que les heuristiques soient très précises afin de ne pas réduire la qualité des données de l'ensemble d'entraînement.
- Nous avons ensuite mis en place un système de surveillance pour vérifier le bon fonctionnement de la béquille. Si, après un certain temps, elle cesse de fonctionner et est complètement recouverte par le modèle, nous pouvons la retirer en toute sécurité. Il est désormais peu probable que ce problème se reproduise.
Une armée de béquilles est donc très utile. L'essentiel est que leur utilité soit temporaire et non permanente.
Formation continue
Le réentraînement consiste à ajouter de nouvelles données, obtenues à partir des retours des utilisateurs ou d'autres systèmes, et à entraîner un modèle existant à partir de ces données. Le réentraînement présente plusieurs problèmes :
- Le modèle peut simplement ne pas prendre en charge de formation supplémentaire, mais apprendre uniquement à partir de zéro.
- Nulle part dans le livre de la nature il n'est écrit qu'une formation supplémentaire améliorera nécessairement la qualité du travail en production. Souvent, c'est tout le contraire qui se produit : seule une détérioration est possible.
- Les changements peuvent être imprévisibles. C'est un point assez subtil que nous avons identifié. Même si un nouveau modèle dans un test A/B présente des résultats similaires à ceux du modèle actuel, cela ne signifie pas qu'il fonctionnera à l'identique. Leurs performances peuvent différer d'environ 1 %, ce qui peut entraîner de nouvelles erreurs ou rétablir d'anciennes erreurs déjà corrigées. Nous et les utilisateurs savons déjà gérer les erreurs actuelles, et lorsqu'un grand nombre de nouvelles erreurs surviennent, l'utilisateur peut également ne pas comprendre ce qui se passe, car il s'attend à un comportement prévisible.
Par conséquent, le plus important dans le recyclage est de garantir que le modèle s’améliorera, ou du moins ne se détériorera pas.
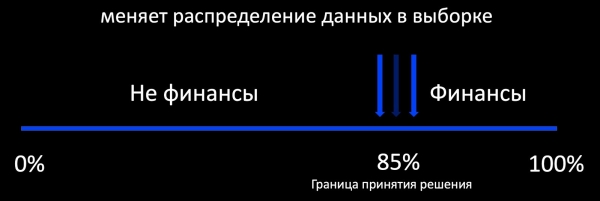
La première chose qui vient à l'esprit lorsqu'on parle d'apprentissage complémentaire est l'approche d'apprentissage actif. Qu'est-ce que cela signifie ? Par exemple, un classificateur détermine si une lettre est liée à la finance et, autour de sa limite de décision, nous ajoutons un échantillon d'exemples étiquetés. Cela fonctionne bien, par exemple, dans le domaine de la publicité, où les retours sont nombreux et où il est possible d'entraîner le modèle en ligne. En revanche, si les retours sont faibles, nous obtenons un échantillon fortement biaisé par rapport à la distribution des données de production, ce qui rend impossible l'évaluation du comportement du modèle en cours d'utilisation.
En fait, notre objectif est de préserver les anciens modèles, déjà connus, et d'en acquérir de nouveaux. La continuité est ici essentielle. Le modèle que nous avons souvent déployé avec beaucoup de difficulté est déjà fonctionnel ; nous pouvons donc nous concentrer sur sa performance.
Différents modèles sont utilisés dans le courrier : arborescents, linéaires, réseaux de neurones. Pour chacun d'eux, nous créons notre propre algorithme d'entraînement complémentaire. Cet entraînement complémentaire nous permet d'obtenir non seulement de nouvelles données, mais aussi souvent de nouvelles caractéristiques, que nous prendrons en compte dans tous les algorithmes ci-dessous.
Modèles linéaires
Prenons l'exemple d'une régression logistique. Nous construisons le modèle de perte à partir des éléments suivants :
- LogLoss sur les nouvelles données ;
- nous régularisons les poids des nouvelles fonctionnalités (nous laissons les anciennes tranquilles) ;
- nous apprenons à partir de données anciennes pour préserver les anciens modèles ;
- et, peut-être, la chose la plus importante : nous accrochons la régularisation harmonique, qui garantit un changement peu important des poids par rapport à l'ancien modèle selon la norme.
Étant donné que chaque composant de perte possède des coefficients, nous pouvons sélectionner les valeurs optimales pour notre tâche à l’aide d’une validation croisée ou en fonction des exigences du produit.
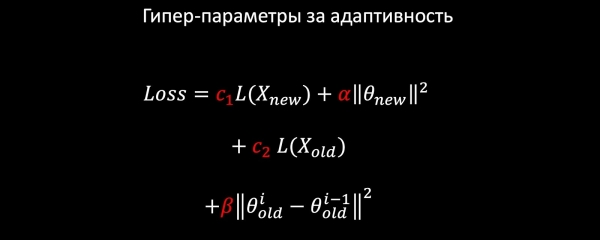
Деревья
Passons maintenant aux arbres de décision. Nous avons élaboré l'algorithme suivant pour le réentraînement des arbres :
- La production gère une forêt de 100 à 300 arbres, formés sur l'ancien ensemble de données.
- Nous supprimons M = 5 pièces à la fin et en ajoutons 2M = 10 nouvelles, formées sur l'ensemble des données, mais avec un poids élevé pour les nouvelles données, ce qui garantit naturellement un changement incrémental dans le modèle.
Il est évident qu'avec le temps, le nombre d'arbres augmente considérablement et qu'il est nécessaire de les réduire périodiquement pour respecter les délais. Pour cela, nous utilisons la distillation des connaissances (DC), désormais omniprésente. En bref, son principe de fonctionnement.
- Nous disposons actuellement d'un modèle « complexe ». Nous l'exécutons sur l'ensemble de données d'entraînement et obtenons la distribution de probabilité des classes de sortie.
- Ensuite, nous formons le modèle étudiant (le modèle avec moins d'arbres dans ce cas) pour reproduire les performances du modèle en utilisant la distribution de classe comme variable cible.
- Il est important de noter ici que nous n'utilisons aucun étiquetage d'ensemble de données et que nous pouvons donc utiliser des données arbitraires. Bien entendu, nous utilisons un échantillon des données de production comme ensemble d'entraînement pour le modèle de Student. Ainsi, l'ensemble d'entraînement nous permet de garantir la précision du modèle, et l'échantillon du flux assure des performances similaires sur la distribution de production, compensant ainsi le biais de l'ensemble d'entraînement.
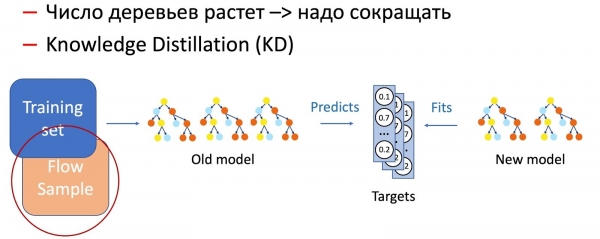
La combinaison de ces deux techniques (ajout d’arbres et réduction périodique de leur nombre à l’aide de la distillation des connaissances) assure l’introduction de nouveaux modèles et une continuité complète.
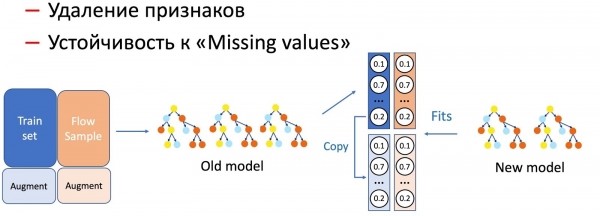
Avec la KD, nous distinguons également les opérations sur les caractéristiques du modèle, telles que la suppression de caractéristiques et l'exploitation des lacunes. Dans notre cas, plusieurs caractéristiques statistiques importantes (par expéditeur, hachages de texte, URL, etc.) stockées dans une base de données ont tendance à échouer. Le modèle n'est évidemment pas préparé à une telle évolution, car il n'existe aucune situation d'échec dans l'ensemble d'apprentissage. Dans ce cas, nous combinons la KD et les techniques d'augmentation : lors de l'apprentissage d'une partie des données, nous supprimons ou mettons à zéro les caractéristiques nécessaires et récupérons les étiquettes d'origine (sorties du modèle actuel). Le modèle étudiant apprend alors à reproduire cette distribution.
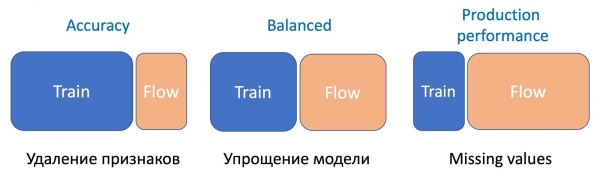
Nous avons remarqué que plus la manipulation du modèle est importante, plus le pourcentage d’échantillons de flux requis est élevé.
La suppression de caractéristiques, l'opération la plus simple, ne nécessite qu'une faible partie du flux, car seules quelques caractéristiques sont modifiées et le modèle actuel a été entraîné sur le même ensemble ; la différence est minime. Simplifier le modèle (réduire plusieurs fois le nombre d'arbres) nécessite un ratio de 50/50. De plus, l'absence de caractéristiques statistiques importantes, qui affectent sérieusement les performances du modèle, nécessite encore plus de flux pour uniformiser le travail du nouveau modèle, résistant aux omissions, sur tous les types de lettres.
Texte rapide
Passons maintenant à FastText. Rappelons que la représentation (Embedding) d'un mot est constituée de la somme de l'embedding du mot lui-même et de tous ses N-grammes, généralement des trigrammes. Comme il peut y avoir un grand nombre de trigrammes, on utilise le hachage par compartiments, c'est-à-dire la transformation de l'espace entier en une table de hachage fixe. On obtient ainsi la matrice de pondération dont la dimension de la couche interne est le nombre de mots + compartiments.
Lors du réentraînement, de nouvelles caractéristiques apparaissent : mots et trigrammes. Lors du réentraînement standard de Facebook, rien de significatif ne se produit. Seules les anciennes pondérations avec entropie croisée sur les nouvelles données sont réentraînées. Ainsi, les nouvelles caractéristiques ne sont pas utilisées. Bien entendu, cette approche présente tous les inconvénients décrits précédemment, liés à l'imprévisibilité du modèle en production. C'est pourquoi nous avons légèrement amélioré FastText. Nous ajoutons toutes les nouvelles pondérations (mots et trigrammes), réentraînons l'ensemble de la matrice avec entropie croisée et appliquons une régularisation harmonique par analogie avec le modèle linéaire, ce qui garantit une variation négligeable des anciennes pondérations.

CNN
Avec les réseaux convolutifs, la situation est un peu plus complexe. Si les dernières couches sont entraînées en CNN, une régularisation harmonique peut bien sûr être appliquée et la continuité garantie. En revanche, si l'entraînement du réseau entier est nécessaire, cette régularisation ne peut pas être appliquée à toutes les couches. Il existe cependant une option permettant d'entraîner des plongements complémentaires via la perte de triplet ().
Triple perte
En prenant l'exemple de la tâche antiphishing, nous analyserons la perte de triplets de manière générale. Nous prendrons notre logo, ainsi que des exemples positifs et négatifs de logos d'autres entreprises. Nous minimiserons la distance entre le premier et maximiserons celle entre le second, en respectant un faible écart afin de garantir une meilleure compacité des classes.
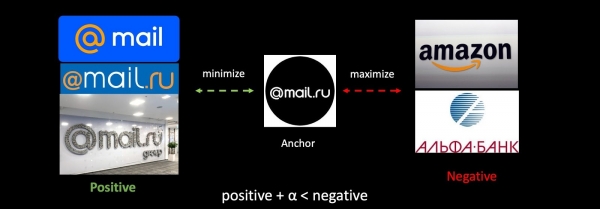
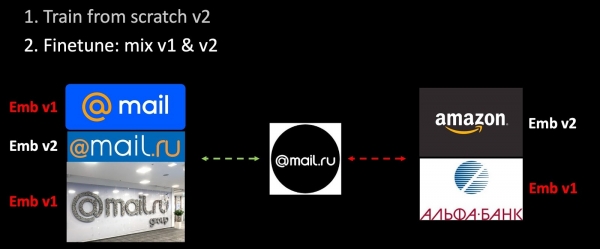
Si nous réentraînons le réseau, notre espace métrique change complètement et devient totalement incompatible avec le précédent. Il s'agit d'un problème sérieux dans les tâches utilisant des vecteurs. Pour contourner ce problème, nous intégrerons d'anciens plongements lors de l'entraînement.
Nous avons ajouté de nouvelles données à l'ensemble d'entraînement et entraîné la deuxième version du modèle de A à Z. Dans un deuxième temps, nous affinons notre réseau : la dernière couche est d'abord affinée, puis l'ensemble du réseau est dégelé. Lors de la composition des triplets, seule une partie des plongements est calculée à l'aide du modèle entraîné, le reste à l'aide de l'ancien. Ainsi, lors de l'affinement, nous garantissons la compatibilité des espaces métriques v1 et v2. Il s'agit d'une version particulière de la régularisation harmonique.
L'architecture dans son intégralité
Si l'on considère l'ensemble du système à l'aide de l'exemple antispam, les modèles ne sont pas isolés, mais imbriqués. Nous prenons des images, du texte et d'autres caractéristiques, et grâce à CNN et Fast Text, nous obtenons des intégrations. Ensuite, des classificateurs sont appliqués par-dessus ces intégrations, ce qui produit des scores pour différentes classes (types d'e-mails, spam, présence d'un logo). Les scores et les caractéristiques sont ensuite intégrés dans la forêt d'arbres pour la prise de décision finale. Des classificateurs distincts dans ce schéma nous permettent de mieux interpréter les résultats du système et d'entraîner plus spécifiquement les composants en cas de problème, plutôt que d'alimenter toutes les données brutes dans les arbres de décision.
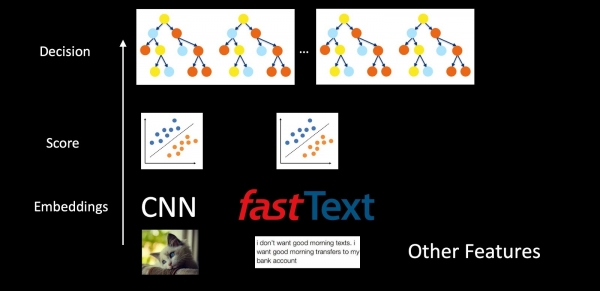
Enfin, nous garantissons la continuité à chaque niveau. Au niveau inférieur, dans CNN et Fast Text, nous utilisons la régularisation harmonique, et pour les classificateurs intermédiaires, nous utilisons également la régularisation harmonique et l'étalonnage des scores pour assurer la cohérence de la distribution de probabilité. Les arbres boostés sont entraînés de manière incrémentale ou par distillation des connaissances.
En général, la maintenance d'un tel système d'apprentissage automatique imbriqué est complexe, car tout composant de niveau inférieur entraîne une mise à jour de l'ensemble du système. Mais comme dans notre configuration, chaque composant change légèrement et est compatible avec le précédent, le système peut être mis à jour par morceaux sans nécessiter de réentraînement de la structure entière, ce qui permet une maintenance sans surcharge importante.
Déployer
Nous avons abordé la collecte de données et la formation supplémentaire de différents types de modèles, nous passons donc à leur déploiement dans l'environnement de production.
Tests A/B
Comme je l'ai mentionné précédemment, lors de la collecte de données, nous obtenons généralement un échantillon biaisé, ce qui rend impossible l'évaluation des performances du modèle en production. Par conséquent, lors du déploiement, le modèle doit être comparé à la version précédente afin de comprendre son fonctionnement réel, c'est-à-dire de réaliser des tests A/B. En effet, le déploiement et l'analyse des graphiques sont des processus assez routiniers et se prêtent bien à l'automatisation. Nous déployons nos modèles progressivement auprès de 5 %, 30 %, 50 % et 100 % des utilisateurs, tout en collectant toutes les métriques disponibles sur les réponses et les retours des utilisateurs. En cas de valeurs aberrantes importantes, nous restaurons automatiquement le modèle. Dans les autres cas, après avoir collecté un nombre suffisant de clics utilisateurs, nous augmentons le pourcentage. Ainsi, le nouveau modèle est déployé automatiquement auprès de 50 % des utilisateurs, et le déploiement à l'ensemble du public est approuvé par une personne, bien que cette étape puisse également être automatisée.
Cependant, le processus de test A/B offre une marge d'optimisation. En effet, tout test A/B est relativement long (dans notre cas, il dure de 6 à 24 heures selon le nombre de retours), ce qui le rend coûteux et nécessite des ressources limitées. De plus, une part importante du flux de test est nécessaire pour accélérer la durée globale du test A/B (collecter un échantillon statistiquement significatif pour évaluer les indicateurs sur un faible pourcentage peut être très long), ce qui limite considérablement le nombre d'emplacements A/B. Évidemment, nous devons uniquement tester les modèles les plus prometteurs, dont nous obtenons un grand nombre lors de l'entraînement supplémentaire.
Pour résoudre ce problème, nous avons entraîné un classificateur distinct qui prédit la réussite d'un test A/B. Pour ce faire, nous utilisons les statistiques de prise de décision, de précision, de rappel et d'autres métriques de l'ensemble d'entraînement, de l'ensemble différé et de l'échantillon du flux comme caractéristiques. Nous comparons également le modèle à celui en production, à l'aide d'heuristiques, et prenons en compte sa complexité. À l'aide de toutes ces caractéristiques, le classificateur entraîné sur l'historique des tests évalue les modèles candidats (dans notre cas, il s'agit de forêts d'arbres) et décide lesquels intégrer au test A/B.
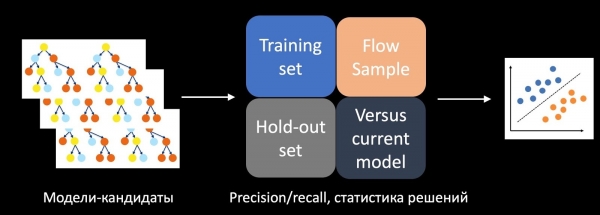
Au moment de la mise en œuvre, cette approche nous a permis d’augmenter plusieurs fois le nombre de tests A/B réussis.
Tests et surveillance
Les tests et la surveillance, curieusement, ne nuisent pas à notre santé ; au contraire, ils l'améliorent et soulagent le stress inutile. Les tests permettent de prévenir les pannes, tandis que la surveillance permet de les détecter à temps pour en réduire l'impact sur les utilisateurs.
Il est important de comprendre que tôt ou tard, votre système fera toujours des erreurs, en raison du cycle de développement de tout logiciel. Au début du développement d'un système, de nombreux bugs surviennent jusqu'à ce que tout se stabilise et que la phase principale d'innovation soit achevée. Mais avec le temps, l'entropie fait des ravages et les erreurs réapparaissent, dues à la dégradation des composants et aux modifications des données, comme je l'ai mentionné au début.
Je tiens à souligner ici que tout système d'apprentissage automatique doit être considéré en termes de rentabilité tout au long de son cycle de vie. Le graphique ci-dessous illustre la façon dont le système s'efforce de détecter un type rare de spam (la ligne sur le graphique est proche de zéro). Un jour, à cause d'une fonctionnalité mal mise en cache, le système a perdu le contrôle. Par chance, aucune surveillance des déclenchements anormaux n'a été effectuée, ce qui a conduit le système à enregistrer massivement des messages dans le dossier spam au seuil de décision. Malgré les corrections apportées, le système a déjà commis tellement d'erreurs qu'il ne sera pas rentabilisé en cinq ans. Il s'agit d'un échec total en termes de cycle de vie du modèle.
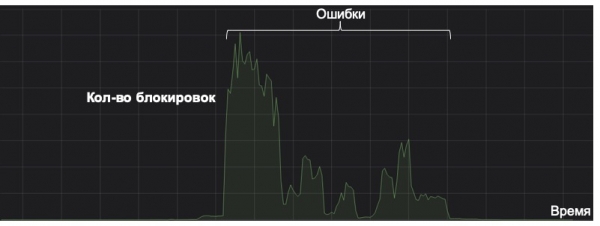
Par conséquent, un élément aussi simple que la surveillance peut devenir essentiel à la vie d'un modèle. Outre les indicateurs standards et évidents, nous prenons en compte la distribution des réponses et des taux du modèle, ainsi que la distribution des valeurs des caractéristiques clés. Grâce à la divergence KL, nous pouvons comparer la distribution actuelle à la distribution historique ou les valeurs du test A/B au reste du flux, ce qui nous permet de détecter les anomalies du modèle et d'annuler les changements dans le temps.
Dans la plupart des cas, nous lançons nos premières versions de systèmes à l'aide d'heuristiques ou de modèles simples que nous utilisons pour la surveillance ultérieure. Par exemple, nous surveillons le modèle NER par rapport aux expressions régulières de boutiques en ligne spécifiques, et si la couverture du classificateur diminue par rapport à celles-ci, nous en déterminons les raisons. Une autre application utile des heuristiques !
Les résultats de
Revenons à nouveau sur les idées clés de l’article.
- FibdeckNous pensons toujours à l'utilisateur : comment acceptera-t-il nos erreurs ? Comment pourra-t-il les signaler ? Nous n'oublions pas que les utilisateurs ne sont pas une source de feedback pure pour les modèles d'entraînement, et que ce feedback doit être affiné à l'aide de systèmes d'apprentissage automatique auxiliaires. S'il n'est pas possible de recueillir un signal de l'utilisateur, nous recherchons d'autres sources de feedback, par exemple des systèmes associés.
- Formation continueL'essentiel ici est la continuité ; nous nous appuyons donc sur le modèle de production actuel. Nous formons les nouveaux modèles afin qu'ils ne diffèrent pas trop du précédent grâce à la régularisation harmonique et à d'autres astuces similaires.
- DéployerLe déploiement automatique par métriques réduit considérablement le temps de mise en œuvre des modèles. Le suivi des statistiques et de la répartition des décisions, ainsi que le nombre de chutes d'utilisateurs, sont essentiels pour un sommeil paisible et des week-ends productifs.
Eh bien, j’espère que ce que vous lisez vous aidera à améliorer vos systèmes ML plus rapidement, à les mettre sur le marché plus rapidement et à les rendre plus fiables, réduisant ainsi le stress au travail.
Source: habr.com
