

Comme vous le savez, SAP propose une gamme complète de logiciels tant pour la maintenance des données transactionnelles que pour le traitement de ces données dans les systèmes d'analyse et de reporting. En particulier, la plateforme SAP Business Warehouse (SAP BW) est une boîte à outils de stockage et d'analyse de données dotée de capacités techniques étendues. Malgré tous ses avantages objectifs, le système SAP BW présente un inconvénient majeur. Il s'agit d'un coût élevé de stockage et de traitement des données, particulièrement visible lors de l'utilisation de SAP BW basé sur le cloud sur Hana.
Et si vous commenciez à utiliser un produit non SAP et de préférence un produit OpenSource comme stockage ? Chez X5 Retail Group, nous avons choisi GreenPlum. Bien sûr, cela résout le problème des coûts, mais en même temps, des problèmes surviennent immédiatement, qui ont été résolus presque par défaut lors de l'utilisation de SAP BW.

En particulier, comment récupérer les données des systèmes sources, qui sont pour la plupart des solutions SAP ?
HR Metrics a été le premier projet dans lequel il a fallu résoudre ce problème. Notre objectif était de créer un référentiel de données RH et de construire des reporting analytiques dans le domaine du travail avec les salariés. Dans ce cas, la principale source de données est le système transactionnel SAP HCM, dans lequel sont effectuées toutes les activités liées au personnel, à l'organisation et aux salaires.
Extraction de données
Dans SAP BW, il existe des extracteurs de données standard pour les systèmes SAP. Ces extracteurs peuvent collecter automatiquement les données nécessaires, surveiller leur intégrité et déterminer les deltas de modification. Voici, par exemple, la source de données standard pour les attributs des employés 0EMPLOYEE_ATTR :
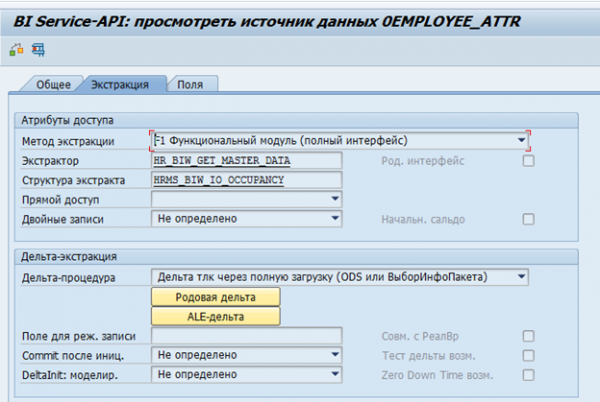
Le résultat de l'extraction des données pour un employé :
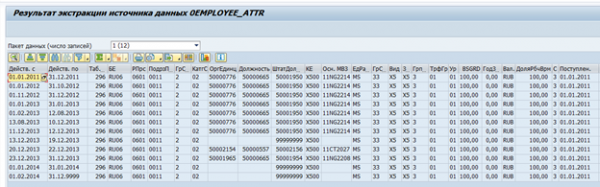
Si nécessaire, un tel extracteur peut être modifié pour répondre à vos propres besoins ou votre propre extracteur peut être créé.
La première idée qui a germé a été la possibilité de les réutiliser. Malheureusement, cela s’est avéré être une tâche impossible. La majeure partie de la logique est implémentée côté SAP BW, et il n'a pas été possible de séparer sans douleur l'extracteur à la source de SAP BW.
Il est devenu évident que nous devions développer notre propre mécanisme pour extraire les données des systèmes SAP.
Structure de stockage des données dans SAP HCM
Pour comprendre les exigences d’un tel mécanisme, nous devons d’abord déterminer de quelles données nous avons besoin.
La plupart des données dans SAP HCM sont stockées dans des tables SQL plates. Sur la base de ces données, les applications SAP visualisent les structures organisationnelles, les employés et d'autres informations RH pour l'utilisateur. Par exemple, voici à quoi ressemble la structure organisationnelle dans SAP HCM :
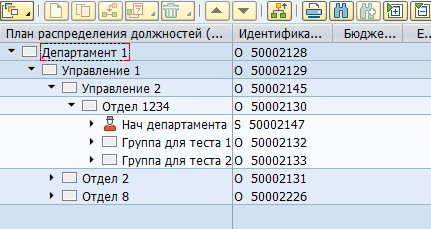
Physiquement, un tel arbre est stocké dans deux tables - dans les objets hrp1000 et dans hrp1001 les connexions entre ces objets.
Objets « Département 1 » et « Bureau 1 » :

Relation entre les objets :

Il peut y avoir un grand nombre de types d'objets et de types de connexions entre eux. Il existe à la fois des connexions standard entre les objets et des connexions personnalisées pour vos propres besoins spécifiques. Par exemple, la relation standard B012 entre une unité organisationnelle et un poste à temps plein indique le chef d'un département.
Affichage du manager dans SAP :
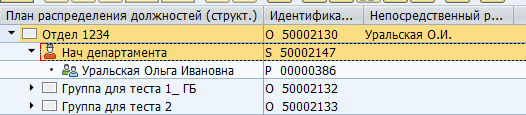
Stockage dans une table de base de données :

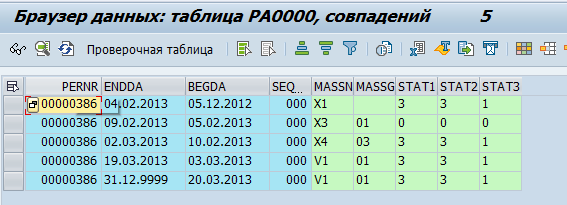
Les données des employés sont stockées dans des tables pa*. Par exemple, les données sur les événements personnels d'un employé sont stockées dans la table pa0000.
Nous avons décidé que GreenPlum prendrait des données « brutes », c'est-à-dire copiez-les simplement à partir des tables SAP. Et directement dans GreenPlum, ils seront traités et convertis en objets physiques (par exemple, service ou employé) et en métriques (par exemple, effectif moyen).
Environ 70 tables ont été définies, dont les données doivent être transférées vers GreenPlum. Après quoi, nous avons commencé à élaborer une méthode pour transmettre ces données.
SAP propose un large éventail de mécanismes d'intégration. Cependant, la méthode la plus simple, l'accès direct à la base de données, est interdite en raison de restrictions de licence. Par conséquent, tous les flux d'intégration doivent être implémentés au niveau de SAP. serveur приложений.
Le problème suivant était le manque de données sur les enregistrements supprimés dans la base de données SAP. Lorsque vous supprimez une ligne dans la base de données, elle est physiquement supprimée. Ceux. la formation d'un delta de changement basé sur le moment du changement n'était pas possible.
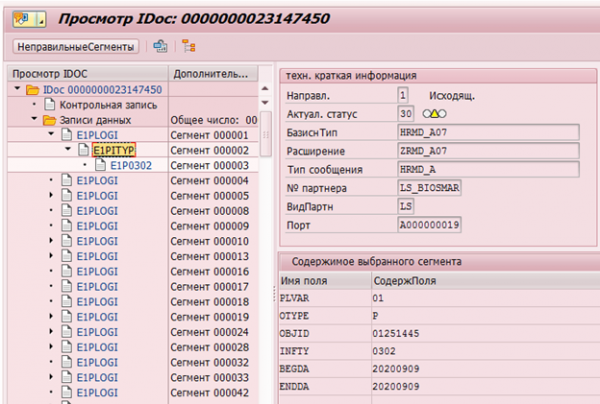
Bien entendu, SAP HCM dispose de mécanismes pour enregistrer les modifications des données. Par exemple, pour le transfert ultérieur vers les systèmes destinataires, il existe des pointeurs de modification qui enregistrent toute modification et sur la base desquels un Idoc est formé (un objet à transférer vers des systèmes externes).
Exemple d'IDoc pour modifier l'infotype 0302 pour un salarié portant le matricule 1251445 :
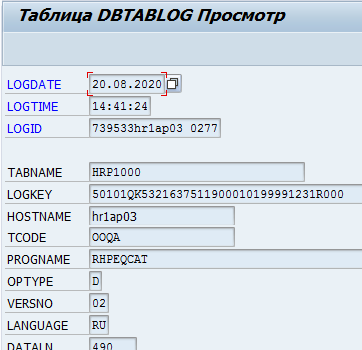
Ou conserver des journaux de modifications de données dans la table DBTABLOG.
Un exemple de journal de suppression d'un enregistrement avec la clé QK53216375 de la table hrp1000 :
Mais ces mécanismes ne sont pas disponibles pour toutes les données nécessaires, et leur traitement au niveau du serveur d'applications peut consommer beaucoup de ressources. Par conséquent, l’activation massive de la journalisation sur toutes les tables nécessaires peut entraîner une dégradation notable des performances du système.
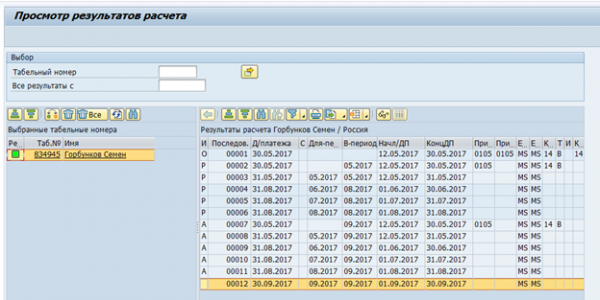
Le prochain problème majeur concernait les tables groupées. Les données d'estimation du temps et de paie dans la version SGBDR de SAP HCM sont stockées sous la forme d'un ensemble de tables logiques pour chaque employé pour chaque calcul. Ces tables logiques sont stockées sous forme de données binaires dans la table pcl2.
Cluster Paie :
Les données des tables clusterisées ne peuvent pas être considérées comme une commande SQL, mais nécessitent l'utilisation de macros SAP HCM ou de modules fonction spéciaux. En conséquence, la vitesse de lecture de ces tableaux sera assez faible. D'un autre côté, ces clusters stockent des données qui ne sont nécessaires qu'une fois par mois - paie finale et estimation du temps. La vitesse dans ce cas n’est donc pas si critique.
En évaluant les options permettant de former un delta de modifications de données, nous avons décidé d'envisager également l'option d'un déchargement complet. L’option consistant à transférer chaque jour des gigaoctets de données inchangées entre des systèmes n’est peut-être pas bonne. Cependant, cela présente également un certain nombre d'avantages : il n'est pas nécessaire à la fois d'implémenter le delta du côté source et d'implémenter l'intégration de ce delta du côté du récepteur. En conséquence, le coût et le temps de mise en œuvre sont réduits et la fiabilité de l'intégration augmente. Dans le même temps, il a été déterminé que presque tous les changements dans SAP HR surviennent dans un délai de trois mois avant la date actuelle. Ainsi, il a été décidé d'opter pour un téléchargement complet quotidien des données de SAP HR N mois avant la date du jour et un téléchargement complet mensuel. Le paramètre N dépend de la table spécifique
et varie de 1 à 15.
Le schéma suivant a été proposé pour l'extraction des données :

Le système externe génère une demande et l'envoie à SAP HCM, où cette demande est vérifiée pour l'exhaustivité des données et les autorisations d'accès aux tables. Si la vérification réussit, SAP HCM exécute un programme qui collecte les données nécessaires et les transfère à la solution d'intégration Fuse. Fuse détermine le sujet requis dans Kafka et y transfère les données. Ensuite, les données de Kafka sont transférées vers Stage Area GP.
Dans cette chaîne, nous nous intéressons à la problématique de l’extraction des données de SAP HCM. Regardons cela plus en détail.
Diagramme d'interaction SAP HCM-FUSE.
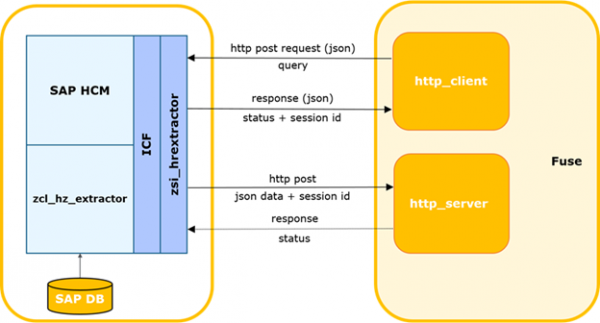
Le système externe détermine l'heure de la dernière demande réussie à SAP.
Le processus peut être lancé par une minuterie ou un autre événement, notamment en définissant un délai d'attente pour attendre une réponse avec les données de SAP et lancer une demande répétée. Ensuite, il génère une demande delta et l'envoie à SAP.
Les données de la requête sont envoyées au corps au format json.
Méthode http : POST.
Exemple de demande :

Le service SAP surveille l'exhaustivité de la demande, sa conformité avec la structure SAP actuelle et la disponibilité de l'autorisation d'accès à la table demandée.
En cas d'erreurs, le service renvoie une réponse avec le code et la description appropriés. Si le contrôle réussit, il crée un processus en arrière-plan pour générer un échantillon, génère et renvoie de manière synchrone un identifiant de session unique.
En cas d'erreur, le système externe l'enregistre dans le journal. En cas de réponse réussie, il transmet l'identifiant de session et le nom de la table pour laquelle la demande a été faite.
Le système externe enregistre la session en cours comme étant ouverte. S'il existe d'autres sessions pour cette table, elles sont fermées avec un avertissement enregistré.
Le travail en arrière-plan SAP génère un curseur basé sur les paramètres spécifiés et un paquet de données de la taille spécifiée. La taille du lot est le nombre maximum d'enregistrements qu'un processus lit dans la base de données. Par défaut, il est supposé être égal à 2000. S'il y a plus d'enregistrements dans l'échantillon de base de données que la taille de paquet utilisée, après la transmission du premier paquet, le bloc suivant est formé avec le décalage correspondant et le numéro de paquet incrémenté. Les nombres sont incrémentés de 1 et envoyés strictement séquentiellement.
Ensuite, SAP transmet le paquet en entrée au service Web du système externe. Et le système effectue des contrôles sur le paquet entrant. Une session avec l'identifiant reçu doit être enregistrée dans le système et elle doit être en statut ouvert. Si le numéro de colis > 1, le système doit enregistrer la réception réussie du colis précédent (package_id-1).
Si le contrôle réussit, le système externe analyse et enregistre les données de la table.
De plus, si l'indicateur final est présent dans le package et que la sérialisation a réussi, le module d'intégration est informé de la réussite du traitement de la session et le module met à jour l'état de la session.
En cas d'erreur de contrôle/analyse, l'erreur est enregistrée et les paquets de cette session seront rejetés par le système externe.
De même, dans le cas contraire, lorsque le système externe renvoie une erreur, celle-ci est enregistrée et la transmission des paquets s'arrête.
Pour demander des données côté SAP HСM, un service d'intégration a été mis en place. Le service est implémenté sur le framework ICF (SAP Internet Communication Framework - ). Il vous permet d'interroger les données du système SAP HCM à l'aide de tables spécifiques. Lors de la création d'une demande de données, il est possible de préciser une liste de champs spécifiques et de paramètres de filtrage afin d'obtenir les données nécessaires. Dans le même temps, la mise en œuvre du service n'implique aucune logique métier. Des algorithmes de calcul de delta, de paramètres de requête, de surveillance de l'intégrité, etc. sont également implémentés du côté du système externe.
Ce mécanisme permet de collecter et de transmettre toutes les données nécessaires en quelques heures. Cette rapidité est à la limite de l'acceptable, nous considérons donc cette solution comme temporaire, qui a permis de combler le besoin d'un outil d'extraction sur le projet.
Dans l'image cible, pour résoudre le problème de l'extraction des données, des options d'utilisation de systèmes CDC tels qu'Oracle Golden Gate ou d'outils ETL tels que SAP DS sont à l'étude.
Source: habr.com
