

HighLoad++ Moscou 2018, Salle des Congrès. 9 novembre, 15h00
Résumés et présentation :
Yuri Nasretdinov (VKontakte) : le rapport parlera de l'expérience de mise en œuvre de ClickHouse dans notre entreprise - pourquoi nous en avons besoin, combien de données nous stockons, comment nous les écrivons, etc.

Matériaux supplémentaires:
Youri Nasretdinov : - Salut tout le monde! Je m'appelle Yuri Nasretdinov, comme je l'ai déjà présenté. Je travaille chez VKontakte. Je parlerai de la façon dont nous insérons les données dans ClickHouse à partir de notre flotte de serveurs (des dizaines de milliers).
Que sont les journaux et pourquoi les collecter ?
Ce que nous vous dirons : ce que nous avons fait, pourquoi nous avions besoin de « ClickHouse », respectivement, pourquoi nous l'avons choisi, quel type de performances vous pouvez obtenir approximativement sans rien configurer spécialement. Je vais vous parler plus en détail des tables tampons, des problèmes que nous avons rencontrés avec elles et de nos solutions que nous avons développées à partir de l'open source - KittenHouse et Lighthouse.
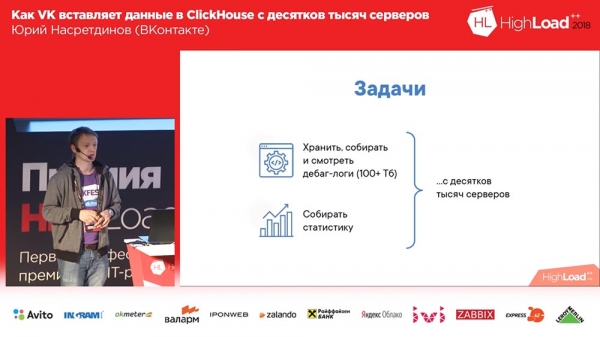
Pourquoi avions-nous besoin de faire quoi que ce soit (tout va toujours bien sur VKontakte, n'est-ce pas ?). Nous voulions collecter des journaux de débogage (et il y avait des centaines de téraoctets de données), peut-être qu'il serait plus pratique de calculer des statistiques ; et nous disposons d'une flotte de dizaines de milliers de serveurs à partir desquels tout cela doit être fait.
Pourquoi avons-nous décidé ? Nous avions probablement des solutions pour stocker les journaux. Ici – il existe un tel « Backend VK » public. Je recommande fortement de s'y abonner.
Que sont les journaux ? Il s'agit d'un moteur qui renvoie des tableaux vides. Les moteurs de VK sont ce que d'autres appellent des microservices. Et voici un sticker souriant (pas mal de likes). Comment ça? Eh bien, écoutez plus loin !

Que peut-on utiliser pour stocker les journaux ? Il est impossible de ne pas mentionner Hadup. Puis, par exemple, Rsyslog (stockage de ces journaux dans des fichiers). LSD. Qui sait ce qu'est le LSD ? Non, pas ce LSD. Stockez également les fichiers, respectivement. Eh bien, ClickHouse est une option étrange.
Clickhouse et concurrents : exigences et opportunités
Que voulons-nous? Nous voulons nous assurer que nous n’avons pas trop à nous soucier du fonctionnement, afin qu’il fonctionne immédiatement, de préférence avec une configuration minimale. Nous voulons écrire beaucoup et écrire vite. Et nous voulons le conserver pendant toutes sortes de mois, d'années, c'est-à-dire pendant longtemps. Nous voudrons peut-être comprendre un problème avec lequel ils sont venus nous voir et nous ont dit : « Quelque chose ne fonctionne pas ici », et c'était il y a 3 mois), et nous voulons pouvoir voir ce qui s'est passé il y a 3 mois. " La compression des données – ce serait clairement un avantage – car elle réduit la quantité d’espace qu’elle occupe.

Et nous avons une exigence tellement intéressante : nous écrivons parfois le résultat de certaines commandes (par exemple, les journaux), cela peut faire plus de 4 kilo-octets assez facilement. Et si cette chose fonctionne via UDP, alors elle n'a pas besoin de dépenser... elle n'aura pas de « surcharge » pour la connexion, et pour un grand nombre de serveurs, ce sera un plus.

Voyons ce que l'open source nous offre. Premièrement, nous avons le moteur de journaux - c'est notre moteur ; En principe, il peut tout faire, il peut même écrire de longues lignes. Eh bien, il ne compresse pas les données de manière transparente - nous pouvons compresser nous-mêmes de grandes colonnes si nous le voulons... nous ne voulons bien sûr pas le faire (si possible). Le seul problème est qu’il ne peut donner que ce qui correspond à sa mémoire ; Pour lire le reste, vous devez récupérer le binlog de ce moteur et, par conséquent, cela prend beaucoup de temps.

Quelles sont les autres options ? Par exemple, "Hadup". Facilité d'utilisation... Qui pense que Hadup est facile à mettre en place ? Bien entendu, il n’y a aucun problème avec l’enregistrement. Lors de la lecture, des questions se posent parfois. En principe, je dirais probablement non, surtout pour les logs. Stockage à long terme - bien sûr, oui, compression des données - oui, longues chaînes - il est clair que vous pouvez enregistrer. Mais enregistrer depuis un grand nombre de serveurs... Encore faut-il faire quelque chose soi-même !
Rsyslog. En fait, nous l'avons utilisé comme option de sauvegarde pour pouvoir le lire sans vider le binlog, mais il ne peut pas écrire de longues lignes ; en principe, il ne peut pas écrire plus de 4 kilo-octets. Vous devez effectuer vous-même la compression des données de la même manière. La lecture viendra des fichiers.

Ensuite, il y a le développement « badushka » du LSD. Essentiellement identique à « Rsyslog » : il prend en charge les chaînes longues, mais il ne peut pas fonctionner sur UDP et, en fait, à cause de cela, malheureusement, il y a pas mal de choses qui doivent être réécrites. LSD doit être repensé pour pouvoir enregistrer à partir de dizaines de milliers de serveurs.

Et ici! Une option amusante est ElasticSearch. Comment dire? Il réussit bien en lecture, c'est-à-dire qu'il lit vite, mais pas très bien en écriture. Premièrement, s’il compresse les données, il est très faible. Très probablement, une recherche complète nécessite des structures de données plus volumineuses que le volume d'origine. Son fonctionnement est difficile et des problèmes surviennent souvent. Et encore une fois, pour enregistrer dans Elastic, nous devons tout faire nous-mêmes.

Ici, ClickHouse est bien sûr une option idéale. Le seul problème est que l’enregistrement à partir de dizaines de milliers de serveurs pose problème. Mais il y a au moins un problème que nous pouvons essayer de résoudre d’une manière ou d’une autre. Et le reste du rapport porte sur ce problème. Quel type de performances pouvez-vous attendre de ClickHouse ?
Comment allons-nous l'insérer ? Fusionner l'arbre
Qui d’entre vous n’a pas entendu parler ou ne connaît pas « ClickHouse » ? Je dois te le dire, n'est-ce pas ? Très vite. L'insertion là-bas - 1 à 2 gigabits par seconde, des rafales allant jusqu'à 10 gigabits par seconde peuvent en fait supporter cette configuration - il y a deux Xeon à 6 cœurs (c'est-à-dire même pas le plus puissant), 256 gigaoctets de RAM, 20 téraoctets en RAID (personne configuré, paramètres par défaut). Alexey Milovidov, développeur de ClickHouse, est probablement assis là à pleurer parce que nous n'avons rien configuré (tout a fonctionné comme ça pour nous). En conséquence, une vitesse de balayage d'environ 6 milliards de lignes par seconde peut être obtenue si les données sont bien compressées. Si vous aimez % sur une chaîne de texte - 100 millions de lignes par seconde, cela semble assez rapide.

Comment allons-nous l'insérer ? Eh bien, vous savez que VK utilise PHP. Nous insérerons chaque travailleur PHP via HTTP dans « ClickHouse », dans la table MergeTree pour chaque enregistrement. Qui voit un problème dans ce système ? Pour une raison quelconque, tout le monde n’a pas levé la main. Laisse moi te dire.
Premièrement, il y a beaucoup de serveurs - par conséquent, il y aura beaucoup de (mauvaises) connexions. Ensuite, il est préférable d'insérer des données dans MergeTree pas plus d'une fois par seconde. Et qui sait pourquoi ? OK OK. Je vais vous en dire un peu plus à ce sujet. Une autre question intéressante est que nous ne faisons pas d'analyse, nous n'avons pas besoin d'enrichir les données, nous n'avons pas besoin de serveurs intermédiaires, nous voulons les insérer directement dans "ClickHouse" (de préférence - plus directement, mieux c'est).

Par conséquent, comment se fait l’insertion dans MergeTree ? Pourquoi est-il préférable de ne pas l'insérer plus d'une fois par seconde ou moins souvent ? Le fait est que "ClickHouse" est une base de données en colonnes et trie les données par ordre croissant de clé primaire, et lorsque vous effectuez une insertion, un nombre de fichiers est créé au moins égal au nombre de colonnes dans lesquelles les données sont triées. par ordre croissant de la clé primaire (un répertoire séparé est créé, un ensemble de fichiers sur le disque pour chaque insertion). Ensuite, l'insertion suivante arrive, et en arrière-plan, elles sont combinées en « partitions » plus grandes. Puisque les données sont triées, il est possible de « fusionner » deux fichiers triés sans consommer beaucoup de mémoire.
Mais, comme vous pouvez le deviner, si vous écrivez 10 fichiers pour chaque insertion, ClickHouse (ou votre serveur) se terminera rapidement, il est donc recommandé d'insérer de gros lots. En conséquence, nous n’avons jamais lancé le premier projet en production. Nous en avons immédiatement lancé un, qui ici n°2 présente :

Imaginez ici qu'il y ait environ un millier de serveurs sur lesquels nous avons lancé, il n'y a que PHP. Et sur chaque serveur se trouve notre agent local, que nous appelons « Kittenhouse », qui maintient une connexion avec « ClickHouse » et insère des données toutes les quelques secondes. Insère les données non pas dans MergeTree, mais dans une table tampon, qui sert précisément à éviter de les insérer directement dans MergeTree.
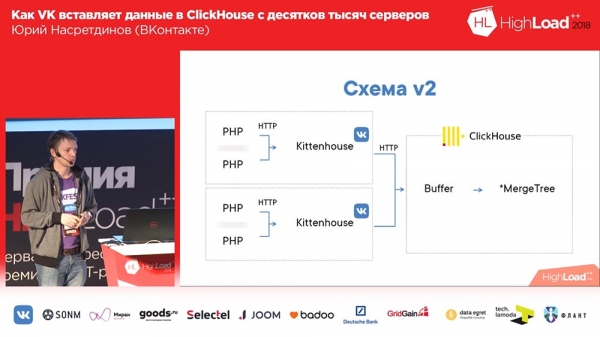
Travailler avec des tables tampon
Ce que c'est? Les tables tampons sont un morceau de mémoire fragmentée (c'est-à-dire qu'elle peut y être insérée fréquemment). Ils sont constitués de plusieurs morceaux, et chacun des morceaux fonctionne comme un tampon indépendant, et ils sont vidés indépendamment (si vous avez plusieurs morceaux dans le tampon, il y aura alors plusieurs insertions par seconde). Il est possible de lire à partir de ces tables - vous lisez ensuite l'union du contenu du tampon et de la table parent, mais à ce moment l'écriture est bloquée, il est donc préférable de ne pas lire à partir de là. Et les tableaux de tampons affichent de très bons QPS, c'est-à-dire que jusqu'à 3 XNUMX QPS, vous n'aurez aucun problème lors de l'insertion. Il est clair que si le serveur tombe en panne de courant, les données peuvent être perdues, car elles n'étaient stockées qu'en mémoire.

Dans le même temps, le schéma avec un tampon complique ALTER, car vous devez d'abord supprimer l'ancienne table tampon avec l'ancien schéma (les données ne disparaîtront nulle part, car elles seront vidées avant que la table ne soit supprimée). Ensuite, vous « modifiez » la table dont vous avez besoin et créez à nouveau la table tampon. Par conséquent, même s'il n'y a pas de table tampon, vos données ne circuleront nulle part, mais vous pouvez les avoir sur le disque au moins localement.

Qu’est-ce que Kittenhouse et comment ça marche ?
Qu’est-ce que KittenHouse ? Ceci est un proxy. Devinez quelle langue ? J'ai rassemblé les sujets les plus en vogue dans mon rapport - "Clickhouse", Go, peut-être que je me souviendrai d'autre chose. Oui, c’est écrit en Go, parce que je ne sais pas trop écrire en C, je ne veux pas.

En conséquence, il maintient une connexion avec chaque serveur et peut écrire en mémoire. Par exemple, si nous écrivons des journaux d'erreurs sur Clickhouse, alors si Clickhouse n'a pas le temps d'insérer des données (après tout, si trop de données sont écrites), alors nous ne gonflons pas la mémoire - nous jetons simplement le reste. Parce que si nous écrivons plusieurs gigabits par seconde d’erreurs, nous pourrons probablement en rejeter. Kittenhouse peut le faire. De plus, il peut effectuer une livraison fiable, c'est-à-dire écrire sur le disque de la machine locale et une fois à chaque fois (là-bas, toutes les deux secondes), il essaie de fournir les données de ce fichier. Et au début, nous avons utilisé le format Values standard - pas un format binaire, un format texte (comme dans le SQL standard).
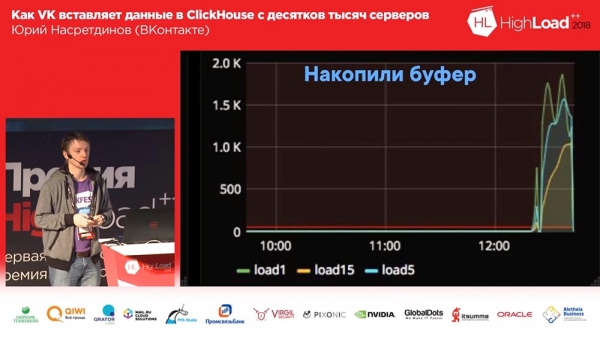
Mais ensuite, ceci s'est produit. Nous avons utilisé une livraison fiable, écrit des journaux, puis décidé (c'était un cluster de test conditionnel)... Il a été éteint pendant plusieurs heures et relancé, et une insertion a commencé à partir d'un millier de serveurs - il s'est avéré que Clickhouse avait encore un "Thread sur connexion" - en conséquence, dans mille connexions, une insertion active entraîne une charge moyenne sur le serveur d'environ un millier et demi. Étonnamment, le serveur a accepté les demandes, mais les données ont quand même été insérées après un certain temps ; mais c'était très difficile pour le serveur de le servir.
Ajouter nginx
Une telle solution pour le modèle Thread par connexion est nginx. Nous avons installé nginx devant Clickhouse, mis en place en même temps un équilibrage pour deux répliques (notre vitesse d'insertion a augmenté de 2 fois, même si ce n'est pas un fait que cela devrait être le cas) et limité le nombre de connexions à Clickhouse, au en amont et, par conséquent, plus de 50 connexions, il semble inutile d'insérer.
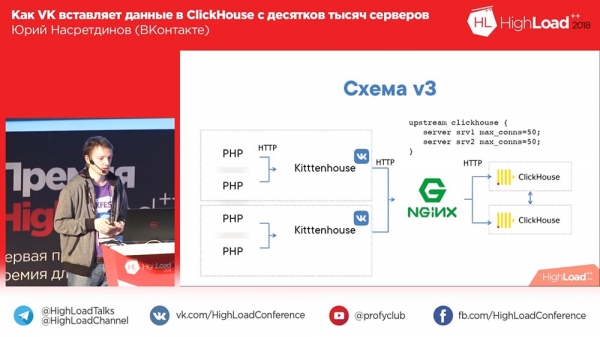
Ensuite, nous avons réalisé que ce schéma présentait généralement des inconvénients, car nous n'avons ici qu'un seul nginx. En conséquence, si ce nginx plante, malgré la présence de répliques, nous perdons des données ou, du moins, n'écrivons nulle part. C'est pourquoi nous avons créé notre propre équilibrage de charge. Nous avons également réalisé que "Clickhouse" était toujours adapté aux journaux, et le "démon" a également commencé à écrire ses journaux dans "Clickhouse" - très pratique, pour être honnête. Nous l'utilisons encore pour d'autres « démons ».

Ensuite, nous avons découvert ce problème intéressant : si vous utilisez une méthode d'insertion non standard en mode SQL, cela force un analyseur SQL à part entière basé sur AST, ce qui est assez lent. En conséquence, nous avons ajouté des paramètres pour garantir que cela ne se produise jamais. Nous avons effectué un équilibrage de charge et des contrôles de santé, de sorte que si l'un d'eux meurt, nous laissons toujours les données. Nous avons maintenant un grand nombre de tables dont nous avons besoin pour avoir différents clusters Clickhouse. Et nous avons également commencé à réfléchir à d'autres utilisations - par exemple, nous voulions écrire des journaux à partir de modules nginx, mais ils ne savent pas comment communiquer avec notre RPC. Eh bien, j'aimerais leur apprendre à envoyer au moins d'une manière ou d'une autre - par exemple, recevoir des événements sur localhost via UDP, puis les transmettre à Clickhouse.
À un pas de la solution
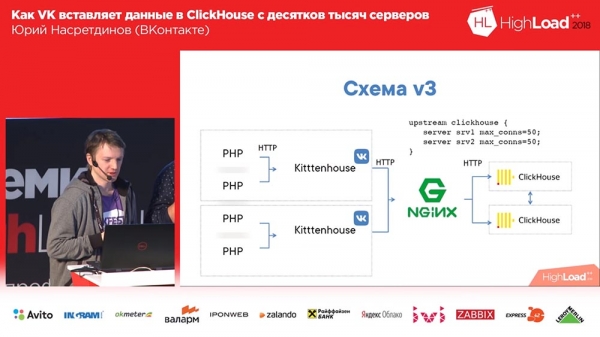
Le schéma final a commencé à ressembler à ceci (la quatrième version de ce schéma) : sur chaque serveur devant Clickhouse il y a nginx (sur le même serveur) et il transmet simplement les requêtes à localhost avec une limite sur le nombre de connexions de 50 pièces. Et ce système fonctionnait déjà assez bien, tout allait plutôt bien avec.
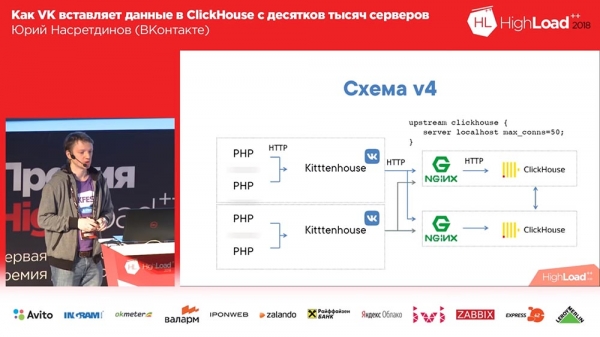
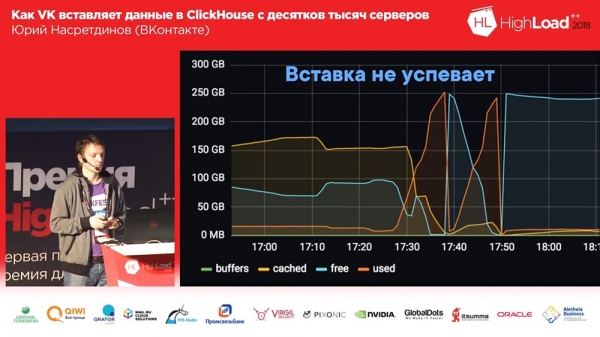
Nous avons vécu ainsi pendant environ un mois. Tout le monde était content, ils ont ajouté des tables, ils ont ajouté, ils ont ajouté... En général, il s'est avéré que la façon dont nous avons ajouté les tables tampons n'était pas très optimale (disons-le ainsi). Nous avons réalisé 16 pièces dans chaque tableau et un intervalle de flash de quelques secondes ; nous avions 20 tables et chaque table recevait 8 insertions par seconde - et c'est à ce moment-là que « Clickhouse » a commencé... les enregistrements ont commencé à ralentir. Ils ne sont même pas passés par là... Nginx par défaut avait une chose tellement intéressante que si les connexions se terminaient en amont, alors il renvoyait simplement « 502 » à toutes les nouvelles requêtes.

Et ici nous avons (je viens de regarder les journaux dans Clickhouse lui-même) environ un demi pour cent des demandes ont échoué. En conséquence, l'utilisation du disque était élevée et de nombreuses fusions ont eu lieu. Eh bien, qu'est-ce que j'ai fait ? Naturellement, je n’ai pas pris la peine de comprendre pourquoi exactement la connexion et l’amont se sont terminés.
Remplacer nginx par un proxy inverse
J'ai décidé que nous devions gérer cela nous-mêmes, nous n'avions pas besoin de laisser nginx s'en charger - nginx ne sait pas quelles tables il y a dans Clickhouse, et j'ai remplacé nginx par un proxy inverse, que j'ai également écrit moi-même.
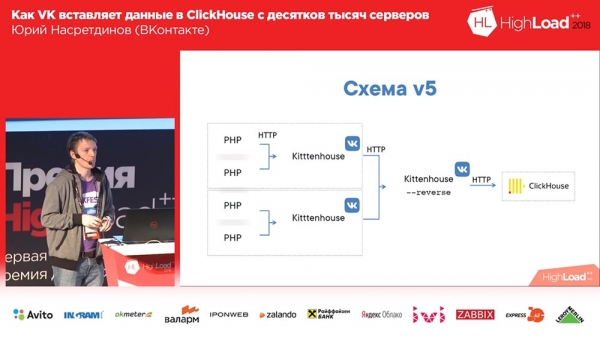
Que fait-il? Il fonctionne sur la base de la bibliothèque fasthttp « goshnoy », c'est-à-dire rapide, presque aussi rapide que nginx. Désolé, Igor, si vous êtes présent ici (note : Igor Sysoev est un programmeur russe qui a créé le serveur web nginx). Il peut comprendre de quel type de requêtes il s'agit – INSERT ou SELECT – en conséquence, il contient différents pools de connexions pour différents types de requêtes.

Ainsi, même si nous n'avons pas le temps de terminer les demandes d'insertion, les « sélections » passeront, et vice versa. Et il regroupe les données dans des tables tampon - avec un petit tampon : s'il y avait des erreurs, des erreurs de syntaxe, etc. - afin qu'elles n'affectent pas beaucoup le reste des données, car lorsque nous les insérons simplement dans des tables tampon, nous il y avait un petit "bachi", et toutes les erreurs de syntaxe seulement affectaient ce petit morceau; et ici, ils affecteront déjà un grand tampon. Petit correspond à 1 mégaoctet, c'est-à-dire pas si petit.
L'insertion d'une synchronisation et le remplacement essentiellement de nginx font essentiellement la même chose que nginx faisait auparavant - vous n'avez pas besoin de changer le "Kittenhouse" local pour cela. Et comme il utilise fasthttp, il est très rapide : vous pouvez effectuer plus de 100 XNUMX requêtes par seconde pour des insertions uniques via un proxy inverse. Théoriquement, vous pouvez insérer une ligne à la fois dans le proxy inverse Kittenhouse, mais bien sûr, nous ne le faisons pas.
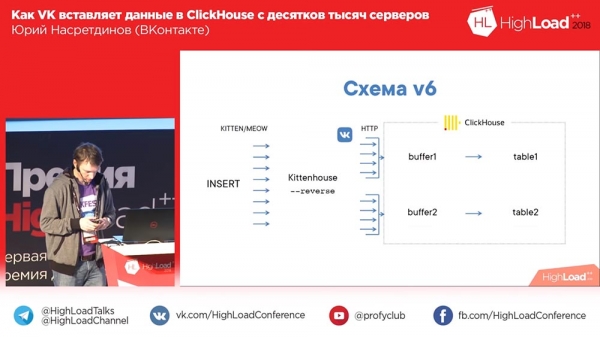
Le schéma a commencé à ressembler à ceci : « Kittenhouse », le proxy inverse regroupe de nombreuses requêtes dans des tables et, à leur tour, les tables tampon les insèrent dans les principales.
Killer est une solution temporaire, Kitten est permanent
C'est un problème intéressant... L'un d'entre vous a-t-il utilisé fasthttp ? Qui a utilisé fasthttp avec les requêtes POST ? Cela n'aurait probablement pas dû être fait, car cela met en mémoire tampon le corps de la requête par défaut et la taille de notre tampon a été définie sur 16 mégaoctets. L'insertion a cessé de suivre à un moment donné et des morceaux de 16 mégaoctets ont commencé à arriver des dizaines de milliers de serveurs, et ils ont tous été mis en mémoire tampon avant d'être envoyés à Clickhouse. En conséquence, la mémoire s'est épuisée, le Out-Of-Memory Killer est venu et a tué le proxy inverse (ou « Clickhouse », qui pourrait théoriquement « manger » plus que le proxy inverse). Le cycle s'est répété. Ce n’est pas un problème très agréable. Bien que nous ne soyons tombés dessus qu'après plusieurs mois de fonctionnement.
Ce que j'ai fait? Encore une fois, je n'aime pas vraiment comprendre ce qui s'est passé exactement. Je pense qu'il est assez évident que vous ne devriez pas mettre en mémoire tampon. Je n'ai pas pu patcher fasthttp, même si j'ai essayé. Mais j'ai trouvé un moyen de faire en sorte qu'il n'y ait pas besoin de patcher quoi que ce soit, et j'ai trouvé ma propre méthode en HTTP - je l'ai appelée KITTEN. Eh bien, c'est logique - "VK", "Chaton"... Quoi d'autre ?..

Si une requête parvient au serveur avec la méthode Kitten, alors le serveur doit répondre « miaou » - logiquement. S'il répond à cela, alors on considère qu'il comprend ce protocole, puis j'intercepte la connexion (fasthttp a une telle méthode), et la connexion passe en mode « brut ». Pourquoi en ai-je besoin ? Je souhaite contrôler la manière dont la lecture à partir des connexions TCP se produit. TCP a une propriété merveilleuse : si personne ne lit de l'autre côté, alors l'écriture commence à attendre et la mémoire n'est pas particulièrement dépensée pour cela.
Et donc j'ai lu environ 50 clients à la fois (sur cinquante car cinquante devraient certainement suffire, même si le tarif vient d'un autre DC)... La consommation a diminué avec cette approche au moins 20 fois, mais moi, pour être honnête , je n'ai pas pu mesurer exactement quelle heure, car c'est déjà inutile (c'est déjà atteint le niveau d'erreur). Le protocole est binaire, c'est-à-dire qu'il contient le nom et les données de la table ; il n'y a pas d'en-tête http, donc je n'ai pas utilisé de socket Web (je n'ai pas besoin de communiquer avec les navigateurs - j'ai créé un protocole qui répond à nos besoins). Et tout s'est bien passé pour lui.
La table tampon est triste
Récemment, nous sommes tombés sur une autre fonctionnalité intéressante des tables tampon. Et ce problème est déjà bien plus douloureux que les autres. Imaginons cette situation : vous utilisez déjà activement Clickhouse, vous disposez de dizaines de serveurs Clickhouse, et vous avez des requêtes qui sont très longues à lire (disons, plus de 60 secondes) ; et vous venez faire Alter à ce moment-là... En attendant, les « sélections » qui ont commencé avant « Alter » ne seront pas incluses dans ce tableau, « Alter » ne démarrera pas - probablement certaines caractéristiques du fonctionnement de « Clickhouse » dans cet endroit. Peut-être que cela peut être corrigé ? Ou est-ce impossible ?

En général, il est clair qu'en réalité ce n'est pas un si gros problème, mais avec les tables tampons, cela devient plus pénible. Parce que, si, disons, votre « Alter » expire (et il peut expirer sur un autre hôte - pas sur le vôtre, mais sur une réplique, par exemple), alors... Vous avez supprimé la table tampon, votre « Alter » ( ou un autre hôte) a expiré. puis une erreur « Alter » s'est produite) - vous devez toujours vous assurer que les données continuent d'être écrites : vous recréez les tables tampon (selon le même schéma que la table parent), puis « Alter » passe, se termine après tout, et le tampon dans lequel la table commence à différer du schéma de celui du parent. Selon ce qu'était le "Alter", l'insertion peut ne plus aller dans cette table tampon - c'est très triste.

Il existe également un tel signe (peut-être que quelqu'un l'a remarqué) - il s'appelle query_thread_log dans les nouvelles versions de Clickhouse. Par défaut, dans certaines versions, il y en avait un. Ici, nous avons accumulé 840 millions d'enregistrements en quelques mois (100 gigaoctets). Cela est dû au fait que des « inserts » y ont été écrits (peut-être que maintenant, d'ailleurs, ils ne sont pas écrits). Comme je vous l'ai dit, nos « inserts » sont petits - nous avons eu beaucoup d'« inserts » dans les tables tampons. Il est clair que ceci est désactivé - je vous dis juste ce que j'ai vu sur notre serveur. Pourquoi? C'est un autre argument contre l'utilisation de tables tampon ! Spotty est très triste.

Qui savait que ce type s'appelait Spotty ? Les employés de VK ont levé la main. D'ACCORD.
À propos des projets de « KitttenHouse »
Habituellement, les plans ne sont pas partagés, n'est-ce pas ? Du coup, vous ne les remplirez pas et vous ne paraîtrez plus très bien aux yeux des autres. Mais je prends le risque ! Nous voulons faire ce qui suit : les tables tampons, me semble-t-il, sont toujours une béquille et nous devons tamponner nous-mêmes l'insertion. Mais nous ne voulons toujours pas le mettre en mémoire tampon sur le disque, nous allons donc mettre en mémoire tampon l'insertion.

En conséquence, lorsqu'une "insertion" est effectuée, elle ne sera plus synchrone - elle fonctionnera déjà comme une table tampon, s'insérera dans la table parent (enfin, un jour plus tard) et signalera via un canal séparé quelles insertions ont réussi et lesquelles ne pas avoir.

Pourquoi ne puis-je pas quitter l'insertion synchrone ? C'est beaucoup plus pratique. Le fait est que si vous insérez 10 100 hôtes, tout va bien - vous obtiendrez un peu de chaque hôte, vous y insérez une fois par seconde, tout va bien. Mais j'aimerais que ce schéma fonctionne, par exemple, à partir de deux machines, afin que vous puissiez télécharger à grande vitesse - peut-être pas tirer le maximum de Clickhouse, mais écrire au moins XNUMX mégaoctets par seconde à partir d'une machine via un proxy inverse - pour cela, le schéma doit s'adapter à la fois aux grandes et aux petites quantités, nous ne pouvons donc pas attendre une seconde pour chaque insertion, il doit donc être asynchrone. Et de la même manière, les confirmations asynchrones devraient intervenir une fois l'insertion terminée. Nous saurons si cela a été adopté ou non.
Le plus important est que dans ce schéma, nous sachions avec certitude si l'insertion a eu lieu ou non. Imaginez cette situation : vous avez une table tampon, vous y avez écrit quelque chose, puis, disons, la table est passée en mode lecture seule et a essayé de vider la mémoire tampon. Où iront les données ? Ils resteront dans le tampon. Mais nous ne pouvons pas en être sûrs - et s'il y avait une autre erreur, à cause de laquelle les données ne resteront pas dans le tampon... (S'adresse à Alexey Milovidov, Yandex, développeur ClickHouse) Ou restera-t-il ? Toujours? Alexey nous convainc que tout ira bien. Nous n'avons aucune raison de ne pas le croire. Mais quand même : si nous n’utilisons pas de tables tampons, elles ne poseront aucun problème. Créer deux fois plus de tables n'est pas non plus pratique, même si en principe il n'y a pas de gros problèmes. C'est le plan.
Parlons de lecture
Parlons maintenant de lecture. Nous avons également écrit notre propre outil ici. Il semblerait, eh bien, pourquoi écrire votre propre instrument ici ?... Et qui a utilisé Tabix ? D'une manière ou d'une autre, peu de gens ont levé la main... Et qui est satisfait de la performance de Tabix ? Eh bien, nous n’en sommes pas satisfaits et ce n’est pas très pratique pour visualiser des données. C'est bien pour l'analyse, mais juste pour la visualisation, ce n'est clairement pas optimisé. J'ai donc écrit ma propre interface.

C'est très simple : il ne peut lire que des données. Il ne sait pas afficher des graphiques, il ne sait rien faire. Mais il peut montrer ce dont nous avons besoin : par exemple, combien de lignes il y a dans le tableau, combien d'espace il occupe (sans le décomposer en colonnes), c'est-à-dire qu'une interface très basique est ce dont nous avons besoin.
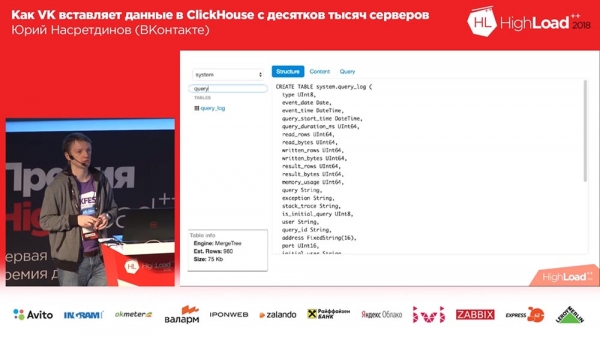
Et cela ressemble beaucoup à Sequel Pro, mais uniquement réalisé sur Bootstrap de Twitter et sur la deuxième version. Vous demandez : « Yuri, pourquoi sur la deuxième version ? Quelle année? 2018 ? En général, je l'ai fait il y a assez longtemps pour « Muscle » (MySQL) et j'ai juste modifié quelques lignes dans les requêtes là-bas, et cela a commencé à fonctionner pour « Clickhouse », pour lequel un merci spécial ! Parce que l'analyseur est très similaire à celui « musculaire », et les requêtes sont très similaires - très pratiques, surtout au début.
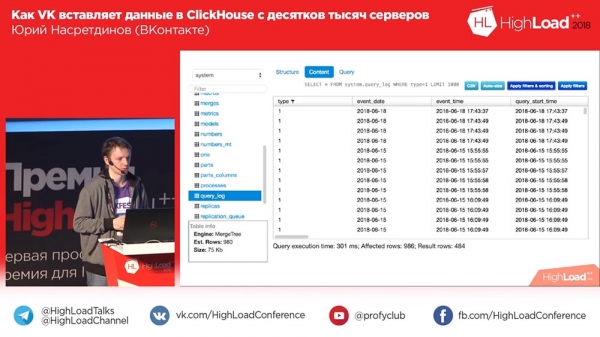
Eh bien, il peut filtrer les tables, afficher la structure et le contenu de la table, vous permet de trier, de filtrer par colonnes, affiche la requête qui a abouti au résultat, les lignes affectées (combien en conséquence), c'est-à-dire le éléments de base pour visualiser les données. Assez rapide.
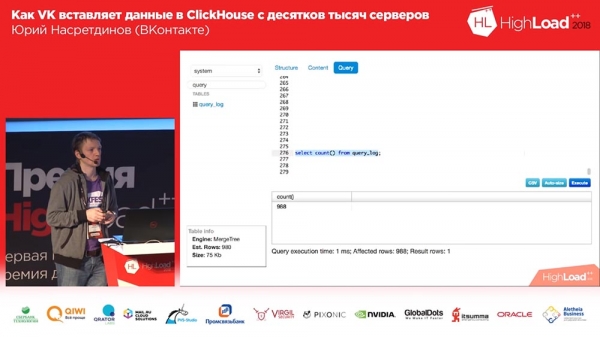
Il y a aussi un éditeur. Honnêtement, j'ai essayé de voler l'intégralité de l'éditeur de Tabix, mais je n'ai pas pu. Mais d’une manière ou d’une autre, ça marche. En principe, c'est tout.
"Clickhouse" convient aux tanières
Je tiens à vous dire que Clickhouse, malgré tous les problèmes décrits, est très bien adapté aux bûches. Plus important encore, cela résout notre problème : il est très rapide et vous permet de filtrer les journaux par colonnes. En principe, les tables tampons ne fonctionnent pas bien, mais généralement personne ne sait pourquoi... Peut-être que maintenant vous savez mieux où vous rencontrerez des problèmes.

TCP ? En général, dans VK, il est d'usage d'utiliser UDP. Et quand j'utilisais TCP... Bien sûr, personne ne m'a dit : « Yuri, de quoi tu parles ! Vous ne pouvez pas, vous avez besoin d’UDP. Il s'est avéré que TCP n'est pas si effrayant. La seule chose est que si vous écrivez des dizaines de milliers de composés actifs, vous devez les préparer un peu plus soigneusement ; mais c'est possible et assez facile.
J'ai promis de publier « Kittenhouse » et « Lighthouse » sur HighLoad Sibérie si tout le monde s'abonnait à notre « backend VK » public... Et vous savez, tout le monde n'est pas abonné... Bien sûr, je n'exigerai pas que vous vous abonniez à notre publique. Vous êtes encore trop nombreux, quelqu'un peut même être offensé, mais quand même, abonnez-vous (et là je dois faire des yeux comme ceux d'un chat). C'est . Merci beaucoup! Github est à nous . Avec Clickhouse vos cheveux seront doux et soyeux.

Modérateur - Amis, maintenant pour les questions. Juste après nous vous présentons le certificat d'appréciation et votre rapport en VHS.
Yuri Nasretdinov (ci-après dénommé YN) : – Comment avez-vous pu enregistrer mon reportage en VHS s’il vient de se terminer ?

Modérateur – Vous aussi, vous ne pouvez pas déterminer pleinement comment « Clickhouse » fonctionnera ou non ! Amis, 5 minutes pour les questions !
des questions
Question du public (ci-après dénommée Q) : - Bon après-midi. Merci beaucoup pour le rapport. J'ai deux questions. Je vais commencer par quelque chose de frivole : le nombre de lettres t dans le nom "Kittenhouse" dans les schémas (3, 4, 7...) affecte-t-il la satisfaction des chats ?
ON : - Quantité de quoi ?
Z : – Lettre t. Il y a trois t, quelque part autour de trois t.
ON : - Je ne l'ai pas réparé ? Eh bien, bien sûr que oui ! Ce sont des produits différents – je vous trompais tout ce temps. D'accord, je plaisante, ça n'a pas d'importance. Ah, juste ici ! Non, c'est la même chose, j'ai fait une faute de frappe.
Z : - Merci. La deuxième question est sérieuse. D'après ce que je comprends, dans Clickhouse, les tables tampons vivent exclusivement en mémoire, ne sont pas mises en mémoire tampon sur le disque et, par conséquent, ne sont pas persistantes.
ON : - Oui.
Z : – Et en même temps, votre client met en mémoire tampon sur disque, ce qui implique une certaine garantie de livraison de ces mêmes logs. Mais cela n'est en aucun cas garanti chez Clickhouse. Expliquez comment s'effectue la garantie, à cause de quoi ?.. Voici ce mécanisme plus en détail
ON : – Oui, en théorie, il n’y a pas de contradictions ici, car lorsque Clickhouse tombe, on peut le détecter de mille manières différentes. Si Clickhouse plante (s'il se termine mal), vous pouvez, en gros, rembobiner un peu votre journal que vous avez écrit et recommencer à partir du moment où tout allait parfaitement bien. Disons que vous rembobinez une minute, c'est-à-dire que l'on considère que vous avez tout vidé en une minute.
Z : – Autrement dit, « Kittenhouse » tient la fenêtre plus longtemps et, en cas de chute, peut la reconnaître et la rembobiner ?
ON : – Mais c’est en théorie. Dans la pratique, nous ne le faisons pas, et une livraison fiable va de zéro à l'infini. Mais en moyenne un. Nous sommes convaincus que si Clickhouse plante pour une raison quelconque ou si les serveurs « redémarrent », nous perdons un peu. Dans tous les autres cas, rien ne se passera.
Z : - Bonjour. Dès le début, il m'a semblé que vous utiliseriez effectivement UDP dès le début du rapport. Vous avez http, tout ça... Et la plupart des problèmes que vous avez décrits, si je comprends bien, ont été causés par cette solution particulière...
ON : – Qu’utilise-t-on TCP ?
Z : - Essentiellement oui.
ON : -Non.
Z : – C’est avec fasthttp que vous avez eu des problèmes, avec la connexion vous avez eu des problèmes. Si vous aviez simplement utilisé UDP, vous auriez gagné du temps. Bon, il y aurait des problèmes avec les messages longs ou autre chose...
ON : - Avec quoi?

Z : – Avec des messages longs, puisqu'ils peuvent ne pas rentrer dans le MTU, autre chose... Eh bien, il peut y avoir leurs propres problèmes. La question est : pourquoi pas UDP ?
ON : – Je crois que les auteurs qui ont développé TCP/IPIls sont bien plus compétents que moi et savent mieux sérialiser les paquets (pour qu'ils arrivent à destination), tout en ajustant la fenêtre d'envoi, sans surcharger le réseau, en fournissant des informations sur les données non lues et sans avoir à compter depuis l'autre extrémité… À mon avis, tous ces problèmes existeraient aussi avec UDP, mais je devrais écrire encore plus de code pour les implémenter moi-même, et probablement de manière médiocre. Je n'aime déjà pas programmer en C, alors imaginez avec UDP…
Z : - Juste pratique ! Envoyé ok et n’attendez rien – c’est complètement asynchrone. Une notification est revenue indiquant que tout allait bien - cela signifie qu'elle est arrivée ; Si ça ne vient pas, c’est que c’est mauvais.
ON : – J'ai besoin des deux – je dois pouvoir envoyer les deux avec et sans garantie de livraison. Ce sont deux scénarios différents. Je ne dois pas perdre certains journaux ou ne pas les perdre dans des limites raisonnables.
Z : – Je ne perdrai pas de temps. Cela doit être discuté davantage. Merci.
Modérateur – Qui a des questions – les mains vers le ciel !

Z : - Bonjour, je m'appelle Sasha. Quelque part au milieu du rapport, il y avait le sentiment qu'en plus de TCP, il était possible d'utiliser une solution toute faite - une sorte de Kafka.
ON : – Eh bien... je t'ai dit que je ne voulais pas utiliser de serveurs intermédiaires, parce que... chez Kafka, il s'avère que nous avons dix mille hôtes ; en fait, nous en avons davantage : des dizaines de milliers d’hôtes. Il peut également être pénible de travailler avec Kafka sans aucun mandataire. De plus, et surtout, cela donne toujours de la « latence », cela donne des hôtes supplémentaires dont vous avez besoin. Mais je ne veux pas les avoir - je veux...
Z : "Mais finalement, c'est comme ça que ça s'est passé."
ON : – Non, il n’y a pas d’hôtes ! Tout cela fonctionne sur les hôtes Clickhouse.
Z : - Eh bien, et « Kittenhouse », ce qui est l'inverse - où habite-t-il ?

ON : – Sur l'hôte Clickhouse, il n'écrit rien sur le disque.
Z : - Supposons.
Modérateur - Es-tu satisfait? Pouvons-nous vous donner un salaire ?
Z : - Oui, vous pouvez. En fait, il y a beaucoup de béquilles pour obtenir la même chose, et maintenant - la réponse précédente sur le thème TCP contredit, à mon avis, cette situation. J’ai juste l’impression que tout aurait pu être fait à genoux en beaucoup moins de temps.
ON : – Et aussi pourquoi je ne voulais pas utiliser Kafka, car il y avait beaucoup de plaintes dans le chat Clickhouse Telegram selon lesquelles, par exemple, des messages de Kafka étaient perdus. Pas de Kafka lui-même, mais de l'intégration de Kafka et Clickhaus ; ou quelque chose ne s'est pas connecté là-bas. En gros, il faudrait alors écrire un client pour Kafka. Je ne pense pas qu'il puisse y avoir de solution plus simple ou plus fiable.
Z : – Dis-moi, pourquoi n’as-tu pas essayé de faire la queue ou de prendre un bus commun ? Puisque vous dites qu'avec l'asynchronie, vous pourriez envoyer les journaux eux-mêmes via la file d'attente et recevoir la réponse de manière asynchrone via la file d'attente ?

ON : – Veuillez suggérer quelles files d'attente pourraient être utilisées ?
Z : – N'importe lequel, même sans garantie qu'il soit en ordre. Une sorte de Redis, RMQ...
ON : – J'ai le sentiment que Redis ne sera probablement pas en mesure de générer un tel volume d'insertion, même sur un seul hôte (au sens de plusieurs serveurs) qui retire Clickhouse. Je ne peux étayer cela avec aucune preuve (je ne l'ai pas comparé), mais il me semble que Redis n'est pas la meilleure solution ici. En principe, ce système peut être considéré comme une file d’attente de messages improvisée, mais qui est conçue uniquement pour « Clickhouse »
Modérateur – Yuri, merci beaucoup. Je propose de terminer ici les questions et réponses et de dire à qui de ceux qui ont posé la question nous donnerons le livre.
ON : – Je voudrais offrir un livre à la première personne qui posera une question.
Modérateur - Merveilleux! Super! Fabuleux! Merci beaucoup!

Quelques publicités 🙂
Merci de rester avec nous. Vous aimez nos articles ? Vous voulez voir du contenu plus intéressant ? Soutenez-nous en passant une commande ou en recommandant à vos amis, , un analogue unique des serveurs d'entrée de gamme, que nous avons inventé pour vous : (disponible avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher dans le centre de données Equinix Tier IV à Amsterdam ? Ici seulement aux Pays-Bas! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - à partir de 99$ ! En savoir plus
Source: habr.com
