


Le Web moderne est presque impensable sans contenu multimédia : presque toutes les grand-mères possèdent un smartphone, tout le monde est sur les réseaux sociaux et les temps d'arrêt liés à la maintenance coûtent cher aux entreprises. Voici une transcription de l'histoire de l'entreprise sur la façon dont elle a organisé la livraison des photos à l'aide d'une solution matérielle, les problèmes de performances qu'elle a rencontrés au cours du processus, leurs causes et comment ces problèmes ont été résolus à l'aide d'une solution logicielle basée sur Nginx, tout en garantissant la tolérance aux pannes à tous les niveaux (). Nous remercions les auteurs de l'histoire d'Oleg Efimova et Alexandra Dymova, qui ont partagé leur expérience lors de la conférence .
— Commençons par une petite introduction sur la façon dont nous stockons et mettons en cache les photos. Nous avons un calque où nous les stockons et un calque où nous mettons en cache les photos. Dans le même temps, si nous voulons atteindre un taux de manipulation élevé et réduire la charge de stockage, il est important pour nous que chaque photo d'un utilisateur individuel se trouve sur un serveur de mise en cache. Sinon, il faudrait installer autant de disques que nous avons de serveurs. Notre taux de triage est d'environ 99%, c'est-à-dire que nous réduisons de 100 fois la charge de notre stockage, et pour ce faire, il y a 10 ans, lorsque tout cela était en cours de construction, nous avions 50 serveurs. En conséquence, pour diffuser ces photos, nous avions essentiellement besoin de 50 domaines externes desservis par ces serveurs.
Naturellement, la question s'est immédiatement posée : si l'un de nos serveurs tombe en panne et devient indisponible, quelle partie du trafic perdons-nous ? Nous avons regardé ce qui existait sur le marché et avons décidé d'acheter du matériel afin qu'il résolve tous nos problèmes. Le choix s'est porté sur la solution de la société du réseau F5 (qui a d'ailleurs récemment racheté NGINX, Inc) : BIG-IP Local Traffic Manager.

Ce que fait ce matériel (LTM) : il s'agit d'un routeur en fer qui effectue une redondance en fer de ses ports externes et vous permet d'acheminer le trafic en fonction de la topologie du réseau, de certains paramètres, et effectue des contrôles de santé. Il était important pour nous que ce matériel puisse être programmé. En conséquence, nous pourrions décrire la logique selon laquelle les photographies d'un utilisateur spécifique étaient servies à partir d'un cache spécifique. À quoi cela ressemble-t-il? Il existe un élément matériel qui examine Internet sur un domaine, une adresse IP, effectue le déchargement SSL, analyse les requêtes http, sélectionne un numéro de cache dans IRule, où aller et laisse le trafic y aller. En même temps, il effectue des contrôles de santé et, en cas d'indisponibilité d'une machine, nous avons fait en sorte que le trafic soit dirigé vers un serveur de sauvegarde. D'un point de vue configuration, il y a bien sûr quelques nuances, mais en général tout est assez simple : on enregistre une carte, correspondance d'un certain numéro avec notre IP sur le réseau, on dit qu'on va écouter sur les ports 80 et 443, nous disons que si le serveur est indisponible, alors vous devez envoyer du trafic vers celui de sauvegarde, dans ce cas le 35e, et nous décrivons un tas de logique sur la façon dont cette architecture doit être démontée. Le seul problème était que le langage dans lequel le matériel était programmé était Tcl. Si quelqu'un s'en souvient... ce langage est plus en écriture seule qu'un langage pratique pour la programmation :

Qu'avons-nous obtenu ? Nous avons reçu un matériel qui garantit la haute disponibilité de notre infrastructure, achemine tout notre trafic, offre des avantages pour la santé et fonctionne tout simplement. De plus, cela fonctionne depuis assez longtemps : au cours des 10 dernières années, il n'y a eu aucune plainte à ce sujet. Début 2018, nous envoyions déjà environ 80 80 photos par seconde. Cela représente environ XNUMX gigabits de trafic provenant de nos deux centres de données.
Cependant ...
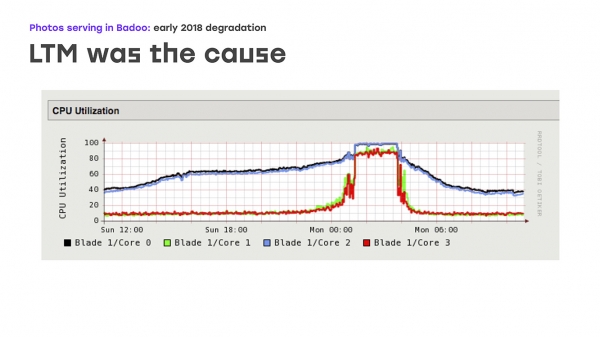
Début 2018, nous avons vu un tableau laid dans les charts : le temps nécessaire à l'envoi des photos avait nettement augmenté. Et ça ne nous convenait plus. Le problème est que ce comportement n'était visible qu'aux heures de pointe du trafic - pour notre entreprise, il s'agit de la nuit du dimanche au lundi. Mais le reste du temps, le système s’est comporté comme d’habitude, sans aucun signe de défaillance.

Il fallait néanmoins résoudre le problème. Nous avons identifié d’éventuels goulots d’étranglement et commencé à les éliminer. Tout d’abord, bien sûr, nous avons étendu les liaisons montantes externes, mené un audit complet des liaisons montantes internes et identifié tous les goulots d’étranglement possibles. Mais tout cela n’a pas donné de résultat évident, le problème n’a pas disparu.
Un autre goulot d'étranglement possible était la performance des caches de photos eux-mêmes. Et nous avons décidé que le problème venait peut-être d’eux. Eh bien, nous avons étendu les performances - principalement les ports réseau sur les caches de photos. Mais encore une fois, aucune amélioration évidente n’a été constatée. En fin de compte, nous avons prêté une attention particulière aux performances du LTM lui-même, et ici nous avons vu une triste image sur les graphiques : la charge sur tous les processeurs commence à se dérouler sans problème, mais arrive ensuite soudainement à un plateau. Dans le même temps, LTM cesse de répondre correctement aux contrôles de santé et aux liaisons montantes et commence à les désactiver de manière aléatoire, ce qui entraîne une grave dégradation des performances.
Autrement dit, nous avons identifié la source du problème, identifié le goulot d'étranglement. Reste à décider ce que nous ferons.
La première chose, et la plus évidente, que nous pourrions faire est de moderniser le LTM lui-même. Mais il y a quelques nuances ici, car ce matériel est assez unique, vous n'irez pas au supermarché le plus proche pour l'acheter. Il s’agit d’un contrat distinct, d’un contrat de licence distinct, et cela prendra beaucoup de temps. La deuxième option consiste à commencer à réfléchir par vous-même, à proposer votre propre solution en utilisant vos propres composants, de préférence en utilisant un programme en libre accès. Il ne reste plus qu'à décider ce que nous choisirons exactement pour cela et combien de temps nous consacrerons à résoudre ce problème, car les utilisateurs ne recevaient pas suffisamment de photos. Il faut donc faire tout cela très, très vite, pourrait-on dire hier.
Puisque la tâche ressemblait à "faire quelque chose le plus rapidement possible et en utilisant le matériel dont nous disposons", la première chose à laquelle nous avons pensé a été de simplement supprimer certaines machines peu puissantes de l'avant, d'y mettre Nginx, avec lequel nous savons comment travaillez et essayez d’implémenter la même logique que le matériel utilisé. Autrement dit, nous avons abandonné notre matériel, installé 4 serveurs supplémentaires que nous avons dû configurer, créé des domaines externes pour eux, comme c'était le cas il y a 10 ans... Nous avons perdu un peu en disponibilité si ces machines tombaient, mais encore moins, ils ont résolu le problème de nos utilisateurs localement.
En conséquence, la logique reste la même : nous installons Nginx, il peut effectuer un déchargement SSL, nous pouvons en quelque sorte programmer la logique de routage, des contrôles de santé dans les configurations et simplement dupliquer la logique que nous avions auparavant.
Asseyons-nous pour écrire des configurations. Au début, il semblait que tout était très simple, mais malheureusement, il est très difficile de trouver des manuels pour chaque tâche. Par conséquent, nous ne recommandons pas simplement de rechercher sur Google « comment configurer Nginx pour les photos » : il est préférable de se référer à la documentation officielle, qui indiquera quels paramètres doivent être touchés. Mais il est préférable de choisir vous-même le paramètre spécifique. Eh bien, tout est simple : nous décrivons les serveurs dont nous disposons, nous décrivons les certificats... Mais le plus intéressant est en fait la logique de routage elle-même.
Au début, il nous a semblé que nous décrivions simplement notre emplacement, en faisant correspondre le numéro de notre cache de photos, en utilisant nos mains ou un générateur pour décrire le nombre d'amont dont nous avons besoin, dans chaque amont, nous indiquons le serveur vers lequel le trafic doit être envoyé. go, et un serveur de sauvegarde - si le serveur principal n'est pas disponible :

Mais probablement, si tout était si simple, nous rentrerions simplement chez nous sans rien dire. Malheureusement, avec les paramètres par défaut de Nginx, qui, en général, ont été définis au cours de nombreuses années de développement et ne sont pas entièrement adaptés à ce cas... la configuration ressemble à ceci : si un serveur en amont a une erreur de requête ou un timeout, Nginx toujours fait passer le trafic au suivant. De plus, après le premier échec, dans les 10 secondes, le serveur sera également éteint, à la fois par erreur et par timeout - cela ne peut même pas être configuré de quelque manière que ce soit. Autrement dit, si nous supprimons ou réinitialisons l'option timeout dans la directive en amont, même si Nginx ne traitera pas cette demande et répondra avec une erreur pas très bonne, le serveur s'arrêtera.

Pour éviter cela, nous avons fait deux choses :
a) ils ont interdit à Nginx de le faire manuellement - et malheureusement, la seule façon de le faire est de simplement définir les paramètres d'échec maximum.
b) nous nous sommes souvenus que dans d'autres projets, nous utilisons un module qui nous permet d'effectuer des contrôles de santé en arrière-plan - en conséquence, nous avons effectué des contrôles de santé assez fréquents afin que les temps d'arrêt en cas d'accident soient minimes.
Malheureusement, ce n'est pas tout non plus, car littéralement les deux premières semaines de fonctionnement de ce schéma ont montré que le contrôle de santé TCP n'est pas non plus une chose fiable : sur le serveur en amont, il se peut qu'il ne s'agisse pas de Nginx, ni de Nginx à l'état D, mais dans dans ce cas, le noyau acceptera la connexion, le contrôle de santé réussira, mais ne fonctionnera pas. Par conséquent, nous l'avons immédiatement remplacé par un contrôle de santé http, en avons créé un spécifique qui, s'il renvoie 200, alors tout fonctionne dans ce script. Vous pouvez effectuer une logique supplémentaire - par exemple, dans le cas de serveurs de mise en cache, vérifiez que le système de fichiers est correctement monté :

Et cela nous conviendrait, sauf qu'à ce moment-là, le circuit répétait complètement ce que faisait le matériel. Mais nous voulions faire mieux. Auparavant, nous avions un serveur de sauvegarde, et ce n'est probablement pas très bon, car si vous avez une centaine de serveurs, alors lorsque plusieurs tombent en panne en même temps, il est peu probable qu'un serveur de sauvegarde puisse faire face à la charge. Nous avons donc décidé de répartir la réservation sur tous les serveurs : nous en avons simplement fait une autre séparée en amont, y avons écrit tous les serveurs avec certains paramètres en fonction de la charge qu'ils peuvent servir, ajouté les mêmes contrôles de santé que nous avions auparavant :

Puisqu'il est impossible d'aller vers un autre amont au sein d'un amont, il fallait s'assurer que si l'amont principal, dans lequel nous avons simplement enregistré le cache photo correct et nécessaire, n'était pas disponible, nous passions simplement par la page_erreur pour revenir, de où nous sommes allés à la sauvegarde en amont :

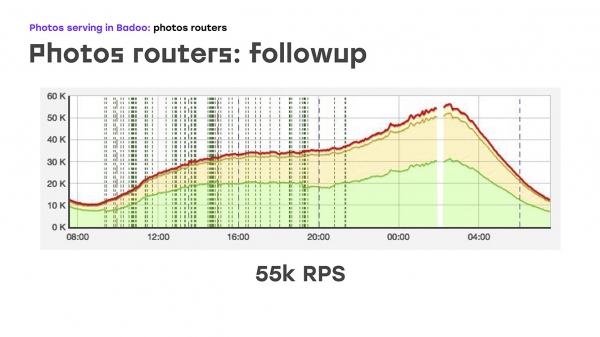
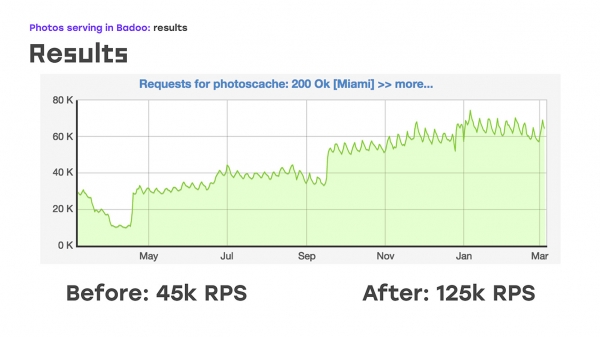
Et en ajoutant littéralement quatre serveurs, voici ce que nous avons obtenu : nous avons remplacé une partie de la charge - nous l'avons supprimée du LTM vers ces serveurs, y avons implémenté la même logique, en utilisant du matériel et des logiciels standard, et avons immédiatement reçu le bonus que ces serveurs peuvent être mis à l'échelle, car ils peuvent simplement être fournis autant que nécessaire. Eh bien, le seul point négatif est que nous avons perdu la haute disponibilité pour les utilisateurs externes. Mais à ce moment-là, nous avons dû sacrifier cela, car il fallait résoudre le problème immédiatement. Nous avons donc supprimé une partie de la charge, elle était d'environ 40 % à ce moment-là, LTM se sentait bien, et littéralement deux semaines après le début du problème, nous avons commencé à envoyer non pas 45 55 requêtes par seconde, mais 20 XNUMX. En fait, nous avons augmenté de XNUMX % - c'est clairement le trafic que nous n'avons pas donné à l'utilisateur. Et après cela, ils ont commencé à réfléchir à la manière de résoudre le problème restant : garantir une grande accessibilité externe.
Nous avons fait une pause pendant laquelle nous avons discuté de la solution que nous utiliserions pour cela. Il y a eu des propositions pour assurer la fiabilité en utilisant DNS, en utilisant des scripts maison, des protocoles de routage dynamique... il y avait de nombreuses options, mais il est déjà devenu clair que pour une livraison vraiment fiable des photos, vous devez introduire une autre couche qui surveillera cela. . Nous appelions ces machines des directeurs photo. Le logiciel sur lequel nous nous sommes appuyés était Keepalived :

Pour commencer, en quoi consiste Keepalived ? Le premier est le protocole VRRP, largement connu des réseauteurs, situé sur les équipements réseau qui offre une tolérance aux pannes sur l'adresse IP externe à laquelle les clients se connectent. La deuxième partie est l'IPVS, serveur virtuel IP, permettant d'équilibrer les routeurs photo et d'assurer la tolérance aux pannes à ce niveau. Et troisièmement, les contrôles de santé.
Commençons par la première partie : VRRP – à quoi ça ressemble ? Il existe une certaine adresse IP virtuelle, qui a une entrée dans le DNS badoocdn.com, où les clients se connectent. À un moment donné, nous avons une adresse IP sur un serveur. Les paquets Keepalived s'exécutent entre les serveurs à l'aide du protocole VRRP, et si le maître disparaît du radar - le serveur a redémarré ou autre chose, alors le serveur de sauvegarde récupère automatiquement cette adresse IP - aucune action manuelle n'est requise. La différence entre maître et sauvegarde est principalement la priorité : plus elle est élevée, plus grandes sont les chances que la machine devienne maître. Un très gros avantage est que vous n'avez pas besoin de configurer les adresses IP sur le serveur lui-même, il suffit de les décrire dans la configuration, et si les adresses IP nécessitent des règles de routage personnalisées, cela est décrit directement dans la configuration, en utilisant le même syntaxe que celle décrite dans le package VRRP. Vous ne rencontrerez aucune chose inconnue.
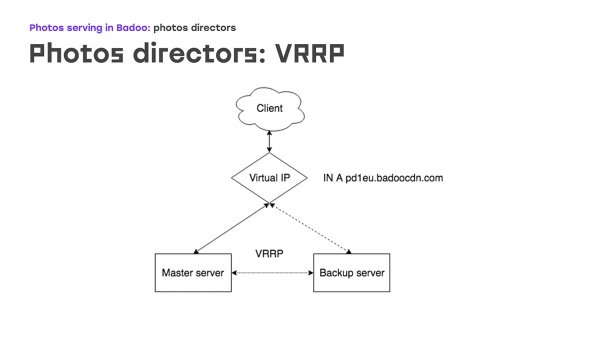
A quoi cela ressemble-t-il en pratique ? Que se passe-t-il si l'un des serveurs tombe en panne ? Dès que le maître disparaît, notre sauvegarde cesse de recevoir des publicités et devient automatiquement maître. Après un certain temps, nous avons réparé le maître, redémarré, activé Keepalived - les publicités arrivent avec une priorité plus élevée que la sauvegarde, et la sauvegarde revient automatiquement, supprime les adresses IP, aucune action manuelle n'est nécessaire.

Ainsi, nous avons assuré la tolérance aux pannes de l’adresse IP externe. La partie suivante consiste à équilibrer d'une manière ou d'une autre le trafic de l'adresse IP externe vers les routeurs photo qui y terminent déjà. Tout est assez clair avec les protocoles d'équilibrage. Il s'agit soit d'un simple tour de rôle, soit de choses légèrement plus complexes, par exemple, de connexion de liste, etc. Ceci est essentiellement décrit dans la documentation, il n'y a rien de spécial. Mais le mode de livraison... Nous allons voir ici de plus près pourquoi nous en avons choisi un. Il s'agit de NAT, de routage direct et de TUN. Le fait est que nous avions immédiatement prévu de délivrer 100 gigabits de trafic depuis les sites. Si vous estimez, vous avez besoin de 10 cartes Gigabit, n'est-ce pas ? 10 cartes Gigabit dans un serveur dépassent déjà le cadre, du moins, de notre concept d'« équipement standard ». Et puis nous nous sommes rappelés que nous ne donnions pas seulement du trafic, nous donnions des photos.
Qu'est-ce qui est spécial ? — Énorme différence entre le trafic entrant et sortant. Le trafic entrant est très faible, le trafic sortant est très important :
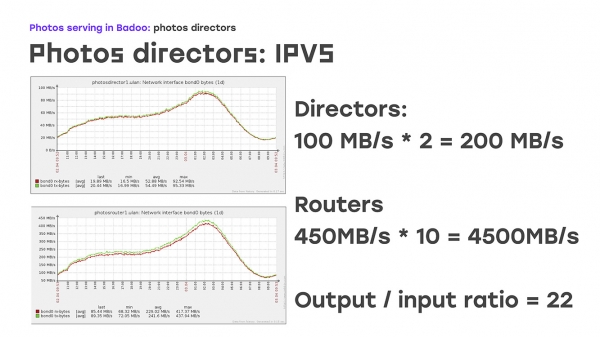
Si vous regardez ces graphiques, vous remarquerez qu'au moment où le réalisateur reçoit environ 200 Mo par seconde, c'est une journée très ordinaire. Nous restituons 4,500 1 Mo par seconde, notre ratio est d'environ 22/22. Il est déjà clair que pour fournir pleinement le trafic sortant à XNUMX serveurs de travail, nous n'en avons besoin que d'un seul qui accepte cette connexion. C’est là que l’algorithme de routage direct nous vient en aide.
À quoi cela ressemble-t-il? Notre directeur photo, selon son tableau, transmet les connexions aux routeurs photo. Mais les routeurs photo envoient le trafic retour directement sur Internet, l'envoient au client, il ne passe pas par le directeur photo, ainsi, avec un nombre minimum de machines, nous assurons une tolérance totale aux pannes et le pompage de tout le trafic. Dans les configurations, cela ressemble à ceci : nous spécifions l'algorithme, dans notre cas c'est un simple rr, fournissons la méthode de routage direct puis commençons à lister tous les vrais serveurs, combien nous en avons. Ce qui déterminera ce trafic. Si nous y avons un ou deux serveurs supplémentaires, ou plusieurs serveurs, un tel besoin se fait sentir - nous ajoutons simplement cette section à la configuration et ne nous inquiétez pas trop. Du côté des serveurs réels, du côté du routeur photo, cette méthode nécessite la configuration la plus minimale, elle est parfaitement décrite dans la documentation, et il n'y a là aucun piège.
Ce qui est particulièrement intéressant, c'est qu'une telle solution n'implique pas une refonte radicale du réseau local ; c'était important pour nous ; nous devions résoudre ce problème avec des coûts minimes. Si tu regardes , nous verrons ensuite à quoi cela ressemble. Ici, nous avons un certain serveur virtuel, sur le port 443, écoute, accepte la connexion, tous les serveurs fonctionnels sont répertoriés et vous pouvez voir que la connexion est, à peu près, la même. Si nous regardons les statistiques sur le même serveur virtuel, nous avons des paquets entrants, des connexions entrantes, mais absolument aucune connexion sortante. Les connexions sortantes vont directement au client. D'accord, nous avons réussi à le déséquilibrer. Maintenant, que se passe-t-il si l'un de nos routeurs photo tombe en panne ? Après tout, le fer reste du fer. Le noyau peut paniquer, il peut se briser, l'alimentation électrique peut griller. Rien. C'est pourquoi des contrôles de santé sont nécessaires. Ils peuvent être aussi simples que vérifier comment le port est ouvert, ou quelque chose de plus complexe, jusqu'à certains scripts écrits à la maison qui vérifieront même la logique métier.
On s'est arrêté quelque part au milieu : on a une requête https vers un emplacement précis, le script est appelé, s'il répond par une 200ème réponse, on pense que tout va bien avec ce serveur, qu'il est vivant et peut être tout à fait allumé facilement.
Encore une fois, à quoi cela ressemble-t-il dans la pratique ? Éteignons le serveur pour maintenance - en flashant le BIOS, par exemple. Dans les logs, on a immédiatement un timeout, on voit la première ligne, puis après trois tentatives elle est marquée comme « échoué », et elle est simplement supprimée de la liste.

Une deuxième option de comportement est également possible, lorsque VS est simplement mis à zéro, mais si la photo est renvoyée, cela ne fonctionne pas bien. Le serveur apparaît, Nginx démarre là, le bilan de santé comprend immédiatement que la connexion fonctionne, que tout va bien, et le serveur apparaît dans notre liste, et la charge commence immédiatement à lui être appliquée. Aucune action manuelle n'est requise de la part de l'administrateur de service. Le serveur a redémarré la nuit - le service de surveillance ne nous appelle pas la nuit. Ils vous informent que cela s'est produit, tout va bien.
Ainsi, d'une manière assez simple, avec l'aide d'un petit nombre de serveurs, nous avons résolu le problème de la tolérance aux pannes externes.
Il ne reste plus qu'à dire que tout cela doit bien entendu être surveillé. Par ailleurs, il convient de noter que Keepalivede, en tant que logiciel écrit il y a longtemps, dispose de plusieurs moyens de le surveiller, tous deux en utilisant des contrôles via DBus, SMTP, SNMP et Zabbix standard. De plus, il sait lui-même écrire des lettres pour presque tous les éternuements, et pour être honnête, à un moment donné, nous avons même pensé à l'éteindre, car il écrit beaucoup de lettres pour tout changement de trafic, activation, pour chaque connexion IP, et ainsi de suite . Bien sûr, s'il y a beaucoup de serveurs, vous pouvez alors vous submerger de ces lettres. Nous surveillons nginx sur les routeurs photo à l'aide de méthodes standard, et la surveillance matérielle n'a pas disparu. Nous conseillerions bien sûr deux autres choses : premièrement, des contrôles de santé externes et la disponibilité, car même si tout fonctionne, en fait, les utilisateurs ne reçoivent peut-être pas de photos à cause de problèmes avec des fournisseurs externes ou de quelque chose de plus complexe. Cela vaut toujours la peine de conserver quelque part sur un autre réseau, sur Amazon ou ailleurs, une machine distincte qui peut pinger vos serveurs de l'extérieur, et cela vaut également la peine d'utiliser soit la détection d'anomalies, pour ceux qui savent faire du machine learning délicat, soit un simple contrôle, au moins pour savoir si les demandes ont fortement diminué, ou au contraire augmenté. Cela peut aussi être utile.
Résumons : nous avons en fait remplacé la solution à toute épreuve, qui à un moment donné a cessé de nous convenir, par un système assez simple qui fait tout de même, c'est-à-dire qu'il assure la terminaison du trafic HTTPS et un routage intelligent supplémentaire avec le contrôles de santé nécessaires. Nous avons augmenté la stabilité de ce système, c'est-à-dire que nous avons toujours une haute disponibilité pour chaque couche, et nous avons en plus l'avantage qu'il est assez facile de tout faire évoluer sur chaque couche, car il s'agit d'un matériel standard avec un logiciel standard, c'est-à-dire , nous avons simplifié le diagnostic des problèmes possibles.
Avec quoi avons-nous fini? Nous avons eu un problème pendant les vacances de janvier 2018. Au cours des six premiers mois de mise en œuvre de ce système, nous l'avons étendu à tout le trafic afin de supprimer tout le trafic du LTM, nous avons augmenté uniquement le trafic dans un centre de données de 40 gigabits à 60 gigabits, et en même temps pour pendant toute l’année 2018, nous avons pu envoyer près de trois fois plus de photos par seconde.
Source: habr.com
