

Salut Habr ! L'inscription à un nouveau volet de cours est ouverte dès maintenant chez OTUS. . En prévision du début du cours, nous avons traditionnellement préparé pour vous une traduction du matériel intéressant.
Chaque jour, plus de cent millions de personnes visitent Twitter pour découvrir ce qui se passe dans le monde et en discuter. Chaque tweet et toute autre action de l'utilisateur génère un événement disponible pour l'analyse des données internes au sein de Twitter. Des centaines d'employés analysent et visualisent ces données, et l'amélioration de leur expérience est une priorité absolue pour l'équipe Twitter Data Platform.
Nous pensons que les utilisateurs possédant un large éventail de compétences techniques devraient être capables de trouver des données et d'avoir accès à des outils d'analyse et de visualisation basés sur SQL qui fonctionnent bien. Cela permettrait à un tout nouveau groupe d'utilisateurs moins techniques, notamment des analystes de données et des chefs de produits, d'extraire des informations à partir des données, leur permettant ainsi de mieux comprendre et utiliser la puissance de Twitter. C’est ainsi que nous démocratisons l’analyse des données sur Twitter.
À mesure que nos outils et nos capacités d'analyse des données internes se sont améliorés, nous avons constaté une amélioration du service Twitter. Cependant, des améliorations sont encore possibles. Les outils actuels comme Scalding nécessitent une expérience en programmation. Les outils d'analyse basés sur SQL tels que Presto et Vertica présentent des problèmes de performances à grande échelle. Nous avons également un problème avec la distribution des données sur plusieurs systèmes sans accès constant à celles-ci.
L'année dernière, nous avons annoncé , au sein duquel nous transférons une partie de notre sur la plateforme Google Cloud (GCP). Nous avons conclu que les outils Google Cloud peuvent nous aider dans nos initiatives visant à démocratiser l'analyse, la visualisation et l'apprentissage automatique sur Twitter :
- : entrepôt de données d'entreprise avec moteur SQL basé , réputé pour sa rapidité, sa simplicité et qui fait face à .
- outil de visualisation Big Data avec des fonctionnalités de collaboration comme Google Docs.
Dans cet article, vous découvrirez notre expérience avec ces outils : ce que nous avons fait, ce que nous avons appris et ce que nous ferons ensuite. Nous allons maintenant nous concentrer sur les analyses par lots et interactives. L'analyse en temps réel sera abordée dans le prochain article.
L'histoire des entrepôts de données sur Twitter
Avant de plonger dans BigQuery, il convient de raconter brièvement l'histoire des entrepôts de données sur Twitter. En 2011, l'analyse des données sur Twitter a été réalisée dans Vertica et Hadoop. Pour créer des tâches MapReduce Hadoop, nous avons utilisé Pig. En 2012, nous avons remplacé Pig par Scalding, qui disposait d'une API Scala offrant des avantages tels que la possibilité de créer des pipelines complexes et la facilité des tests. Cependant, pour de nombreux analystes de données et chefs de produits plus à l’aise avec SQL, la courbe d’apprentissage a été assez abrupte. Vers 2016, nous avons commencé à utiliser Presto comme interface SQL pour les données Hadoop. Spark propose une interface Python qui en fait un bon choix pour la science des données ad hoc et l'apprentissage automatique.
Depuis 2018, nous utilisons les outils suivants pour l'analyse et la visualisation des données :
- Ébouillantage pour les lignes de production
- Scalding et Spark pour l'analyse de données ad hoc et l'apprentissage automatique
- Vertica et Presto pour une analyse SQL ad hoc et interactive
- Druid pour un accès peu interactif, exploratoire et à faible latence aux métriques de séries chronologiques
- Tableau, Zeppelin et Pivot pour la visualisation des données
Nous avons constaté que même si ces outils offrent des fonctionnalités très puissantes, nous avons eu du mal à rendre ces fonctionnalités accessibles à un public plus large sur Twitter. En étendant notre plateforme avec Google Cloud, nous nous concentrons sur la simplification de nos outils d'analyse pour l'ensemble de Twitter.
L'entrepôt de données BigQuery de Google
Plusieurs équipes de Twitter ont déjà inclus BigQuery dans certains de leurs pipelines de production. Grâce à leur expérience, nous avons commencé à évaluer les possibilités de BigQuery pour tous les cas d'utilisation de Twitter. Notre objectif était de proposer BigQuery à l'ensemble de l'entreprise, ainsi que de le standardiser et de le prendre en charge au sein de la boîte à outils Data Platform. Cela a été difficile pour de nombreuses raisons. Nous devions développer une infrastructure capable de recevoir de manière fiable de grandes quantités de données, de prendre en charge la gestion des données à l'échelle de l'entreprise, de garantir des contrôles d'accès appropriés et de garantir la confidentialité des clients. Nous avons également dû créer des systèmes d'allocation, de surveillance et de rétrofacturation des ressources afin que les équipes puissent utiliser BigQuery efficacement.
En novembre 2018, nous avons publié une version alpha de BigQuery et Data Studio pour l'ensemble de l'entreprise. Nous avons proposé au personnel de Twitter certaines de nos feuilles de calcul d'effacement des données personnelles les plus utilisées. BigQuery a été utilisé par plus de 250 utilisateurs issus de diverses équipes, notamment d'ingénierie, de finance et de marketing. Plus récemment, ils traitaient environ 8 100 requêtes, traitant environ XNUMX Po par mois, sans compter les requêtes planifiées. Après avoir reçu des retours très positifs, nous avons décidé d'aller de l'avant et de proposer BigQuery comme principale ressource pour interagir avec les données sur Twitter.
Voici un schéma de l'architecture de haut niveau de notre entrepôt de données Google BigQuery.
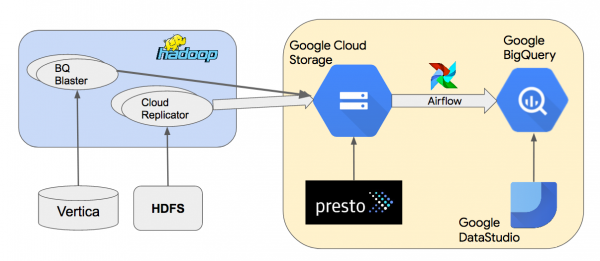
Nous copions les données des clusters Hadoop sur site vers Google Cloud Storage (GCS) à l'aide de l'outil interne Cloud Replicator. Nous utilisons ensuite Apache Airflow pour créer des pipelines qui utilisent "» pour charger les données de GCS dans BigQuery. Nous utilisons Presto pour interroger les ensembles de données Parquet ou Thrift-LZO dans GCS. BQ Blaster est un outil Scalding interne permettant de charger des ensembles de données HDFS Vertica et Thrift-LZO dans BigQuery.
Dans les sections suivantes, nous discuterons de notre approche et de notre expertise en matière de facilité d'utilisation, de performances, de gestion des données, de santé du système et de coût.
Facilité d'utilisation
Nous avons constaté qu'il était facile pour les utilisateurs de démarrer avec BigQuery, car il ne nécessitait pas d'installation de logiciel et les utilisateurs pouvaient y accéder via une interface Web intuitive. Cependant, les utilisateurs devaient se familiariser avec certaines fonctionnalités et concepts de GCP, notamment des ressources telles que des projets, des ensembles de données et des tables. Nous avons développé des tutoriels et des tutoriels pour aider les utilisateurs à démarrer. Une fois les connaissances de base acquises, il est facile pour les utilisateurs de parcourir les ensembles de données, d'afficher les données de schéma et de table, d'exécuter des requêtes simples et de visualiser les résultats dans Data Studio.
Notre objectif avec la saisie de données dans BigQuery était de permettre un chargement transparent des ensembles de données HDFS ou GCS en un seul clic. Nous avons considéré (géré par Airflow) mais nous n'avons pas pu l'utiliser en raison de notre modèle de sécurité « Partage restreint de domaine » (plus d'informations à ce sujet dans la section Gestion des données ci-dessous). Nous avons expérimenté l'utilisation du service de transfert de données Google (DTS) pour organiser les tâches de chargement BigQuery. Bien que DTS ait été rapide à mettre en place, il n’était pas flexible pour créer des pipelines avec des dépendances. Pour notre version alpha, nous avons créé notre propre environnement Apache Airflow dans GCE et le préparons pour la production et la possibilité de prendre en charge davantage de sources de données telles que Vertica.
Pour transformer des données dans BigQuery, les utilisateurs créent des pipelines de données SQL simples à l'aide de requêtes planifiées. Pour les pipelines complexes à plusieurs étapes avec des dépendances, nous prévoyons d'utiliser soit notre propre framework Airflow, soit Cloud Composer avec .
Performance
BigQuery est conçu pour les requêtes SQL à usage général qui traitent de grandes quantités de données. Il n'est pas destiné aux requêtes à faible latence et à haut débit requises par une base de données transactionnelle, ni à l'analyse de séries temporelles à faible latence mise en œuvre par . Pour les requêtes analytiques interactives, nos utilisateurs s’attendent à un temps de réponse inférieur à une minute. Nous avons dû concevoir l'utilisation de BigQuery pour répondre à ces attentes. Afin de fournir des performances prévisibles à nos utilisateurs, nous avons utilisé la fonctionnalité BigQuery, disponible pour les clients sur une base forfaitaire, qui permet aux propriétaires de projets de réserver un minimum d'emplacements pour leurs requêtes. BigQuery est une unité de puissance de calcul nécessaire pour exécuter des requêtes SQL.
Nous avons analysé plus de 800 requêtes traitant chacune environ 1 To de données et avons constaté que le temps d'exécution moyen était de 30 secondes. Nous avons également appris que les performances dépendent fortement de l'utilisation de notre emplacement dans divers projets et tâches. Nous avons dû clairement séparer nos réserves de slots de production et ad hoc afin de maintenir les performances pour les cas d'utilisation en production et l'analyse interactive. Cela a grandement influencé notre conception des réservations de créneaux horaires et des hiérarchies de projets.
Nous parlerons de la gestion des données, des fonctionnalités et du coût des systèmes dans les prochains jours dans la deuxième partie de la traduction, et maintenant nous invitons tout le monde à , où vous pourrez en savoir plus sur le cours et poser des questions à notre expert - Egor Mateshuk (Senior Data Engineer, MaximaTelecom).
Lire la suite:
Source: habr.com
