

Bonjour à tous, je m'appelle Alexander, je travaille au CIAN en tant qu'ingénieur et je suis impliqué dans l'administration système et l'automatisation des processus d'infrastructure. Dans les commentaires de l'un des articles précédents, on nous a demandé d'indiquer d'où nous obtenons 4 To de journaux par jour et ce que nous en faisons. Oui, nous avons beaucoup de journaux et un cluster d'infrastructure distinct a été créé pour les traiter, ce qui nous permet de résoudre rapidement les problèmes. Dans cet article, je parlerai de la façon dont nous l'avons adapté au cours d'une année pour travailler avec un flux de données toujours croissant.
Par où avons-nous commencé ?
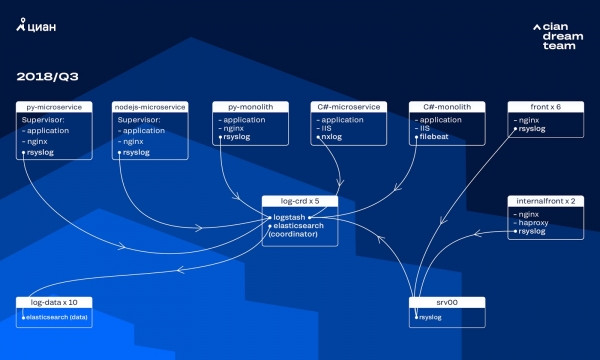
Au cours des dernières années, la charge sur cian.ru a augmenté très rapidement et au troisième trimestre 2018, le trafic des ressources a atteint 11.2 millions d'utilisateurs uniques par mois. À cette époque, aux moments critiques, nous perdions jusqu'à 40 % des journaux, c'est pourquoi nous ne pouvions pas traiter rapidement les incidents et consacrions beaucoup de temps et d'efforts à les résoudre. Souvent, nous ne parvenions pas non plus à trouver la cause du problème, qui réapparaissait après un certain temps. C'était l'enfer et il fallait faire quelque chose.
À cette époque, nous utilisions un cluster de 10 nœuds de données avec ElasticSearch version 5.5.2 avec des paramètres d'index standard pour stocker les journaux. Il a été introduit il y a plus d'un an comme une solution populaire et abordable : alors le flux de journaux n'était pas si important, il ne servait à rien de proposer des configurations non standard.
Le traitement des journaux entrants était assuré par Logstash sur différents ports de cinq coordinateurs ElasticSearch. Un index, quelle que soit sa taille, était composé de cinq fragments. Une rotation horaire et quotidienne a été organisée, de sorte qu'environ 100 nouveaux fragments sont apparus dans le cluster chaque heure. Même s’il n’y avait pas beaucoup de journaux, le cluster s’en sortait bien et personne ne prêtait attention à ses paramètres.
Les défis d’une croissance rapide
Le volume de journaux générés a augmenté très rapidement, car deux processus se chevauchaient. D’une part, le nombre d’utilisateurs du service a augmenté. D’un autre côté, nous avons commencé à passer activement à une architecture de microservices, en sciant nos anciens monolithes en C# et Python. Plusieurs dizaines de nouveaux microservices qui ont remplacé certaines parties du monolithe ont généré beaucoup plus de journaux pour le cluster d'infrastructure.
C’est la mise à l’échelle qui nous a conduit au point où le cluster est devenu pratiquement ingérable. Lorsque les journaux ont commencé à arriver à un rythme de 20 6 messages par seconde, une rotation inutile et fréquente a augmenté le nombre de fragments à 600 XNUMX, et il y avait plus de XNUMX fragments par nœud.
Cela a entraîné des problèmes d'allocation de RAM, et lorsqu'un nœud tombait en panne, tous les fragments migraient simultanément, augmentant le trafic et surchargeant les nœuds restants, rendant pratiquement impossible l'écriture de données sur le cluster. Pendant cette période, nous nous sommes retrouvés sans journaux. Et s'il y avait un problème avec serveur Nous perdions 1/10 du cluster au total. Le grand nombre de petits index contribuait à la complexité.
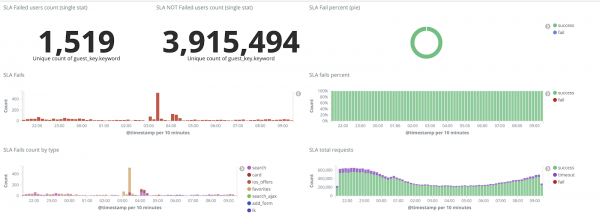
Sans journaux, nous ne comprenions pas les raisons de l'incident et pourrions tôt ou tard marcher à nouveau sur le même râteau, et dans l'idéologie de notre équipe, cela était inacceptable, car tous nos mécanismes de travail sont conçus pour faire exactement le contraire - ne jamais répéter les mêmes problèmes. Pour ce faire, nous avions besoin du volume total de journaux et de leur livraison presque en temps réel, puisqu'une équipe d'ingénieurs en service surveillait les alertes non seulement à partir des métriques, mais également des journaux. Pour comprendre l'ampleur du problème, à cette époque, le volume total de journaux était d'environ 2 To par jour.
Nous nous sommes fixés pour objectif d'éliminer complètement la perte de logs et de réduire le délai de leur livraison au cluster ELK à un maximum de 15 minutes en cas de force majeure (nous nous sommes ensuite appuyés sur ce chiffre comme KPI interne).
Nouveau mécanisme de rotation et nœuds chauds
Nous avons commencé la conversion du cluster en mettant à jour la version d'ElasticSearch de 5.5.2 à 6.4.3. Une fois de plus, notre cluster version 5 est mort et nous avons décidé de le désactiver et de le mettre à jour complètement - il n'y a toujours pas de journaux. Nous avons donc effectué cette transition en quelques heures seulement.
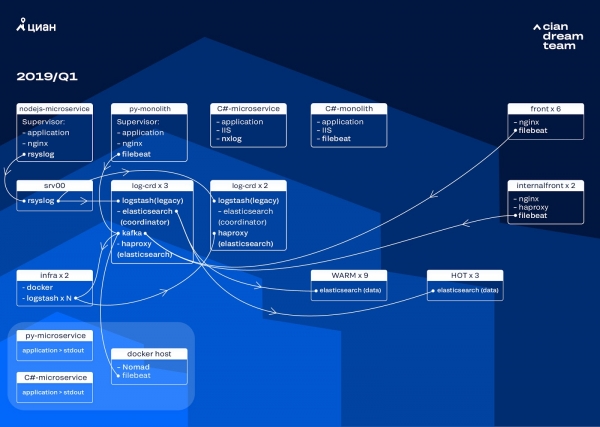
La transformation la plus importante à ce stade a été la mise en œuvre d'Apache Kafka sur trois nœuds avec un coordinateur comme tampon intermédiaire. Le courtier de messages nous a évité de perdre des journaux lors de problèmes avec ElasticSearch. Dans le même temps, nous avons ajouté 2 nœuds au cluster et basculé vers une architecture hot-warm avec trois nœuds « chauds » situés dans différents racks du centre de données. Nous leur avons redirigé les journaux à l'aide d'un masque qui ne doit en aucun cas être perdu - nginx, ainsi que les journaux d'erreurs des applications. Des journaux mineurs ont été envoyés aux nœuds restants - débogage, avertissement, etc., et après 24 heures, les journaux « importants » des nœuds « chauds » ont été transférés.
Afin de ne pas augmenter le nombre de petits index, nous sommes passés de la rotation temporelle au mécanisme de rollover. Il y avait beaucoup d'informations sur les forums selon lesquelles la rotation par taille d'index est très peu fiable, nous avons donc décidé d'utiliser la rotation par nombre de documents dans l'index. Nous avons analysé chaque index et enregistré le nombre de documents après lequel la rotation devrait fonctionner. Ainsi, nous avons atteint la taille de partition optimale - pas plus de 50 Go.
Optimisation des clusters
Cependant, nous n’avons pas complètement éliminé les problèmes. Malheureusement, de petits index sont toujours apparus : ils n'ont pas atteint le volume spécifié, n'ont pas subi de rotation et ont été supprimés par un nettoyage global des index de plus de trois jours, puisque nous avons supprimé la rotation par date. Cela a entraîné une perte de données en raison du fait que l'index du cluster a complètement disparu et qu'une tentative d'écriture dans un index inexistant a brisé la logique du conservateur que nous utilisions pour la gestion. L'alias d'écriture a été converti en index et a brisé la logique de roulement, provoquant une croissance incontrôlée de certains index jusqu'à 600 Go.
Par exemple, pour la configuration de rotation :
сurator-elk-rollover.yaml
---
actions:
1:
action: rollover
options:
name: "nginx_write"
conditions:
max_docs: 100000000
2:
action: rollover
options:
name: "python_error_write"
conditions:
max_docs: 10000000
S'il n'y avait pas d'alias de survol, une erreur se produisait :
ERROR alias "nginx_write" not found.
ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
Nous avons laissé la solution à ce problème pour l'itération suivante et avons abordé un autre problème : nous sommes passés à la logique pull de Logstash, qui traite les journaux entrants (suppression des informations inutiles et enrichissement). Nous l'avons placé dans Docker, que nous lançons via docker-compose, et nous y avons également placé logstash-exporter, qui envoie des métriques à Prometheus pour la surveillance opérationnelle du flux de journaux. De cette façon, nous nous sommes donné la possibilité de modifier en douceur le nombre d'instances logstash responsables du traitement de chaque type de journal.
Pendant que nous améliorions le cluster, le trafic de cian.ru a augmenté pour atteindre 12,8 millions d'utilisateurs uniques par mois. En conséquence, il s'est avéré que nos transformations étaient un peu en retard par rapport aux changements de production, et nous avons été confrontés au fait que les nœuds « chauds » ne pouvaient pas supporter la charge et ralentissaient toute la livraison des grumes. Nous avons reçu des données « chaudes » sans échec, mais nous avons dû intervenir dans la livraison du reste et effectuer un rollover manuel afin de répartir uniformément les index.
Dans le même temps, la mise à l'échelle et la modification des paramètres des instances logstash dans le cluster étaient compliquées par le fait qu'il s'agissait d'un docker-compose local et que toutes les actions étaient effectuées manuellement (pour ajouter de nouvelles fins, il était nécessaire de parcourir manuellement toutes les serveurs et faites docker-compose up -d partout).
Redistribution des journaux
En septembre de cette année, nous étions encore en train de découper le monolithe, la charge sur le cluster augmentait et le flux de journaux approchait les 30 XNUMX messages par seconde.
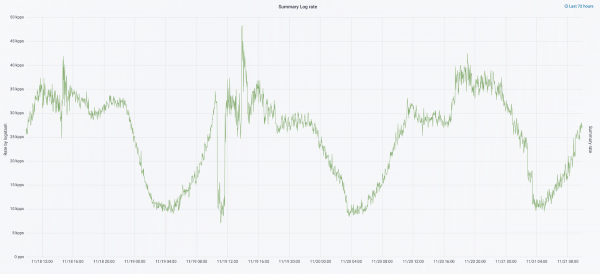
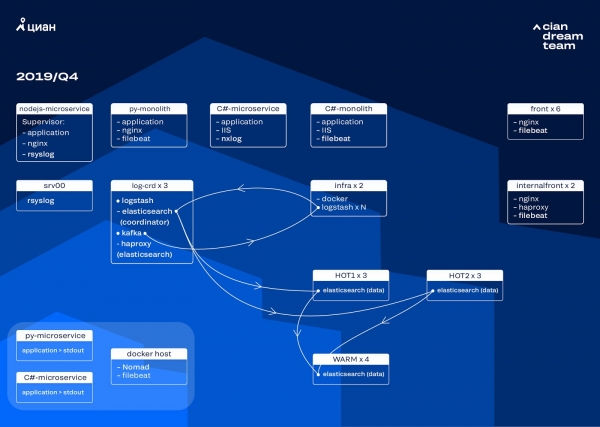
Nous avons commencé la prochaine itération avec une mise à jour matérielle. Nous sommes passés de cinq coordinateurs à trois, avons remplacé les nœuds de données et avons gagné en termes d'argent et d'espace de stockage. Pour les nœuds, nous utilisons deux configurations :
- Pour les nœuds « chauds » : E3-1270 v6 / 960 Go SSD / 32 Go x 3 x 2 (3 pour Hot1 et 3 pour Hot2).
- Pour les nœuds « chauds » : E3-1230 v6 / 4 To SSD / 32 Go x 4.
Lors de cette itération, nous avons déplacé l'index avec les journaux d'accès aux microservices, qui occupe le même espace que les journaux nginx de première ligne, vers le deuxième groupe de trois nœuds « chauds ». Nous stockons désormais les données sur des nœuds « chauds » pendant 20 heures, puis les transférons vers des nœuds « chauds » vers le reste des journaux.
Nous avons résolu le problème de la disparition des petits index en reconfigurant leur rotation. Désormais, les index changent toutes les 23 heures, même s'il y a peu de données. Cela a légèrement augmenté le nombre de fragments (il y en avait environ 800), mais du point de vue des performances du cluster, c'est tolérable.
En conséquence, il y avait six nœuds « chauds » et seulement quatre nœuds « chauds » dans le cluster. Cela entraîne un léger retard dans les requêtes sur de longs intervalles de temps, mais l'augmentation du nombre de nœuds à l'avenir résoudra ce problème.
Cette itération a également résolu le problème du manque de mise à l'échelle semi-automatique. Pour ce faire, nous avons déployé un cluster d'infrastructure Nomad - similaire à ce que nous avons déjà déployé en production. Pour l'instant, la quantité de Logstash ne change pas automatiquement en fonction de la charge, mais nous y reviendrons.
Plans pour l'avenir
La configuration mise en œuvre est parfaitement évolutive et nous stockons désormais 13,3 To de données - tous les journaux pendant 4 jours, ce qui est nécessaire pour l'analyse d'urgence des alertes. Nous convertissons certains journaux en métriques, que nous ajoutons à Graphite. Pour faciliter le travail des ingénieurs, nous disposons de métriques pour le cluster d'infrastructure et de scripts pour la réparation semi-automatique des problèmes courants. Après avoir augmenté le nombre de nœuds de données, prévu pour l'année prochaine, nous passerons au stockage des données de 4 à 7 jours. Cela suffira pour le travail opérationnel, car nous essayons toujours d'enquêter sur les incidents le plus rapidement possible, et pour les enquêtes à long terme, nous disposons de données télémétriques.
En octobre 2019, le trafic vers cian.ru atteignait déjà 15,3 millions d'utilisateurs uniques par mois. Cela est devenu un test sérieux de la solution architecturale pour la livraison des journaux.
Nous nous préparons maintenant à mettre à jour ElasticSearch vers la version 7. Cependant, pour cela, nous devrons mettre à jour le mappage de nombreux index dans ElasticSearch, car ils sont passés de la version 5.5 et ont été déclarés obsolètes dans la version 6 (ils n'existent tout simplement pas dans la version 7). Cela signifie que pendant le processus de mise à jour, il y aura certainement une sorte de force majeure, qui nous laissera sans journaux jusqu'à ce que le problème soit résolu. De la version 7, nous attendons avec impatience Kibana avec une interface améliorée et de nouveaux filtres.
Nous avons atteint notre objectif principal : nous avons arrêté de perdre des journaux et réduit les temps d'arrêt du cluster d'infrastructure de 2 à 3 pannes par semaine à quelques heures de travail de maintenance par mois. Tout ce travail de production est presque invisible. Cependant, maintenant que nous pouvons déterminer exactement ce qui se passe avec notre service, nous pouvons le faire rapidement en mode silencieux et ne pas craindre que les journaux soient perdus. En général, nous sommes satisfaits, heureux et nous préparons à de nouveaux exploits, dont nous parlerons plus tard.
Source: habr.com
