


Cet article contient quelques modèles courants pour aider les ingénieurs à travailler avec des services à grande échelle accessibles par des millions d'utilisateurs.
D'après l'expérience de l'auteur, il ne s'agit pas d'une liste exhaustive, mais effectivement efficace des conseils. Alors, commençons.
Traduit avec support .
Niveau d'entrée
Les mesures énumérées ci-dessous sont relativement simples à mettre en œuvre mais ont un impact élevé. Si vous ne les avez jamais essayés auparavant, vous serez surpris des améliorations significatives.
Infrastructure en tant que code
La première partie du conseil consiste à implémenter l'infrastructure en tant que code. Cela signifie que vous devez disposer d'un moyen programmatique pour déployer l'intégralité de l'infrastructure. Cela semble compliqué, mais nous parlons en réalité du code suivant :
Déploiement de 100 machines virtuelles
- с Ubuntu
- 2 Go de RAM chacun
- ils auront le code suivant
- avec ces paramètres
Vous pouvez suivre les modifications apportées à votre infrastructure et y revenir rapidement à l'aide du contrôle de version.
Le moderniste en moi dit que vous pouvez utiliser Kubernetes/Docker pour faire tout ce qui précède, et il a raison.
De plus, vous pouvez fournir une automatisation à l'aide de Chef, Puppet ou Terraform.
Intégration et livraison continues
Pour créer un service évolutif, il est important de disposer d'un pipeline de construction et de test pour chaque demande d'extraction. Même si le test est très simple, il garantira au moins que le code que vous déployez est compilé.
A chaque fois à ce stade vous répondez à la question : mon assemblage va-t-il compiler et réussir les tests, est-ce valide ? Cela peut sembler une barre basse, mais cela résout de nombreux problèmes.
Il n'y a rien de plus beau que de voir ces tiques
Pour cette technologie, vous pouvez évaluer Github, CircleCI ou Jenkins.
Équilibreurs de charge
Nous souhaitons donc exécuter un équilibreur de charge pour rediriger le trafic et garantir une charge égale sur tous les nœuds, sinon le service continue en cas de panne :
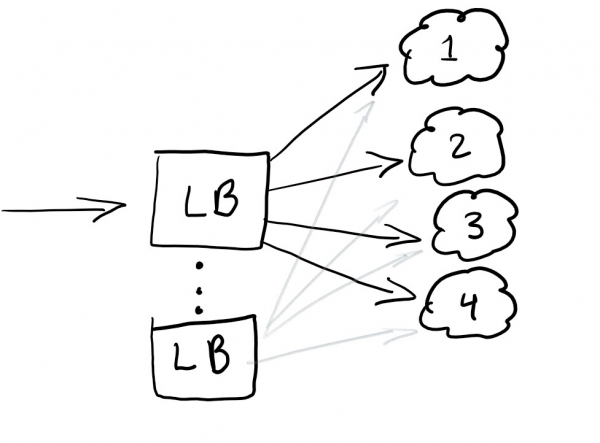
Un équilibreur de charge fait généralement un bon travail de répartition du trafic. La meilleure pratique consiste à suréquilibrer afin de ne pas avoir un seul point de défaillance.
En règle générale, les équilibreurs de charge sont configurés dans le cloud que vous utilisez.
RayID, ID de corrélation ou UUID pour les requêtes
Avez-vous déjà rencontré une erreur d'application avec un message comme celui-ci : " Quelque chose s'est mal passé. Enregistrez cet identifiant et envoyez-le à notre équipe d'assistance"?
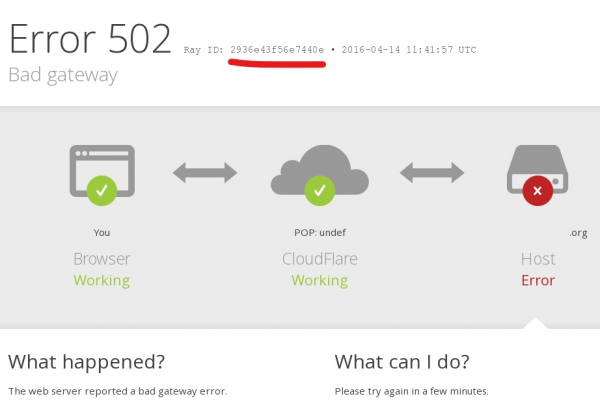
Un identifiant unique, un ID de corrélation, un RayID ou l'une des variantes est un identifiant unique qui vous permet de suivre une demande tout au long de son cycle de vie. Cela vous permet de suivre l'intégralité du chemin de la demande dans les journaux.
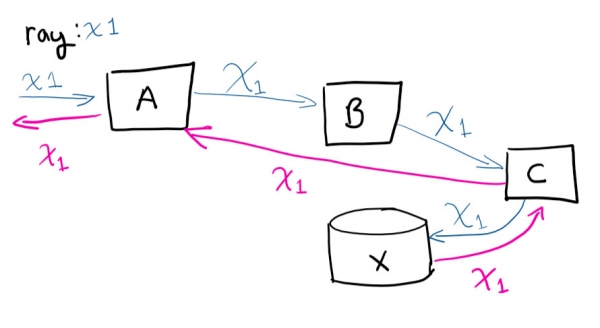
L'utilisateur fait une demande au système A, puis A contacte B, qui contacte C, la stocke dans X, puis la demande est renvoyée à A.
Si vous deviez vous connecter à distance à des machines virtuelles et essayer de retracer le chemin de la requête (et de corréler manuellement les appels effectués), vous deviendrez fou. Avoir un identifiant unique rend la vie beaucoup plus facile. C’est l’une des choses les plus simples que vous puissiez faire pour gagner du temps à mesure que votre service se développe.
Niveau moyen
Les conseils ici sont plus complexes que les précédents, mais les bons outils facilitent la tâche, offrant un retour sur investissement même pour les petites et moyennes entreprises.
Journalisation centralisée
Toutes nos félicitations! Vous avez déployé 100 machines virtuelles. Le lendemain, le PDG vient se plaindre d'une erreur qu'il a reçue lors du test du service. Il indique l'ID correspondant dont nous avons parlé ci-dessus, mais vous devrez parcourir les journaux de 100 machines pour trouver celle qui a provoqué le crash. Et il faut le trouver avant la présentation de demain.
Même si cela semble être une aventure amusante, il est préférable de vous assurer que vous avez la possibilité de rechercher tous les magazines au même endroit. J'ai résolu le problème de la centralisation des journaux en utilisant la fonctionnalité intégrée de la pile ELK : elle prend en charge la collecte de journaux consultable. Cela aidera vraiment à résoudre le problème de la recherche d’une revue spécifique. En prime, vous pouvez créer des graphiques et d’autres choses amusantes comme ça.
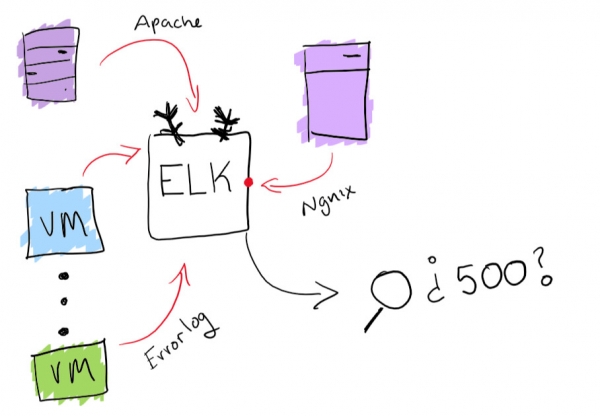
Fonctionnalité de la pile ELK
Agents de surveillance
Maintenant que votre service est opérationnel, vous devez vous assurer qu’il fonctionne correctement. La meilleure façon d'y parvenir est d'exécuter plusieurs agents, qui fonctionnent en parallèle et vérifient qu'ils fonctionnent et que les opérations de base sont effectuées.
A ce stade, vous vérifiez que la version en cours se sent bien et fonctionne bien.
Pour les projets de petite et moyenne taille, je recommande Postman pour surveiller et documenter les API. Mais en général, vous voulez simplement vous assurer que vous disposez d’un moyen de savoir quand une panne s’est produite et d’être averti en temps opportun.
Mise à l'échelle automatique en fonction de la charge
C'est très simple. Si vous avez des demandes de maintenance de VM et que son utilisation de la mémoire approche les 80 %, vous pouvez soit augmenter ses ressources, soit ajouter plus de VM au cluster. L'exécution automatique de ces opérations est excellente pour les changements de puissance élastiques sous charge. Mais vous devez toujours faire attention au montant que vous dépensez et fixer des limites raisonnables.
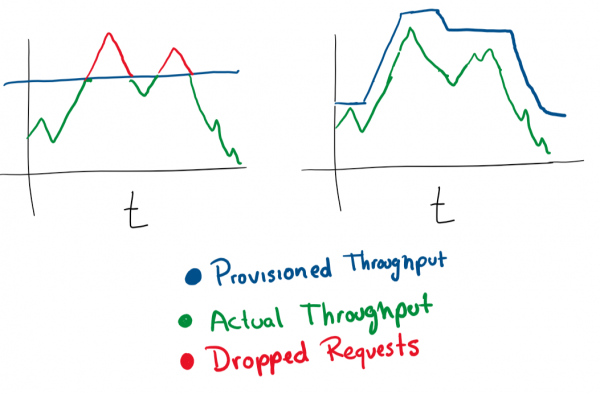
Avec la plupart des services cloud, vous pouvez le configurer pour une mise à l'échelle automatique en utilisant davantage de serveurs ou des serveurs plus puissants.
Système d'expérimentation
Un bon moyen de déployer les mises à jour en toute sécurité est de pouvoir tester quelque chose pour 1 % des utilisateurs pendant une heure. Vous avez bien sûr vu de tels mécanismes en action. Par exemple, Facebook affiche une couleur différente à certaines parties de l’audience ou modifie la taille de la police pour voir comment les utilisateurs perçoivent les changements. C’est ce qu’on appelle les tests A/B.
Même la publication d'une nouvelle fonctionnalité peut être lancée à titre expérimental, puis déterminer comment la publier. Vous avez également la possibilité de « mémoriser » ou de modifier la configuration à la volée en fonction de la fonction qui provoque la dégradation de votre service.
Niveau avancé
Voici des astuces assez difficiles à mettre en œuvre. Vous aurez probablement besoin d’un peu plus de ressources, donc une petite ou moyenne entreprise aura du mal à gérer cela.
Déploiements bleu-vert
C’est ce que j’appelle la manière « Erlang » de se déployer. Erlang est devenu largement utilisé avec l’apparition des compagnies de téléphone. Les softswitches ont commencé à être utilisés pour acheminer les appels téléphoniques. L'objectif principal du logiciel sur ces commutateurs était de ne pas interrompre les appels lors des mises à niveau du système. Erlang a une bonne façon de charger un nouveau module sans planter le précédent.
Cette étape dépend de la présence d'un équilibreur de charge. Imaginons que vous disposez de la version N de votre logiciel, et que vous souhaitiez ensuite déployer la version N+1.
Vous pourrait arrêtez simplement le service et déployez la version suivante à un moment qui convient à vos utilisateurs et obtenez un certain temps d'arrêt. Mais supposons que vous ayez vraiment conditions strictes de SLA. Ainsi, SLA 99,99 % signifie que vous pouvez vous déconnecter seulement de 52 minutes par an.
Si vous souhaitez vraiment atteindre de tels indicateurs, vous avez besoin de deux déploiements en même temps :
- celui qui est en ce moment (N) ;
- version suivante (N+1).
Vous dites à l'équilibreur de charge de rediriger un pourcentage du trafic vers la nouvelle version (N+1) pendant que vous surveillez activement les régressions.
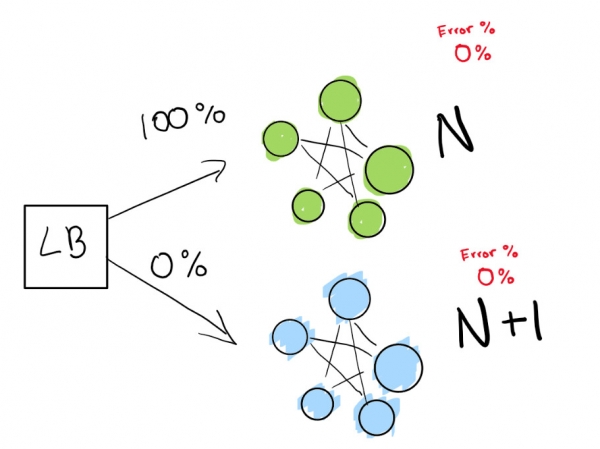
Ici, nous avons un déploiement N vert qui fonctionne bien. Nous essayons de passer à la prochaine version de ce déploiement
Nous envoyons d’abord un très petit test pour voir si notre déploiement N+1 fonctionne avec une petite quantité de trafic :
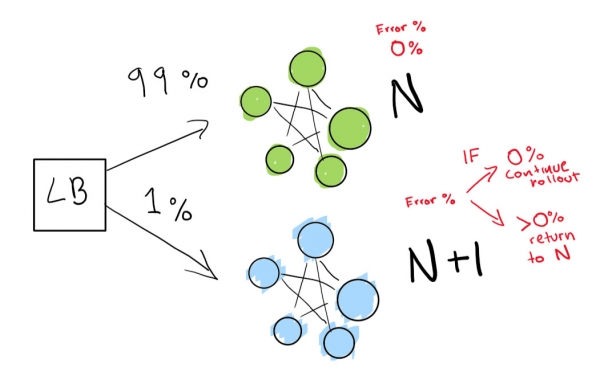
Enfin, nous disposons d'un ensemble de contrôles automatisés que nous exécutons éventuellement jusqu'à ce que notre déploiement soit terminé. Si tu très très attention, vous pouvez également sauvegarder votre déploiement N pour toujours pour un rollback rapide en cas de mauvaise régression :
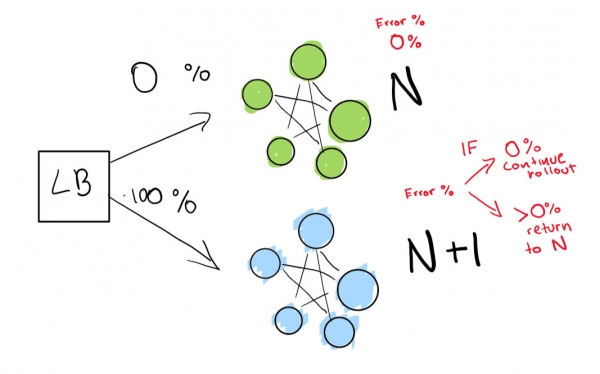
Si vous souhaitez passer à un niveau encore plus avancé, laissez tout s'exécuter automatiquement dans le déploiement bleu-vert.
Détection des anomalies et atténuation automatique
Étant donné que vous disposez d’une journalisation centralisée et d’une bonne collecte de journaux, vous pouvez déjà définir des objectifs plus élevés. Par exemple, prédisez de manière proactive les échecs. Les fonctions sont suivies sur des moniteurs et dans des journaux et divers diagrammes sont créés - et vous pouvez prédire à l'avance ce qui ne va pas :
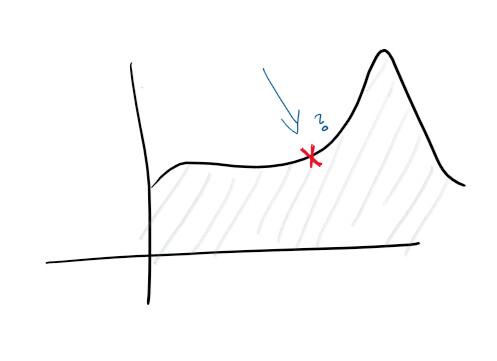
Une fois les anomalies détectées, vous commencez à examiner certains des indices fournis par le service. Par exemple, un pic de charge du processeur peut indiquer qu'un disque dur est en panne, tandis qu'un pic de requêtes peut indiquer que vous devez évoluer. Ce type de données statistiques vous permet de rendre le service proactif.
Grâce à ces informations, vous pouvez évoluer dans n'importe quelle dimension et modifier de manière proactive et réactive les caractéristiques des machines, des bases de données, des connexions et d'autres ressources.
C'est ça!
Cette liste de priorités vous évitera bien des problèmes si vous développez un service cloud.
L'auteur de l'article original invite les lecteurs à laisser leurs commentaires et à apporter des modifications. L'article est distribué en open source, pull request de l'auteur .
Que lire d'autre sur le sujet :
Source: habr.com
