

Considérez le concept de surveillance Kubernetes, familiarisez-vous avec l'outil Prometheus et parlez d'alerte.
Le sujet de la surveillance est volumineux, il ne peut être démonté en un seul article. L’objectif de ce texte est de donner un aperçu des outils, concepts et approches.
Le matériau de l'article est une compression de . Si vous souhaitez suivre un cours complet, inscrivez-vous à un cours sur .

Ce qui est surveillé dans un cluster Kubernetes
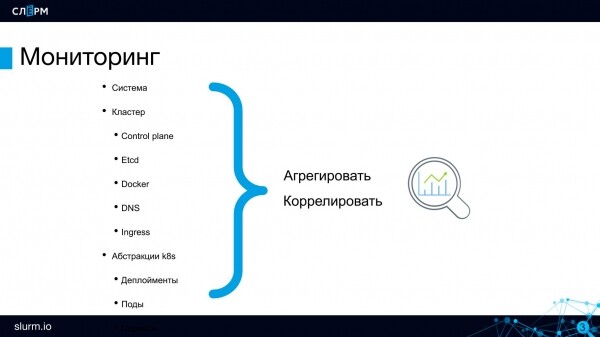
serveurs physiques. Si le cluster Kubernetes est déployé sur ses serveurs, vous devez surveiller leur santé. Zabbix gère cette tâche ; si vous travaillez avec lui, vous n'avez pas besoin de refuser, il n'y aura pas de conflits. C'est Zabbix qui surveille l'état de nos serveurs.
Passons à la surveillance au niveau du cluster.
Composants du plan de contrôle : API, planificateur et autres. Au minimum, vous devez vous assurer que l'API des serveurs ou etcd est supérieure à 0. Etcd peut renvoyer de nombreuses métriques : par les disques sur lesquels il tourne, par la santé de son cluster etcd, et autres.
Docker est apparu il y a longtemps et tout le monde est bien conscient de ses problèmes : de nombreux conteneurs donnent lieu à des gels et autres problèmes. Par conséquent, Docker lui-même, en tant que système, devrait également être contrôlé, au moins en termes de disponibilité.
DNS Si le DNS tombe en panne dans le cluster, l'ensemble du service Discovery tombera après, les appels de pods à pods cesseront de fonctionner. Dans ma pratique, de tels problèmes ne se sont pas produits, mais cela ne signifie pas que l'état du DNS n'a pas besoin d'être surveillé. La latence des requêtes et certaines autres mesures peuvent être suivies sur CoreDNS.
Ingress. Il est nécessaire de contrôler la disponibilité des entrées (y compris l'Ingress Controller) comme points d'entrée au projet.
Les principaux composants du cluster ont été démantelés - passons maintenant au niveau des abstractions.
Il semblerait que les applications fonctionnent dans des pods, ce qui signifie qu'elles doivent être contrôlées, mais en réalité ce n'est pas le cas. Les pods sont éphémères : aujourd'hui ils fonctionnent sur un serveur, demain sur un autre ; aujourd'hui il y en a 10, demain 2. Personne ne surveille donc les pods. Au sein d’une architecture de microservices, il est plus important de contrôler la disponibilité de l’application dans son ensemble. Vérifiez en particulier la disponibilité des points de terminaison du service : est-ce que quelque chose fonctionne ? Si l'application est disponible, que se passe-t-il derrière elle, combien de répliques il y a maintenant - ce sont des questions du second ordre. Il n'est pas nécessaire de surveiller des instances individuelles.
Au dernier niveau, vous devez contrôler le fonctionnement de l'application elle-même, prendre des mesures commerciales : le nombre de commandes, le comportement des utilisateurs, etc.
Prométhée
Le meilleur système pour surveiller un cluster est . Je ne connais aucun outil qui puisse égaler Prometheus en termes de qualité et de facilité d'utilisation. C'est idéal pour une infrastructure flexible, donc quand ils parlent de « surveillance Kubernetes », ils pensent généralement à Prometheus.
Il existe plusieurs options pour démarrer avec Prometheus : en utilisant Helm, vous pouvez installer un opérateur Prometheus ou Prometheus standard.
- Prométhée régulier. Tout va bien pour lui, mais vous devez configurer ConfigMap - en fait, écrire des fichiers de configuration textuels, comme nous le faisions auparavant, avant l'architecture des microservices.
- Prometheus Operator est un peu plus étendu, un peu plus compliqué en termes de logique interne, mais il est plus facile de travailler avec : il y a des objets séparés, des abstractions sont ajoutées au cluster, elles sont donc beaucoup plus pratiques à contrôler et à configurer.
Pour comprendre le produit, je recommande d'installer d'abord le Prometheus standard. Vous devrez tout configurer via la configuration, mais cela sera bénéfique : vous découvrirez ce qui appartient à quoi et comment c'est configuré. Dans Prometheus Operator, vous montez immédiatement à une abstraction supérieure, même si vous pouvez également plonger dans les profondeurs si vous le souhaitez.
Prometheus est bien intégré à Kubernetes : il peut accéder et interagir avec le serveur API.
Prometheus est populaire, c'est pourquoi un grand nombre d'applications et de langages de programmation le prennent en charge. Une prise en charge est nécessaire, car Prometheus possède son propre format de métriques et pour le transférer, vous avez besoin soit d'une bibliothèque dans l'application, soit d'un exportateur prêt à l'emploi. Et il existe de nombreux exportateurs de ce type. Par exemple, il existe PostgreSQL Exporter : il récupère les données de PostgreSQL et les convertit au format Prometheus afin que Prometheus puisse les utiliser.
Architecture de Prométhée
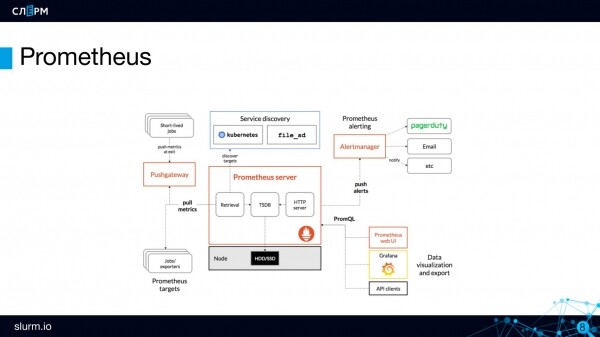
Serveur Prometheus est l'arrière-plan, le cerveau de Prométhée. Les métriques sont stockées et traitées ici.
Les métriques sont stockées dans la base de données de séries chronologiques (TSDB). TSDB n'est pas une base de données distincte, mais un package en langage Go intégré à Prometheus. En gros, tout est dans un seul binaire.
Ne stockez pas de données dans TSDB pendant une longue période
L'infrastructure Prometheus n'est pas adaptée au stockage à long terme des métriques. La période de conservation par défaut est de 15 jours. Vous pouvez dépasser cette limite, mais gardez à l'esprit : plus vous stockez de données dans TSDB et plus vous le faites longtemps, plus cela consommera de ressources. Le stockage de données historiques dans Prometheus est considéré comme une mauvaise pratique.
Si vous avez un trafic énorme, le nombre de métriques est de plusieurs centaines de milliers par seconde, alors il est préférable de limiter leur stockage par espace disque ou par période. Habituellement, les « données chaudes » sont stockées dans TSDB, les métriques en quelques heures seulement. Pour un stockage plus long, le stockage externe est utilisé dans les bases de données qui s'y prêtent vraiment, par exemple InfluxDB, ClickHouse, etc. J'ai vu d'autres bonnes critiques sur ClickHouse.
Prometheus Server fonctionne sur le modèle tirer: il recherche des métriques sur les points finaux que nous lui avons donnés. Ils ont dit : « allez sur le serveur API », et il y va toutes les n secondes et prend les métriques.
Pour les objets à courte durée de vie (job ou tâche cron) pouvant apparaître entre les périodes de scraping, il existe un composant Pushgateway. Les métriques des objets à court terme y sont poussées : le travail a augmenté, effectué une action, envoyé des métriques à Pushgateway et terminé. Après un certain temps, Prometheus descendra à son propre rythme et récupérera ces métriques de Pushgateway.
Pour configurer les notifications dans Prometheus, il existe un composant distinct : Gestionnaire d'alertes. Et les règles d'alerte. Par exemple, vous devez créer une alerte si l'API du serveur est 0. Lorsque l'événement se déclenche, l'alerte est transmise au gestionnaire d'alertes pour une diffusion ultérieure. Le gestionnaire d'alertes dispose de paramètres de routage assez flexibles : un groupe d'alertes peut être envoyé au chat télégramme des administrateurs, un autre au chat des développeurs et un troisième au chat des travailleurs de l'infrastructure. Les notifications peuvent être envoyées à Slack, Telegram, par e-mail et à d'autres canaux.
Et enfin, je vais vous parler de la fonctionnalité tueur de Prometheus - Découverte. Lorsque vous travaillez avec Prometheus, vous n'avez pas besoin de spécifier des adresses spécifiques d'objets à surveiller, il suffit de définir leur type. Autrement dit, vous n'avez pas besoin d'écrire "voici l'adresse IP, voici le port - moniteur", vous devez plutôt déterminer selon quels principes trouver ces objets (objectifs - objectifs). Prometheus lui-même, en fonction des objets actuellement actifs, récupère ceux nécessaires et les ajoute à la surveillance.
Cette approche s'adapte bien à la structure Kubernetes, où tout flotte aussi : aujourd'hui il y a 10 serveurs, demain 3. Afin de ne pas préciser à chaque fois l'adresse IP du serveur, ils ont écrit une fois comment la trouver - et Discovering le fera .
La langue de Prométhée s'appelle PromQL. En utilisant ce langage, vous pouvez obtenir les valeurs de métriques spécifiques, puis les convertir et créer des calculs analytiques basés sur elles.
https://prometheus.io/docs/prometheus/latest/querying/basics/
Простой запрос
container_memory_usage_bytes
Математические операции
container_memory_usage_bytes / 1024 / 1024
Встроенные функции
sum(container_memory_usage_bytes) / 1024 / 1024
Уточнение запроса
100 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m]) * 100)Interface Web Prometheus
Prometheus possède sa propre interface Web assez minimaliste. Convient uniquement pour le débogage ou la démonstration.
Dans la ligne Expression, vous pouvez écrire une requête dans le langage PromQL.
L'onglet Alertes contient des règles d'alerte et elles ont trois statuts :
- inactif - si l'alerte n'est pas active pour le moment, c'est-à-dire que tout va bien et qu'elle n'a pas fonctionné ;
- en attente - c'est si l'alerte a fonctionné, mais que l'envoi n'a pas encore réussi. Le délai est défini pour compenser le clignotement du réseau : si le service spécifié a augmenté en une minute, l'alarme ne doit pas encore être déclenchée ;
- le tir est le troisième état lorsque l'alerte s'allume et envoie des messages.
Dans le menu Statut, vous aurez accès à des informations sur ce qu'est Prometheus. Il y a aussi une transition vers les cibles (cibles), dont nous avons parlé plus haut.
Pour un aperçu plus détaillé de l'interface Prometheus, voir .
Intégration avec Grafana
Dans l'interface Web de Prometheus, vous ne trouverez pas de graphiques beaux et compréhensibles à partir desquels vous pourrez tirer une conclusion sur l'état du cluster. Pour les construire, Prometheus est intégré à Grafana. Nous obtenons de tels tableaux de bord.
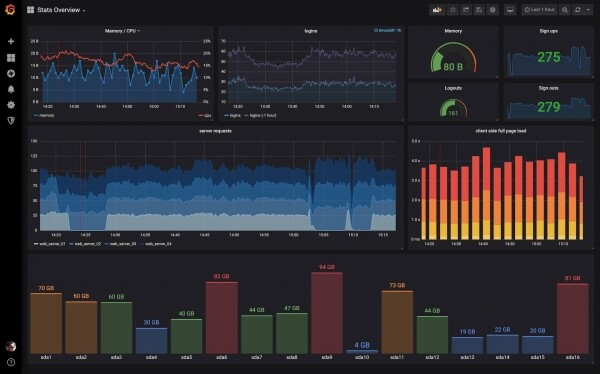
Mettre en place l'intégration de Prometheus et Grafana n'est pas difficile du tout, vous pouvez trouver des instructions dans la documentation : Eh bien, je vais terminer par ceci.
Dans les articles suivants, nous continuerons le sujet de la surveillance : nous parlerons de la collecte et de l'analyse des journaux à l'aide de Grafana Loki et d'outils alternatifs.
Auteur : Marcel Ibraev, administrateur Kubernetes certifié, ingénieur en exercice dans l'entreprise , conférencier et développeur de cours Slurm.
Source: habr.com
