

Cet article est une traduction de mon article sur le support - , qui s'est avéré très populaire, probablement en raison de sa simplicité. Par conséquent, j'ai décidé de l'écrire en russe et d'en ajouter un peu pour faire comprendre à une personne ordinaire qui n'est pas un spécialiste des données ce qu'est un entrepôt de données (DW), et ce qu'est un lac de données (Data Lake), et comment ils s'entendre.
Pourquoi ai-je voulu écrire sur le lac de données ? Je travaille avec les données et l'analyse depuis plus de 10 ans, et maintenant je travaille définitivement avec le Big Data chez Amazon Alexa AI à Cambridge, qui se trouve à Boston, même si je vis à Victoria sur l'île de Vancouver et que je visite souvent Boston et Seattle. , et À Vancouver, et parfois même à Moscou, je prends la parole lors de conférences. J'écris aussi de temps en temps, mais j'écris principalement en anglais, et j'ai déjà écrit , j'ai également besoin de partager les tendances analytiques d'Amérique du Nord, et j'écris parfois dans .
J'ai toujours travaillé avec des entrepôts de données et depuis 2015, j'ai commencé à travailler en étroite collaboration avec Amazon Web Services et je suis généralement passé à l'analyse cloud (AWS, Azure, GCP). J'ai observé l'évolution des solutions d'analyse depuis 2007 et j'ai même travaillé pour le fournisseur d'entrepôts de données Teradata et l'ai implémenté chez Sberbank, et c'est à ce moment-là qu'est apparu le Big Data avec Hadoop. Tout le monde a commencé à dire que l'ère du stockage était révolue et que maintenant tout était sur Hadoop, puis ils ont recommencé à parler de Data Lake, que maintenant la fin de l'entrepôt de données était définitivement arrivée. Mais heureusement (peut-être malheureusement pour certains qui ont gagné beaucoup d’argent en créant Hadoop), l’entrepôt de données n’a pas disparu.
Dans cet article, nous verrons ce qu'est un lac de données. Cet article est destiné aux personnes qui ont peu ou pas d’expérience avec les entrepôts de données.

Sur la photo, le lac de Bled, c'est l'un de mes lacs préférés, même si je n'y suis allé qu'une seule fois, je m'en suis souvenu toute ma vie. Mais nous parlerons d'un autre type de lac : un lac de données. Peut-être que beaucoup d'entre vous ont déjà entendu parler de ce terme plus d'une fois, mais une définition supplémentaire ne fera de mal à personne.
Tout d’abord, voici les définitions les plus populaires d’un Data Lake :
"un stockage de fichiers de tous les types de données brutes disponibles pour analyse par n'importe qui dans l'organisation" - Martin Fowler.
« Si vous pensez qu'un datamart est une bouteille d'eau - purifiée, conditionnée et conditionnée pour une consommation pratique, alors un lac de données est un immense réservoir d'eau sous sa forme naturelle. Utilisateurs, je peux collecter de l'eau pour moi-même, plonger profondément, explorer »- James Dixon.
Nous savons désormais avec certitude qu'un lac de données concerne l'analyse, il nous permet de stocker de grandes quantités de données dans leur forme originale et nous disposons de l'accès nécessaire et pratique aux données.
J'aime souvent simplifier les choses. Si je peux expliquer un terme complexe en termes simples, c'est que j'ai compris son fonctionnement et son utilité. Une fois, je fouinais dans iPhone dans la galerie photo, et là j'ai réalisé qu'il s'agissait d'un véritable lac de données, j'ai même créé une diapositive pour des conférences :
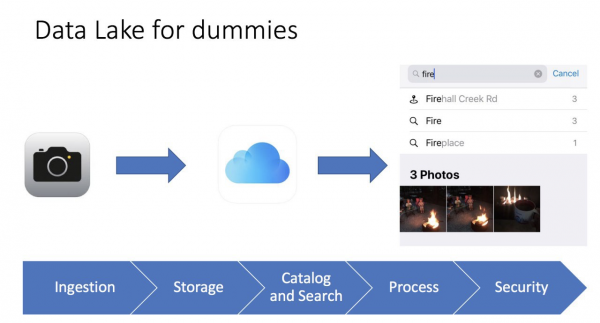
C'est très simple. On prend une photo avec son téléphone, elle est enregistrée sur le téléphone et peut être sauvegardée sur iCloud (un service de stockage de fichiers dans le nuage). Le téléphone enregistre également les métadonnées de la photo : son contenu, sa géolocalisation et la date et l'heure. On peut ainsi utiliser une interface conviviale. iPhonePour retrouver nos photos, on consulte même les statistiques. Par exemple, si je recherche des photos avec le mot « feu », je trouve trois photos de feux de camp. Pour moi, c'est comme un outil de veille stratégique : rapide et efficace.
Et bien sûr, il ne faut pas oublier la sécurité (autorisation et authentification), sinon nos données peuvent facilement tomber dans le domaine public. Il y a beaucoup de nouvelles concernant les grandes entreprises et les startups dont les données sont devenues accessibles au public en raison de la négligence des développeurs et du non-respect de règles simples.
Même une image aussi simple nous aide à imaginer ce qu'est un lac de données, ses différences par rapport à un entrepôt de données traditionnel et ses principaux éléments :
- Chargement des données (Ingestion) est un élément clé du lac de données. Les données peuvent entrer dans l'entrepôt de données de deux manières : par lots (chargement à intervalles) et par streaming (flux de données).
- Stockage de fichiers (Stockage) est le composant principal du Data Lake. Nous avions besoin que le stockage soit facilement évolutif, extrêmement fiable et peu coûteux. Par exemple, dans AWS, il s'agit de S3.
- Catalogue et recherche (Catalogue et recherche) - pour éviter le Data Swamp (c'est-à-dire lorsque nous vidons toutes les données dans une seule pile, et qu'il est alors impossible de travailler avec), nous devons créer une couche de métadonnées pour classer les données. afin que les utilisateurs puissent facilement trouver les données dont ils ont besoin pour l'analyse. De plus, vous pouvez utiliser des solutions de recherche supplémentaires telles que ElasticSearch. La recherche aide l'utilisateur à trouver les données requises via une interface conviviale.
- Traitement (Processus) - cette étape est responsable du traitement et de la transformation des données. Nous pouvons transformer les données, modifier leur structure, les nettoyer et bien plus encore.
- sécurité (Sécurité) - Il est important de consacrer du temps à la conception sécuritaire de la solution. Par exemple, le cryptage des données pendant le stockage, le traitement et le chargement. Il est important d'utiliser des méthodes d'authentification et d'autorisation. Enfin, un outil d'audit est nécessaire.
D’un point de vue pratique, on peut caractériser un lac de données par trois attributs :
- Collectez et stockez n'importe quoi — le lac de données contient toutes les données, à la fois les données brutes non traitées pour n'importe quelle période de temps et les données traitées/nettoyées.
- Analyse approfondie — un lac de données permet aux utilisateurs d'explorer et d'analyser des données.
- Accès flexible — Le lac de données offre un accès flexible à différentes données et différents scénarios.
Nous pouvons maintenant parler de la différence entre un entrepôt de données et un lac de données. Habituellement, les gens demandent :
- Qu’en est-il de l’entrepôt de données ?
- Remplaçons-nous l’entrepôt de données par un lac de données ou l’étendons-nous ?
- Est-il encore possible de se passer d’un lac de données ?
Bref, il n'y a pas de réponse claire. Tout dépend de la situation spécifique, des compétences de l'équipe et du budget. Par exemple, migration d'un entrepôt de données d'Oracle vers AWS et création d'un lac de données par une filiale d'Amazon - Woot - .
D'un autre côté, l'éditeur Snowflake affirme qu'il n'est plus nécessaire de penser à un lac de données, puisque sa plateforme de données (jusqu'en 2020, c'était un entrepôt de données) vous permet de combiner à la fois un lac de données et un entrepôt de données. Je n'ai pas beaucoup travaillé avec Snowflake, et c'est vraiment un produit unique qui peut faire cela. Le prix de l'émission est une autre affaire.
En conclusion, mon opinion personnelle est que nous avons toujours besoin d'un entrepôt de données comme principale source de données pour nos rapports, et que tout ce qui ne convient pas, nous le stockons dans un lac de données. Tout le rôle de l’analyse est de fournir un accès facile aux entreprises pour qu’elles puissent prendre des décisions. Quoi qu'on en dise, les utilisateurs professionnels travaillent plus efficacement avec un entrepôt de données qu'avec un lac de données, par exemple chez Amazon - il y a Redshift (entrepôt de données analytiques) et il y a Redshift Spectrum/Athena (interface SQL pour un lac de données dans S3 basée sur Ruche/Presto). Il en va de même pour d’autres entrepôts de données analytiques modernes.
Examinons une architecture typique d'entrepôt de données :
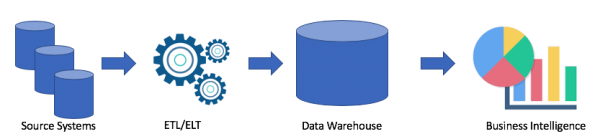
C'est une solution classique. Nous avons des systèmes sources, en utilisant ETL/ELT, nous copions les données dans un entrepôt de données analytiques et les connectons à une solution de Business Intelligence (mon préféré est Tableau, et le vôtre ?).
Cette solution présente les inconvénients suivants :
- Les opérations ETL/ELT nécessitent du temps et des ressources.
- En règle générale, la mémoire pour stocker les données dans un entrepôt de données analytiques n'est pas bon marché (par exemple, Redshift, BigQuery, Teradata), car nous devons acheter un cluster entier.
- Les utilisateurs professionnels ont accès à des données nettoyées et souvent agrégées et n'ont pas accès aux données brutes.
Bien entendu, tout dépend de votre cas. Si vous ne rencontrez aucun problème avec votre entrepôt de données, vous n'avez pas du tout besoin d'un lac de données. Mais lorsque des problèmes surviennent en raison du manque d’espace, de puissance ou que le prix joue un rôle clé, vous pouvez alors envisager l’option d’un lac de données. C’est pourquoi le lac de données est très populaire. Voici un exemple d’architecture de lac de données :
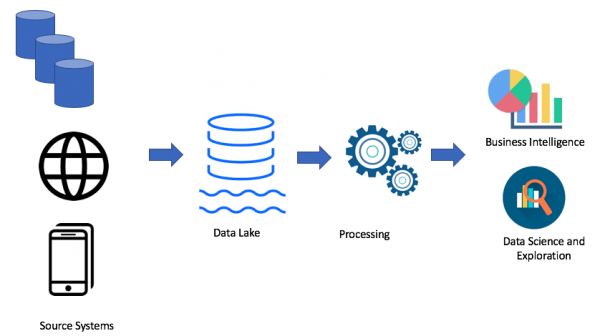
En utilisant l'approche du lac de données, nous chargeons des données brutes dans notre lac de données (par lots ou en streaming), puis nous traitons les données selon nos besoins. Le lac de données permet aux utilisateurs métiers de créer leurs propres transformations de données (ETL/ELT) ou d'analyser les données dans des solutions de Business Intelligence (si le pilote nécessaire est disponible).
L'objectif de toute solution d'analyse est de servir les utilisateurs professionnels. Nous devons donc toujours travailler selon les exigences de l’entreprise. (Chez Amazon, c'est l'un des principes : travailler à rebours).
En travaillant à la fois avec un entrepôt de données et un lac de données, nous pouvons comparer les deux solutions :
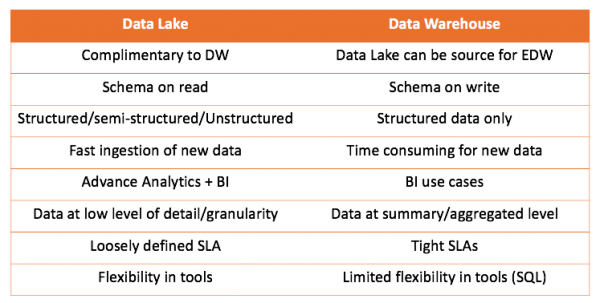
La principale conclusion que l’on peut tirer est que l’entrepôt de données ne concurrence pas le lac de données, mais le complète. Mais c'est à vous de décider ce qui convient à votre cas. C’est toujours intéressant de l’essayer soi-même et d’en tirer les bonnes conclusions.
Je voudrais également vous raconter un des cas où j'ai commencé à utiliser l'approche du lac de données. Tout est assez trivial, j'ai essayé d'utiliser un outil ELT (nous avions Matillion ETL) et Amazon Redshift, ma solution a fonctionné, mais ne répondait pas aux exigences.
J'avais besoin de prendre des journaux Web, de les transformer et de les agréger pour fournir des données pour 2 cas :
- L'équipe marketing souhaitait analyser l'activité des robots pour le référencement
- Le service informatique souhaitait examiner les mesures de performances des sites Web
Des journaux très simples, très simples. Voici un exemple :
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188
192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57
"GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2
arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067
"Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012"
1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"Un fichier pesait 1 à 4 mégaoctets.
Mais il y avait une difficulté. Nous avions 7 domaines dans le monde et 7000 50 4 fichiers ont été créés en une journée. Ce n'est pas beaucoup plus de volume, seulement XNUMX gigaoctets. Mais la taille de notre cluster Redshift était également petite (XNUMX nœuds). Le chargement d'un fichier de manière traditionnelle a pris environ une minute. Autrement dit, le problème n’a pas été résolu de front. Et ce fut le cas lorsque j’ai décidé d’utiliser l’approche du lac de données. La solution ressemblait à ceci :
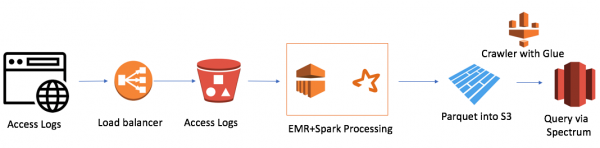
C'est assez simple (je tiens à préciser que l'avantage de travailler dans le cloud est la simplicité). J'ai utilisé:
- AWS Elastic Map Reduction (Hadoop) pour la puissance de calcul
- AWS S3 comme stockage de fichiers avec la possibilité de chiffrer les données et de limiter l'accès
- Spark comme puissance de calcul InMemory et PySpark pour la logique et la transformation des données
- Parquet grâce à Spark
- AWS Glue Crawler en tant que collecteur de métadonnées sur les nouvelles données et partitions
- Redshift Spectrum en tant qu'interface SQL vers le lac de données pour les utilisateurs Redshift existants
Le plus petit cluster EMR+Spark a traité l'intégralité de la pile de fichiers en 30 minutes. Il existe d'autres cas pour AWS, notamment beaucoup liés à Alexa, où il y a beaucoup de données.
Tout récemment, j'ai appris que l'un des inconvénients d'un lac de données est le RGPD. Le problème est que lorsque le client demande de le supprimer et que les données se trouvent dans l'un des fichiers, nous ne pouvons pas utiliser le langage de manipulation de données et l'opération DELETE comme dans une base de données.
J'espère que cet article a clarifié la différence entre un entrepôt de données et un lac de données. Si cela vous intéresse, je peux traduire davantage de mes articles ou d'articles de professionnels que je lis. Et aussi parler des solutions avec lesquelles je travaille et de leur architecture.
Source: habr.com
