

1. Données initiales
Le nettoyage des données est l’un des défis auxquels sont confrontées les tâches d’analyse des données. Ce matériel reflétait les développements et les solutions résultant de la résolution d'un problème pratique d'analyse de la base de données dans la formation de la valeur cadastrale. Sources ici .
Le fichier « Modèle comparatif total.ods » dans « Annexe B. Résultats de la détermination du KS 5. Informations sur la méthode de détermination de la valeur cadastrale 5.1 Approche comparative » a été pris en compte.
Tableau 1. Indicateurs statistiques de l'ensemble de données dans le fichier « Modèle comparatif total.ods »
Nombre total de champs, pcs. — 44
Nombre total d'enregistrements, pcs. — 365 490
Nombre total de caractères, pcs. — 101 714 693
Nombre moyen de caractères dans un enregistrement, pcs. — 278,297 XNUMX
Écart type des caractères dans un enregistrement, pcs. — 15,510 XNUMX
Nombre minimum de caractères dans une entrée, pcs. — 198
Nombre maximum de caractères dans une entrée, pcs. — 363
2. Partie introductive. Normes de base
Lors de l'analyse de la base de données spécifiée, une tâche a été créée pour préciser les exigences relatives au degré de purification, car, comme chacun le sait, la base de données spécifiée crée des conséquences juridiques et économiques pour les utilisateurs. Au cours des travaux, il s'est avéré qu'il n'existait aucune exigence spécifique quant au degré de nettoyage des mégadonnées. En analysant les normes juridiques en la matière, je suis arrivé à la conclusion qu'elles sont toutes formées de possibilités. C'est-à-dire qu'une certaine tâche est apparue, des sources d'informations sont compilées pour la tâche, puis un ensemble de données est formé et, sur la base de l'ensemble de données créé, des outils pour résoudre le problème. Les solutions qui en résultent constituent des points de référence pour choisir parmi des alternatives. Je l'ai présenté dans la figure 1.
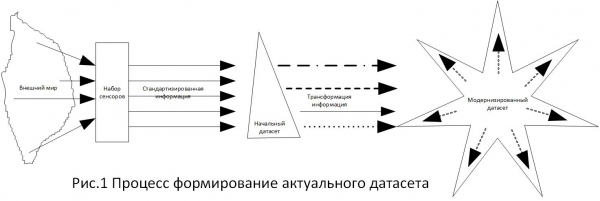
Puisque, en matière de détermination d'éventuelles normes, il est préférable de s'appuyer sur des technologies éprouvées, j'ai choisi les exigences énoncées dans , car je considérais ce document comme le plus complet sur cette problématique. En particulier, dans ce document, la section indique : « Il convient de noter que les exigences en matière d'intégrité des données s'appliquent également aux données manuelles (sur papier) et électroniques. » (traduction : « …les exigences en matière d'intégrité des données s'appliquent également aux données manuelles (papier) et électroniques »). Cette formulation est tout particulièrement associée à la notion de « preuve écrite », dans les dispositions de l'article 71 du Code de procédure civile, art. 70 TAS, article 75 CPA, « par écrit » Art. 84 Code de procédure civile.
La figure 2 présente un schéma de la formation des approches des types d'informations en jurisprudence.
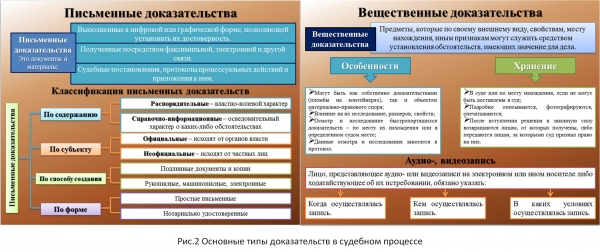
Riz. 2. Origine .
La figure 3 montre le mécanisme de la figure 1, pour les tâches du « guidage » ci-dessus. Il est facile, en faisant une comparaison, de constater que les approches utilisées pour répondre aux exigences d'intégrité de l'information dans les normes modernes relatives aux systèmes d'information sont considérablement limitées par rapport au concept juridique d'information.
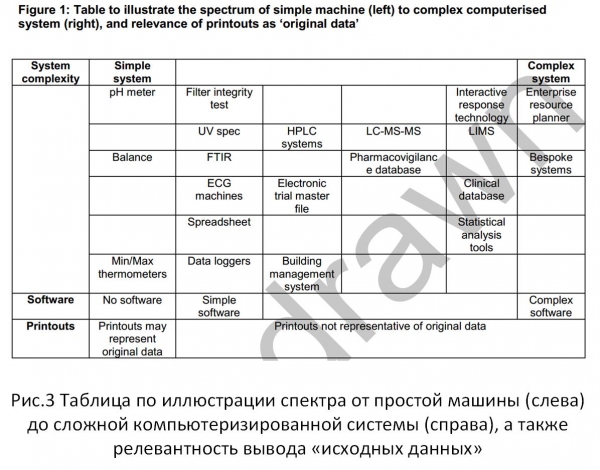
Ris.3
Dans le document spécifié (Guide), le lien avec la partie technique, les capacités de traitement et de stockage des données, est bien confirmé par une citation du chapitre 18.2. Base de données relationnelle : "Cette structure de fichiers est intrinsèquement plus sécurisée, car les données sont conservées dans un format de fichier volumineux qui préserve la relation entre les données et les métadonnées."
En fait, dans cette approche - à partir des capacités techniques existantes, il n'y a rien d'anormal et, en soi, il s'agit d'un processus naturel, puisque l'expansion des concepts provient de l'activité la plus étudiée - la conception de bases de données. Mais, d'un autre côté, apparaissent des normes juridiques qui ne prévoient pas de réductions sur les capacités techniques des systèmes existants, par exemple : .

Riz. 4. Entonnoir de capacités techniques ().
Sous ces aspects, il devient clair que l'ensemble de données d'origine (Fig. 1) devra, tout d'abord, être sauvegardé et, deuxièmement, servir de base pour en extraire des informations supplémentaires. Eh bien, à titre d'exemple : les caméras enregistrant les règles de circulation sont omniprésentes, les systèmes de traitement de l'information éliminent les contrevenants, mais d'autres informations peuvent également être proposées à d'autres consommateurs, par exemple, comme le suivi marketing de la structure du flux de clients vers un centre commercial. Et c’est une source de valeur ajoutée supplémentaire lors de l’utilisation de BigDat. Il est fort possible que les ensembles de données collectés aujourd’hui, quelque part dans le futur, aient une valeur selon un mécanisme similaire à la valeur actuelle des éditions rares de 1700. Après tout, en fait, les ensembles de données temporaires sont uniques et il est peu probable qu’ils se reproduisent à l’avenir.
3. Partie introductive. Critère d'évaluation
Au cours du processus de traitement, la classification suivante des erreurs a été élaborée.
1. Classe d'erreurs (basée sur GOST R 8.736-2011) : a) erreurs systématiques ; b) des erreurs aléatoires ; c) une erreur.
2. Par multiplicité : a) distorsion mono ; b) multi-distorsion.
3. Selon la criticité des conséquences : a) critique ; b) pas critique.
4. Par source d'occurrence :
A) Technique – erreurs qui surviennent lors du fonctionnement de l’équipement. Une erreur assez pertinente pour les systèmes IoT, les systèmes ayant un degré d'influence significatif sur la qualité de la communication, les équipements (matériel).
B) Erreurs de l'opérateur - erreurs dans un large éventail allant des fautes de frappe de l'opérateur lors de la saisie aux erreurs dans les spécifications techniques pour la conception de la base de données.
C) Erreurs de l'utilisateur - voici les erreurs de l'utilisateur dans toute la gamme, depuis « j'ai oublié de changer de disposition » jusqu'à la confusion entre les mètres et les pieds.
5. Séparé en une classe distincte :
a) la « tâche du séparateur », c'est-à-dire l'espace et le « : » (dans notre cas) lors de sa duplication ;
b) des mots écrits ensemble ;
c) pas d'espace après les caractères de service
d) symboles symétriquement multiples : (), "", "...".
Dans l'ensemble, avec la systématisation des erreurs de base de données présentée dans la figure 5, un système de coordonnées assez efficace est formé pour rechercher des erreurs et développer un algorithme de nettoyage des données pour cet exemple.
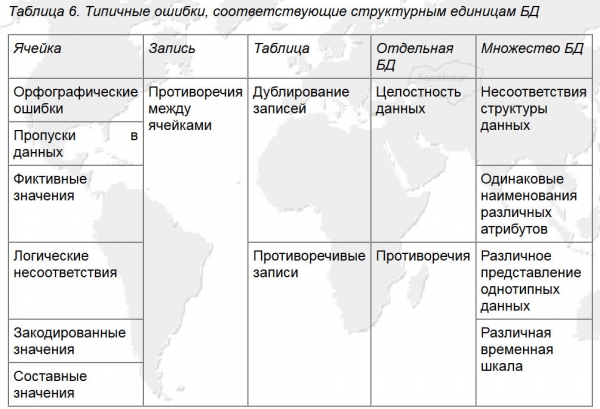
Riz. 5. Erreurs typiques correspondant aux unités structurelles de la base de données (Source : ).
Précision, intégrité du domaine, type de données, cohérence, redondance, exhaustivité, duplication, conformité aux règles commerciales, précision structurelle, anomalie des données, clarté, ponctualité, respect des règles d'intégrité des données. (Page 334. Principes fondamentaux de l'entreposage de données pour les professionnels de l'informatique / Paulraj Ponniah.—2e éd.)
Présentation du texte anglais et de la traduction automatique russe entre parenthèses.
Précision. La valeur stockée dans le système pour un élément de données est la bonne valeur pour cette occurrence de l'élément de données. Si vous avez un nom de client et une adresse stockés dans un enregistrement, alors l'adresse est la bonne adresse pour le client portant ce nom. Si vous trouvez la quantité commandée en 1000 12345678 unités dans l'enregistrement du numéro de commande XNUMX, alors cette quantité est la quantité exacte pour cette commande.
[Précision. La valeur stockée dans le système pour un élément de données est la valeur correcte pour cette occurrence de l'élément de données. Si vous avez un nom et une adresse de client stockés dans un enregistrement, alors l'adresse est la bonne adresse pour le client portant ce nom. Si vous trouvez la quantité commandée en 1000 12345678 unités dans l'enregistrement du numéro de commande XNUMX, alors cette quantité est la quantité exacte pour cette commande.]
Intégrité du domaine. La valeur des données d'un attribut se situe dans la plage de valeurs définies et autorisées. L'exemple courant est que les valeurs autorisées sont « masculin » et « féminin » pour l'élément de données de genre.
[Intégrité du domaine. La valeur des données d'attribut se situe dans la plage de valeurs valides et définies. Un exemple général est les valeurs valides « masculin » et « femelle » pour un élément de données de genre.]
Type de données. La valeur d'un attribut de données est en fait stockée en tant que type de données défini pour cet attribut. Lorsque le type de données du champ Nom du magasin est défini comme « texte », toutes les instances de ce champ contiennent le nom du magasin affiché au format textuel et non en codes numériques.
[Type de données. La valeur d'un attribut de données est en fait stockée en tant que type de données défini pour cet attribut. Si le type de données du champ Nom du magasin est défini comme « texte », toutes les instances de ce champ contiennent le nom du magasin affiché au format texte plutôt que des codes numériques.]
Cohérence. La forme et le contenu d'un champ de données sont les mêmes sur plusieurs systèmes sources. Si le code produit du produit ABC dans un système est 1234, alors le code de ce produit est 1234 dans chaque système source.
[Cohérence. La forme et le contenu du champ de données sont les mêmes dans les différents systèmes sources. Si le code produit du produit ABC sur un système est 1234, alors le code de ce produit est 1234 sur chaque système source.]
Redondance. Les mêmes données ne doivent pas être stockées à plus d’un endroit dans un système. Si, pour des raisons d'efficacité, un élément de données est intentionnellement stocké à plusieurs endroits dans un système, la redondance doit alors être clairement identifiée et vérifiée.
[Redondance. Les mêmes données ne doivent pas être stockées à plusieurs endroits du système. Si, pour des raisons d'efficacité, un élément de données est intentionnellement stocké à plusieurs endroits d'un système, la redondance doit alors être clairement définie et vérifiée.]
Complétude. Il n'y a aucune valeur manquante pour un attribut donné dans le système. Par exemple, dans un fichier client, il doit y avoir une valeur valide pour le champ « état » pour chaque client. Dans le fichier des détails de la commande, chaque enregistrement détaillé d'une commande doit être entièrement rempli.
[Exhaustivité. Il n'y a aucune valeur manquante dans le système pour cet attribut. Par exemple, le fichier client doit avoir une valeur valide pour le champ « statut » pour chaque client. Dans le fichier détaillé de la commande, chaque enregistrement détaillé de la commande doit être entièrement complété.]
Reproduction. La duplication des enregistrements dans un système est complètement résolue. Si le fichier produit contient des enregistrements en double, tous les enregistrements en double pour chaque produit sont identifiés et une référence croisée est créée.
[Dupliquer. La duplication des enregistrements dans le système a été complètement éliminée. Si l'on sait qu'un fichier de produit contient des entrées en double, alors toutes les entrées en double pour chaque produit sont identifiées et une référence croisée est créée.]
Conformité aux règles métier. Les valeurs de chaque élément de données respectent les règles métier prescrites. Dans un système d'enchères, le prix d'adjudication ou de vente ne peut être inférieur au prix de réserve. Dans un système de prêt bancaire, le solde du prêt doit toujours être positif ou nul.
[Respect des règles métiers. Les valeurs de chaque élément de données sont conformes aux règles métier établies. Dans un système d'enchères, le prix d'adjudication ou de vente ne peut être inférieur au prix de réserve. Dans un système de crédit bancaire, le solde du prêt doit toujours être positif ou nul.]
Définition structurelle. Partout où un élément de données peut naturellement être structuré en composants individuels, l'élément doit contenir cette structure bien définie. Par exemple, le nom d’un individu se divise naturellement en prénom, initiale et nom de famille. Les valeurs des noms d'individus doivent être stockées sous forme de prénom, d'initiale et de nom de famille. Cette caractéristique de la qualité des données simplifie l'application des normes et réduit les valeurs manquantes.
[Certitude structurelle. Lorsqu'un élément de données peut être naturellement structuré en composants individuels, l'élément doit contenir cette structure bien définie. Par exemple, le nom d’une personne est naturellement divisé en prénom, initiale et nom de famille. Les valeurs des noms individuels doivent être stockées sous forme de prénom, d’initiale et de nom de famille. Cette caractéristique de qualité des données simplifie l'application des normes et réduit les valeurs manquantes.]
Anomalie de données. Un champ doit être utilisé uniquement dans le but pour lequel il est défini. Si le champ Adresse-3 est défini pour une éventuelle troisième ligne d'adresse pour les adresses longues, alors ce champ doit être utilisé uniquement pour enregistrer la troisième ligne d'adresse. Il ne doit pas être utilisé pour saisir un numéro de téléphone ou de fax pour le client.
[Anomalie des données. Un champ ne doit être utilisé que dans le but pour lequel il est défini. Si le champ Adresse-3 est défini pour une éventuelle troisième ligne d'adresse pour les adresses longues, alors ce champ ne doit être utilisé que pour enregistrer la troisième ligne d'adresse. Il ne doit pas être utilisé pour saisir un numéro de téléphone ou de fax pour un client.]
Clarté. Un élément de données peut posséder toutes les autres caractéristiques des données de qualité, mais si les utilisateurs ne comprennent pas clairement sa signification, alors l'élément de données n'a aucune valeur pour les utilisateurs. Des conventions de dénomination appropriées aident à rendre les éléments de données bien compris par les utilisateurs.
[Clarté. Un élément de données peut avoir toutes les autres caractéristiques d’une bonne donnée, mais si les utilisateurs ne comprennent pas clairement sa signification, alors l’élément de données n’a aucune valeur pour les utilisateurs. Des conventions de dénomination correctes aident à rendre les éléments de données bien compris par les utilisateurs.]
Opportun. Les utilisateurs déterminent l'actualité des données. Si les utilisateurs s'attendent à ce que les données de dimension client ne datent pas de plus d'un jour, les modifications apportées aux données client dans les systèmes sources doivent être appliquées quotidiennement à l'entrepôt de données.
[En temps opportun. Les utilisateurs déterminent l'actualité des données. Si les utilisateurs s'attendent à ce que les données de dimension client ne datent pas de plus d'un jour, les modifications apportées aux données client dans les systèmes sources doivent être appliquées quotidiennement à l'entrepôt de données.]
Utilité. Chaque élément de données de l'entrepôt de données doit satisfaire à certaines exigences de l'ensemble des utilisateurs. Un élément de données peut être précis et de haute qualité, mais s’il n’a aucune valeur pour les utilisateurs, il est alors totalement inutile que cet élément de données se trouve dans l’entrepôt de données.
[Utilitaire. Chaque élément de données du magasin de données doit satisfaire à certaines exigences de la collection utilisateur. Un élément de données peut être précis et de haute qualité, mais s'il n'apporte pas de valeur aux utilisateurs, il n'est pas nécessaire que cet élément de données se trouve dans l'entrepôt de données.]
Respect des règles d'intégrité des données. Les données stockées dans les bases de données relationnelles des systèmes sources doivent respecter les règles d'intégrité d'entité et d'intégrité référentielle. Toute table qui autorise null comme clé primaire n'a pas d'intégrité d'entité. L’intégrité référentielle force l’établissement correct des relations parent-enfant. Dans une relation client-commande, l'intégrité référentielle garantit l'existence d'un client pour chaque commande dans la base de données.
[Conformité aux règles d'intégrité des données. Les données stockées dans les bases de données relationnelles des systèmes sources doivent respecter les règles d’intégrité des entités et d’intégrité référentielle. Toute table qui autorise null comme clé primaire n'a pas d'intégrité d'entité. L’intégrité référentielle force la relation entre parents et enfants à s’établir correctement. Dans une relation client-commande, l'intégrité référentielle garantit qu'un client existe pour chaque commande dans la base de données.]
4. Qualité du nettoyage des données
La qualité du nettoyage des données est une question plutôt problématique dans le bigdata. Répondre à la question de savoir quel degré de nettoyage des données est nécessaire pour accomplir la tâche est fondamental pour tout analyste de données. Dans la plupart des problèmes actuels, chaque analyste le détermine lui-même et il est peu probable que quelqu'un de l'extérieur soit capable d'évaluer cet aspect dans sa solution. Mais pour la tâche à accomplir dans cette affaire, cette question était extrêmement importante, puisque la fiabilité des données juridiques devait tendre vers une seule.
Considérer les technologies de test de logiciels pour déterminer la fiabilité opérationnelle. Aujourd'hui, il y a plus que ces modèles . De nombreux modèles utilisent un modèle de gestion des sinistres :
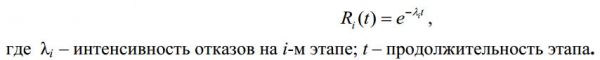
Fig. 6
En pensant comme suit : « Si l’erreur trouvée est un événement similaire à l’événement de défaillance dans ce modèle, alors comment trouver un analogue du paramètre t ? » Et j'ai compilé le modèle suivant : Imaginons que le temps qu'il faut à un testeur pour vérifier un enregistrement est de 1 minute (pour la base de données en question), puis pour trouver toutes les erreurs il lui faudra 365 494 minutes, soit environ 3 ans et 3 ans. mois de temps de travail. Comme nous le comprenons, il s'agit d'un travail très important et les coûts de vérification de la base de données seront prohibitifs pour le compilateur de cette base de données. Dans cette réflexion, la notion économique de coûts apparaît et après analyse je suis arrivé à la conclusion qu'il s'agit d'un outil assez efficace. Basé sur la loi de l'économie : « Le volume de production (en unités) auquel une entreprise atteint le profit maximum est situé au point où le coût marginal de production d'une nouvelle unité de production est comparé au prix que cette entreprise peut recevoir. pour une nouvelle unité. Partant du postulat selon lequel la détection de chaque erreur ultérieure nécessite de plus en plus de vérifications des enregistrements, il s’agit d’un facteur de coût. C'est-à-dire que le postulat adopté dans les modèles de test prend une signification physique dans le schéma suivant : si pour trouver la i-ème erreur, il était nécessaire de vérifier n enregistrements, alors pour trouver la prochaine (i+1) erreur, il faudra pour vérifier m enregistrements et en même temps n
- Lorsque le nombre d'enregistrements vérifiés avant qu'une nouvelle erreur ne soit détectée se stabilise ;
- Lorsque le nombre d'enregistrements vérifiés avant de trouver l'erreur suivante augmentera.
Pour déterminer la valeur critique, je me suis tourné vers le concept de faisabilité économique, qui dans ce cas, en utilisant le concept de coûts sociaux, peut être formulé comme suit : « Les coûts de correction de l'erreur doivent être supportés par l'agent économique qui peut le faire. au moindre coût. » Nous avons un agent : un testeur qui passe 1 minute à vérifier un enregistrement. En termes monétaires, si vous gagnez 6000 12,2 roubles par jour, cela équivaudra à 1 roubles. (environ aujourd'hui). Reste à déterminer le deuxième côté de l’équilibre en droit économique. J'ai raisonné comme ça. Une erreur existante obligera la personne concernée à déployer des efforts pour la corriger, c'est-à-dire le propriétaire. Disons que cela nécessite XNUMX jour d’action (déposer une candidature, recevoir un document corrigé). Ensuite, d'un point de vue social, ses coûts seront égaux au salaire journalier moyen. Salaire moyen accumulé dans l'Okrug autonome des Khantys-Mansi 73285 roubles. ou 3053,542 roubles/jour. En conséquence, nous obtenons une valeur critique égale à :
3053,542 : 12,2 = 250,4 unités d'enregistrements.
Cela signifie que, d’un point de vue social, si un testeur vérifie 251 enregistrements et trouve une erreur, cela équivaut à ce que l’utilisateur corrige lui-même cette erreur. Par conséquent, si le testeur a consacré un temps égal à la vérification de 252 enregistrements pour trouver l'erreur suivante, il est alors préférable dans ce cas de faire supporter le coût de la correction par l'utilisateur.
Une approche simplifiée est présentée ici, puisque d'un point de vue social il faut prendre en compte toute la valeur supplémentaire générée par chaque spécialiste, c'est-à-dire les coûts incluant les impôts et les prestations sociales, mais le modèle est clair. Une conséquence de cette relation est l'exigence suivante pour les spécialistes : un spécialiste du secteur informatique doit avoir un salaire supérieur à la moyenne nationale. Si son salaire est inférieur au salaire moyen des utilisateurs potentiels de la base de données, il doit alors vérifier lui-même l'ensemble de la base de données.
Lors de l'utilisation du critère décrit, la première exigence de qualité de la base de données est formée :
Je(tr). La part des erreurs critiques ne doit pas dépasser 1/250,4 = 0,39938 %. Un peu moins que l'or dans l'industrie. Et physiquement, il n’y a pas plus de 1459 XNUMX enregistrements contenant des erreurs.
Recul économique.
En fait, en commettant un tel nombre d'erreurs dans les registres, la société accepte des pertes économiques d'un montant de :
1459*3053,542 = 4 455 118 roubles.
Ce montant est déterminé par le fait que la société ne dispose pas des outils nécessaires pour réduire ces coûts. Il s'ensuit que si quelqu'un dispose d'une technologie qui lui permet de réduire le nombre d'enregistrements erronés à, par exemple, 259, alors cela permettra à la société d'économiser :
1200*3053,542 = 3 664 250 roubles.
Mais en même temps, il peut demander son talent et son travail, disons, 1 million de roubles.
Autrement dit, les coûts sociaux sont réduits de :
3 664 250 – 1 000 000 = 2 664 250 roubles.
Cet effet constitue essentiellement la valeur ajoutée de l’utilisation des technologies BigDat.
Mais ici, il faut tenir compte du fait qu'il s'agit d'un effet social, et que le propriétaire de la base de données est les autorités municipales, leurs revenus provenant de l'utilisation des biens enregistrés dans cette base de données, au taux de 0,3%, sont de : 2,778 milliards de roubles/ année. Et ces frais (4 455 118 roubles) ne le dérangent pas beaucoup, puisqu'ils sont transférés aux propriétaires. Et, à cet égard, le développeur de technologies plus raffinées dans le Bigdata devra montrer sa capacité à convaincre le propriétaire de cette base de données, et de telles choses nécessitent un talent considérable.
Dans cet exemple, l'algorithme d'évaluation des erreurs a été choisi sur la base du modèle Schumann [2] de vérification logicielle lors des tests de fiabilité. En raison de sa prévalence sur Internet et de la possibilité d'obtenir les indicateurs statistiques nécessaires. La méthodologie est tirée de Monakhov Yu.M. « Stabilité fonctionnelle des systèmes d'information », voir sous le spoiler sur la Fig. 7-9.
Riz. 7 – 9 Méthodologie du modèle Schumann


La deuxième partie de ce document présente un exemple de nettoyage de données, dans lequel les résultats de l'utilisation du modèle Schumann sont obtenus.
Je vous présente les résultats obtenus :
Nombre estimé d'erreurs N = 3167 n.
Paramètre C, fonction lambda et fiabilité :
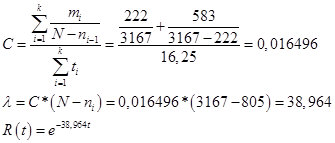
Ris.17
Essentiellement, lambda est un véritable indicateur de l’intensité avec laquelle les erreurs sont détectées à chaque étape. Si vous regardez la deuxième partie, l'estimation de cet indicateur était de 42,4 erreurs par heure, ce qui est tout à fait comparable à l'indicateur Schumann. Ci-dessus, il a été déterminé que le taux auquel un développeur trouve des erreurs ne doit pas être inférieur à 1 erreur pour 250,4 enregistrements, lors de la vérification d'un enregistrement par minute. D'où la valeur critique de lambda pour le modèle de Schumann :
60 / 250,4 = 0,239617.
C'est-à-dire que la nécessité d'effectuer des procédures de détection d'erreurs doit être effectuée jusqu'à ce que lambda, du 38,964 existant, diminue à 0,239617.
Ou jusqu'à ce que l'indicateur N (nombre potentiel d'erreurs) moins n (nombre d'erreurs corrigé) diminue en dessous de notre seuil accepté - 1459 pcs.
littérature
- Monakhov, Yu. M. Stabilité fonctionnelle des systèmes d'information. En 3 heures Partie 1. Fiabilité du logiciel : manuel. allocation / Yu. M. Monakhov; Vladimir. État univ. – Vladimir : Izvo Vladim. État Université, 2011. – 60 p. – ISBN978-5-9984-0189-3.
- Martin L. Shooman, « Modèles probabilistes pour la prévision de la fiabilité des logiciels ».
- Principes fondamentaux de l'entreposage de données pour les professionnels de l'informatique / Paulraj Ponniah.—2e éd.
Source: habr.com
