

Qu'est-ce qui pourrait forcer une entreprise aussi grande que Lamoda, dotée d'un processus rationalisé et de dizaines de services interconnectés, à modifier considérablement son approche ? La motivation peut être complètement différente : de la législative au désir d'expérimenter inhérent à tous les programmeurs.
Mais cela ne signifie pas que vous ne pouvez pas compter sur des avantages supplémentaires. Sergey Zaika vous dira exactement ce que vous pouvez gagner si vous implémentez l'API basée sur les événements sur Kafka (). On parlera aussi certainement de grands projets et de découvertes intéressantes - l'expérience ne peut pas s'en passer.
Avis de non-responsabilité : cet article est basé sur les éléments d'une rencontre organisée par Sergey en novembre 2018 sur HighLoad++. L'expérience en direct de Lamoda en travaillant avec Kafka a attiré les auditeurs tout autant que les autres reportages au programme. Nous pensons qu'il s'agit d'un excellent exemple du fait que vous pouvez et devez toujours trouver des personnes partageant les mêmes idées, et les organisateurs de HighLoad++ continueront d'essayer de créer une atmosphère propice à cela.
À propos du processus
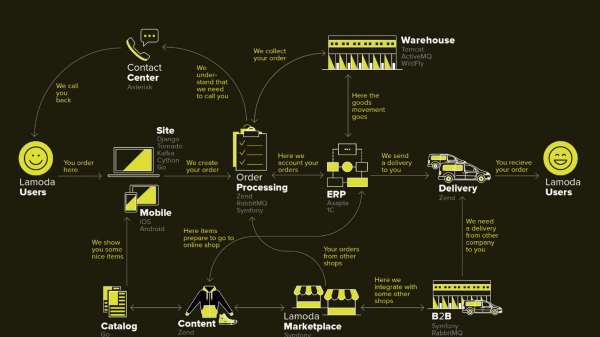
Lamoda est une grande plateforme de commerce électronique qui possède son propre centre de contact, un service de livraison (et de nombreux affiliés), un studio photo, un immense entrepôt, et tout cela fonctionne sur son propre logiciel. Il existe des dizaines de méthodes de paiement, des partenaires b2b qui peuvent utiliser tout ou partie de ces services et souhaitent connaître des informations à jour sur leurs produits. De plus, Lamoda opère dans trois pays en plus de la Fédération de Russie et tout y est un peu différent. Au total, il existe probablement plus d'une centaine de façons de configurer une nouvelle commande, qui doit être traitée à sa manière. Tout cela fonctionne avec l’aide de dizaines de services qui communiquent parfois de manière non évidente. Il existe également un système central dont la principale responsabilité est le statut des commandes. On l'appelle BOB, je travaille avec elle.
Outil de remboursement avec API basée sur les événements
Le mot événementiel est assez galvaudé ; un peu plus loin, nous définirons plus en détail ce que l'on entend par là. Je vais commencer par le contexte dans lequel nous avons décidé d'essayer l'approche API basée sur les événements dans Kafka.

Dans n'importe quel magasin, en plus des commandes pour lesquelles les clients paient, il arrive parfois que le magasin soit tenu de restituer de l'argent parce que le produit ne convenait pas au client. Il s'agit d'un processus relativement court : nous clarifions les informations, si nécessaire, et transférons l'argent.
Mais le retour est devenu plus compliqué en raison des changements de législation, et nous avons dû mettre en place un microservice distinct pour cela.

Nos motivations :
- Loi FZ-54 - en bref, la loi impose de déclarer au fisc toute opération monétaire, qu'il s'agisse d'une déclaration ou d'un reçu, dans un délai SLA assez court de quelques minutes. En tant qu'entreprise de commerce électronique, nous effectuons de nombreuses opérations. Techniquement, cela signifie une nouvelle responsabilité (et donc un nouveau service) et des améliorations dans tous les systèmes impliqués.
- Division BOB est un projet interne de l'entreprise visant à soulager BOB d'un grand nombre de responsabilités non essentielles et à réduire sa complexité globale.
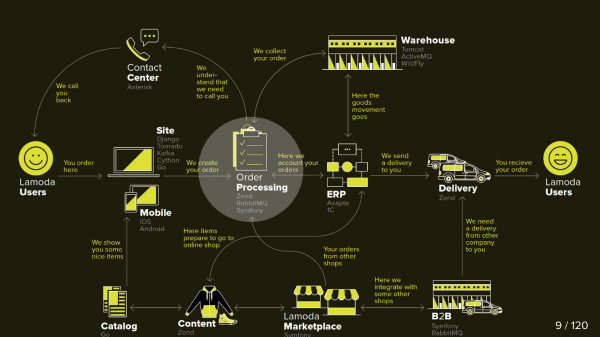
Ce diagramme montre les principaux systèmes Lamoda. Maintenant, la plupart d'entre eux sont plus une constellation de 5 à 10 microservices autour d'un monolithe en diminution. Ils grandissent lentement, mais nous essayons de les réduire, car déployer le fragment sélectionné au milieu est effrayant - nous ne pouvons pas le laisser tomber. Nous sommes obligés de réserver tous les échanges (flèches) et de prendre en compte le fait que l'un d'entre eux peut s'avérer indisponible.
BOB dispose également de nombreux échanges : systèmes de paiement, systèmes de livraison, systèmes de notification, etc.
Techniquement, BOB est :
- ~150 100 lignes de code + ~XNUMX XNUMX lignes de tests ;
- php7.2 + Zend 1 et composants Symfony 3 ;
- >100 API et ~50 intégrations sortantes ;
- 4 pays avec leur propre logique business.
Déployer BOB est coûteux et pénible, la quantité de code et de problèmes qu'il résout est telle que personne ne peut tout se mettre en tête. En général, il existe de nombreuses raisons de le simplifier.
Processus de retour
Initialement, deux systèmes sont impliqués dans le processus : BOB et Payment. Maintenant, deux autres apparaissent :
- Service de Fiscalisation, qui s'occupera des problèmes de fiscalisation et de communication avec les services externes.
- Refund Tool, qui contient simplement de nouveaux échanges pour ne pas gonfler le BOB.
Maintenant, le processus ressemble à ceci :
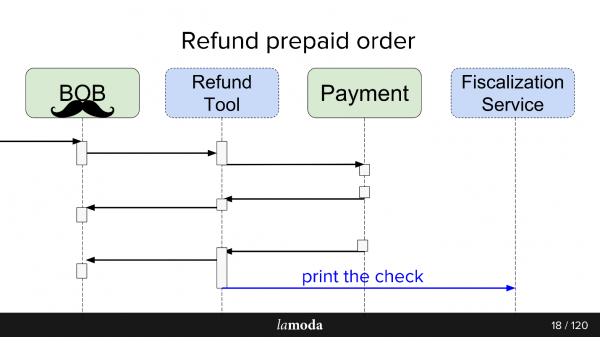
- BOB reçoit une demande de remboursement.
- BOB parle de cet outil de remboursement.
- L'outil de remboursement indique au paiement : "Restituez l'argent".
- Le paiement rend l'argent.
- Refund Tool et BOB synchronisent les statuts entre eux, car pour l'instant ils en ont tous deux besoin. Nous ne sommes pas encore prêts à passer complètement à l'outil de remboursement, car BOB dispose d'une interface utilisateur, de rapports de comptabilité et, en général, de nombreuses données qui ne peuvent pas être transférées aussi facilement. Il faut s'asseoir sur deux chaises.
- La demande de fiscalisation disparaît.
En conséquence, nous avons créé une sorte de bus événementiel sur Kafka - un bus événementiel, sur lequel tout a commencé. Hourra, nous avons maintenant un seul point d'échec (sarcasme).
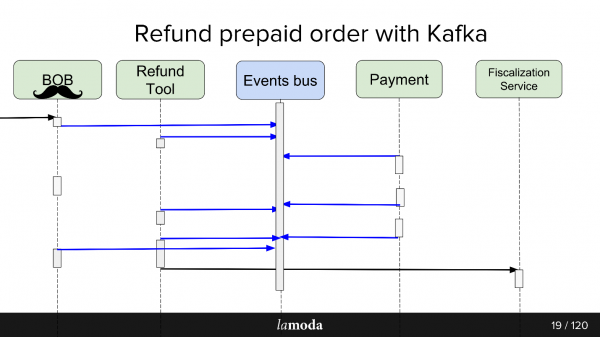
Les avantages et les inconvénients sont assez évidents. Nous avons fabriqué un bus, ce qui signifie que désormais tous les services en dépendent. Cela simplifie la conception, mais introduit un point de défaillance unique dans le système. Kafka va planter, le processus s'arrêtera.
Qu'est-ce qu'une API basée sur les événements
Une bonne réponse à cette question se trouve dans le rapport de Martin Fowler (GOTO 2017) .
En bref ce que nous avons fait :
- Concluez tous les échanges asynchrones via stockage d'événements. Au lieu d'informer tous les consommateurs intéressés d'un changement de statut sur le réseau, nous écrivons un événement sur un changement de statut vers un stockage centralisé, et les consommateurs intéressés par le sujet lisent tout ce qui apparaît à partir de là.
- L'événement dans ce cas est une notification (Notifications) que quelque chose a changé quelque part. Par exemple, le statut de la commande a changé. Un consommateur intéressé par certaines données accompagnant le changement de statut et non incluses dans la notification peut connaître lui-même son statut.
- L'option maximale est le sourcing d'événements à part entière, transfert d'état, auquel cas contient toutes les informations nécessaires au traitement : d'où elles proviennent et quel statut elles sont passées, comment exactement les données ont changé, etc. La seule question est la faisabilité et la quantité d'informations que vous pouvez vous permettre de stocker.
Dans le cadre du lancement du Refund Tool, nous avons utilisé la troisième option. Ce traitement des événements simplifié puisqu'il n'était pas nécessaire d'extraire des informations détaillées, et a également éliminé le scénario dans lequel chaque nouvel événement génère une explosion de demandes de clarification de la part des consommateurs.
Service d'outil de remboursement pas chargé, donc Kafka est plus un avant-goût de la plume qu'une nécessité. Je ne pense pas que si le service de remboursement devenait un projet à forte charge, les entreprises seraient contentes.
Échange asynchrone TEL QUEL
Pour les échanges asynchrones, le département PHP utilise généralement RabbitMQ. Nous avons collecté les données de la demande, les avons mises dans une file d'attente, et le consommateur du même service les a lues et envoyées (ou ne les a pas envoyées). Pour l'API elle-même, Lamoda utilise activement Swagger. Nous concevons une API, la décrivons dans Swagger et générons du code client et serveur. Nous utilisons également un JSON RPC 2.0 légèrement amélioré.
Dans certains endroits, des bus ESB sont utilisés, certains vivent sur activeMQ, mais, en général, RabbitMQ - standard.
Échange asynchrone À ÊTRE
Lors de la conception d'un échange via un bus d'événements, une analogie peut être tracée. De la même manière, nous décrivons les échanges de données futurs à travers des descriptions de structures d'événements. Au format yaml, nous avons dû faire la génération de code nous-mêmes, le générateur crée des DTO selon les spécifications et apprend aux clients et aux serveurs à travailler avec eux. La génération passe en deux langues - golang et php. Cela permet de maintenir la cohérence des bibliothèques. Le générateur est écrit en golang, c'est pourquoi il porte le nom de gogi.
Le sourcing d'événements sur Kafka est une chose typique. Il existe une solution de la version entreprise principale de Kafka Confluent, il y a , une solution de nos frères de domaine Zalando. Notre motivation pour commencer avec la vanille Kafka - cela signifie laisser la solution libre jusqu'à ce que nous décidions enfin si nous l'utiliserons partout, et aussi nous laisser des marges de manœuvre et d'amélioration : nous voulons un accompagnement pour notre JSONRPC 2.0, générateurs pour deux langues et voyons quoi d'autre.
Il est ironique que même dans un cas aussi heureux, alors qu’il existe une entreprise à peu près similaire, Zalando, qui a élaboré une solution à peu près similaire, nous ne pouvons pas l’utiliser efficacement.
Le modèle architectural au lancement est le suivant : nous lisons directement depuis Kafka, mais écrivons uniquement via le bus d'événements. Il y a beaucoup de choses prêtes à lire dans Kafka : des courtiers, des équilibreurs, et c'est plus ou moins prêt pour une mise à l'échelle horizontale, je voulais garder ça. Nous voulions terminer l’enregistrement via une seule passerelle, également appelée Events-bus, et voici pourquoi.
Bus événementiel
Ou un bus événementiel. Il s'agit simplement d'une passerelle http sans état, qui assume plusieurs rôles importants :
- Produire la validation — nous vérifions que les événements répondent à notre cahier des charges.
- Système maître d'événements, c'est-à-dire qu'il s'agit du système principal et unique de l'entreprise qui répond à la question de savoir quels événements avec quelles structures sont considérés comme valables. La validation implique simplement des types de données et des énumérations pour spécifier strictement le contenu.
- Fonction de hachage pour le partitionnement - la structure du message Kafka est clé-valeur et en utilisant le hachage de la clé, il est calculé où la placer.
Pourquoi
Nous travaillons dans une grande entreprise avec un processus rationalisé. Pourquoi changer quoi que ce soit ? Ceci est une expérience, et nous espérons en récolter plusieurs avantages.
Echanges 1:n+1 (un à plusieurs)
Kafka facilite la connexion de nouveaux consommateurs à l'API.
Disons que vous disposez d'un répertoire que vous devez tenir à jour dans plusieurs systèmes à la fois (et dans certains nouveaux). Auparavant, nous avions inventé un bundle qui implémentait set-API, et le système maître était informé des adresses des consommateurs. Désormais, le système maître envoie des mises à jour sur le sujet et toutes les personnes intéressées le lisent. Un nouveau système est apparu - nous l'avons inscrit sur le sujet. Oui, également en bundle, mais en plus simple.
Dans le cas de l'outil de remboursement, qui est un élément de BOB, il est pratique pour nous de les synchroniser via Kafka. Le paiement indique que l'argent a été restitué : BOB, RT l'ont découvert, ont changé leur statut, le Service de Fiscalisation l'a découvert et a émis un chèque.
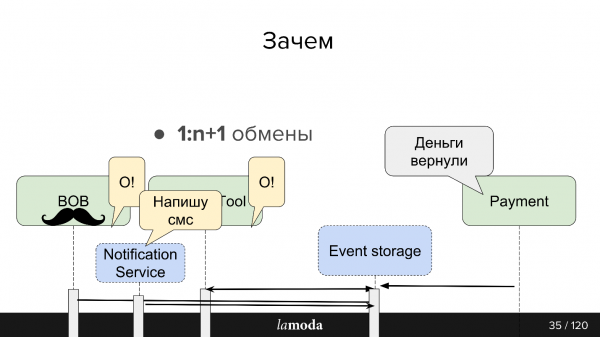
Nous prévoyons de créer un service de notifications unifié qui informerait le client des nouvelles concernant sa commande/son retour. Désormais, cette responsabilité est répartie entre les systèmes. Il nous suffira d'apprendre au service de notifications à récupérer les informations pertinentes de Kafka et à y répondre (et à désactiver ces notifications dans d'autres systèmes). Aucun nouvel échange direct ne sera requis.
Axée sur les données:
Les informations entre les systèmes deviennent transparentes, quelle que soit votre « entreprise sanglante » et quel que soit l'ampleur de votre retard. Lamoda dispose d'un département Data Analytics qui collecte les données des systèmes et les met sous une forme réutilisable, à la fois pour les entreprises et pour les systèmes intelligents. Kafka vous permet de leur fournir rapidement un grand nombre de données et de maintenir ce flux d'informations à jour.
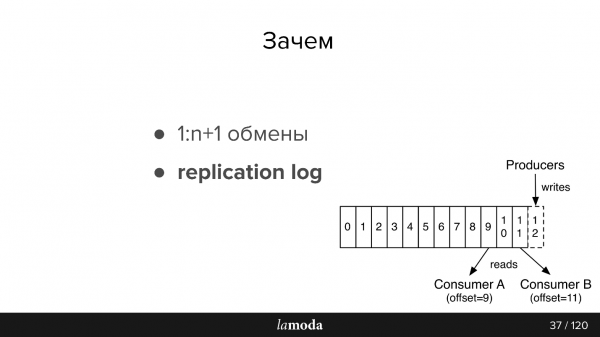
Journal de réplication
Les messages ne disparaissent pas après avoir été lus, comme dans RabbitMQ. Lorsqu'un événement contient suffisamment d'informations pour le traitement, nous disposons d'un historique des modifications récentes apportées à l'objet et, si nous le souhaitons, de la possibilité d'appliquer ces modifications.
La période de stockage du journal de réplication dépend de l'intensité de l'écriture sur ce sujet ; Kafka vous permet de définir de manière flexible des limites sur la durée de stockage et le volume de données. Pour les sujets intensifs, il est important que tous les consommateurs aient le temps de lire les informations avant qu'elles ne disparaissent, même en cas d'inopérabilité de courte durée. Il est généralement possible de stocker des données pour unités de jours, ce qui est largement suffisant pour le support.
Ensuite, un petit récit de la documentation, pour ceux qui ne connaissent pas Kafka (la photo est également issue de la documentation)
AMQP a des files d'attente : nous écrivons des messages dans une file d'attente pour le consommateur. En règle générale, une file d'attente est traitée par un système avec la même logique métier. Si vous devez notifier plusieurs systèmes, vous pouvez apprendre à l'application à écrire dans plusieurs files d'attente ou configurer l'échange avec le mécanisme de diffusion, qui les clone lui-même.
Kafka a une abstraction similaire sujet, dans lequel vous écrivez des messages, mais ils ne disparaissent pas après la lecture. Par défaut, lorsque vous vous connectez à Kafka, vous recevez tous les messages et avez la possibilité de les enregistrer là où vous vous êtes arrêté. Autrement dit, vous lisez séquentiellement, vous ne pouvez pas marquer le message comme lu, mais enregistrer l'identifiant à partir duquel vous pourrez ensuite continuer la lecture. L'identifiant que vous avez choisi est appelé offset et le mécanisme est commit offset.
En conséquence, une logique différente peut être mise en œuvre. Par exemple, nous avons BOB dans 4 instances pour différents pays - Lamoda est en Russie, au Kazakhstan, en Ukraine et en Biélorussie. Puisqu’ils sont déployés séparément, ils ont des configurations légèrement différentes et leur propre logique métier. Nous indiquons dans le message à quel pays il fait référence. Chaque consommateur BOB dans chaque pays lit avec un groupId différent, et si le message ne s'applique pas à lui, il l'ignore, c'est-à-dire engage immédiatement le décalage +1. Si le même sujet est lu par notre service de paiement, il le fait avec un groupe distinct et les compensations ne se croisent donc pas.
Exigences de l'événement :
- Complétude des données. J'aimerais que l'événement contienne suffisamment de données pour pouvoir être traité.
- Intégrité Nous déléguons à Events-bus la vérification de la cohérence de l'événement et il peut le traiter.
- L'ordre est important. En cas de retour, nous sommes obligés de travailler avec l’histoire. Avec les notifications, la commande n'a pas d'importance, s'il s'agit de notifications homogènes, l'email sera le même quelle que soit la commande arrivée en premier. Dans le cas d'un remboursement, il existe un processus clair : si nous modifions la commande, des exceptions surviendront, le remboursement ne sera ni créé ni traité - nous nous retrouverons dans un statut différent.
- Cohérence. Nous avons un magasin et maintenant nous créons des événements au lieu d'une API. Nous avons besoin d’un moyen de transmettre à nos services rapidement et à moindre coût des informations sur les nouveaux événements et les modifications apportées aux événements existants. Ceci est réalisé grâce à une spécification commune dans un référentiel git distinct et des générateurs de code. Par conséquent, les clients et les serveurs des différents services sont coordonnés.
Kafka à Lamoda
Nous disposons de trois installations Kafka :
- Journaux ;
- R&D;
- Bus événementiel.
Aujourd'hui, nous ne parlons que du dernier point. Chez events-bus, nous n'avons pas de très grandes installations - 3 courtiers (serveurs) et seulement 27 sujets. En règle générale, un sujet est un processus. Mais c’est un point subtil, et nous y reviendrons maintenant.
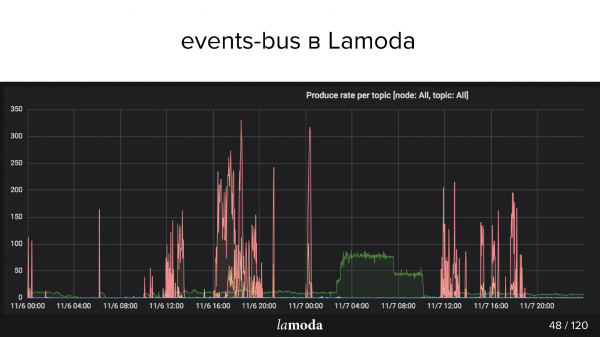
Ci-dessus, le graphique rps. Le processus de remboursement est marqué d'une ligne turquoise (oui, celle sur l'axe X), et la ligne rose est le processus de mise à jour du contenu.
Le catalogue Lamoda contient des millions de produits et les données sont mises à jour en permanence. Certaines collections se démodent, de nouvelles viennent les remplacer et de nouveaux modèles apparaissent constamment dans le catalogue. Nous essayons de prédire ce qui intéressera nos clients demain, c'est pourquoi nous achetons constamment de nouvelles choses, les photographions et mettons à jour la vitrine.
Les pics roses sont des mises à jour de produits, c'est-à-dire des modifications apportées aux produits. On voit que les gars ont pris des photos, pris des photos, et puis encore ! — chargé un pack d'événements.
Cas d'utilisation des événements Lamoda
Nous utilisons l'architecture construite pour les opérations suivantes :
- Suivi de l'état du retour: appel à l'action et suivi du statut de tous les systèmes impliqués. Paiement, statuts, fiscalisation, notifications. Ici, nous avons testé l'approche, créé des outils, collecté tous les bugs, rédigé de la documentation et expliqué à nos collègues comment l'utiliser.
- Mise à jour des fiches produits : configuration, métadonnées, caractéristiques. Un système lit (qui affiche) et plusieurs écrivent.
- Email, push et sms: la commande a été récupérée, la commande est arrivée, le retour a été accepté, etc., ils sont nombreux.
- Renouvellement des stocks, entrepôts — mise à jour quantitative des articles, juste des chiffres : arrivée à l'entrepôt, retour. Il est nécessaire que tous les systèmes associés à la réservation de marchandises fonctionnent avec les données les plus récentes. Actuellement, le système de mise à jour des stocks est assez complexe ; Kafka va le simplifier.
- Historique (Département R&D), outils ML, analyses, statistiques. Nous voulons que les informations soient transparentes – Kafka est bien adapté pour cela.
Passons maintenant à la partie la plus intéressante concernant les gros obstacles et les découvertes intéressantes qui ont eu lieu au cours des six derniers mois.
Les problèmes de conception
Disons que nous voulons faire quelque chose de nouveau - par exemple, transférer l'intégralité du processus de livraison vers Kafka. Désormais, une partie du processus est implémentée dans le traitement des commandes dans BOB. Il existe un modèle de statut derrière le transfert d'une commande vers le service de livraison, le déplacement vers un entrepôt intermédiaire, etc. Il existe tout un monolithe, voire deux, plus un tas d'API dédiées à la livraison. Ils en savent beaucoup plus sur la livraison.
Ces domaines semblent être similaires, mais le traitement des commandes dans BOB et le système d'expédition ont des statuts différents. Par exemple, certains services de messagerie n'envoient pas les statuts intermédiaires, mais uniquement les statuts finaux : « livré » ou « perdu ». D'autres, au contraire, rendent compte de manière très détaillée du mouvement des marchandises. Chacun a ses propres règles de validation : pour certains, l’email est valide, ce qui signifie qu’il sera traité ; pour d'autres, ce n'est pas valable, mais la commande sera quand même traitée car il existe un numéro de téléphone pour contacter, et quelqu'un dira qu'une telle commande ne sera pas traitée du tout.
Flux de données
Dans le cas de Kafka, la question de l’organisation du flux de données se pose. Cette tâche consiste à choisir une stratégie basée sur plusieurs points ; passons-les tous en revue.
Dans un sujet ou dans différents ?
Nous avons une spécification d'événement. Chez BOB nous écrivons que telle ou telle commande doit être livrée, et indiquons : le numéro de commande, sa composition, quelques SKU et codes barres, etc. Lorsque les marchandises arriveront à l'entrepôt, la livraison pourra recevoir des statuts, des horodatages et tout ce qui est nécessaire. Mais nous souhaitons ensuite recevoir des mises à jour sur ces données dans BOB. Nous avons un processus inverse de réception des données dès la livraison. Est-ce le même événement ? Ou s'agit-il d'un échange distinct qui mérite son propre sujet ?
Très probablement, ils seront très similaires, et la tentation de créer un seul sujet n'est pas sans fondement, car un sujet distinct signifie des consommateurs distincts, des configurations distinctes, une génération distincte de tout cela. Mais ce n’est pas un fait.
Nouveau domaine ou nouvel événement ?
Mais si vous utilisez les mêmes événements, un autre problème se pose. Par exemple, tous les systèmes de livraison ne peuvent pas générer le type de DTO que BOB peut générer. Nous leur envoyons l'identifiant, mais ils ne l'enregistrent pas car ils n'en ont pas besoin, et du point de vue du démarrage du processus de bus d'événements, ce champ est obligatoire.
Si nous introduisons une règle pour le bus d'événements selon laquelle ce champ est obligatoire, nous sommes alors obligés de définir des règles de validation supplémentaires dans le BOB ou dans le gestionnaire d'événements de démarrage. La validation commence à se répandre dans tout le service - ce n'est pas très pratique.
Un autre problème est la tentation d’un développement progressif. On nous dit qu'il faut ajouter quelque chose à l'événement et peut-être, si nous y réfléchissons, cela aurait dû être un événement à part. Mais dans notre schéma, un événement distinct est un sujet distinct. Un sujet distinct est l'ensemble du processus que j'ai décrit ci-dessus. Le développeur est tenté d’ajouter simplement un autre champ au schéma JSON et de le régénérer.
Dans le cas des remboursements, nous sommes arrivés à l'événement en six mois. Nous avons eu un méta-événement appelé mise à jour du remboursement, qui comportait un champ de type décrivant ce qu'était réellement cette mise à jour. Pour cette raison, nous avons eu de « merveilleux » échanges avec des validateurs qui nous ont expliqué comment valider cet événement avec ce type.
Gestion des versions d'événements
Pour valider les messages dans Kafka, vous pouvez utiliser , mais il fallait immédiatement s'y mettre et utiliser Confluent. Dans notre cas, nous devons faire attention au versioning. Il ne sera pas toujours possible de relire les messages du journal de réplication car le modèle est « parti ». Fondamentalement, il s'avère construire des versions pour que le modèle soit rétrocompatible : par exemple, rendre un champ temporairement facultatif. Si les différences sont trop fortes, nous commençons à écrire dans un nouveau sujet et transférons les clients lorsqu'ils ont fini de lire l'ancien.
Ordre de lecture garanti des partitions
Les sujets dans Kafka sont divisés en partitions. Ce n’est pas très important lorsque nous concevons des entités et des échanges, mais c’est important lorsque nous décidons comment les consommer et les faire évoluer.
Dans le cas habituel, vous écrivez un sujet dans Kafka. Par défaut, une partition est utilisée et tous les messages de cette rubrique y sont dirigés. Et le consommateur lit donc ces messages de manière séquentielle. Disons que nous devons maintenant étendre le système pour que les messages soient lus par deux consommateurs différents. Si, par exemple, vous envoyez des SMS, vous pouvez demander à Kafka de créer une partition supplémentaire, et Kafka commencera à diviser les messages en deux parties - la moitié ici, la moitié ici.
Comment Kafka les divise-t-il ? Chaque message a un corps (dans lequel nous stockons JSON) et une clé. Vous pouvez attacher une fonction de hachage à cette clé, qui déterminera dans quelle partition le message ira.
Dans notre cas des remboursements, c'est important, si nous prenons deux partitions, alors il y a une chance qu'un consommateur parallèle traite le deuxième événement avant le premier et il y aura des problèmes. La fonction de hachage garantit que les messages avec la même clé se retrouvent dans la même partition.
Événements vs commandes
C'est un autre problème que nous avons rencontré. Un événement est un certain événement : nous disons que quelque chose s'est produit quelque part (something_happened), par exemple, un article a été annulé ou un remboursement a eu lieu. Si quelqu'un écoute ces événements, alors en fonction de « article annulé », l'entité de remboursement sera créée et « le remboursement a eu lieu » sera écrit quelque part dans les configurations.
Mais généralement, lorsque vous concevez des événements, vous ne voulez pas les écrire en vain : vous comptez sur le fait que quelqu'un les lira. Il y a une forte tentation d'écrire non pas quelque chose_happened (item_canceled, remboursé_refunded), mais quelque chose_should_be_done. Par exemple, l'article est prêt à être retourné.
D’une part, cela suggère comment l’événement sera utilisé. D’un autre côté, cela ressemble beaucoup moins à un nom d’événement normal. De plus, la commande do_something n'est pas loin d'ici. Mais vous n’avez aucune garantie que quelqu’un lise cet événement ; et si vous le lisez, alors vous le lisez avec succès ; et si vous l’avez lu avec succès, alors vous avez fait quelque chose, et cette chose a réussi. Dès qu’un événement devient do_something, le feedback devient nécessaire, et c’est un problème.

Dans un échange asynchrone dans RabbitMQ, lorsque vous lisez le message, allez sur http, vous avez une réponse - au moins que le message a été reçu. Lorsque vous écrivez à Kafka, il y a un message que vous avez écrit à Kafka, mais vous ne savez rien de la façon dont il a été traité.
Par conséquent, dans notre cas, nous avons dû introduire un événement de réponse et mettre en place une surveillance pour que si autant d'événements étaient envoyés, après tel ou tel temps, le même nombre d'événements de réponse arrive. Si cela ne se produit pas, il semble que quelque chose ne va pas. Par exemple, si nous avons envoyé l'événement « item_ready_to_refund », nous nous attendons à ce qu'un remboursement soit créé, l'argent sera restitué au client et l'événement « money_refunded » nous sera envoyé. Mais ce n’est pas certain et une surveillance est donc nécessaire.
Nuances
Il y a un problème assez évident : si vous lisez un sujet de manière séquentielle et que vous avez un mauvais message, le consommateur tombera et vous n'irez pas plus loin. Vous avez besoin arrêter tous les consommateurs, validez davantage le décalage pour continuer la lecture.
Nous le savions, nous comptions dessus, et pourtant c'est arrivé. Et cela s'est produit parce que l'événement était valide du point de vue du bus d'événements, l'événement était valide du point de vue du validateur d'application, mais il n'était pas valide du point de vue de PostgreSQL, car dans notre seul système MySQL avec UNSIGNED INT, et dans la nouvelle version, le système avait PostgreSQL uniquement avec INT. Sa taille est un peu plus petite et la carte d'identité ne lui convenait pas. Symfony est mort à une exception près. Bien sûr, nous avons détecté l'exception parce que nous comptions sur elle et allions valider ce décalage, mais avant cela, nous voulions incrémenter le compteur de problèmes, car le message n'a pas été traité sans succès. Les compteurs de ce projet sont également dans la base de données, et Symfony a déjà fermé la communication avec la base de données, et la deuxième exception a tué l'ensemble du processus sans possibilité de valider le décalage.
Le service s'est arrêté pendant un certain temps - heureusement, avec Kafka, ce n'est pas si grave, car les messages restent. Une fois les travaux restaurés, vous pourrez terminer leur lecture. C'est confortable.
Kafka a la capacité de définir un décalage arbitraire via des outils. Mais pour ce faire, vous devez arrêter tous les consommateurs - dans notre cas, préparer une version séparée dans laquelle il n'y aura ni consommateurs ni redéploiements. Ensuite, dans Kafka, vous pouvez déplacer le décalage via l'outillage et le message sera transmis.
Une autre nuance - journal de réplication vs rdkafka.so - est lié aux spécificités de notre projet. Nous utilisons PHP, et en PHP, en règle générale, toutes les bibliothèques communiquent avec Kafka via le référentiel rdkafka.so, puis il existe une sorte de wrapper. Il s'agit peut-être de nos difficultés personnelles, mais il s'est avéré que relire simplement un morceau de ce que nous avions déjà lu n'est pas si facile. En général, il y avait des problèmes logiciels.
Revenant aux spécificités du travail avec les partitions, c'est écrit directement dans la documentation consommateurs >= partitions de sujet. Mais je l’ai découvert bien plus tard que je ne l’aurais souhaité. Si vous souhaitez évoluer et avoir deux consommateurs, vous avez besoin d'au moins deux partitions. Autrement dit, si vous aviez une partition dans laquelle 20 XNUMX messages se sont accumulés et que vous en avez créé une nouvelle, le nombre de messages ne sera pas égalisé de sitôt. Par conséquent, pour avoir deux consommateurs parallèles, vous devez gérer les partitions.
Surveillance
Je pense que la façon dont nous suivrons la situation permettra de mieux identifier les problèmes liés à l'approche actuelle.
Par exemple, nous calculons combien de produits dans la base de données ont récemment changé de statut et, par conséquent, des événements auraient dû se produire sur la base de ces changements, et nous envoyons ce numéro à notre système de surveillance. Ensuite, Kafka nous donne le deuxième chiffre, combien d’événements ont été réellement enregistrés. Évidemment, la différence entre ces deux nombres doit toujours être nulle.
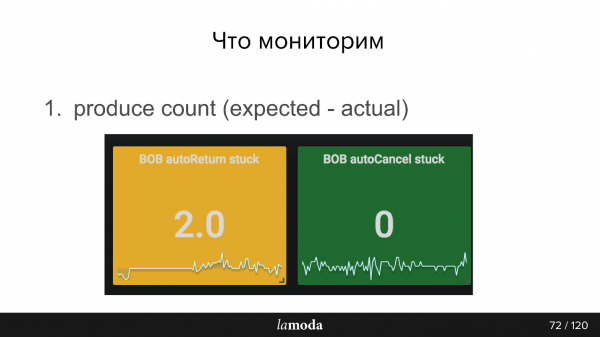
De plus, vous devez surveiller les performances du producteur, si le bus d'événements a reçu des messages et les performances du consommateur. Par exemple, dans les graphiques ci-dessous, Refund Tool se porte bien, mais BOB a clairement quelques problèmes (pics bleus).
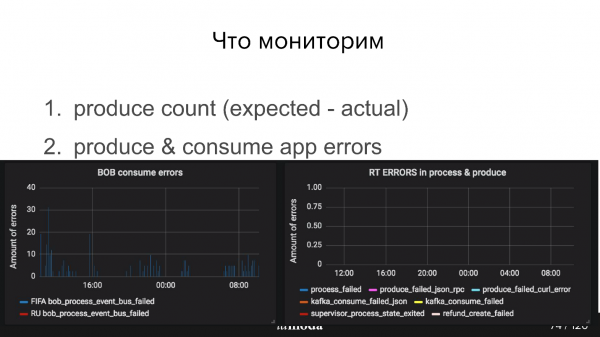
J'ai déjà mentionné le décalage entre les groupes de consommateurs. En gros, il s'agit du nombre de messages non lus. En général, nos consommateurs travaillent rapidement, le décalage est donc généralement de 0, mais il peut parfois y avoir un pic à court terme. Kafka peut le faire immédiatement, mais vous devez définir un certain intervalle.
Il y a un projet qui vous donnera plus d'informations sur Kafka. Il utilise simplement l'API du groupe de consommateurs pour indiquer l'état d'avancement de ce groupe. En plus de OK et Failed, il y a un avertissement et vous pouvez découvrir que vos consommateurs ne peuvent pas faire face au rythme de production - ils n'ont pas le temps de relire ce qui est écrit. Le système est assez intelligent et facile à utiliser.
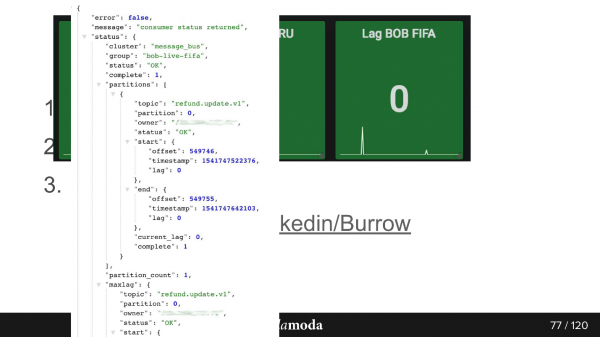
Voici à quoi ressemble la réponse de l'API. Voici le groupe bob-live-fifa, partition remboursé.update.v1, statut OK, décalage 0 - le dernier décalage final tel ou tel.
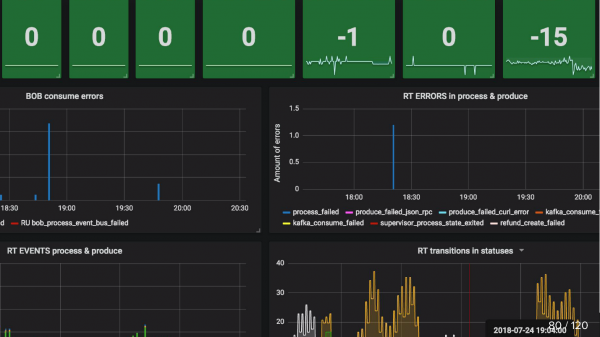
Surveillance update_at SLA (bloqué) Je l'ai déjà mentionné. Par exemple, le produit est passé au statut prêt à être retourné. Nous installons Cron, qui dit que si dans 5 minutes cet objet n'a pas été remboursé (nous restituons l'argent via les systèmes de paiement très rapidement), alors quelque chose s'est définitivement mal passé, et c'est définitivement un cas de support. Par conséquent, nous prenons simplement Cron, qui lit de telles choses, et si elles sont supérieures à 0, alors il envoie une alerte.
Pour résumer, l'utilisation d'événements est pratique lorsque:
- les informations sont nécessaires à plusieurs systèmes ;
- le résultat du traitement n'est pas important ;
- il y a peu d'événements ou de petits événements.
Il semblerait que l'article ait un sujet très spécifique - l'API asynchrone sur Kafka, mais à ce sujet, je voudrais recommander beaucoup de choses à la fois.
D'abord, ensuite nous devons attendre novembre, en avril il y aura une version à Saint-Pétersbourg et en juin nous parlerons des charges élevées à Novossibirsk.
Deuxièmement, l'auteur du rapport, Sergei Zaika, est membre du comité de programme de notre nouvelle conférence sur la gestion des connaissances. . La conférence dure une journée, elle aura lieu le 26 avril, mais son programme est très intense.
Et ce sera en mai и (avec DevOpsConf inclus) - vous pouvez également y suggérer votre sujet, parler de votre expérience et vous plaindre de vos cônes bourrés.
Source: habr.com
