

Je vous suggère de lire la transcription du rapport de Vladimir Sitnikov début 2016 « PostgreSQL et JDBC extraient tout le jus »


Bon après-midi Je m'appelle Vladimir Sitnikov. Je travaille pour NetCracker depuis 10 ans. Et je suis surtout intéressé par la productivité. Tout ce qui touche à Java, tout ce qui touche à SQL, c'est ce que j'aime.
Et aujourd'hui, je vais parler de ce que nous avons rencontré dans l'entreprise lorsque nous avons commencé à utiliser PostgreSQL comme serveur de base de données. Et nous travaillons principalement avec Java. Mais ce que je vais vous dire aujourd’hui ne concerne pas seulement Java. Comme l'a montré la pratique, cela se produit également dans d'autres langues.

Nous parlerons:
- sur l'échantillonnage des données.
- À propos de la sauvegarde des données.
- Et aussi sur les performances.
- Et à propos des râteaux sous-marins qui y sont enterrés.

Commençons par une question simple. Nous sélectionnons une ligne du tableau en fonction de la clé primaire.

La base de données est située sur le même hôte. Et tout ce farm prend 20 millisecondes.

Ces 20 millisecondes, c'est beaucoup. Si vous avez 100 requêtes de ce type, alors vous passez du temps par seconde à faire défiler ces requêtes, c'est-à-dire nous perdons du temps.
Nous n’aimons pas faire ça et regardons ce que la base nous propose pour cela. La base de données nous offre deux options pour exécuter des requêtes.

La première option est une simple demande. Qu'est-ce qu'il y a de bien là-dedans ? Le fait que nous le prenons et l’envoyons, et rien de plus.

La base de données dispose également d'une requête avancée, plus délicate, mais plus fonctionnelle. Vous pouvez envoyer séparément une demande d'analyse, d'exécution, de liaison de variable, etc.
La requête super étendue est quelque chose que nous ne couvrirons pas dans le rapport actuel. Nous voulons peut-être quelque chose de la base de données et il y a une liste de souhaits qui a été formée sous une forme ou une autre, c'est-à-dire c'est ce que nous voulons, mais c'est impossible maintenant et l'année prochaine. Alors on vient de l’enregistrer et on va faire tourner les principaux personnages.

Et ce que nous pouvons faire, c'est une requête simple et une requête étendue.
Quelle est la particularité de chaque approche ?
Une requête simple convient pour une exécution unique. Une fois fait et oublié. Et le problème est qu’il ne prend pas en charge le format de données binaire, c’est-à-dire qu’il ne convient pas à certains systèmes hautes performances.

Requête étendue – vous permet de gagner du temps sur l'analyse. C'est ce que nous avons fait et avons commencé à utiliser. Cela nous a vraiment, vraiment aidé. Il n'y a pas que des économies sur l'analyse. Il y a des économies sur le transfert de données. Le transfert de données au format binaire est beaucoup plus efficace.

Passons à la pratique. Voilà à quoi ressemble une application typique. Cela pourrait être Java, etc.
Nous avons créé une déclaration. Exécuté la commande. Créé à proximité. Où est l'erreur ici ? Quel est le problème? Aucun problème. C'est ce qui est dit dans tous les livres. C’est ainsi qu’il faut l’écrire. Si vous voulez des performances maximales, écrivez comme ceci.

Mais la pratique a montré que cela ne fonctionne pas. Pourquoi? Parce que nous avons une méthode « proche ». Et lorsque nous faisons cela, du point de vue de la base de données, il s’avère que c’est comme un fumeur travaillant avec une base de données. Nous avons dit "PARSE EXECUTE DEALLOCATE".
Pourquoi toute cette création et ce déchargement supplémentaires d'instructions ? Personne n’en a besoin. Mais ce qui se passe généralement dans PreparedStatements, c'est que lorsque nous les fermons, ils ferment tout ce qui se trouve dans la base de données. Ce n'est pas ce que nous voulons.

Nous voulons, comme les personnes en bonne santé, travailler avec la base. Nous avons pris et préparé notre déclaration une fois, puis nous l'avons exécutée plusieurs fois. En fait, plusieurs fois - c'est une fois dans toute la vie des applications - elles ont été analysées. Et nous utilisons le même identifiant d'instruction sur différents REST. C'est notre objectif.

Comment pouvons-nous y parvenir?

C'est très simple : pas besoin de fermer les instructions. Nous l'écrivons ainsi : « préparer » « exécuter ».


Si nous lançons quelque chose comme ça, alors il est clair que quelque chose va déborder quelque part. Si ce n'est pas clair, vous pouvez l'essayer. Écrivons un benchmark qui utilise cette méthode simple. Créez une déclaration. Nous le lançons sur une version du pilote et constatons qu'il plante assez rapidement avec la perte de toute la mémoire dont il disposait.
Il est clair que de telles erreurs sont faciles à corriger. Je n'en parlerai pas. Mais je dirai que la nouvelle version fonctionne beaucoup plus rapidement. La méthode est stupide, mais quand même.

Comment travailler correctement ? Que devons-nous faire pour cela ?
En réalité, les applications ferment toujours les instructions. Dans tous les livres, ils disent de le fermer, sinon la mémoire fuira.
Et PostgreSQL ne sait pas comment mettre en cache les requêtes. Il faut que chaque session crée ce cache pour elle-même.
Et nous ne voulons pas non plus perdre de temps en analyse.

Et comme d'habitude, nous avons deux options.
La première option est de prendre cela et de dire que nous enveloppons tout dans PgSQL. Il y a une cache là-bas. Il met tout en cache. Cela s'avérera génial. Nous avons vu cela. Nous avons 100500 XNUMX demandes. Ne marche pas. Nous n’acceptons pas de transformer manuellement les demandes en procédures. Non non.
Nous avons une deuxième option : prenez-le et coupez-le nous-mêmes. Nous ouvrons les sources et commençons à couper. Nous avons vu et vu. Il s'est avéré que ce n'est pas si difficile à faire.

Celui-ci est apparu en août 2015. Il existe désormais une version plus moderne. Et tout est génial. Cela fonctionne tellement bien qu’on ne change rien dans l’application. Et nous avons même arrêté de penser en direction de PgSQL, c'est-à-dire cela nous suffisait amplement pour réduire tous les frais généraux à presque zéro.
En conséquence, les instructions préparées par le serveur sont activées à la 5ème exécution afin d'éviter de gaspiller de la mémoire dans la base de données à chaque requête unique.

Vous vous demandez peut-être : où sont les chiffres ? Qu'obtenez-vous ? Et ici je ne donnerai pas de chiffres, car chaque demande a le sien.
Nos requêtes étaient telles que nous avons passé environ 20 millisecondes à analyser les requêtes OLTP. Il y avait 0,5 millisecondes pour l'exécution, 20 millisecondes pour l'analyse. Requête – 10 Ko de texte, 170 lignes de plan. Il s'agit d'une requête OLTP. Il demande 1, 5, 10 lignes, parfois plus.
Mais nous ne voulions pas du tout perdre 20 millisecondes. Nous l'avons réduit à 0. Tout est très bien.
Que pouvez-vous retenir d’ici ? Si vous avez Java, prenez la version moderne du pilote et réjouissez-vous.
Si vous parlez une langue différente, réfléchissez : peut-être en avez-vous aussi besoin ? Car du point de vue du langage final, par exemple, si PL 8 ou si vous avez LibPQ, alors il n'est pas évident pour vous que vous perdiez du temps non pas sur l'exécution, sur l'analyse, et cela mérite d'être vérifié. Comment? Tout est gratuit.
Sauf qu’il y a des erreurs et quelques particularités. Et nous en parlerons maintenant. La majeure partie portera sur l'archéologie industrielle, sur ce que nous avons trouvé, sur ce que nous avons découvert.

Si la demande est générée dynamiquement. Ça arrive. Quelqu'un colle les chaînes ensemble, ce qui génère une requête SQL.
Pourquoi est-il mauvais ? C'est dommage car à chaque fois on se retrouve avec une chaîne différente.
Et le hashCode de cette chaîne différente doit être relu. Il s'agit en réalité d'une tâche du processeur : trouver un long texte de requête, même dans un hachage existant, n'est pas si simple. Par conséquent, la conclusion est simple : ne générez pas de demandes. Stockez-les dans une variable. Et réjouissez-vous.

Prochain problème. Les types de données sont importants. Il existe des ORM qui disent que peu importe le type de NULL existant, qu'il y en ait un. Si Int, alors nous disons setInt. Et si NULL, alors que ce soit toujours VARCHAR. Et quelle différence cela fait-il au final, qu'y ait-il NULL ? La base de données elle-même comprendra tout. Et cette image ne fonctionne pas.
En pratique, la base de données s'en fiche du tout. Si vous avez dit la première fois qu'il s'agit d'un nombre, et la deuxième fois que vous avez dit qu'il s'agit d'un VARCHAR, alors il est impossible de réutiliser les instructions préparées par le serveur. Et dans ce cas, nous devons recréer notre déclaration.

Si vous exécutez la même requête, assurez-vous que les types de données de votre colonne ne sont pas confondus. Vous devez faire attention à NULL. Il s'agit d'une erreur courante que nous avons rencontrée après avoir commencé à utiliser PreparedStatements.

D'accord, allumé. Peut-être qu'ils ont pris le chauffeur. Et la productivité a chuté. Les choses ont mal tourné.
Comment cela peut-il arriver? Est-ce un bug ou une fonctionnalité? Malheureusement, il n'a pas été possible de comprendre s'il s'agissait d'un bug ou d'une fonctionnalité. Mais il existe un scénario très simple pour reproduire ce problème. Elle nous a tendu une embuscade de manière complètement inattendue. Et cela consiste à échantillonner littéralement à partir d’une seule table. Bien entendu, nous avons eu davantage de demandes de ce type. En règle générale, ils comprenaient deux ou trois tables, mais il existe un tel scénario de lecture. Prenez n’importe quelle version de votre base de données et jouez-la.

Le fait est que nous avons deux colonnes, chacune étant indexée. Il y a un million de lignes dans une colonne NULL. Et la deuxième colonne ne contient que 20 lignes. Lorsque nous exécutons sans variables liées, tout fonctionne bien.
Si nous commençons à exécuter avec des variables liées, c'est-à-dire que nous exécutons le "?" ou « 1 $ » pour notre demande, qu'obtenons-nous finalement ?
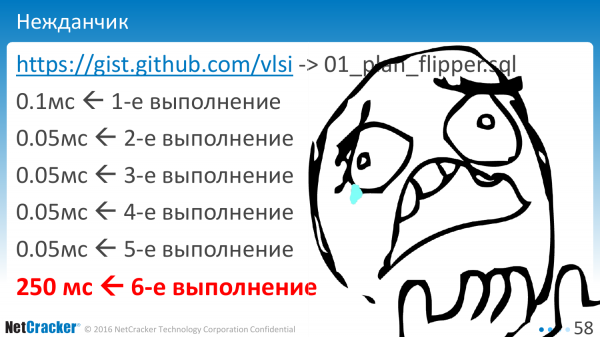
La première exécution est comme prévu. Le second est un peu plus rapide. Quelque chose a été mis en cache. Troisième, quatrième, cinquième. Puis bang - et quelque chose comme ça. Et le pire, c'est que cela se produit à la sixième exécution. Qui savait qu’il était nécessaire de procéder exactement à six exécutions pour comprendre quel était le véritable plan d’exécution ?

Qui est coupable ? Ce qui s'est passé? La base de données contient une optimisation. Et il semble optimisé pour le cas générique. Et, en conséquence, à partir d’un moment donné, elle passe à un plan générique, qui, malheureusement, peut s’avérer différent. Cela peut s'avérer être le même, ou cela peut être différent. Et il existe une sorte de valeur seuil qui conduit à ce comportement.
Que peux-tu y faire? Ici, bien entendu, il est plus difficile de présumer quoi que ce soit. Il existe une solution simple que nous utilisons. C'est +0, OFFSET 0. Vous connaissez sûrement de telles solutions. Nous le prenons simplement et ajoutons « +0 » à la demande et tout va bien. Je te montrerai plus tard.
Et il existe une autre option : examinez les plans plus attentivement. Le développeur doit non seulement rédiger une demande, mais aussi dire « expliquer analyser » 6 fois. Si c'est 5, ça ne marchera pas.
Et il existe une troisième option : écrire une lettre aux pirates de pgsql. J'ai écrit, cependant, il n'est pas encore clair s'il s'agit d'un bug ou d'une fonctionnalité.

Pendant que nous nous demandons s’il s’agit d’un bug ou d’une fonctionnalité, corrigeons-le. Prenons notre demande et ajoutons "+0". Tout va bien. Deux symboles et vous n’avez même pas besoin de penser à ce que c’est ou à ce que c’est. Très simple. Nous avons simplement interdit à la base de données d'utiliser un index sur cette colonne. Nous n’avons pas d’index sur la colonne « +0 » et c’est tout, la base de données n’utilise pas l’index, tout va bien.

C'est la règle de 6, expliquez-vous. Désormais, dans les versions actuelles, vous devez le faire 6 fois si vous avez des variables liées. Si vous n'avez pas de variables liées, c'est ce que nous faisons. Et finalement, c’est précisément cette demande qui échoue. Ce n'est pas une chose délicate.
Il semblerait, combien est-il possible ? Un bug ici, un bug là. En fait, le bug est partout.

Regardons de plus près. Par exemple, nous avons deux schémas. Schéma A avec tableau S et schéma B avec tableau S. Requête – sélectionnez des données dans une table. Qu'aurons-nous dans ce cas ? Nous aurons une erreur. Nous aurons tout ce qui précède. La règle est la suivante : un bug est partout, nous aurons tout ce qui précède.

Maintenant la question est : « Pourquoi ? » Il semblerait qu'il existe une documentation selon laquelle si nous avons un schéma, alors il existe une variable "search_path" qui nous indique où chercher la table. Il semblerait qu'il existe une variable.
Quel est le problème? Le problème est que les instructions préparées par le serveur ne soupçonnent pas que search_path peut être modifié par quelqu'un. Cette valeur reste en quelque sorte constante pour la base de données. Et certaines parties peuvent ne pas acquérir de nouvelles significations.

Bien entendu, cela dépend de la version sur laquelle vous testez. Cela dépend de la gravité de la différence entre vos tables. Et la version 9.1 exécutera simplement les anciennes requêtes. Les nouvelles versions peuvent détecter le bug et vous informer que vous avez un bug.

Comment le traiter ? Il existe une recette simple : ne la faites pas. Il n'est pas nécessaire de modifier search_path pendant l'exécution de l'application. Si vous changez, il est préférable de créer une nouvelle connexion.
Vous pouvez discuter, c'est-à-dire ouvrir, discuter, ajouter. Peut-être pouvons-nous convaincre les développeurs de bases de données que lorsque quelqu'un modifie une valeur, la base de données devrait en informer le client : « Écoutez, votre valeur a été mise à jour ici. Peut-être avez-vous besoin de réinitialiser les déclarations et de les recréer ? » Désormais, la base de données se comporte secrètement et ne signale en aucune manière que les instructions ont changé quelque part à l'intérieur.
Et j'insiste encore une fois : c'est quelque chose qui n'est pas typique de Java. Nous verrons la même chose en PL/pgSQL un à un. Mais il y sera reproduit.

Essayons une sélection supplémentaire de données. Nous choisissons et choisissons. Nous avons une table avec un million de lignes. Chaque ligne fait un kilo-octet. Environ un gigaoctet de données. Et nous avons une mémoire de travail dans la machine Java de 128 mégaoctets.
Comme recommandé dans tous les livres, nous utilisons le traitement de flux. Autrement dit, nous ouvrons resultSet et lisons les données à partir de là petit à petit. Est-ce que ça marchera? Est-ce que cela tombera de la mémoire ? Veux-tu lire un peu ? Faisons confiance à la base de données, faisons confiance à Postgres. Nous n'y croyons pas. Allons-nous tomber en OutOFMemory ? Qui a connu OutOfMemory ? Qui a réussi à le réparer après ça ? Quelqu'un a réussi à le réparer.
Si vous avez un million de lignes, vous ne pouvez pas simplement choisir. OFFSET/LIMIT est requis. Qui est pour cette option ? Et qui est favorable à jouer avec autoCommit ?
Ici, comme d'habitude, l'option la plus inattendue s'avère correcte. Et si vous désactivez soudainement autoCommit, cela vous aidera. Pourquoi donc? La science n’en sait rien.

Mais par défaut, tous les clients se connectant à une base de données Postgres récupèrent l'intégralité des données. PgJDBC ne fait pas exception à cet égard : il sélectionne toutes les lignes.
Il existe une variante du thème FetchSize, c'est-à-dire que vous pouvez dire au niveau d'une instruction distincte qu'ici, veuillez sélectionner les données par 10, 50. Mais cela ne fonctionne pas tant que vous n'avez pas désactivé autoCommit. AutoCommit désactivé - il commence à fonctionner.
Mais parcourir le code et définir setFetchSize partout n'est pas pratique. Par conséquent, nous avons défini un paramètre qui indiquera la valeur par défaut pour l'ensemble de la connexion.
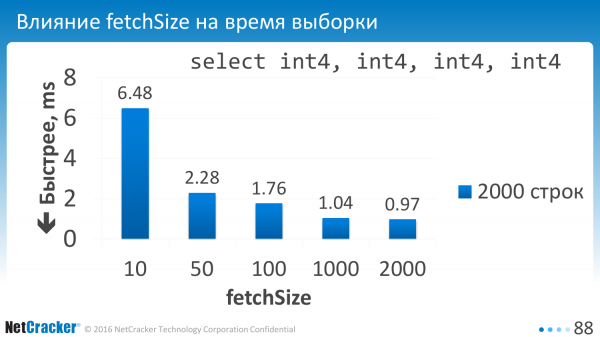
C'est ce que nous avons dit. Le paramètre a été configuré. Et qu’avons-nous obtenu ? Si nous sélectionnons de petits montants, si, par exemple, nous sélectionnons 10 lignes à la fois, nous avons alors des frais généraux très importants. Par conséquent, cette valeur doit être fixée à environ une centaine.
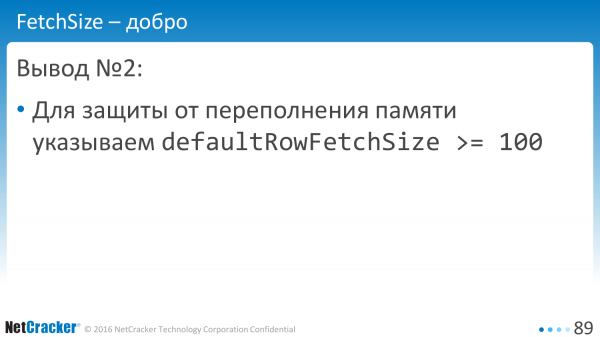
Idéalement, bien sûr, vous devez encore apprendre à le limiter en octets, mais la recette est la suivante : définissez defaultRowFetchSize sur plus de cent et soyez heureux.

Passons à l'insertion de données. L'insertion est plus facile, il existe différentes options. Par exemple, INSÉRER, VALEURS. C'est une bonne option. Vous pouvez dire « INSERT SELECT ». En pratique, c'est la même chose. Il n'y a aucune différence de performances.
Les livres disent que vous devez exécuter une instruction Batch, les livres disent que vous pouvez exécuter des commandes plus complexes avec plusieurs parenthèses. Et Postgres a une fonctionnalité merveilleuse : vous pouvez faire COPY, c'est-à-dire le faire plus rapidement.

Si vous le mesurez, vous pourrez à nouveau faire des découvertes intéressantes. Comment voulons-nous que cela fonctionne ? Nous ne voulons pas analyser ni exécuter de commandes inutiles.
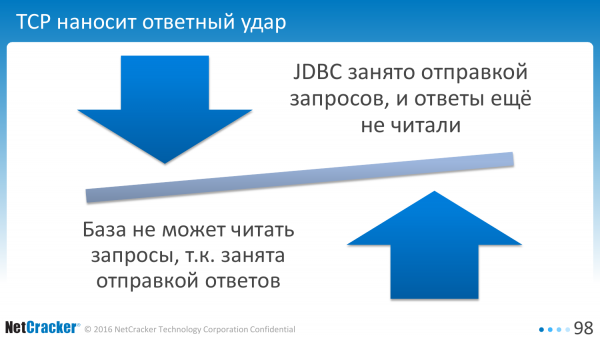
En pratique, TCP ne nous permet pas de faire cela. Si le client est occupé à envoyer une requête, la base de données ne lit pas les requêtes pour tenter de nous envoyer des réponses. Le résultat final est que le client attend que la base de données lise la demande et que la base de données attend que le client lise la réponse.

Et donc le client est obligé d'envoyer périodiquement un paquet de synchronisation. Interactions réseau supplémentaires, perte de temps supplémentaire.
 Et plus on en ajoute, plus la situation empire. Le conducteur est assez pessimiste et les ajoute assez souvent, environ une fois toutes les 200 lignes, selon la taille des lignes, etc.
Et plus on en ajoute, plus la situation empire. Le conducteur est assez pessimiste et les ajoute assez souvent, environ une fois toutes les 200 lignes, selon la taille des lignes, etc.
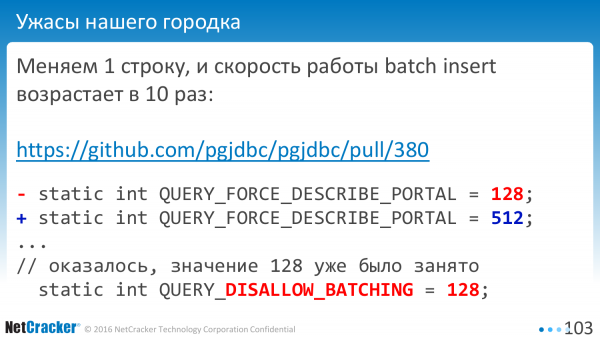
Il arrive que vous corrigiez une seule ligne et que tout s'accélère 10 fois. Ça arrive. Pourquoi? Comme d'habitude, une constante comme celle-ci a déjà été utilisée quelque part. Et la valeur « 128 » signifiait ne pas utiliser le traitement par lots.

C'est bien que cela ne soit pas inclus dans la version officielle. Découvert avant le début de la sortie. Toutes les significations que je donne sont basées sur des versions modernes.

Essayons-le. Nous mesurons InsertBatch simple. Nous mesurons InsertBatch plusieurs fois, c'est-à-dire la même chose, mais il existe de nombreuses valeurs. Déplacement délicat. Tout le monde ne peut pas faire cela, mais c’est une démarche si simple, bien plus facile que COPIER.

Vous pouvez faire COPIER.

Et vous pouvez le faire sur des structures. Déclarez le type par défaut de l'utilisateur, transmettez le tableau et INSERT directement dans la table.
Si vous ouvrez le lien : pgjdbc/ubenchmsrk/InsertBatch.java, alors ce code est sur GitHub. Vous pouvez voir spécifiquement quelles demandes y sont générées. Cela n'a pas d'importance.
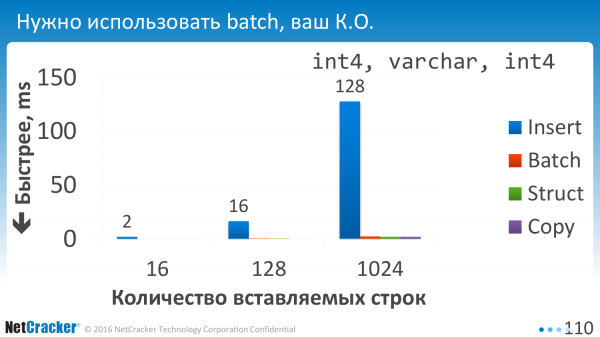
Nous avons lancé. Et la première chose que nous avons réalisé, c’est que ne pas utiliser le batch est tout simplement impossible. Toutes les options de batching sont nulles, c'est-à-dire que le temps d'exécution est pratiquement nul par rapport à une exécution unique.
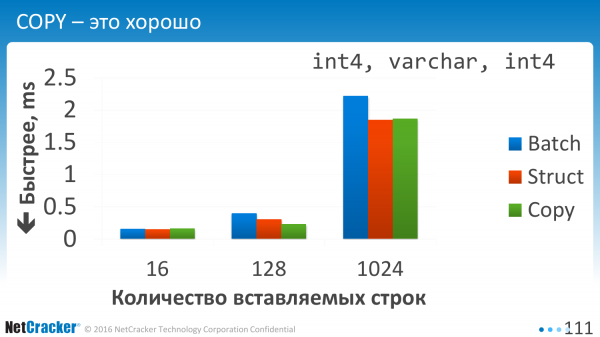
Nous insérons des données. C'est un tableau très simple. Trois colonnes. Et que voit-on ici ? Nous constatons que ces trois options sont à peu près comparables. Et COPIER est, bien sûr, meilleur.
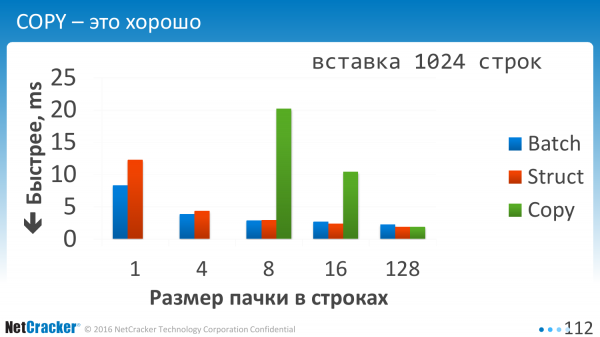
C'est à ce moment-là que nous insérons des pièces. Quand nous avons dit qu'une valeur VALEURS, deux valeurs VALEURS, trois valeurs VALEURS, ou nous en avons indiqué 10 séparées par une virgule. C'est juste horizontal maintenant. 1, 2, 4, 128. On peut voir que l'encart de lot, dessiné en bleu, lui permet de se sentir beaucoup mieux. Autrement dit, lorsque vous en insérez un à la fois ou même lorsque vous en insérez quatre à la fois, cela devient deux fois mieux, simplement parce que nous avons mis un peu plus de VALEURS. Moins d’opérations EXECUTE.
Utiliser COPY sur de petits volumes est extrêmement peu prometteur. Je n'ai même pas dessiné les deux premiers. Ils vont au paradis, c'est-à-dire ces nombres verts pour COPIER.
COPY doit être utilisé lorsque vous disposez d'au moins une centaine de lignes de données. La surcharge liée à l’ouverture de cette connexion est importante. Et pour être honnête, je n’ai pas creusé dans cette direction. J'ai optimisé Batch, mais pas COPY.
Que faisons-nous ensuite? Nous l'avons essayé. Nous comprenons qu'il faut utiliser soit des structures, soit un bain astucieux qui combine plusieurs significations.

Que devriez-vous retenir du rapport d’aujourd’hui ?
- PreparedStatement est notre tout. Cela donne beaucoup pour la productivité. Cela produit un gros échec dans la pommade.
- Et vous devez faire EXPLIQUER ANALYSER 6 fois.
- Et nous devons diluer OFFSET 0 et des astuces comme +0 afin de corriger le pourcentage restant de nos requêtes problématiques.
Source: habr.com
