

style de code DevOps Ansible
Hé! Mon nom est Je travaille en tant qu'ingénieur dans le département d'automatisation des processus de développement. Chaque jour, de nouvelles versions d'applications sont déployées sur des centaines de serveurs de campagne. Et dans cet article, je partage mon expérience d'utilisation d'Ansible à ces fins.
Ce guide propose un moyen d'organiser les variables dans un déploiement. Ce guide est conçu pour ceux qui utilisent déjà des rôles dans leurs playbooks et lisent mais je rencontre des problèmes similaires :
- Après avoir trouvé une variable dans le code, il est impossible de comprendre immédiatement de quoi elle est responsable ;
- Il existe plusieurs rôles et les variables doivent être associées à une seule valeur, mais cela ne fonctionne pas ;
- Avoir des difficultés à expliquer aux autres comment fonctionne la logique des variables de vos playbooks
Nous avons rencontré ces problèmes sur des projets dans notre entreprise, à la suite de quoi nous sommes parvenus aux règles de formatage des variables dans nos playbooks, ce qui a dans une certaine mesure résolu ces problèmes.

Variables dans les rôles
Un rôle est un objet système de déploiement distinct. Comme tout objet du système, il doit disposer d’une interface pour interagir avec le reste du système. Les variables de rôle sont une telle interface.
Prenons par exemple le rôle api, qui installe une application Java sur le serveur. Quelles variables a-t-il ?
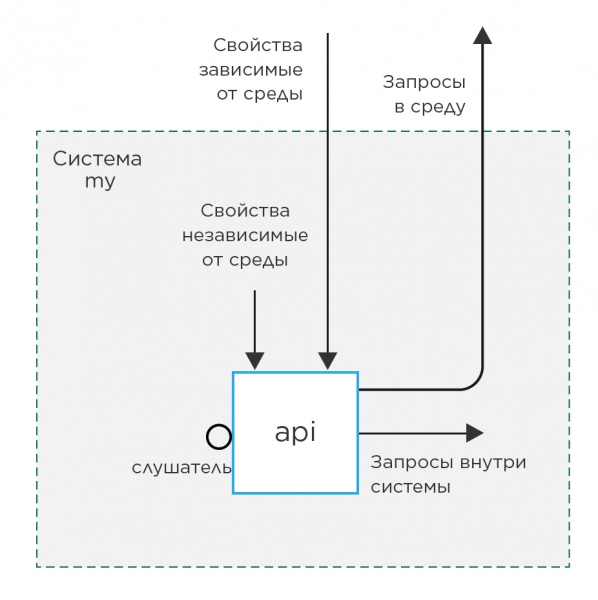
Les variables de rôle peuvent être divisées en 2 types par type :
1. Свойства
a) независимые от среды
б) зависимые от среды
2. Связи
a) слушатели
б) запросы внутри системы
в) запросы в среду
Propriétés variables sont des variables qui définissent le comportement d'un rôle.
Variables de requête sont des variables dont la valeur permet de désigner des ressources externes au rôle.
Écouteurs variables sont des variables dont la valeur est utilisée pour former des variables de requête.
En revanche, 1a, 2a, 2b sont des variables qui ne dépendent pas de l'environnement (fer, ressources externes, etc.) et peuvent être renseignées avec des valeurs par défaut dans le rôle defaults. Cependant, les variables comme 1.b et 2.c ne peuvent pas être remplies avec des valeurs autres que « exemple », car elles changeront d'un stand à l'autre en fonction de l'environnement.
Style de code
- Le nom de la variable doit commencer par le nom du rôle. Cela permettra de déterminer facilement à l'avenir de quel rôle est la variable et de quoi elle est responsable.
- Lors de l'utilisation de variables dans des rôles, vous devez vous assurer de suivre le principe d'encapsulation et d'utiliser des variables définies soit dans le rôle lui-même, soit dans les rôles dont dépend le rôle actuel.
Évitez d'utiliser des dictionnaires pour les variables. Ansible ne vous permet pas de remplacer facilement des valeurs individuelles dans un dictionnaire.
Un exemple de mauvaise variable :
myrole_user: login: admin password: adminIci, la connexion est la variable médiane et le mot de passe est la variable dépendante. Mais
puisqu'ils sont regroupés dans un dictionnaire, vous devrez le préciser au complet
Toujours. Ce qui est très gênant. Mieux vaut ainsi :myrole_user_login: admin myrole_user_password: admin
Variables dans les playbooks de déploiement
Lors de la compilation d'un playbook de déploiement (ci-après dénommé playbook), nous adhérons à la règle selon laquelle il doit être placé dans un référentiel séparé. Tout comme les rôles : chacun dans son propre référentiel git. Cela vous permet de réaliser que les rôles et le playbook sont des objets indépendants différents du système de déploiement et que les modifications apportées à un objet ne doivent pas affecter le fonctionnement de l'autre. Ceci est réalisé en modifiant les valeurs par défaut des variables.
Lors de la compilation d'un playbook, pour résumer, il est possible de remplacer les valeurs par défaut des variables de rôle à deux endroits : dans les variables du playbook et dans les variables d'inventaire.
mydeploy # Каталог деплоя
├── deploy.yml # Плейбук деплоя
├── group_vars # Каталог переменных плейбука
│ ├── all.yml # Файл для переменных связи всей системы
│ └── myapi.yml # Файл переменных свойств группы myapi
└── inventories #
└── prod # Каталог окружения prod
├── prod.ini # Инвентори файл
└── group_vars # Каталог для переменных инвентори
└── myapi #
├── vars.yml # Средозависимые переменные группы myapi
└── vault.yml # Секреты (всегда средозависимы) ** -
La différence est que les variables du playbook sont toujours utilisées lors de l'appel de playbooks situés au même niveau que celui-ci. Cela signifie que ces variables sont idéales pour modifier les valeurs par défaut des variables qui ne dépendent pas de l'environnement. A l’inverse, les variables d’inventaire ne seront utilisées que pour un environnement particulier, ce qui est idéal pour les variables spécifiques à l’environnement.
Il est important de noter que la priorité des variables ne vous permettra pas de redéfinir les variables d'abord dans les variables du playbook, puis séparément dans le même inventaire.
Cela signifie que dès ce stade, vous devez décider si la variable dépend ou non de l'environnement et la placer au bon endroit.
Par exemple, dans un projet, la variable responsable de l'activation de SSL a longtemps dépendu de l'environnement, car nous ne pouvions pas activer SSL pour des raisons indépendantes de notre volonté sur l'un des stands. Après avoir résolu ce problème, il est devenu indépendant du support et a été déplacé vers les variables du playbook.
Variables de propriété pour les groupes
Développons notre modèle dans la figure 1 en ajoutant 2 groupes de serveurs avec une application Java différente, mais avec des paramètres différents.
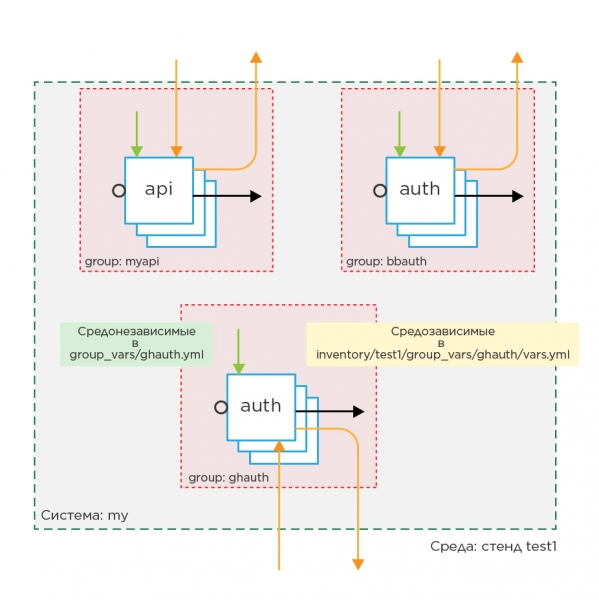
Imaginez à quoi ressemblera le playbook dans ce cas :
- hosts: myapi
roles:
- api
- hosts: bbauth
roles:
- auth
- hosts: ghauth
roles:
- authNous avons trois groupes dans le playbook, il est donc recommandé de créer autant de fichiers de groupe dans les variables d'inventaire group_vars et les variables du playbook à la fois. Dans ce cas, un fichier de groupe est la description d'un composant de votre application dans le playbook. Lorsque vous ouvrez le fichier de groupe dans les variables du playbook, vous voyez immédiatement toutes les différences par rapport au comportement par défaut des rôles attribués au groupe. Dans les variables d'inventaire : différences de comportement des groupes d'un stand à l'autre.
Style de code
- Essayez de ne pas utiliser du tout les variables host_vars, car elles ne décrivent pas le système, mais seulement un cas particulier, ce qui à long terme soulèvera des questions : « Pourquoi cet hôte est-il différent des autres ? », dont la réponse est pas toujours facile à trouver.
Lier des variables
Cependant, il s'agit de variables de propriété, mais qu'en est-il des variables de lien ?
Leur différence est qu’ils doivent avoir la même valeur dans différents groupes.
Au début il y avait utiliser une construction monstrueuse de la forme :
hostvars[groups['bbauth'][0]]['auth_bind_port'], mais il a été immédiatement abandonné
parce qu'il a des défauts. Tout d’abord, l’encombrement. Deuxièmement, la dépendance à l'égard d'un hôte spécifique du groupe. Troisièmement, il est nécessaire de collecter des faits sur tous les hôtes avant de démarrer le déploiement, si nous ne voulons pas obtenir une erreur de variable non définie.
En conséquence, il a été décidé d'utiliser des variables de lien.
Lier des variables sont des variables qui appartiennent au playbook et sont nécessaires pour lier les objets système.
Les variables de lien sont renseignées dans les variables système générales group_vars/all/vars et sont formés en supprimant toutes les variables d'écoute de chaque groupe et en ajoutant le nom du groupe dont l'écouteur a été supprimé au début de la variable.
Ainsi, l'uniformité et la non-intersection des noms sont assurées.
Essayons de lier les variables de l'exemple ci-dessus :
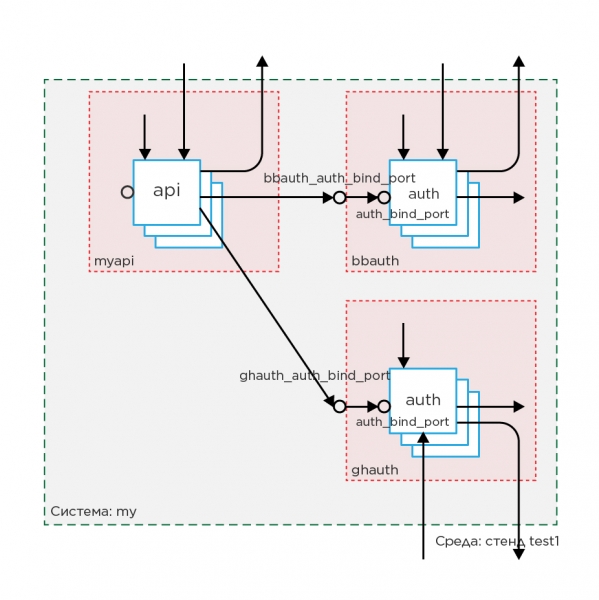
Imaginez que nous ayons des variables qui dépendent les unes des autres :
# roles/api/defaults:
# Переменная запроса
api_auth1_address: "http://example.com:80"
api_auth2_address: "http://example2.com:80"
# roles/auth/defaults:
# Переменная слушатель
auth_bind_port: "20000"Mettons-le dans des variables communes group_vars/all/vars tous les auditeurs, et ajoutez le nom du groupe au nom :
# group_vars/all/vars
bbauth_auth_bind_port: "20000"
ghauth_auth_bind_port: "30000"
# group_vars/bbauth/vars
auth_bind_port: "{{ bbauth_auth_bind_port }}"
# group_vars/ghauth/vars
auth_bind_port: "{{ ghauth_auth_bind_port }}"
# group_vars/myapi/vars
api_auth1_address: "http://{{ bbauth_auth_service_name }}:{{ bbauth_auth_bind_port }}"
api_auth2_address: "http://{{ ghauth_auth_service_name }}:{{ ghauth_auth_bind_port }}"Désormais, en modifiant la valeur du connecteur, nous serons sûrs que la requête ira vers le même port.
Style de code
- Étant donné que les rôles et les groupes sont des objets système différents, ils doivent avoir des noms différents afin que les variables de lien indiquent avec précision qu'elles appartiennent à un groupe de serveurs spécifique et non à un rôle dans le système.
Fichiers d'environnement
Les rôles peuvent utiliser des fichiers qui diffèrent d'un environnement à l'autre.
Les certificats SSL sont un exemple de tels fichiers. Stockez-les sous forme de texte
dans une variable n'est pas très pratique. Mais il est pratique de stocker leur chemin dans une variable.
Par exemple, nous utilisons la variable api_ssl_key_file: "/path/to/file".
Puisqu'il est évident que le certificat de clé changera d'un environnement à l'autre, il s'agit d'une variable dépendante de l'environnement, ce qui signifie qu'elle doit être située dans le fichier
group_vars/myapi/vars inventaire des variables, et contient la valeur 'par exemple'.
Le moyen le plus pratique dans ce cas est de placer le fichier clé dans le référentiel du playbook le long du chemin
files/prod/certs/myapi.key, alors la valeur de la variable sera :
api_ssl_key_file: "prod/certs/myapi.key". L'avantage réside dans le fait que les personnes chargées du déploiement du système sur un stand particulier disposent également de leur propre emplacement dédié dans le référentiel pour stocker leurs fichiers. Parallèlement, il reste possible de préciser le chemin absolu du certificat sur le serveur, au cas où les certificats seraient fournis par un autre système.
Plusieurs stands dans un seul environnement
Il est souvent nécessaire de déployer plusieurs stands presque identiques dans le même environnement avec des différences minimes. Dans ce cas, nous divisons les variables dépendantes de l’environnement entre celles qui ne changent pas dans cet environnement et celles qui changent. Et nous retirons ces derniers directement dans les fichiers d'inventaire eux-mêmes. Après cette manipulation, il devient possible de créer un autre inventaire directement dans le répertoire de l'environnement.
Il réutilisera l'inventaire group_vars et pourra également redéfinir certaines variables directement pour lui-même.
La structure de répertoires finale pour le projet de déploiement :
mydeploy # Каталог деплоя
├── deploy.yml # Плейбук деплоя
├── files # Каталог для файлов деплоя
│ ├── prod # Католог для средозависимых файлов стенда prod
│ │ └── certs #
│ │ └── myapi.key #
│ └── test1 # Каталог для средозависимых файлов стенда test1
├── group_vars # Каталог переменных плейбука
│ ├── all.yml # Файл для переменных связи всей системы
│ ├── myapi.yml # Файл переменных свойств группы myapi
│ ├── bbauth.yml #
│ └── ghauth.yml #
└── inventories #
├── prod # Каталог окружения prod
│ ├── group_vars # Каталог для переменных инвентори
│ │ ├── myapi #
│ │ │ ├── vars.yml # Средозависимые переменные группы myapi
│ │ │ └── vault.yml # Секреты (всегда средозависимы)
│ │ ├── bbauth #
│ │ │ ├── vars.yml #
│ │ │ └── vault.yml #
│ │ └── ghauth #
│ │ ├── vars.yml #
│ │ └── vault.yml #
│ └── prod.ini # Инвентори стенда prod
└── test # Каталог окружения test
├── group_vars #
│ ├── myapi #
│ │ ├── vars.yml #
│ │ └── vault.yml #
│ ├── bbauth #
│ │ ├── vars.yml #
│ │ └── vault.yml #
│ └── ghauth #
│ ├── vars.yml #
│ └── vault.yml #
├── test1.ini # Инвентори стенда test1 в среде test
└── test2.ini # Инвентори стенда test2 в среде testRésumé
Après avoir organisé les variables conformément à l'article : chaque fichier contenant des variables est responsable d'une tâche spécifique. Et comme le dossier comporte certaines tâches, il est devenu possible de désigner une personne responsable de l'exactitude de chaque dossier. Par exemple, le développeur du déploiement du système devient responsable du remplissage correct des variables du playbook, tandis que l'administrateur, dont le stand est décrit dans l'inventaire, est directement responsable du remplissage de l'inventaire des variables.
Les rôles sont devenus une unité de développement autonome avec leur propre interface, permettant au développeur de rôles de développer des fonctionnalités plutôt que d'adapter le rôle au système. Ce problème était particulièrement vrai pour les rôles communs à tous les systèmes d'une campagne.
Les administrateurs système n'ont plus besoin de comprendre le code de déploiement. Tout ce qui leur est demandé pour un déploiement réussi est de remplir les fichiers de variables d'environnement.
littérature
auteur
Kaloujny Denis Alexandrovitch
Source: habr.com
