


Malgré le fait qu'il y a maintenant beaucoup de données presque partout, les bases de données analytiques sont encore assez exotiques. Ils sont mal connus et encore moins capables de les utiliser efficacement. Beaucoup continuent à "manger du cactus" avec MySQL ou PostgreSQL, qui sont conçus pour d'autres scénarios, souffrent avec NoSQL ou surpayent pour des solutions commerciales. ClickHouse change les règles du jeu et abaisse considérablement le seuil d'entrée dans le monde des SGBD analytiques.
Rapport de BackEnd Conf 2018 et il est publié avec la permission de l'orateur.


Qui suis-je et pourquoi parle-t-on de ClickHouse ? Je suis directeur du développement chez LifeStreet, qui utilise ClickHouse. Aussi, je suis le fondateur d'Altinity. C'est un partenaire de Yandex qui promeut ClickHouse et aide Yandex à rendre ClickHouse plus efficace. Également prêt à partager des connaissances sur ClickHouse.

Et je ne suis pas le frère de Petya Zaitsev. Je suis souvent interrogé à ce sujet. Non, nous ne sommes pas frères.

"Tout le monde sait" que ClickHouse :
- Très vite,
- Très confortable
- Utilisé dans Yandex.
On en sait un peu moins dans quelles entreprises et comment il est utilisé.

Je vais vous dire pourquoi, où et comment ClickHouse est utilisé, à l'exception de Yandex.
Je vais vous expliquer comment des tâches spécifiques sont résolues à l'aide de ClickHouse dans différentes entreprises, quels outils ClickHouse vous pouvez utiliser pour vos tâches et comment ils ont été utilisés dans différentes entreprises.
J'ai pris trois exemples qui montrent ClickHouse sous différents angles. Je pense que ce sera intéressant.

La première question est : "Pourquoi avons-nous besoin de ClickHouse ?". Cela semble être une question assez évidente, mais il y a plus d'une réponse à cela.

- La première réponse concerne les performances. ClickHouse est très rapide. Analytics sur ClickHouse est également très rapide. Il peut souvent être utilisé là où quelque chose d'autre est très lent ou très mauvais.
- La deuxième réponse est le coût. Et tout d'abord, le coût de la mise à l'échelle. Par exemple, Vertica est une base de données absolument géniale. Cela fonctionne très bien si vous n'avez pas beaucoup de téraoctets de données. Mais lorsqu'il s'agit de centaines de téraoctets ou de pétaoctets, le coût d'une licence et de l'assistance représente un montant assez important. Et c'est cher. Et ClickHouse est gratuit.
- La troisième réponse est le coût d'exploitation. Il s'agit d'une approche légèrement différente. RedShift est un excellent analogue. Sur RedShift, vous pouvez prendre une décision très rapidement. Cela fonctionnera bien, mais en même temps, chaque heure, chaque jour et chaque mois, vous paierez très cher Amazon, car il s'agit d'un service très coûteux. Google BigQuery aussi. Si quelqu'un l'a utilisé, alors il sait que là, vous pouvez exécuter plusieurs demandes et obtenir une facture de centaines de dollars tout d'un coup.
ClickHouse n'a pas ces problèmes.

Où ClickHouse est-il utilisé maintenant ? En plus de Yandex, ClickHouse est utilisé dans un tas d'entreprises et d'entreprises différentes.
- Tout d'abord, il s'agit d'analyse d'applications Web, c'est-à-dire qu'il s'agit d'un cas d'utilisation provenant de Yandex.
- De nombreuses entreprises AdTech utilisent ClickHouse.
- De nombreuses entreprises qui ont besoin d'analyser les journaux de transactions provenant de différentes sources.
- Plusieurs entreprises utilisent ClickHouse pour surveiller les journaux de sécurité. Ils les téléchargent sur ClickHouse, font des rapports et obtiennent les résultats dont ils ont besoin.
- Les entreprises commencent à l'utiliser dans l'analyse financière, c'est-à-dire que progressivement les grandes entreprises se rapprochent également de ClickHouse.
- nuageux. Si quelqu'un suit ClickHouse, il a probablement entendu le nom de cette entreprise. C'est l'un des contributeurs essentiels de la communauté. Et ils ont une installation ClickHouse très sérieuse. Par exemple, ils ont créé Kafka Engine pour ClickHouse.
- Les entreprises de télécommunications ont commencé à utiliser. Plusieurs entreprises utilisent ClickHouse comme preuve de concept ou déjà en production.
- Une entreprise utilise ClickHouse pour surveiller les processus de production. Ils testent des microcircuits, annulent un tas de paramètres, il y a environ 2 000 caractéristiques. Et puis ils analysent si le jeu est bon ou mauvais.
- Analyse de la chaîne de blocs. Il existe une société russe telle que Bloxy.info. Ceci est une analyse du réseau Ethereum. Ils l'ont également fait sur ClickHouse.

Et la taille n'a pas d'importance. De nombreuses entreprises utilisent un seul petit serveur, et cela résout leurs problèmes. Et encore plus d'entreprises utilisent de grands clusters de plusieurs serveurs. les serveurs ou des dizaines de serveurs.
Et si vous regardez les enregistrements, alors :
- Yandex : plus de 500 serveurs, ils y stockent 25 milliards d'enregistrements par jour.
- LifeStreet : 60 serveurs, environ 75 milliards d'enregistrements par jour. Il y a moins de serveurs, plus d'enregistrements que dans Yandex.
- CloudFlare : 36 serveurs, ils sauvegardent 200 milliards d'enregistrements par jour. Ils ont encore moins de serveurs et stockent encore plus de données.
- Bloomberg : 102 serveurEnviron mille milliards de participations par jour. Détenteur du record du nombre de participations.
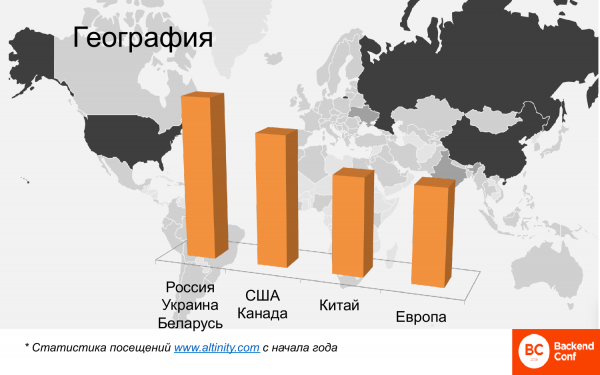
Géographiquement, c'est aussi beaucoup. Cette carte montre ici une carte thermique des endroits où ClickHouse est utilisé dans le monde. La Russie, la Chine, l'Amérique se distinguent clairement ici. Il y a peu de pays européens. Et il y a 4 clusters.
Il s'agit d'une analyse comparative, il n'est pas nécessaire de chercher des chiffres absolus. Il s'agit d'une analyse des visiteurs qui lisent des documents en anglais sur le site Web d'Altinity, car il n'y en a pas de russophones. Et la Russie, l'Ukraine, la Biélorussie, c'est-à-dire la partie russophone de la communauté, ce sont les utilisateurs les plus nombreux. Viennent ensuite les États-Unis et le Canada. La Chine est en train de rattraper son retard. Il n'y avait presque pas de Chine il y a six mois, maintenant la Chine a déjà dépassé l'Europe et continue de croître. La vieille Europe n'est pas loin non plus, et le leader de l'utilisation de ClickHouse est, curieusement, la France.

Pourquoi est-ce que je raconte tout ça ? Pour montrer que ClickHouse est en train de devenir une solution standard pour l'analyse de données volumineuses et qu'elle est déjà utilisée dans de nombreux endroits. Si vous l'utilisez, vous êtes dans la bonne tendance. Si vous ne l'utilisez pas encore, vous ne pouvez pas avoir peur d'être laissé seul et personne ne vous aidera, car beaucoup le font déjà.

Ce sont des exemples d'utilisation réelle de ClickHouse dans plusieurs entreprises.
- Le premier exemple est un réseau publicitaire : migration de Vertica vers ClickHouse. Et je connais quelques entreprises qui ont quitté Vertica ou sont en train de le faire.
- Le deuxième exemple est le stockage transactionnel sur ClickHouse. Ceci est un exemple construit sur des anti-modèles. Tout ce qui ne devrait pas être fait dans ClickHouse sur les conseils des développeurs est fait ici. Et c'est fait si efficacement que ça marche. Et cela fonctionne bien mieux que la solution transactionnelle typique.
- Le troisième exemple est l'informatique distribuée sur ClickHouse. Il y avait une question sur la façon dont ClickHouse peut être intégré dans l'écosystème Hadoop. Je vais montrer un exemple de la façon dont une entreprise a fait quelque chose de similaire à un conteneur de réduction de carte sur ClickHouse, en gardant une trace de la localisation des données, etc., pour calculer une tâche très non triviale.

- LifeStreet est une société Ad Tech qui possède toute la technologie fournie avec un réseau publicitaire.
- Elle est engagée dans l'optimisation des publicités, les enchères programmatiques.
- Beaucoup de données : environ 10 milliards d'événements par jour. Dans le même temps, les événements peuvent être divisés en plusieurs sous-événements.
- Il existe de nombreux clients de ces données, et ce ne sont pas seulement des personnes, bien plus encore - ce sont divers algorithmes qui sont engagés dans les enchères programmatiques.

L'entreprise a parcouru un chemin long et épineux. Et j'en ai parlé sur HighLoad. Tout d'abord, LifeStreet est passé de MySQL (avec un bref arrêt à Oracle) à Vertica. Et vous pouvez trouver une histoire à ce sujet.
Et tout était très bien, mais il est vite devenu évident que les données se multiplient et que Vertica coûte cher. Par conséquent, diverses alternatives ont été recherchées. Certains d'entre eux sont répertoriés ici. Et en fait, nous avons fait des preuves de concept ou parfois des tests de performance de presque toutes les bases de données qui étaient disponibles sur le marché de la 13e à la 16e année et qui étaient approximativement adaptées en termes de fonctionnalité. Et j'en ai aussi parlé sur HighLoad.

La tâche consistait en premier lieu à migrer depuis Vertica, car les données augmentaient. Et ils ont grandi de façon exponentielle au fil des ans. Ensuite, ils sont allés sur l'étagère, mais quand même. Et en prédisant cette croissance, les besoins de l'entreprise pour la quantité de données sur lesquelles une sorte d'analyse devait être effectuée, il était clair que les pétaoctets seraient bientôt discutés. Et payer pour des pétaoctets est déjà très cher, nous cherchions donc une alternative où aller.
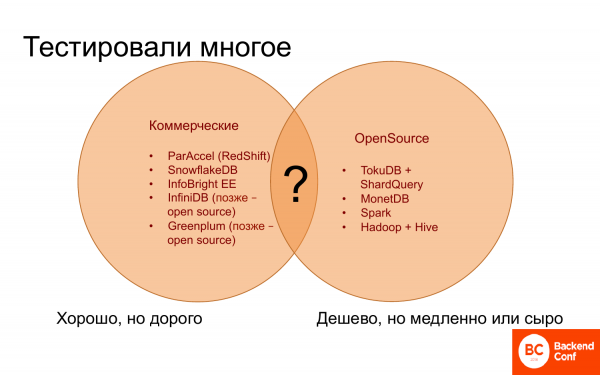
Où aller? Et pendant longtemps, on ne savait pas du tout où aller, car d'une part il y a des bases de données commerciales, elles semblent bien fonctionner. Certains fonctionnent presque aussi bien que Vertica, d'autres moins bien. Mais ils sont tous chers, rien de moins cher et de mieux n'a pu être trouvé.
En revanche, il existe des solutions open source, qui ne sont pas très nombreuses, c'est-à-dire pour l'analytics, ça se compte sur les doigts. Et ils sont gratuits ou bon marché, mais lents. Et ils manquent souvent des fonctionnalités nécessaires et utiles.
Et il n'y avait rien pour combiner le bien qu'il y a dans les bases de données commerciales et tout le gratuit qu'il y a dans l'open source.

Il n'y avait rien jusqu'à ce que, de manière inattendue, Yandex sorte ClickHouse, comme un magicien d'un chapeau, comme un lapin. Et c'était une décision inattendue, ils se posent encore la question: "Pourquoi?", Mais néanmoins.
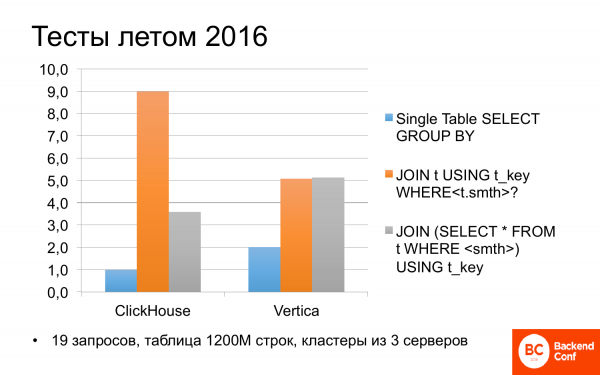
Et tout de suite à l'été 2016, nous avons commencé à regarder ce qu'est ClickHouse. Et il s'est avéré que parfois il peut être plus rapide que Vertica. Nous avons testé différents scénarios sur différentes requêtes. Et si la requête n'utilisait qu'une seule table, c'est-à-dire sans aucune jointure (jointure), alors ClickHouse était deux fois plus rapide que Vertica.
Je n'étais pas trop paresseux et j'ai regardé les tests Yandex l'autre jour. C'est pareil là-bas : ClickHouse est deux fois plus rapide que Vertica, donc ils en parlent souvent.
Mais s'il y a des jointures dans les requêtes, alors tout ne se passe pas très clairement. Et ClickHouse peut être deux fois plus lent que Vertica. Et si vous corrigez légèrement la demande et la réécrivez, elles sont à peu près égales. Pas mal. Et libre.

Et après avoir reçu les résultats du test, et en les regardant sous différents angles, LifeStreet est allé à ClickHouse.

C'est la 16e année, je vous le rappelle. C'était comme une blague sur les souris qui pleuraient et se piquaient, mais continuaient à manger le cactus. Et cela a été décrit en détail, il y a une vidéo à ce sujet, etc.

Par conséquent, je n'en parlerai pas en détail, je ne parlerai que des résultats et de quelques choses intéressantes dont je n'ai pas parlé à l'époque.
Les résultats sont :
- Migration réussie et plus d'un an que le système fonctionne déjà en production.
- La productivité et la flexibilité ont augmenté. Sur les 10 milliards d'enregistrements que nous pouvions nous permettre de stocker par jour, puis pendant une courte période, LifeStreet stocke désormais 75 milliards d'enregistrements par jour et peut le faire pendant 3 mois ou plus. Si vous comptez au maximum, cela représente jusqu'à un million d'événements par seconde. Plus d'un million de requêtes SQL arrivent chaque jour dans ce système, la plupart provenant de différents robots.
- Malgré le fait que plus de serveurs ont été utilisés pour ClickHouse que pour Vertica, ils ont également économisé sur le matériel, car des disques SAS plutôt coûteux ont été utilisés dans Vertica. ClickHouse a utilisé SATA. Et pourquoi? Parce que dans Vertica, l'insertion est synchrone. Et la synchronisation nécessite que les disques ne ralentissent pas trop, et aussi que le réseau ne ralentisse pas trop, c'est-à-dire une opération assez coûteuse. Et dans ClickHouse, l'insertion est asynchrone. De plus, vous pouvez toujours tout écrire localement, il n'y a pas de frais supplémentaires pour cela, de sorte que les données peuvent être insérées dans ClickHouse beaucoup plus rapidement que dans Vertika, même sur des disques plus lents. Et la lecture est à peu près la même. Lecture sur SATA, s'ils sont en RAID, alors tout cela est assez rapide.
- Non limité par la licence, c'est-à-dire 3 pétaoctets de données dans 60 serveurs (20 serveurs est une réplique) et 6 XNUMX milliards d'enregistrements dans les faits et les agrégations. Rien de tel ne pouvait être offert à Vertica.

Je passe maintenant aux choses pratiques dans cet exemple.
- Le premier est un schéma efficace. Cela dépend beaucoup du schéma.
- La seconde est la génération SQL efficace.
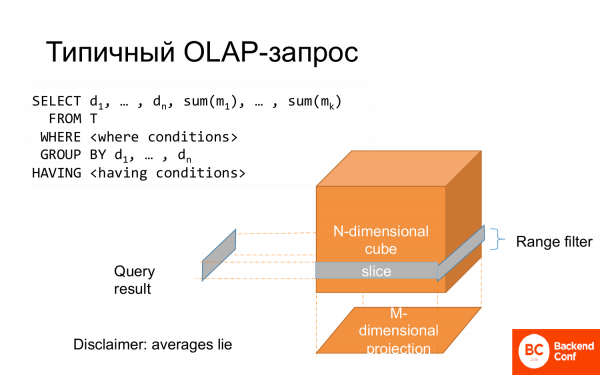
Une requête OLAP typique est une sélection. Certaines des colonnes vont au groupe par, certaines des colonnes vont aux fonctions d'agrégation. Il y a où, qui peut être représenté comme une tranche de cube. L'ensemble du groupe peut être considéré comme une projection. Et c'est pourquoi cela s'appelle l'analyse de données multivariées.

Et souvent, cela est modélisé sous la forme d'un schéma en étoile, lorsqu'il y a un fait central et des caractéristiques de ce fait le long des côtés, le long des rayons.

Et en termes de conception physique, comment cela tient sur la table, ils font généralement une représentation normalisée. Vous pouvez dénormaliser, mais cela coûte cher sur le disque et n'est pas très efficace sur les requêtes. Par conséquent, ils font généralement une représentation normalisée, c'est-à-dire une table de faits et de nombreuses tables de dimensions.
Mais cela ne fonctionne pas bien dans ClickHouse. Il y a deux raisons :
- La première est que ClickHouse n'a pas de très bonnes jointures, c'est-à-dire qu'il y a des jointures, mais elles sont mauvaises. Bien que mauvais.
- La seconde est que les tables ne sont pas mises à jour. Habituellement, dans ces plaques, qui sont autour du circuit en étoile, quelque chose doit être changé. Par exemple, le nom du client, le nom de l'entreprise, etc. Et ça ne marche pas.
Et il y a un moyen de sortir de cela dans ClickHouse. voire deux :
- Le premier est l'utilisation de dictionnaires. Les dictionnaires externes sont ce qui aide à 99% à résoudre le problème avec le schéma en étoile, avec les mises à jour, etc.
- La seconde est l'utilisation de tableaux. Les tableaux aident également à se débarrasser des jointures et des problèmes de normalisation.

- Aucune jointure requise.
- Évolutif. Depuis mars 2018, une opportunité non documentée est apparue (vous ne la trouverez pas dans la documentation) pour mettre à jour partiellement les dictionnaires, c'est-à-dire les entrées qui ont changé. Pratiquement, c'est comme une table.
- Toujours en mémoire, les jointures avec un dictionnaire fonctionnent donc plus rapidement que s'il s'agissait d'une table sur disque et ce n'est pas encore un fait qu'elle se trouve dans le cache, très probablement pas.

- Vous n'avez pas non plus besoin de jointures.
- Il s'agit d'une représentation compacte 1-à-plusieurs.
- Et à mon avis, les tableaux sont faits pour les geeks. Ce sont des fonctions lambda et ainsi de suite.
Ce n'est pas pour les mots rouges. Il s'agit d'une fonctionnalité très puissante qui vous permet de faire beaucoup de choses de manière très simple et élégante.

Exemples typiques qui aident à résoudre des tableaux. Ces exemples sont assez simples et clairs :
- Recherche par tags. Si vous avez des hashtags là-bas et que vous souhaitez trouver des messages par hashtag.
- Recherche par paires clé-valeur. Il existe également des attributs avec une valeur.
- Stocker des listes de clés que vous devez traduire en autre chose.
Toutes ces tâches peuvent être résolues sans tableaux. Les balises peuvent être placées sur une ligne et sélectionnées avec une expression régulière ou dans une table séparée, mais vous devez ensuite faire des jointures.

Et dans ClickHouse, vous n'avez rien à faire, il suffit de décrire le tableau de chaînes pour les hashtags ou de créer une structure imbriquée pour les systèmes clé-valeur.
La structure imbriquée n'est peut-être pas le meilleur nom. Ce sont deux tableaux qui ont une partie commune dans le nom et certaines caractéristiques connexes.
Et il est très facile de rechercher par tag. Avoir une fonction has, qui vérifie que le tableau contient un élément. Tout le monde, a trouvé toutes les entrées qui se rapportent à notre conférence.
La recherche par sous-id est un peu plus compliquée. Nous devons d'abord trouver l'index de la clé, puis prendre l'élément avec cet index et vérifier que cette valeur est celle dont nous avons besoin. Cependant, il est très simple et compact.
L'expression régulière que vous voudriez écrire si vous la gardiez sur une seule ligne, ce serait, premièrement, maladroit. Et, deuxièmement, cela a fonctionné beaucoup plus longtemps que deux tableaux.

Un autre exemple. Vous avez un tableau dans lequel vous stockez l'ID. Et vous pouvez les traduire en noms. Fonction arrayMap. Il s'agit d'une fonction lambda typique. Vous y passez des expressions lambda. Et elle extrait la valeur du nom de chaque ID du dictionnaire.
La recherche peut être effectuée de la même manière. Une fonction de prédicat est passée qui vérifie ce que les éléments correspondent.

Ces choses simplifient grandement le circuit et résolvent un tas de problèmes.
Mais le problème suivant auquel nous sommes confrontés, et que j'aimerais mentionner, est l'efficacité des requêtes.
- ClickHouse n'a pas de planificateur de requêtes. Absolument pas.
- Néanmoins, les requêtes complexes doivent encore être planifiées. Dans quels cas ?
- S'il y a plusieurs jointures dans la requête, vous les encapsulez dans des sous-sélections. Et l'ordre dans lequel ils sont exécutés compte.
- Et le second - si la demande est distribuée. Parce que dans une requête distribuée, seule la sous-sélection la plus interne est exécutée distribuée, et tout le reste est transmis à un serveur auquel vous vous êtes connecté et exécuté là-bas. Par conséquent, si vous avez distribué des requêtes avec de nombreuses jointures (jointure), vous devez choisir l'ordre.
Et même dans des cas plus simples, il faut parfois aussi faire le travail du planificateur et réécrire un peu les requêtes.

Voici un exemple. Sur le côté gauche se trouve une requête qui affiche les 5 premiers pays. Et cela prend 2,5 secondes, à mon avis. Et sur le côté droit, la même requête, mais légèrement réécrite. Au lieu de regrouper par chaîne, nous avons commencé à regrouper par clé (int). Et c'est plus rapide. Et puis nous avons connecté un dictionnaire au résultat. Au lieu de 2,5 secondes, la demande prend 1,5 seconde. C'est bon.

Un exemple similaire avec des filtres de réécriture. Voici une demande pour la Russie. Il tourne pendant 5 secondes. Si nous le réécrivons de manière à comparer à nouveau non pas une chaîne, mais des nombres avec un ensemble de ces clés qui se rapportent à la Russie, alors ce sera beaucoup plus rapide.

Il existe de nombreuses astuces de ce type. Et ils vous permettent d'accélérer considérablement les requêtes qui, selon vous, s'exécutent déjà rapidement ou, au contraire, s'exécutent lentement. Ils peuvent être fabriqués encore plus rapidement.

- Travail maximum en mode distribué.
- Trier par types minimum, comme je l'ai fait par ints.
- S'il y a des jointures (join), des dictionnaires, alors il vaut mieux les faire en dernier recours, lorsque vous avez déjà des données au moins partiellement regroupées, alors l'opération de jointure ou l'appel du dictionnaire sera appelé moins de fois et ce sera plus rapide .
- Remplacement des filtres.
Il existe d'autres techniques, et pas seulement celles que j'ai démontrées. Et tous peuvent parfois accélérer considérablement l'exécution des requêtes.

Passons à l'exemple suivant. Société X des États-Unis. Que fait-elle?
Il y avait une tâche :
- Liaison hors ligne des transactions publicitaires.
- Modélisation de différents modèles de liaison.

Quel est le scénario ?
Un visiteur ordinaire vient sur le site, par exemple, 20 fois par mois à partir de différentes publicités, ou juste comme ça vient parfois sans aucune publicité, car il se souvient de ce site. Regarde certains produits, les met dans le panier, les sort du panier. Et, à la fin, quelque chose achète.
Questions raisonnables : "Qui doit payer la publicité, si nécessaire ?" et "Quelle publicité l'a influencé, le cas échéant ?". Autrement dit, pourquoi a-t-il acheté et comment amener des gens comme cette personne à acheter aussi ?
Afin de résoudre ce problème, vous devez connecter les événements qui se produisent sur le site Web de la bonne manière, c'est-à-dire établir une connexion entre eux. Ensuite, ils sont envoyés pour analyse à DWH. Et sur la base de cette analyse, créez des modèles de qui et de quelles annonces diffuser.

Une transaction publicitaire est un ensemble d'événements utilisateur associés qui commencent par la diffusion d'une annonce, puis quelque chose se produit, puis peut-être un achat, puis il peut y avoir des achats au sein d'un achat. Par exemple, s'il s'agit d'une application mobile ou d'un jeu mobile, l'installation de l'application est généralement gratuite, et si quelque chose y est fait, de l'argent peut être nécessaire pour cela. Et plus une personne dépense dans l'application, plus elle est précieuse. Mais pour cela, vous devez tout connecter.

Il existe de nombreux modèles de reliure.
Les plus populaires sont :
- Dernière interaction, où l'interaction est soit un clic, soit une impression.
- Première interaction, c'est-à-dire la première chose qui a amené une personne sur le site.
- Combinaison linéaire - tous également.
- Atténuation.
- Etc.
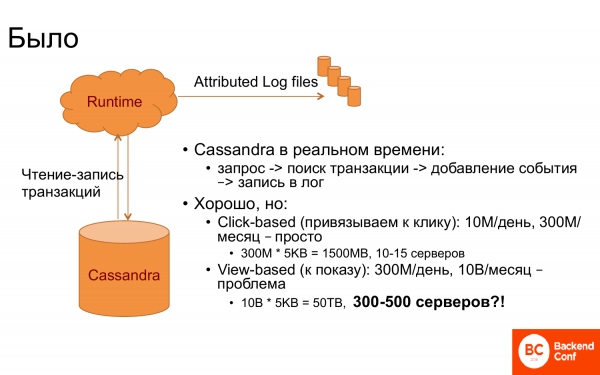
Et comment tout cela a-t-il fonctionné en premier lieu ? Il y avait Runtime et Cassandra. Cassandra a été utilisée comme stockage de transactions, c'est-à-dire que toutes les transactions associées y étaient stockées. Et lorsqu'un événement survient dans Runtime, par exemple, en affichant une page ou autre chose, une demande a été faite à Cassandra - existe-t-il une telle personne ou non. Ensuite, les transactions qui s'y rapportent ont été obtenues. Et le lien s'est fait.
Et s'il y a de la chance que la requête ait un identifiant de transaction, alors c'est facile. Mais généralement pas de chance. Il fallait donc trouver la dernière transaction ou la transaction au dernier clic, etc.
Et tout fonctionnait très bien tant que la reliure était au dernier clic. Parce qu'il y a, disons, 10 millions de clics par jour, 300 millions par mois, si on se fixe une fenêtre d'un mois. Et puisque dans Cassandra, tout doit être en mémoire pour fonctionner rapidement, car le Runtime doit répondre rapidement, il a fallu environ 10 à 15 serveurs.
Et quand ils ont voulu lier une transaction à l'affichage, cela s'est immédiatement avéré moins amusant. Et pourquoi? On peut voir qu'il faut stocker 30 fois plus d'événements. Et, par conséquent, vous avez besoin de 30 fois plus de serveurs. Et il s'avère que c'est une sorte de chiffre astronomique. Conserver jusqu'à 500 serveurs pour effectuer la liaison, malgré le fait qu'il y a beaucoup moins de serveurs dans Runtime, c'est une sorte de chiffre erroné. Et ils ont commencé à penser quoi faire.

Et nous sommes allés à ClickHouse. Et comment le faire sur ClickHouse ? À première vue, il semble qu'il s'agisse d'un ensemble d'anti-modèles.
- La transaction grandit, nous y accrochons de plus en plus d'événements, c'est-à-dire qu'elle est modifiable, et ClickHouse ne fonctionne pas très bien avec les objets modifiables.
- Lorsqu'un visiteur vient chez nous, nous devons extraire ses transactions par clé, par son identifiant de visite. C'est aussi une requête ponctuelle, ils ne le font pas dans ClickHouse. Habituellement, ClickHouse a de gros … scans, mais ici, nous devons obtenir des enregistrements. Aussi un anti-modèle.
- De plus, la transaction était en json, mais ils ne voulaient pas la réécrire, ils voulaient donc stocker json de manière non structurée et, si nécessaire, en tirer quelque chose. Et c'est aussi un anti-modèle.
C'est-à-dire un ensemble d'anti-modèles.
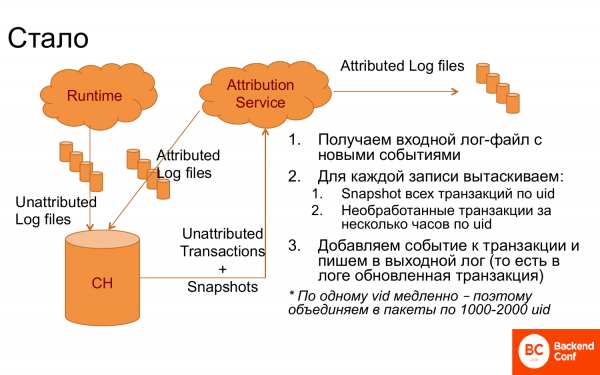
Mais néanmoins, il s'est avéré que c'était un système qui fonctionnait très bien.
Ce qui a été fait? ClickHouse est apparu, dans lequel des journaux ont été jetés, divisés en enregistrements. Un service attribué est apparu qui a reçu des journaux de ClickHouse. Après cela, pour chaque entrée, par identifiant de visite, j'ai reçu des transactions qui n'auraient peut-être pas encore été traitées et plus des instantanés, c'est-à-dire des transactions déjà connectées, à savoir le résultat d'un travail précédent. J'en ai déjà fait une logique, choisi la bonne transaction, connecté de nouveaux événements. Connecté à nouveau. Le journal est retourné à ClickHouse, c'est-à-dire qu'il s'agit d'un système constamment cyclique. Et d'ailleurs, je suis allé à DWH pour l'analyser là-bas.
C'est sous cette forme que cela ne fonctionnait pas très bien. Et pour faciliter la tâche de ClickHouse, lorsqu'il y avait une demande par identifiant de visite, ils ont regroupé ces demandes en blocs de 1 000 à 2 000 identifiants de visite et ont extrait toutes les transactions pour 1 000 à 2 000 personnes. Et puis tout a fonctionné.
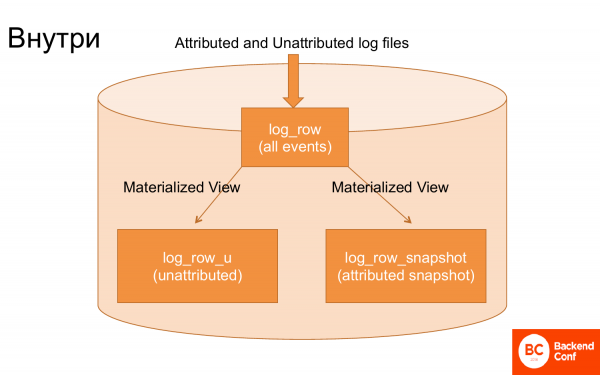
Si vous regardez à l'intérieur de ClickHouse, il n'y a que 3 tables principales qui servent tout cela.
La première table dans laquelle les journaux sont téléchargés, et les journaux sont téléchargés presque sans traitement.
Deuxième tableau. Grâce à la vue matérialisée, à partir de ces journaux, les événements qui n'ont pas encore été attribués, c'est-à-dire ceux qui ne sont pas liés, ont été supprimés. Et grâce à la vue matérialisée, les transactions ont été extraites de ces journaux pour créer un instantané. Autrement dit, une vue matérialisée spéciale a créé un instantané, à savoir le dernier état accumulé de la transaction.
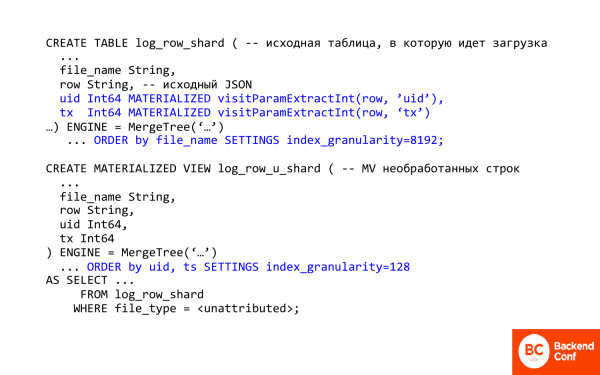
Voici le texte écrit en SQL. Je voudrais commenter quelques éléments importants.
La première chose importante est la possibilité d'extraire des colonnes et des champs de json dans ClickHouse. C'est-à-dire que ClickHouse a quelques méthodes pour travailler avec json. Ils sont très, très primitifs.
visitParamExtractInt vous permet d'extraire des attributs de json, c'est-à-dire que le premier hit fonctionne. Et de cette façon, vous pouvez extraire l'identifiant de transaction ou l'identifiant de visite. Ce temps.
Deuxièmement, un champ matérialisé délicat est utilisé ici. Qu'est-ce que ça veut dire? Cela signifie que vous ne pouvez pas l'insérer dans la table, c'est-à-dire qu'il n'est pas inséré, il est calculé et stocké lors de l'insertion. Lors du collage, ClickHouse fait le travail pour vous. Et ce dont vous avez besoin plus tard est déjà extrait de json.
Dans ce cas, la vue matérialisée concerne les lignes brutes. Et la première table avec des bûches pratiquement brutes est juste utilisée. Et que fait-il ? Tout d'abord, cela change le tri, c'est-à-dire que le tri se fait désormais par identifiant de visite, car nous devons rapidement extraire sa transaction pour une personne spécifique.
La deuxième chose importante est index_granularity. Si vous avez vu MergeTree, c'est généralement 8 par défaut index_granularity. Ce que c'est? Il s'agit du paramètre de parcimonie de l'indice. Dans ClickHouse, l'index est clairsemé, il n'indexe jamais chaque entrée. Il le fait tous les 192 8. Et c'est bien quand beaucoup de données doivent être calculées, mais mauvais quand un peu, car il y a une surcharge importante. Et si nous réduisons la granularité de l'index, nous réduisons la surcharge. Il ne peut pas être réduit à un, car il n'y a peut-être pas assez de mémoire. L'index est toujours stocké en mémoire.

Snapshot utilise également d'autres fonctionnalités intéressantes de ClickHouse.
Tout d'abord, c'est AggregatingMergeTree. Et AggregatingMergeTree stocke argMax, c'est-à-dire qu'il s'agit de l'état de la transaction correspondant au dernier horodatage. Des transactions sont générées tout le temps pour un visiteur donné. Et dans le tout dernier état de cette transaction, nous avons ajouté un événement et nous avons un nouvel état. Il a de nouveau frappé ClickHouse. Et grâce à argMax dans cette vue matérialisée, nous pouvons toujours obtenir l'état actuel.

- La liaison est "découplée" du Runtime.
- Jusqu'à 3 milliards de transactions par mois sont stockées et traitées. C'est un ordre de grandeur supérieur à ce qu'il était dans Cassandra, c'est-à-dire dans un système transactionnel typique.
- Cluster de 2x5 serveurs ClickHouse. 5 serveurs et chaque serveur a une réplique. C'est encore moins que dans Cassandra pour faire une attribution basée sur les clics, et ici nous avons une attribution basée sur l'impression. Autrement dit, au lieu d'augmenter le nombre de serveurs de 30 fois, ils ont réussi à les réduire.

Et le dernier exemple est la société financière Y, qui a analysé les corrélations des variations des cours des actions.
Et la tâche était :
- Il y a environ 5 000 actions.
- Des cotations toutes les 100 millisecondes sont connues.
- Les données ont été accumulées sur 10 ans. Apparemment, pour certaines entreprises plus, pour d'autres moins.
- Il y a environ 100 milliards de lignes au total.
Et il fallait calculer la corrélation des changements.
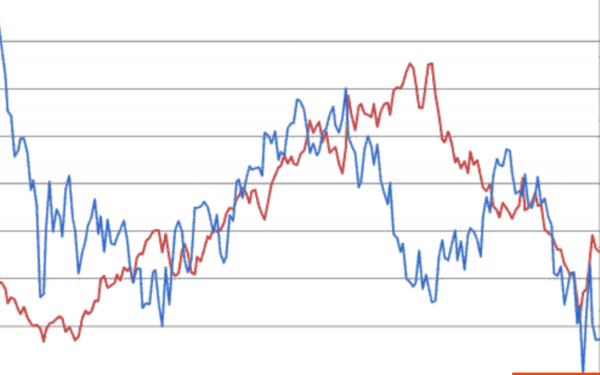
Voici deux actions et leurs cotations. Si l'un monte et l'autre monte, alors c'est une corrélation positive, c'est-à-dire que l'un monte et l'autre monte. Si l'un monte, comme à la fin du graphique, et l'autre descend, alors c'est une corrélation négative, c'est-à-dire que quand l'un monte, l'autre baisse.
En analysant ces changements mutuels, on peut faire des prédictions sur le marché financier.

Mais la tâche est difficile. Qu'est-ce qui est fait pour cela ? Nous avons 100 milliards d'enregistrements qui ont : le temps, le stock et le prix. Nous devons calculer les 100 premiers milliards de fois la différence de course à partir de l'algorithme de prix. RunningDifference est une fonction de ClickHouse qui calcule séquentiellement la différence entre deux chaînes.
Et après cela, vous devez calculer la corrélation, et la corrélation doit être calculée pour chaque paire. Pour 5 000 actions, les paires sont de 12,5 millions. Et c'est beaucoup, c'est-à-dire 12,5 fois il faut calculer une telle fonction de corrélation.
Et si quelqu'un a oublié, alors ͞x et ͞y est un échec et mat. attente d'échantillonnage. Autrement dit, il est nécessaire non seulement de calculer les racines et les sommes, mais également une somme supplémentaire à l'intérieur de ces sommes. Un tas de calculs doivent être effectués 12,5 millions de fois, et même regroupés par heures. Nous avons aussi beaucoup d'heures. Et vous devez le faire en 60 secondes. C'est une blague.

Il était nécessaire d'avoir du temps au moins d'une manière ou d'une autre, car tout cela fonctionnait très, très lentement avant l'arrivée de ClickHouse.

Ils ont essayé de le calculer sur Hadoop, sur Spark, sur Greenplum. Et tout cela était très lent ou coûteux. C'est-à-dire qu'il était possible de calculer d'une manière ou d'une autre, mais cela coûtait cher.
Et puis ClickHouse est arrivé et les choses se sont beaucoup améliorées.
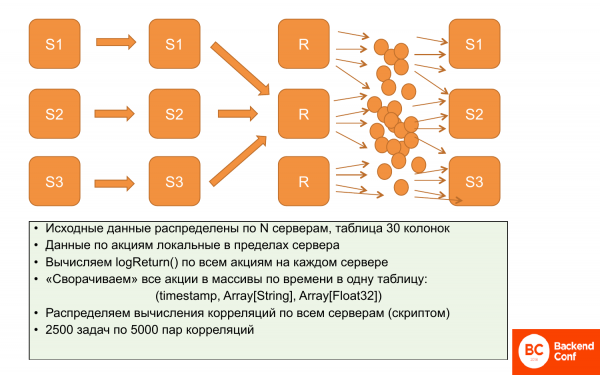
Je vous rappelle que nous avons un problème avec la localité des données, car les corrélations ne peuvent pas être localisées. On ne peut pas mettre une partie des données sur un serveur, une autre sur un autre et calculer, il faut avoir toutes les données partout.
Qu'ont-ils fait? Dans un premier temps, les données sont localisées. Chaque serveur stocke des données sur le prix d'un certain ensemble d'actions. Et ils ne se chevauchent pas. Par conséquent, il est possible de calculer logReturn en parallèle et indépendamment, tout cela se passe jusqu'à présent en parallèle et distribué.
Ensuite, nous avons décidé de réduire ces données, sans perdre en expressivité. Réduisez l'utilisation de tableaux, c'est-à-dire que pour chaque période de temps, créez un tableau d'actions et un tableau de prix. Par conséquent, il occupe beaucoup moins d'espace de données. Et ils sont un peu plus faciles à travailler. Ce sont des opérations presque parallèles, c'est-à-dire que nous lisons partiellement en parallèle puis écrivons sur le serveur.
Après cela, il peut être reproduit. La lettre "r" signifie que nous avons répliqué ces données. Autrement dit, nous avons les mêmes données sur les trois serveurs - ce sont les tableaux.
Et puis avec un script spécial de cet ensemble de 12,5 millions de corrélations qui doivent être calculées, vous pouvez créer des packages. C'est-à-dire 2 500 tâches avec 5 000 paires de corrélations. Et cette tâche doit être calculée sur un serveur ClickHouse spécifique. Il a toutes les données, car les données sont les mêmes et il peut les calculer séquentiellement.
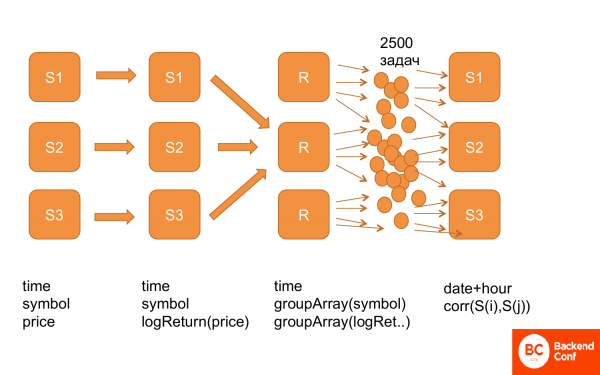
Encore une fois, voilà à quoi ça ressemble. Tout d'abord, nous avons toutes les données dans cette structure : temps, actions, prix. Ensuite, nous avons calculé logReturn, c'est-à-dire des données de même structure, mais au lieu du prix, nous avons déjà logReturn. Ensuite, ils ont été refaits, c'est-à-dire que nous avons obtenu le temps et le groupArray pour les stocks et les prix. Répliqué. Et après cela, nous avons généré un tas de tâches et les avons transmises à ClickHouse pour qu'il les compte. Et il fonctionne.

Lors de la preuve de concept, la tâche était une sous-tâche, c'est-à-dire que moins de données ont été prises. Et seulement trois serveurs.
Ces deux premières étapes : le calcul de Log_return et l'emballage dans des tableaux ont pris environ une heure.
Et le calcul de la corrélation est d'environ 50 heures. Mais 50 heures ne suffisent pas, car ils travaillaient pendant des semaines. Ce fut un grand succès. Et si vous comptez, alors 70 fois par seconde tout a été compté sur ce cluster.
Mais le plus important est que ce système est pratiquement sans goulots d'étranglement, c'est-à-dire qu'il évolue presque linéairement. Et ils l'ont vérifié. Mise à l'échelle réussie.

- Le bon schéma est la moitié du succès. Et le bon schéma est l'utilisation de toutes les technologies ClickHouse nécessaires.
- Summing/AggregatingMergeTrees sont des technologies qui vous permettent d'agréger ou de considérer un instantané d'état comme un cas particulier. Et cela simplifie énormément beaucoup de choses.
- Les vues matérialisées vous permettent de contourner la limite d'un index. Peut-être que je ne l'ai pas dit très clairement, mais lorsque nous avons chargé les journaux, les journaux bruts étaient dans la table avec un index, et les journaux d'attributs étaient dans la table, c'est-à-dire les mêmes données, seulement filtrées, mais l'index était complètement autres. Il semble que ce soit les mêmes données, mais un tri différent. Et les vues matérialisées vous permettent, si vous en avez besoin, de contourner une telle limitation de ClickHouse.
- Réduisez la granularité de l'index pour les requêtes ponctuelles.
- Et distribuez les données intelligemment, essayez de localiser les données au sein du serveur autant que possible. Et essayez de vous assurer que les demandes utilisent également la localisation autant que possible.
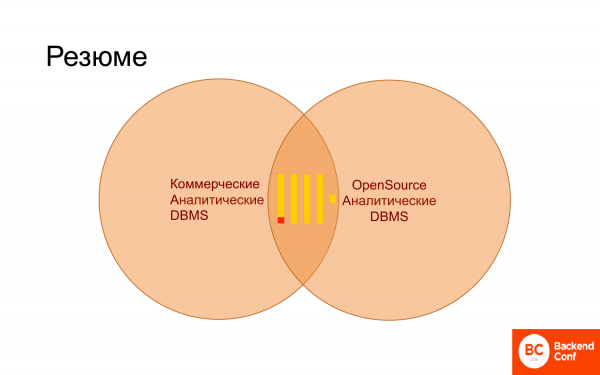
Et pour résumer ce petit discours, on peut dire que ClickHouse a maintenant fermement occupé le territoire des bases de données commerciales et des bases de données open source, c'est-à-dire spécifiquement pour l'analyse. Il s'intègre parfaitement dans ce paysage. Et de plus, cela commence lentement à en évincer les autres, car lorsque vous avez ClickHouse, vous n'avez pas besoin d'InfiniDB. Vertika ne sera peut-être pas nécessaire bientôt s'il prend en charge SQL normalement. Apprécier!

-Merci pour le rapport ! Très intéressant! Y avait-il des comparaisons avec Apache Phoenix ?
Non, je n'ai entendu personne comparer. Nous et Yandex essayons de garder une trace de toutes les comparaisons ClickHouse avec différentes bases de données. Parce que si tout à coup quelque chose s'avère plus rapide que ClickHouse, alors Lesha Milovidov ne peut pas dormir la nuit et commence à l'accélérer rapidement. Je n'ai pas entendu parler d'une telle comparaison.
(Aleksey Milovidov) Apache Phoenix est un moteur SQL alimenté par Hbase. Hbase est principalement destiné au scénario de travail clé-valeur. Là, dans chaque ligne, il peut y avoir un nombre arbitraire de colonnes avec des noms arbitraires. Cela peut être dit à propos de systèmes tels que Hbase, Cassandra. Et ce sont précisément les requêtes analytiques lourdes qui ne fonctionneront pas normalement pour eux. Ou vous pourriez penser qu'ils fonctionnent bien si vous n'avez aucune expérience avec ClickHouse.
merci
Bon après-midi Je suis déjà très intéressé par ce sujet, car j'ai un sous-système analytique. Mais quand je regarde ClickHouse, j'ai l'impression que ClickHouse est très bien adapté à l'analyse d'événements, modifiable. Et si j'ai besoin d'analyser beaucoup de données commerciales avec un tas de grandes tables, alors ClickHouse, pour autant que je sache, ne me convient pas vraiment ? Surtout s'ils changent. Est-ce correct ou y a-t-il des exemples qui peuvent réfuter cela?
C'est juste. Et cela est vrai de la plupart des bases de données analytiques spécialisées. Ils sont adaptés au fait qu'il existe une ou plusieurs grandes tables modifiables, et pour de nombreuses petites tables qui changent lentement. Autrement dit, ClickHouse n'est pas comme Oracle, où vous pouvez tout mettre et créer des requêtes très complexes. Afin d'utiliser ClickHouse efficacement, vous devez créer un schéma d'une manière qui fonctionne bien dans ClickHouse. Autrement dit, évitez une normalisation excessive, utilisez des dictionnaires, essayez de faire moins de liens longs. Et si le schéma est construit de cette manière, des tâches commerciales similaires peuvent être résolues sur ClickHouse beaucoup plus efficacement que sur une base de données relationnelle traditionnelle.
Merci pour le rapport ! J'ai une question sur la dernière affaire financière. Ils avaient des analyses. Il fallait comparer comment ils montaient et descendaient. Et je comprends que vous avez construit le système spécifiquement pour cette analyse ? Si demain, par exemple, ils ont besoin d'un autre rapport sur ces données, doivent-ils reconstruire le schéma et télécharger les données ? Autrement dit, faire une sorte de prétraitement pour obtenir la demande ?
Bien sûr, il s'agit de l'utilisation de ClickHouse pour une tâche bien précise. Il pourrait plus traditionnellement être résolu dans Hadoop. Pour Hadoop, c'est une tâche idéale. Mais sur Hadoop, c'est très lent. Et mon objectif est de démontrer que ClickHouse peut résoudre des tâches qui sont généralement résolues par des moyens complètement différents, mais en même temps le faire beaucoup plus efficacement. Il est adapté à une tâche spécifique. Il est clair que s'il y a un problème avec quelque chose de similaire, il peut être résolu de la même manière.
Il est clair. Vous avez dit que 50 heures ont été traitées. Est-ce depuis le tout début, quand avez-vous chargé les données ou obtenu les résultats ?
Oui, oui.
D'accord, merci beaucoup.
C'est sur un cluster de 3 serveurs.
Salutations! Merci pour le rapport ! Tout est très intéressant. Je ne poserai pas de questions sur la fonctionnalité, mais sur l'utilisation de ClickHouse en termes de stabilité. Autrement dit, en aviez-vous, avez-vous dû restaurer? Comment se comporte ClickHouse dans ce cas ? Et est-il arrivé que vous ayez aussi une réplique ? Par exemple, nous avons rencontré un problème avec ClickHouse alors qu'il sortait toujours de sa limite et tombait.
Bien sûr, il n'y a pas de systèmes idéaux. Et ClickHouse a aussi ses propres problèmes. Mais avez-vous entendu parler de Yandex.Metrica qui ne fonctionne pas depuis longtemps ? Probablement pas. Il fonctionne de manière fiable depuis 2012-2013 sur ClickHouse. Je peux dire la même chose de mon expérience. Nous n'avons jamais eu d'échecs complets. Certaines choses partielles pouvaient arriver, mais elles n'étaient jamais assez critiques pour affecter sérieusement l'entreprise. Ce n'est jamais arrivé. ClickHouse est assez fiable et ne plante pas au hasard. Vous n'avez pas à vous en soucier. Ce n'est pas une chose brute. Cela a été prouvé par de nombreuses entreprises.
Bonjour! Vous avez dit que vous deviez réfléchir au schéma de données tout de suite. Et si ça arrivait ? Mes données coulent et coulent. Six mois passent, et je comprends qu'il est impossible de vivre comme ça, je dois re-télécharger les données et faire quelque chose avec elles.
Cela dépend bien sûr de votre système. Il existe plusieurs façons de le faire sans pratiquement aucun arrêt. Par exemple, vous pouvez créer une vue matérialisée dans laquelle créer une structure de données différente si elle peut être mappée de manière unique. Autrement dit, s'il permet le mappage à l'aide de ClickHouse, c'est-à-dire extraire certaines choses, changer la clé primaire, changer le partitionnement, alors vous pouvez créer une vue matérialisée. Écrasez vos anciennes données ici, les nouvelles seront écrites automatiquement. Et puis passez simplement à l'utilisation de la vue matérialisée, puis changez d'enregistrement et supprimez l'ancienne table. Il s'agit généralement d'une méthode non-stop.
Merci.
Source: habr.com
