

Bon après-midi Je m'appelle Danil Lipovoy, notre équipe chez Sbertech a commencé à utiliser HBase comme stockage pour les données opérationnelles. Au cours de son étude, une expérience s'est accumulée que j'ai voulu systématiser et décrire (nous espérons qu'elle sera utile à beaucoup). Toutes les expériences ci-dessous ont été réalisées avec les versions HBase 1.2.0-cdh5.14.2 et 2.0.0-cdh6.0.0-beta1.
- Architecture générale
- Écriture de données sur HBASE
- Lecture de données depuis HBASE
- Mise en cache des données
- Traitement des données par lots MultiGet/MultiPut
- Stratégie de fractionnement des tables en régions (fractionnement)
- Tolérance aux pannes, compactification et localisation des données
- Paramètres et performances
- Tests de résistance
- résultats
1. Architecture générale
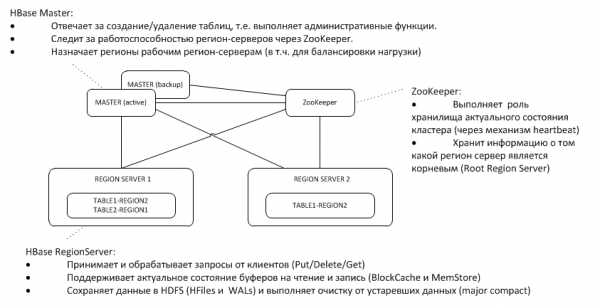
Le Maître de sauvegarde écoute le battement de cœur de l'actif sur le nœud ZooKeeper et, en cas de disparition, reprend les fonctions du maître.
2. Écrivez les données sur HBASE
Tout d'abord, examinons le cas le plus simple : écrire un objet clé-valeur dans une table à l'aide de put(rowkey). Le client doit d'abord découvrir où se trouve le serveur de région racine (RRS), qui stocke la table hbase:meta. Il reçoit ces informations de ZooKeeper. Après quoi, il accède à RRS et lit la table hbase:meta, à partir de laquelle il extrait des informations sur le RegionServer (RS) responsable du stockage des données pour une clé de ligne donnée dans la table d'intérêt. Pour une utilisation future, la méta-table est mise en cache par le client et donc les appels ultérieurs sont plus rapides, directement vers RS.
Ensuite, RS, après avoir reçu une demande, l'écrit tout d'abord dans WriteAheadLog (WAL), ce qui est nécessaire à la récupération en cas de crash. Enregistrez ensuite les données sur MemStore. Il s'agit d'un tampon en mémoire qui contient un ensemble trié de clés pour une région donnée. Une table peut être divisée en régions (partitions), chacune contenant un ensemble disjoint de clés. Cela vous permet de placer des régions sur différents serveurs pour obtenir des performances plus élevées. Cependant, malgré l’évidence de cette affirmation, nous verrons plus loin que cela ne fonctionne pas dans tous les cas.
Après avoir placé une entrée dans le MemStore, une réponse est renvoyée au client indiquant que l'entrée a été enregistrée avec succès. Cependant, en réalité, ils sont stockés uniquement dans un tampon et n'arrivent sur le disque qu'après un certain temps ou lorsqu'ils sont remplis de nouvelles données.
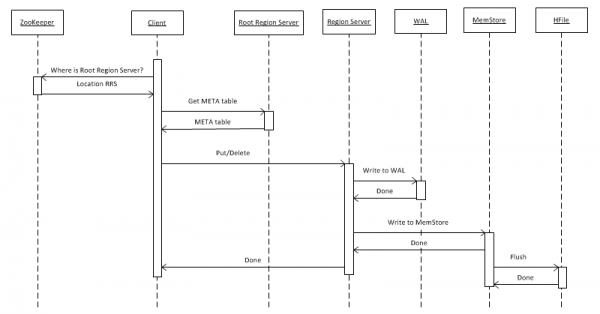
Lors de l'exécution de l'opération « Supprimer », les données ne sont pas physiquement supprimées. Ils sont simplement marqués comme supprimés, et la destruction elle-même se produit au moment de l'appel de la fonction majeure compacte, qui est décrite plus en détail au paragraphe 7.
Les fichiers au format HFile sont accumulés dans HDFS et de temps en temps le processus de compactage mineur est lancé, qui fusionne simplement les petits fichiers en plus gros sans rien supprimer. Au fil du temps, cela se transforme en un problème qui n'apparaît qu'à la lecture des données (nous y reviendrons un peu plus tard).
En plus du processus de chargement décrit ci-dessus, il existe une procédure beaucoup plus efficace, qui constitue peut-être l'aspect le plus fort de cette base de données : BulkLoad. Cela réside dans le fait que nous formons indépendamment des HFiles et les mettons sur le disque, ce qui nous permet d'évoluer parfaitement et d'atteindre des vitesses très décentes. En fait, la limitation ici n'est pas HBase, mais les capacités du matériel. Vous trouverez ci-dessous les résultats de démarrage sur un cluster composé de 16 RegionServers et de 16 NodeManager YARN (CPU Xeon E5-2680 v4 à 2.40 GHz * 64 threads), HBase version 1.2.0-cdh5.14.2.
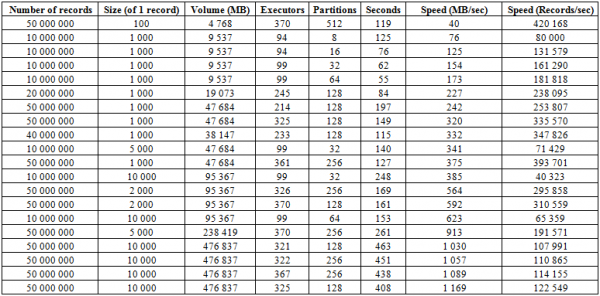
Ici, vous pouvez voir qu'en augmentant le nombre de partitions (régions) dans le tableau, ainsi que les exécuteurs Spark, nous obtenons une augmentation de la vitesse de téléchargement. De plus, la vitesse dépend du volume d'enregistrement. Les gros blocs donnent une augmentation du Mo/sec, les petits blocs du nombre d'enregistrements insérés par unité de temps, toutes choses étant égales par ailleurs.
Vous pouvez également commencer à charger sur deux tables en même temps et doubler la vitesse. Ci-dessous, vous pouvez voir que l'écriture simultanée de blocs de 10 Ko sur deux tables se produit à une vitesse d'environ 600 Mo/s dans chacune (total 1275 623 Mo/s), ce qui coïncide avec la vitesse d'écriture sur une table de 11 Mo/s (voir n° XNUMX ci-dessus)

Mais la deuxième exécution avec des enregistrements de 50 Ko montre que la vitesse de téléchargement augmente légèrement, ce qui indique qu'elle se rapproche des valeurs limites. Dans le même temps, vous devez garder à l'esprit qu'il n'y a pratiquement aucune charge créée sur HBASE lui-même, tout ce qui lui est demandé est d'abord de donner les données de hbase:meta, et après avoir aligné HFiles, de réinitialiser les données BlockCache et de sauvegarder le Tampon MemStore sur le disque, s'il n'est pas vide.
3. Lecture des données depuis HBASE
Si nous supposons que le client dispose déjà de toutes les informations de hbase:meta (voir point 2), alors la requête va directement au RS où est stockée la clé requise. Tout d'abord, la recherche est effectuée dans MemCache. Qu'il y ait ou non des données, la recherche est également effectuée dans le tampon BlockCache et, si nécessaire, dans HFiles. Si des données ont été trouvées dans le fichier, elles sont placées dans BlockCache et seront renvoyées plus rapidement lors de la prochaine requête. La recherche dans HFile est relativement rapide grâce à l'utilisation du filtre Bloom, c'est-à-dire après avoir lu une petite quantité de données, il détermine immédiatement si ce fichier contient la clé requise et sinon, passe au suivant.
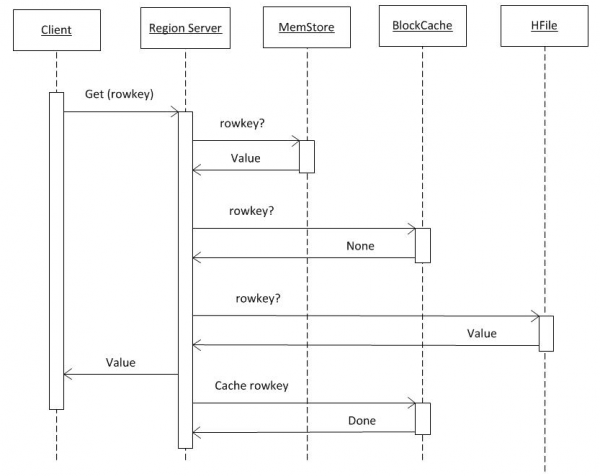
Ayant reçu des données de ces trois sources, RS génère une réponse. Il peut notamment transférer plusieurs versions trouvées d'un objet à la fois si le client a demandé le versionnage.
4. Mise en cache des données
Les tampons MemStore et BlockCache occupent jusqu'à 80 % de la mémoire RS allouée sur le tas (le reste est réservé aux tâches de service RS). Si le mode d'utilisation typique est tel que les processus écrivent et lisent immédiatement les mêmes données, il est alors logique de réduire BlockCache et d'augmenter MemStore, car Lorsque les données d'écriture ne pénètrent pas dans le cache pour être lues, BlockCache sera utilisé moins fréquemment. Le tampon BlockCache se compose de deux parties : LruBlockCache (toujours sur le tas) et BucketCache (généralement hors tas ou sur un SSD). BucketCache doit être utilisé lorsqu'il y a beaucoup de demandes de lecture et qu'elles ne rentrent pas dans LruBlockCache, ce qui conduit au travail actif de Garbage Collector. Dans le même temps, il ne faut pas s'attendre à une augmentation radicale des performances grâce à l'utilisation du cache de lecture, mais nous y reviendrons au paragraphe 8.
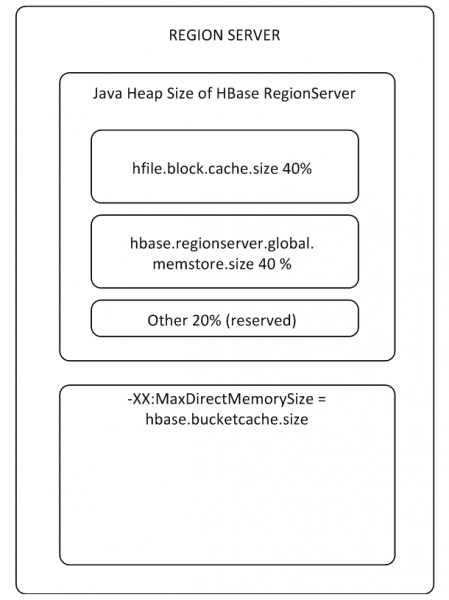
Il existe un BlockCache pour l'ensemble du RS et un MemStore pour chaque table (un pour chaque famille de colonnes).
Comme en théorie, lors de l'écriture, les données ne vont pas dans le cache et en effet, ces paramètres CACHE_DATA_ON_WRITE pour la table et « Cache DATA on Write » pour RS sont définis sur false. Cependant, en pratique, si nous écrivons des données sur MemStore, puis les vidons sur le disque (les effaçant ainsi), puis supprimons le fichier résultant, puis en exécutant une requête get, nous recevrons avec succès les données. De plus, même si vous désactivez complètement BlockCache et remplissez le tableau avec de nouvelles données, puis réinitialisez le MemStore sur le disque, supprimez-les et demandez-les à une autre session, elles seront toujours récupérées quelque part. Ainsi, HBase stocke non seulement des données, mais aussi des mystères mystérieux.
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
Le paramètre « Cache DATA on Read » est défini sur false. Si vous avez des idées, n'hésitez pas à en discuter dans les commentaires.
5. Traitement des données par lots MultiGet/MultiPut
Le traitement de requêtes uniques (Get/Put/Delete) est une opération assez coûteuse, donc si possible, vous devez les combiner dans une liste ou une liste, ce qui vous permet d'obtenir une amélioration significative des performances. Cela est particulièrement vrai pour l'opération d'écriture, mais lors de la lecture, il existe le piège suivant. Le graphique ci-dessous montre le temps nécessaire pour lire 50 000 enregistrements de MemStore. La lecture a été effectuée dans un thread et l'axe horizontal indique le nombre de clés dans la requête. Ici, vous pouvez voir qu'en augmentant jusqu'à mille clés en une seule requête, le temps d'exécution diminue, c'est-à-dire la vitesse augmente. Cependant, avec le mode MSLAB activé par défaut, après ce seuil, une baisse radicale des performances commence, et plus la quantité de données dans l'enregistrement est importante, plus la durée de fonctionnement est longue.
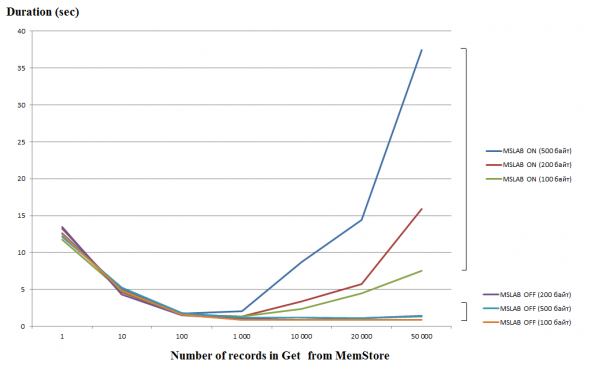
Les tests ont été réalisés sur une machine virtuelle, 8 cœurs, version HBase 2.0.0-cdh6.0.0-beta1.
Le mode MSLAB est conçu pour réduire la fragmentation du tas, qui se produit en raison du mélange de données de nouvelle et d'ancienne génération. Pour contourner ce problème, lorsque MSLAB est activé, les données sont placées dans des cellules relativement petites (morceaux) et traitées par morceaux. Par conséquent, lorsque le volume du paquet de données demandé dépasse la taille allouée, les performances chutent fortement. D'un autre côté, désactiver ce mode n'est pas non plus conseillé, car cela entraînerait des arrêts dus au GC lors des moments de traitement intensif des données. Une bonne solution est d'augmenter le volume des cellules dans le cas d'une écriture active via put en même temps que la lecture. Il convient de noter que le problème ne se produit pas si, après l'enregistrement, vous exécutez la commande flush, qui réinitialise MemStore sur le disque, ou si vous chargez à l'aide de BulkLoad. Le tableau ci-dessous montre que les requêtes du MemStore pour des données plus volumineuses (et de même quantité) entraînent des ralentissements. Cependant, en augmentant la taille des morceaux, nous ramenons le temps de traitement à la normale.
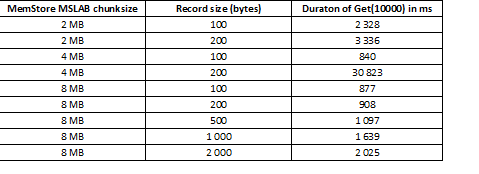
En plus d'augmenter la taille des fragments, il est utile de diviser les données par région, c'est-à-dire fractionnement des tables. Cela se traduit par moins de demandes arrivant dans chaque région et si elles rentrent dans une cellule, la réponse reste bonne.
6. Stratégie de fractionnement des tables en régions (splitting)
Étant donné que HBase est un stockage clé-valeur et que le partitionnement est effectué par clé, il est extrêmement important de diviser les données de manière égale dans toutes les régions. Par exemple, diviser une telle table en trois parties entraînera la division des données en trois régions :
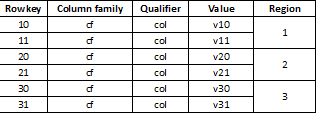
Il arrive que cela entraîne un fort ralentissement si les données chargées ultérieurement ressemblent, par exemple, à des valeurs longues, la plupart commençant par le même chiffre, par exemple :
1000001
1000002
...
1100003
Étant donné que les clés sont stockées sous forme de tableau d'octets, elles commenceront toutes de la même manière et appartiendront à la même région n°1 stockant cette plage de clés. Il existe plusieurs stratégies de partitionnement :
HexStringSplit – Transforme la clé en une chaîne codée hexadécimale dans la plage "00000000" => "FFFFFFFF" et remplit la gauche avec des zéros.
UniformSplit – Transforme la clé en un tableau d'octets avec un codage hexadécimal dans la plage "00" => "FF" et un remplissage à droite avec des zéros.
De plus, vous pouvez spécifier n'importe quelle plage ou jeu de clés pour le fractionnement et configurer le fractionnement automatique. Cependant, l'une des approches les plus simples et les plus efficaces est UniformSplit et l'utilisation de la concaténation de hachage, par exemple la paire d'octets la plus significative issue de l'exécution de la clé via la fonction CRC32 (rowkey) et la rowkey elle-même :
hachage + clé de ligne
Ensuite, toutes les données seront réparties uniformément entre les régions. Lors de la lecture, les deux premiers octets sont simplement supprimés et la clé d'origine reste. RS contrôle également la quantité de données et de clés dans la région et, si les limites sont dépassées, la divise automatiquement en plusieurs parties.
7. Tolérance aux pannes et localisation des données
Puisqu'une seule région est responsable de chaque jeu de clés, la solution aux problèmes associés aux pannes ou au déclassement de RS consiste à stocker toutes les données nécessaires dans HDFS. Lorsque RS tombe, le maître le détecte grâce à l'absence de battement de cœur sur le nœud ZooKeeper. Ensuite, il attribue la région desservie à un autre RS et puisque les HFiles sont stockés dans un système de fichiers distribué, le nouveau propriétaire les lit et continue de servir les données. Cependant, comme certaines données peuvent se trouver dans le MemStore et n'ont pas eu le temps d'entrer dans HFiles, WAL, qui est également stocké dans HDFS, est utilisé pour restaurer l'historique des opérations. Une fois les modifications appliquées, RS est capable de répondre aux demandes, mais ce déplacement conduit au fait que certaines des données et les processus qui les gèrent se retrouvent sur des nœuds différents, c'est-à-dire la localité diminue.
La solution au problème est un compactage majeur - cette procédure déplace les fichiers vers les nœuds qui en sont responsables (où se trouvent leurs régions), de sorte qu'au cours de cette procédure, la charge sur le réseau et les disques augmente fortement. Cependant, à l’avenir, l’accès aux données sera sensiblement accéléré. De plus, major_compaction effectue la fusion de tous les HFiles en un seul fichier au sein d'une région et nettoie également les données en fonction des paramètres de la table. Par exemple, vous pouvez spécifier le nombre de versions d'un objet qui doivent être conservées ou la durée de vie après laquelle l'objet est physiquement supprimé.
Cette procédure peut avoir un effet très positif sur le fonctionnement de HBase. L'image ci-dessous montre comment les performances se sont dégradées en raison de l'enregistrement actif des données. Ici, vous pouvez voir comment 40 threads ont écrit dans une table et 40 threads ont lu simultanément des données. Les threads d'écriture génèrent de plus en plus de HFiles, qui sont lus par d'autres threads. En conséquence, de plus en plus de données doivent être supprimées de la mémoire et finalement le GC commence à fonctionner, ce qui paralyse pratiquement tout le travail. Le lancement d'un important compactage a permis le déblayage des débris résultants et le rétablissement de la productivité.
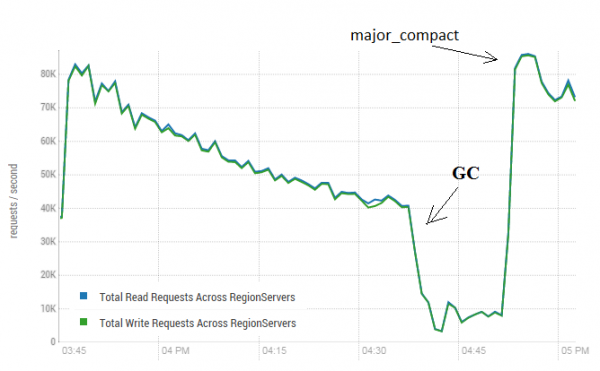
Le test a été réalisé sur 3 DataNodes et 4 RS (CPU Xeon E5-2680 v4 à 2.40 GHz * 64 threads). HBase version 1.2.0-cdh5.14.2
Il convient de noter qu'un compactage majeur a été lancé sur une table « en direct », dans laquelle les données étaient activement écrites et lues. Il y avait une déclaration en ligne selon laquelle cela pourrait conduire à une réponse incorrecte lors de la lecture des données. Pour vérifier, un processus a été lancé qui a généré de nouvelles données et les a écrites dans une table. Après quoi, j'ai immédiatement lu et vérifié si la valeur résultante coïncidait avec ce qui avait été écrit. Pendant que ce processus était en cours, un compactage majeur a été effectué environ 200 fois et aucun échec n'a été enregistré. Le problème apparaît peut-être rarement et uniquement en cas de charge élevée. Il est donc plus sûr d'arrêter les processus d'écriture et de lecture comme prévu et d'effectuer un nettoyage pour éviter de tels retraits du GC.
De plus, un compactage majeur n'affecte pas l'état du MemStore ; pour le vider sur le disque et le compacter, vous devez utiliser flush (connection.getAdmin().flush(TableName.valueOf(tblName))).
8. Paramètres et performances
Comme déjà mentionné, HBase montre son plus grand succès là où il n'a rien à faire, lors de l'exécution de BulkLoad. Cependant, cela s’applique à la plupart des systèmes et des personnes. Cependant, cet outil est plus adapté au stockage de données en masse dans de gros blocs, alors que si le processus nécessite plusieurs requêtes de lecture et d'écriture concurrentes, les commandes Get et Put décrites ci-dessus sont utilisées. Pour déterminer les paramètres optimaux, des lancements ont été effectués avec diverses combinaisons de paramètres et réglages de table :
- 10 threads ont été lancés simultanément 3 fois de suite (appelons cela un bloc de threads).
- Le temps de fonctionnement de tous les threads d’un bloc était moyenné et constituait le résultat final du fonctionnement du bloc.
- Tous les threads travaillaient avec la même table.
- Avant chaque démarrage du bloc de thread, un compactage majeur était effectué.
- Chaque bloc n'a effectué qu'une seule des opérations suivantes :
-Mettre
-Obtenir
—Obtenir+Mettre
- Chaque bloc a effectué 50 000 itérations de son opération.
- La taille de bloc d'un enregistrement est de 100 octets, 1000 10000 octets ou XNUMX XNUMX octets (aléatoire).
- Les blocs ont été lancés avec différents nombres de clés demandées (soit une clé, soit 10).
- Les blocs ont été exécutés sous différents paramètres de table. Paramètres modifiés :
— BlockCache = activé ou désactivé
— BlockSize = 65 Ko ou 16 Ko
— Partitions = 1, 5 ou 30
— MSLAB = activé ou désactivé
Le bloc ressemble donc à ceci :
un. Le mode MSLAB a été activé/désactivé.
b. Une table a été créée pour laquelle les paramètres suivants ont été définis : BlockCache = true/none, BlockSize = 65/16 Ko, Partition = 1/5/30.
c. La compression a été réglée sur GZ.
d. 10 threads ont été lancés simultanément en effectuant 1/10 opérations put/get/get+put dans cette table avec des enregistrements de 100/1000/10000 octets, effectuant 50 000 requêtes d'affilée (clés aléatoires).
e. Le point d a été répété trois fois.
F. La durée de fonctionnement de tous les threads a été moyennée.
Toutes les combinaisons possibles ont été testées. Il est prévisible que la vitesse diminuera à mesure que la taille de l'enregistrement augmente, ou que la désactivation de la mise en cache entraînera un ralentissement. Cependant, l'objectif était de comprendre le degré et l'importance de l'influence de chaque paramètre, c'est pourquoi les données collectées ont été introduites dans une fonction de régression linéaire, ce qui permet d'évaluer l'importance à l'aide de statistiques t. Vous trouverez ci-dessous les résultats des blocs effectuant des opérations Put. Ensemble complet de combinaisons 2*2*3*2*3 = 144 options + 72 tk. certains ont été réalisés deux fois. Il y a donc 216 exécutions au total :
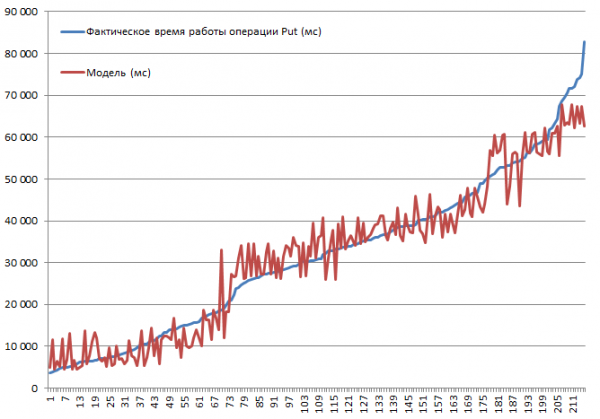
Les tests ont été effectués sur un mini-cluster composé de 3 DataNodes et 4 RS (CPU Xeon E5-2680 v4 à 2.40 GHz * 64 threads). HBase version 1.2.0-cdh5.14.2.
La vitesse d'insertion la plus élevée de 3.7 secondes a été obtenue avec le mode MSLAB désactivé, sur une table avec une partition, avec BlockCache activé, BlockSize = 16, enregistrements de 100 octets, 10 pièces par paquet.
La vitesse d'insertion la plus basse de 82.8 secondes a été obtenue avec le mode MSLAB activé, sur une table avec une partition, avec BlockCache activé, BlockSize = 16, enregistrements de 10000 1 octets, XNUMX chacun.
Regardons maintenant le modèle. On voit la bonne qualité du modèle basé sur R2, mais il est tout à fait clair que l’extrapolation est ici contre-indiquée. Le comportement réel du système lorsque les paramètres changent ne sera pas linéaire ; ce modèle n'est pas nécessaire pour faire des prédictions, mais pour comprendre ce qui s'est passé dans le cadre des paramètres donnés. Par exemple, nous voyons ici d’après le critère de Student que les paramètres BlockSize et BlockCache n’ont pas d’importance pour l’opération Put (qui est généralement assez prévisible) :

Mais le fait que l'augmentation du nombre de partitions entraîne une diminution des performances est quelque peu inattendu (nous avons déjà vu l'impact positif de l'augmentation du nombre de partitions avec BulkLoad), bien que compréhensible. Premièrement, pour le traitement, il faut générer des requêtes vers 30 régions au lieu d'une, et le volume de données n'est pas tel que cela puisse générer un gain. Deuxièmement, la durée totale de fonctionnement est déterminée par le RS le plus lent, et comme le nombre de DataNodes est inférieur au nombre de RS, certaines régions ont une localité nulle. Eh bien, regardons les cinq premiers :

Évaluons maintenant les résultats de l'exécution des blocs Get :

Le nombre de partitions a perdu de son importance, ce qui s'explique probablement par le fait que les données sont bien mises en cache et que le cache de lecture est le paramètre le plus important (statistiquement). Naturellement, augmenter le nombre de messages dans une requête est également très utile pour les performances. Meilleurs scores:

Et bien, enfin, regardons le modèle du bloc qui a d'abord effectué get puis put :

Tous les paramètres sont ici significatifs. Et les résultats des dirigeants :

9. Test de charge
Bon, enfin, nous lancerons une charge plus ou moins décente, mais c'est toujours plus intéressant quand on a quelque chose à comparer. Sur le site de DataStax, le développeur clé de Cassandra, on trouve NT d'un certain nombre de stockages NoSQL, y compris HBase version 0.98.6-1. Le chargement a été effectué par 40 threads, taille des données 100 octets, disques SSD. Le résultat des tests des opérations de lecture-modification-écriture a montré les résultats suivants.
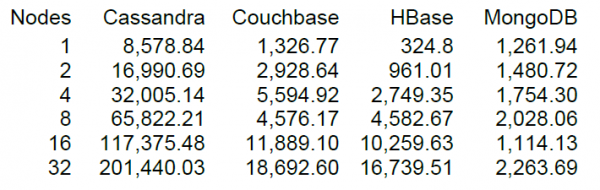
D'après ce que je comprends, la lecture a été effectuée par blocs de 100 enregistrements et pour 16 nœuds HBase, le test DataStax a montré une performance de 10 XNUMX opérations par seconde.
Heureusement que notre cluster dispose également de 16 nœuds, mais ce n'est pas très « chanceux » que chacun ait 64 cœurs (threads), alors que dans le test DataStax il n'y en a que 4. Par contre, ils ont des disques SSD, alors que nous avons des disques durs ou plus, la nouvelle version de HBase et l'utilisation du processeur pendant le chargement n'ont pratiquement pas augmenté de manière significative (visuellement de 5 à 10 %). Cependant, essayons de commencer à utiliser cette configuration. Paramètres de table par défaut, la lecture est effectuée dans la plage clé de 0 à 50 millions de manière aléatoire (c'est-à-dire essentiellement nouvelle à chaque fois). La table contient 50 millions d'enregistrements, répartis en 64 partitions. Les clés sont hachées à l'aide de crc32. Les paramètres du tableau sont par défaut, MSLAB est activé. En lançant 40 threads, chaque thread lit un ensemble de 100 clés aléatoires et réécrit immédiatement les 100 octets générés sur ces clés.
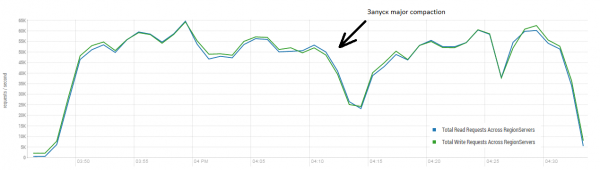
Support : 16 DataNode et 16 RS (CPU Xeon E5-2680 v4 à 2.40 GHz * 64 threads). HBase version 1.2.0-cdh5.14.2.
Le résultat moyen est plus proche de 40 10 opérations par seconde, ce qui est nettement meilleur que dans le test DataStax. Cependant, à des fins expérimentales, vous pouvez légèrement modifier les conditions. Il est peu probable que tous les travaux soient effectués exclusivement sur une seule table, ainsi que sur des clés uniques. Supposons qu'il existe un certain ensemble de touches « chaudes » qui génèrent la charge principale. Par conséquent, essayons de créer une charge avec des enregistrements plus gros (100 Ko), également par lots de 4, dans 50 tables différentes et en limitant la plage de clés demandées à 40 100. Le graphique ci-dessous montre le lancement de 10 threads, chaque thread lit un jeu de XNUMX clés et écrit immédiatement XNUMX Ko aléatoires sur ces clés.
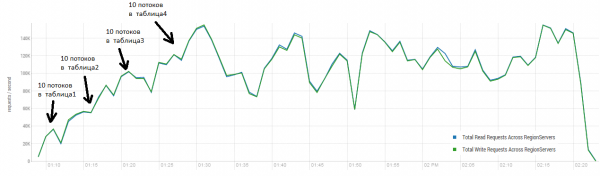
Support : 16 DataNode et 16 RS (CPU Xeon E5-2680 v4 à 2.40 GHz * 64 threads). HBase version 1.2.0-cdh5.14.2.
Pendant le chargement, un compactage majeur a été lancé à plusieurs reprises, comme indiqué ci-dessus, sans cette procédure, les performances se dégraderont progressivement, cependant, une charge supplémentaire apparaîtra également pendant l'exécution. Les prélèvements sont causés par diverses raisons. Parfois, les threads finissaient de fonctionner et il y avait une pause pendant leur redémarrage, parfois des applications tierces créaient une charge sur le cluster.
Lire et écrire immédiatement est l'un des scénarios de travail les plus difficiles pour HBase. Si vous effectuez uniquement de petites requêtes put, par exemple 100 octets, en les combinant en paquets de 10 à 50 50 éléments, vous pouvez obtenir des centaines de milliers d'opérations par seconde, et la situation est similaire avec les requêtes en lecture seule. Il convient de noter que les résultats sont radicalement meilleurs que ceux obtenus par DataStax, principalement grâce à des requêtes par blocs de XNUMX XNUMX.
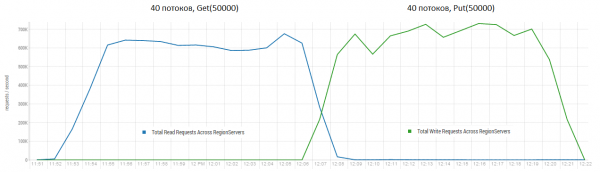
Support : 16 DataNode et 16 RS (CPU Xeon E5-2680 v4 à 2.40 GHz * 64 threads). HBase version 1.2.0-cdh5.14.2.
10. Conclusions
Ce système est configuré de manière assez flexible, mais l'influence d'un grand nombre de paramètres reste encore inconnue. Certains d’entre eux ont été testés, mais n’ont pas été inclus dans l’ensemble de tests résultant. Par exemple, des expériences préliminaires ont montré une signification insignifiante d'un paramètre tel que DATA_BLOCK_ENCODING, qui code les informations en utilisant les valeurs des cellules voisines, ce qui est compréhensible pour les données générées aléatoirement. Si vous utilisez un grand nombre d’objets dupliqués, le gain peut être important. De manière générale, on peut dire que HBase donne l'impression d'une base de données assez sérieuse et bien pensée, qui peut être assez productive lors de la réalisation d'opérations avec de gros blocs de données. Surtout s'il est possible de séparer dans le temps les processus de lecture et d'écriture.
S'il y a quelque chose à votre avis qui n'est pas suffisamment divulgué, je suis prêt à vous le dire plus en détail. Nous vous invitons à partager votre expérience ou à discuter si vous n'êtes pas d'accord avec quelque chose.
Source: habr.com
