

La traduction de l'article a été préparée spécifiquement pour les étudiants du cours .
est un développeur de logiciels, un fanatique de Go et un résolveur de problèmes. Il est également responsable de Prometheus et co-fondateur de l'instrumentation Kubernetes SIG. Dans le passé, il était ingénieur de production chez SoundCloud et dirigeait l'équipe de monitoring chez CoreOS. Travaille actuellement chez Google.
- Ingénieur Infrastructure chez Improbable. Il s'intéresse aux nouvelles technologies et aux problématiques des systèmes distribués. Il possède une expérience en programmation de bas niveau chez Intel, une expérience en tant que contributeur chez Mesos et une expérience de production SRE de classe mondiale chez Improbable. Dédié à l’amélioration du monde des microservices. Ses trois amours : le Golang, l'open source et le volley.
En regardant notre produit phare SpatialOS, vous pouvez deviner qu'Improbable nécessite une infrastructure cloud hautement dynamique à l'échelle mondiale avec des dizaines de clusters Kubernetes. Nous avons été parmi les premiers à utiliser un système de surveillance . Prometheus est capable de suivre des millions de métriques en temps réel et est livré avec un langage de requête puissant qui vous permet d'extraire les informations dont vous avez besoin.
La simplicité et la fiabilité de Prometheus sont l'un de ses principaux avantages. Cependant, une fois dépassé une certaine échelle, nous avons rencontré plusieurs inconvénients. Pour résoudre ces problèmes, nous avons développé est un projet open source créé par Improbable pour transformer de manière transparente les clusters Prometheus existants en un système de surveillance unique avec un stockage illimité de données historiques. Thanos est disponible sur Github .
Nos objectifs avec Thanos
À une certaine échelle, des problèmes surgissent qui dépassent les capacités de Vanilla Prometheus. Comment stocker de manière fiable et économique des pétaoctets de données historiques ? Est-ce possible sans compromettre le temps de réponse ? Est-il possible d'accéder à toutes les métriques situées sur différents serveurs Prometheus avec une seule requête API ? Existe-t-il un moyen de combiner les données répliquées collectées à l'aide de Prometheus HA ?
Pour résoudre ces problèmes, nous avons créé Thanos. Les sections suivantes décrivent comment nous avons abordé ces questions et expliquent nos objectifs.
Interrogation de données à partir de plusieurs instances Prometheus (requête globale)
Prometheus propose une approche fonctionnelle du partitionnement. Même un seul serveur Prometheus offre suffisamment d’évolutivité pour libérer les utilisateurs des complexités du partitionnement horizontal dans presque tous les cas d’utilisation.
Bien qu'il s'agisse d'un excellent modèle de déploiement, il est souvent nécessaire d'accéder aux données sur différents serveurs Prometheus via une seule API ou interface utilisateur – une vue globale. Bien entendu, il est possible d'afficher plusieurs requêtes dans un seul panneau Grafana, mais chaque requête ne peut être exécutée que sur un seul serveur Prometheus. D'un autre côté, avec Thanos, vous pouvez interroger et regrouper les données de plusieurs serveurs Prometheus puisqu'ils sont tous accessibles à partir d'un seul point de terminaison.
Auparavant, pour obtenir une vue globale dans Improbable, nous organisions nos instances Prometheus en plusieurs niveaux. . Cela signifiait créer un méta-serveur Prometheus qui collecte certaines des métriques de chaque serveur feuille.
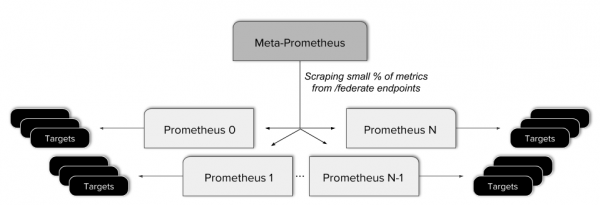
Cette approche s'est avérée problématique. Cela a abouti à des configurations plus complexes, à l'ajout d'un point de défaillance potentiel supplémentaire et à l'application de règles complexes pour garantir que le point de terminaison fédéré reçoit uniquement les données dont il a besoin. De plus, ce type de fédération ne permet pas d’avoir une véritable vision globale, puisque toutes les données ne sont pas disponibles à partir d’une seule requête API.
Une vue unifiée des données collectées sur les serveurs Prometheus à haute disponibilité (HA) est étroitement liée à cela. Le modèle HA de Prometheus collecte indépendamment les données deux fois, ce qui est si simple qu'il ne pourrait pas être plus simple. Cependant, utiliser une vue combinée et dédupliquée des deux flux serait bien plus pratique.
Bien entendu, des serveurs Prometheus hautement disponibles sont nécessaires. Chez Improbable, nous prenons très au sérieux la surveillance des données minute par minute, mais avoir une instance Prometheus par cluster constitue un point de défaillance unique. Toute erreur de configuration ou panne matérielle peut potentiellement entraîner la perte de données importantes. Même un simple déploiement peut entraîner des perturbations mineures dans la collecte des métriques, car les redémarrages peuvent être considérablement plus longs que l'intervalle de scraping.
Stockage fiable des données historiques
Le stockage de métriques bon marché, rapide et à long terme est notre rêve (partagé par la plupart des utilisateurs de Prometheus). Dans Improbable, nous avons été obligés de configurer la période de conservation des métriques à neuf jours (pour Prometheus 1.8). Cela ajoute des limites évidentes à la distance dans laquelle nous pouvons regarder en arrière.
Prometheus 2.0 s'est amélioré à cet égard, puisque le nombre de séries temporelles n'affecte plus les performances globales du serveur (voir. ). Cependant, Prometheus stocke les données sur le disque local. Bien qu'une compression de données à haute efficacité puisse réduire considérablement l'utilisation des disques SSD locaux, il existe toujours une limite à la quantité de données historiques pouvant être stockées.
De plus, chez Improbable, nous nous soucions de la fiabilité, de la simplicité et du coût. Les disques locaux volumineux sont plus difficiles à exploiter et à sauvegarder. Ils coûtent plus cher et nécessitent davantage d’outils de sauvegarde, ce qui entraîne une complexité inutile.
Sous-échantillonnage
Une fois que nous avons commencé à travailler avec des données historiques, nous avons réalisé qu'il existe des difficultés fondamentales avec big-O qui rendent les requêtes de plus en plus lentes à mesure que nous travaillons avec des semaines, des mois et des années de données.
La solution standard à ce problème serait (sous-échantillonnage) - réduction de la fréquence d'échantillonnage du signal. Grâce au sous-échantillonnage, nous pouvons « réduire » à une période plus large et conserver le même nombre d’échantillons, ce qui permet aux requêtes de rester réactives.
Le sous-échantillonnage des anciennes données est une exigence inévitable de toute solution de stockage à long terme et dépasse la portée de Vanilla Prometheus.
Objectifs supplémentaires
L'un des objectifs initiaux du projet Thanos était de s'intégrer de manière transparente à toutes les installations Prometheus existantes. Le deuxième objectif était la facilité d’exploitation avec un minimum de barrières à l’entrée. Toutes les dépendances doivent être facilement satisfaites, aussi bien pour les petits que pour les grands utilisateurs, ce qui signifie également un faible coût de base.
Architecture de Thanos
Après avoir énuméré nos objectifs dans la section précédente, parcourons-les et voyons comment Thanos résout ces problèmes.
Vue globale
Pour obtenir une vue globale des instances Prometheus existantes, nous devons lier un seul point d'entrée de requête à tous les serveurs. C'est exactement ce que fait le composant Thanos. . Il est déployé à côté de chaque serveur Prometheus et agit comme un proxy, servant les données Prometheus locales via l'API gRPC Store, permettant de récupérer les données de séries chronologiques par balise et par plage horaire.
De l’autre côté se trouve le composant Querier évolutif et sans état, qui ne fait guère plus que simplement répondre aux requêtes PromQL via l’API HTTP Prometheus standard. Querier, Sidecar et d'autres composants Thanos communiquent via .
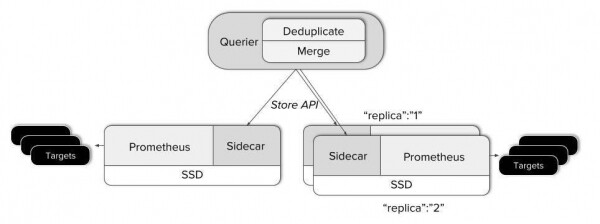
- Querier, dès réception d'une demande, se connecte au serveur API Store correspondant, c'est-à-dire à nos Sidecars et reçoit des données de séries chronologiques des serveurs Prometheus correspondants.
- Après cela, il combine les réponses et exécute une requête PromQL sur celles-ci. Querier peut fusionner à la fois des données disjointes et des données en double provenant des serveurs Prometheus HA.
Cela résout une pièce majeure de notre puzzle : combiner les données de serveurs Prometheus isolés en une seule vue. En fait, Thanos ne peut être utilisé que pour cette fonctionnalité. Aucune modification ne doit être apportée aux serveurs Prometheus existants !
Durée de conservation illimitée !
Cependant, tôt ou tard, nous souhaiterons stocker les données au-delà de la durée de conservation normale de Prometheus. Nous avons choisi le stockage objet pour stocker les données historiques. Il est largement disponible dans n’importe quel cloud ainsi que dans les centres de données sur site et est très rentable. De plus, presque tous les stockages d'objets sont disponibles via la célèbre API S3.
Prometheus écrit les données de la RAM sur le disque environ toutes les deux heures. Le bloc de données stocké contient toutes les données pendant une période de temps déterminée et est immuable. C'est très pratique car Thanos Sidecar peut simplement consulter le répertoire de données Prometheus et, à mesure que de nouveaux blocs deviennent disponibles, les charger dans des compartiments de stockage d'objets.
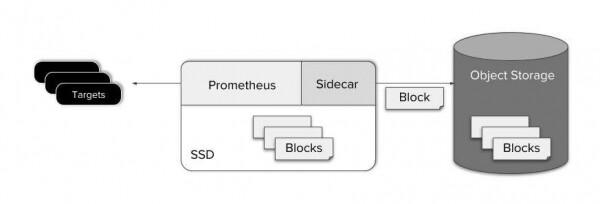
Le chargement dans le stockage d'objets immédiatement après l'écriture sur le disque vous permet également de conserver la simplicité du scraper (Prometheus et Thanos Sidecar). Ce qui simplifie le support, les coûts et la conception du système.
Comme vous pouvez le constater, la sauvegarde des données est très simple. Mais qu’en est-il de l’interrogation des données dans le stockage objet ?
Le composant Thanos Store agit comme un proxy pour récupérer les données du stockage d'objets. Comme Thanos Sidecar, il participe au cluster gossip et implémente l'API Store. De cette façon, le demandeur existant peut le traiter comme un side-car, comme une autre source de données de séries chronologiques – aucune configuration particulière n'est requise.
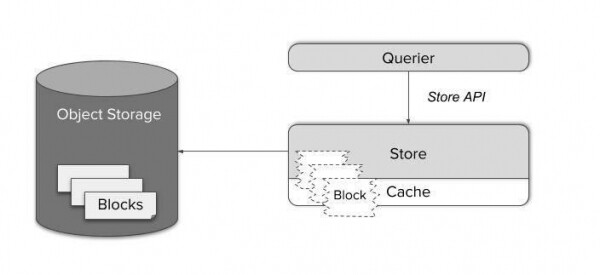
Les blocs de données de séries chronologiques sont constitués de plusieurs fichiers volumineux. Les charger à la demande serait assez inefficace et les mettre en cache localement nécessiterait une énorme quantité de mémoire et d'espace disque.
Au lieu de cela, Store Gateway sait comment gérer le format de stockage Prometheus. Grâce à un planificateur de requêtes intelligent et à la mise en cache uniquement des parties d'index nécessaires des blocs, il est possible de réduire les requêtes complexes à un nombre minimum de requêtes HTTP vers des fichiers de stockage d'objets. De cette manière, vous pouvez réduire le nombre de requêtes de quatre à six ordres de grandeur et atteindre des temps de réponse généralement difficiles à distinguer des requêtes de données sur un SSD local.
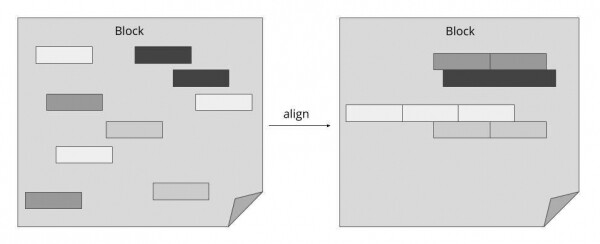
Comme le montre le diagramme ci-dessus, Thanos Querier réduit considérablement le coût par requête des données de stockage d'objets en tirant parti du format de stockage Prometheus et en plaçant côte à côte les données associées. Grâce à cette approche, nous pouvons combiner de nombreuses requêtes uniques en un nombre minimum d'opérations groupées.
Compactage et sous-échantillonnage
Une fois qu’un nouveau bloc de données de séries chronologiques est chargé avec succès dans le stockage d’objets, nous le traitons comme des données « historiques », immédiatement disponibles via Store Gateway.
Cependant, après un certain temps, les blocs provenant d'une seule source (Prometheus avec Sidecar) s'accumulent et n'utilisent plus tout le potentiel d'indexation. Pour résoudre ce problème, nous avons introduit un autre composant appelé Compactor. Il applique simplement le moteur de compactage local de Prometheus aux données historiques dans le stockage d'objets et peut être exécuté comme un simple travail par lots périodique.
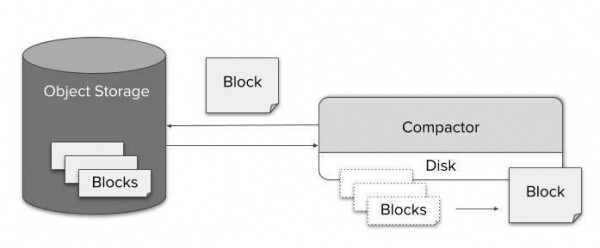
Grâce à une compression efficace, interroger le stockage sur une longue période ne pose pas de problème en termes de taille des données. Cependant, le coût potentiel lié au décompression d'un milliard de valeurs et à leur exécution via un processeur de requêtes entraînera inévitablement une augmentation spectaculaire du temps d'exécution des requêtes. D’un autre côté, comme il y a des centaines de points de données par pixel sur l’écran, il devient même impossible de visualiser les données en pleine résolution. Ainsi, le sous-échantillonnage est non seulement possible, mais n’entraînera pas non plus de perte notable de précision.
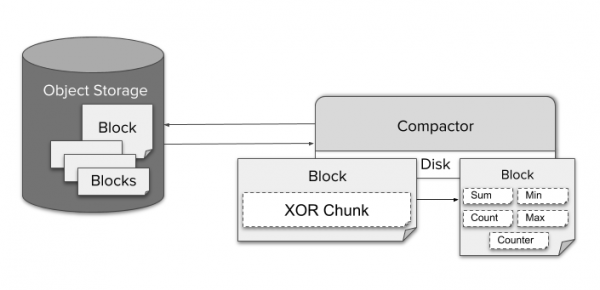
Pour sous-échantillonner les données, Compactor agrège continuellement les données à une résolution de cinq minutes et une heure. Pour chaque morceau brut codé à l'aide de la compression TSDB XOR, différents types de données agrégées sont stockés, tels que le minimum, le maximum ou la somme pour un bloc. Cela permet à Querier de sélectionner automatiquement un agrégat approprié pour une requête PromQL donnée.
Aucune configuration particulière n'est requise pour que l'utilisateur puisse utiliser des données de précision réduite. Querier bascule automatiquement entre différentes résolutions et données brutes lorsque l'utilisateur effectue un zoom avant et arrière. S'il le souhaite, l'utilisateur peut contrôler cela directement via le paramètre « step » dans la requête.
Étant donné que le coût de stockage d'un Go est faible, Thanos stocke par défaut les données brutes, les données de résolution de cinq minutes et d'une heure. Il n'est pas nécessaire de supprimer les données originales.
Règles d'enregistrement
Même avec Thanos, les règles d'enregistrement constituent un élément essentiel de la pile de surveillance. Ils réduisent la complexité, la latence et le coût des requêtes. Ils permettent également aux utilisateurs d'obtenir des données agrégées par métriques. Thanos est basé sur des instances Prometheus vanille, il est donc parfaitement acceptable de stocker des règles d'enregistrement et des règles d'alerte sur un serveur Prometheus existant. Cependant, dans certains cas, cela peut ne pas suffire :
- Alerte et règle globales (par exemple, une alerte lorsqu'un service ne fonctionne pas sur plus de deux clusters sur trois).
- Règle pour les données en dehors du stockage local.
- Le désir de stocker toutes les règles et alertes en un seul endroit.
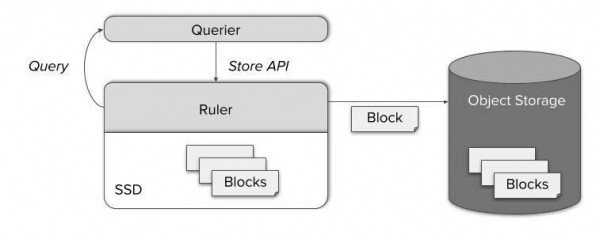
Pour tous ces cas, Thanos inclut un composant distinct appelé Ruler, qui calcule les règles et les alertes via les requêtes Thanos. En fournissant une StoreAPI bien connue, le nœud Query peut accéder à des métriques fraîchement calculées. Plus tard, ils sont également stockés dans le stockage d’objets et mis à disposition via Store Gateway.
Le pouvoir de Thanos
Thanos est suffisamment flexible pour être personnalisé selon vos besoins. Ceci est particulièrement utile lors de la migration depuis la plaine Prometheus. Récapitulons rapidement ce que nous avons appris sur les composants de Thanos avec un exemple rapide. Voici comment emmener votre Prometheus vanille dans le monde du « stockage de métriques illimité » :
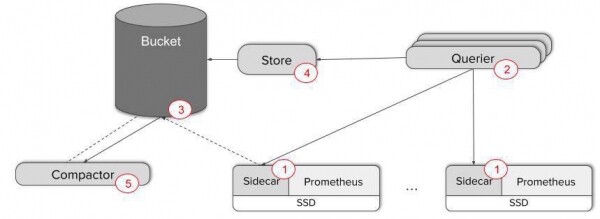
- Ajoutez Thanos Sidecar à vos serveurs Prometheus - par exemple, un conteneur side-car dans un pod Kubernetes.
- Déployez plusieurs répliques Thanos Querier pour pouvoir afficher les données. A ce stade, il est facile d'établir des ragots entre Scraper et Querier. Pour vérifier l'interaction des composants, utilisez la métrique « thanos_cluster_members ».
Ces deux étapes suffisent pour fournir une vue globale et une déduplication transparente des données à partir de répliques potentielles de Prometheus HA ! Connectez simplement vos tableaux de bord au point de terminaison HTTP Querier ou utilisez directement l'interface utilisateur de Thanos.
Toutefois, si vous avez besoin d'une sauvegarde des métriques et d'un stockage à long terme, vous devrez effectuer trois étapes supplémentaires :
- Créez un compartiment AWS S3 ou GCS. Configurez Sidecar pour copier les données dans ces compartiments. Le stockage local des données peut désormais être minimisé.
- Déployez Store Gateway et connectez-le à votre cluster Gossip existant. Vous pouvez désormais interroger les données sauvegardées !
- Déployez Compactor pour améliorer l'efficacité des requêtes sur de longues périodes grâce au compactage et au sous-échantillonnage.
Si vous souhaitez en savoir plus, n'hésitez pas à jeter un œil à notre и !
En seulement cinq étapes, nous avons transformé Prometheus en un système de surveillance fiable avec une vue globale, une durée de stockage illimitée et une haute disponibilité potentielle des métriques.
Pull request : nous avons besoin de vous !
est un projet open source depuis le tout début. L'intégration transparente avec Prometheus et la possibilité d'utiliser seulement une partie de Thanos en font un excellent choix pour faire évoluer votre système de surveillance sans effort.
Nous acceptons toujours les demandes et problèmes de pull GitHub. En attendant, n'hésitez pas à nous contacter via Github Issues ou Slacksi vous avez des questions ou des commentaires, ou si vous souhaitez partager votre expérience d'utilisation ! Si vous aimez ce que nous faisons chez Improbable, n'hésitez pas à nous contacter - !
Source: habr.com
