

VictoriaMetrics, TimescaleDB et InfluxDB ont été comparés dans sur un ensemble de données contenant un milliard de points de données appartenant à 40 XNUMX séries chronologiques uniques.
Il y a quelques années, il y avait une ère de Zabbix. Chaque serveur nu n'avait que quelques indicateurs : utilisation du processeur, utilisation de la RAM, utilisation du disque et utilisation du réseau. De cette façon, les métriques de milliers de serveurs peuvent s'intégrer dans 40 XNUMX séries chronologiques uniques, et Zabbix peut utiliser MySQL comme backend pour les données de séries chronologiques :)
Actuellement seul avec les configurations par défaut, fournit plus de 500 métriques sur l'hôte moyen. Il y a beaucoup de pour diverses bases de données, serveurs Web, systèmes matériels, etc. Ils fournissent tous une variété de mesures utiles. Tous commencer à se fixer divers indicateurs. Il existe Kubernetes avec des clusters et des pods qui exposent de nombreuses métriques. Cela conduit les serveurs à exposer des milliers de métriques uniques par hôte. Ainsi, la série chronologique unique de 40 XNUMX n’est plus de grande puissance. Il devient courant et devrait être facilement géré par n'importe quel TSDB moderne sur un seul serveur.
Quel est le grand nombre de séries chronologiques uniques à l’heure actuelle ? Probablement 400K ou 4M ? Ou 40 m ? Comparons les TSDB modernes à ces chiffres.
Installer un benchmark
est un excellent outil d'analyse comparative pour les TSDB. Il vous permet de générer un nombre arbitraire de métriques en transmettant le nombre requis de séries temporelles divisé par 10 - flag (ancien -scale-var). 10 est le nombre de mesures (métriques) générées sur chaque hôte ou serveur. Les ensembles de données suivants ont été générés à l'aide du TSBS pour le benchmark :
- 400 60 séries chronologiques uniques, intervalle de 3 secondes entre les points de données, les données s'étendent sur 1.7 jours complets, environ XNUMX milliard de points de données au total.
- Série chronologique unique de 4 millions, intervalle de 600 secondes, données s'étendant sur 3 jours complets, nombre total de points de données d'environ 1.7 milliard.
- Série chronologique unique de 40 millions, intervalle de 1 heure, données s'étendant sur 3 jours complets, nombre total de points de données d'environ 2.8 milliards.
Le client et le serveur fonctionnaient sur des instances dédiées dans le cloud Google. Ces instances avaient les configurations suivantes :
- Processeurs virtuels : 16
- RAM: 60 GB
- Stockage : disque dur standard de 1 To. Il offre un débit de lecture/écriture de 120 Mbps, 750 opérations de lecture par seconde et 1,5K écritures par seconde.
Les TSDB ont été extraites des images Docker officielles et exécutées dans Docker avec les configurations suivantes :
VictoriaMetrics :
docker run -it --rm -v /mnt/disks/storage/vmetrics-data:/victoria-metrics-data -p 8080:8080 valyala/victoria-metricsLes valeurs InfluxDB (-e) sont requises pour prendre en charge une puissance élevée. Voir les détails dans ):
docker run -it --rm -p 8086:8086 -e INFLUXDB_DATA_MAX_VALUES_PER_TAG=4000000 -e INFLUXDB_DATA_CACHE_MAX_MEMORY_SIZE=100g -e INFLUXDB_DATA_MAX_SERIES_PER_DATABASE=0 -v /mnt/disks/storage/influx-data:/var/lib/influxdb influxdbTimescaleDB (configuration tirée de déposer):
MEM=`free -m | grep "Mem" | awk ‘{print $7}’`
let "SHARED=$MEM/4"
let "CACHE=2*$MEM/3"
let "WORK=($MEM-$SHARED)/30"
let "MAINT=$MEM/16"
let "WAL=$MEM/16"
docker run -it — rm -p 5432:5432
--shm-size=${SHARED}MB
-v /mnt/disks/storage/timescaledb-data:/var/lib/postgresql/data
timescale/timescaledb:latest-pg10 postgres
-cmax_wal_size=${WAL}MB
-clog_line_prefix="%m [%p]: [%x] %u@%d"
-clogging_collector=off
-csynchronous_commit=off
-cshared_buffers=${SHARED}MB
-ceffective_cache_size=${CACHE}MB
-cwork_mem=${WORK}MB
-cmaintenance_work_mem=${MAINT}MB
-cmax_files_per_process=100Le chargeur de données a été exécuté avec 16 threads parallèles.
Cet article contient uniquement les résultats des tests d'insertion. Les résultats du benchmark sélectif seront publiés dans un article séparé.
400 XNUMX séries chronologiques uniques
Commençons par des éléments simples - 400K. Résultats de référence :
- VictoriaMetrics : 2,6 millions de points de données par seconde ; Utilisation de la RAM : 3 Go ; taille finale des données sur le disque : 965 Mo
- InfluxDB : 1.2 million de points de données par seconde ; Utilisation de la RAM : 8.5 Go ; taille finale des données sur le disque : 1.6 Go
- Échelle de temps : 849 2,5 points de données par seconde ; Utilisation de la RAM : 50 Go ; taille finale des données sur le disque : XNUMX Go
Comme vous pouvez le voir sur les résultats ci-dessus, VictoriaMetrics gagne en termes de performances d'insertion et de taux de compression. Timeline gagne en termes d'utilisation de la RAM, mais il utilise beaucoup d'espace disque - 29 octets par point de données.
Vous trouverez ci-dessous les graphiques d'utilisation du processeur pour chacun des TSDB lors du test :
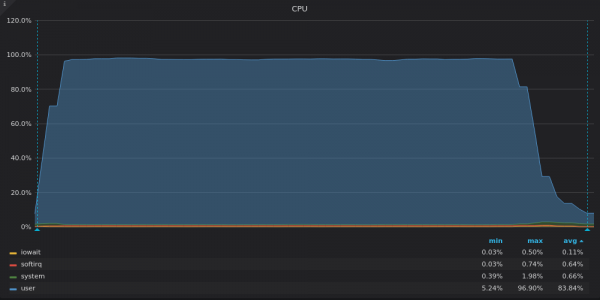
Ci-dessus, une capture d'écran : VictoriaMetrics - Charge du processeur pendant le test d'insertion pour une métrique unique de 400 Ko.
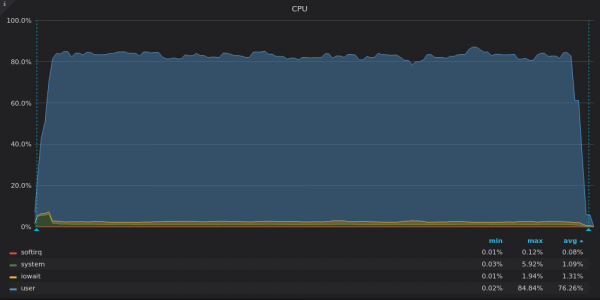
Ci-dessus, une capture d'écran : InfluxDB - Charge du processeur pendant le test d'insertion pour une métrique unique de 400 XNUMX K.
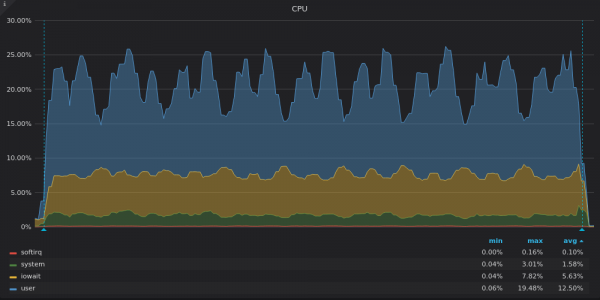
Ci-dessus, une capture d'écran : TimescaleDB - Charge CPU pendant le test d'insertion pour une métrique unique de 400K.
VictoriaMetrics utilise tous les vCPU disponibles, tandis qu'InfluxDB sous-utilise environ 2 vCPU sur 16.
Timescale n’utilise que 3 à 4 des 16 processeurs virtuels. Des proportions élevées d'iowait et de système dans le graphique d'échelle de temps TimescaleDB indiquent un goulot d'étranglement dans le sous-système d'entrée/sortie (E/S). Examinons les graphiques d'utilisation de la bande passante du disque :
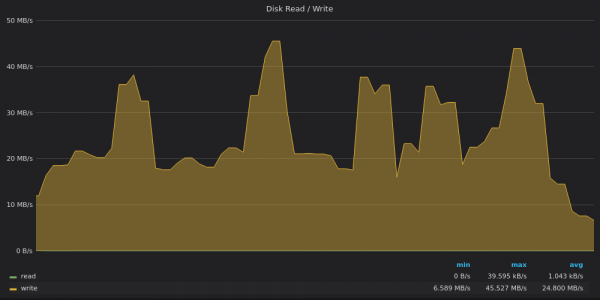
Ci-dessus, une capture d'écran : VictoriaMetrics - Utilisation de la bande passante du disque dans le test d'insertion pour des métriques uniques 400K.
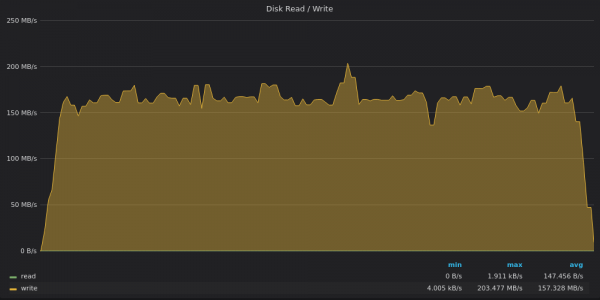
Ci-dessus, une capture d'écran : InfluxDB - Utilisation de la bande passante du disque lors du test d'insertion pour des métriques uniques 400K.
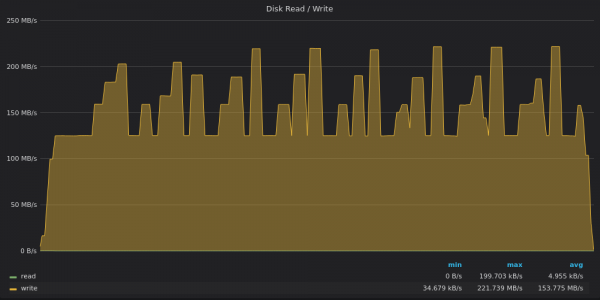
Ci-dessus, une capture d'écran : TimescaleDB - Utilisation de la bande passante du disque lors du test d'insertion pour des métriques uniques 400 XNUMX.
VictoriaMetrics enregistre les données à 20 Mbps avec des pics jusqu'à 45 Mbps. Les pics correspondent à de grandes fusions partielles dans l'arbre .
InfluxDB écrit des données à 160 Mo/s, tandis qu'un disque de 1 To débit d'écriture 120 Mo/s.
TimescaleDB est limité à un débit d'écriture de 120 Mbps, mais il dépasse parfois cette limite et atteint 220 Mbps en valeurs maximales. Ces pics correspondent aux vallées d’utilisation insuffisante du processeur dans le graphique précédent.
Examinons les graphiques d'utilisation des entrées/sorties (E/S) :
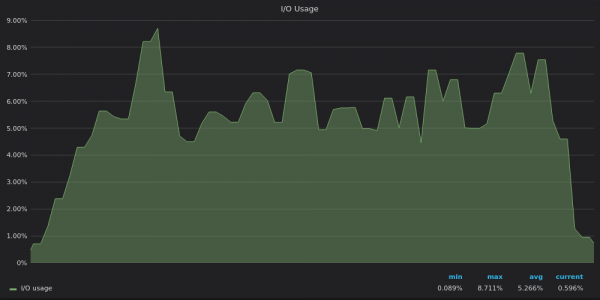
Ci-dessus, une capture d'écran : VictoriaMetrics – Insérer l'utilisation des E/S de test pour 400 XNUMX métriques uniques.
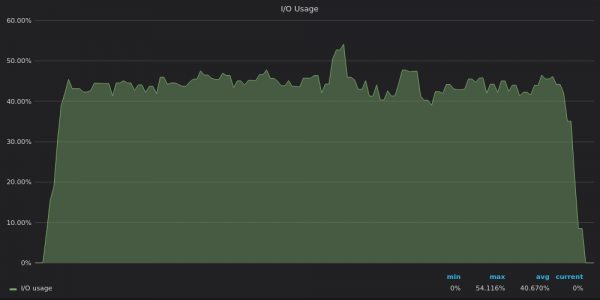
Ci-dessus, une capture d'écran : InfluxDB - Insérer l'utilisation des E/S de test pour 400 XNUMX métriques uniques.
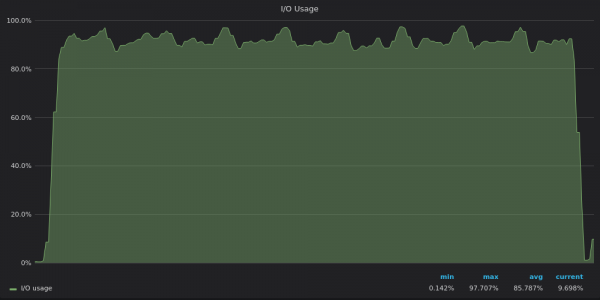
Ci-dessus, une capture d'écran : TimescaleDB - Insérer l'utilisation des E/S de test pour 400 XNUMX métriques uniques.
Il est désormais clair que TimescaleDB atteint sa limite d'E/S et ne peut donc pas utiliser les 12 vCPU restants.
Série chronologique unique 4M
Les séries chronologiques 4M semblent un peu difficiles. Mais nos concurrents réussissent cet examen. Résultats de référence :
- VictoriaMetrics : 2,2 millions de points de données par seconde ; Utilisation de la RAM : 6 Go ; taille finale des données sur le disque : 3 Go.
- InfluxDB : 330 20,5 points de données par seconde ; Utilisation de la RAM : 18,4 Go ; taille finale des données sur le disque : XNUMX Go.
- TimescaleDB : 480 2,5 points de données par seconde ; Utilisation de la RAM : 52 Go ; taille finale des données sur le disque : XNUMX Go.
Les performances d'InfluxDB sont passées de 1,2 million de points de données par seconde pour une série chronologique de 400 330 à 4 XNUMX points de données par seconde pour une série chronologique de XNUMX millions. Il s'agit d'une perte de performances importante par rapport aux autres concurrents. Examinons les graphiques d'utilisation du processeur pour comprendre la cause première de cette perte :
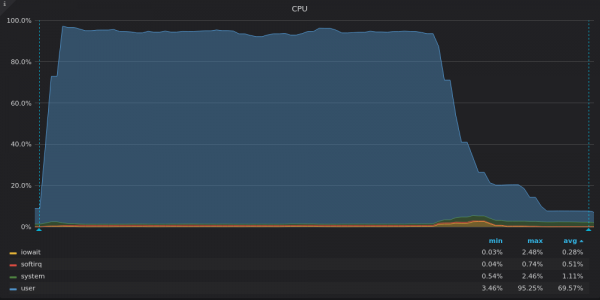
Ci-dessus, une capture d'écran : VictoriaMetrics - Utilisation du processeur pendant le test d'insertion pour une série temporelle unique de 4 M.
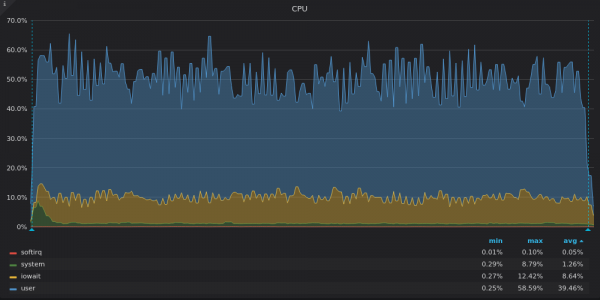
Ci-dessus, une capture d'écran : InfluxDB - Utilisation du processeur pendant le test d'insertion pour une série temporelle unique de 4 M.
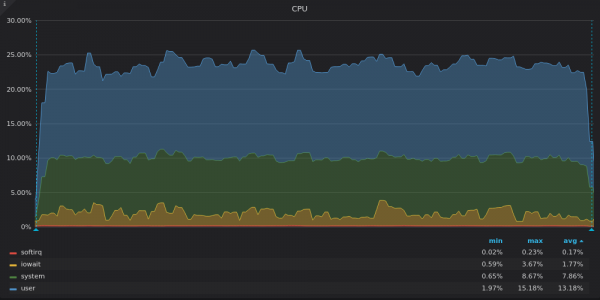
Ci-dessus, une capture d'écran : TimescaleDB - Utilisation du processeur pendant le test d'insertion pour une série temporelle unique de 4 M.
VictoriaMetrics utilise presque toute la puissance de l'unité de traitement (CPU). La goutte à la fin correspond aux fusions LSM restantes une fois que toutes les données ont été insérées.
InfluxDB n'utilise que 8 des 16 vCPU, tandis que TimsecaleDB utilise 4 des 16 vCPU. Quel est le point commun entre leurs graphiques ? Part élevée iowait, ce qui indique à nouveau un goulot d'étranglement d'E/S.
TimescaleDB a une part élevée system. Nous supposons qu'une puissance élevée a entraîné de nombreux appels système ou de nombreux .
Regardons les graphiques de débit du disque :
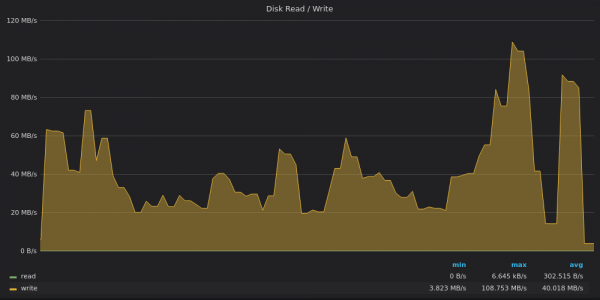
Ci-dessus, une capture d'écran : VictoriaMetrics - Utilisation de la bande passante du disque pour insérer 4 M de métriques uniques.
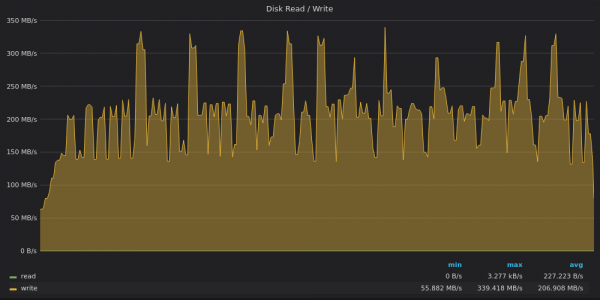
Ci-dessus, une capture d'écran : InfluxDB - Utilisation de la bande passante du disque pour insérer 4 M de métriques uniques.
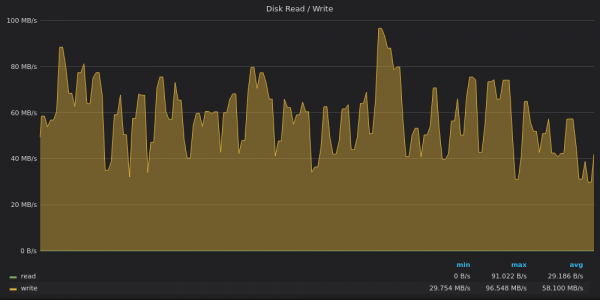
Ci-dessus, une capture d'écran : TimescaleDB - Utilisation de la bande passante du disque pour insérer 4 M de métriques uniques.
VictoriaMetrics a atteint une limite de 120 Mo/s en pointe, tandis que la vitesse d'écriture moyenne était de 40 Mo/s. Il est probable que plusieurs fusions lourdes de LSM aient été réalisées pendant le pic.
InfluxDB atteint à nouveau un débit d'écriture moyen de 200 Mo/s avec des pics allant jusqu'à 340 Mo/s sur un disque avec une limite d'écriture de 120 Mo/s :)
TimescaleDB n'est plus limité au disque. Il semble être limité par autre chose lié à une proportion élevée системной Charge du processeur.
Regardons les graphiques d'utilisation des E/S :
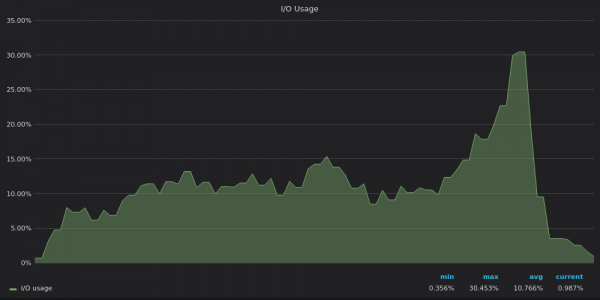
Ci-dessus, une capture d'écran : VictoriaMetrics - Utilisation des E/S pendant le test d'insertion pour une série temporelle unique de 4 M.
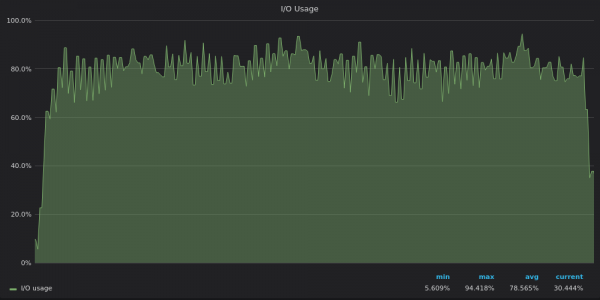
Ci-dessus, une capture d'écran : InfluxDB - Utilisation des E/S pendant le test d'insertion pour une série temporelle unique de 4 M.
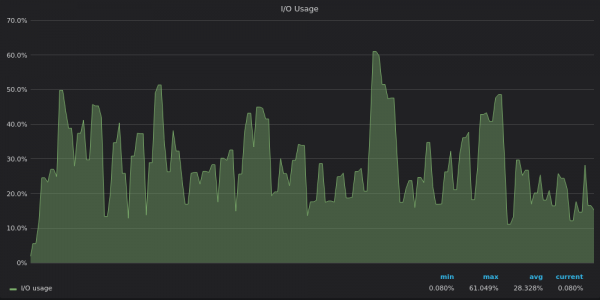
Ci-dessus, une capture d'écran : TimescaleDB - Utilisation des E/S pendant le test d'insertion pour une série temporelle unique de 4 M.
Les modèles d'utilisation des E/S reflètent ceux de la bande passante du disque : InfluxDB est limité en E/S, tandis que VictoriaMetrics et TimescaleDB disposent de ressources d'E/S de rechange.
40 millions de séries chronologiques uniques
Une série chronologique unique de 40 millions était trop grande pour InfluxDB :)
Résultats de référence :
- VictoriaMetrics : 1,7 million de points de données par seconde ; Utilisation de la RAM : 29 Go ; Utilisation de l'espace disque : 17 Go.
- InfluxDB : n'a pas été terminé car il nécessitait plus de 60 Go de RAM.
- TimescaleDB : 330 2,5 points de données par seconde, utilisation de la RAM : 84 Go ; Utilisation de l'espace disque : XNUMX Go.
TimescaleDB affiche une utilisation de la RAM exceptionnellement faible et stable à 2,5 Go – la même que pour les métriques uniques 4M et 400K.
VictoriaMetrics a lentement évolué à un rythme de 100 40 points de données par seconde jusqu'à ce que les 1,5 millions de noms de métriques balisés soient traités. Il a ensuite atteint un taux d'insertion soutenu de 2,0 à 1,7 millions de points de données par seconde, le résultat final étant donc de XNUMX million de points de données par seconde.
Les graphiques pour les séries chronologiques uniques de 40 millions sont similaires aux graphiques pour les séries chronologiques uniques de 4 millions, alors ignorons-les.
résultats
- Les TSDB modernes sont capables de traiter des insertions pour des millions de séries temporelles uniques sur un seul serveur. Dans le prochain article, nous testerons dans quelle mesure les TSDB effectuent une sélection sur des millions de séries temporelles uniques.
- Une utilisation insuffisante du processeur indique généralement un goulot d'étranglement d'E/S. Cela peut également indiquer que le blocage est trop grossier, avec seulement quelques threads pouvant s'exécuter à la fois.
- Le goulot d'étranglement des E/S existe, en particulier dans le stockage non SSD tel que les périphériques de bloc virtualisés des fournisseurs de cloud.
- VictoriaMetrics offre la meilleure optimisation pour un stockage lent et à faible E/S. Il offre la meilleure vitesse et le meilleur taux de compression.
Télécharger et essayez-le sur vos données. Le binaire statique correspondant est disponible sur .
En savoir plus sur VictoriaMetrics dans ce .
Mise à jour : publiée avec des résultats reproductibles.
Mise à jour n°2 : Lire aussi .
Mise à jour n°3 : !
Телеграм чат :
Source: habr.com
