

Si au début de la pièce vous dites qu'il y a du code C++ accroché au mur, alors à la fin, il vous tirera forcément une balle dans le pied.
Bjarne Stroustrup
Du 31 octobre au 1er novembre, la conférence C++ Russia Piter s'est tenue à Saint-Pétersbourg - l'une des conférences de programmation à grande échelle en Russie, organisée par le groupe JUG Ru. Les conférenciers invités comprennent des membres du comité des normes C++, des conférenciers CppCon, des auteurs de livres O'Reilly et des responsables de projets tels que LLVM, libc++ et Boost. La conférence s'adresse aux développeurs C++ expérimentés qui souhaitent approfondir leur expertise et échanger leurs expériences en matière de communication en direct. Les étudiants, les étudiants diplômés et les professeurs d'université bénéficient de très belles réductions.
L'édition de Moscou de la conférence pourra être visitée dès avril de l'année prochaine, mais en attendant, nos étudiants vous raconteront les choses intéressantes qu'ils ont apprises lors du dernier événement.

Photos de
Qui sommes-nous
Deux étudiants de l'École supérieure d'économie de l'Université nationale de recherche de Saint-Pétersbourg ont travaillé sur ce poste :
- Liza Vasilenko est une étudiante de 4e année de premier cycle qui étudie les langages de programmation dans le cadre du programme de mathématiques appliquées et informatique. M'étant familiarisé avec le langage C++ dès ma première année d'université, j'ai ensuite acquis de l'expérience en travaillant avec celui-ci grâce à des stages en industrie. Ma passion pour les langages de programmation en général et la programmation fonctionnelle en particulier a marqué la sélection des rapports de la conférence.
- Danya Smirnov est étudiante en 1ère année du programme de master « Programmation et analyse de données ». Alors que j'étais encore à l'école, j'ai écrit des problèmes de l'Olympiade en C++, puis il s'est avéré que cette langue revenait constamment dans les activités éducatives et devenait finalement la principale langue de travail. J'ai décidé de participer à la conférence pour améliorer mes connaissances et également découvrir de nouvelles opportunités.
Dans le bulletin d'information, la direction du corps professoral partage souvent des informations sur les événements éducatifs liés à notre spécialité. En septembre, nous avons vu des informations sur C++ Russie et avons décidé de nous inscrire comme auditeurs. C'est notre première expérience de participation à de telles conférences.
Structure de la conférence
Доклады
Pendant deux jours, les experts ont lu 30 rapports couvrant de nombreux sujets d'actualité : utilisations ingénieuses des fonctionnalités du langage pour résoudre des problèmes appliqués, mises à jour du langage à venir en relation avec la nouvelle norme, compromis dans la conception C++ et précautions à prendre lors de l'utilisation de leurs conséquences, exemples. d'architecture de projet intéressante, ainsi que quelques détails sous le capot de l'infrastructure linguistique. Trois représentations ont eu lieu simultanément, le plus souvent deux en russe et une en anglais.
Zones de discussion
Après le discours, toutes les questions non posées et les discussions inachevées ont été transférées dans des zones spécialement désignées pour la communication avec les orateurs, équipées de tableaux de signalisation. Une bonne façon de combler la pause entre les discours par une conversation agréable.
Lightning Talks et discussions informelles
Si vous souhaitez faire un bref rapport, vous pouvez vous inscrire sur le tableau blanc pour le Lightning Talk du soir et disposer de cinq minutes pour parler de tout ce qui concerne le sujet de la conférence. Par exemple, une introduction rapide aux désinfectants pour C++ (pour certains, c'était nouveau) ou une histoire sur un bug dans la génération d'onde sinusoïdale qui ne peut être qu'entendu, mais pas vu.
Un autre format est la table ronde « Avec un comité de cœur à cœur ». Sur scène se trouvent quelques membres du comité de normalisation, sur le projecteur il y a une cheminée (officiellement - pour créer une ambiance sincère, mais la raison "parce que TOUT EST EN FEU" semble plus drôle), des questions sur le standard et la vision générale du C++ , sans discussions techniques animées ni vacances. Il s'est avéré que le comité contient également des personnes vivantes qui peuvent ne pas être complètement sûres de quelque chose ou ne pas savoir quelque chose.
Pour les fans de Holivars, le troisième événement est resté - la session BOF « Go vs. C++ ». Nous prenons un amoureux de Go, un amoureux de C++, avant le début de la session ils préparent ensemble 100500 XNUMX slides sur un sujet (comme les problèmes avec les packages en C++ ou le manque de génériques en Go), puis ils ont une discussion animée entre eux et avec le public, et le public essaie de comprendre deux points de vue à la fois. Si un holivar démarre hors contexte, le modérateur intervient et réconcilie les parties. Ce format est addictif : plusieurs heures après le début, seule la moitié des slides étaient réalisées. La fin a dû être grandement accélérée.
Stands partenaires
Les partenaires de la conférence étaient représentés dans les halls - sur les stands, ils parlaient des projets en cours, proposaient des stages et des emplois, organisaient des quiz et des petits concours, et tiraient également au sort de jolis prix. Dans le même temps, certaines entreprises ont même proposé de passer par les premières étapes d'entretiens, ce qui pourrait être utile à ceux qui venaient non seulement pour écouter des reportages.
Détails techniques des rapports
Nous avons écouté les reportages les deux jours. Il était parfois difficile de choisir un rapport parmi les rapports parallèles - nous avons convenu de nous séparer et d'échanger les connaissances acquises pendant les pauses. Et même ainsi, il semble que beaucoup de choses soient laissées de côté. Nous aimerions ici parler du contenu de certains des rapports que nous avons trouvés les plus intéressants.
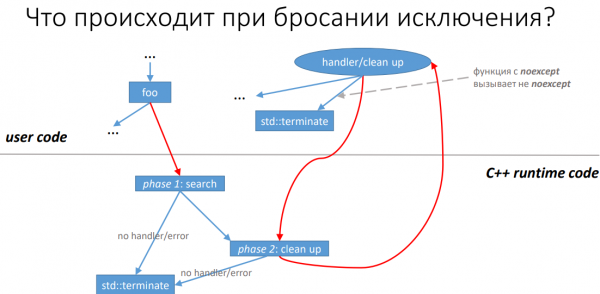
Les exceptions en C++ au prisme des optimisations du compilateur, Roman Rusyaev
Glisser de
Comme le titre l'indique, Roman a envisagé de travailler avec des exceptions en utilisant LLVM comme exemple. Dans le même temps, pour ceux qui n'utilisent pas Clang dans leur travail, le rapport peut quand même donner une idée de la manière dont le code pourrait potentiellement être optimisé. En effet, les développeurs de compilateurs et les bibliothèques standard correspondantes communiquent entre eux et de nombreuses solutions réussies peuvent coïncider.
Ainsi, pour gérer une exception, vous devez faire beaucoup de choses : appeler le code de gestion (le cas échéant) ou libérer des ressources au niveau actuel et faire monter la pile plus haut. Tout cela conduit au fait que le compilateur ajoute des instructions supplémentaires pour les appels susceptibles de générer des exceptions. Par conséquent, si l’exception n’est pas réellement déclenchée, le programme effectuera quand même des actions inutiles. Afin de réduire d'une manière ou d'une autre la surcharge, LLVM dispose de plusieurs heuristiques pour déterminer les situations dans lesquelles le code de gestion des exceptions n'a pas besoin d'être ajouté ou le nombre d'instructions « supplémentaires » peut être réduit.
L'intervenant en examine une douzaine et montre aussi bien des situations où elles permettent d'accélérer l'exécution d'un programme que celles où ces méthodes ne sont pas applicables.
Ainsi, Roman Rusyaev amène les étudiants à la conclusion que le code contenant la gestion des exceptions ne peut pas toujours être exécuté sans surcharge, et donne le conseil suivant :
- lors du développement de bibliothèques, il vaut la peine d'abandonner les exceptions en principe ;
- si des exceptions sont encore nécessaires, alors, dans la mesure du possible, il vaut la peine d'ajouter des modificateurs nosauf (et const) partout afin que le compilateur puisse optimiser autant que possible.
D’une manière générale, l’orateur a confirmé l’opinion selon laquelle il est préférable d’utiliser les exceptions au minimum, voire de les abandonner complètement.
Les diapositives du rapport sont disponibles au lien suivant :
Générateurs, coroutines et autres douceurs qui déroulent le cerveau, Adi Shavit

Glisser de
L'un des nombreux rapports de cette conférence consacrée aux innovations en C++20 a été mémorable non seulement par sa présentation colorée, mais aussi par son identification claire des problèmes existants avec la logique de traitement des collections (boucle for, rappels).
Adi Shavit souligne ce qui suit : les méthodes actuellement disponibles parcourent toute la collection et ne donnent pas accès à un état intermédiaire interne (ou elles le font dans le cas des rappels, mais avec un grand nombre d'effets secondaires désagréables, comme le Callback Hell). . Il semblerait qu'il y ait des itérateurs, mais même avec eux, tout n'est pas si fluide : il n'y a pas de points d'entrée et de sortie communs (begin → end versus rbegin → rend et ainsi de suite), on ne sait pas combien de temps nous allons itérer ? À partir de C++20, ces problèmes sont résolus !
Première option : les gammes. En encapsulant les itérateurs, nous obtenons une interface commune pour le début et la fin d'une itération, et nous obtenons également la possibilité de composer. Tout cela facilite la création de pipelines de traitement de données à part entière. Mais tout n'est pas aussi fluide : une partie de la logique de calcul se situe à l'intérieur de l'implémentation d'un itérateur spécifique, ce qui peut compliquer la compréhension et le débogage du code.

Glisser de
Eh bien, pour ce cas, C++20 a ajouté des coroutines (fonctions dont le comportement est similaire aux générateurs en Python) : l'exécution peut être différée en renvoyant une valeur actuelle tout en préservant un état intermédiaire. Ainsi, nous parvenons non seulement à travailler avec les données telles qu'elles apparaissent, mais également à encapsuler toute la logique dans une coroutine spécifique.
Mais il y a un problème : pour le moment, ils ne sont que partiellement pris en charge par les compilateurs existants, et ne sont pas non plus implémentés aussi parfaitement que nous le souhaiterions : par exemple, cela ne vaut pas encore la peine d'utiliser des références et des objets temporaires dans les coroutines. De plus, il existe certaines restrictions sur ce que peuvent être des coroutines, et les fonctions constexpr, les constructeurs/destructeurs et main ne sont pas inclus dans cette liste.
Ainsi, les coroutines résolvent une partie importante des problèmes grâce à la simplicité de la logique de traitement des données, mais leurs implémentations actuelles nécessitent des améliorations.
Matériaux:
- Diapositives de C++ Russie -
Astuces C++ de Yandex.Taxi, Anton Polukhin
Dans mes activités professionnelles, je dois parfois implémenter des choses purement auxiliaires : un wrapper entre l'interface interne et l'API d'une bibliothèque, la journalisation ou l'analyse. Dans ce cas, aucune optimisation supplémentaire n’est généralement nécessaire. Mais que se passerait-il si ces composants étaient utilisés dans certains des services les plus populaires de RuNet ? Dans une telle situation, vous devrez traiter seul des téraoctets par heure de logs ! Ensuite, chaque milliseconde compte et vous devez donc recourir à diverses astuces - Anton Polukhin en a parlé.
L’exemple le plus intéressant est peut-être l’implémentation du modèle pointeur vers l’implémentation (pimpl).
#include <third_party/json.hpp> //PROBLEMS!
struct Value {
Value() = default;
Value(Value&& other) = default;
Value& operator=(Value&& other) = default;
~Value() = default;
std::size_t Size() const { return data_.size(); }
private:
third_party::Json data_;
};Dans cet exemple, je souhaite d'abord me débarrasser des fichiers d'en-tête des bibliothèques externes - cela sera compilé plus rapidement et vous pourrez vous protéger contre d'éventuels conflits de noms et autres erreurs similaires.
D'accord, nous avons déplacé #include vers le fichier .cpp : nous avons besoin d'une déclaration directe de l'API encapsulée, ainsi que de std::unique_ptr. Nous avons désormais des allocations dynamiques et d'autres choses désagréables comme des données dispersées dans un ensemble de données et des garanties réduites. std::aligned_storage peut vous aider avec tout cela.
struct Value {
// ...
private:
using JsonNative = third_party::Json;
const JsonNative* Ptr() const noexcept;
JsonNative* Ptr() noexcept;
constexpr std::size_t kImplSize = 32;
constexpr std::size_t kImplAlign = 8;
std::aligned_storage_t<kImplSize, kImplAlign> data_;
};Le seul problème : vous devez spécifier la taille et l'alignement de chaque wrapper - créons notre modèle de bouton avec des paramètres , utilisez des valeurs arbitraires et ajoutez une vérification au destructeur pour que tout soit correct :
~FastPimpl() noexcept {
validate<sizeof(T), alignof(T)>();
Ptr()->~T();
}
template <std::size_t ActualSize, std::size_t ActualAlignment>
static void validate() noexcept {
static_assert(
Size == ActualSize,
"Size and sizeof(T) mismatch"
);
static_assert(
Alignment == ActualAlignment,
"Alignment and alignof(T) mismatch"
);
}Étant donné que T est déjà défini lors du traitement du destructeur, ce code sera analysé correctement et au stade de la compilation, il affichera les valeurs de taille et d'alignement requises qui doivent être saisies comme erreurs. Ainsi, au prix d'une exécution de compilation supplémentaire, nous nous débarrassons de l'allocation dynamique des classes encapsulées, cachons l'API dans un fichier .cpp avec l'implémentation et obtenons également une conception plus adaptée à la mise en cache par le processeur.
La journalisation et l'analyse semblent moins impressionnantes et ne seront donc pas mentionnées dans cette revue.
Les diapositives du rapport sont disponibles au lien suivant :
Techniques modernes pour garder votre code SEC, Björn Fahller
Dans cette présentation, Björn Fahller montre différentes manières de lutter contre les défauts stylistiques des contrôles d'état répétés :
assert(a == IDLE || a == CONNECTED || a == DISCONNECTED);Semble familier? En utilisant plusieurs techniques C++ puissantes introduites dans les normes récentes, vous pouvez implémenter avec élégance les mêmes fonctionnalités sans aucune perte de performances. Comparer:
assert(a == any_of(IDLE, CONNECTED, DISCONNECTED));Pour gérer un nombre non fixe de vérifications, vous devez immédiatement utiliser des modèles variadiques et des expressions de pliage. Supposons que nous souhaitions vérifier l'égalité de plusieurs variables avec l'élément state_type de l'énumération. La première chose qui me vient à l’esprit est d’écrire une fonction d’assistance is_any_of :
enum state_type { IDLE, CONNECTED, DISCONNECTED };
template <typename ... Ts>
bool is_any_of(state_type s, const Ts& ... ts) {
return ((s == ts) || ...);
}
Ce résultat intermédiaire est décevant. Pour l'instant, le code n'est pas plus lisible :
assert(is_any_of(state, IDLE, DISCONNECTING, DISCONNECTED)); Les paramètres de modèle non-type aideront à améliorer un peu la situation. Avec leur aide, nous transférerons les éléments énumérables de l'énumération vers la liste des paramètres du modèle :
template <state_type ... states>
bool is_any_of(state_type t) {
return ((t == states) | ...);
}
assert(is_any_of<IDLE, DISCONNECTING, DISCONNECTED>(state)); En utilisant auto dans un paramètre de modèle non-type (C++17), l'approche se généralise simplement aux comparaisons non seulement avec les éléments state_type, mais également avec les types primitifs qui peuvent être utilisés comme paramètres de modèle non-type :
template <auto ... alternatives, typename T>
bool is_any_of(const T& t) {
return ((t == alternatives) | ...);
}Grâce à ces améliorations successives, la syntaxe fluide souhaitée pour les contrôles est obtenue :
template <class ... Ts>
struct any_of : private std::tuple<Ts ...> {
// поленимся и унаследуем конструкторы от tuple
using std::tuple<Ts ...>::tuple;
template <typename T>
bool operator ==(const T& t) const {
return std::apply(
[&t](const auto& ... ts) {
return ((ts == t) || ...);
},
static_cast<const std::tuple<Ts ...>&>(*this));
}
};
template <class ... Ts>
any_of(Ts ...) -> any_of<Ts ... >;
assert(any_of(IDLE, DISCONNECTING, DISCONNECTED) == state);
Dans cet exemple, le guide de déduction sert à suggérer les paramètres du modèle de structure souhaités au compilateur, qui connaît les types des arguments du constructeur.
De plus, c'est plus intéressant. Bjorn enseigne comment généraliser le code résultant pour les opérateurs de comparaison au-delà de ==, puis pour les opérations arbitraires. En cours de route, des fonctionnalités telles que l'attribut no_unique_address (C++20) et les paramètres de modèle dans les fonctions lambda (C++20) sont expliquées à l'aide d'exemples d'utilisation. (Oui, maintenant la syntaxe lambda est encore plus facile à retenir - ce sont quatre paires consécutives de parenthèses de toutes sortes.) La solution finale utilisant des fonctions comme détails du constructeur me réchauffe vraiment l'âme, sans parler de l'expression tuple dans les meilleures traditions de lambda calcul.
À la fin, n’oubliez pas de le peaufiner :
- N'oubliez pas que les lambdas sont constexpr gratuitement ;
- Ajoutons un transfert parfait et examinons sa syntaxe laide par rapport au pack de paramètres dans la fermeture lambda ;
- Donnons au compilateur plus de possibilités d'optimisation avec nosauf conditionnel ;
- Prenons soin d'une sortie d'erreur plus compréhensible dans les modèles grâce aux valeurs de retour explicites des lambdas. Cela forcera le compilateur à effectuer davantage de vérifications avant que la fonction modèle ne soit réellement appelée - au stade de la vérification du type.
Pour plus de détails, veuillez vous référer au matériel de cours :
- Diapositives du rapport :
Nos impressions
Notre première participation à C++ Russie a été mémorable par son intensité. J'ai eu l'impression de C++ Russie comme d'un événement sincère, où la frontière entre formation et communication en direct est presque imperceptible. De l'humeur des intervenants aux concours des partenaires de l'événement, tout est propice à des discussions animées. Le contenu de la conférence, composé de rapports, couvre un éventail assez large de sujets, notamment les innovations C++, les études de cas de grands projets et les considérations architecturales idéologiques. Mais il serait injuste d'ignorer la composante sociale de l'événement, qui permet de surmonter les barrières linguistiques non seulement en ce qui concerne le C++.
Nous remercions les organisateurs de la conférence pour l’opportunité de participer à un tel événement !
Vous avez peut-être vu le message des organisateurs sur le passé, le présent et l'avenir de C++ Russie .
Merci d’avoir lu et nous espérons que notre récit des événements vous a été utile !
Source: habr.com
