


Op 9 jannewaris waard Pandas 1.0.0rc frijlitten. De foarige ferzje fan 'e bibleteek is 0.25.
De earste grutte release befettet in protte geweldige nije funksjes, ynklusyf ferbettere automatyske gearfetting fan gegevensframe, mear útfierformaten, nije gegevenstypen, en sels in nije dokumintaasjeside.
Alle feroarings kinne wurde besjoen , yn it artikel sille wy ús beheine ta in lyts, minder technyske resinsje fan 'e wichtichste dingen.
Jo kinne de bibleteek lykas gewoanlik ynstallearje mei pip, mar sûnt op it stuit fan skriuwen is Pandas 1.0 noch frijlitting kandidaat, moatte jo de ferzje eksplisyt oantsjutte:
pip install --upgrade pandas==1.0.0rc0Wês foarsichtich: om't dit in wichtige release is, kin de fernijing de âlde koade brekke!
Trouwens, stipe foar Python 2 is sûnt dizze ferzje folslein beëinige (wat kin in goede reden wêze — ca. oersetting). Pandas 1.0 fereasket op syn minst Python 3.6+, dus as jo net wis binne, kontrolearje hokker jo ynstalleare hawwe:
$ pip --version
pip 19.3.1 from /usr/local/lib/python3.7/site-packages/pip (python 3.7)
$ python --version
Python 3.7.5De maklikste manier om de Pandas-ferzje te kontrolearjen is dit:
>>> import pandas as pd
>>> pd.__version__
1.0.0rc0Ferbettere automatyske gearfetting mei DataFrame.info
Myn favorite ynnovaasje wie de fernijing fan 'e metoade DataFrame.info. De funksje is folle lêsber wurden, wat it proses fan gegevensferkenning noch makliker makket:
>>> df = pd.DataFrame({
...: 'A': [1,2,3],
...: 'B': ["goodbye", "cruel", "world"],
...: 'C': [False, True, False]
...:})
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 3 non-null int64
1 B 3 non-null object
2 C 3 non-null object
dtypes: int64(1), object(2)
memory usage: 200.0+ bytesTafels útfiere yn Markdown-formaat
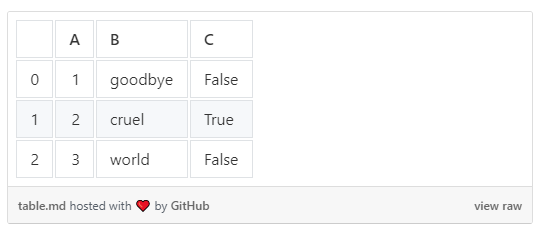
In like noflike ynnovaasje is de mooglikheid om dataframes te eksportearjen nei Markdown-tabellen mei help fan DataFrame.to_markdown.
>>> df.to_markdown()
| | A | B | C |
|---:|----:|:--------|:------|
| 0 | 1 | goodbye | False |
| 1 | 2 | cruel | True |
| 2 | 3 | world | False |Dit makket it folle makliker om tabellen te publisearjen op siden lykas Medium mei github-gists.
Nije soarten foar snaren en booleans
De Pandas 1.0-release hat ek nij tafoege eksperiminteel soarten. Har API kin noch feroarje, dus brûk it mei foarsichtigens. Mar yn 't algemien advisearret Pandas om nije soarten te brûken wêr't it ek sin makket.
Foar no moat de cast eksplisyt dien wurde:
>>> B = pd.Series(["goodbye", "cruel", "world"], dtype="string")
>>> C = pd.Series([False, True, False], dtype="bool")
>>> df.B = B, df.C = C
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 3 non-null int64
1 B 3 non-null string
2 C 3 non-null bool
dtypes: int64(1), object(1), string(1)
memory usage: 200.0+ bytesNotysje hoe't de kolom Dtype toant nije typen - string и bool.
De meast brûkbere funksje fan it nije tekenrige type is de mooglikheid om te selektearjen allinnich rige kolommen fan dataframes. Dit kin it parsearjen fan tekstgegevens folle makliker meitsje:
df.select_dtypes("string")Eartiids koenen rige kolommen net selektearre wurde sûnder eksplisyt oantsjutte nammen.
Jo kinne mear lêze oer nije soarten .
Tankewol foar it lêzen! De folsleine list fan feroarings, lykas al neamd, kin wurde besjoen .
Boarne: www.habr.com
