


Op hokker prinsipes is in ideaal Data Warehouse boud?
Fokus op saaklike wearde en analytyk by it ûntbrekken fan boilerplate-koade. DWH beheare as koadebase: ferzje, resinsje, automatisearre testen en CI. Modulêr, útwreidber, iepen boarne en mienskip. Brûkersfreonlike dokumintaasje en fisualisaasje fan ôfhinklikens (Data Lineage).
Mear oer dit alles en oer de rol fan DBT yn it Big Data & Analytics-ekosysteem - wolkom by kat.
Hallo allegear
Artemy Kozyr is yn kontakt. Foar mear as 5 jier haw ik wurke mei data warehouses, it bouwen fan ETL / ELT, lykas data analytics en fisualisaasje. Ik wurkje op it stuit yn , Ik les by OTUS op in kursus , en hjoed wol ik in artikel mei jo diele dat ik skreau yn ôfwachting fan it begjin nije ynskriuwing foar de kursus.
Koarte resinsje
It DBT-kader giet alles oer de T yn it ELT (Extract - Transform - Load) akronym.
Mei de komst fan sokke produktive en skalberbere analytyske databases as BigQuery, Redshift, Snowflake, wie d'r gjin punt om transformaasjes bûten it Data Warehouse te dwaan.
DBT net download gegevens út boarnen, mar jout grutte mooglikheden foar in wurk mei gegevens dy't al laden yn de Storage (yn Ynterne of Eksterne Storage).
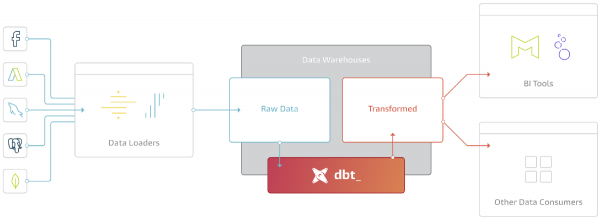
It haaddoel fan DBT is om de koade te nimmen, te kompilearjen yn SQL, de kommando's yn 'e juste folchoarder yn' e Repository út te fieren.
DBT Project Struktuer
It projekt bestiet út mappen en bestannen fan mar 2 soarten:
- Model (.sql) - in ienheid fan transformaasje útdrukt troch in SELECT query
- Konfiguraasjetriem (.yml) - parameters, ynstellings, tests, dokumintaasje
Op basisnivo is it wurk as folget strukturearre:
- De brûker taret modelkoade op yn elke handige IDE
- Mei de CLI wurde modellen lansearre, DBT kompilearret de modelkoade yn SQL
- De kompilearre SQL-koade wurdt útfierd yn 'e Storage yn in opjûne folchoarder (grafyk)
Hjir is hoe't rinnen fan 'e CLI der útsjen kin:
Alles is SELECT
Dit is in killer funksje fan it ramt foar Data Build Tool. Mei oare wurden, DBT abstrahearret alle koade dy't ferbûn is mei it materialisearjen fan jo fragen yn 'e winkel (fariaasjes fan' e kommando's CREATE, INSERT, UPDATE, DELETE ALTER, GRANT, ...).
Elk model omfettet it skriuwen fan ien SELECT-query dy't de resultearjende dataset definiearret.
Yn dit gefal kin de transformaasjelogika multi-nivo wêze en gegevens konsolidearje fan ferskate oare modellen. In foarbyld fan in model dat in bestellingsshowcase sil bouwe (f_orders):
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
Hokker nijsgjirrige dingen kinne wy hjir sjen?
Earst: Brûkte CTE (Common Table Expressions) - om koade te organisearjen en te begripen dy't in protte transformaasjes en bedriuwslogika befettet
Twadde: Modelkoade is in mingsel fan SQL en taal (sjabloantaal).
It foarbyld brûkt in loop foar om it bedrach te generearjen foar elke betellingsmetoade oantsjutte yn 'e útdrukking set. De funksje wurdt ek brûkt ref - de mooglikheid om te ferwizen nei oare modellen binnen de koade:
- Tidens kompilaasje ref wurdt omboud ta in doelwyt oanwizer nei in tabel of werjefte yn Storage
- ref kinne jo bouwe in model ôfhinklikens grafyk
It wie foeget hast ûnbeheinde mooglikheden ta oan DBT. De meast brûkte binne:
- As / else statements - branch statements
- Foar loops
- Fariabelen
- Makro - it meitsjen fan makro's
Materialisaasje: Tabel, View, Incremental
Materialisaasjestrategy is in oanpak wêryn't de resultearjende set fan modelgegevens sil wurde opslein yn 'e Storage.
Yn basisbegripen is it:
- Tabel - fysike tafel yn 'e Storage
- View - view, firtuele tabel yn Storage
D'r binne ek mear komplekse materialisaasjestrategyen:
- Incremental - inkrementeel laden (fan grutte feittabellen); nije rigels wurde tafoege, feroare rigels wurde bywurke, wiske rigels wurde wiske
- Ephemeral - it model komt net direkt, mar docht mei as CTE yn oare modellen
- Elke oare strategyen kinne jo sels tafoegje
Neist materialisaasjestrategyen binne d'r mooglikheden foar optimalisaasje foar spesifike opslach, bygelyks:
- Snowflake: Transient tabellen, Gedrach gearfoegje, Tabel klustering, Kopiearje subsydzjes, Feilige views
- Redshift: Distkey, Sortkey (interleaved, gearstald), Late Binding Views
- bigquery: Tabelferdieling en klustering, Gedrach gearfoegje, KMS-fersifering, Labels en tags
- Fonk: Bestânsformaat (parket, csv, json, orc, delta), partition_by, clustered_by, buckets, incremental_strategy
De folgjende opslach wurdt op it stuit stipe:
- postgres
- Redshift
- bigquery
- Snowflake
- Presto (foar in part)
- Spark (foar in part)
- Microsoft SQL Server (mienskipsadapter)
Litte wy ús model ferbetterje:
- Litte wy it ynfoljen ynkrementeel meitsje (ynkrementeel)
- Litte wy segmintaasje- en sorteartoetsen tafoegje foar Redshift
-- Конфигурация модели:
-- Инкрементальное наполнение, уникальный ключ для обновления записей (unique_key)
-- Ключ сегментации (dist), ключ сортировки (sort)
{{
config(
materialized='incremental',
unique_key='order_id',
dist="customer_id",
sort="order_date"
)
}}
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
where 1=1
{% if is_incremental() -%}
-- Этот фильтр будет применен только для инкрементального запуска
and order_date >= (select max(order_date) from {{ this }})
{%- endif %}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
Model ôfhinklikens grafyk
It is ek in ôfhinklikensbeam. It is ek bekend as DAG (Directed Acyclic Graph).
DBT bout in grafyk basearre op de konfiguraasje fan alle projekt modellen, of leaver, ref () keppelings binnen modellen nei oare modellen. Mei in grafyk kinne jo de folgjende dingen dwaan:
- Running modellen yn de juste folchoarder
- Parallelisaasje fan winkelfrontfoarming
- It útfieren fan in willekeurige subgraph
Foarbyld fan grafyske fisualisaasje:
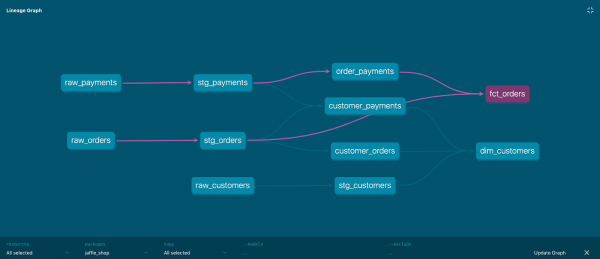
Elke knooppunt fan 'e grafyk is in model; de rânen fan' e grafyk wurde oantsjutte troch de ekspresje ref.
Gegevenskwaliteit en dokumintaasje
Neist it generearjen fan de modellen sels, lit DBT jo in oantal oannames testen oer de resultearjende dataset, lykas:
- Net Null
- Unyk
- Referinsjeintegriteit - referinsjele yntegriteit (bygelyks klant_id yn 'e oardertabel komt oerien mei id yn' e klanttabel)
- Matching de list mei akseptabel wearden
It is mooglik om jo eigen tests (oanpaste gegevenstests) ta te foegjen, lykas bygelyks % ôfwiking fan ynkomsten mei yndikatoaren fan in dei, in wike, in moanne lyn. Elke oanname formulearre as in SQL-query kin in test wurde.
Op dizze manier kinne jo net winske ôfwikingen en flaters fange yn gegevens yn 'e Warehouse-finsters.
Wat dokumintaasje oanbelanget, leveret DBT meganismen foar it tafoegjen, ferzjejen en fersprieden fan metadata en opmerkingen op it model en sels attribútnivo's.
Hjir is hoe it tafoegjen fan tests en dokumintaasje liket op it nivo fan konfiguraasjetriem:
- name: fct_orders
description: This table has basic information about orders, as well as some derived facts based on payments
columns:
- name: order_id
tests:
- unique # проверка на уникальность значений
- not_null # проверка на наличие null
description: This is a unique identifier for an order
- name: customer_id
description: Foreign key to the customers table
tests:
- not_null
- relationships: # проверка ссылочной целостности
to: ref('dim_customers')
field: customer_id
- name: order_date
description: Date (UTC) that the order was placed
- name: status
description: '{{ doc("orders_status") }}'
tests:
- accepted_values: # проверка на допустимые значения
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
En hjir is hoe't dizze dokumintaasje derút sjocht op 'e generearre webside:
Makro's en modules
It doel fan DBT is net sasear om in set fan SQL-skripts te wurden, mar om brûkers in krêftige en funksje-rike middel te jaan foar it bouwen fan har eigen transformaasjes en it fersprieden fan dizze modules.
Makro's binne sets fan konstruksjes en útdrukkingen dy't kinne wurde neamd as funksjes binnen modellen. Makro's kinne jo SQL opnij brûke tusken modellen en projekten yn oerienstimming mei it DRY (Don't Repeat Yourself) engineeringprinsipe.
Foarbyld fan makro:
{% macro rename_category(column_name) %}
case
when {{ column_name }} ilike '%osx%' then 'osx'
when {{ column_name }} ilike '%android%' then 'android'
when {{ column_name }} ilike '%ios%' then 'ios'
else 'other'
end as renamed_product
{% endmacro %}
En syn gebrûk:
{% set column_name = 'product' %}
select
product,
{{ rename_category(column_name) }} -- вызов макроса
from my_table
DBT komt mei in pakketbehearder wêrmei brûkers yndividuele modules en makro's kinne publisearje en opnij brûke.
Dit betsjut dat jo bibleteken kinne laden en brûke lykas:
- : wurkje mei datum/tiid, surrogaattoetsen, skematests, pivot / unpivot en oaren
- Ready-made showcase sjabloanen foar tsjinsten lykas и
- Biblioteken foar spesifike Data Stores, f.eks.
- - Module foar logging DBT-operaasje
In folsleine list mei pakketten is te finen op .
Noch mear funksjes
Hjir sil ik in pear oare nijsgjirrige funksjes en ymplemintaasjes beskriuwe dy't it team en ik brûke om in Data Warehouse yn te bouwen .
Skieding fan runtime omjouwings DEV - TEST - PROD
Sels binnen itselde DWH-kluster (binnen ferskate regelingen). Bygelyks, mei help fan de folgjende útdrukking:
with source as (
select * from {{ source('salesforce', 'users') }}
where 1=1
{%- if target.name in ['dev', 'test', 'ci'] -%}
where timestamp >= dateadd(day, -3, current_date)
{%- endif -%}
)
Dizze koade seit letterlik: foar omjouwings dev, test, ci nim gegevens allinnich foar de lêste 3 dagen en net mear. Dat is, rinnen yn dizze omjouwings sil folle rapper wêze en minder boarnen fereaskje. As jo rinne op omjouwing produksje de filter betingst sil wurde negearre.
Materialisaasje mei alternative kolomkodearring
Redshift is in kolomme DBMS wêrmei jo gegevenskompresjealgoritmen kinne ynstelle foar elke yndividuele kolom. Selektearje optimale algoritmen kinne skiifromte mei 20-50% ferminderje.
Makro sil it kommando ANALYZE COMPRESSION útfiere, in nije tabel meitsje mei de oanrikkemandearre kolomkodearjende algoritmen, spesifisearre segmentaasjekaaien (dist_key) en sortearkeys (sort_key), oerdrage de gegevens dernei, en, as nedich, de âlde kopy wiskje.
Makro hântekening:
{{ compress_table(schema, table,
drop_backup=False,
comprows=none|Integer,
sort_style=none|compound|interleaved,
sort_keys=none|List<String>,
dist_style=none|all|even,
dist_key=none|String) }}
Logging model rint
Jo kinne heakken heakje oan elke útfiering fan it model, dy't sil wurde útfierd foar lansearring of fuort nei it meitsjen fan it model is foltôge:
pre-hook: "{{ logging.log_model_start_event() }}"
post-hook: "{{ logging.log_model_end_event() }}"
De logmodule lit jo alle nedige metadata opnimme yn in aparte tabel, dy't dêrnei brûkt wurde kin om knelpunten te kontrolearjen en te analysearjen.
Dit is hoe't it dashboard derút sjocht basearre op loggegevens yn Looker:
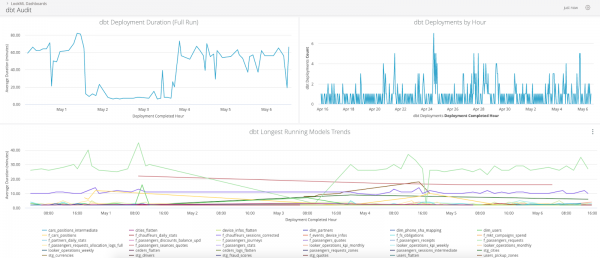
Automatisearring fan Storage Underhâld
As jo wat útwreidingen fan 'e funksjonaliteit fan' e brûkte Repository brûke, lykas UDF (User Defined Functions), dan is ferzje fan dizze funksjes, tagongskontrôle, en automatisearre útrol fan nije releases heul handich om te dwaan yn DBT.
Wy brûke UDF yn Python om hashes, e-postdomeinen en bitmask-dekodearring te berekkenjen.
In foarbyld fan in makro dy't in UDF makket op elke útfieringsomjouwing (dev, test, prod):
{% macro create_udf() -%}
{% set sql %}
CREATE OR REPLACE FUNCTION {{ target.schema }}.f_sha256(mes "varchar")
RETURNS varchar
LANGUAGE plpythonu
STABLE
AS $$
import hashlib
return hashlib.sha256(mes).hexdigest()
$$
;
{% endset %}
{% set table = run_query(sql) %}
{%- endmacro %}
By Wheely brûke wy Amazon Redshift, dat is basearre op PostgreSQL. Foar Redshift is it wichtich om regelmjittich statistiken oer tabellen te sammeljen en skiifromte frij te meitsjen - respektivelik de kommando's ANALYZE en VACUUM.
Om dit te dwaan, wurde de kommando's fan 'e makro redshift_maintenance elke nacht útfierd:
{% macro redshift_maintenance() %}
{% set vacuumable_tables=run_query(vacuumable_tables_sql) %}
{% for row in vacuumable_tables %}
{% set message_prefix=loop.index ~ " of " ~ loop.length %}
{%- set relation_to_vacuum = adapter.get_relation(
database=row['table_database'],
schema=row['table_schema'],
identifier=row['table_name']
) -%}
{% do run_query("commit") %}
{% if relation_to_vacuum %}
{% set start=modules.datetime.datetime.now() %}
{{ dbt_utils.log_info(message_prefix ~ " Vacuuming " ~ relation_to_vacuum) }}
{% do run_query("VACUUM " ~ relation_to_vacuum ~ " BOOST") %}
{{ dbt_utils.log_info(message_prefix ~ " Analyzing " ~ relation_to_vacuum) }}
{% do run_query("ANALYZE " ~ relation_to_vacuum) %}
{% set end=modules.datetime.datetime.now() %}
{% set total_seconds = (end - start).total_seconds() | round(2) %}
{{ dbt_utils.log_info(message_prefix ~ " Finished " ~ relation_to_vacuum ~ " in " ~ total_seconds ~ "s") }}
{% else %}
{{ dbt_utils.log_info(message_prefix ~ ' Skipping relation "' ~ row.values() | join ('"."') ~ '" as it does not exist') }}
{% endif %}
{% endfor %}
{% endmacro %}
DBT Cloud
It is mooglik om DBT te brûken as in tsjinst (Managed Service). Ynbegrepen:
- Web IDE foar it ûntwikkeljen fan projekten en modellen
- Job konfiguraasje en scheduling
- Ienfâldige en handige tagong ta logs
- Webside mei dokumintaasje fan jo projekt
- Connecting CI (Continuous Integration)
konklúzje
It tarieden en konsumearjen fan DWH wurdt like noflik en foardielich as it drinken fan in smoothie. DBT bestiet út Jinja, brûkersútwreidings (modules), in kompilator, in útfierer, en in pakketbehearder. Troch dizze eleminten byinoar te setten krije jo in folsleine wurkomjouwing foar jo Data Warehouse. D'r is hjoed amper in bettere manier om transformaasje binnen DWH te behearjen.

De oertsjûgingen folge troch de ûntwikkelders fan DBT wurde as folget formulearre:
- Koade, net GUI, is de bêste abstraksje foar it uterjen fan komplekse analytyske logika
- Wurkje mei gegevens moat bêste praktiken oanpasse yn software engineering (Software Engineering)
- Krityske gegevensynfrastruktuer moat wurde kontrolearre troch de brûkersmienskip as iepen boarne software
- Net allinich analytyske ark, mar ek koade sil hieltyd mear it eigendom wurde fan 'e Open Source-mienskip
Dizze kearnleauwen hawwe in produkt opwekke dat wurdt brûkt troch mear dan 850 bedriuwen hjoed, en se foarmje de basis fan in protte spannende útwreidingen dy't yn 'e takomst sille wurde makke.
Foar belangstellenden is d'r in fideo fan in iepen les dy't ik in pear moanne lyn joech as ûnderdiel fan in iepen les by OTUS - .
Neist DBT en Data Warehousing, as ûnderdiel fan 'e kursus Data Engineer op it OTUS-platfoarm, jouwe myn kollega's en ik lessen oer in oantal oare relevante en moderne ûnderwerpen:
- Arsjitektoanyske konsepten foar applikaasjes foar grutte gegevens
- Oefenje mei Spark en Spark Streaming
- Ferkenne metoaden en ark foar it laden fan gegevens boarnen
- Bouwe analytyske showcases yn DWH
- NoSQL-konsepten: HBase, Cassandra, ElasticSearch
- Prinsipes fan tafersjoch en orkestraasje
- Finale projekt: alle feardichheden byinoar sette ûnder mentoringsstipe
Ferwizings:
- - Offisjele dokumintaasje
- - Besjoch artikel troch ien fan 'e skriuwers fan DBT
- - YouTube, Opname fan in iepen OTUS-les
- - De folgjende iepen les is 15 maaie 2020
- — OTUS
- - In blik op 'e takomst fan gegevens en analytyk
- - De evolúsje fan analytiken en de ynfloed fan Open Source
- - Prinsipes fan it bouwen fan CI mei DBT
- - Oefenje, Stap-foar-stap ynstruksjes foar ûnôfhinklik wurk
- - Github, edukative projektkoade
Boarne: www.habr.com
