

It bringen fan in nije projektútjefte yn produksje fereasket in soarchfâldich lykwicht tusken ynsetsnelheid en oplossingsbetrouberens. Slack wearden rappe iteraasjes, koarte feedbacksyklusen, en prompt antwurd op brûkersoanfragen. Derneist hat it bedriuw hûnderten programmeurs dy't stribje om sa produktyf mooglik te wêzen.
De auteurs fan it materiaal, de oersetting wêrfan wy hjoed publisearje, sizze dat in bedriuw dat stribbet om sokke wearden te hâlden en tagelyk groeit, syn projektynsetsysteem konstant moat ferbetterje. It bedriuw moat ynvestearje yn transparânsje en betrouberens fan wurkprosessen, dit dwaan om te soargjen dat dizze prosessen oerienkomme mei de skaal fan it projekt. Hjir sille wy prate oer de workflows dy't hawwe ûntwikkele yn Slack, en oer guon fan 'e besluten dy't liede it bedriuw te brûken it projekt ynset systeem dat bestiet hjoed.
Hoe projektynsetprosessen hjoed wurkje
Elke PR (pull request) yn Slack moat ûnderwurpen wêze oan koadebeoardieling en moat alle tests mei súkses trochjaan. Pas nei't dizze betingsten foldien binne, kin de programmeur syn koade fusearje yn 'e mastertûke fan it projekt. Dizze koade wurdt lykwols allinich ynset tidens bedriuwstiden, Noardamerikaanske tiid. As gefolch, troch it feit dat ús meiwurkers op har wurkplak binne, binne wy folslein ree om alle ûnferwachte problemen op te lossen.
Alle dagen fiere wy sa'n 12 plande ynset út. Tidens elke ynset is de programmeur oanwiisd as de ynsetleader ferantwurdlik foar it yn produksje bringe fan de nije build. Dit is in proses yn meardere stappen dat soarget foar dat de gearstalling soepel yn produksje brocht wurdt. Mei tank oan dizze oanpak kinne wy flaters ûntdekke foardat se al ús brûkers beynfloedzje. As der tefolle flaters binne, kin de ynset fan de gearkomste weromdraaid wurde. As in spesifyk probleem wurdt ûntdutsen nei frijlitting, kin der maklik in fix foar frijlitten wurde.
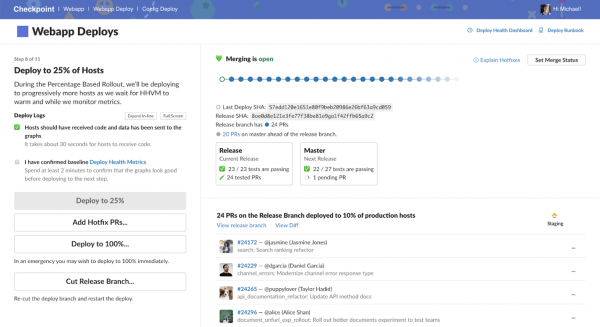
Ynterface fan it Checkpoint-systeem, dat wurdt brûkt yn Slack om projekten yn te setten
It proses fan it ynsetten fan in nije release nei produksje kin tocht wurde as besteande út fjouwer stappen.
▍1. It meitsjen fan in release branch
Elke release begjint mei in nije release-tûke, in punt yn ús Git-skiednis. Hjirmei kinne jo tags tawize oan de release en biedt in plak wêr't jo live fixes kinne meitsje foar bugs fûn yn it proses fan it tarieden fan de release foar frijlitting nei produksje.
▍2. Ynset yn in staging omjouwing
De folgjende stap is om de gearkomste yn te setten op staging-tsjinners en in automatyske test út te fieren foar de algemiene prestaasjes fan it projekt (reektest). De staging-omjouwing is in produksjeomjouwing dy't gjin ekstern ferkear ûntfangt. Yn dizze omjouwing fiere wy ekstra hânmjittich testen út. Dit jout ús ekstra fertrouwen dat it oanpaste projekt goed wurket. Automatisearre tests allinich binne net genôch om dit nivo fan fertrouwen te leverjen.
▍3. Ynset yn dogfood en kanaryske omjouwings
Ynset nei produksje begjint mei in dogfood-omjouwing, fertsjintwurdige troch in set hosts dy't ús ynterne Slack-wurkromten tsjinje. Om't wy heul aktive Slack-brûkers binne, holp dizze oanpak ús in protte bugs te fangen betiid yn 'e ynset. Neidat wy hawwe der wis fan dat de basis funksjonaliteit fan it systeem is net brutsen, de gearkomste wurdt ynset yn de kanaryske omjouwing. It fertsjintwurdiget systemen dy't goed foar likernôch 2% fan produksjeferkear.
▍4. Stadichoan frijlitting nei produksje
As de monitoaring yndikatoaren foar de nije release blike te wêzen stabyl, en as nei it ynsetten fan it projekt yn 'e kanaryske omjouwing wy hawwe net krigen gjin klachten, wy fierder te stadichoan oerdrage de produksje tsjinners nei de nije release. It ynsetproses is ferdield yn de folgjende stadia: 10%, 25%, 50%, 75% en 100%. As resultaat kinne wy produksjeferkear stadichoan oerdrage nei de nije release fan it systeem. Tagelyk hawwe wy tiid om de situaasje te ûndersykjen as der anomalies wurde ûntdutsen.
▍Wat as der wat mis giet by ynset?
It meitsjen fan wizigingen oan koade is altyd in risiko. Mar wy omgean mei dit tank oan de oanwêzigens fan goed oplaat "ynset lieders" dy't beheare it proses fan bringen in nije release yn produksje, tafersjoch op tafersjoch yndikatoaren en koördinearje it wurk fan programmeurs útjaan koade.
Yn it gefal dat der echt wat mis giet, besykje wy it probleem sa betiid mooglik te ûntdekken. Wy ûndersykje it probleem, fine de PR dy't de flaters feroarsaket, rôlje it werom, analysearje it yngeand en meitsje in nijbou. Wier, soms giet it probleem ûngemurken oant it projekt yn produksje giet. Yn sa'n situaasje is it wichtichste ding om de tsjinst te herstellen. Dêrom, foardat wy begjinne mei it ûndersykjen fan it probleem, rôlje wy fuortendaliks werom nei de foarige wurkbou.
Boublokken fan in ynsetsysteem
Litte wy nei de technologyen sjen dy't ús projektynsetsysteem ûnderlizze.
▍ Fluch ynset
De hjirboppe beskreaune workflow kin, efterôf, wat fanselssprekkend lykje. Mar ús ynsetsysteem waard net direkt sa.
Doe't it bedriuw folle lytser wie, koe ús heule applikaasje rinne op 10 Amazon EC2-eksimplaren. It ynsetten fan it projekt yn dizze situaasje betsjutte it brûken fan rsync om alle servers fluch te syngronisearjen. Earder wie nije koade mar ien stap fuort fan produksje, fertsjintwurdige troch in staging-omjouwing. Assemblies waarden makke en hifke yn sa'n omjouwing, en dan gie direkt nei produksje. It wie heul maklik om sa'n systeem te begripen; it koe elke programmeur de koade dy't hy skreaun hie op elk momint ynsette.
Mar doe't it oantal fan ús kliïnten groeide, groeide ek de skaal fan 'e ynfrastruktuer dy't nedich wie om it projekt te stypjen. Gau, sjoen de konstante groei fan it systeem, wie ús ynsetmodel, basearre op it triuwen fan nije koade nei de servers, net mear syn wurk. It tafoegjen fan elke nije tsjinner betsjutte nammentlik it fergrutsjen fan de tiid nedich om de ynset te foltôgjen. Sels strategyen basearre op parallel gebrûk fan rsync hawwe bepaalde beheiningen.
Wy hawwe dit probleem úteinlik oplost troch te ferpleatsen nei in folslein parallele ynsetsysteem, dat oars wie ûntwurpen as it âlde systeem. Wy hawwe nammentlik no gjin koade nei de servers stjoerd mei in syngronisaasjeskript. No hat elke tsjinner selsstannich de nije gearstalling ynladen, wittende dat it dit moast dwaan troch de wiziging fan 'e Consul-kaai te kontrolearjen. De tsjinners laden de koade parallel. Dit liet ús in hege snelheid fan ynset behâlde, sels yn in omjouwing fan konstante systeemgroei.

1. Produksje-tsjinners kontrolearje de Consul-kaai. 2. De kaai feroarings, dit fertelt de tsjinners dat se moatte begjinne te downloaden nije koade. 3. Servers download tarball triemmen mei applikaasje koade
▍Atomyske ynset
In oare oplossing dy't ús holp om in multi-tier ynsetsysteem te berikken wie atomyske ynset.
Foardat jo atomyske ynset brûke, koe elke ynset in grut oantal flaterberjochten opleverje. It feit is dat it proses fan it kopiearjen fan nije bestannen nei produksjeservers net atomysk wie. Dit resultearre yn in koarte tiidperioade wêryn de koade dy't nije funksjes neamde, beskikber wie foardat de funksjes sels beskikber wiene. Doe't sa'n koade waard neamd, it resultearre yn ynterne flaters wurde werom. Dit manifestearre him yn mislearre API-oanfragen en brutsen websiden.
It team dat wurke oan dit probleem hat it oplost troch it yntrodusearjen fan it konsept fan "hot" en "kâld" mappen. De koade yn 'e hot directory is ferantwurdlik foar it ferwurkjen fan produksjeferkear. En yn "kâlde" mappen wurdt de koade, wylst it systeem rint, allinich taret foar gebrûk. Tidens ynset wurdt nije koade kopiearre nei in net brûkte kâlde map. Dan, as d'r gjin aktive prosessen binne op 'e tsjinner, wurdt in direkte mapwikseling útfierd.
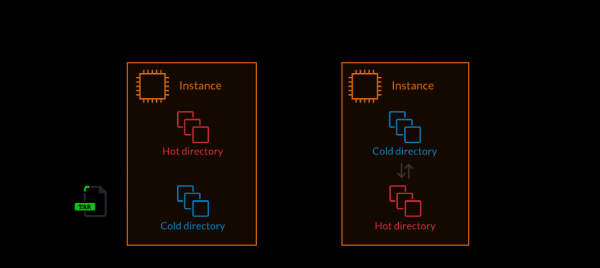
1. Utpakke de applikaasje koade yn in "kâld" triemtafel. 2. It systeem oerskeakelje nei in "kâlde" map, dy't "hot" wurdt (atomyske operaasje)
Resultaten: ferskowing yn klam nei betrouberens
Yn 2018 groeide it projekt ta sa'n skaal dat heul rappe ynset begon de stabiliteit fan it produkt skea te meitsjen. Wy hiene in heul avansearre ynsetsysteem wêryn wy in protte tiid en muoite ynvestearren. Alles wat wy hoege te dwaan wie ús ynsetprosessen opnij opbouwe en ferbetterje. Wy binne útgroeid ta in frij grut bedriuw, waans ûntjouwings oer de hiele wrâld binne brûkt om ûnûnderbrutsen kommunikaasje te organisearjen en wichtige problemen op te lossen. Dêrom waard betrouberens it fokus fan ús oandacht.
Wy moasten it proses fan it ynsetten fan nije Slack-releases feiliger meitsje. Dizze need hat ús laat om ús ynsetsysteem te ferbetterjen. Yn feite hawwe wy dit ferbettere systeem hjirboppe besprutsen. Yn 'e djipten fan it systeem bliuwe wy gebrûk meitsje fan rappe en atomêre ynsettechnologyen. De manier wêrop ynset wurdt dien is feroare. Us nije systeem is ûntworpen om nije koade stadichoan yn te setten op ferskate nivo's, yn ferskate omjouwings. Wy brûke no mear avansearre stipe-ark en ark foar systeemmonitoring dan earder. Dit jout ús de mooglikheid om flaters te fangen en te reparearjen lang foardat se in kâns hawwe om de einbrûker te berikken.
Mar dêr sille wy net ophâlde. Wy ferbetterje dit systeem konstant, mei mear avansearre helpmiddels en ark foar automatisearring fan wurk.
Dear readers! Hoe wurket it proses fan it ynsetten fan nije projektreleases wêr't jo wurkje?
Boarne: www.habr.com
