

Pas op foar operaasjes dy't buffers bringe ...
Mei in lytse query as foarbyld, litte wy nei guon universele oanpak sjen foar it optimalisearjen fan queries yn PostgreSQL. Oft jo se brûke of net is oan jo, mar it is it wurdich te witten oer har.
Yn guon folgjende ferzjes fan PG kin de situaasje feroarje as de planner slimmer wurdt, mar foar 9.4 / 9.6 sjocht it sawat itselde út, lykas yn 'e foarbylden hjir.
Litte wy in heul wirklik fersyk nimme:
SELECT
TRUE
FROM
"Документ" d
INNER JOIN
"ДокументРасширение" doc_ex
USING("@Документ")
INNER JOIN
"ТипДокумента" t_doc ON
t_doc."@ТипДокумента" = d."ТипДокумента"
WHERE
(d."Лицо3" = 19091 or d."Сотрудник" = 19091) AND
d."$Черновик" IS NULL AND
d."Удален" IS NOT TRUE AND
doc_ex."Состояние"[1] IS TRUE AND
t_doc."ТипДокумента" = 'ПланРабот'
LIMIT 1; oer tabel- en fjildnammenDe "Russyske" nammen fan fjilden en tabellen kinne oars wurde behannele, mar dit is in kwestje fan smaak. Fanwege de d'r binne gjin bûtenlânske ûntwikkelders, en PostgreSQL lit ús nammen jaan, sels yn hiëroglyfen, as se ynsletten yn quotes, dan neame wy objekten it leafst ûndûbelsinnich en dúdlik, sadat der gjin diskrepânsjes binne.
Litte wy nei it resultearjende plan sjen:
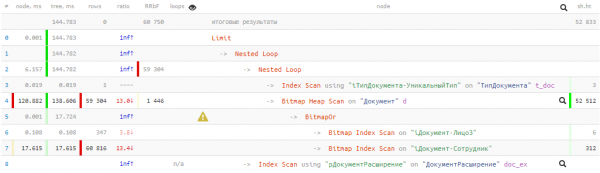
144ms en hast 53K buffers - dat is, mear dan 400MB oan gegevens! En wy sille lokkich wêze as se allegear yn 'e cache binne op' e tiid fan ús oanfraach, oars sil it in protte kearen langer duorje by it lêzen fan skiif.
It algoritme is it wichtichste!
Om elk fersyk op ien of oare manier te optimalisearjen, moatte jo earst begripe wat it moat dwaan.
Litte wy de ûntwikkeling fan 'e databankstruktuer sels bûten it berik fan dit artikel litte foar no, en iens dat wy relatyf "goedkeap" kinne herskriuwe it fersyk en / of rôlje op 'e basis guon fan' e dingen dy't wy nedich binne yndeksen.
Dus it fersyk:
- kontrolearret it bestean fan op syn minst wat dokumint
- yn 'e tastân dy't wy nedich binne en fan in bepaald type
- wêr't de auteur of performer de meiwurker is dy't wy nedich binne
JOIN + LIMIT 1
Hiel faak is it makliker foar in ûntwikkelder om in query te skriuwen wêrby't in grut oantal tabellen earst byinoar komme, en dan bliuwt der mar ien rekord fan dizze hiele set. Mar makliker foar de ûntwikkelder betsjut net effisjinter foar de databank.
Yn ús gefal wiene d'r mar 3 tafels - en wat is it effekt ...
Litte wy earst de ferbining mei de tabel "Document Type" kwytreitsje, en tagelyk de databank fertelle dat ús type record is unyk (wy witte dit, mar de planner hat noch gjin idee):
WITH T AS (
SELECT
"@ТипДокумента"
FROM
"ТипДокумента"
WHERE
"ТипДокумента" = 'ПланРабот'
LIMIT 1
)
...
WHERE
d."ТипДокумента" = (TABLE T)
...Ja, as de tabel/CTE bestiet út ien fjild fan ien record, dan kinne jo yn PG sels sa skriuwe, ynstee fan
d."ТипДокумента" = (SELECT "@ТипДокумента" FROM T LIMIT 1)Lazy evaluaasje yn PostgreSQL queries
BitmapOr vs UNION
Yn guon gefallen sil Bitmap Heap Scan ús in protte kostje - bygelyks yn ús situaasje, as in protte records foldogge oan de fereaske betingst. Wy krigen it omdat OR betingst feroare yn BitmapOr- operaasje yn plan.
Litte wy weromgean nei it orizjinele probleem - wy moatte in oerienkommende rekord fine immen fan 'e betingsten - dat is, d'r is net nedich om te sykjen nei alle 59K-records ûnder beide betingsten. Der is in manier om te wurkjen út ien betingst, en gean nei de twadde allinne as neat waard fûn yn de earste. It folgjende ûntwerp sil ús helpe:
(
SELECT
...
LIMIT 1
)
UNION ALL
(
SELECT
...
LIMIT 1
)
LIMIT 1"Eksterne" LIMIT 1 soarget derfoar dat it sykjen einiget as it earste rekord wurdt fûn. En as it al fûn is yn it earste blok, sil it twadde blok net wurde útfierd (nea útfierd oangeande).
"Swiere omstannichheden ferbergje ûnder CASE"
D'r is in ekstreem ûngemaklik momint yn 'e orizjinele fraach - kontrolearje de status tsjin de relatearre tabel "DocumentExtension". Nettsjinsteande de wierheid fan oare betingsten yn 'e útdrukking (bygelyks, d. "Wiske" IS NET TRUE), dizze ferbining wurdt altyd útfierd en "kostet boarnen". Mear of minder fan har sille wurde bestege - hinget ôf fan 'e grutte fan dizze tafel.
Mar jo kinne de query wizigje sadat it sykjen nei in relatearre record allinich foarkomt as it echt nedich is:
SELECT
...
FROM
"Документ" d
WHERE
... /*index cond*/ AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END Ien kear út 'e keppele tabel oan ús gjin fan 'e fjilden binne nedich foar it resultaat, dan hawwe wy de kâns om JOIN te feroarjen yn in betingst op in subquery.
Litte wy de yndeksearre fjilden "bûten de CASE-heakjes" litte, foegje ienfâldige betingsten ta fan it rekord oan it WHEN-blok - en no wurdt de "swiere" query allinich útfierd by it trochjaan nei THEN.
Myn efternamme is "Totaal"
Wy sammelje de resultearjende query mei alle hjirboppe beskreaune meganika:
WITH T AS (
SELECT
"@ТипДокумента"
FROM
"ТипДокумента"
WHERE
"ТипДокумента" = 'ПланРабот'
)
(
SELECT
TRUE
FROM
"Документ" d
WHERE
("Лицо3", "ТипДокумента") = (19091, (TABLE T)) AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END
LIMIT 1
)
UNION ALL
(
SELECT
TRUE
FROM
"Документ" d
WHERE
("ТипДокумента", "Сотрудник") = ((TABLE T), 19091) AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END
LIMIT 1
)
LIMIT 1;Oanpassing [oan] yndeksen
In trained each merkte op dat de yndekseare betingsten yn 'e UNION-subblokken wat oars binne - dit is om't wy al passende yndeksen op' e tafel hawwe. En as se net bestie, soe it it wurdich wêze om te meitsjen: Dokumint(Persoan3, DocumentType) и Dokumint (DocumentType, Meiwurker).
oer de folchoarder fan fjilden yn ROW betingstenUt it eachpunt fan de planner kinne jo fansels skriuwe (A, B) = (constA, constB)en (B, A) = (constB, constA). Mar by opname yn de folchoarder fan de fjilden yn de yndeks, sa'n fersyk is gewoan handiger om letter te debuggen.
Wat stiet yn it plan?
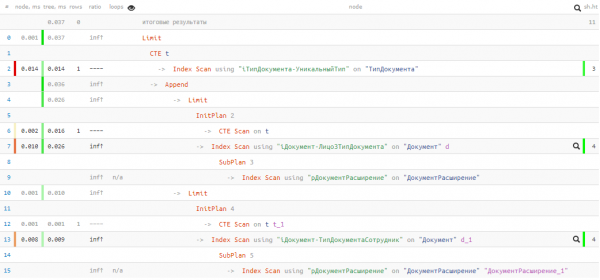
Spitigernôch wiene wy pech en waard neat fûn yn it earste UNION-blok, dus de twadde waard noch útfierd. Mar sels sa - allinnich 0.037ms en 11 buffers!
Wy hawwe it fersyk fersnelle en gegevenspompen yn it ûnthâld fermindere ferskate tûzen kear, mei frij ienfâldige techniken - in goed resultaat mei in bytsje copy-paste. 🙂
Boarne: www.habr.com
