

Moderne datasintra hawwe hûnderten aktive apparaten ynstalleare, bedekt troch ferskate soarten tafersjoch. Mar sels in ideale yngenieur mei perfekte tafersjoch yn 'e hân sil yn in pear minuten goed kinne reagearje op in netwurkfout. Yn in rapport op 'e Next Hop 2020-konferinsje presinteare ik in metoade foar DC-netwurkûntwerp, dy't in unike funksje hat - it datasintrum genêst himsels yn millisekonden. Mear krekter reparearret de yngenieur it probleem kalm, wylst de tsjinsten it gewoan net fernimme.
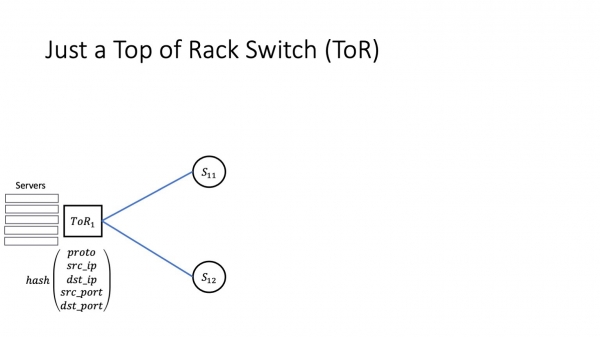
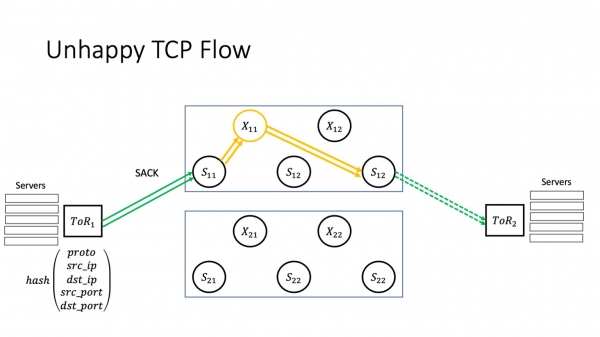
Foar in protte netwurk yngenieurs begjint in datacenter netwurk, fansels, mei ToR, mei in switch yn it rek. ToR hat normaal twa soarten keppelings. De lytse geane nei de servers, oaren - d'r binne N kear mear fan har - geane nei de spines fan it earste nivo, dat is, nei syn uplinks. Uplinks wurde meastal beskôge as gelyk, en ferkear tusken uplinks is balansearre basearre op in hash út 5-tuple, dy't omfiemet proto, src_ip, dst_ip, src_port, dst_port. Gjin ferrassingen hjir.
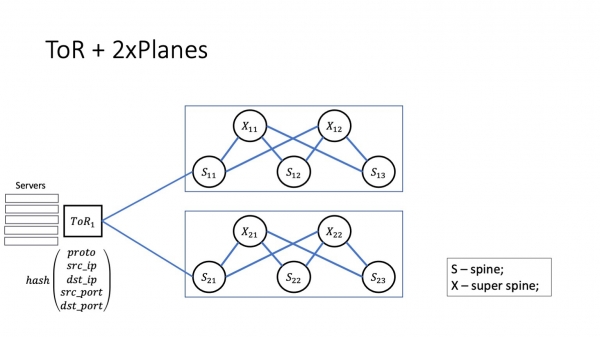
Folgjende, hoe sjocht de plan-arsjitektuer derút? Spines fan it earste nivo binne net ferbûn mei elkoar, mar binne ferbûn troch superspines. De letter X sil ferantwurdlik wêze foar superspines; it is hast as in krúsferbining.
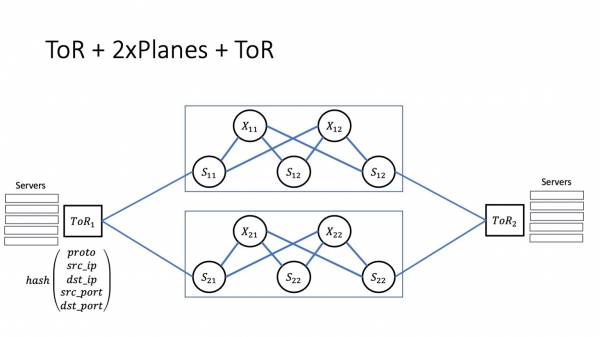
En it is dúdlik dat, oan 'e oare kant, tori binne ferbûn mei alle spines fan it earste nivo. Wat is wichtich yn dizze foto? As wy ynteraksje binnen it rek hawwe, dan giet de ynteraksje fansels troch ToR. As de ynteraksje optreedt binnen de module, dan komt de ynteraksje troch de spines fan it earste nivo. As de ynteraksje yntermodulêr is - lykas hjir, ToR 1 en ToR 2 - dan sil de ynteraksje troch spinnen fan sawol it earste as twadde nivo gean.
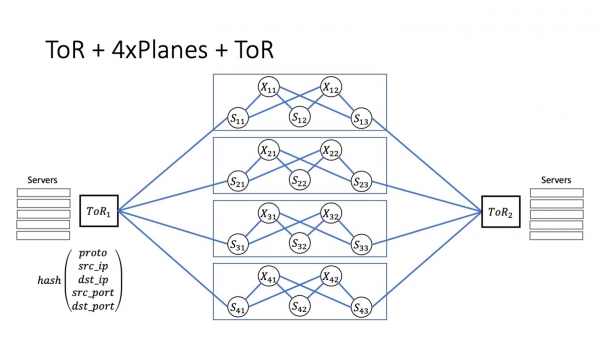
Yn teory is sa'n arsjitektuer maklik skalberber. As wy havenkapasiteit hawwe, frije romte yn it datasintrum en foarôf lein glêstried, dan kin it oantal leanen altyd ferhege wurde, wêrtroch de totale kapasiteit fan it systeem ferheget. Dit is heul maklik te dwaan op papier. It soe sa wêze yn it libben. Mar dêr giet it ferhaal fan hjoed net oer.

Ik wol dat de goede konklúzjes lutsen wurde. Wy hawwe in protte paden binnen it datasintrum. Se binne betingst ûnôfhinklik. Ien paad binnen it datasintrum is allinich mooglik binnen ToR. Binnen de module hawwe wy it oantal paden gelyk oan it oantal banen. It oantal paden tusken modules is gelyk oan it produkt fan it oantal fleantugen en it oantal superspines yn elk fleantúch. Om it dúdliker te meitsjen, om in gefoel fan 'e skaal te krijen, sil ik nûmers jaan dy't jildich binne foar ien fan' e Yandex-datasintra.

Der binne acht fleantugen, elk fleantúch hat 32 superspines. As gefolch, it docht bliken dat der binne acht paden binnen de module, en mei intermodule ynteraksje binne der al 256 fan harren.

Dat is, as wy Cookbook ûntwikkelje, besykje te learen hoe't jo fouttolerante datasintra bouwe dy't harsels genêze, dan is planêre arsjitektuer de juste kar. It lost it skaalfergruttingsprobleem op, en yn teory is it maklik. D'r binne in protte ûnôfhinklike paden. De fraach bliuwt: hoe oerlibbet sa'n arsjitektuer mislearrings? Der binne ferskate mislearrings. En dit sille wy no beprate.
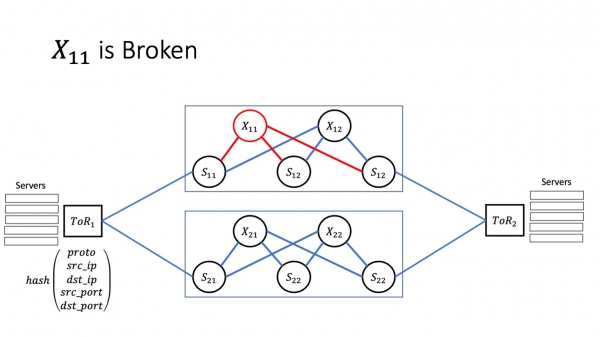
Lit ien fan ús superspines "siik wurde". Hjir ik werom nei de twa-plane arsjitektuer. Wy sille dizze as foarbyld hâlde, om't it gewoan makliker sil wêze om te sjen wat der bart mei minder bewegende dielen. Lit X11 siik wurde. Hoe sil dit de tsjinsten beynfloedzje dy't yn datasintra libje? In protte hinget ôf fan hoe't it mislearjen der eins útsjocht.
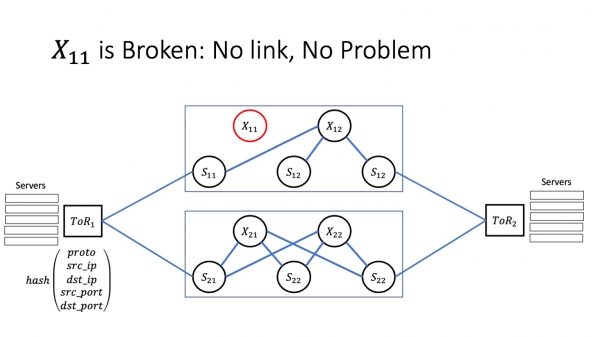
As it mislearjen goed is, wurdt it fongen op it automatisearringsnivo fan deselde BFD, de automatisearring set lokkich de problematyske gewrichten en isolearret it probleem, dan is alles goed. Wy hawwe in protte paden, ferkear wurdt daliks trochstjoerd nei alternative rûtes, en tsjinsten sille neat fernimme. Dit is in goed skript.
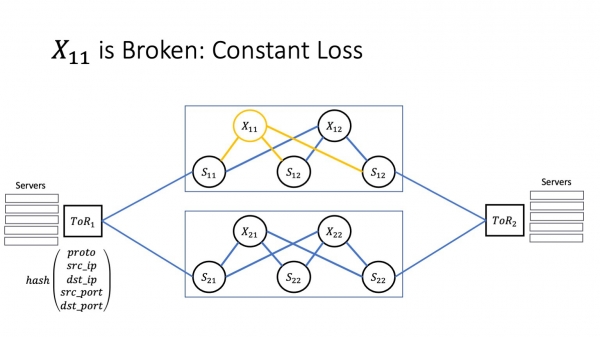
In min senario is as wy konstante ferliezen hawwe, en de automatisearring merkt it probleem net op. Om te begripen hoe't dit in applikaasje beynfloedet, moatte wy in bytsje tiid besteegje oan it besprekken fan hoe't TCP wurket.
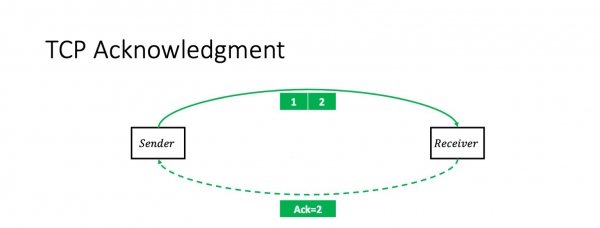
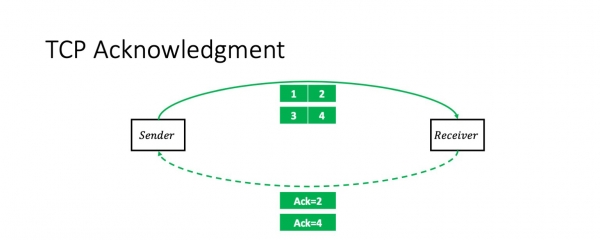
Ik hoopje dat ik net shock gjinien mei dizze ynformaasje: TCP is in transmissie befêstiging protokol. Dat is, yn it ienfâldichste gefal, de stjoerder stjoert twa pakketten en ûntfangt in kumulative ack op har: "Ik krige twa pakketten."
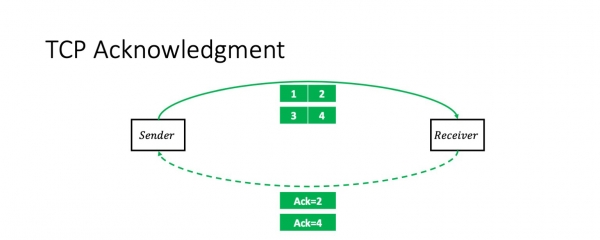
Dêrnei sil hy noch twa pakketten stjoere, en de situaasje sil werhelje. Ik ferûntskuldigje my foarôf foar wat ferienfâldiging. Dit senario is korrekt as it finster (it oantal pakketten yn 'e flecht) twa is. Fansels is dit yn it algemiene gefal net needsaaklik it gefal. Mar de finstergrutte hat gjin ynfloed op de kontekst fan pakketferstjoering.
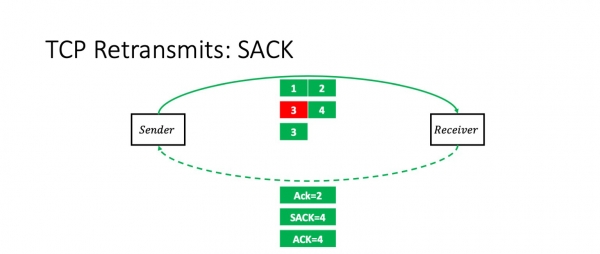
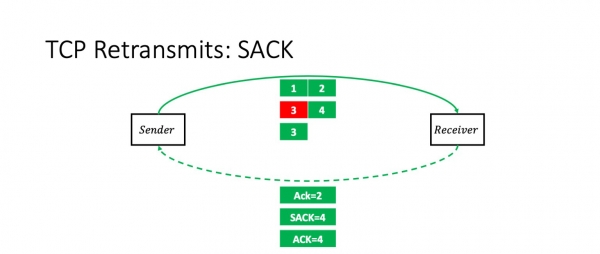
Wat bart der as wy pakket 3 ferlieze? Yn dit gefal sil de ûntfanger pakketten 1, 2 en 4 ûntfange. En hy sil de stjoerder eksplisyt fertelle mei de SACK-opsje: "Jo witte, trije kamen, mar it midden wie ferlern." Hy seit: "Ack 2, SACK 4."
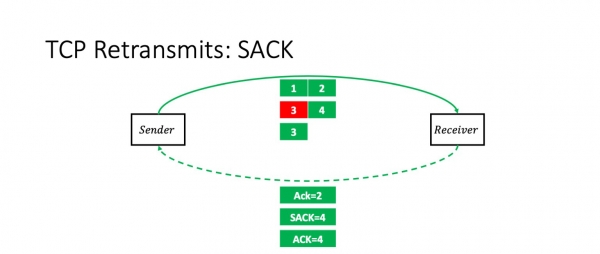
Op dit stuit werhellet de stjoerder sûnder problemen krekt it pakket dat ferlern gien is.
Mar as it lêste pakket yn it finster ferlern is, sil de situaasje folslein oars útsjen.
De ûntfanger ûntfangt de earste trije pakketten en begjint te wachtsjen. Mei tank oan guon optimalisaasjes yn 'e kernel TCP-stack, Linux It sil wachtsje op in oerienkommend pakket, útsein as der in eksplisite flagge is dy't oanjout dat it it lêste pakket is of soksawat. It sil wachtsje oant de Delayed ACK-timeout ferrint en dan in befêstiging stjoere foar de earste trije pakketten. Mar no sil de stjoerder wachtsje moatte. It wit net oft it fjirde pakket ferlern gien is of op it punt stiet oan te kommen. Om oerlêst fan it netwurk te foarkommen, sil it besykje te wachtsjen oant der in eksplisite oantsjutting is dat it pakket ferlern gien is of oant de RTO-timeout ferrint.
Wat is RTO timeout? Dit is it maksimum fan 'e RTT berekkene troch de TCP-stapel en wat konstante. Wat foar konstante dit is, sille wy no beprate.
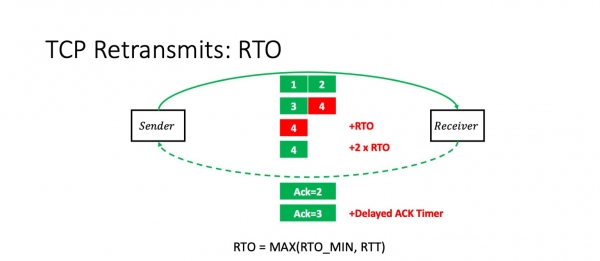
Mar it wichtichste is dat as wy wer pech hawwe en it fjirde pakket wer ferlern is, dan ferdûbelet de RTO. Dat is, elke mislearre poging betsjut ferdûbeling fan de time-out.
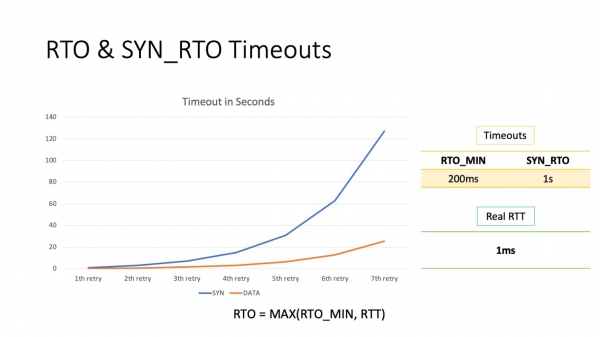
Litte wy no sjen wat dizze basis gelyk is. Standert is de minimale RTO 200 ms. Dit is de minimale RTO foar gegevenspakketten. Foar SYN-pakketten is it oars, 1 sekonde. Sa't jo sjen kinne, sil sels de earste poging om pakketten opnij te ferstjoeren 100 kear langer duorje dan de RTT yn it datasintrum.
Litte wy no weromgean nei ús senario. Wat bart der mei de tsjinst? De tsjinst begjint pakketten te ferliezen. Lit de tsjinst earst betingst gelok wêze en wat yn 'e midden fan it finster ferlieze, dan krijt it in SACK en ferstjoert de pakketten dy't ferlern gienen opnij.
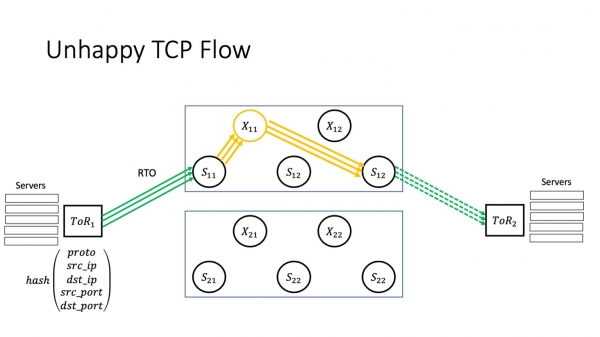
Mar as pech him werhellet, dan hawwe wy in RTO. Wat is hjir wichtich? Ja, wy hawwe in protte paden yn ús netwurk. Mar it TCP-ferkear fan ien bepaalde TCP-ferbining sil trochgean troch deselde brutsen stapel te gean. Pakketferlies, op betingst dat dizze magyske X11 fan ús net op himsels útgiet, liedt net ta ferkear streamt yn gebieten dy't net problematysk binne. Wy besykje it pakket troch deselde brutsen stapel te leverjen. Dit liedt ta in cascadearjende mislearring: in datasintrum is in set fan ynteraktive applikaasjes, en guon fan 'e TCP-ferbiningen fan al dizze applikaasjes begjinne te degradearjen - om't superspine alle applikaasjes beynfloedet dy't besteane yn it datasintrum. As it sprekwurd seit: as jo gjin hynder skoeiden, gyng it hynder kreupel; it hynder gie kreupel - it rapport waard net levere; it rapport waard net levere - wy hawwe de oarloch ferlern. Allinnich hjir is de telling yn sekonden fan it momint dat it probleem ûntstiet oant it stadium fan degradaasje dat de tsjinsten begjinne te fielen. Dit betsjut dat brûkers earne wat misse kinne.

D'r binne twa klassike oplossingen dy't elkoar oanfolje. De earste is tsjinsten dy't besykje strie yn te setten en it probleem sa op te lossen: "Litte wy wat yn 'e TCP-stapel oanpasse. Litte wy time-outs meitsje op it tapassingsnivo as lange libbene TCP-sesjes mei ynterne sûnenskontrôles. It probleem is dat sokke oplossingen: a) hielendal net skaalfergrutsje; b) binne tige min kontrolearre. Dat is, sels as de tsjinst per ûngelok de TCP-stapel konfigurearret op in manier dy't it better makket, as earste is it net wierskynlik fan tapassing foar alle applikaasjes en alle datasintra, en twadde, wierskynlik, sil it net begripe dat it dien is. korrekt, en wat net. Dat is, it wurket, mar it wurket min en skaal net. En as der in netwurkprobleem is, wa is de skuld? Fansels, NOC. Wat docht NOC?

In protte tsjinsten leauwe dat yn NOC wurk soks bart. Mar om earlik te wêzen, net allinich dat.

NOC yn it klassike skema is dwaande mei de ûntwikkeling fan in protte tafersjochsystemen. Dit binne sawol swarte doaze as wite doazemonitoring. Oer in foarbyld fan swarte doaze spine monitoring Alexander Klimenko by de lêste Next Hop. Trouwens, dizze tafersjoch wurket. Mar sels ideale tafersjoch sil in tiidfertraging hawwe. Normaal is dit in pear minuten. Nei't it ôfgiet, hawwe de yngenieurs op plicht tiid nedich om har wurking dûbel te kontrolearjen, it probleem te lokalisearjen en dan it probleemgebiet te blussen. Dat is, yn it bêste gefal, it behanneljen fan it probleem duorret 5 minuten, yn it slimste gefal 20 minuten, as it net direkt dúdlik is wêr't de ferliezen foarkomme. It is dúdlik dat al dizze tiid - 5 of 20 minuten - ús tsjinsten sille trochgean te lijen, wat wierskynlik net goed is.
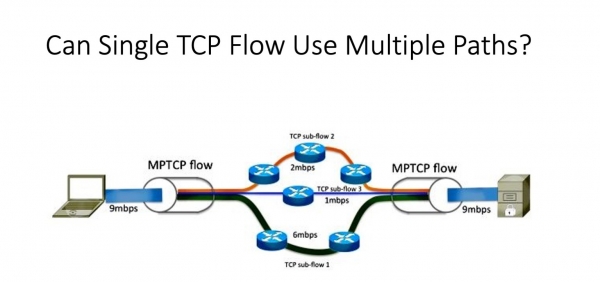
Wat wolle jo echt krije? Wy hawwe safolle manieren. En problemen ûntsteane krekt om't TCP-streamen dy't pech hawwe, trochgean mei deselde rûte. Wy hawwe wat nedich wêrtroch wy meardere rûtes kinne brûke binnen ien TCP-ferbining. It liket derop dat wy in oplossing hawwe. D'r is TCP, dat wurdt multipath TCP neamd, dat is TCP foar meardere paden. Wier, it is ûntwikkele foar in folslein oare taak - foar smartphones dy't ferskate netwurkapparaten hawwe. Om maksimalisearjen oerdracht of meitsje primêre / reservekopy modus, in meganisme waard ûntwikkele dat makket meardere triedden (sesjes) transparant foar de applikaasje en kinne jo wikselje tusken harren yn it gefal fan in mislearring. Of, lykas ik sei, maksimalisearje de streak.
Mar hjir is in nuânse. Om te begripen wat it is, sille wy moatte sjen nei hoe't triedden wurde oprjochte.
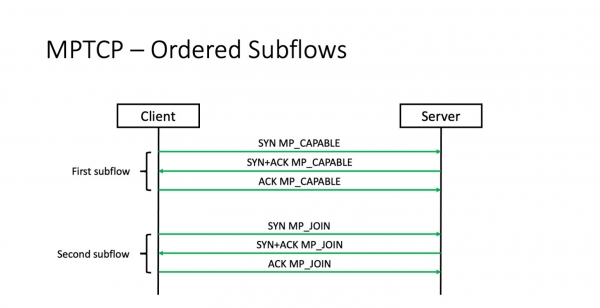
Threads wurde sequentially ynstalleare. De earste tried wurdt earst ynstallearre. Folgjende diskusjes wurde dan ynsteld mei it koekje dat al oerienkommen is binnen dat diskusje. En hjir is it probleem.

It probleem is dat as de earste tried him net fêstiget, de twadde en tredde triedden nea ûntstean. Dat is, multipath TCP net oplosse it ferlies fan in SYN pakket yn de earste stream. En as de SYN ferlern is, feroaret multipath TCP yn reguliere TCP. Dit betsjut dat it yn in datacenteromjouwing ús net sil helpe om it probleem fan ferlies yn it fabryk op te lossen en leare om meardere paden te brûken yn gefal fan in mislearring.
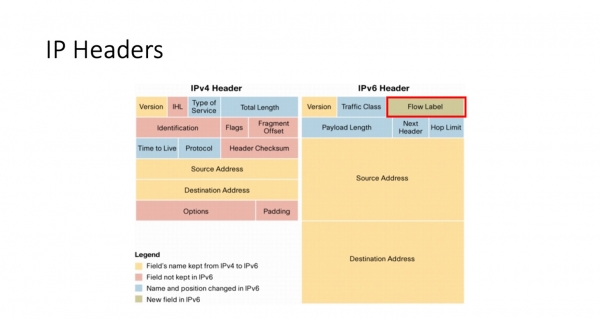
Wat kin ús helpe? Guon fan jimme hawwe al út 'e titel riede dat in wichtich fjild yn ús fierdere diskusje it IPv6-streamlabel-headerfjild sil wêze. Yndied, dit fjild, dat ferskynt yn v6 en ôfwêzich is fan v4, nimt 20 bits yn beslach, en it gebrûk dêrfan is ûnderwerp west fan in soad debat. Dit is tige nijsgjirrich - d'r wie debat, guon dingen waarden reparearre yn RFC's, en yn Linux- tagelyk ferskynde in ymplemintaasje yn 'e kernel, dy't nea earne dokumintearre is.

Ik nûgje jo út om mei my mei te dwaan oan in lyts ûndersyk. Litte wy sjen wat der yn 'e kearn barde. Linux oer de ôfrûne pear jier.

2014. In yngenieur fan in grut en respektearre bedriuw foeget funksjonaliteit ta oan 'e kernel Linux De ôfhinklikens fan 'e streamlabelwearde fan 'e socket-hash. Wat besochten se hjir op te lossen? Dit is relatearre oan RFC 6438, dy't it folgjende probleem bespruts. Binnen in datasintrum wurdt IPv4 faak ynkapsulearre yn IPv6-pakketten, om't de fabric sels IPv6 is, mar IPv4 moat ekstern levere wurde. Lange tiid wiene d'r problemen mei switches dy't net ûnder twa IP-headers koene sjen om by TCP of UDP te kommen en src_ports en dst_ports te finen. Dit betsjutte dat de hash, by it besjen fan 'e earste twa IP-headers, praktysk fêst wie. Om dit te foarkommen, en om in goede lykwichtigens fan dit ynkapsulearre ferkear te garandearjen, waard foarsteld om de hash fan it 5-tuple ynkapsulearre pakket ta te foegjen oan it streamlabelfjild. Rûchwei itselde waard dien foar oare ynkapsulaasjeskema's, foar UDP en foar GRE, de lêste mei it GRE Key-fjild. Yn alle gefallen binne de doelen hjir dúdlik. En teminsten op dat stuit wiene se nuttich.
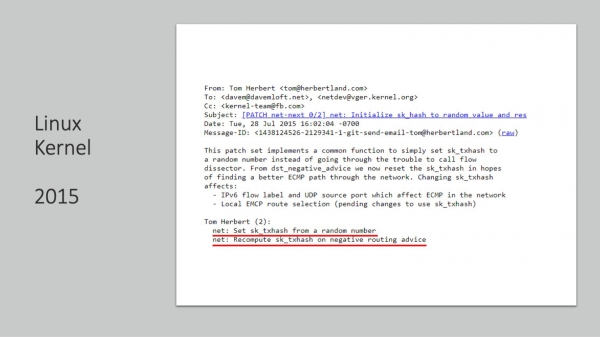
Yn 2015 komt in nije patch fan deselde respekteare yngenieur. Hy is tige nijsgjirrich. It seit it folgjende - wy sille de hash randomisearje yn gefal fan in negatyf routing-evenemint. Wat is in negatyf routing-evenemint? Dit is de RTO dy't wy earder besprutsen, dat is, it ferlies fan 'e sturt fan it finster is in barren dat wirklik negatyf is. Wier, it is relatyf lestich te rieden dat dit it is.

2016, in oar renommearre bedriuw, ek grut. It disassemble de lêste krukken en makket it sa dat de hash, dy't wy earder makke willekeurich, no feroaret foar eltse SYN retransmission en nei eltse RTO timeout. En yn dizze brief wurdt foar de earste en lêste kear it ultime doel oanjûn - om te soargjen dat ferkear yn gefal fan ferlies of kanaaloerlêst de mooglikheid hat om sêft omlaat te wurden en meardere paden te brûken. Fansels, nei dit wiene in protte publikaasjes, kinne jo maklik fine se.
Hoewol nee, jo kinne net, om't der gjin inkelde publikaasje oer dit ûnderwerp west hat. Mar wy witte!

En as jo net folslein begripe wat der dien is, sil ik jo no fertelle.

Wat is der dien, hokker funksjonaliteit is der tafoege oan 'e kernel? Linux? De txhash feroaret nei in willekeurige wearde nei elke RTO-evenemint. Dit is itselde negative routingresultaat. De hash hinget ôf fan dizze txhash, en it streamlabel hinget ôf fan 'e skb-hash. D'r binne hjir wat funksjonele útlis, mar ien slide sil net alle details dekke. As immen nijsgjirrich is, kinne jo troch de kernelkoade stappe en kontrolearje.
Wat is hjir wichtich? De wearde fan de flow label fjild feroaret nei in willekeurich getal nei eltse RTO. Hoe hat dit ynfloed op ús ûngelokkige TCP-stream?
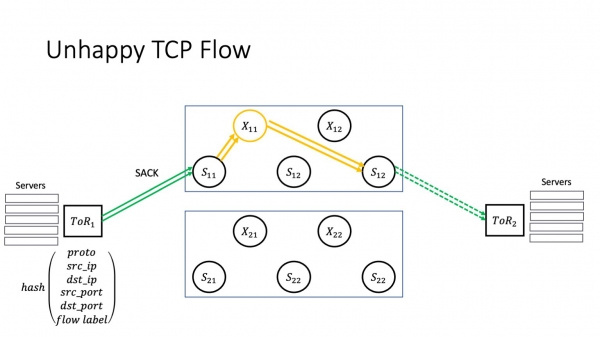
As in SACK optreedt, feroaret neat, om't wy besykje in bekend ferlern pakket opnij te ferstjoeren. Sa fier sa goed.
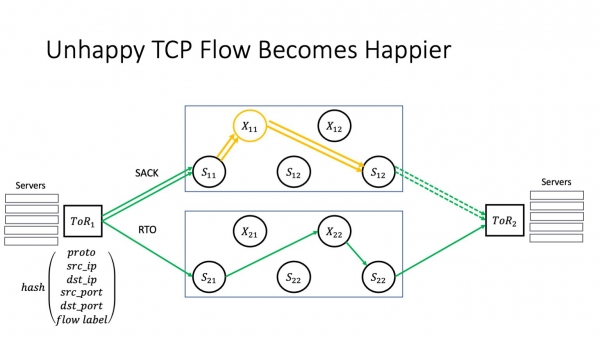
Mar yn it gefal fan RTO, op betingst dat wy in streamlabel tafoege hawwe oan 'e hashfunksje op ToR, kin it ferkear in oare rûte nimme. En hoe mear leanen, hoe grutter de kâns dat it in paad sil fine dat net wurdt beynfloede troch in mislearring op in spesifyk apparaat.
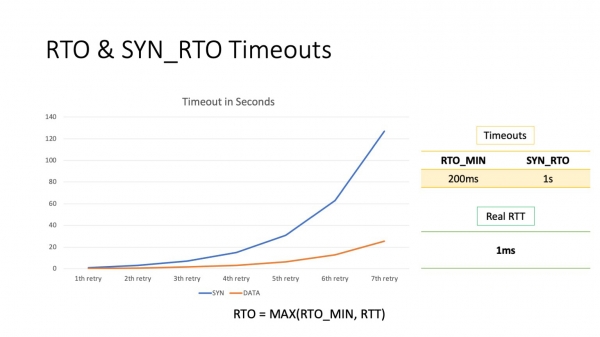
Ien probleem bliuwt - RTO. Fansels is der in oare rûte, mar dêr wurdt in soad tiid oan fergriemd. 200 ms is in protte. In twadde is perfoarst wyld. Earder haw ik it oer timeouts dy't tsjinsten binne konfigureare. Dat, in twadde is in time-out, dy't normaal wurdt konfigureare troch de tsjinst op it applikaasjenivo, en yn dit sil de tsjinst sels relatyf rjocht wêze. Boppedat, ik werhelje, de echte RTT binnen in moderne data sintrum is om 1 millisekonde.

Wat kinne jo dwaan mei RTO-timeouts? De timeout, dy't ferantwurdlik is foar RTO yn gefal fan ferlies fan gegevenspakketten, kin relatyf maklik konfigureare wurde fan brûkersromte: d'r is in IP-hulpprogramma, en ien fan syn parameters befettet deselde rto_min. Yn betinken nommen dat RTO, fansels, moat wurde oanpast net globaal, mar foar opjûne foarheaksels, sa'n meganisme liket frij wurkber.

Wier, mei SYN_RTO is alles wat slimmer. It is natuerlik spikere. De kearn hat in fêste wearde fan 1 sekonde, en dat is it. Jo kinne dêr net berikke fanút brûkersromte. Der is mar ien manier.
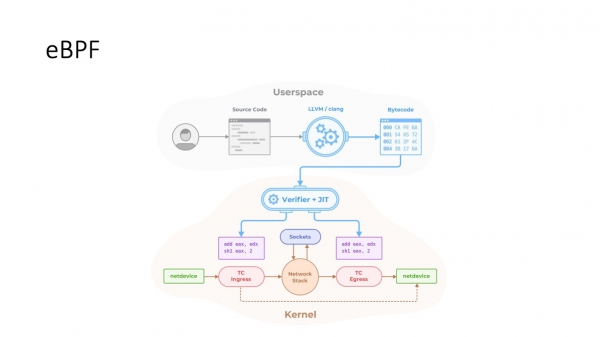
eBPF komt ta de rêding. Om it gewoan te sizzen binne dit lytse programma's C. Se kinne op ferskate plakken yn 'e útfiering fan 'e kearnstapel en de TCP-stapel yn 'e haken ynfoege wurde, wêrmei't jo in hiel grut oantal ynstellings feroarje kinne. Yn 't algemien is eBPF in lange termyn trend. Ynstee fan tsientallen nije sysctl-parameters te snijen en it IP-hulpprogramma út te wreidzjen, giet de beweging nei eBPF en wreidet de funksjonaliteit út. Mei eBPF kinne jo de kontrôles foar congestie en ferskate oare TCP-ynstellingen dynamysk feroarje.
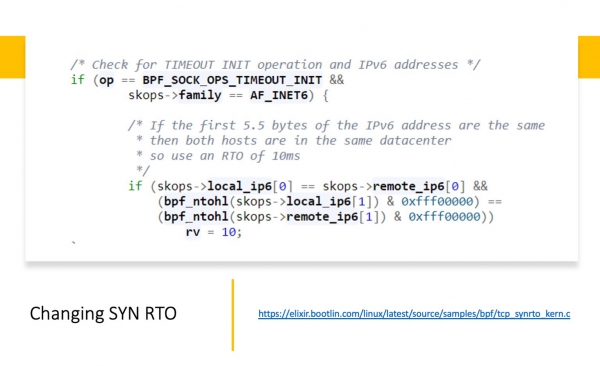
Mar it is wichtich foar ús dat it kin wurde brûkt om de SYN_RTO-wearden te feroarjen. Boppedat is d'r in iepenbier pleatst foarbyld: . Wat is hjir dien? It foarbyld wurket, mar is op himsels tige rûch. Hjir wurdt oannommen dat binnen it datasintrum wy de earste 44 bits fergelykje; as se oerienkomme, dan binne wy binnen it datasintrum. En yn dit gefal feroarje wy de SYN_RTO-timeoutwearde nei 4ms. Deselde taak kin folle eleganter dien wurde. Mar dit ienfâldige foarbyld lit sjen dat dit a) mooglik is; b) relatyf ienfâldich.

Wat witte wy al? It feit dat de fleantúcharsjitektuer skaalfergrutting mooglik makket, docht bliken dat it ekstreem nuttich is foar ús as wy it streamlabel op ToR ynskeakelje en de mooglikheid krije om probleemgebieten hinne te streamen. De bêste manier om RTO- en SYN-RTO-wearden te ferminderjen is eBPF-programma's te brûken. De fraach bliuwt: is it feilich om in streamlabel te brûken foar balânsjen? En hjir is in nuânse.
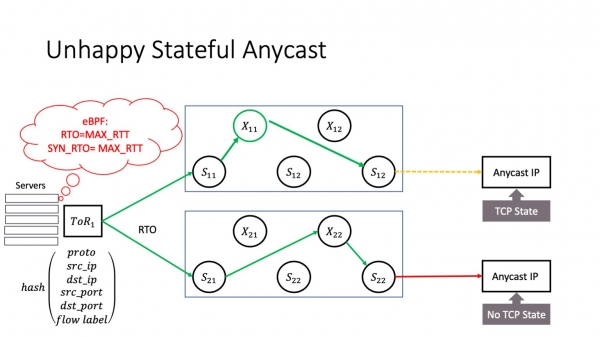
Stel dat jo in tsjinst hawwe op jo netwurk dy't yn anycast libbet. Spitigernôch, ik haw gjin tiid om te gean yn detail oer wat anycast is, mar it is in ferspraat tsjinst mei ferskate fysike tsjinners tagonklik fia itselde IP-adres. En hjir is in mooglik probleem: it RTO-evenemint kin net allinich foarkomme as ferkear troch de stof giet. It kin ek foarkomme op it ToR-buffernivo: as in incast-evenemint bart, kin it sels foarkomme op 'e host as de host wat spielet. Wannear't in RTO evenemint optreedt en it feroaret de flow label. Yn dit gefal kin ferkear nei in oare cast-eksimplaar gean. Litte wy oannimme dat dit in steatlike anycast is, it befettet in ferbiningstatus - it kin in L3 Balancer wêze as in oare tsjinst. Dan ûntstiet in probleem, want nei RTO komt de TCP-ferbining op de tsjinner, dy't neat fan dizze TCP-ferbining wit. En as wy gjin steatsdielen hawwe tusken alle cast-tsjinners, dan sil sa'n ferkear falle en de TCP-ferbining wurdt brutsen.
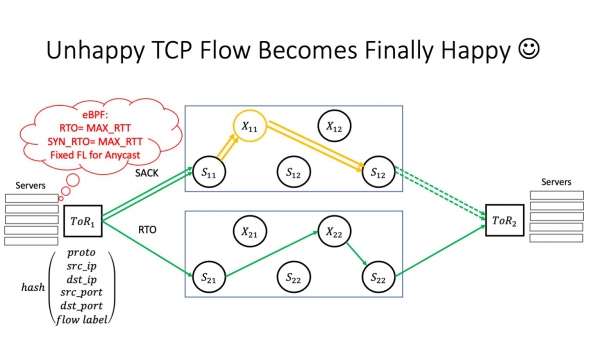
Wat kinne jo hjir dwaan? Binnen jo kontroleare omjouwing, wêr't jo balânsjen fan streamlabels ynskeakelje, moatte jo de wearde fan it streamlabel opnimme by tagong ta anycast-servers. De maklikste manier is dit te dwaan fia itselde eBPF-programma. Mar hjir is in heul wichtich punt - wat te dwaan as jo gjin datacenternetwurk hawwe, mar in telekomoperator binne? Dit is ek jo probleem: begjinnend mei bepaalde ferzjes fan Juniper en Arista, befetsje se standert in streamlabel yn har hashfunksjes - earlik sein, om in reden dy't my ûndúdlik is. Dit kin feroarsaakje dat jo TCP-ferbiningen falle fan brûkers dy't troch jo netwurk passe. Dat ik riede tige oan om jo routerynstellingen hjir te kontrolearjen.
Op ien of oare manier liket it my ta dat wy ree binne om oer te gean nei eksperiminten.
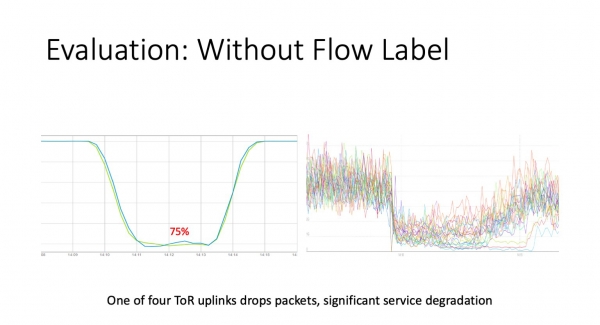
Doe't wy it streamlabel op ToR ynskeakele, de eBPF-agint tariede, dy't no op 'e hosts libbet, besleaten wy net te wachtsjen op 'e folgjende grutte mislearring, mar om kontroleare eksploazjes út te fieren. Wy namen ToR, dy't fjouwer uplinks hat, en sette drops op ien fan har op. Se tekene in regel en seine - no binne jo alle pakketten kwyt. As jo links sjen kinne, hawwe wy per-pakketmonitoring, dy't sakke is nei 75%, dat is, 25% fan pakketten binne ferlern. Oan 'e rjochterkant binne grafiken fan tsjinsten dy't efter dizze ToR libje. Yn essinsje binne dit ferkearsgrafiken fan 'e ynterfaces mei servers binnen it rack. Sa't jo sjen kinne, sonken se noch leger. Wêrom foelen se leger - net mei 25%, mar yn guon gefallen mei 3-4 kear? As de TCP-ferbining pech hat, bliuwt it besykjen te berikken troch it brutsen knooppunt. Dit wurdt fergrutte troch it typyske gedrach fan 'e tsjinst binnen de DC - foar ien brûkersfersyk wurde N oanfragen oan ynterne tsjinsten oanmakke, en it antwurd sil nei de brûker gean as alle gegevensboarnen reagearje, of as in time-out optreedt by de applikaasje nivo, dat noch moat wurde konfigurearre. Dat is, alles is heul, heul min.
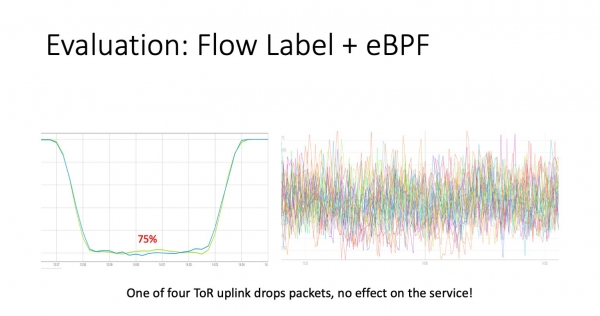
No itselde eksperimint, mar mei de flow label wearde ynskeakele. Lykas jo kinne sjen, sakke ús batchmonitoring oan 'e linkerkant mei deselde 25%. Dit is absolút korrekt, om't it neat wit oer retransmits, it stjoert pakketten en telt gewoan de ferhâlding fan it oantal levere en ferlerne pakketten.
En oan 'e rjochterkant is it tsjinstskema. Jo sille it effekt fan in problematyske joint hjir net fine. Yn dyselde millisekonden streamde ferkear fan it probleemgebiet nei de trije oerbleaune uplinks dy't net beynfloede waarden troch it probleem. Wy krigen in netwurk dat himsels genêzen.

Dit is myn lêste slide; tiid om ôf te sluten. No hoopje ik dat jo witte hoe't jo in selsherstellend datasintrumnetwurk bouwe kinne. Jo hoege net yn it kernelargyf te dûken. Linux En sykje dêr nei spesjale patches. Jo witte dat Flow Label it probleem yn dit gefal oplost, mar jo moatte dit meganisme mei foarsichtigens benaderje. En ik beklamje nochris dat as jo in telekomoperator binne, jo Flow Label net as in hashfunksje brûke moatte, oars fersteure jo de sesjes fan jo brûkers.
Netwurkingenieurs moatte in konseptuele ferskowing ûndergean: it netwurk begjint net mei de ToR, net mei it netwurkapparaat, mar mei de host. In frij opfallend foarbyld is hoe't wy eBPF brûke sawol om de RTO te feroarjen as om it streamlabel te reparearjen nei anycast-tsjinsten.
De meganika fan 'e flowlabel binne grif geskikt foar oare tapassingen binnen it kontroleare bestjoerlike segmint. Dit kin ferkear wêze tusken datasintra, of jo kinne sokke meganika op in spesjale manier brûke om útgeand ferkear te behearjen. Mar ik sil jo hjiroer fertelle, hoopje ik, de folgjende kear. Tige tank foar jo oandacht.
Boarne: www.habr.com
