

Hallo elkenien, myn namme is Alexander, en ik bin in yngenieur fan gegevenskwaliteit dy't gegevens kontrolearret op har kwaliteit. Dit artikel sil prate oer hoe't ik hjiroan kaam en wêrom yn 2020 dit gebiet fan testen op 'e top fan in welle wie.

Global trend
De wrâld fan hjoed belibbet in oare technologyske revolúsje, ien aspekt dêrfan is it brûken fan opboude gegevens troch alle soarten bedriuwen om har eigen fleanwiel fan ferkeap, winst en PR te befoarderjen. It liket derop dat de oanwêzigens fan goede (kwaliteit) gegevens, lykas betûfte harsens dy't der jild fan meitsje kinne (korrekt ferwurkje, fisualisearjen, masine-learmodellen bouwe, ensfh.), binne de kaai wurden foar sukses foar in protte hjoed. As 15-20 jier lyn grutte bedriuwen benammen belutsen wiene by yntinsyf wurk mei gegevensakkumulaasje en monetarisaasje, hjoed is dit it lot fan hast alle sûne minsken.
Yn dit ferbân, ferskate jierren lyn begon alle portalen wijd oan wurksykjen om 'e wrâld te foljen mei fakatueres foar Data Scientists, om't elkenien der wis fan wie dat, nei it ynhieren fan sa'n spesjalist, it mooglik wêze soe om in supermodel fan masine learen te bouwen , foarsizze de takomst en útfiere in "quantum sprong" foar it bedriuw. Yn 'e rin fan' e tiid realisearre minsken dat dizze oanpak hast noait oeral wurket, om't net alle gegevens dy't yn 'e hannen fan sokke spesjalisten falle binne geskikt foar trainingsmodellen.
En oanfragen fan Data Scientists begûnen: "Litte wy mear gegevens keapje fan dizze en dy ...", "Wy hawwe net genôch gegevens ...", "Wy hawwe wat mear gegevens nedich, leafst ien fan hege kwaliteit ..." . Op grûn fan dizze oanfragen begon tal fan ynteraksjes te bouwen tusken bedriuwen dy't ien of oare set gegevens hawwe. Fansels easke dit de technyske organisaasje fan dit proses - ferbining mei de gegevensboarne, ynlade, kontrolearje of it folslein laden wie, ensfh. spesjalisten - Data Quality yngenieurs - dyjingen dy't soe tafersjoch op de stream fan gegevens yn it systeem (data pipelines), de kwaliteit fan gegevens by de ynfier en útfier, en lûke konklúzjes oer harren genôchens, yntegriteit en oare skaaimerken.
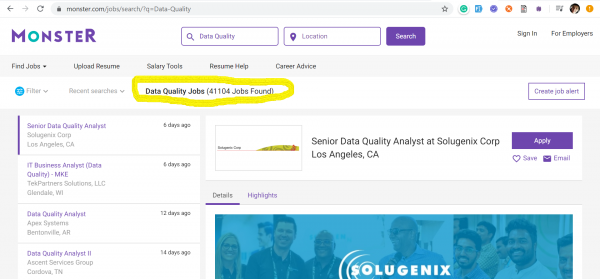
De trend foar yngenieurs foar gegevenskwaliteit kaam nei ús út 'e FS, wêr't, yn' e midden fan it razende tiidrek fan kapitalisme, gjinien ree is om de striid om gegevens te ferliezen. Hjirûnder haw ik skermôfbyldings levere fan twa fan 'e populêrste siden foar wurksykjen yn' e FS: и - dy't gegevens werjaan fanôf 17 maart 2020 oer it oantal pleatste fakatueres ûntfongen mei de kaaiwurden: Data Quality and Data Scientist.
Data Scientists - 21416 fakatueres
Gegevenskwaliteit - 41104 fakatueres
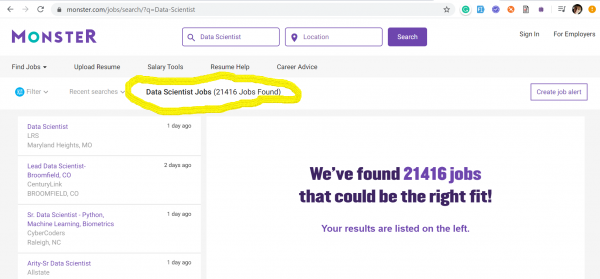
Data Scientists - 404 fakatueres
Gegevenskwaliteit - fakatueres 2020
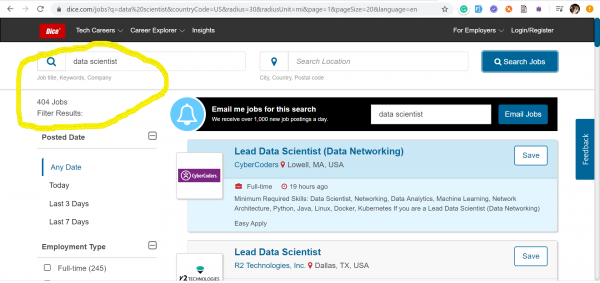
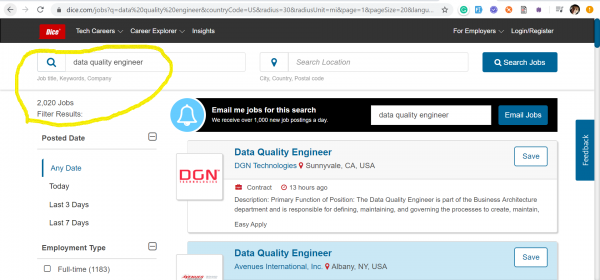
Fansels binne dizze beroppen op gjin inkelde manier mei elkoar konkurrearje. Mei skermôfbyldings woe ik gewoan de hjoeddeistige situaasje op 'e arbeidsmerk yllustrearje oangeande oanfragen foar yngenieurs fan Data Quality, fan wa't no folle mear nedich binne as Data Scientists.
Yn juny 2019 skiede EPAM, yn antwurd op de behoeften fan 'e moderne IT-merk, Data Quality yn in aparte praktyk. Yngenieurs fan gegevenskwaliteit, yn 'e rin fan har deistich wurk, beheare gegevens, kontrolearje har gedrach yn nije omstannichheden en systemen, kontrolearje de relevânsje fan' e gegevens, har genôchens en relevânsje. Mei dit alles, yn praktyske sin, besteegje yngenieurs fan Data Quality wirklik bytsje tiid oan klassike funksjonele testen, BUT dit hinget sterk ôf fan it projekt (ik sil hjirûnder in foarbyld jaan).
De ferantwurdlikheden fan in yngenieur foar gegevenskwaliteit binne net allinich beheind ta routine hantlieding / automatyske kontrôles foar "nullen, tellen en sommen" yn databasetabellen, mar fereaskje in djip begryp fan 'e saaklike behoeften fan 'e klant en, dus, de mooglikheid om beskikbere gegevens te transformearjen yn brûkbere saaklike ynformaasje.
Data Quality Theory

Om de rol fan sa'n yngenieur folsleiner foar te stellen, litte wy útfine wat gegevenskwaliteit yn teory is.
Data kwaliteit - ien fan 'e stadia fan Data Management (in hiele wrâld dy't wy foar jo sille ferlitte om op jo eigen te studearjen) en is ferantwurdlik foar it analysearjen fan gegevens neffens de folgjende kritearia:
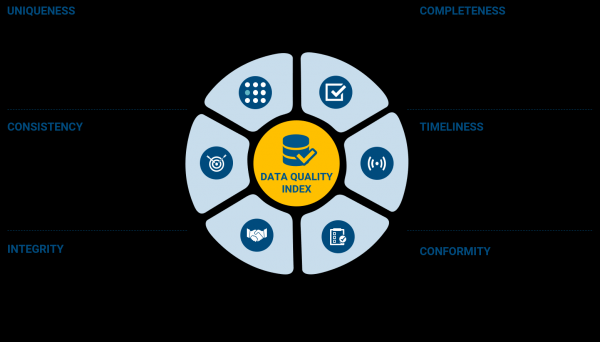
Ik tink dat d'r gjin need is om elk fan 'e punten te ûntsiferjen (yn teory wurde se "data-dimensjes" neamd), se binne frij goed beskreaun yn 'e foto. Mar it testproses sels betsjut net dat dizze funksjes strikt kopiearje yn testgefallen en se kontrolearje. Yn Gegevenskwaliteit, lykas yn elke oare soart testen, is it foarearst nedich om te bouwen op 'e easken foar gegevenskwaliteit ôfpraat mei de projektdielnimmers dy't saaklike besluten nimme.
Ofhinklik fan it Data Quality-projekt kin in yngenieur ferskate funksjes útfiere: fan in gewoane automatisearringstester mei in oerflakkige beoardieling fan gegevenskwaliteit, oant in persoan dy't djippe profilearring fan 'e gegevens fiert neffens de boppesteande kritearia.
In heul detaillearre beskriuwing fan 'e gegevensbehear, gegevenskwaliteit en besibbe prosessen is goed beskreaun yn it boek neamd "DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition". Ik rekommandearje dit boek tige oan as ynlieding foar dit ûnderwerp (jo sille in keppeling dernei fine oan 'e ein fan it artikel).
Myn ferhaal
Yn 'e IT-sektor wurke ik myn wei omheech fan in Junior tester yn produktbedriuwen nei in Lead Data Quality Engineer by EPAM. Nei sa'n twa jier wurkjen as tester, hie ik de fêste oertsjûging dat ik absolút alle soarten testen dien hie: regression, funksjoneel, stress, stabiliteit, feiligens, UI, ensfh. - en besocht in grut oantal testynstruminten, mei wurke tagelyk yn trije programmeartalen: Java, Scala, Python.
As ik weromsjoch, begryp ik wêrom't myn feardigensset sa ferskaat wie - ik wie belutsen by data-oandreaune projekten, grut en lyts. Dit is wat my brocht yn in wrâld fan in protte ark en kânsen foar groei.
Om it ferskaat oan ark en kânsen te wurdearjen om nije kennis en feardigens te krijen, sjoch gewoan nei de ôfbylding hjirûnder, dy't de populêrste toant yn 'e wrâld "Data & AI".

Dit soarte fan yllustraasje wurdt jierliks gearstald troch ien fan 'e ferneamde venture capitalists Matt Turck, dy't komt fan software ûntwikkeling. Hjir nei syn blog en , dêr't er wurket as partner.
Ik groeide profesjoneel benammen fluch doe't ik wie de ienige tester op it projekt, of op syn minst oan it begjin fan it projekt. It is op sa'n momint dat jo ferantwurdlik wêze moatte foar it hiele testproses, en jo hawwe gjin kâns om werom te lûken, allinich foarút. Earst wie it eng, mar no binne alle foardielen fan sa'n test foar my dúdlik:
- Jo begjinne te kommunisearjen mei it heule team lykas nea earder, om't d'r gjin proxy is foar kommunikaasje: noch de testmanager noch oare testers.
- De ûnderdompeling yn it projekt wurdt ongelooflijk djip, en jo hawwe ynformaasje oer alle komponinten, sawol yn it algemien as yn detail.
- Untwikkelders sjogge jo net as "dy testman dy't net wit wat hy docht", mar as in lykweardich dy't ongelooflijke foardielen produsearret foar it team mei syn automatisearre tests en ferwachting fan bugs dy't ferskine yn in spesifike komponint fan 'e produkt.
- As gefolch binne jo effektiver, mear kwalifisearre en mear yn fraach.
As it projekt groeide, waard ik yn 100% fan 'e gefallen in mentor foar nije testers, learde se en joech de kennis troch dy't ik sels leard hie. Tagelyk krige ik, ôfhinklik fan it projekt, net altyd it heechste nivo fan spesjalisten foar autotesten fan it management en wie d'r ferlet om se te trenen yn automatisearring (foar belangstellenden) of ark te meitsjen foar gebrûk yn deistige aktiviteiten (ark foar it generearjen fan gegevens en it laden yn it systeem, in ark foar it útfieren fan loadtesten / stabiliteitstests "fluch", ensfh.).
Foarbyld fan in spesifyk projekt
Spitigernôch kin ik fanwegen net-ferplichtingen net yn detail prate oer de projekten dêr't ik oan wurke haw, mar ik sil foarbylden jaan fan typyske taken fan in Data Quality Engineer op ien fan 'e projekten.
De essinsje fan it projekt is it ymplementearjen fan in platfoarm foar it tarieden fan gegevens foar training fan masine-learmodellen basearre op it. De klant wie in grut farmaseutysk bedriuw út 'e FS. Technysk wie it in kluster , opkommen oan eksimplaren, mei ferskate mikrotsjinsten en it ûnderlizzende Open Source-projekt fan EPAM - , oanpast oan 'e behoeften fan in spesifike klant (no is it projekt opnij berne yn ). ETL-prosessen waarden organisearre mei help fan en ferpleatst gegevens út klant systemen yn Emmers. Dêrnei waard in Docker-ôfbylding fan in masine-learmodel op it platfoarm ynset, dat waard oplaat op farske gegevens en, mei de REST API-ynterface, produsearre foarsizzingen dy't fan belang wiene foar it bedriuw en spesifike problemen oplosse.
Visueel seach alles der sa út:
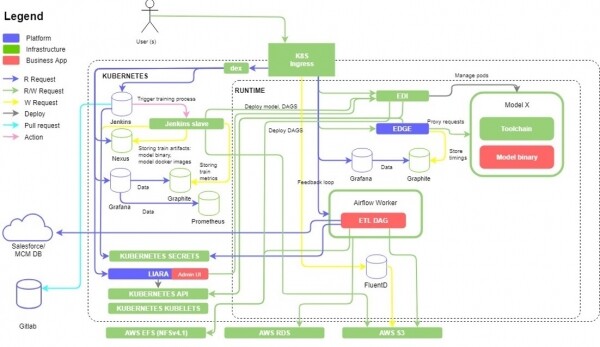
D'r wiene genôch funksjonele testen op dit projekt, en sjoen de snelheid fan funksjeûntwikkeling en de needsaak om it tempo fan 'e frijlittingssyklus te behâlden (sprints fan twa wiken), wie it needsaaklik om fuortendaliks nei te tinken oer it automatisearjen fan testen fan' e meast krityske komponinten fan it systeem. It grutste part fan it Kubernetes-basearre platfoarm sels waard dekt troch autotests ymplementearre yn + Python, mar it wie ek nedich om se te stypjen en út te wreidzjen. Derneist, foar it gemak fan 'e klant, waard in GUI makke om masine-learmodellen te behearjen dy't ynset binne nei it kluster, lykas ek de mooglikheid om oan te jaan wêr't en wêr't gegevens moatte wurde oerdroegen foar it oplieden fan de modellen. Dizze wiidweidige tafoeging omfette in útwreiding fan automatisearre funksjonele testen, dy't meast waard dien fia REST API-oproppen en in lyts oantal ein-2-ein UI-tests. Om de evener fan al dizze beweging waarden wy tegearre mei in manuele tester dy't in poerbêste baan die mei akseptaasjetesten fan produktferzjes en kommunisearje mei de klant oangeande de akseptaasje fan 'e folgjende release. Dêrnjonken koene wy, troch de komst fan in nije spesjalist, ús wurk dokumintearje en ferskate heul wichtige hânkontrôles tafoegje dy't daliks dreech te automatisearjen wiene.
En úteinlik, nei't wy stabiliteit fan it platfoarm en de GUI-tafoeging deroer hawwe berikt, begon wy ETL-pipelines te bouwen mei Apache Airflow DAG's. Automatisearre gegevenskwaliteitskontrôle waard útfierd troch spesjale Airflow DAG's te skriuwen dy't de gegevens kontroleare op basis fan 'e resultaten fan it ETL-proses. As ûnderdiel fan dit projekt, wy wiene gelok en de klant joech ús tagong ta anonime datasets dêr't wy testen. Wy kontrolearren de gegevens rigel foar rigel foar neilibjen fan typen, de oanwêzigens fan brutsen gegevens, it totale oantal records foar en nei, fergeliking fan transformaasjes makke troch it ETL-proses foar aggregaasje, feroarjen fan kolomnammen, en oare dingen. Derneist waarden dizze kontrôles skalearre nei ferskate gegevensboarnen, bygelyks neist SalesForce, ek nei MySQL.
Finale gegevenskwaliteitskontrôles waarden al útfierd op it S3-nivo, wêr't se waarden opslein en klear te brûken foar training fan masine-learmodellen. Om gegevens te krijen fan it definitive CSV-bestân op 'e S3 Bucket en it te falidearjen, waard koade skreaun mei .
D'r wie ek in eask fan 'e klant om in diel fan' e gegevens op te slaan yn ien S3 Bucket en diel yn in oar. Dit easke ek it skriuwen fan ekstra kontrôles om de betrouberens fan sa'n sortearring te kontrolearjen.
Algemien ûnderfining fan oare projekten
In foarbyld fan 'e meast algemiene list mei aktiviteiten fan in yngenieur foar gegevenskwaliteit:
- Tariede testgegevens (jildich ûnjildich grut lyts) fia in automatisearre ark.
- Upload de tariede gegevensset nei de orizjinele boarne en kontrolearje dat it klear is foar gebrûk.
- Start ETL-prosessen foar it ferwurkjen fan in set gegevens fan 'e boarne opslach nei de definitive of tuskenlizzende opslach mei in bepaalde set ynstellings (as it mooglik is, ynstelle konfigurearbere parameters foar de ETL-taak).
- Ferifiearje gegevens ferwurke troch it ETL-proses foar har kwaliteit en neilibjen fan saaklike easken.
Tagelyk moat de haadfokus fan kontrôles net allinich wêze op it feit dat de gegevensstream yn it systeem yn prinsipe wurke hat en foltôging berikt (wat diel is fan funksjonele testen), mar meast op it kontrolearjen en validearjen fan gegevens foar neilibjen fan ferwachte easken, identifisearjen fan anomalies en oare dingen.
Tools
Ien fan 'e techniken foar sokke gegevenskontrôle kin de organisaasje fan ketenkontrôles wêze yn elke poadium fan gegevensferwurking, de saneamde "gegevensketen" yn 'e literatuer - kontrôle fan gegevens fan 'e boarne oant it punt fan úteinlik gebrûk. Dizze soarten kontrôles wurde meastentiids ymplementearre troch it skriuwen fan kontrolearjende SQL-fragen. It is dúdlik dat sokke fragen sa licht mooglik wêze moatte en yndividuele stikken gegevenskwaliteit kontrolearje (metadata fan tabellen, lege rigels, NULL's, Flaters yn syntaksis - oare attributen nedich foar kontrôle).
Yn it gefal fan regressiontesten, dy't gebrûk meitsje fan klearmakke (net te feroarjen, in bytsje feroare) datasets, kin de autotestkoade klearmakke sjabloanen opslaan foar it kontrolearjen fan gegevens op konformiteit mei kwaliteit (beskriuwings fan ferwachte tabelmetadata; rige foarbyldobjekten dy't kinne wurde willekeurich selektearre tidens de test, ensfh.).
Ek moatte jo tidens testen ETL-testprosessen skriuwe mei help fan kaders lykas Apache Airflow, of sels in black-box wolk type ark , Ensafuorthinne. Dizze omstannichheid twingt de test-yngenieur om him te ferdjipjen yn 'e prinsipes fan wurking fan' e boppesteande ark en noch effektiver sawol funksjonele testen (bygelyks besteande ETL-prosessen op in projekt) en brûke se om gegevens te kontrolearjen. Benammen Apache Airflow hat ready-made operators foar wurkjen mei populêre analytyske databases, bygelyks . It meast basale foarbyld fan it gebrûk is al sketst , dus ik sil my net werhelje.
Utsein klearmakke oplossingen, gjinien ferbiedt jo om jo eigen techniken en ark út te fieren. Dit sil net allinich foardielich wêze foar it projekt, mar ek foar de Data Quality Engineer sels, dy't dêrmei syn technyske horizonten en kodearringfeardigens ferbetterje sil.
Hoe't it wurket op in echt projekt
In goede yllustraasje fan 'e lêste paragrafen oer de "gegevensketen", ETL en ubiquitêre kontrôles is it folgjende proses fan ien fan 'e echte projekten:
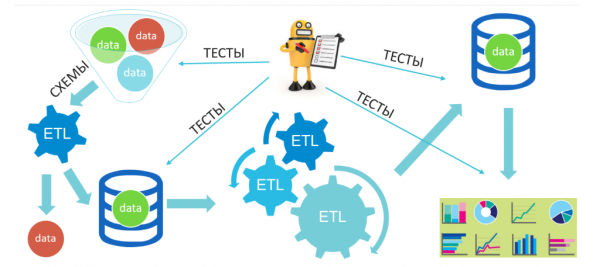
Hjir komme ferskate gegevens (natuerlik, taret troch ús) de ynfier "trechter" fan ús systeem yn: jildich, ûnjildich, mingd, ensfh., dan wurde se filtere en einigje yn in tuskenopslach, dan ûndergeane se wer in searje transformaasjes en wurde pleatst yn 'e definitive opslach, wêrfan't, op syn beurt, analytiken, it bouwen fan datamarts en it sykjen nei saaklike ynsjoch sille wurde útfierd. Yn sa'n systeem, sûnder funksjoneel te kontrolearjen fan 'e wurking fan ETL-prosessen, rjochtsje wy ús op' e kwaliteit fan gegevens foar en nei transformaasjes, lykas op 'e útfier nei analytyk.
Om it boppesteande te gearfetten, nettsjinsteande de plakken wêr't ik wurke, wie ik oeral belutsen by Data-projekten dy't de folgjende funksjes dielde:
- Allinich fia automatisearring kinne jo guon gefallen testen en in frijlittingssyklus berikke dy't akseptabel is foar it bedriuw.
- In tester op sa'n projekt is ien fan 'e meast respekteare leden fan it team, om't it grutte foardielen foar elk fan' e dielnimmers bringt (fersnelling fan testen, goede gegevens fan 'e Data Scientist, identifikaasje fan defekten yn' e iere stadia).
- It makket net út oft jo oan jo eigen hardware of yn 'e wolken wurkje - alle boarnen wurde abstrahearre yn in kluster lykas Hortonworks, Cloudera, Mesos, Kubernetes, ensfh.
- Projekten binne boud op in microservice oanpak, ferspraat en parallel computing oerhearskje.
Ik wol opmerke dat by it dwaan fan testen op it mêd fan gegevenskwaliteit, in testspesjalist syn profesjonele fokus ferpleatst nei de koade fan it produkt en de brûkte ark.
Underskate skaaimerken fan testen fan gegevenskwaliteit
Derneist haw ik foar mysels de folgjende identifisearre (ik sil daliks reservearje dat se Hiel generalisearre en eksklusyf subjektyf binne) ûnderskiedende skaaimerken fan testen yn Data (Big Data) projekten (systemen) en oare gebieten:

Nuttige keppelings
- Teory: .
- EPAM
- Oanrikkemandearre materialen foar in begjinnende yngenieur foar gegevenskwaliteit:
- Fergees kursus oer Stepik: .
- Kursus oer LinkedIn Learning: .
- Artikels:
- ;
- ;
- ;
- Video:
- ;
- ;
konklúzje
Data kwaliteit is in heul jonge belofte rjochting, om diel te wêzen fan dat betsjut diel te wêzen fan in opstart. Ien kear yn Gegevenskwaliteit sille jo ûnderdompele wurde yn in grut oantal moderne technologyen op fraach, mar it wichtichste, enoarme kânsen sille foar jo iepenje om jo ideeën te generearjen en út te fieren. Jo sille de oanpak foar trochgeande ferbettering net allinich kinne brûke op it projekt, mar ek foar josels, kontinu ûntwikkeljen as spesjalist.
Boarne: www.habr.com
