

Go tréimhsiúil, tagann an tasc chun cuardach a dhéanamh ar shonraí gaolmhara ag baint úsáide as sraith eochracha. go dtí go bhfaighimid an líon iomlán taifead riachtanach.
Is é an sampla is “fíorshaol” le taispeáint 20 fadhbanna is sine, liostaithe ar liosta na bhfostaithe (mar shampla, laistigh de rannán amháin). I gcás “deais” bainistíochta éagsúla le hachoimrí gearra ar réimsí oibre, is minic a bhíonn ábhar cosúil leis ag teastáil.

San Airteagal seo féachfaimid ar chur i bhfeidhm i PostgreSQL réiteach “naive” ar fhadhb den sórt sin, algartam “níos cliste” agus an-chasta. “lúb” in SQL le coinníoll scoir ó na sonraí aimsithe, is féidir a bheith úsáideach le haghaidh forbairt ghinearálta agus le húsáid i gcásanna eile dá samhail.
Tógfaimid tacar sonraí tástála ó . Chun na taifid ar taispeáint a chosc ó “léim” ó am go chéile nuair a bhíonn na luachanna sórtáilte ag an am céanna, an t-innéacs ábhair a leathnú trí eochair phríomha a chur leis. Ag an am céanna, tabharfaidh sé seo uathúlacht láithreach dó agus ráthóidh sé dúinn go bhfuil an t-ordú sórtála gan athbhrí:
CREATE INDEX ON task(owner_id, task_date, id);
-- а старый - удалим
DROP INDEX task_owner_id_task_date_idx;Mar a chloistear, mar sin tá sé scríofa
Gcéad dul síos, déanaimis sceitse amach an leagan is simplí den iarratas, ag tabhairt aitheantais na n-taibheoirí :
SELECT
*
FROM
task
WHERE
owner_id = ANY('{1,2,4,8,16,32,64,128,256,512}'::integer[])
ORDER BY
task_date, id
LIMIT 20; 
Beagán brónach - níor ordaigh muid ach 20 taifead, ach chuir Index Scan ar ais chugainn é 960 líne, a bhí ansin freisin le bheith curtha in eagar... Déanaimis iarracht níos lú a léamh.
aimhleas + ARRAY
Is é an chéad chomaoin a chabhróidh linn ná má theastaíonn uainn ach 20 curtha in eagar taifid, ansin díreach a léamh nach mó ná 20 curtha in eagar san ord céanna do gach ceann acu eochair. Maith, innéacs oiriúnach (úinéir_id, tasc_date, id) atá againn.
Bainimis úsáid as an meicníocht chéanna chun asbhaint agus “scaipeadh isteach i gcolúin” taifead tábla lárnach, mar atá i . Is féidir linn fillte a chur i bhfeidhm freisin ag baint úsáide as an bhfeidhm ARRAY():
WITH T AS (
SELECT
unnest(ARRAY(
SELECT
t
FROM
task t
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 20 -- ограничиваем тут...
)) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
(r).*
FROM
T
ORDER BY
(r).task_date, (r).id
LIMIT 20; -- ... и тут - тоже 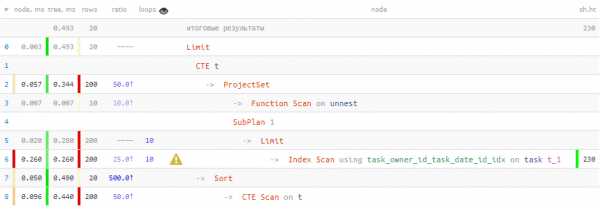
Ó, i bhfad níos fearr cheana féin! 40% níos tapúla agus 4.5 uair níos lú sonraí Bhí orm é a léamh.
Taifid tábla a chur i gcrích trí CTELig dom d’aird a tharraingt ar an bhfíric go bhfuil i gcásanna áirithe Má dhéantar iarracht oibriú láithreach le réimsí taifid tar éis é a chuardach i bhfocheist, gan é a “timfhilleadh” i CTE, d’fhéadfadh go dtiocfadh "iolrú" InitPlan i gcomhréir le líon na réimsí céanna seo:
SELECT
((
SELECT
t
FROM
task t
WHERE
owner_id = 1
ORDER BY
task_date, id
LIMIT 1
).*);Result (cost=4.77..4.78 rows=1 width=16) (actual time=0.063..0.063 rows=1 loops=1)
Buffers: shared hit=16
InitPlan 1 (returns $0)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.031..0.032 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t (cost=0.42..387.57 rows=500 width=48) (actual time=0.030..0.030 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 2 (returns $1)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_1 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 3 (returns $2)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_2 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4"
InitPlan 4 (returns $3)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_3 (cost=0.42..387.57 rows=500 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
Breathnaíodh ar an taifead céanna 4 huaire... Suas go dtí PostgreSQL 11, tarlaíonn an t-iompar seo go rialta, agus is é an réiteach atá ann ná é a "timfhilleadh" i CTE, teorainn iomlán don optimizer sna leaganacha seo.
Carnán athfhillteach
Sa leagan roimhe seo, san iomlán a léamh againn 200 líne ar mhaithe leis an 20 riachtanach. Ní 960, ach níos lú fós - an bhfuil sé indéanta?
Déanaimis iarracht an t-eolas atá de dhíth orainn a úsáid iomlán 20 taifid. Is é sin, ní dhéanfaimid athrá ar léamh sonraí ach amháin go dtí go sroichfimid an méid a theastaíonn uainn.
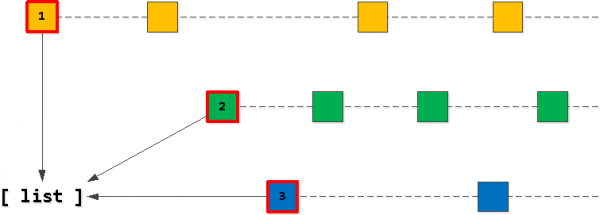
Céim 1: Liosta Tosaigh
Ar ndóigh, ba cheart go dtosódh ár liosta “sprioc” de 20 taifead leis na “céad thaifid” do cheann dár n-eochracha úinéara_id. Dá bhrí sin, ar dtús beidh muid ag teacht ar a leithéid “an chéad cheann” do gach ceann de na heochracha agus é a chur leis an liosta, é a shórtáil san ord ba mhaith linn - (task_date, id).
Céim 2: Faigh na hiontrálacha “seo chugainn”.
Anois má thógaimid an chéad iontráil ónár liosta agus tosú “céim” níos faide ar aghaidh an innéacs ag caomhnú na heochair úinéir_id, ansin is iad na taifid go léir a aimsíodh go díreach na cinn eile sa roghnú mar thoradh air. Ar ndóigh, amháin go dtí go dtrasnaíonn muid an eochair Butt an dara hiontráil sa liosta.
Má tharlaíonn sé gur “thrasnaigh” muid an dara taifead, ansin ba chóir an iontráil dheireanach a léamh a chur leis an liosta in ionad an chéad cheann (leis an úinéir_id céanna), agus ina dhiaidh sin déanaimid an liosta a athshórtáil arís.
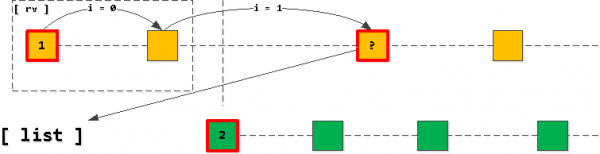
Is é sin, tuigimid i gcónaí nach bhfuil níos mó ná iontráil amháin ar an liosta le haghaidh gach ceann de na heochracha (má ritheann na hiontrálacha amach agus mura gcuirimid "trasnú", ansin imeoidh an chéad iontráil ón liosta agus ní chuirfear aon rud leis ), agus siad i gcónaí curtha in eagar in ord ardaitheach na heochrach feidhmchláir (task_date, id).
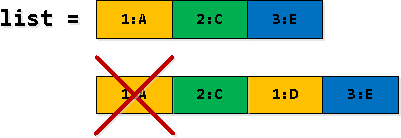
Céim 3: taifid a scagadh agus a “leathnú”.
I roinnt de na sraitheanna dár rogha athchúrsach, roinnt taifead rv a mhacasamhlú - ar dtús faighimid cosúil le “trasnú teorann an 2ú iontráil ar an liosta”, agus ansin cuirimid ina ionad é mar an 1ú háit ón liosta. Mar sin is gá an chéad tarlú a scagadh.
An cheist deiridh scanrúil
WITH RECURSIVE T AS (
-- #1 : заносим в список "первые" записи по каждому из ключей набора
WITH wrap AS ( -- "материализуем" record'ы, чтобы обращение к полям не вызывало умножения InitPlan/SubPlan
WITH T AS (
SELECT
(
SELECT
r
FROM
task r
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 1
) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
array_agg(r ORDER BY (r).task_date, (r).id) list -- сортируем список в нужном порядке
FROM
T
)
SELECT
list
, list[1] rv
, FALSE not_cross
, 0 size
FROM
wrap
UNION ALL
-- #2 : вычитываем записи 1-го по порядку ключа, пока не перешагнем через запись 2-го
SELECT
CASE
-- если ничего не найдено для ключа 1-й записи
WHEN X._r IS NOT DISTINCT FROM NULL THEN
T.list[2:] -- убираем ее из списка
-- если мы НЕ пересекли прикладной ключ 2-й записи
WHEN X.not_cross THEN
T.list -- просто протягиваем тот же список без модификаций
-- если в списке уже нет 2-й записи
WHEN T.list[2] IS NULL THEN
-- просто возвращаем пустой список
'{}'
-- пересортировываем словарь, убирая 1-ю запись и добавляя последнюю из найденных
ELSE (
SELECT
coalesce(T.list[2] || array_agg(r ORDER BY (r).task_date, (r).id), '{}')
FROM
unnest(T.list[3:] || X._r) r
)
END
, X._r
, X.not_cross
, T.size + X.not_cross::integer
FROM
T
, LATERAL(
WITH wrap AS ( -- "материализуем" record
SELECT
CASE
-- если все-таки "перешагнули" через 2-ю запись
WHEN NOT T.not_cross
-- то нужная запись - первая из спписка
THEN T.list[1]
ELSE ( -- если не пересекли, то ключ остался как в предыдущей записи - отталкиваемся от нее
SELECT
_r
FROM
task _r
WHERE
owner_id = (rv).owner_id AND
(task_date, id) > ((rv).task_date, (rv).id)
ORDER BY
task_date, id
LIMIT 1
)
END _r
)
SELECT
_r
, CASE
-- если 2-й записи уже нет в списке, но мы хоть что-то нашли
WHEN list[2] IS NULL AND _r IS DISTINCT FROM NULL THEN
TRUE
ELSE -- ничего не нашли или "перешагнули"
coalesce(((_r).task_date, (_r).id) < ((list[2]).task_date, (list[2]).id), FALSE)
END not_cross
FROM
wrap
) X
WHERE
T.size < 20 AND -- ограничиваем тут количество
T.list IS DISTINCT FROM '{}' -- или пока список не кончился
)
-- #3 : "разворачиваем" записи - порядок гарантирован по построению
SELECT
(rv).*
FROM
T
WHERE
not_cross; -- берем только "непересекающие" записи 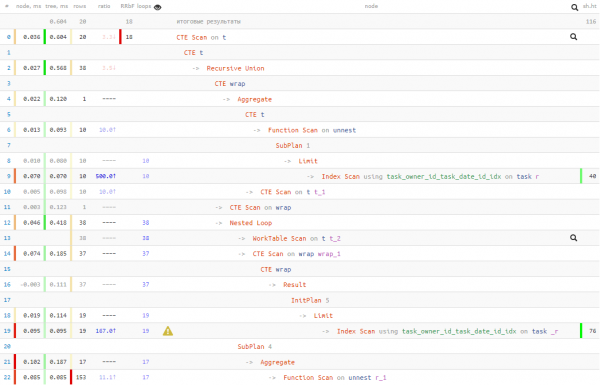
Dá bhrí sin, táimid Léann 50% de na sonraí a thrádáil ar feadh 20% den am forghníomhaithe. Is é sin, má tá cúiseanna agat chun a chreidiúint go bhféadfadh go dtógfaidh léamh ar feadh i bhfad (mar shampla, is minic nach mbíonn na sonraí sa taisce, agus caithfidh tú dul chuig diosca dó), ansin ar an mbealach seo is féidir leat a bheith ag brath níos lú ar léamh .
Ar aon chuma, b'fhearr an t-am forghníomhaithe ná mar a bhí sa chéad rogha "naive". Ach cé acu de na 3 rogha seo atá le húsáid agatsa.
Foinse: will.com
