


A base de datos de series temporais (TSDB) en Prometheus 2 é un excelente exemplo dunha solución de enxeñería que ofrece melloras importantes sobre o almacenamento v2 en Prometheus 1 en termos de velocidade de acumulación de datos, execución de consultas e eficiencia dos recursos. Estivemos a implementar Prometheus 2 en Percona Monitoring and Management (PMM) e tiven a oportunidade de comprender o rendemento de Prometheus 2 TSDB. Neste artigo falarei dos resultados destas observacións.
Carga de traballo media de Prometheus
Para aqueles afeitos a manexar bases de datos de propósito xeral, a carga de traballo típica de Prometheus é bastante interesante. A taxa de acumulación de datos adoita ser estable: normalmente os servizos que supervisa envían aproximadamente o mesmo número de métricas e a infraestrutura cambia relativamente lentamente.
As solicitudes de información poden proceder de diversas fontes. Algúns deles, como as alertas, tamén se esforzan por un valor estable e previsible. Outros, como as solicitudes dos usuarios, poden provocar ráfagas, aínda que este non é o caso da maioría das cargas de traballo.
Proba de carga
Durante as probas, centreime na capacidade de acumular datos. Despleguei Prometheus 2.3.2 compilado con Go 1.10.1 (como parte de PMM 1.14) no servizo Linode usando este script: . Para a xeración de carga máis realista, use isto Lancei varios nodos de MySQL cunha carga real (proba Sysbench TPC-C), cada un dos cales emulaba 10 nodos Linux/MySQL.
Todas as seguintes probas realizáronse nun servidor Linode con oito núcleos virtuais e 32 GB de memoria, realizando 20 simulacións de carga monitorizando duascentas instancias de MySQL. Ou, en termos de Prometheus, 800 obxectivos, 440 scrapes por segundo, 380 mil rexistros por segundo e 1,7 millóns de series temporais activas.
Proxecto
O enfoque habitual das bases de datos tradicionais, incluída a utilizada por Prometheus 1.x, é a de . Se non é suficiente para xestionar a carga, experimentarás altas latencias e algunhas solicitudes fallarán. O uso da memoria en Prometheus 2 pódese configurar mediante unha tecla storage.tsdb.min-block-duration, que determina canto tempo se gardarán as gravacións na memoria antes de descargalas no disco (o predeterminado é 2 horas). A cantidade de memoria necesaria dependerá do número de series temporais, etiquetas e scrapes engadidos ao fluxo de entrada neto. En canto ao espazo no disco, Prometheus pretende utilizar 3 bytes por rexistro (mostra). Por outra banda, os requisitos de memoria son moito maiores.
Aínda que é posible configurar o tamaño do bloque, non se recomenda configuralo manualmente, polo que estás obrigado a darlle a Prometheus tanta memoria como necesite para a túa carga de traballo.
Se non hai memoria suficiente para soportar o fluxo de métricas entrante, Prometheus quedará sen memoria ou o asasino OOM chegará a ela.
Engadir intercambio para atrasar o accidente cando Prometheus queda sen memoria non axuda realmente, porque o uso desta función provoca un consumo explosivo de memoria. Creo que é algo que ver con Go, o seu colector de lixo e a forma en que trata o intercambio.
Outro enfoque interesante é configurar o bloque de cabeza para que se lance ao disco nun momento determinado, en lugar de contalo desde o inicio do proceso.
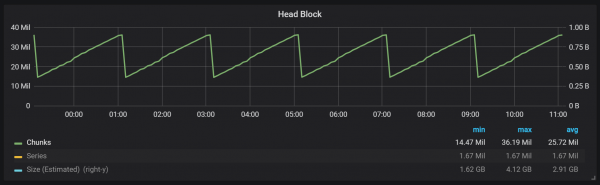
Como podes ver no gráfico, os lavados no disco ocorren cada dúas horas. Se cambia o parámetro de duración do bloque mínimo a unha hora, estes restableceranse cada hora, comezando despois de media hora.
Se queres usar este e outros gráficos na túa instalación de Prometheus, podes utilizalo . Foi deseñado para PMM pero, con pequenas modificacións, encaixa en calquera instalación de Prometheus.
Temos un bloque activo chamado head block que se almacena na memoria; os bloques con datos máis antigos están dispoñibles a través de mmap(). Isto elimina a necesidade de configurar a caché por separado, pero tamén significa que ten que deixar espazo suficiente para a caché do sistema operativo se quere consultar datos máis antigos que os que pode albergar o bloque principal.
Isto tamén significa que o consumo de memoria virtual de Prometheus parecerá bastante alto, o que non é algo do que preocuparse.
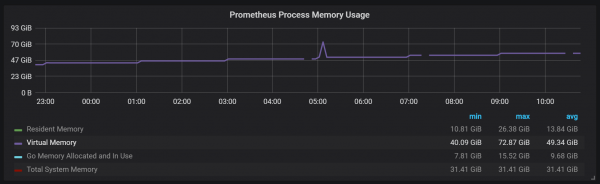
Outro punto de deseño interesante é o uso de WAL (write ahead log). Como podes ver na documentación de almacenamento, Prometheus usa WAL para evitar fallos. Desafortunadamente, os mecanismos específicos para garantir a supervivencia dos datos non están ben documentados. A versión 2.3.2 de Prometheus lava WAL no disco cada 10 segundos e esta opción non é configurable polo usuario.
Compactacións
Prometheus TSDB está deseñado como unha tenda LSM (Log Structured Merge): o bloque principal lánzase periodicamente ao disco, mentres que un mecanismo de compactación combina varios bloques xuntos para evitar escanear demasiados bloques durante as consultas. Aquí podes ver o número de bloques que observei no sistema de proba despois dun día de carga.
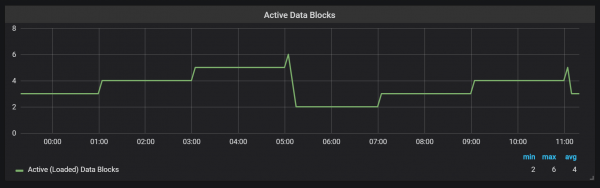
Se queres obter máis información sobre a tenda, podes examinar o ficheiro meta.json, que ten información sobre os bloques dispoñibles e como se crearon.
{
"ulid": "01CPZDPD1D9R019JS87TPV5MPE",
"minTime": 1536472800000,
"maxTime": 1536494400000,
"stats": {
"numSamples": 8292128378,
"numSeries": 1673622,
"numChunks": 69528220
},
"compaction": {
"level": 2,
"sources": [
"01CPYRY9MS465Y5ETM3SXFBV7X",
"01CPYZT0WRJ1JB1P0DP80VY5KJ",
"01CPZ6NR4Q3PDP3E57HEH760XS"
],
"parents": [
{
"ulid": "01CPYRY9MS465Y5ETM3SXFBV7X",
"minTime": 1536472800000,
"maxTime": 1536480000000
},
{
"ulid": "01CPYZT0WRJ1JB1P0DP80VY5KJ",
"minTime": 1536480000000,
"maxTime": 1536487200000
},
{
"ulid": "01CPZ6NR4Q3PDP3E57HEH760XS",
"minTime": 1536487200000,
"maxTime": 1536494400000
}
]
},
"version": 1
}As compactacións en Prometheus están ligadas ao momento en que o bloque da cabeza se lava ao disco. Neste punto, pódense realizar varias operacións deste tipo.
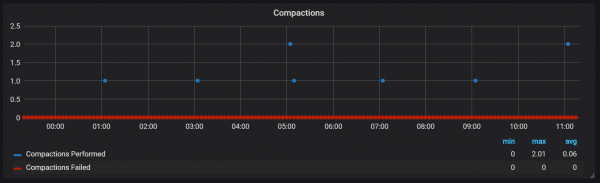
Parece que as compactacións non están limitadas de ningún xeito e poden causar grandes picos de E/S do disco durante a execución.
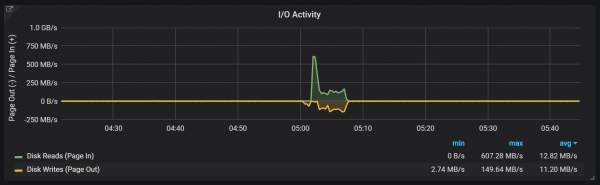
Picos de carga da CPU
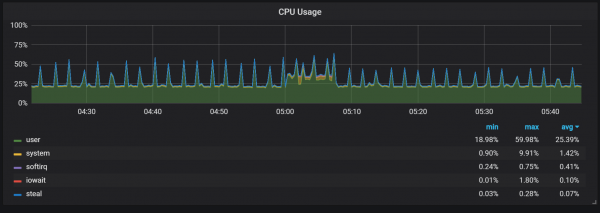
Por suposto, isto ten un impacto bastante negativo na velocidade do sistema e tamén supón un serio desafío para o almacenamento LSM: como facer a compactación para soportar altas taxas de solicitude sen causar demasiada sobrecarga?
O uso da memoria no proceso de compactación tamén parece bastante interesante.
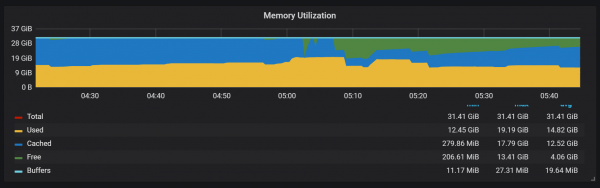
Podemos ver como, despois da compactación, a maior parte da memoria cambia de estado de Caché a Libre: isto significa que a información potencialmente valiosa foi eliminada de alí. Curioso se se usa aquí fadvice() ou algunha outra técnica de minimización, ou é porque a caché foi liberada de bloques destruídos durante a compactación?
Recuperación despois dun fallo
A recuperación dos fallos leva tempo e por unha boa razón. Para un fluxo de entrada dun millón de rexistros por segundo, tiven que esperar uns 25 minutos mentres se realizaba a recuperación tendo en conta a unidade SSD.
level=info ts=2018-09-13T13:38:14.09650965Z caller=main.go:222 msg="Starting Prometheus" version="(version=2.3.2, branch=v2.3.2, revision=71af5e29e815795e9dd14742ee7725682fa14b7b)"
level=info ts=2018-09-13T13:38:14.096599879Z caller=main.go:223 build_context="(go=go1.10.1, user=Jenkins, date=20180725-08:58:13OURCE)"
level=info ts=2018-09-13T13:38:14.096624109Z caller=main.go:224 host_details="(Linux 4.15.0-32-generic #35-Ubuntu SMP Fri Aug 10 17:58:07 UTC 2018 x86_64 1bee9e9b78cf (none))"
level=info ts=2018-09-13T13:38:14.096641396Z caller=main.go:225 fd_limits="(soft=1048576, hard=1048576)"
level=info ts=2018-09-13T13:38:14.097715256Z caller=web.go:415 component=web msg="Start listening for connections" address=:9090
level=info ts=2018-09-13T13:38:14.097400393Z caller=main.go:533 msg="Starting TSDB ..."
level=info ts=2018-09-13T13:38:14.098718401Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536530400000 maxt=1536537600000 ulid=01CQ0FW3ME8Q5W2AN5F9CB7R0R
level=info ts=2018-09-13T13:38:14.100315658Z caller=web.go:467 component=web msg="router prefix" prefix=/prometheus
level=info ts=2018-09-13T13:38:14.101793727Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536732000000 maxt=1536753600000 ulid=01CQ78486TNX5QZTBF049PQHSM
level=info ts=2018-09-13T13:38:14.102267346Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536537600000 maxt=1536732000000 ulid=01CQ78DE7HSQK0C0F5AZ46YGF0
level=info ts=2018-09-13T13:38:14.102660295Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536775200000 maxt=1536782400000 ulid=01CQ7SAT4RM21Y0PT5GNSS146Q
level=info ts=2018-09-13T13:38:14.103075885Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536753600000 maxt=1536775200000 ulid=01CQ7SV8WJ3C2W5S3RTAHC2GHB
level=error ts=2018-09-13T14:05:18.208469169Z caller=wal.go:275 component=tsdb msg="WAL corruption detected; truncating" err="unexpected CRC32 checksum d0465484, want 0" file=/opt/prometheus/data/.prom2-data/wal/007357 pos=15504363
level=info ts=2018-09-13T14:05:19.471459777Z caller=main.go:543 msg="TSDB started"
level=info ts=2018-09-13T14:05:19.471604598Z caller=main.go:603 msg="Loading configuration file" filename=/etc/prometheus.yml
level=info ts=2018-09-13T14:05:19.499156711Z caller=main.go:629 msg="Completed loading of configuration file" filename=/etc/prometheus.yml
level=info ts=2018-09-13T14:05:19.499228186Z caller=main.go:502 msg="Server is ready to receive web requests."O principal problema do proceso de recuperación é o alto consumo de memoria. A pesar de que nunha situación normal o servidor pode funcionar de forma estable coa mesma cantidade de memoria, se falla é posible que non se recupere debido a OOM. A única solución que atopei foi desactivar a recollida de datos, abrir o servidor, deixalo recuperar e reiniciar coa recollida activada.
Quecemento
Outro comportamento a ter en conta durante o quecemento é a relación entre o baixo rendemento e o alto consumo de recursos inmediatamente despois do inicio. Durante algúns, pero non todos os inicios, observei unha carga grave na CPU e na memoria.
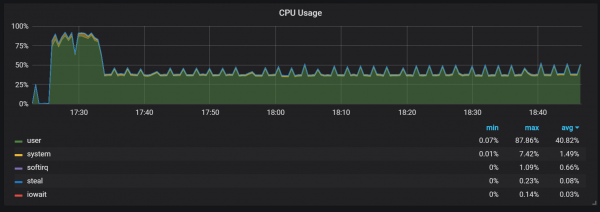
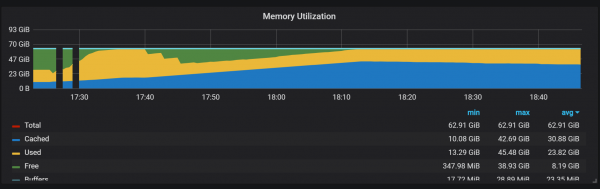
As lagoas no uso da memoria indican que Prometheus non pode configurar todas as coleccións desde o principio e pérdese algunha información.
Non descubrín as razóns exactas da alta carga de CPU e memoria. Sospeito que isto se debe á creación de novas series temporais no bloque de cabeza cunha alta frecuencia.
Aumento da carga da CPU
Ademais das compactacións, que crean unha carga de E/S bastante alta, notei picos graves na carga da CPU cada dous minutos. As ráfagas son máis longas cando o fluxo de entrada é alto e parecen ser causadas polo colector de lixo de Go, con polo menos algúns núcleos completamente cargados.
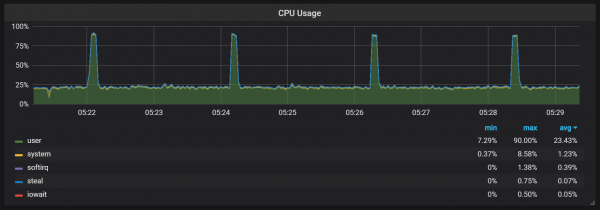
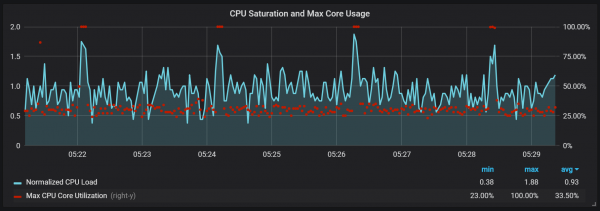
Estes saltos non son tan insignificantes. Parece que cando estes ocorren, o punto de entrada interno de Prometheus e as métricas non están dispoñibles, causando lagoas de datos durante estes mesmos períodos de tempo.
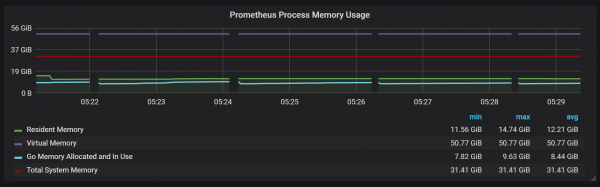
Tamén podes notar que o exportador de Prometheus apaga durante un segundo.
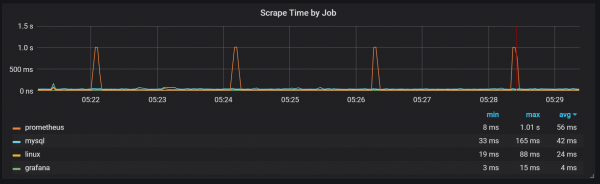
Podemos notar correlacións coa recollida de lixo (GC).
Conclusión
TSDB en Prometheus 2 é rápido, capaz de manexar millóns de series temporais e ao mesmo tempo miles de rexistros por segundo usando un hardware bastante modesto. A utilización de E/S da CPU e do disco tamén é impresionante. O meu exemplo mostrou ata 200 métricas por segundo por núcleo utilizado.
Para planificar a expansión, cómpre lembrar cantidades suficientes de memoria, e esta debe ser memoria real. A cantidade de memoria utilizada que observei foi duns 5 GB por cada 100 rexistros por segundo do fluxo de entrada, o que xunto coa caché do sistema operativo deu uns 000 GB de memoria ocupada.
Por suposto, aínda queda moito traballo por facer para domar os picos de E/S da CPU e do disco, e isto non é de estrañar tendo en conta o novo TSDB Prometheus 2 en comparación con InnoDB, TokuDB, RocksDB, WiredTiger, pero todos tiñan similares. problemas no inicio do seu ciclo de vida.
Fonte: www.habr.com
